[LLM 应用评估] 提示词四大要素 | 评估样本_单次交互快照 | 数据集 | Hugging Face集成
改进AI应用不是艺术,而是科学
第二章:提示词工程
欢迎回来
在第一章:大语言模型与向量嵌入中,我们了解了 Ragas 的"大脑"(大语言模型,LLMs)和"翻译器"(向量嵌入)。本章将探讨如何通过**提示词(Prompts)**精确控制这些智能组件,如同为超级机器人编写操作手册。
什么是提示词?
提示词是向 LLM 发送的"指令手册",明确告知其任务目标、输入格式与输出规范。在 Ragas 中,LLM 充当"AI裁判"的角色,用于评估聊天机器人等AI系统的响应质量。例如判断"该回答是否准确?“或"是否与原始文档一致?”
提示词确保 LLM 以标准化方式执行评估任务,使 Ragas 能系统化处理评估结果。
Ragas 提示词的四大要素
相关前文:[Meetily后端框架] AI摘要结构化 | SummaryResponse模型 | Pydantic库 | vs marshmallow库
Ragas 采用 PydanticPrompt 类构建提示词("Pydantic"源于Python数据验证库),其结构如同精密配方:
-
指令(Instruction)
核心任务描述,如同主厨命令:“烘焙蛋糕!”instruction = "回答给定问题" -
小样本示例(Few-Shot Examples)
输入输出范例,如同展示成品照片:“请参照此样式制作”examples = [(MyInput(question="谁在构建LLM应用评估的开源标准?"), MyOutput(answer="Ragas")) ] -
输入模型(Input Model)
定义LLM接收的数据结构,如同食材清单:“需要面粉、糖和鸡蛋”class MyInput(BaseModel):question: str = Field(description="待解答的问题") -
输出模型(Output Model)
规定响应格式,如同蛋糕造型规范:“需为圆形并搭配巧克力霜”class MyOutput(BaseModel):answer: str = Field(description="问题答案")
Pydantic 模型确保数据格式的严格性,使 Ragas 与 LLM 间的通信准确无误。
创建与使用提示词实例
以下示例演示如何构建问答提示词:
步骤1:定义输入输出模型
from pydantic import BaseModel, Field# 输入模型:接收问题字符串
class 问题输入(BaseModel):问题描述: str = Field(description="用户提出的问题")# 输出模型:返回答案字符串
class 问题输出(BaseModel):答案内容: str = Field(description="生成的解答")
步骤2:构建提示词类
from ragas.prompt import PydanticPromptclass 问答提示词(PydanticPrompt[问题输入, 问题输出]):# 核心指令instruction = "请准确回答下列问题"# 绑定数据模型input_model = 问题输入output_model = 问题输出# 添加示例examples = [(问题输入(问题描述="Ragas框架的主要功能是什么?"),问题输出(答案内容="评估基于RAG的AI系统性能"))]
步骤3:调用提示词生成响应
# 初始化LLM(参照第一章配置)
评估用LLM = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o"))# 实例化提示词
问答实例 = 问答提示词()# 准备输入数据
当前问题 = 问题输入(问题描述="法国的首都是哪里?")# 生成响应
响应结果 = await 问答实例.generate(llm=评估用LLM, data=当前问题
)print(响应结果.答案内容) # 输出:巴黎
此流程将指令、示例与输入数据整合,通过LLM生成结构化响应,便于Ragas后续处理。
底层机制
⭕RAG(检索增强生成)
结合了信息检索和文本生成,先搜索外部知识库获取相关信息,再基于这些信息生成更准确的回答。
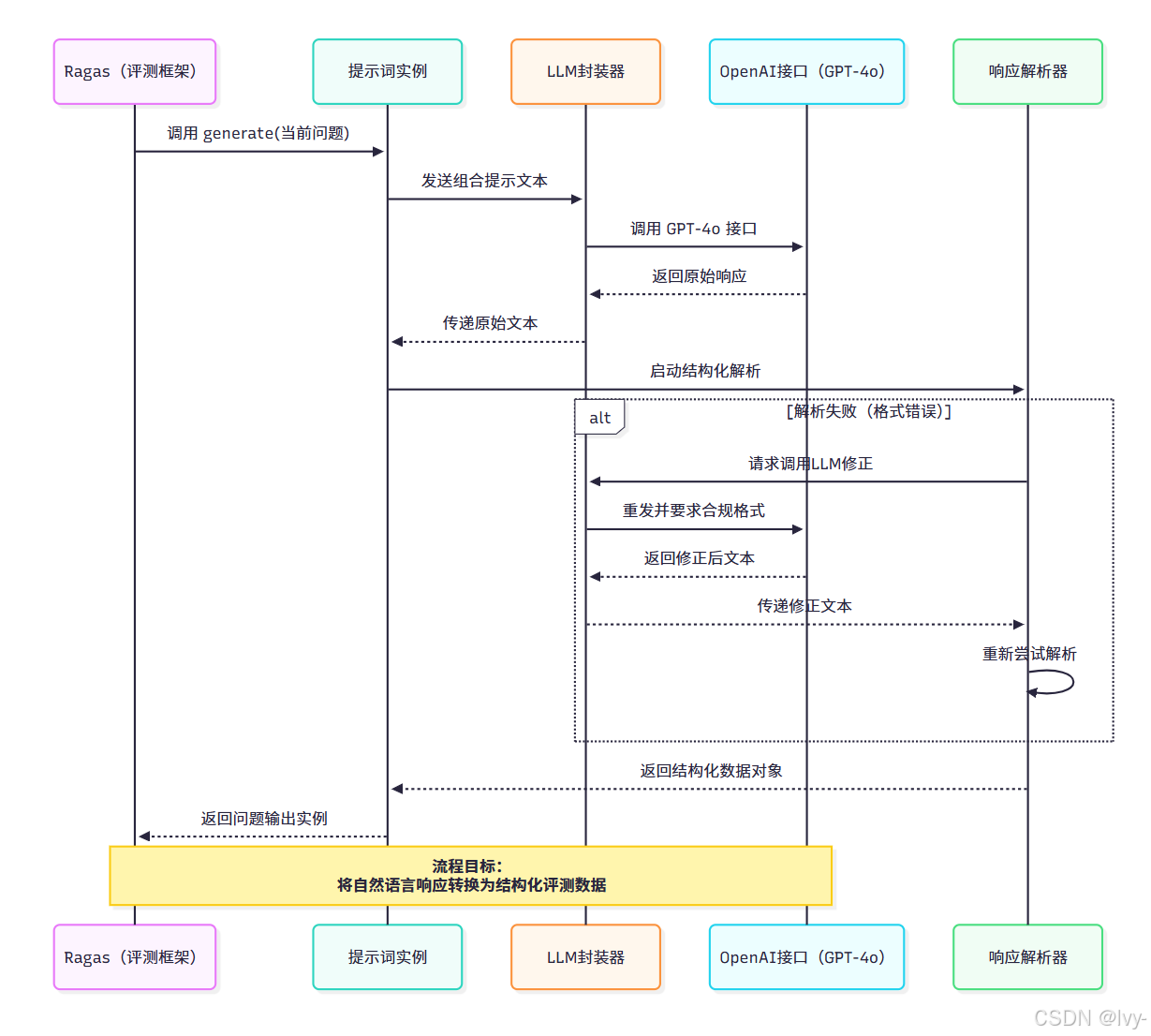
当调用 generate() 方法时,Ragas 执行以下关键步骤:
-
提示词构建
将指令、示例、输入数据组合为完整提示文本:指令:请准确回答下列问题 输出格式要求:{"答案内容": "..."}示例: 输入:{"问题描述": "Ragas框架...?"} 输出:{"答案内容": "评估基于RAG..."}输入:{"问题描述": "法国的首都是哪里?"} -
LLM通信
通过LangchainLLMWrapper将提示文本发送至LLM服务商(如OpenAI)。 -
响应解析
使用RagasOutputParser验证响应格式,必要时自动纠错:class RagasOutputParser:async def 解析响应(原始文本):try:return 问题输出.parse_raw(原始文本)except 格式错误:修正提示 = f"请修正JSON格式:{原始文本}"修正响应 = await LLM.generate(修正提示)return 问题输出.parse_raw(修正响应) -
结构化返回
最终输出符合问题输出模型的Pydantic对象,如:问题输出(答案内容="巴黎")
代码架构
Ragas 提示词系统基于抽象类 BasePrompt 实现(定义于 ragas/src/ragas/prompt/base.py):
# 简化自Ragas源码
from abc import ABC, abstractmethodclass 基础提示词(ABC):@abstractmethodasync def generate(self, llm: 任意类型, data: 任意类型) -> 任意类型:"""生成单个响应"""@abstractmethoddef 批量生成(self, llm: 任意类型, data: 任意类型, 数量: int=1) -> 列表:"""批量生成响应"""
具体到 PydanticPrompt 类(ragas/src/ragas/prompt/pydantic_prompt.py):
class Pydantic提示词(基础提示词):def 构建提示文本(self, 输入数据) -> str:完整提示 = f"{self.instruction}\n"完整提示 += "输出需符合JSON格式:\n"完整提示 += json.dumps(输出模型.schema(), indent=4)完整提示 += "\n示例:\n"for 输入示例, 输出示例 in self.examples:完整提示 += f"输入:{输入示例.json()}\n输出:{输出示例.json()}\n"完整提示 += f"当前输入:{输入数据.json()}\n输出:"return 完整提示
此设计确保不同提示词类型(如Pydantic或字符串提示)在Ragas中具有统一接口。
小结
- 提示词四要素:
指令、示例、输入输出模型构成标准化任务定义 - 结构化通信:
Pydantic模型保障数据格式,降低通信误差 - 自动纠错机制:响应解析器在格式错误时
触发LLM自修正 - 可扩展架构:通过继承
基础提示词实现自定义提示类型
掌握提示词设计后,我们需为评估准备"案例素材"。下一章将详解评估样本与数据集,探讨如何构建高质量测试集
第三章:评估样本与数据集
在第一章我们了解了Ragas的"大脑"与"翻译器",第二章探讨了如何为AI裁判编写指令手册。
本章我们将准备评估所需的"案例卷宗"——评估样本(Evaluation Samples)与数据集(Datasets)。
评估样本与数据集解析
这些是AI应用(如聊天机器人或问答系统)的真实交互记录,Ragas通过分析这些记录量化系统表现。
类比医院病历系统:
- 评估样本:单次诊疗记录,包含患者问题、医生诊断、检查报告及理想治疗方案
- 评估数据集:全院患者数据库,汇集所有个体诊疗记录
Ragas通过分析这些"医疗档案"评估AI系统的"健康状态",如同医院通过病案分析医疗质量。
核心价值
构建AI应用时,不能仅凭猜测判断其表现。评估数据集提供真实测试案例,Ragas通过量化分析给出客观评分,如同通过临床试验验证药物疗效。
评估样本:单次交互快照
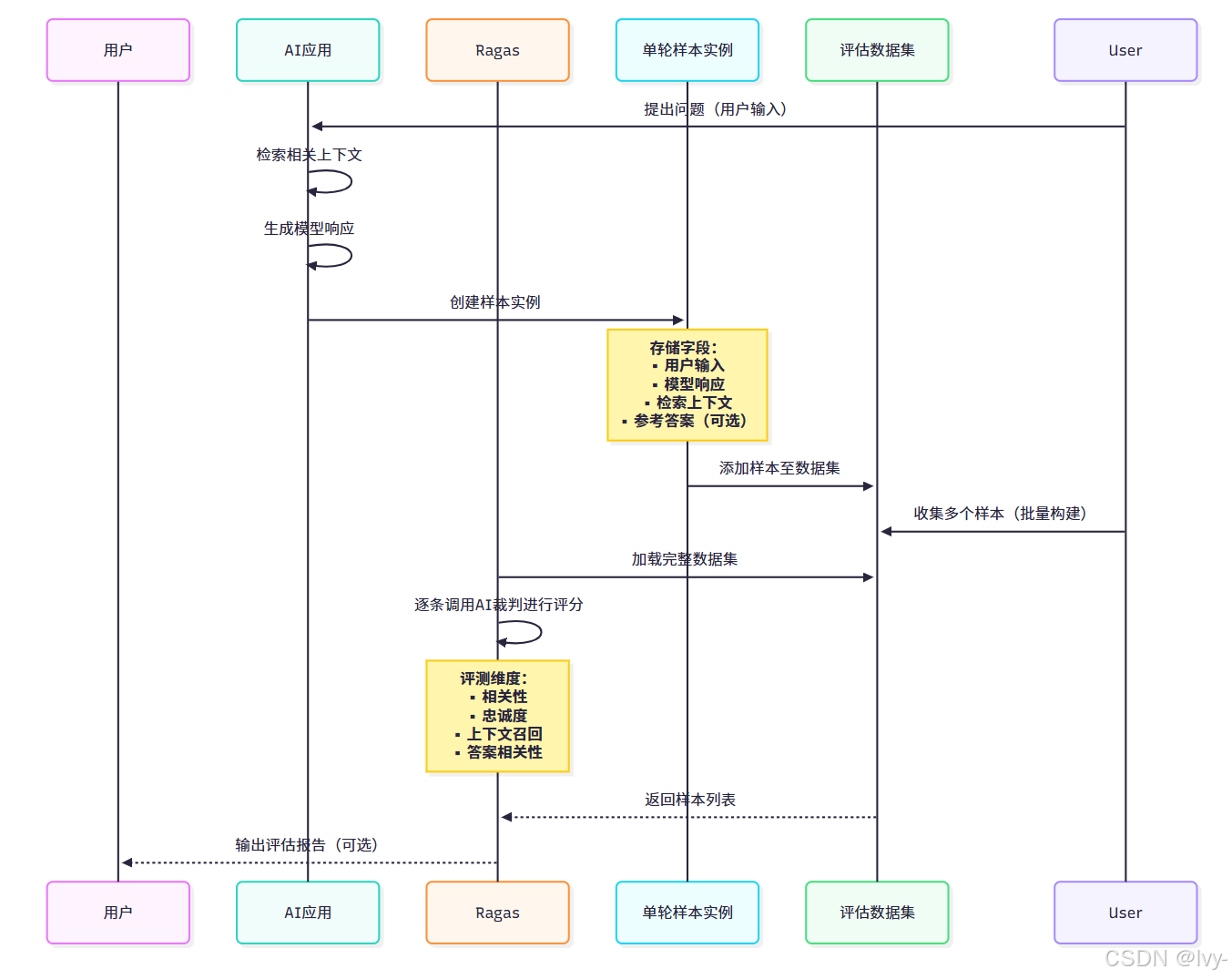
Ragas中评估样本是单次交互的结构化快照。针对RAG系统,最常用的是单轮样本(SingleTurnSample),包含:
- 用户输入(user_input):用户提出的问题
- 系统响应(response):AI生成的答案
- 检索上下文(retrieved_contexts):AI检索的参考信息(文档/段落)
- 参考答案(reference):人工标注的理想答案(可选)
- 评估标准(rubrics):预定义的质量检查标准(可选)
创建单轮样本
from ragas import SingleTurnSample# 用户提问
用户问题 = "德国的首都是哪里?"# 检索上下文(RAG系统获取的参考资料)
检索资料 = ["柏林是德国的首都和最大城市。","德国是位于中欧的国家。"
]# AI生成的回答
系统响应 = "德国的首都是柏林。"# 参考答案(人工标注)
参考答案 = "柏林"# 创建评估样本
样本实例 = SingleTurnSample(user_input=用户问题,retrieved_contexts=检索资料,response=系统响应,reference=参考答案,
)print(样本实例)
该代码创建包含完整交互信息的样本对象,Ragas可据此评估响应准确性、引用相关性等指标。
对于多轮对话场景,Ragas支持MultiTurnSample类型。本教程主要聚焦单轮样本以简化理解。
评估数据集:样本集合
评估数据集是多个样本的集合,用于全面评估AI表现。通过EvaluationDataset类管理:
from ragas import SingleTurnSample, EvaluationDataset# 样本1:德国首都
样本1 = SingleTurnSample(user_input="德国的首都是哪里?",retrieved_contexts=["柏林是德国的首都和最大城市。"],response="德国的首都是柏林。",reference="柏林"
)# 样本2:文学作品作者
样本2 = SingleTurnSample(user_input="《傲慢与偏见》的作者是谁?",retrieved_contexts=["《傲慢与偏见》是简·奥斯汀的小说。"],response="《傲慢与偏见》由简·奥斯汀创作。",reference="简·奥斯汀"
)# 样本3:化学公式
样本3 = SingleTurnSample(user_input="水的化学式是什么?",retrieved_contexts=["水的化学式为H₂O。"],response="水的化学式是H₂O。",reference="H₂O"
)# 构建数据集
数据集实例 = EvaluationDataset(samples=[样本1, 样本2, 样本3])print(f"数据集包含样本数:{len(数据集实例)}") # 输出:3
加载现有数据集(Hugging Face集成)
Ragas支持从Hugging Face平台加载现成数据集:
from datasets import load_dataset
from ragas import EvaluationDataset# 加载Hugging Face通用知识问答数据集
原始数据集 = load_dataset("explodinggradients/amnesty_qa", "english_v3")# 转换为Ragas数据集
转换后数据集 = EvaluationDataset.from_hf_dataset(原始数据集["eval"])print(f"成功加载样本数:{len(转换后数据集)}")
from_hf_dataset方法实现无缝格式转换,便于利用现有数据资源。
底层架构
Ragas通过BaseSample基类和RagasDataset数据集类实现结构化数据管理:
样本基类(dataset_schema.py)
from pydantic import BaseModelclass 样本基类(BaseModel):"""所有评估样本的基类"""def 转字典(self):return self.model_dump(exclude_none=True)class 单轮样本(样本基类):user_input: str | None = Noneretrieved_contexts: list[str] | None = Noneresponse: str | None = Nonereference: str | None = Nonerubrics: dict[str, str] | None = None
数据集管理(dataset_schema.py)
from dataclasses import dataclass@dataclass
class RagasDataset:samples: list[样本基类] # 样本集合def __post_init__(self):self.samples = self.验证样本类型(self.samples)def 验证样本类型(self, 样本列表):"""确保数据集样本类型一致"""首样本类型 = type(样本列表[0])for 索引, 样本 in enumerate(样本列表):if not isinstance(样本, 首样本类型):raise ValueError(f"第{索引}个样本类型{type(样本)}与首样本类型{首样本类型}不符")return 样本列表@dataclass
class 评估数据集(RagasDataset):"""单轮或多轮样本的集合"""pass
数据处理流程
小结
- 评估样本:单次交互的完整记录,包含问题、响应、上下文与参考答案
- 评估数据集:样本集合,构成系统化测试案例库
- 数据兼容性:支持从Hugging Face等平台导入现有数据集
- 强类型校验:通过Pydantic模型保障数据结构一致性
准备好"案例卷宗"后,我们将进入**第四章:评估指标**,揭秘Ragas如何量化AI系统的表现质量。