闲鱼智能监控机器人:基于 Playwright 与 AI 的多任务监控分析工具
一、项目概述
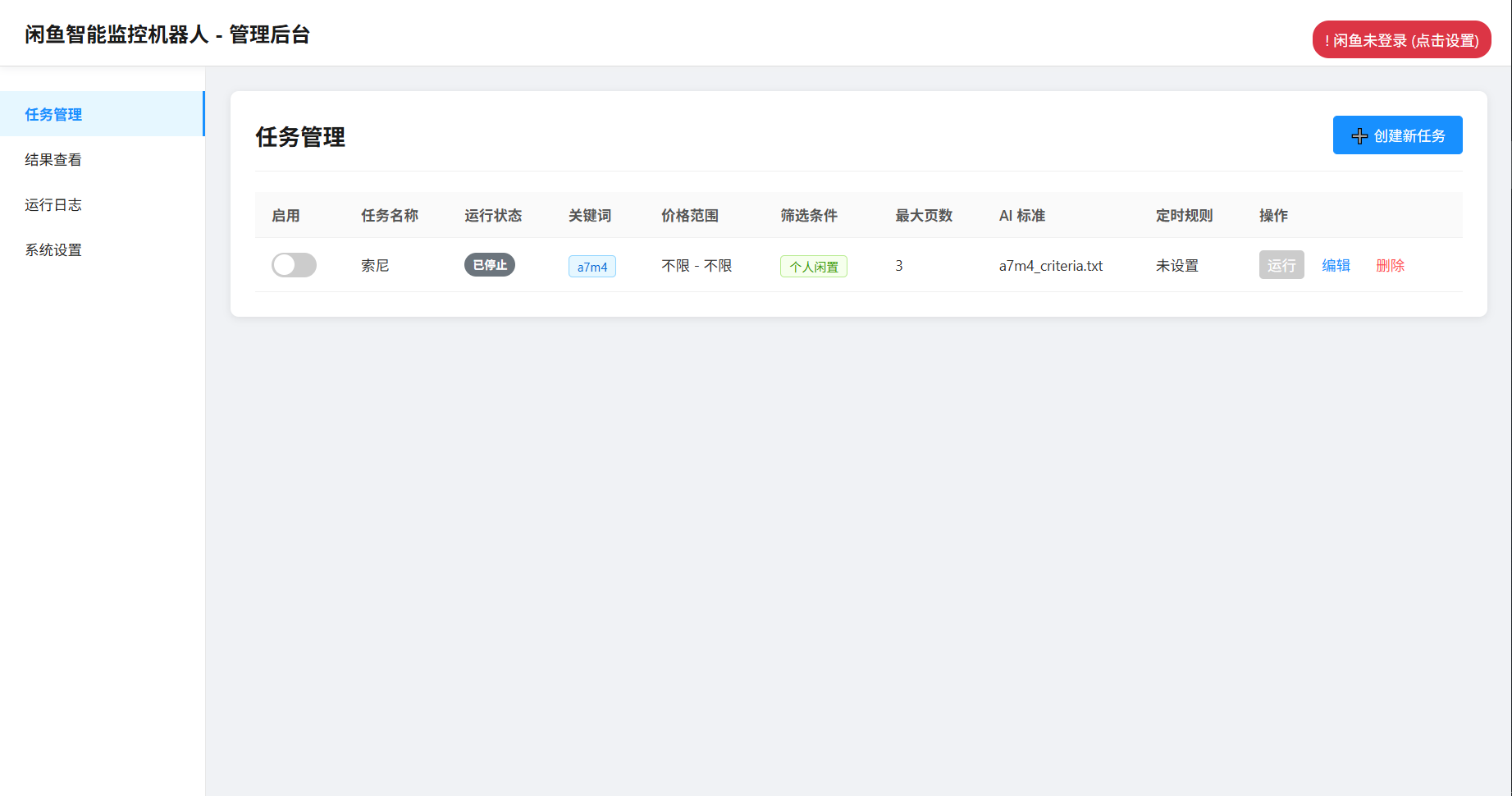
闲鱼智能监控机器人是一个借助 Playwright 实现模拟操作、结合 AI 进行过滤分析的闲鱼多任务实时监控与智能分析工具,具备功能完善的 Web 管理界面。它支持可视化任务管理、AI 驱动任务创建、多任务并发、实时流式处理、深度 AI 分析等特性,还能实现即时通知、定时任务调度、Docker 一键部署等,在闲鱼商品监控场景中作用显著。
二、代码结构总览
从项目文件结构来看,主要包含以下几类关键文件和目录,各自承担不同功能,共同支撑项目运行:
ai - goofish - monitor
├── .github/workflows # GitHub Actions 工作流配置,用于自动化 CI/CD
├── chrome - extension # Chrome 扩展相关文件,辅助提取闲鱼登录状态
├── prompts # 存放提示词相关内容,用于与 AI 交互时的指令引导
├── src # 核心功能代码目录,可能包含业务逻辑实现等
├── static # 静态资源目录,如页面样式、图片等,用于 Web 界面
├── templates # 模板文件目录,可能用于生成 Web 页面等
├── .env.example # 环境变量示例文件,复制后配置实际环境变量
├── .gitignore # Git 忽略规则文件,指定无需版本控制的文件/目录
├── AUTH_README.md # 认证相关说明文档
├── DISCLAIMER.md # 免责声明文档
├── Dockerfile # Docker 镜像构建配置文件,用于容器化部署
├── FAQ.md # 常见问题解答文档
├── LICENSE # 项目许可证文件,规定使用权限等
├── README.md # 项目核心说明文档,介绍功能、使用方法等
├── config.json.example # 配置文件示例,复制后配置实际监控任务等信息
├── docker - compose.yaml # Docker Compose 配置文件,实现多容器编排部署
├── login.py # 登录相关脚本,用于获取闲鱼登录状态
├── prompt_generator.py # 提示词生成器,为 AI 交互生成合适的提示内容
├── requirements.txt # Python 依赖包列表,用于安装项目所需库
├── spider_v2.py # 爬虫核心脚本,负责抓取闲鱼商品数据
└── web_server.py # Web 服务器脚本,提供 Web 管理界面相关服务三、核心模块代码结构分析
(一)爬虫模块(spider_v2.py)
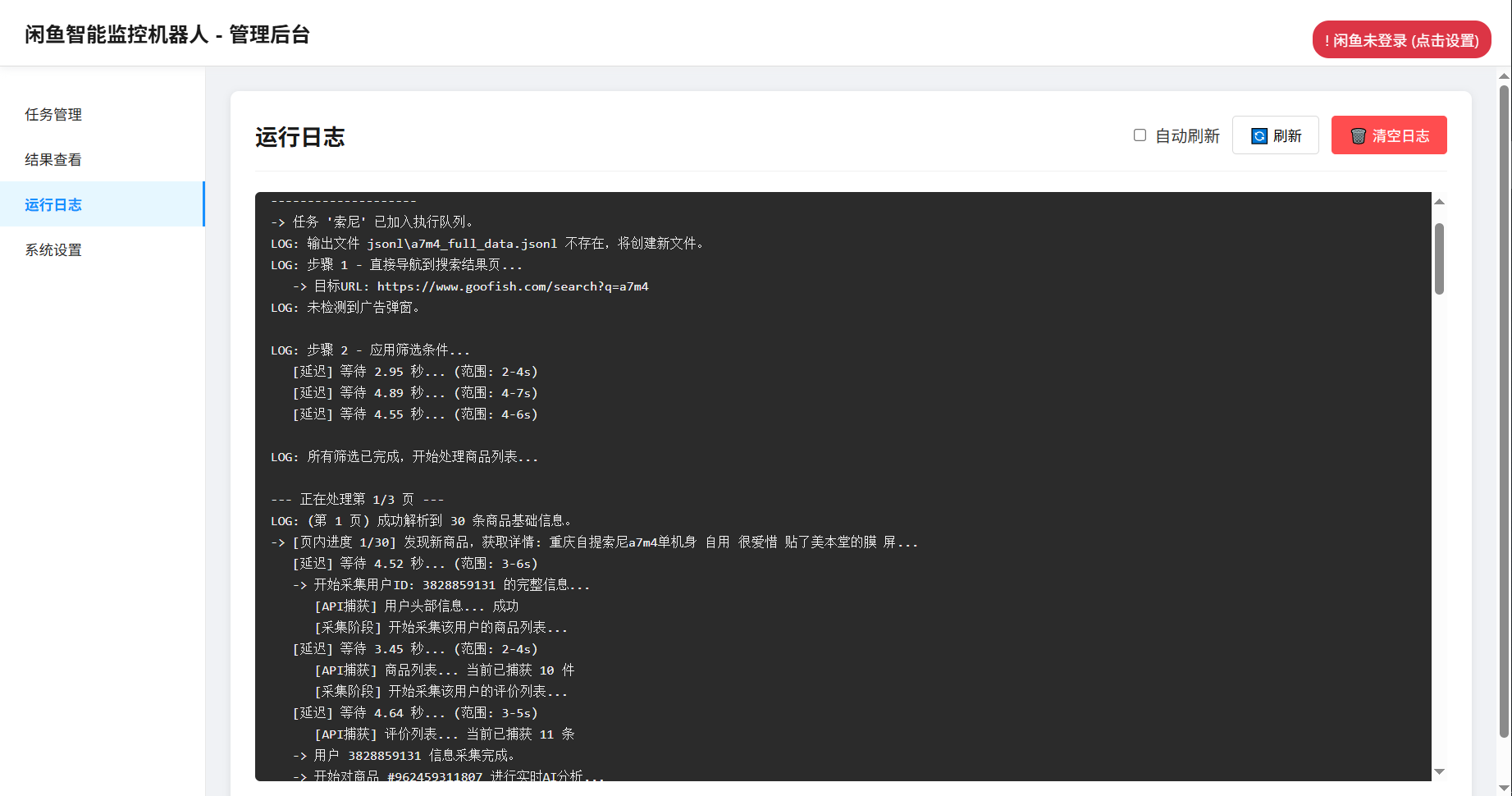
- 功能定位:负责模拟用户操作闲鱼页面,抓取商品数据,是实现监控功能的基础数据来源模块。它模拟真人操作,包含随机延迟、多样用户行为等反爬策略,保障数据获取的稳定性。
- 关键逻辑:
- 利用 Playwright 库启动浏览器,模拟登录后访问闲鱼搜索页面。通过
page.goto()跳转页面,page.fill()page.click()等方法模拟用户输入、点击等交互,实现搜索商品操作。 - 配置随机延迟,如在页面操作之间插入
time.sleep(random.uniform(2, 5))(示例,实际可能结合 Playwright 等待机制更优雅实现),模拟真人操作节奏,规避反爬机制。 - 解析页面元素,提取商品的标题、价格、描述、卖家信息等数据,可能使用
page.locator()定位元素,再通过text_content()get_attribute()等方法提取信息,如:
from playwright.sync_api import sync_playwrightdef crawl_xianyu(keyword):with sync_playwright() as p:browser = p.chromium.launch(headless=False) # 可根据配置决定是否无头运行page = browser.new_page()# 模拟登录等操作,此处省略具体登录态处理,实际需结合登录模块获取的状态page.goto(f"https://2.taobao.com/search?q={keyword}") # 闲鱼搜索页面# 随机延迟,模拟真人操作import timetime.sleep(3) # 提取商品数据items = page.locator('.item J_MouserOnverReq ') # 假设商品列表元素定位器for item in items.element_handles():title = item.locator('.J_MemoCtrl').text_content()price = item.locator('.J_price').text_content()# 继续提取其他字段...yield {'title': title, 'price': price}browser.close() - 利用 Playwright 库启动浏览器,模拟登录后访问闲鱼搜索页面。通过
- 与其他模块交互:获取
login.py提供的登录状态,确保以登录态爬取数据;将抓取到的商品数据传递给 AI 分析模块(可能在src等目录中),进行深度处理。
(二)Web 服务器模块(web_server.py)
- 功能定位:搭建 Web 管理界面服务,提供可视化操作入口,让用户能通过浏览器管理监控任务、查看运行日志、配置系统参数等,是用户与工具交互的核心模块。
- 关键逻辑:
- 使用 Flask 或类似 Web 框架(从功能推测,实际需看代码实现)创建 Web 应用,定义路由,如
@app.route('/task_management')对应任务管理页面,@app.route('/system_settings')对应系统设置页面。 - 实现用户认证,基于 Basic 认证,校验登录用户名和密码(与
.env中配置的WEB_USERNAMEWEB_PASSWORD关联),保护管理界面安全,示例(Flask 为例):
- 使用 Flask 或类似 Web 框架(从功能推测,实际需看代码实现)创建 Web 应用,定义路由,如
from flask import Flask, request, Response
import osapp = Flask(__name__)@app.before_request
def check_auth():auth = request.authorizationif not auth or auth.username != os.getenv('WEB_USERNAME') or auth.password != os.getenv('WEB_PASSWORD'):return Response('Unauthorized', 401, {'WWW-Authenticate': 'Basic realm="Login Required"'})@app.route('/')
def index():return "Welcome to AI Goofish Monitor Web Server"- 对接任务管理、结果查看、运行日志、系统设置等功能模块,将用户操作转化为对后台任务的创建、启动、停止等指令,同时从其他模块获取数据展示到 Web 界面,如从
spider_v2.py获取爬虫运行状态,从 AI 分析模块获取商品分析结果。 - 与其他模块交互:接收前端页面(基于
statictemplates目录资源渲染)的用户操作请求,调用任务管理相关逻辑(可能在src等目录)执行监控任务;从spider_v2.pyprompt_generator.py等模块获取数据,展示任务运行状态、商品监控结果等。
(三)AI 分析模块(结合prompt_generator.py及可能的 AI 调用逻辑)
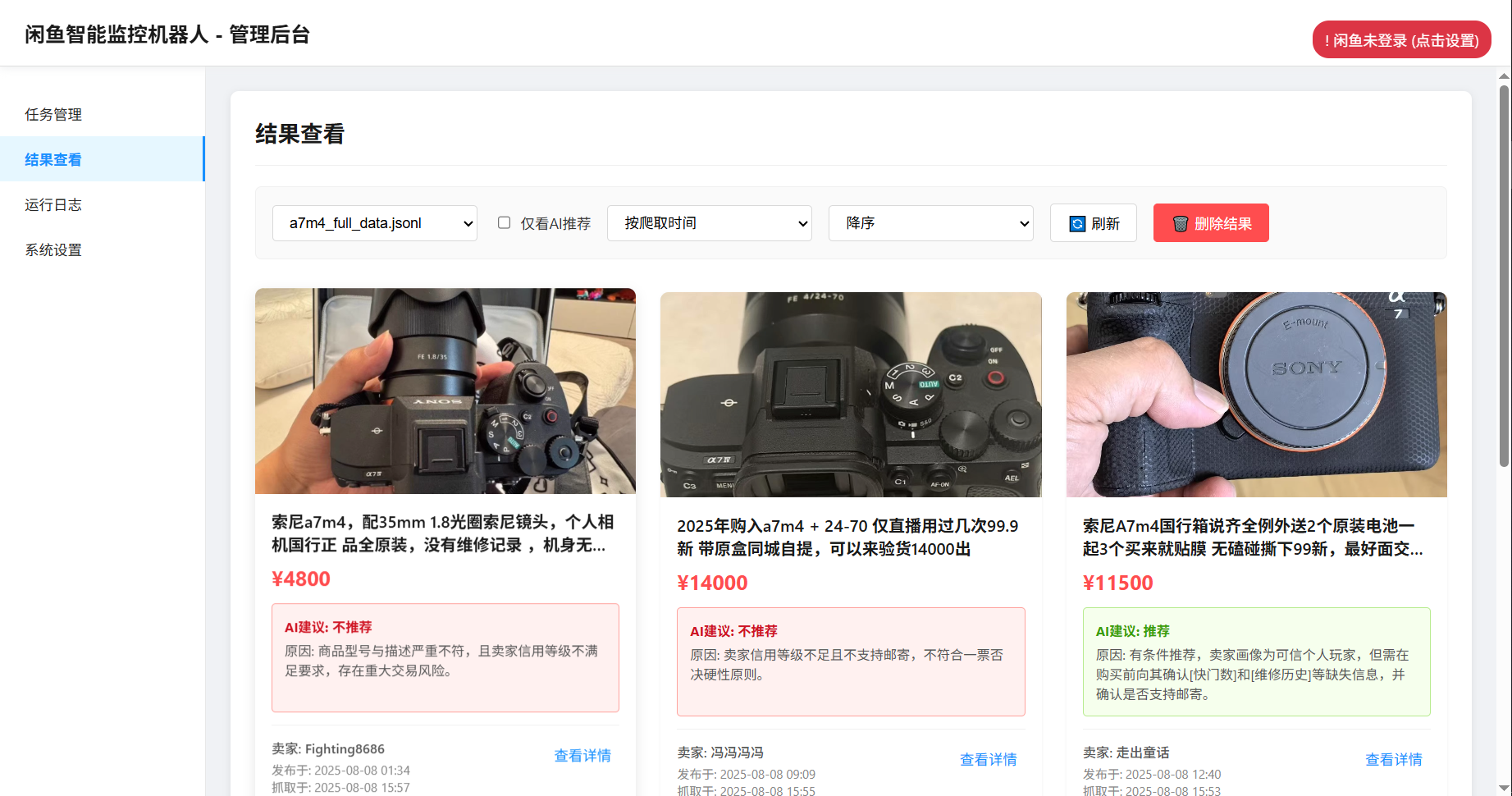
- 功能定位:集成多模态大语言模型,对爬虫模块抓取的商品数据进行深度分析,结合商品图文、卖家画像等筛选出符合用户需求的商品,是实现智能监控的核心模块,让工具具备 “智能” 判断能力。
- 关键逻辑:
prompt_generator.py根据用户创建任务时的自然语言需求,生成合适的 AI 提示词(Prompt),引导 AI 模型进行分析。例如用户需求是 “95 新以上的索尼 A7M4 相机,预算 1 万 3 以内,快门数低于 5000”,会生成包含这些条件的提示内容:
def generate_prompt(user_requirement):prompt_template = "请分析以下闲鱼商品数据,筛选出符合需求的商品:{user_requirement},需结合商品图文、卖家信息等进行判断,给出是否推荐的结论及理由"return prompt_template.format(user_requirement=user_requirement)
- 调用 AI 模型(如 GPT - 4o 等,通过
OPENAI_BASE_URLOPENAI_MODEL_NAME等环境变量配置的接口),传入提示词和商品数据,获取 AI 分析结果,示例(假设使用 OpenAI API 交互,实际可能根据配置的 API 调整):
import openai
import osopenai.api_key = os.getenv('OPENAI_API_KEY')
openai.api_base = os.getenv('OPENAI_BASE_URL')def analyze_with_ai(prompt, product_data):response = openai.ChatCompletion.create(model=os.getenv('OPENAI_MODEL_NAME'),messages=[{"role": "user", "content": f"{prompt},商品数据:{product_data}"}])return response.choices[0].message.content
- 解析 AI 返回结果,判断商品是否符合需求,提取分析理由等信息,用于后续通知和 Web 界面展示。
- 与其他模块交互:接收
spider_v2.py传递的商品数据,接收prompt_generator.py生成的提示词;将分析结果传递给web_server.py用于展示,传递给通知模块(如ntfy.sh、企业微信群机器人等相关通知逻辑代码)进行消息推送。
(四)登录模块(login.py)
- 功能定位:负责获取闲鱼的登录状态,让爬虫能以登录态访问页面,获取更多商品信息、规避部分限制,是保障数据获取全面性和稳定性的基础模块。
- 关键逻辑:
- 提供两种获取登录状态的方式,推荐的 Web UI 方式通过引导用户在个人电脑 Chrome 浏览器安装扩展、提取登录状态;备用的脚本方式
python login.py会弹出浏览器窗口,让用户扫码登录,成功后生成xianyu_state.json文件保存登录信息,核心代码逻辑(以 Playwright 实现为例):
- 提供两种获取登录状态的方式,推荐的 Web UI 方式通过引导用户在个人电脑 Chrome 浏览器安装扩展、提取登录状态;备用的脚本方式
from playwright.sync_api import sync_playwright
import jsondef get_login_state():with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto('https://www.goofish.com/login') # 闲鱼登录页面# 等待用户扫码登录,可通过页面元素判断登录状态page.wait_for_selector('.login - success - indicator') cookies = page.context.cookies()# 保存登录状态到文件with open('xianyu_state.json', 'w') as f:json.dump(cookies, f)browser.close()return cookies
- 与其他模块交互:将获取的登录状态提供给
spider_v2.py,使其能以登录态爬取数据;在 Web UI 方式中,与web_server.py的系统设置页面交互,接收用户通过扩展提取的登录状态并保存、使用。
(五)任务管理与配置相关(config.json.example .env.example等)
- 功能定位:
config.json.example用于配置多任务监控信息,如同时监控的关键词、各任务的价格范围等;.env.example用于配置项目运行的环境变量,涵盖 AI 接口、通知方式、Web 服务等各类参数,是项目个性化配置的核心载体,让工具能适配不同运行环境和用户需求。 - 关键逻辑:
config.json.example以 JSON 格式组织任务配置,示例如下:
{"tasks": [{"keyword": "索尼A7M4","price_range": "10000 - 13000","filter_conditions": "95新以上,快门数低于5000","ai_prompt": "按照需求筛选商品"}]
}
.env.example以键值对形式定义环境变量,如:
OPENAI_API_KEY=your_api_key_here
OPENAI_BASE_URL=https://api.example.com
# 其他环境变量...
- 项目启动时,会加载这些配置文件(实际运行需复制为
config.json.env并填入真实值 ),spider_v2.pyweb_server.py等模块通过读取这些配置,确定监控任务、AI 接口、通知方式等参数,实现不同任务并行、个性化功能启用等。
- 与其他模块交互:
spider_v2.py读取config.json中的任务配置,执行对应的监控任务;web_server.py读取.env中的WEB_USERNAMEWEB_PASSWORD等配置,实现 Web 界面认证和服务端口设置;AI 分析模块读取OPENAI_API_KEY等配置,连接对应的 AI 模型接口。
四、项目运行流程梳理
- 环境准备与配置:用户克隆项目后,安装
requirements.txt中的 Python 依赖,复制.env.example为.env、config.json.example为config.json并填入真实配置(如 AI 接口密钥、通知方式参数、Web 登录账号等 ),获取闲鱼登录状态(通过 Web UI 扩展或login.py脚本方式 )。 - 启动 Web 服务:运行
web_server.py,启动 Web 管理界面,用户通过浏览器访问对应地址(如http://127.0.0.1:8000),使用配置的账号密码登录。 - 创建与管理任务:在 Web 界面的任务管理页面,用户以自然语言描述需求创建任务,
prompt_generator.py生成提示词,spider_v2.py根据任务配置和登录状态,以 Playwright 模拟操作爬取商品数据。 - 数据处理与分析:爬虫获取商品数据后,立即进入 AI 分析流程,
ai - analyze模块调用 AI 模型,结合提示词分析商品是否符合需求,生成分析结果。 - 结果展示与通知:AI 分析结果回传到 Web 界面展示,同时若商品符合需求,通过配置的通知方式(如 ntfy.sh、企业微信等 )推送给用户;任务运行日志等信息也实时在 Web 界面呈现,方便用户监控工具运行状态。
- 任务调度与持续运行:依据
config.json或 Web 界面设置的定时规则(Cron 表达式 ),web_server.py调度spider_v2.py等模块,持续执行监控任务,实现对闲鱼商品的实时、智能监控。