《从零实现哈希表:详解设计、冲突解决与优化》
《从零实现哈希表:详解设计、冲突解决与优化》
文章目录
- 《从零实现哈希表:详解设计、冲突解决与优化》
- 一、哈希概念
- 1.1 直接定址法
- 1.2 哈希冲突
- 1.3 负载因子
- 1.4 将关键字转为整数
- 1.5 哈希函数
- 1.5.1 除法散列法/除留余数法
- 1.5.2 乘法散列法
- 1.5.3 全域散列法
- 1.6 处理哈希冲突
- 1.6.1 开放定址法
- 线性探测
- 二次探测
- 双重散列
- 1.6.2 开放定址法代码实现
- 扩容
- key不能取模的问题
- 完整代码实现
- 1.6.3 链地址法
- 解决冲突的思路
- 扩容
- 极端场景
- 1.6.4 链地址法代码实现
- 二、整体源代码实现
一、哈希概念

1.1 直接定址法


1.2 哈希冲突

1.3 负载因子

1.4 将关键字转为整数

1.5 哈希函数
一个好的哈希函数应该让N个关键字被等概率地均分的散列分布到哈希表的M个空间中,
但是实际中却很难做到,但是我们要尽量往这个方向去考量设计
1.5.1 除法散列法/除留余数法



1.5.2 乘法散列法

1.5.3 全域散列法

1.6 处理哈希冲突
实践中哈希表一般还是选择除法散列法作为哈希函数,当然哈希表无论选择什么哈希函数也避免不了冲突, 解决冲突的两种方法:开放定址发和链地址法
1.6.1 开放定址法

线性探测

二次探测

双重散列

1.6.2 开放定址法代码实现
开放定址法在实践中,不如下面讲的链地址发,因为开放定址法解决冲突不管使用哪种方法,
占用的都是哈希表中的空间,始终存在互相影响的问题。
所以开放定址法,我们简单选择线性探测实现即可
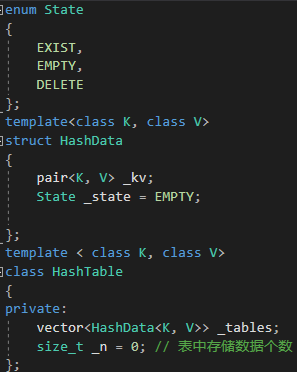
开放定址法的哈希表结构:代码如下(示例):
enum State
{EXIST,EMPTY,DELETE
};
template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;};
template < class K, class V>
class HashTable
{
private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数
};

扩容

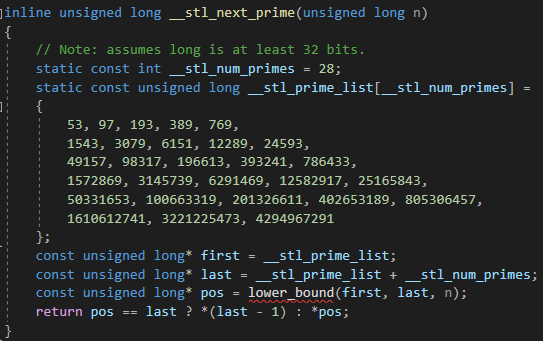
代码如下(示例):
inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}
key不能取模的问题

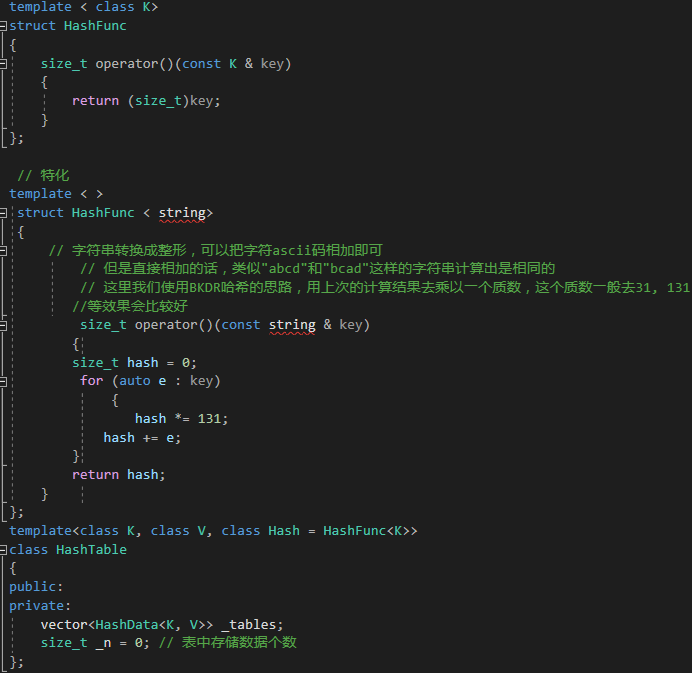
代码如下(示例):
template < class K>
struct HashFunc
{size_t operator()(const K & key){return (size_t)key;}
};// 特化
template < >struct HashFunc < string>{// 字符串转换成整形,可以把字符ascii码相加即可// 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的// 这⾥我们使⽤BKDR哈希的思路,⽤上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131//等效果会⽐较好size_t operator()(const string & key){size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
public:
private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数
};
完整代码实现
代码如下(示例):
namespace open_address
{enum State{EXIST,EMPTY,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}HashTable(){_tables.resize(__stl_next_prime(0));}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因⼦⼤于0.7就扩容if (_n * 10 / _tables.size() >= 7){// 这⾥利⽤类似深拷⻉现代写法的思想插⼊后交换解决HashTable<K, V, Hash> newHT;newHT._tables.resize(__stl_next_prime(_tables.size() + 1));for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}_tables.swap(newHT._tables);}Hash hash;size_t hash0 = hash(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state == EXIST){// 线性探测hashi = (hash0 + i) % _tables.size();// ⼆次探测就变成 +- i^2++i;}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}HashData<K, V>* Find(const K& key){Hash hash;size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}// 线性探测hashi = (hash0 + i) % _tables.size();++i;}return nullptr;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret == nullptr){return false;}else{ret->_state = DELETE;--_n;return true;}}private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数};
}
1.6.3 链地址法
解决冲突的思路

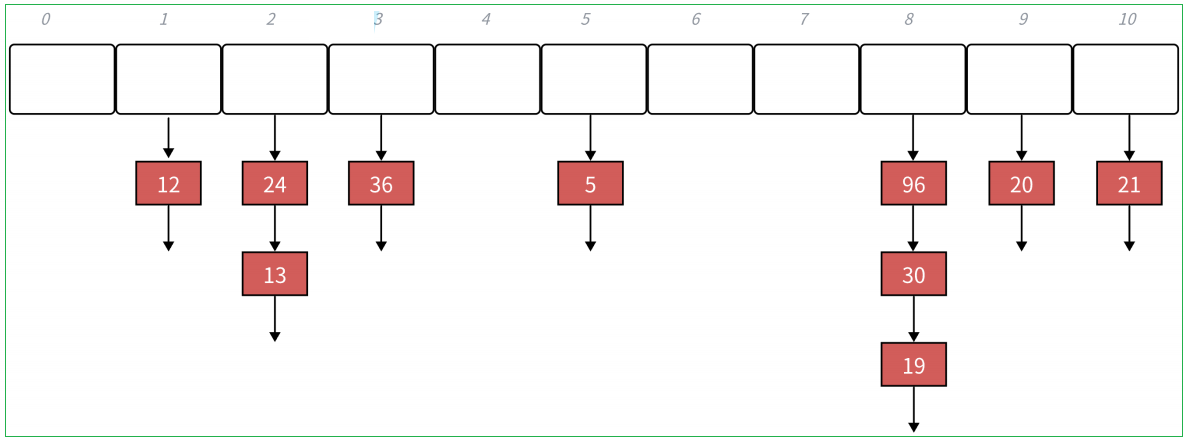
扩容

极端场景


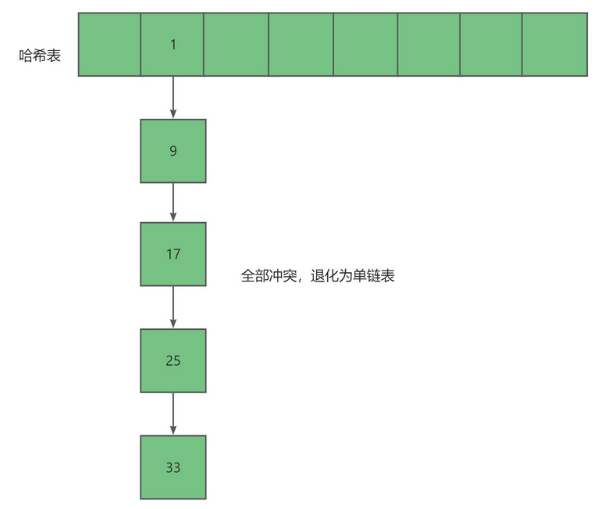
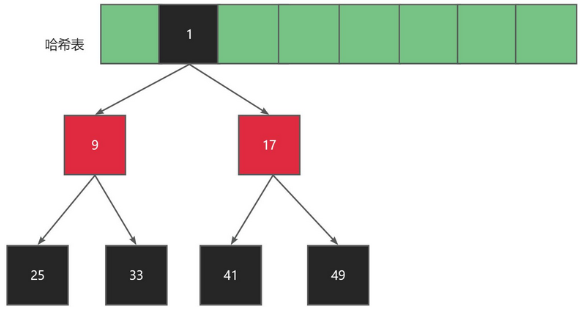
1.6.4 链地址法代码实现
代码如下(示例):
// 链地址法代码实现
namespace hash_bucket
{template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}public:HashTable(){_tables.resize(__stl_next_prime(0), nullptr);}// 拷⻉构造和赋值拷⻉需要实现深拷⻉,有兴趣的同学可以⾃⾏实现~HashTable(){// 依次把每个桶释放for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){Hash hs;size_t hashi = hs(kv.first) % _tables.size();// 负载因⼦==1扩容if (_n == _tables.size()){/*HashTable<K, V> newHT;newHT._tables.resize(__stl_next_prime(_tables.size()+1);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while(cur){newHT.Insert(cur->_kv);
cur = cur->_next;
}
}
_tables.swap(newHT._tables);*/
// 这⾥如果使⽤上⾯的⽅法,扩容时创建新的结点,后⾯还要使⽤就结点,浪费了// 下⾯的⽅法,直接移动旧表的结点到新表,效率更好vector<Node*>newtables(__stl_next_prime(_tables.size() + 1), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 旧表中节点,挪动新表重新映射的位置size_t hashi = hs(cur->_kv.first) %newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 表中存储数据个数};
}
二、整体源代码实现
代码如下(示例):
//enum State
//{
// EXIST,
// EMPTY,
// DELETE
//};
//template<class K, class V>
//struct HashData
//{
// pair<K, V> _kv;
// State _state = EMPTY;
//
//};
//template < class K, class V>
//class HashTable
//{
//private:
// vector<HashData<K, V>> _tables;
// size_t _n = 0; // 表中存储数据个数
//};
//
//
//inline unsigned long __stl_next_prime(unsigned long n)
//{
// // Note: assumes long is at least 32 bits.
// static const int __stl_num_primes = 28;
// static const unsigned long __stl_prime_list[__stl_num_primes] =
// {
// 53, 97, 193, 389, 769,
// 1543, 3079, 6151, 12289, 24593,
// 49157, 98317, 196613, 393241, 786433,
// 1572869, 3145739, 6291469, 12582917, 25165843,
// 50331653, 100663319, 201326611, 402653189, 805306457,
// 1610612741, 3221225473, 4294967291
// };
// const unsigned long* first = __stl_prime_list;
// const unsigned long* last = __stl_prime_list + __stl_num_primes;
// const unsigned long* pos = lower_bound(first, last, n);
// return pos == last ? *(last - 1) : *pos;
//}
//#include<string>
//
//template < class K>
//struct HashFunc
//{
// size_t operator()(const K & key)
// {
// return (size_t)key;
// }
//};
//
// // 特化
//template < >
// struct HashFunc < string>
// {
// // 字符串转换成整形,可以把字符ascii码相加即可
// // 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的
// // 这⾥我们使⽤BKDR哈希的思路,⽤上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131
// //等效果会⽐较好
// size_t operator()(const string & key)
// {
// size_t hash = 0;
// for (auto e : key)
// {
// hash *= 131;
// hash += e;
// }
// return hash;
// }
//};
//template<class K, class V, class Hash = HashFunc<K>>
//class HashTable
//{
//public:
//private:
// vector<HashData<K, V>> _tables;
// size_t _n = 0; // 表中存储数据个数
//};namespace open_address
{enum State{EXIST,EMPTY,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}HashTable(){_tables.resize(__stl_next_prime(0));}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因⼦⼤于0.7就扩容if (_n * 10 / _tables.size() >= 7){// 这⾥利⽤类似深拷⻉现代写法的思想插⼊后交换解决HashTable<K, V, Hash> newHT;newHT._tables.resize(__stl_next_prime(_tables.size() + 1));for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}_tables.swap(newHT._tables);}Hash hash;size_t hash0 = hash(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state == EXIST){// 线性探测hashi = (hash0 + i) % _tables.size();// ⼆次探测就变成 +- i^2++i;}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}HashData<K, V>* Find(const K& key){Hash hash;size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}// 线性探测hashi = (hash0 + i) % _tables.size();++i;}return nullptr;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret == nullptr){return false;}else{ret->_state = DELETE;--_n;return true;}}private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数};
}// 链地址法代码实现
namespace hash_bucket
{template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}public:HashTable(){_tables.resize(__stl_next_prime(0), nullptr);}// 拷⻉构造和赋值拷⻉需要实现深拷⻉,有兴趣的同学可以⾃⾏实现~HashTable(){// 依次把每个桶释放for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){Hash hs;size_t hashi = hs(kv.first) % _tables.size();// 负载因⼦==1扩容if (_n == _tables.size()){/*HashTable<K, V> newHT;newHT._tables.resize(__stl_next_prime(_tables.size()+1);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while(cur){newHT.Insert(cur->_kv);
cur = cur->_next;
}
}
_tables.swap(newHT._tables);*/
// 这⾥如果使⽤上⾯的⽅法,扩容时创建新的结点,后⾯还要使⽤就结点,浪费了// 下⾯的⽅法,直接移动旧表的结点到新表,效率更好vector<Node*>newtables(__stl_next_prime(_tables.size() + 1), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 旧表中节点,挪动新表重新映射的位置size_t hashi = hs(cur->_kv.first) %newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 表中存储数据个数};
}