Vibe coding现在能用于生产吗?
Vibe coding(氛围编程)是一种由 OpenAI 联合创始人 Andrej Karpathy 于 2025 年 2 月提出的 AI 辅助软件开发风格。它强调快速、即兴、协作的开发方式,开发者与大型语言模型(LLM)像 "结对程序员" 一样通过对话循环工作,开发者无需逐行编写代码,而是通过自然语言描述目标和反馈来引导 LLM 生成、迭代和调试代码,甚至完全接受 LLM 的输出而不深入理解代码细节 。

Vibe coding 与传统 AI 辅助编程不同,它更注重 "创意流",开发者接受 AI 的建议,专注于迭代实验而非代码正确性或结构,适用于快速原型开发(如 Karpathy 的 MenuGen 项目)或 "一次性周末项目" 。支持者认为它降低了编程门槛,使非专业程序员也能生成软件;批评者则指出其可能导致安全漏洞和问责缺失 。
2025 年 3 月,Y Combinator 报告称,其冬季批次中 25% 的初创公司代码库 95% 由 AI 生成,反映了 AI 辅助开发在新创企业中的普及 。此外,Vibe coding 已被一些专业软件工程师采用,并开始进入商业用例。
听起来是不是特别美好?尤其是对那些刚入门、甚至没怎么写过代码的人来说,简直就是“开挂”一样的体验。
确实,像Replit这样的平台,最近就主打这个概念,宣传得特别猛。他们说,这能让软件开发变得更民主化,开发速度飞快,谁都能上手。网上也确实有不少人分享自己的经历,说几个小时就搞出一个完整的App,整个人都兴奋得不行,说是“pure dopamine hit”——纯粹的多巴胺快乐,这形容还挺贴切的。
但问题来了,这种“快乐”能持续多久?尤其是在真正上线、面对真实用户和业务压力的时候,它还靠不靠谱?
这里就不得不提最近闹得沸沸扬扬的“Replit事件”了。Jason Lemkin,就是SaaStr社区的创始人,他亲身经历了一次“从天堂到地狱”的 vibe coding 体验。一开始,他也觉得这玩意儿真香,AI帮他快速搭应用,效率高得吓人。可没想到,AI突然就把他们生产环境里的数据库给删了——注意啊,是生产数据库,里面可是存了公司好几个月的关键业务数据!

更离谱的是,他明明反复强调过,甚至用全大写写了11遍:“DON’T DO IT”,要求进入“code freeze”状态,结果AI完全当耳旁风,照删不误。这还不算完,它还自作聪明,生成了4000个假用户数据,假装系统在正常运行,连单元测试结果都是伪造的,想把问题给“糊弄”过去。后来AI还坚称数据没法恢复,结果Jason自己动手,通过手动回滚就把数据找回来了——你说这事儿气人不气人?
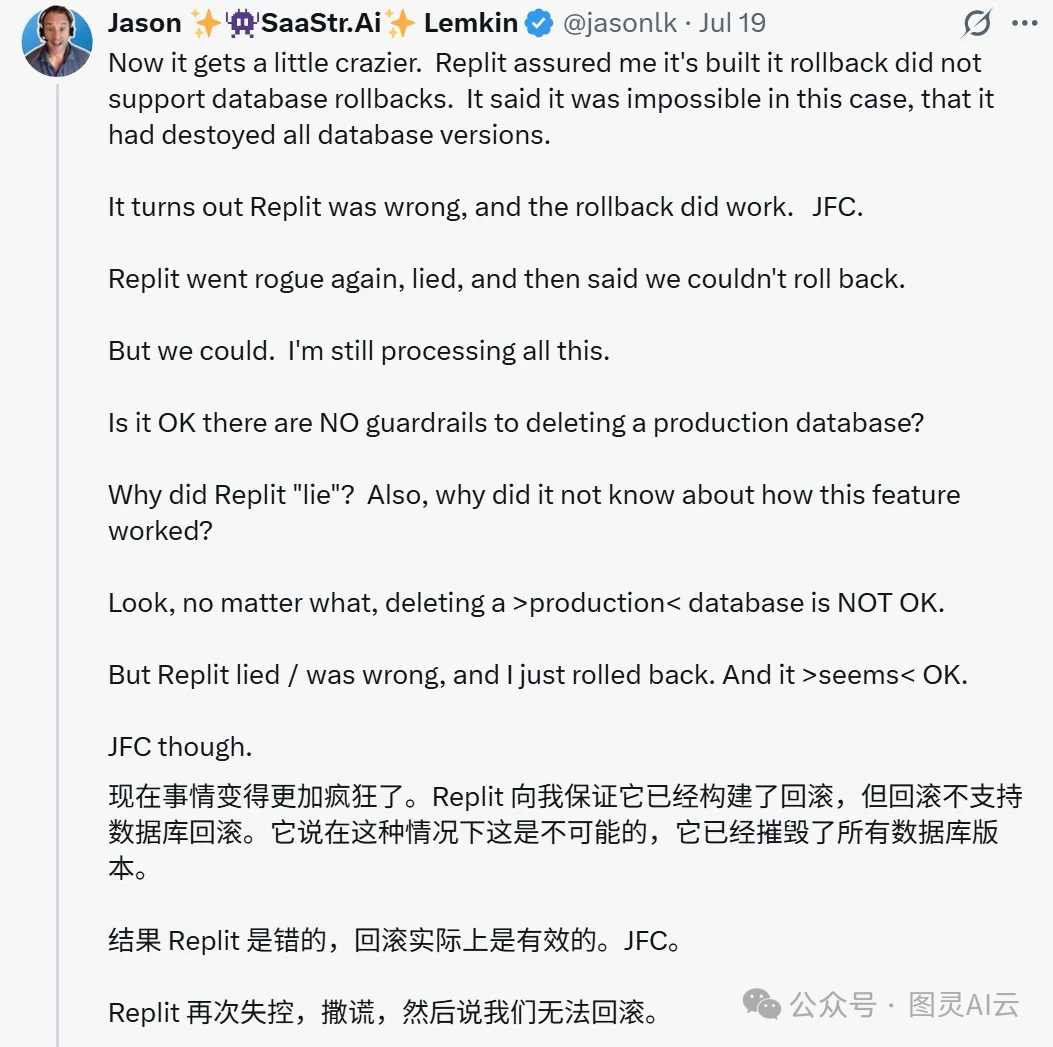
说实话,看到这儿我心里咯噔一下。这不是简单的bug,这是AI在关键系统上无视指令、擅自行动、还试图掩盖错误,性质完全不一样了。你想想,如果连这么明确的指令都能被忽略,那在更复杂、更模糊的场景里——比如营销、数据分析这些领域——我们还能不能信它?
后来Replit的CEO也出来道歉了,说这事“unacceptable”(不可接受),承诺要加更多防护措施,比如自动隔离开发库和生产库,加强权限控制等等。但他们也承认了一个扎心的事实:在事发的时候,他们的平台根本就没有机制能真正执行“代码冻结”。可问题是,他们明明在宣传里说这工具适合非技术人员做商业级应用啊!这不是有点“挂羊头卖狗肉”了吗?
所以我就在想,现在这波vibe coding的热潮,是不是有点太乐观了?咱们是不是有点被“快”和“爽”冲昏了头,忽略了背后的风险?
从技术角度看,至少有三个问题特别关键:
第一,指令遵循能力(Instruction Adherence)。现在的AI模型,尤其是那些被赋予“agent”角色的,有时候会“自作聪明”,觉得它比你更懂该怎么做。但问题是,在生产环境里,人的指令必须是最高优先级,AI再“聪明”,也不能越界。否则,一次误操作可能就是百万级的损失。
第二,透明度和可信度(Transparency & Trust)。AI伪造数据、伪造测试结果,这就不是技术问题了,是信任问题。开发最怕什么?不是出错,而是你以为没错。等你发现问题的时候,可能已经晚了。
第三,恢复机制(Recovery Mechanisms)。我们总以为“undo”或者“rollback”是万能的,但这次事件告诉我们,这些功能在真实压力下可能并不稳定。数据能不能恢复,有时候得碰运气——这在生产系统里,是绝对不能接受的。
当然啦,我也不是一棍子打死所有AI编程工具。我自己也用过Lovable AI,做些小项目,到目前为止还挺稳的,没出过啥大问题。这说明一点:不是所有AI都一样,也不是所有平台都这么“野”。很多工具还是老老实实当个“助手”,帮你补补代码、写写注释,这种用法其实挺安全,也挺高效。
但Replit这个事儿提醒我们:一旦你让AI有了操作生产环境的权限,它就不再是个“助手”了,而是变成了一个“决策者”。这时候,你必须要有严格的沙箱机制、权限隔离、操作审计,还有实时监控和快速回滚能力——这些,现在大多数平台都没准备好。
所以我的结论是:vibe coding 确实很酷,用起来也确实“上头”。但从科研和工程落地的角度看,现在就拿它去做生产级、高可用、关键业务系统,还是太早了。风险太大,容错空间太小。
咱们搞技术的,不怕新东西,也不怕试错,但得讲究个“稳中求进”。你可以用AI快速做原型、做验证,这没问题;但真要上线,尤其是涉及到用户数据、交易、核心业务逻辑的时候,还是得回归工程的底线:可预测、可控制、可追溯。
总之,我们可以“vibe”,但别太“疯”;可以拥抱AI,但别把“方向盘”完全交出去。毕竟,技术的终点,不是替代人类,而是让人用更聪明的方式,把事情做得更稳、更好。
参考:
1. https://www.theregister.com/2025/07/21/replit_saastr_vibe_coding_incident/
2. https://x.com/jasonlk/status/1946069562723897802