DDR-怎么计算存储空间-什么是预取(Pre-fetch)
问题一:怎么计算DDR SRAM存储空间
比如镁光这款:

Meg:Mega 兆 Gig:Gigab 吉
存储空间-计算公式:
- 128*4*8=4069
- 64*8*8=4096
- 32*16*8=4096
会发现,他们都是4Gbit(4096Mbit)的存储空间,就数据位宽不同,X4 X8 X16(传输带宽差异)
那“32Meg”,“x16”,“8Banks”代表什么?
以及DDR的工作原理是什么?
举个例子:
型号MT41K256M16: 32Meg *16 *8Bank
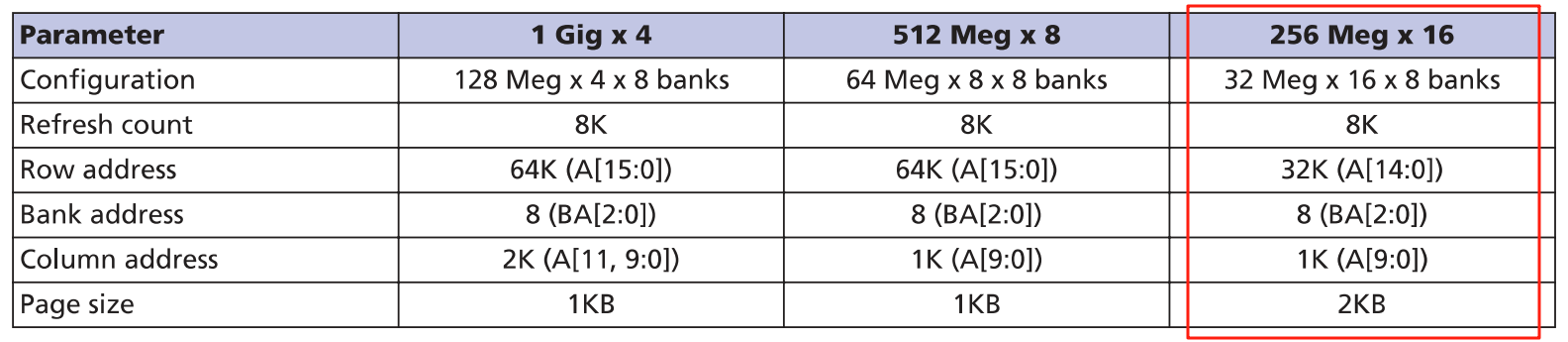
已知:地址线有A[14:0], 数据线D[15:0], BANK是BA[2:0]
页 / 行 / 列结构:
- 单个 bank 包含 32Meg 存储单元,按 “行(row)× 列(column)” 矩阵排列;
- 1 行 = 1 页,页大小(page size)= 2KB(即 1 行包含 2048 字节存储单元);
- 行地址范围:32K(A [14:0]),即每个 bank 有 32768 行;
- 列地址范围:1K(A [9:0]),即 1 行内有 1024 格(每“格”有16 bit=2 字节数据)。
突发长度(BL):支持固定 BL8(突发传输 8 个数据项)和 BC4(突发截断为 4 个,有4个被掩码了),可通过 A12 引脚动态切换(OTF)。
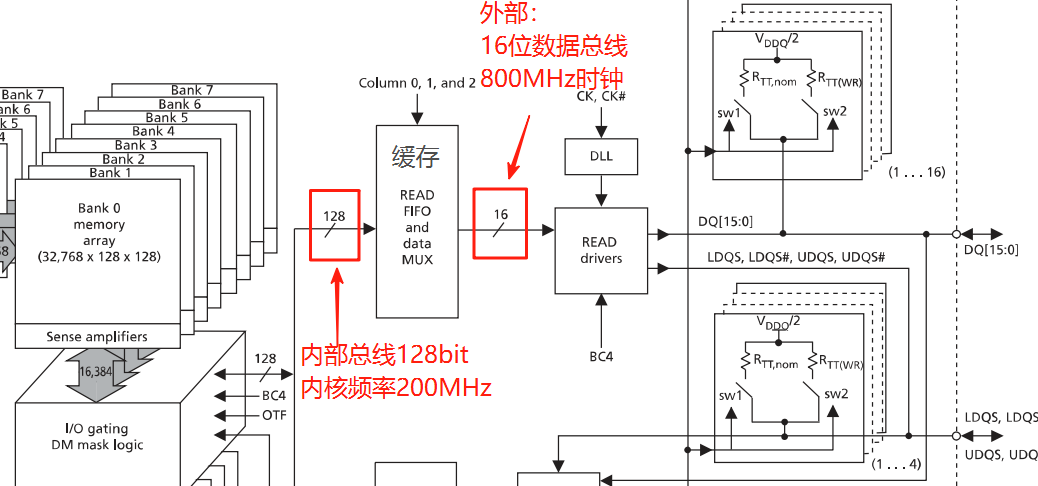
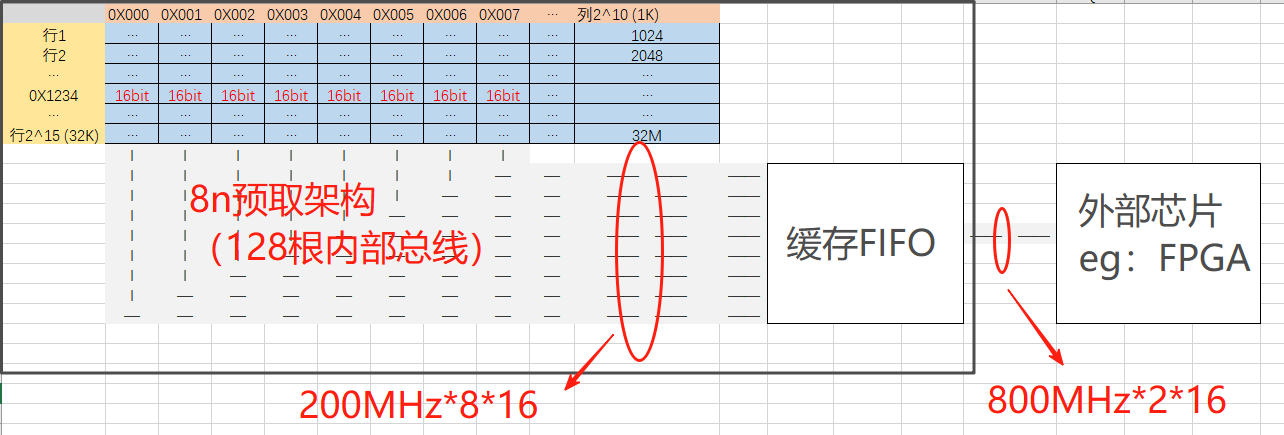
预取架构:8n-bit prefetch(8 位预取,“n” 为外部数据总线宽度),内核一次从存储阵列读取 8 位数据(同时进行),每列16bit同时输出,也就是128位内部总线!
时钟频率:以速度等级 “-125” 为例,对应 DDR3-1600,数据速率 1600 MT/s,外部时钟(CK)频率 = 800 MHz(因 DDR 技术每时钟周期传输 2 次数据)。
外部传输带宽:800MHz*2(DDR)*16bit(外部数据总线)=25600Mbit/s
内核频率:内核频率 =200 MHz,工艺上,内核频率很难提升,所以发明了8n-bit prefetch预取机制:
内部传输带宽:200MHz(单沿)*128bit(内部数据总线)=25600bit/s
内核与内部 FIFO 之间的数据传输通过 128bit 并行总线完成,
依赖硬件并行设计而非速率翻倍。
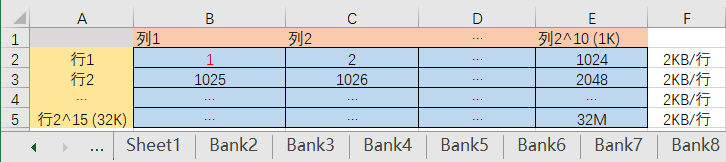
例子:读取 16 字节连续数据
假设 CPU 需要读取内存中 “bank 0、行地址 0x1234、列地址 0x000” 开始的 16 字节连续数据(该数据在同一页内),过程如下:
(地址线是时分复用,先行激活 + 再列访问)
1. 激活行(打开页)
- 内存控制器发送ACTIVATE 命令,通过 bank 地址(BA [2:0]=0)选中 bank 0,通过行地址 A [14:0]=0x1234 选中目标行(页)。
- 该操作将整行(2KB)数据从存储阵列载入行缓冲器(临时缓存),耗时满足
tRCD(行到列延迟,文档中 - 125 等级对应 13.75ns)。
2. 发送读取命令,指定突发长度和列地址
- 行激活后,控制器发送READ 命令,通过列地址 A [9:0]=0x000 指定起始列,并通过 A12=1 选择BL8(A12=0,则BC4)。
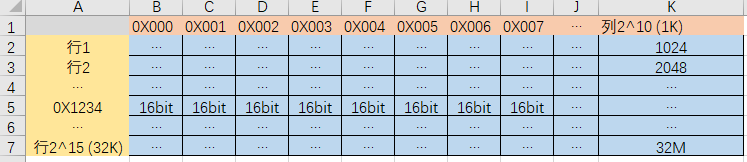
(BL8 本质是一次命令触发对 8 个连续列的访问,访问起始列地址后,内存会自动连续访问后续 7 个列,提升效率)
寻址就完成了,开始搬运16字节数据啦
已知外部数据位宽D[15:0],有16位。
8n-bit prefetch(8 位预取,“n” 为外部数据总线宽度)
3. 预取(Pre-fetch)与内核数据准备(预取操作由内核完成,不受外部时钟直接控制)
- Core内核(存储阵列)以200 MHz 频率工作,也就是一个周期5ns,收到读取请求后,启动8n-bit预取架构:
- 内核周期:200MHz 内核的 1 个周期为 5ns,在此期间,内核通过 “8n-bit 预取” 机制从存储阵列的 8 个连续列中并行读取 128bit 数据(8×16bit),即5ns搬运128bit。
4. 外部时钟同步传输
- 预取的 8 位数据通过内部逻辑拆分,配合外部800 MHz 时钟(CK) 传输:
- DDR 技术支持每时钟周期上升沿 + 下降沿各传输 1 次数据(即 1 时钟周期 = 2 次传输);
- 外部时钟与 FIFO 读取:外部时钟为 800MHz(1.25ns / 周期),通过 DDR 的双沿传输特性(每周期传输 2 次 16bit 数据),从 FIFO 中读取数据:
- 128bit 数据需要 8 次 16bit 传输(128÷16=8),对应 4 个外部周期(8÷2=4),总耗时 4×1.25ns=5ns。
- 这与内核写入 FIFO 的时间(5ns)完全同步,即 FIFO 在被外部接口读完数据的同时,内核已准备好下一批 128bit 数据(若有连续访问需求)。
5. 数据传输完成
- 16 字节数据通过 16 个数据引脚(x16 配置)连续传输到 CPU,整个过程中因数据在同一页内,无需重新激活行,仅需列地址 + 突发传输即可完成,大幅降低延迟。
总结
此例中,页(行)是数据激活的基本单位(2KB),列地址定位页内起始位置,BL8 确保连续 8 个数据项高效传输,8 位预取实现内核与外部接口的速率匹配,800 MHz 外部时钟与200 MHz 内核频率通过预取机制协同,最终实现 16 字节数据在约 5ns 内完成传输(不含激活延迟),体现了 DDR3 的高速传输特性。
所以你明白什么是突发长度,什么是预取了吗?
BL=8: 加快了寻址(只需要访问一次起始列地址,自动给后面7列,节省时间)
8n预取架构:加快了数据运输(内核)
知识补充:
一)200MHz 内核预取8列,每列 16bit 列数据的详细过程
1. 存储阵列的硬件结构支持
内存的存储阵列(行列矩阵)中,同一行(页)的列地址是连续排列的(如列 0x000、0x001、…、0x3FF),且硬件上支持连续列的并行 / 快速访问。当内核收到读取命令(包含起始列地址)后,会通过内部地址解码器定位到起始列,并自动激活后续连续列的访问逻辑。
2. 内核在 1 个周期内完成 8 个 16bit 列的预取
200MHz 内核的 1 个周期(5ns)内,会执行以下操作:
- 地址递增:以内核时钟为基准,从起始列地址(如 0x000)开始,地址逻辑自动生成后续 7 个连续列地址(0x001~0x007),无需额外命令;
- 并行读取:存储阵列的硬件电路同时(或在极短时间内连续)读取这 8 个列的 16bit 数据(每个列 16bit,8 列共 128bit);
- 数据汇聚:读取的 8×16bit 数据通过内部总线汇聚成 128bit 的 “预取块”,存入内核的预取缓冲区(Prefetch Buffer)。
3. 预取与内核时钟的匹配
- 内核以 200MHz 工作,意味着每 5ns 就能完成一次 128bit 的预取(包含 8 个 16bit 列数据);
- 这个速度与外部接口的传输需求完全匹配:外部时钟 800MHz(1.25ns / 周期),通过 DDR 双沿传输(每周期传输 2 次 16bit),4 个外部周期(5ns)刚好传输完 128bit(8×16bit),与内核预取的时间完全同步。
核心逻辑:为什么 200MHz 能高效预取 16bit 列数据?
- 硬件并行性:存储阵列的物理结构允许连续列的并行访问,避免了单个列逐一读取的延迟;
- 预取块设计:8n-bit 预取机制将 8 个 16bit 列数据打包为一个 128bit 的 “预取块”,刚好匹配内核 1 个周期的处理能力;
- 时钟协同:200MHz 内核周期(5ns)与外部 800MHz 时钟的 4 个周期(5ns)时间对齐,确保预取的数据能被外部接口无延迟地传输出去。
其他DDR的内核频率-预取-外部时钟频率的关系:
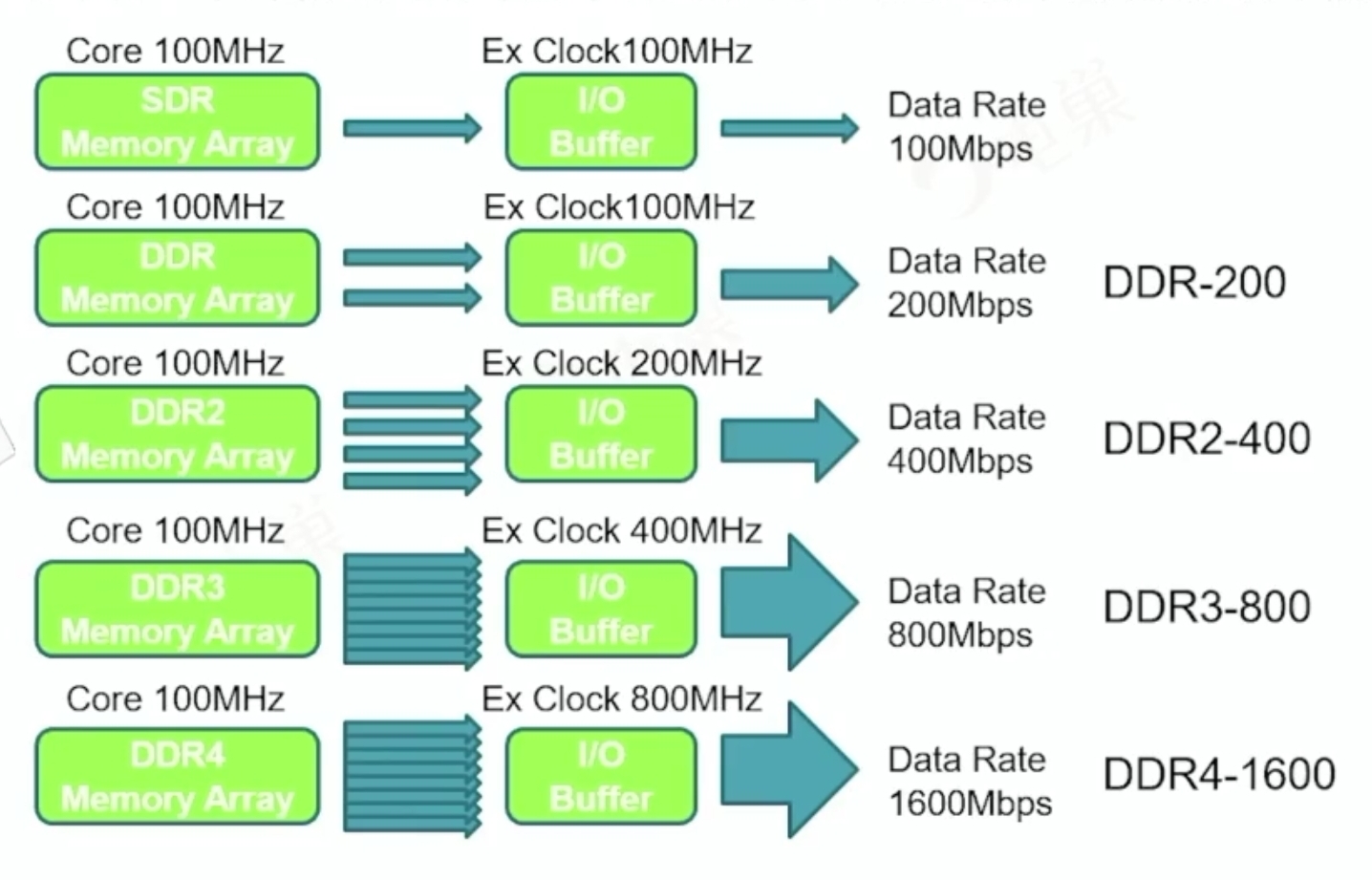
DDR4多了个Bank group功能(2个8bit预取),DDR5是16n-bit预取~
二)什么是ODT技术:
ODT(On-Die Termination)即片上端接技术,是从 DDR2 SDRAM 时代开始新增的功能。以下是关于 ODT 技术的详细介绍:
- 工作原理:ODT 技术将终结电阻集成到内存芯片内部。在内存芯片工作时,系统会把终结电阻器屏蔽,而对于暂时不工作的内存芯片则打开终结电阻器以减少信号的反射。内存控制器可以通过 ODT 同时管理所有内存引脚的信号终结,并且阻抗值有多种选择,如 0Ω、50Ω、75Ω、150Ω 等,可根据系统内干扰信号的强度自动调整阻值大小。
- 作用:在 DDR 通道中,通常会挂接多个 Rank,数据线、地址线等共用,数据信号传递到线路末端时会产生波形反射,影响原始信号。ODT 的目的是让 DQS、RDQS、DQ 和 DM 等信号在终结电阻处消耗完,防止这些信号在电路上形成反射,进而增强信号完整性。
- 优势:一是降低主板制造成本,去掉了主板上的终结电阻器等电器元件,使主板设计更简洁;二是减少内存闲置时的功率消耗,它可以迅速开启和关闭空闲的内存芯片;三是减少内存的延迟等待时间,芯片内部终结比主板终结更及时有效,也使得进一步提高内存的工作频率成为可能。
- 校准:工艺、电压和温度(PVT)的变化会导致 ODT 元件的电阻特性不稳定,ODT 校准可确定最佳端接阻抗,以减少信号反射并补偿 PVT 的变化。校准通过建立与外部精密电阻成正比的 ODT 阻抗来实现,ODT 校准控制器将 ODT 电阻网络上的压降与所表示的外部电阻器上的压降进行比较,通过粗调和微调对电阻网络进行修改,以实现与外部基准电阻非常接近的阻抗值。
那终端电阻还加不加?
DDR2/DDR3的地址总线需要加终端匹配电阻上拉到VTT~
DDR2/DDR3 时代:
地址线(Address)和控制线(Command)通常需要在主板上外接终端电阻到 VTT。
- 原因是此时 ODT 技术仅用于数据线(DQ、DQS 等),地址 / 控制信号的端接依赖主板上的外部电阻,通过匹配传输线阻抗(通常 50Ω)来减少反射。
- VTT 是专门为终端电阻设计的参考电压(通常为电源电压的一半,如 DDR3 的 VTT=0.75V),确保端接效果稳定。
DDR4 及以后:
地址线的外部终端电阻需求大幅减少,甚至被 ODT 取代:
- DDR4 中,地址 / 控制总线(CA)开始支持片上 ODT(通过模式寄存器配置),可通过内存芯片内部的端接电路实现阻抗匹配,无需外接电阻到 VTT。
- DDR5 进一步优化,地址 / 控制信号(CA、CK 等)的 ODT 功能更完善,完全依赖内部端接,主板上无需额外的 VTT 终端电阻。
喜欢 谢工碎碎念 的内容,给个关注,收藏~