Linux中Docker redis介绍以及应用
一、NoSQL
1.1 单机mysql的美好时代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。
那个时候,更多的是静态网页,动态交互类型的网站不多。

上述架构上,我们来看看数据存储的瓶颈是什么?
DAL:Data Access Layer(数据库访问层)
-
数据量的总大小一个机器放不下时
-
数据的索引(B+ Tree)一个机器的内存放不下时
-
访问量(读写混合)一个实例不能承受
如果满足了上面的1 or 3 个时,只能对数据库的整体架构进行重构
1.2 mysql主从读写分离
读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。
Mysql的master-slave模式成为这个时候的网站标配了。
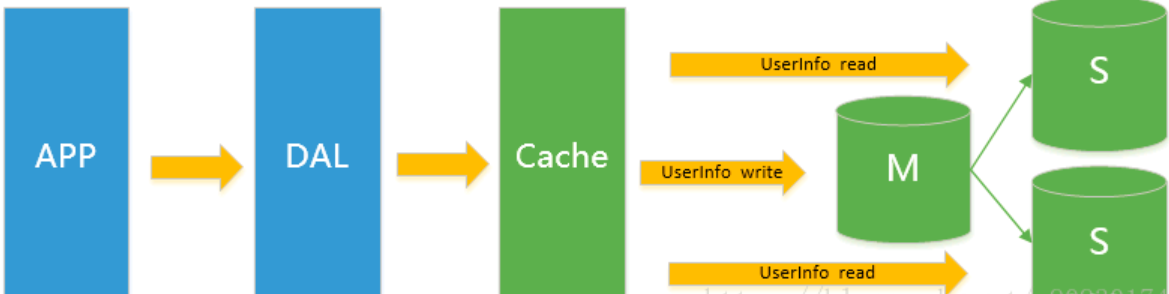
1.3 MySQL的扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。
比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。
关系数据库很强大,但是它并不能很好的应付所有的应用场景。
MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的人员面临的问题。
1.4 今天是什么样子
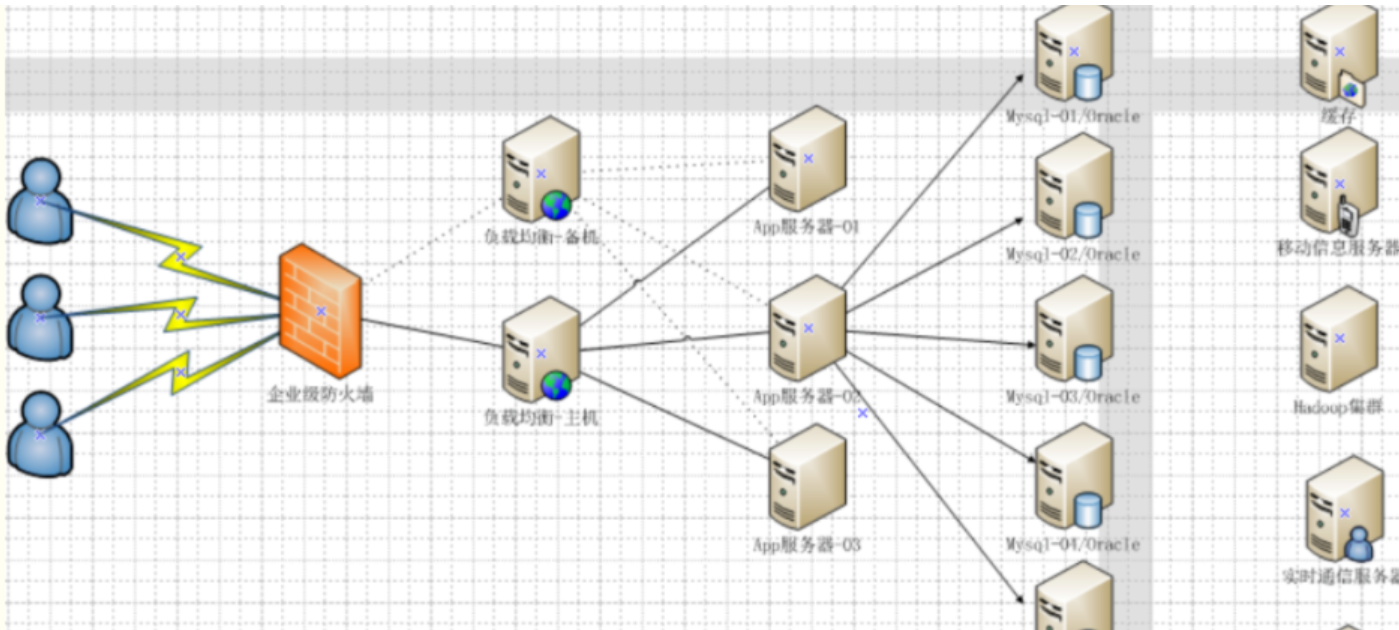
最前面的是企业级防火墙,后面通过负载均衡主机在 web 服务器集群之间进行调度,再由具体的 web 服务器(Tomcat)去访问缓存,访问数据库。
1.5 为什么用nosql
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。
用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。
我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
1.6 什么是nosql
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”。
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。
这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
1.7 nosql代表
MongoDB、Redis 和 Memcached 都是非常流行的数据库/缓存解决方案,但它们的设计目标和使用场景有所不同。
以下是这三个软件的简要分析及其主要区别的表格:
-
MongoDB:虽然MongoDB主要是作为一个NoSQL数据库被广泛认知,它提供了一个灵活的文档存储模型(JSON-like documents),适用于处理各种类型的数据。尽管MongoDB可以作为缓存层使用,但这并不是它的主要用途。MongoDB更适合于需要复杂查询和数据持久化的应用场景。
-
Redis:Redis是一个开源的内存数据结构存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构如字符串、哈希、列表、集合等,并且提供了丰富的操作命令。由于所有数据都存储在内存中,Redis读写速度非常快,适合用于实时数据分析、计数器、排行榜等高性能要求的场景。
-
Memcached:Memcached是一种高性能的分布式内存对象缓存系统,主要用于加速动态Web应用程序的数据访问速度。与Redis相比,Memcached更简单,只支持基本的键值对存储,并且不支持持久化存储。它非常适合用来缓存简单的对象,如HTML片段或数据库查询结果。
| 特性 | MongoDB | Redis | Memcached |
|---|---|---|---|
| 类型 | 文档型NoSQL数据库 | 内存数据结构存储(键值对) | 分布式内存缓存 |
| 主要用途 | 数据库 | 数据库、缓存、消息中间件 | 缓存 |
| 数据结构 | JSON-like文档 | 字符串、哈希、列表、集合等多种数据结构 | 键值对 |
| 持久化 | 支持 | 可选(默认情况下为内存存储) | 不支持 |
| 扩展性 | 水平扩展(分片) | 主从复制、哨兵、集群模式 | 分布式架构 |
| 性能 | 中等(磁盘I/O影响性能) | 高(全内存操作) | 高(全内存操作) |
| 适用场景 | 复杂查询、大数据集 | 实时分析、高速交易、队列 | 加速页面加载、缓存数据库查询结果 |
1.8 关系数据库和nosql的区别
RDBMS
-
高度组织化的结构化数据
-
结构化查询语言(SQL)
-
数据和关系都存储在单独的表中
-
数据操作语言,数据定义语言
-
严格的一致性
-
基础事务
-
ACID原则(事务的特性)
-
A (Atomicity) 原子性:原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
-
C (Consistency) 一致性:一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
-
I (Isolation) 独立性:所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的
-
D (Durability) 持久性:持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
-
nosql
-
没有声明性查询语言
-
没有预定义的模式
-
键 - 值对存储,列存储,文档存储,图形数据库
-
最终一致性,而非ACID属性
-
非结构化和不可预知的数据
-
高性能,高可用性和可伸缩性
-
CAP定理(说明:C:强一致性 A:高可用性 P:分布式容忍性)
-
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
-
Availability(可用性), 好的响应性能
-
Partition tolerance(分区容错性) 可靠性
-
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
1.9 小结
-
在性能方面,NoSQL数据库使用一些算法将对磁盘的随机写转换成顺序写,提升了写的性能
-
在扩展性方面,NoSQL数据库天生支持分布式,支持数据冗余和数据分片的特性
-
在某些场景下,比如全文搜索功能,关系型数据库并不能高效的支持,需要NoSQL数据库的支持
二、软件实践
Redis 是一个开源的内存数据结构存储系统,通常用作数据库、缓存和消息中间件。
它支持多种数据类型,如字符串(String)、哈希(Hash)、列表(List)、集合(Set)以及有序集合(Sorted Set)。
拉取 Redis 镜像
在终端或中运行以下命令来拉取最新的 Redis 官方镜像:
docker pull redis运行 Redis 容器
使用命令启动一个 Redis 容器:
docker run --name my-redis -d redis连接到 Redis 容器
可以使用 Docker 命令进入 Redis 容器内部,然后使用 Redis CLI 来与 Redis 实例进行交互:
docker exec -it my-redis redis-cli字符串(String)
字符串是最基础的数据类型,也是 Redis 的默认数据类型。
SET:设置键值对。
SET key value示例:
set name jackGET:获取键对应的值。
GET key示例:
get name 哈希(Hash)
哈希是用于存储字段和字段值的映射表,适合存储对象。
HSET:设置哈希表中的字段值。
HSET hash field value示例:
hset person name lshhset person age 18HGET:获取哈希表中指定字段的值。
HGET hash field示例:
HGET person name列表(List)
列表是一个简单的字符串列表,按照插入顺序排序。可以从列表的两端进行添加或移除元素。
LPUSH:在列表的左侧插入一个或多个值。
LPUSH list value [value ...]示例:
LPUSH mylist "a" "b"LRANGE:获取列表中指定范围的元素。
LRANGE mylist 0 -1注释:
-1 指的是最后一位集合(Set)
集合是一个无序不重复元素的集合。
SADD:向集合中添加一个或多个成员。
SADD set member [member ...]示例:
sadd names qwe asd zxcSMEMBERS:返回集合中的所有成员。
smembers namesSPOP:随机从集合中抽一个值
spop names有序集合(Sorted Set)
有序集合类似于集合,但每个成员都关联了一个分数,这使得成员可以根据分数来排序。
ZADD:向有序集合中添加一个或多个成员,或者更新已存在成员的分数。
ZADD zset score member [[score member] [score member] ...]示例:
zadd socres 60 wxqzadd socres 70 jyxZRANGE:返回有序集中指定区间内的成员,按分数值递增排序。
ZRANGE zset start stop [WITHSCORES]示例:
zrange socres 0 -1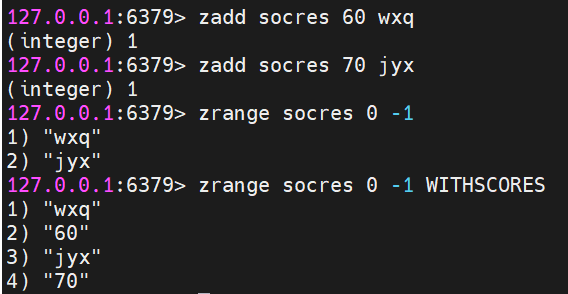
三、主从复制与哨兵模式
Redis的主从复制和哨兵模式是两种不同的机制,旨在提高系统的可用性和数据冗余度。它们各自有不同的目标和实现方式。
主从复制(Replication)
主从复制是指Redis支持单个master节点对应多个slave节点的一种架构模式。在这种模式下:
-
数据同步:Master节点可以进行读写操作,而Slave节点只能进行读操作。Master会自动将数据更新同步给所有连接的Slave节点。
-
高可用性:通过增加Slave节点数量来提升读取性能,并提供一定的数据冗余。如果Master节点发生故障,虽然可以通过手动切换到某个Slave节点作为新的Master节点继续服务,但这个过程需要人工干预,不能自动完成故障转移。
-
配置简单:只需要在配置文件中指定slaveof参数即可让一个Redis实例成为另一个实例的Slave。
哨兵模式(Sentinel)
哨兵模式是在主从复制的基础上增加了自动故障检测和自动故障转移的功能,确保系统具有更高的可用性:
-
监控:哨兵系统可以监控多个Master-Slave集群,持续检查Master和Slave实例的健康状态。
-
通知:当发现Master节点不可用时,哨兵系统能够自动执行故障转移策略,即将其中一个Slave提升为新的Master,并更新其他Slave的配置指向新的Master。
-
自动化故障转移:无需人工干预即可完成故障恢复,减少了停机时间。
-
配置管理:哨兵系统还负责客户端请求的重定向,确保客户端能够正确地连接到当前的Master节点。
| 特性 | 主从复制 | 哨兵模式 |
|---|---|---|
| 数据同步 | Master向Slave同步数据 | 在Master失效后,由Sentinel选择一个Slave晋升为Master并同步数据 |
| 故障处理 | 需要手动干预进行故障转移 | 自动检测故障并自动进行故障转移 |
| 监控能力 | 不具备监控和自动恢复功能 | 提供了对Redis实例的监控及自动恢复服务 |
| 高可用性 | 提供了一定程度的数据冗余,但不保证服务不间断 | 通过自动故障转移提高了系统的高可用性 |
| 使用场景 | 适合于读写分离、数据备份等需求 | 适用于需要高度自动化运维、减少人为干预的场景 |
创建自定义网络
docker network create redis-net启动 Redis Master
docker run -d \--name redis-master \--network redis-net \-p 6379:6379 \redis启动 Redis Slave
docker run -d \--name redis-slave1 \--network redis-net \redis \redis-server --slaveof redis-master 6379docker run -d \--name redis-slave2 \--network redis-net \redis \redis-server --slaveof redis-master 6379查看是否主从复制连接成功
docker logs redis-slave1
查看当前的主从状态
可以通过以下命令进入任意一个 Redis 实例来查看其角色(Master 或 Slave)。
检查 Redis Master 状态
-- 进入redis-master客户端
docker exec -it redis-master redis-cliINFO replication会看到类似于以下内容,表明它是某个 Master 的 Slave:

配置并启动 Sentinel(哨兵)
配置 sentinel.conf 文件,内容如下:
port 26379
dir /tmp
sentinel monitor mymaster redis-master 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 10000
sentinel parallel-syncs mymaster 1注释:
sentinel 哨兵
monitor 监控器
mymaster 集群名(可以随便写)
redis-master 主服务器名字
6379 端口号
1 投票数量(只要投票有1票通过就可以胜任新的主服务器)
down-after-milliseconds 下线时间(主服务器如果5s没有响应,就将其下线)| 配置项 | 含义 | 示例值 |
|---|---|---|
port | Sentinel 监听的端口 | 26379 |
dir | Sentinel 工作目录 | /tmp |
sentinel monitor | 监控的主节点信息 | mymaster redis-master 6379 1 |
sentinel down-after-milliseconds | 多久没响应视为下线 | 5000 ms |
sentinel failover-timeout | 故障转移最大等待时间 | 10000 ms |
sentinel parallel-syncs | 同步新 Master 的 Slave 并发数 | 1 |
然后运行 Sentinel 容器:
docker run -d \--name redis-sentinel \--network redis-net \-p 26379:26379 \-v $(pwd)/sentinel.conf:/usr/local/etc/redis/sentinel.conf \redis \redis-sentinel /usr/local/etc/redis/sentinel.conf检查哨兵是否运行成功:

查看哨兵日志
docker logs redis-sentinel
查看主服务器ip
docker inspect redis-master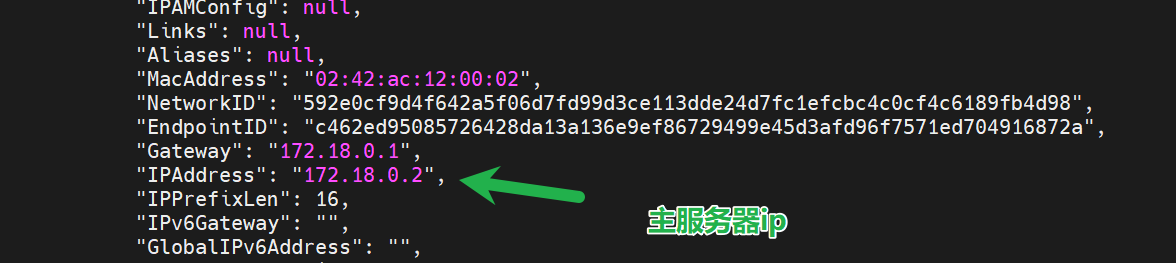
修改哨兵配置文件
vim sentinel.conf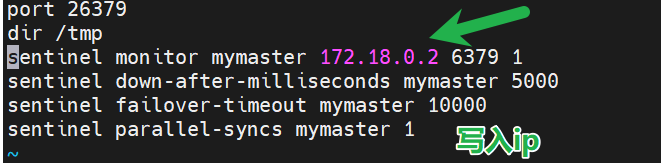
然后重新启动哨兵
docker restart redis-sentinel
如果怕ip会变,可将ip固定
docker run -d \--name redis-master \--network redis-net \--ip 【查询详情里的ip写入即可】-p 6379:6379 \redis注意:其他服务器也可以固定手动触发故障转移
现在让我们模拟 Master 故障的情况。停止 Redis Master 容器:
docker stop redis-master查看哨兵日志
docker logs redis-sentinel
第一句话意思是:检测到主服务器挂了
第二句话意思是:已经选择为172.18.0.4的从服务器为新的主服务器
等待几秒钟后,检查 Sentinel 是否已经将其中一个 Slave 提升为新的 Master。可以通过连接到 Sentinel 来查询当前的 Master:
docker exec -it redis-sentinel redis-cli -p 26379SENTINEL get-master-addr-by-name mymaster如果一切正常,应该得到新 Master 的 IP 地址和端口。
验证故障转移后的状态
再次使用 INFO replication 命令分别检查原 Slave(现在应该是新的 Master)和其他 Slave 的状态,确保它们都正确地进行了角色转换。
对于新的 Master:
docker exec -it redis-slave1 redis-cliINFO replication会发现它的角色变为 role:master。