Nature论文-预测和捕捉人类认知的基础模型-用大模型模拟人类认知

原文地址
摘要
建立一个统一的认知理论一直是心理学的一个重要目标。建立这种理论的第一步是建立一个计算模型,可以预测人类在各种环境中的行为。在这里,我们介绍了Centaur,一个计算模型,可以预测和模拟人类的行为在任何实验表达的自然语言。我们通过在名为Psych-101的大规模数据集上微调最先进的语言模型来获得Centaur。Psych-101具有前所未有的规模,涵盖了超过60,000名参与者在160个实验中进行超过10,000,000次选择的试验数据。Centaur不仅比现有的认知模型更好地捕捉了被拒参与者的行为,而且还概括了以前看不见的封面故事、结构性任务修改和全新的领域。此外,模型的内部表示在微调后变得与人类神经活动更加一致。综上所述,我们的研究结果表明,有可能发现在广泛的领域捕捉人类行为的计算模型。我们相信,这样的模型提供了巨大的潜力,指导认知理论的发展,我们提出了一个案例研究来证明这一点。
文章目录
- 摘要
- 模型概述
- Centaur捕捉人类行为
- 探索泛化能力
- 与人类神经活动的一致性
- 模型引导的科学发现
- 讨论
- 结论
- 方法
- 数据收集
- 微调程序
- 评估指标
- 领域特定认知模型
- 神经对齐
- 模型引导的科学发现
人类的思维是非常普遍的。我们不仅会例行地做出平凡的决定,比如选择早餐麦片或选择一套衣服,而且还会应对复杂的挑战,比如找出如何治愈癌症或探索外太空。我们只从几次演示中学习技能,因果推理,好奇心为我们的行动提供动力。无论我们是爬山,玩电子游戏,还是创造迷人的艺术,我们的多才多艺都定义了人类的意义。
相比之下,大多数当代计算模型,无论是机器学习还是认知科学,都是特定领域的。他们被设计成擅长一个特定的问题,而且只擅长那个问题。以AlphaGo为例,它是由Google DeepMind创建的计算机系统,用于掌握Go游戏。系统可以在令人印象深刻的水平上玩这个特定的游戏,但它不能做更多的事情。在认知科学中也可以观察到类似的模式。例如,前景理论是对人类认知最有影响力的解释之一,它为人们如何做出选择提供了有价值的见解,但它没有告诉我们如何学习、计划或探索。
如果我们想全面了解人类的思想,我们必须从特定领域的理论转向综合理论。这种统一方法的重要性已经被我们领域的先驱所认识。例如,在1990年,有人说,“统一的认知理论是唯一的途径,使[我们的]美妙的,不断增长的知识基金在智力控制之下“2。我们如何才能在这些理论上取得有意义的进展?
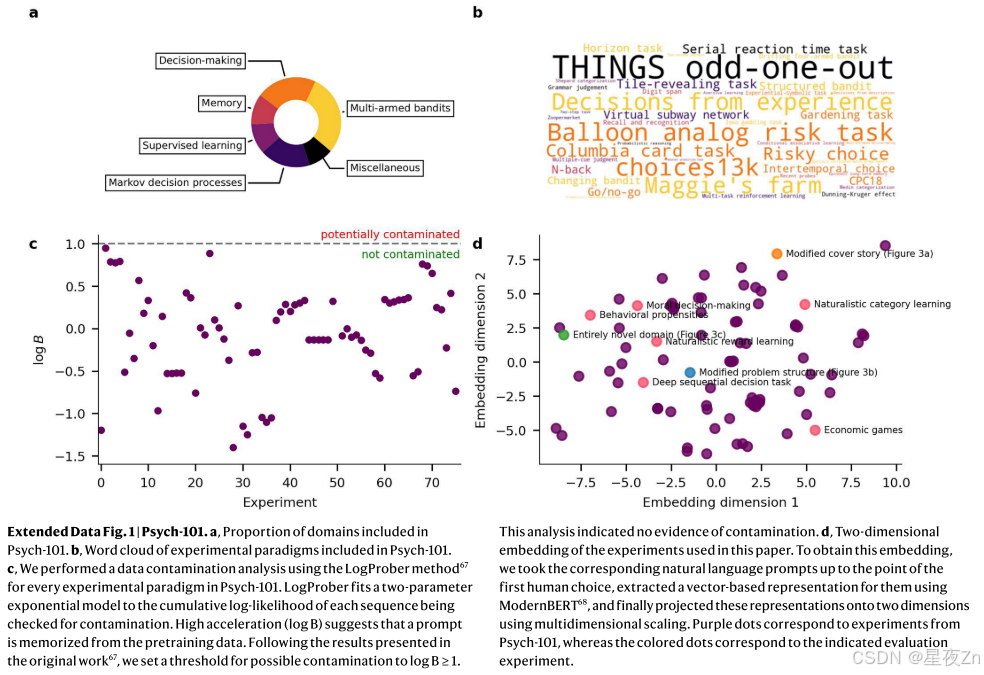
走向统一的认知理论的重要一步是建立一个计算模型,可以预测和模拟人类行为在任何领域。在本文中,我们接受了这一挑战,并介绍了半人马座-人类认知的基础模型。Centaur是以数据驱动的方式设计的,通过在大型人类行为语料库上微调最先进的大型语言模型11。为此,我们策划了一个名为Psych-101的大规模数据集,其中包括来自160个心理学实验的逐个试验数据(见方法,“数据收集”和扩展数据图1)。我们将这些实验转录成自然语言,这为表达截然不同的实验范式提供了一种通用格式12,13。由此产生的数据集具有前所未有的规模,包含超过10,000,000个人类选择,包括来自多臂强盗,决策,记忆,监督学习,马尔可夫决策过程等领域的许多规范研究(参见图1a的概述和示例)。
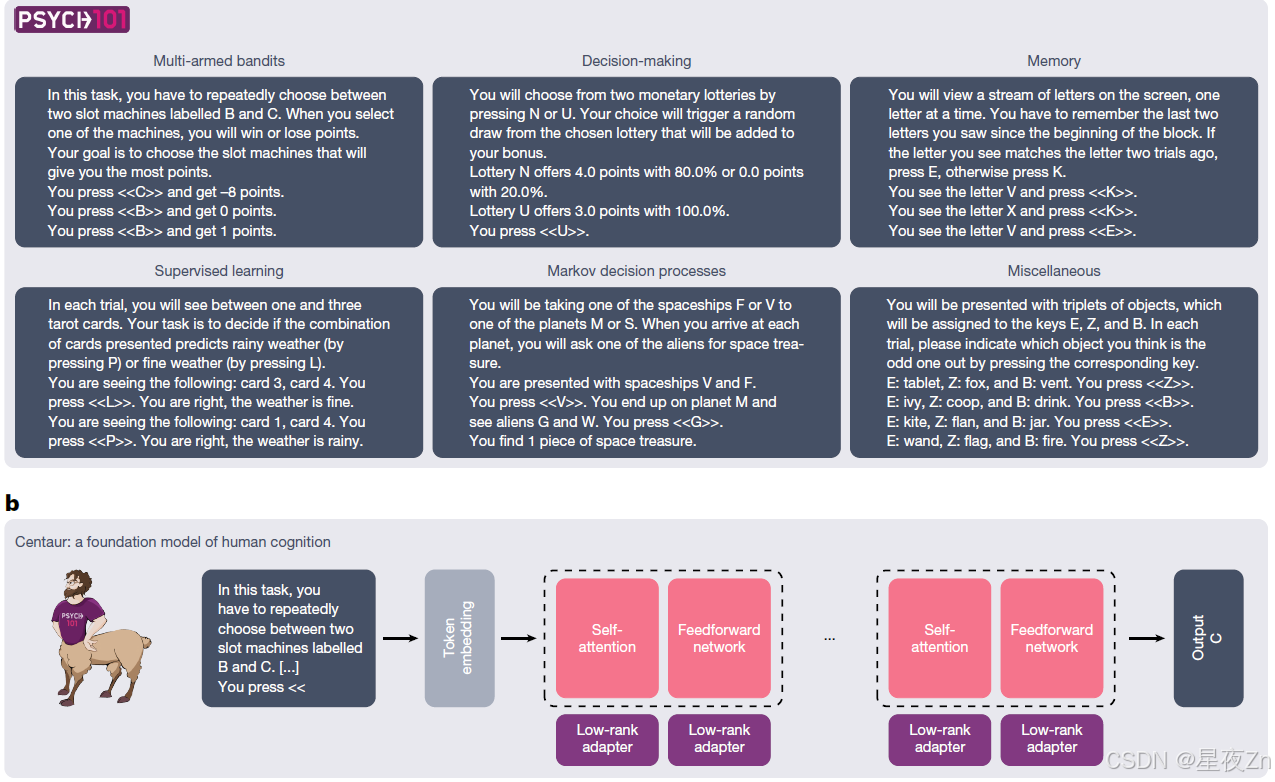
图1| Psych-101和半人马座的概述。a,Psych-101包括来自160个心理学实验的逐个试验的数据,其中60,092名参与者总共做出10,681,650个选择,涉及253,597,411个文本标记。它包含了多武装强盗、决策、记忆、监督学习、马尔可夫决策过程和其他领域(所示示例已被程式化和简化,以便于阅读)。B,半人马是人类认知模型的基础,它是通过向最先进的语言模型添加低级适配器并在Psych-101上对其进行微调而获得的。
我们对Centaur进行了一系列严格的测试,并证明它在几个层面上捕捉到了人类的行为。首先,我们表明,在几乎每一个实验中,Centaur都能比现有的认知模型更好地预测被拒参与者(那些不属于训练数据的参与者)的行为。然后,我们证明了它捕捉人类行为的能力也推广到了实验。在这种情况下,我们发现,半人马座准确地预测人类的行为下修改封面故事,问题结构,甚至在全新的领域。最后,我们表明,半人马座的内部表示变得更加人性化,即使它从来没有明确训练,以捕捉人类的神经活动。
综上所述,我们的研究结果表明,有可能发现在广泛的领域捕捉人类行为的计算模型。我们认为,这样的预测模型提供了许多直接的机会,以获得更好地了解人类的思想14,15,我们提出了一个案例研究,证明了这种潜力。
模型概述
我们在开源语言模型Llama 3.1 70 B的基础上构建了Centaur,Llama 3.1 70 B是由Meta AI预训练的最先进的模型(下文中,我们将此模型简称为Llama)11。有一个大型的语言模型作为主干,使我们能够依赖于这些模型中存在的大量知识。训练过程涉及使用称为量化低秩自适应(QLoRA)的参数高效微调技术对Psych-101进行微调。QLoRA依赖于冻结的四位量化语言模型作为基础模型。虽然基本模型的参数保持不变,但它添加了低秩适配器,这些适配器仅包含一些额外的可训练参数(通常以半精度浮点格式表示)。在我们的例子中,我们将秩r = 8的低秩适配器添加到所有非嵌入层(即自注意机制和前馈网络的所有线性层),如图1b所示。通过这些设置,新添加的参数相当于基本模型参数的0.15%。然后,我们使用标准的交叉熵损失在整个数据集上训练模型一个时期。我们掩盖了所有与人类反应不对应的令牌的损失,从而确保模型专注于捕捉人类行为,而不是完成实验指令。.整个训练过程在A100 80 GB GPU上进行了大约五天(方法,“微调过程”)。
Centaur捕捉人类行为
我们在不同类型的数据上评估了Centaur,以证明它能够有力地捕捉人类行为。在我们的第一次分析中,我们测试了它是否可以预测不属于训练数据的参与者的行为。为此,我们将每个转录实验分为两部分,并使用90%的参与者进行培训,并保留10%用于测试。我们使用响应平均的负对数似然来测量人类选择的拟合优度(方法,“评估指标”)。图2a显示了分析结果,将Centaur与未微调的基础模型以及代表认知科学文献中最先进技术的特定领域模型进行了比较(扩展数据表1)。虽然在不同的实验中,预测性有很大的差异(半人马座,0.49;美洲驼,0.47),微调总是提高拟合优度。微调后,实验间对数似然的平均差异为0.14(Centaur负对数似然,0.44; Llama负对数似然,0.58;单侧t检验:t(1,985,732)= −144.22,P ≤ 0.0001; Cohen’s d,0.20)。
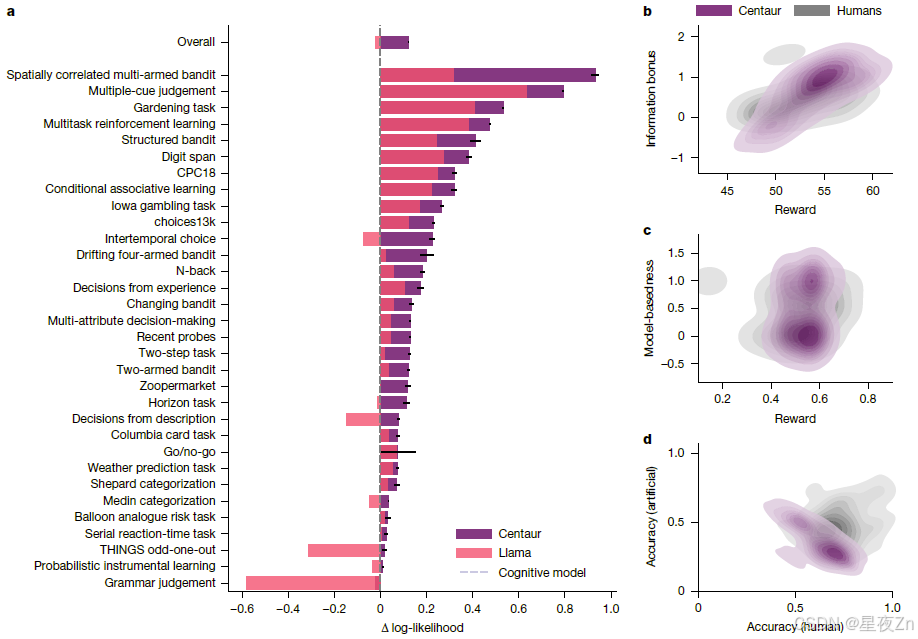
图2|心理学101的拟合优度a,半人马和美洲驼相对于每个实验的领域特定认知模型的对数似然性差异。零值对应于特定领域认知模型的拟合优度,大于零的值表示对人类响应的拟合优度提高。对数似然性是对响应的平均值(n = 992,867)。误差线对应于平均值的标准误差。几乎在所有实验中,半人马的表现都优于羊驼和一组领域特异性认知模型(单侧t检验:t(1,985,732)= −144.22,P ≤ 0.0001; t(1,985,732)= −127.58,P ≤ 0.0001)。我们只纳入了在本图中实施了特定领域认知模型的实验,并使用相同的范式合并了不同的研究。扩展数据表1包含所有实验的数值结果。B.对水平任务进行建模模拟。该图显示了奖励的概率密度以及人和模拟半人马座运行的信息奖励参数。c.对两步任务进行模型模拟。该图显示了奖励的概率密度,以及一个参数,该参数指示了基于模型的学习对于人和模拟的半人马座运行的效果。d.对社会预测游戏进行建模模拟。该图显示了预测人类策略和人工智能策略的准确性的概率密度,以及人类和模拟运行的半人马座的匹配统计数据。
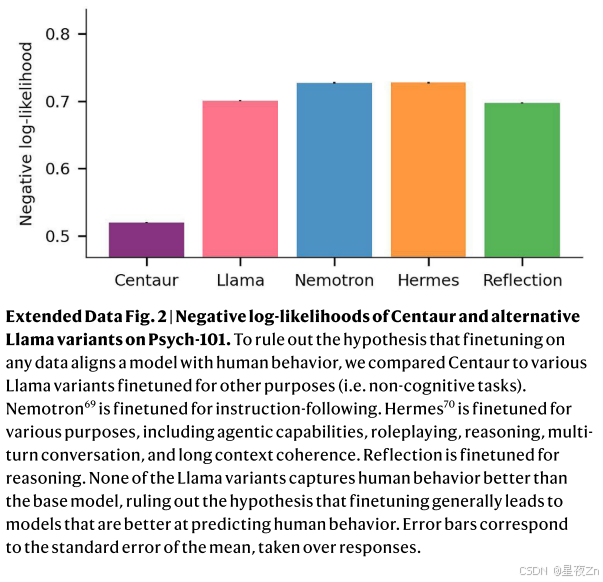
此外,我们将Centaur与前面提到的特定领域认知模型进行了比较。这些模型包括广义上下文模型17、前景理论模型18和各种强化学习模型19、20(方法,“特定领域认知模型”)。我们观察到,Centaur在除一个实验外的所有实验中都优于特定领域的认知模型。特定领域认知模型预测人类行为的平均差异为0.13(认知模型,负对数似然,0.56;单侧t检验:t(1,985,732)=-127.58,P ≤ 0.0001;科恩d,0.18)。扩展数据图图2和图3包含了更多的对非行为数据和噪声上限分析进行微调的模型的比较。
以前的分析集中在预测人类对先前执行的行为的反应。我们可能会问,当以开环方式进行模拟时(也就是说,当将自己的响应反馈到模型中时),Centaur是否也可以产生类似人类的行为。这种设置可以说提供了对模型能力的更强的测试,有时也被称为模型伪造21。为了检查Centaur是否能经受住这个测试,我们在三个不同的实验范例中进行了开环模拟,并检查了这些模拟产生的统计数据的分布。首先,我们在地平线任务范式上模拟了Centaur,这是一种用于检测不同类型探索策略的双臂强盗任务20。我们发现,半人马座(平均值= 54.12,s.d.= 2.89)实现了与人类参与者相当的性能(平均值= 52.78,s.d.= 2.90),这得到了等效性检验的支持,等效性检验使用双单侧t检验程序,边界为±3点(P = 0.02)。半人马座也从事类似水平的不确定性引导的定向探索(图2b),这是一种在许多当代语言模型中明显缺失的模式。
我们还观察到,Centaur不仅捕获了平均参与者的行为,而且还捕获了整个人群产生的轨迹分布。例如,在两步任务中(一种用于区分无模型和基于模型的强化学习的众所周知的范例19),Centaur就像人类受试者一样,产生了学习完全无模型、完全基于模型及其混合的轨迹(如图2c中的双峰分布所示)。最后,我们验证了Centaur无法预测非人类行为。为此,我们考虑了一项研究,该研究要求参与者在四个典型的经济游戏中预测人类的反应或具有匹配统计数据的人工代理的反应22。与最初的人类研究结果相似,Centaur准确地预测了人类反应(准确率为64%),但难以预测人工反应(准确率为35%;单侧t检验:t(230)= 20.32,P ≤ 0.0001;图2d)。综上所述,这些结果表明,Centaur在各种环境中表现出类似人类的特征,证实它可以产生有意义的开环行为。
探索泛化能力
到目前为止,我们已经证明了Centaur可以推广到以前看不见的参与者,这些参与者执行的实验是训练数据的一部分。然而,一个真正的人类认知基础模型还必须捕捉任何任意实验中的行为,即使该实验不是训练数据的一部分。为了探究Centaur是否具有这种能力,我们将其暴露于一系列日益复杂的分布外评估。
首先,我们调查了Centaur在封面故事发生变化时是否稳健。在这个分析中,我们依赖于参考文献23中收集的数据,其中使用了前面提到的两步任务。除了经典的封面故事(宇宙飞船前往外星球寻找宝藏),这项研究还引入了一个新的封面故事,涉及神奇地毯。重要的是,《心理学-101》包括使用经典宇宙飞船封面故事的实验,但没有使用魔法地毯封面故事的实验。即便如此,我们发现半人马座在参考文献23的魔毯实验中捕捉到了人类的行为(图3a)。正如我们之前的分析一样,我们观察到微调后的改进,以及与特定领域认知模型相比的良好拟合度(Centaur负对数似然,0.51;美洲驼负对数似然,0.63;认知模型负对数似然,0.61;比较Centaur与美洲驼的单侧t检验:t(9,701)= −24.7,P ≤ 0.0001;比较Centaur与特定领域认知模型的单侧t检验:t(9,701)= −20.7,P ≤ 0.0001;本分析中使用的特定领域认知模型是一种混合模型,结合了基于模型和无模型的强化学习)。
在第二次分布外评估中,我们探讨了Centaur是否对任务结构的修改具有鲁棒性。为了测试这一点,我们将其暴露在一个名为Maggie的农场25的范例中。Maggie的农场通过增加第三个选项扩展了地平线任务模式。Psych-101包含几个双臂强盗实验(包括地平线任务),但不包括玛吉的农场或任何其他三臂强盗实验(它确实包含多臂强盗实验,有三个以上的选择)。因此,该分析提供了对Centaur对结构任务修改的鲁棒性的测试。我们发现Centaur捕捉到了Maggie农场上的人类行为,如图3b所示。我们再次观察到微调的好处,以及与特定领域的认知模型相比的有利的拟合优度,该模型不能很好地推广到该设置(Centaur阴性对数似然,0.42; Llama阴性对数似然,0.62;认知模型阴性对数似然,0.98;比较Centaur与Llama的单侧t检验:t(510,153)=-204.2,P ≤ 0.0001;比较Centaur与特定领域认知模型的单侧t检验:t(510,153)=-559.8,P ≤ 0.0001)。
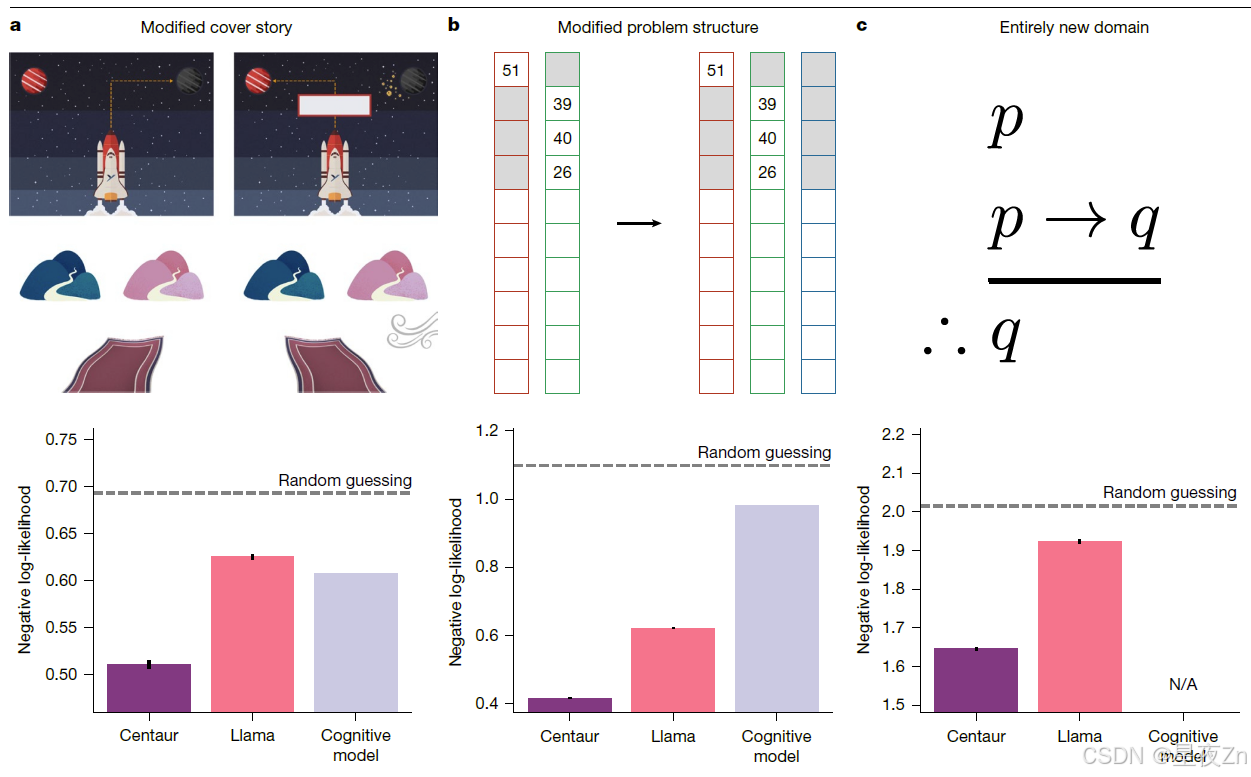
图3|在不同的暂挂设置中进行评估。a,对两步任务(封面故事经过修改)的回答(n = 9,702)进行平均的负对数似然性23。B,三臂强盗实验的反应(n = 510,154)的负对数似然性平均值25。c,对基于法学院入学考试(LSAT)的项目进行逻辑推理26的实验中的回答(n = 99,204)取平均值的负对数似然性。在面对修改的封面故事、问题结构和全新的领域时,半人马的表现优于美洲驼和特定领域的认知模型。不适用,不适用。误差线显示s.e.m.a中的图像摘自参考文献23,Springer Nature Limited。c中的图片转载自Wikipedia. org。
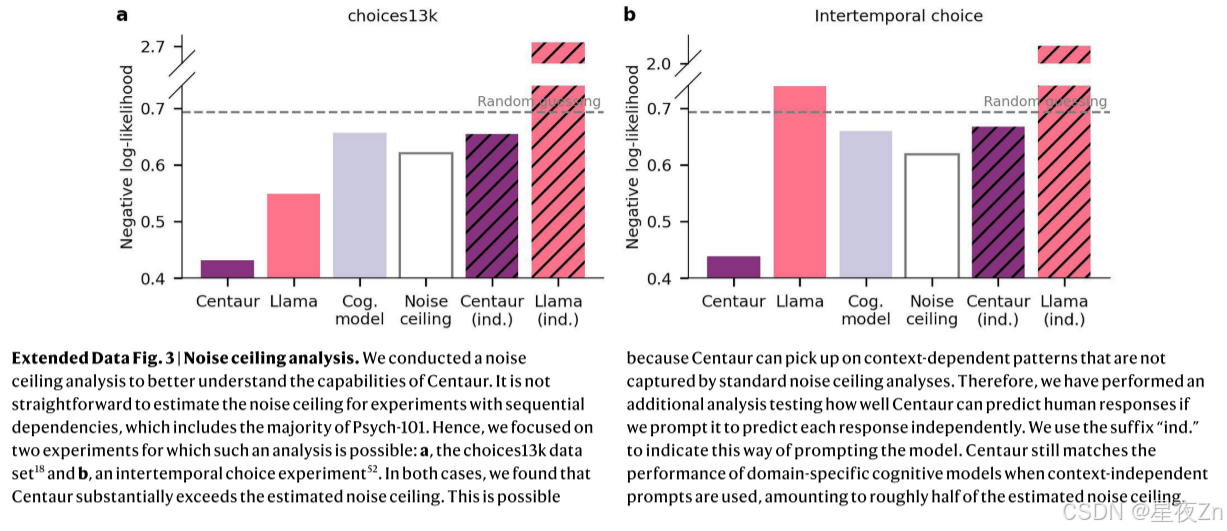
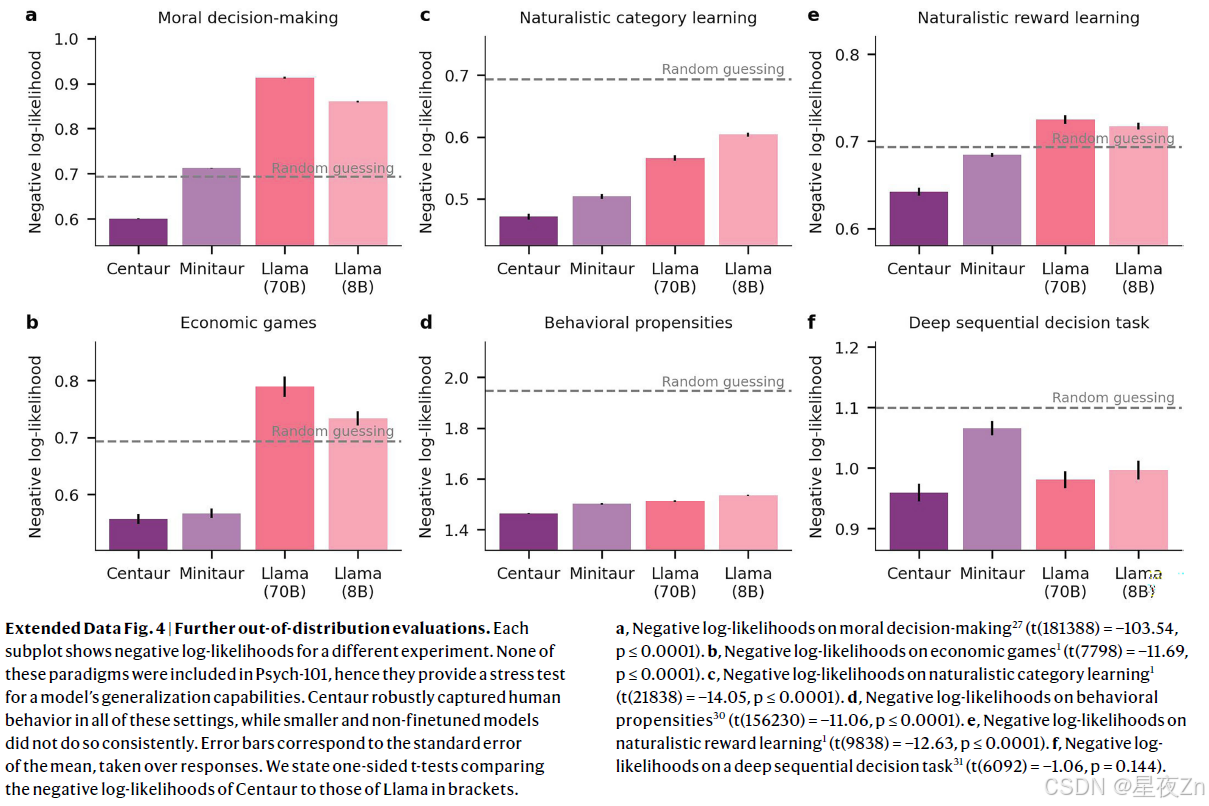
最后,我们研究了Centaur是否可以在全新的领域捕获人类行为。在这种情况下,我们考虑了一项研究调查逻辑推理26。虽然心理学-101包括概率和因果推理问题,但我们有目的地排除了任何涉及逻辑推理的研究。与之前的分析一样,微调也有积极的影响(半人马座负对数似然,1.65;美洲驼负对数似然,1.92;单侧t检验:t(198,406)= −50.39,P ≤ 0.0001;科恩d,0.23;图3c)。请注意,我们在此设置中没有与任何特定领域的认知模型进行比较,因为目前还不清楚如何构建一个模型,该模型将从不包括任何相关问题的训练数据中进行任何有意义的转移。我们通过分析Centaur的六个非分布实验范式来巩固这些结果,这些范式不是任何形式或形式的训练数据的一部分(包括道德决策27,经济游戏28,自然主义类别和奖励学习29,行为倾向30和深度顺序决策任务31)。Centaur在所有这些环境中都能很好地捕捉到人类的行为,而较小的和未经微调的模型并不能始终如一地做到这一点(扩展数据图4)。
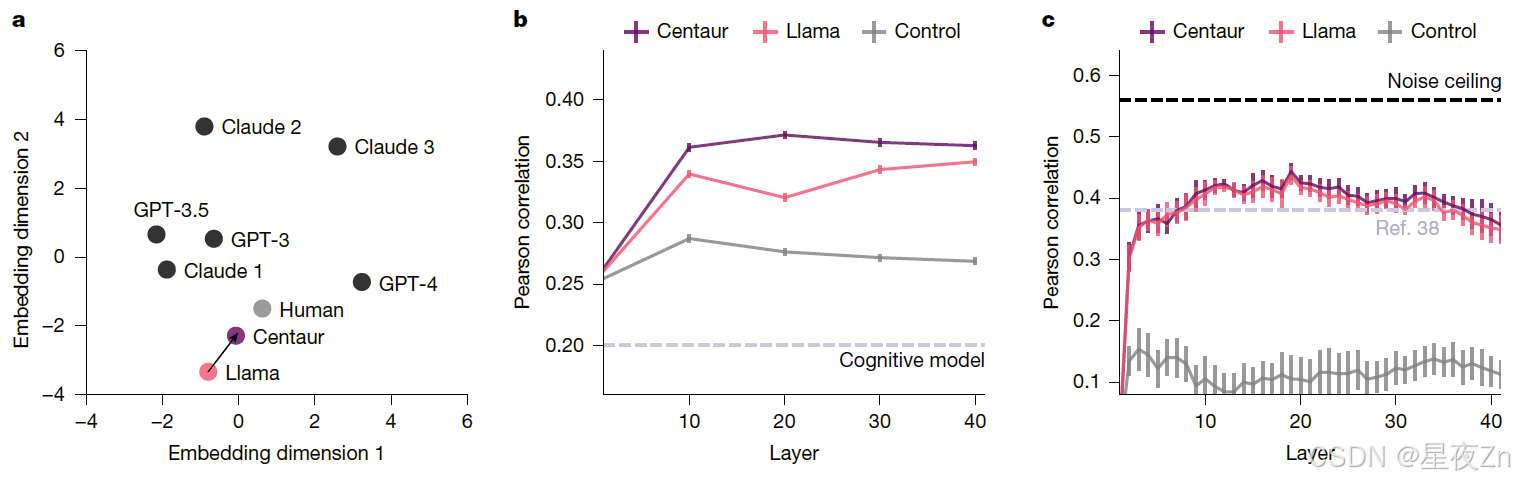
图4|人的一致性。a.多维标度嵌入CogBench33中的十个行为指标,用于不同的模型。B,皮尔森相关系数,其指示使用从不同层提取的半人马座内部表示可以多好地解码两步任务37中的人类神经活动。c.皮尔森相关系数,其指示使用从不同层提取的半人马座内部表示能够在多大程度上解码句子阅读任务38中的人类神经活动。控制指的是使用从具有匹配架构的随机初始化的Transformer模型中提取的表示的模型。
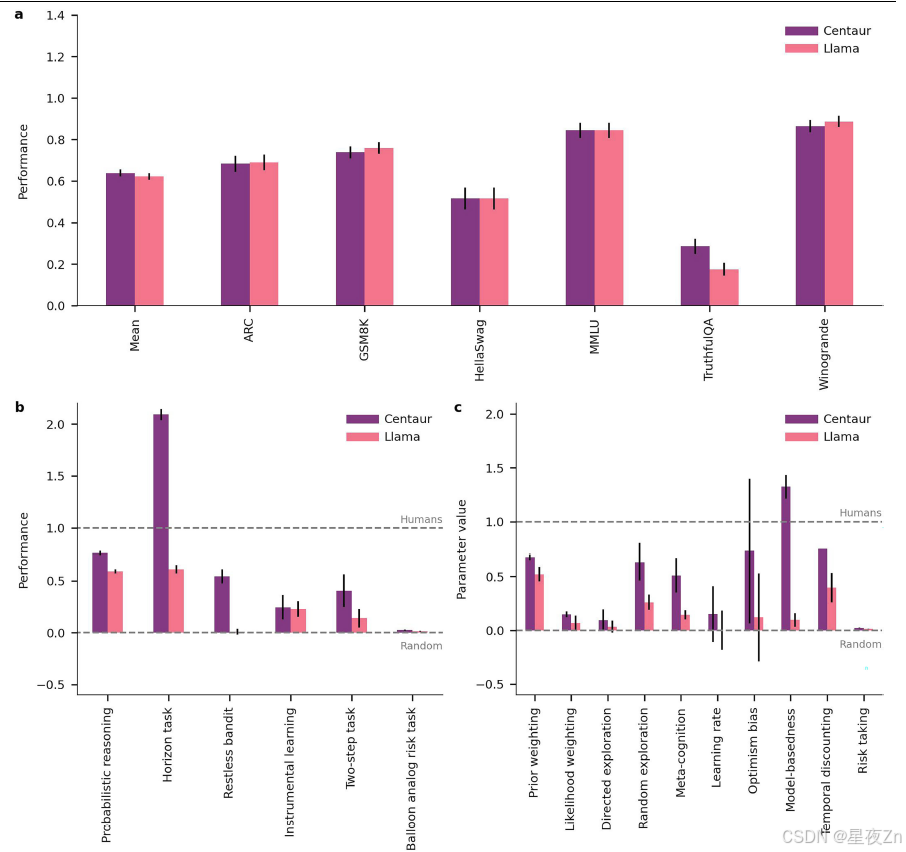
除了分析人类的选择数据,我们还研究了Centaur是否可以预测人类的反应时间。希克定律32表明,个体响应时间是响应熵的线性函数。因此,我们为Psych-101中的一个实验子集提取了近4,000,000个响应时间,并拟合了三个线性混合效应模型,每个模型都基于来自不同计算模型的对数转换响应熵预测对数转换响应时间。我们发现,从Centaur得到的响应熵捕获了响应时间方差的较大比例(条件R2,0.87)比那些来自美洲驼(条件R2,0.75,log[BFCentaur,Llama ] = 53,773.5)和认知模型(条件R2,0.77,log[BFCentaur,认知模型] = 14,995.5),从而强调了Centaur预测纯选择数据之外的测量值的能力。为了证明该模型不会在预训练的问题上降级,我们还在机器学习文献的基准集合上对其进行了验证33,34。我们发现Centaur在基于性能的基准测试中保持稳定,甚至在其中一些基准测试中比基础模型有所改进34(扩展数据图5a,B)。最后,在测量人类对齐的基准测试中,我们观察到向人类特征的转变(扩展数据图5c)。图4a描述了这种改进的对齐,它基于CogBench中的10个行为度量,CogBench是测试大型语言模型认知能力的基准33。
与人类神经活动的一致性
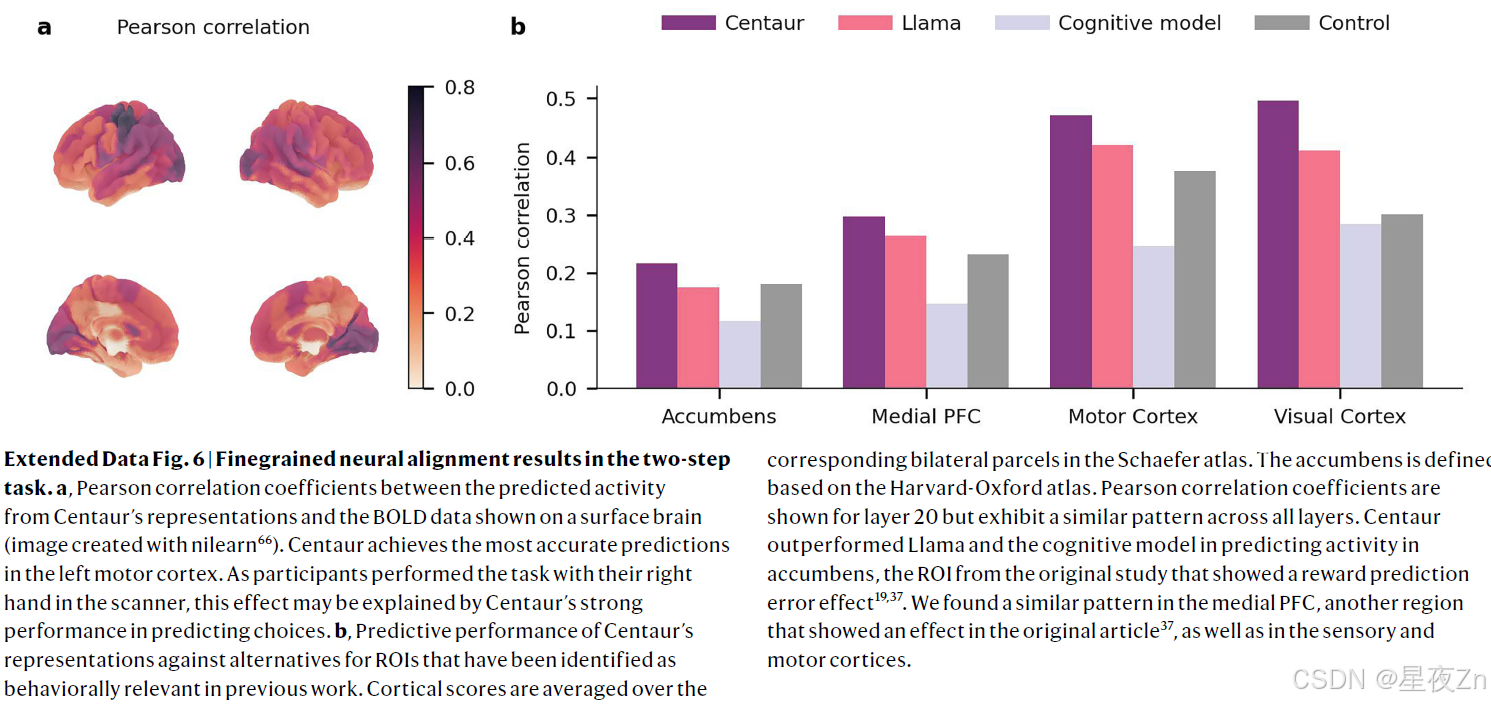
尽管被训练成只匹配人类行为,但我们也想知道半人马座的内部表征是否与人类神经活动更加一致。为了验证这一点,我们进行了两次分析,利用模型的内部表示预测了人类神经活动35、36。我们首先进行了一项全脑分析,在这项分析中,我们预测了执行两步任务的人的功能性磁共振成像(fMRI)测量结果37。为此,我们依赖于之前一项研究37中收集的数据,该研究涉及94名参与者,每人做出300个选择。参与者被测试的内容要么是魔术地毯式的封面故事(我们已经在之前的一次概括分析中使用过),要么是抽象的封面故事。这两个封面故事都不是Centaur训练数据的一部分。我们从模型的剩余流中提取了每个选择之前和反馈之后的录音。然后,我们汇总了每个区域的人类神经活动,并将汇总的活动回归到Centaur的内部表示上。然后对每个参与者和区域分别重复这个过程(方法,“神经元识别”)。图4b显示了Centaur和Llama在测量期间平均的跨层Pearson相关系数(n = 11,374)。我们发现,Centaur的表示在预测人类神经活动方面始终优于Llama的表示(所有成对单侧t检验,P ≤ 0.001),这表明对大规模行为数据进行微调可以使其内部表示与人类神经活动保持一致。值得注意的是,这种类型的分析是可能的,只是因为半人马座的表征的表现力,而使用传统的认知模型的表征导致性能大幅下降(图4b中的虚线)。扩展数据图6给出了我们的结果的更细粒度的报告。
我们在第二次分析中扩展了这些结果,我们依赖于之前收集的数据集,其中包括对人们阅读简单的六个单词的句子的功能磁共振成像测量,比如“这是一幅多么美丽的图画!”38岁。这项分析的主要目的是表明,在认知实验中进行微调后,在不相关的环境中,神经排列仍然完好无损。我们关注了一个由五名参与者组成的子集,他们每人被动地阅读了1,000个句子,分布在20次实验运行和两次扫描会话中。所提供的句子是从九个语料库中提取出来的,并被选择为最大化语义多样性。我们严格遵循了最初研究的协议,预测了语言网络中参与者的聚合神经活动。我们对从半人马座和美洲驼的不同图层中提取的表示重复此过程。如图4c所示,可预测性在第20层附近达到峰值。该峰值与这样的模型的中间层包含最多信息的假设一致。我们对Centaur和Llama之间的相关性差异进行了反向加权荟萃分析39,结果表明,当跨层合并时,微调具有显著的益处(β = 0.007,95%置信区间[0.0002,0.013],P = 0.045)。尽管该效应在各层之间是一致的,但对于任何单个层而言均不具有统计学显著性。
模型引导的科学发现
Psych-101和Centaur都是科学发现的宝贵工具。在下面的部分中,我们将展示一个例子,说明如何使用它们中的每一个来提高我们对人类决策的理解。该过程的各个步骤如图5所示。
Psych-101包含自然语言格式的人类行为数据,这意味着它可以很容易地通过基于语言的推理模型(如DeepSeek-R1)进行处理和分析。为了演示这个用例,我们要求DeepSeek-R1在多属性决策实验中对参与者的行为进行解释。在这个范例中,参与者被给予两个不同的选项,每个选项都有不同的特征(在我们的例子中,两个产品有四个专家评级),然后他们必须决定他们更喜欢哪一个选项(图5a)。该模型产生了几种解释,其中一种引起了我们的注意:“参与者采用了两步决策策略。首先,他们确定了哪些产品在所有专家中获得了大多数正面评级(1)。如果这些产品在正面评级的数量上并列,那么参与者就会考虑最高有效性专家的评级来打破平局。该策略结合了两个众所周知的启发式决策策略,据我们所知,在此组合之前没有考虑过。然后,我们采用这种语言策略,将其作为正式的计算模型来实现,并发现它比原始研究中考虑的三种策略(加权加法策略,等权重和最佳启发式;图5 b)更准确地解释了人类的反应行为。
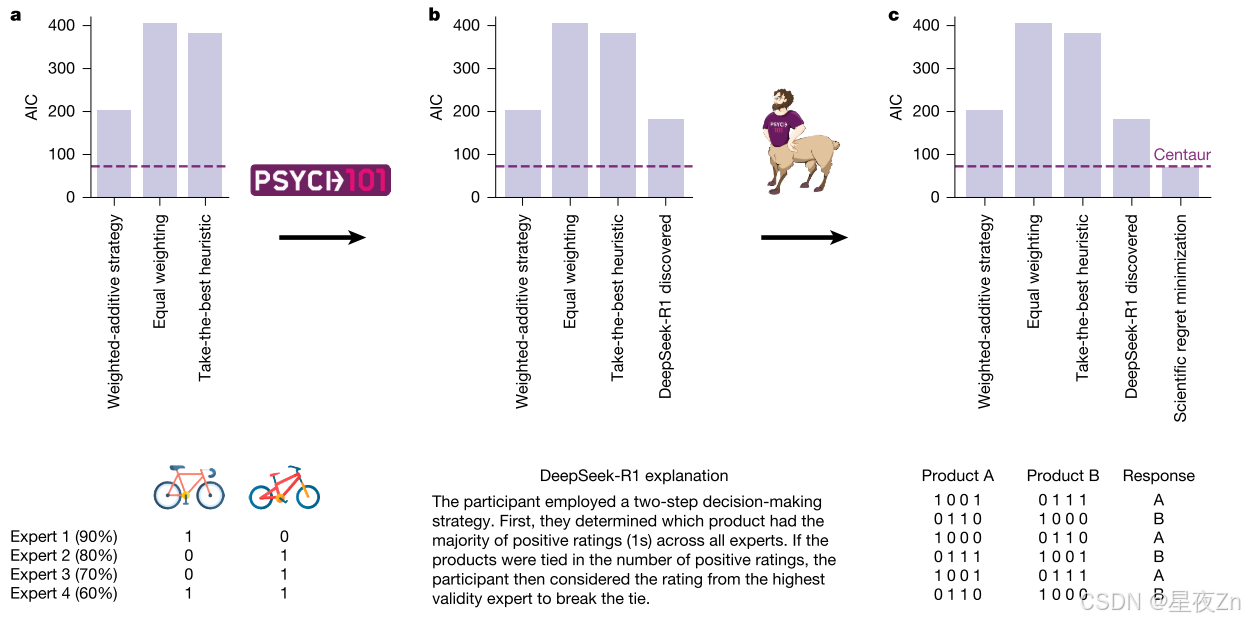
图5|模型引导的科学发现。a.我们使用Psych-101和Centaur指导开发多属性决策研究的认知模型41。每个面板显示了在给定阶段考虑的模型集的AIC,从原始研究中考虑的模型开始。B,我们要求DeepSeek-R1为人类反应生成一个解释,并将生成的语言策略形式化为一个正式的计算模型。c、以半人马座为参考模型,通过科学的后悔最小化方法对模型进行了改进。图中显示了六个数据点,半人马座对这些数据点做出了准确的预测,但DeepSeek-R1发现的模型却没有。然后,我们利用这些信息设计了一个领域特定的认知模型,该模型与半人马座一样具有预测性,但仍然是可解释的。中的自行车图像是从Flaticon.com复制的。
然而,DeepSeek-R1发现的模型Akaike信息标准(AIC; 181.7)仍然没有达到Centaur的拟合优度(AIC,72.5),这表明仍有改进的空间。因此,我们使用了一种被称为科学遗憾最小化的方法,该方法使用黑盒预测模型作为参考,以识别原则上可预测但未被给定模型捕获的反应。通常,科学的后悔最小化需要收集大规模的实验特定数据集来训练这个预测模型。然而,Centaur可以开箱即用,不需要收集任何特定领域的数据,从而绕过了这一步骤,大大扩大了科学遗憾最小化的范围(事实上,正在考虑的多属性决策数据集包含不到100个参与者,使其远远超出了传统的科学遗憾最小化)。当检查Centaur预测良好但不是DeepSeek-R1发现模型的响应时,我们观察到它们都涉及参与者选择总体正面评级较少但被更高有效性专家正面评级的选项的问题(参见图5c关于这些问题的说明和方法,“模型引导的科学发现”以了解更多细节)。这种模式表明,这两种策略之间的切换可能不像DeepSeek-R1-discovered策略最初建议的那样严格。为了抓住这一点,我们用两个概率的加权平均值代替了非此即彼的规则。我们发现,这个过程产生的模型在拟合优度(AIC,71.7)方面与Centaur相匹配,但仍然是可解释的。我们将所有模型的AIC值输入到组级模型选择程序43中,并估计受保护的一致性概率,该概率定义为特定模型在组内的频率高于所有其他候选模型的概率。从科学遗憾最小化模型得出的受保护的服从概率为P = 0.83。值得注意的是,这个模型比较的结果与使用原始模型进行的结果形成对比,并表明人们在做出决策时依赖于一种组合的策略,而不是遵循加权的加法策略44。
讨论
在本文中,我们介绍了Centaur,这是一个人类认知的基础模型,它是通过对Psych-101(一个大规模的人类行为数据集)上最先进的语言模型进行微调而获得的。这种方法使我们能够利用大型语言模型中嵌入的大量知识,并将它们与人类行为保持一致13。Centaur成功地捕捉了人类行为,并通过了广泛的分发检查。它不仅推广到看不见的参与者,而且推广到不同的封面故事、结构变化和全新的领域。除了在行为层面上分析模型外,我们还对其内部表征进行了一系列分析,其中我们发现与人类神经活动的一致性增加。
我们还进行了一项案例研究,展示了Psych-101和Centaur如何用于指导预测性但可解释的认知模型的开发。我们的程序的各个步骤是通用的,因此它可以作为未来其他实验范式中模型引导的科学发现的蓝图。除了这个例子,Centaur还发现了自动认知科学的更多应用45,46。例如,它可以用于实验研究的计算机原型制作47。在这种情况下,可以使用该模型来确定哪些设计会产生最大的效应量,如何设计研究以减少所需参与者的数量或估计效应的功效。本文采取了初步措施,利用半人马座获得更深入的了解人类认知,它也开辟了令人兴奋的新途径,为未来的探索。首先,我们可以进一步探索半人马座的内部表征,以了解它如何表示知识和处理信息。由此产生的见解可以反过来用于生成关于人类知识表示和信息处理的假设,这些假设可以在未来的实验研究中得到验证。我们相信稀疏自动编码器48和注意力地图可视化49等工具为实现这一目标提供了有希望的途径,我们希望在未来的研究中探索它们。
此外,还可以使用我们在本文过程中创建的数据集从头开始训练具有不同架构的模型。这样做将使我们能够以前所未有的规模研究人类认知的神经结构。例如,我们可能会问这样的问题:人类信息处理是由基于注意力的架构50还是由基于向量的记忆的架构更好地描述,或者通过结合神经科学文献的理论,我们可以提高多少。我们期望这种方法的最终结果包含特定领域和通用领域的模块,从而使我们能够研究两者之间的相互作用。据我们所知,Psych-101已经是现有的最广泛和最大的人类行为数据集,我们将其开发视为一个持续的过程,并计划进一步开发。目前的重点主要是学习和决策,但我们打算最终包括更多的领域,如心理语言学,社会心理学和经济游戏。关于个体差异信息的实验是当前Psych-101迭代中被忽视的数据的另一个来源。理想情况下,我们希望在提示中包含有关受试者的所有类型的相关信息(包括年龄,人格特质或社会经济地位),以便在这些数据上训练的模型可以捕获个体差异。发展心理学或计算精神病学的实验为这一目的提供了理想的来源。最后,尽管我们已经纳入了一些跨文化和元研究52 -55,但当前的迭代仍然对西方、受过教育、工业化、富裕和民主(WEIRD)的人口有强烈的偏见56。
最终,我们希望以标准化的格式提供任何心理数据,以促进基准测试,从而补充神经科学界的现有努力57,58。虽然这项工作中使用的自然语言格式(加上相当多的逆向工程)使我们能够表达大量的实验范式,但它引入了对无法用自然语言表达的实验的选择偏见。因此,长期目标应是逐步采用多式联运数据格式59。
结论
当统一认知模型的想法首次提出时,研究人员表示担心认知科学的既定领域可能会对这种模型产生负面反应。特别是,他们担心这种方法可能会被视为不熟悉或与现有理论不兼容,就像“带有不适当信息素的入侵者”一样。这可能会导致“杀人蜂的攻击”,在这种情况下,更传统领域的研究人员会激烈地批评或拒绝新模型,以捍卫他们的既定方法。为了缓解这些担忧,提出了认知十项全能的概念:一个严格的评估框架,其中竞争模型的认知在十个实验中进行测试,并根据其累积表现进行判断。在目前的工作中,我们将Centaur应用于相当于16个这样的认知十项全能,其中它与许多已建立的模型进行了测试,并始终赢得了每一场比赛。这一结果表明,数据驱动的领域一般认知模型的发现是一个很有前途的研究方向。未来研究的下一步应该是将这一领域通用的计算模型转化为人类认知的统一理论。
方法
数据收集
我们通过将160个心理学实验的数据转录成自然语言来构建Psych-101。每个提示都设计为包括来自单个参与者的完整会话的整个试验历史。所包括的实验是使用以下标准选择的:公开可用的数据在一个试验一个试验的水平;转录成文本的可能性,而不会有显着的信息损失;和广泛的领域的覆盖面。每个实验的转录由作者手动完成。根据需要,个体研究获得了机构审查委员会的批准。我们使用以下原则设计自然语言提示:说明应尽可能遵循原始研究;在适当的情况下进行简化;最大提示长度约为32,768个标记。有关所有实验的完整信息,请参见补充信息,示例提示。
微调程序
Llama 3.1 70B是我们微调程序的基础模型。我们使用了一种称为QLoRA16的参数高效微调技术,该技术将所谓的低秩适配器添加到四位量化基础模型的每一层。在微调过程中,基本模型保持固定,仅调整低秩适配器的参数。我们将秩r = 8的低秩适配器添加到自注意机制和前馈网络的所有线性层。每个低秩适配器按如下方式修改前向传递:
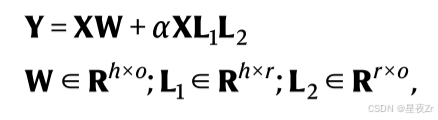
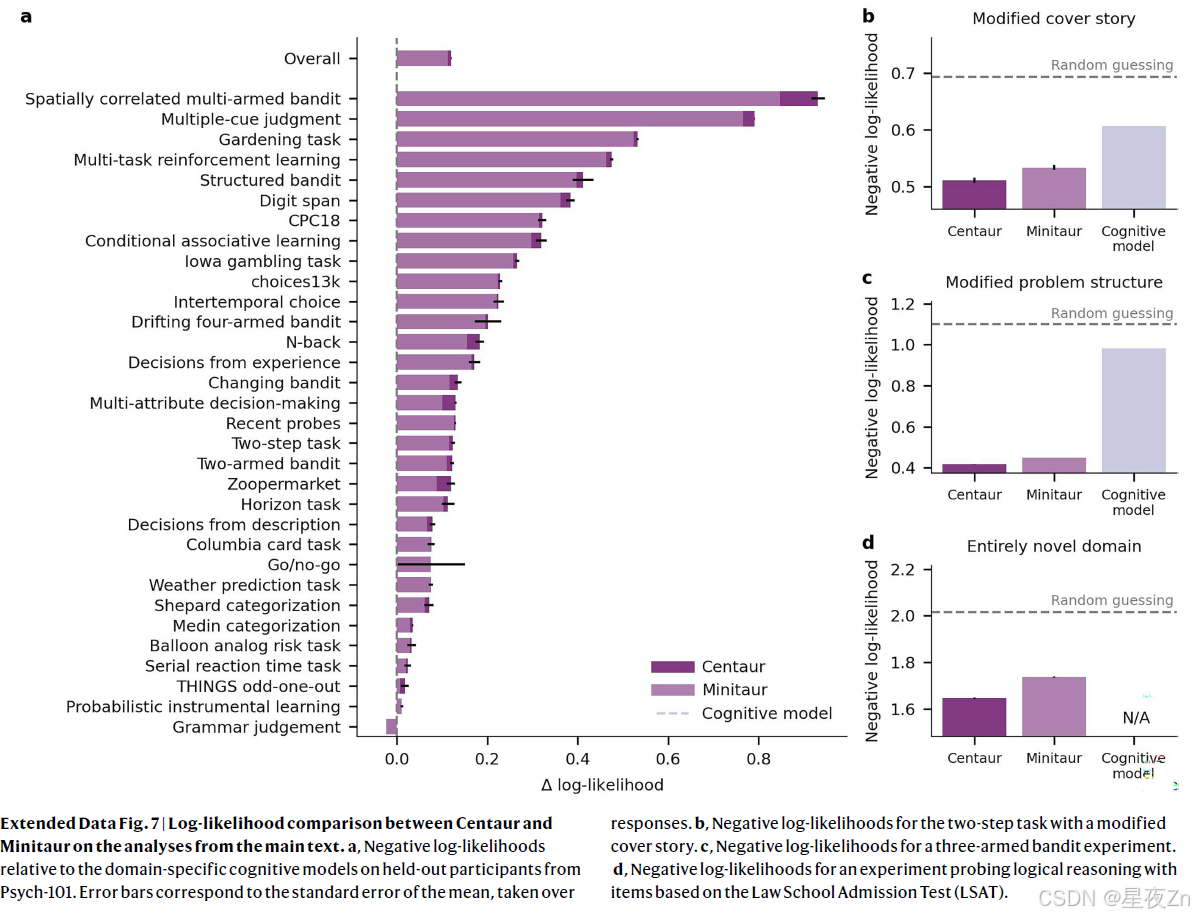
其中XW是基本模型的(量化的)线性变换,XL 1 L2是低秩适配器组件,X是维度为h的层的输入,Y是维度为o的层的输出。超参数α控制着两者之间的权衡。R是真实的的集合。低阶适配器计算以半精度浮点格式执行。有关该技术的更多细节,请参见原著16。我们使用标准的交叉熵损失对整个数据集上的一个时期的模型进行了微调(我们使用延长的训练进行了实验,但发现这会导致过度拟合)。我们只反向传播了人类反应的损失,并掩盖了所有其他令牌的损失。有效批量设定为32,学习率设定为0.00005,重量衰减设定为0.01。我们使用了8位AdamW优化器61,在前100个梯度步骤中线性增加预热。使用unsloth库(https://unsloth.ai/)实现了微调过程。我们还训练了一个更小版本的半人马,称为Minitaur,它使用美洲驼3.1 8B作为基础模型,遵循相同的配方。Minitaur捕捉到接近其训练分布的人类行为,但与较大模型相比,其推广到分布外实验的鲁棒性较差(扩展数据图7)。然而,我们相信Minitaur对于原型开发是有用的,因为它不需要访问任何特定的硬件(例如,它在Google Colab中的免费GPU实例上运行)。
评估指标
我们使用响应平均的(负)对数似然作为我们的评估指标。对于具有多令牌响应的实验,我们在响应内对对数似然进行求和,并对响应进行平均。每当我们测试Centaur在预测人类行为方面是否优于竞争模型时,我们都使用单侧t检验,因为我们的假设是有方向的,并且基于Centaur表现更好的先验预期。由于我们分析中的观测值数量通常很大,因此在适当的情况下对多重比较进行校正后,报告的显著效应仍然存在。
领域特定认知模型
我们选择了14个认知和统计模型作为我们的基线模型,这些模型共同涵盖了Psych-101中的大部分实验。有关所含型号及其规格的更多详细信息,请参见补充信息,建模详细信息。对于我们的主要分析,我们感兴趣的是预测被拒参与者的行为。因此,我们为训练数据中的所有参与者拟合了一组联合参数,并评估了具有这些参数的模型预测参与者的反应的效果。模仿基于语言的模型的评估指标,我们使用响应平均的(负)对数似然来评估拟合优度。对于分布外的评估,我们使用训练集中最相似的实验拟合模型参数,然后我们评估了具有结果参数的模型在看不见的环境中预测人类反应的效果。在两步任务的魔毯版本中,最相似的实验是一个两步任务实验,默认的飞船封面故事。玛吉农场最相似的实验是地平线任务。我们没有包括逻辑推理任务的基线模型,因为训练数据中没有一个实验与之相似。
神经对齐
两步任务的神经对齐分析是使用先前研究中收集的数据进行的37。我们使用正则化线性回归模型来预测来自Centaur和Llama内部表征的fMRI数据(每个参与者和区域使用单独的模型)。我们在两个扫描块的数据上拟合了这些模型,并在第三个扫描块的数据上对其进行了评估。使用嵌套交叉验证程序选择正则化强度。对于每次运行,我们使用具有100个ROI的Schaefer 2018图谱将beta图分为皮质和皮质下感兴趣区域(ROI)62。我们对每个ROI内的beta进行平均,将beta的数量从体素的数量减少到ROI的数量。评价了来自图谱的所有皮质和皮质下ROI。报告的Pearson相关系数对应于所有ROI的平均值。从模型的剩余流中提取内部表示,并使用主成分分析进行转换。我们设置了保留分量的数量,使得它们可以解释95%的方差。使用fMRIPrep 24.0对fMRI数据进行预处理(参考文献63)。我们使用fMRIPrep的默认设置,所有扫描均与MNI 152NLin2009cAsym atlas64对齐。为了提取任务的每个子试验的效果估计(例如第五次试验的第二步,或第十次试验的反馈),我们建立了单独的一般线性模型(GLM)。每个GLM包括感兴趣的子试验作为单独的回归变量,其z评分的β估计值用于比对分析。这部分数据未使用其他回归变量建模。此外,我们还包括不同的回归器,捕获所有第一步,所有第二步和所有反馈步骤。最后,我们使用了六个旋转和平移估计以及逐帧位移作为噪声回归量。使用spm65模型对血流动力学反应进行建模。应用0.01 Hz的高通滤波器和具有6 mm半峰全宽的高斯核。GLM使用nilearn66构建。使用来自原始研究的公开代码38对重复阅读任务进行神经对齐分析。除了用Centaur和Llama替换GPT2-XL外,未进行其他变更。请参阅原始研究38了解更多详情。
模型引导的科学发现
在我们的模型引导的科学发现分析中,我们专注于测试集中的参与者,以避免任何潜在的污染问题。我们使用最大似然估计为每个参与者分别拟合所有认知模型的参数。使用AIC将模型彼此进行比较。原始研究中的三个模型通过以下等式实现:
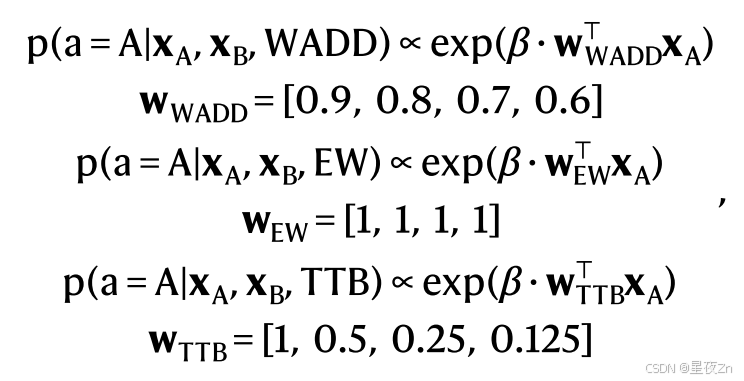
其中xA和xB是包含四个专家评级(0或1)的向量,β是控制噪声水平的自由参数。我们提示DeepSeek-R1(在Distill-Llama-70 B变体中)生成对人类决策的解释;相应的提示在补充信息,模型引导的科学发现中提供。然后,我们将图5 b中所示的解释形式化为以下计算模型:
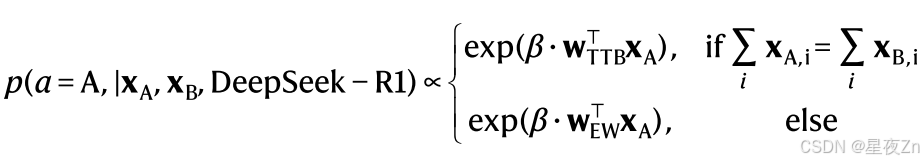
对于科学遗憾最小化管道,我们计算了Centaur和DeepSeekR1发现的模型之间的对数似然差异。我们可视化并检查了差异最大的十个数据点。该过程产生以下计算模型:
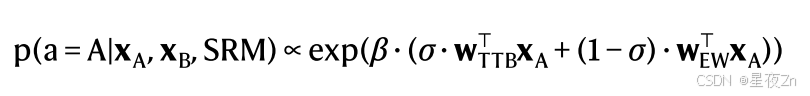
其中σ是约束在0和1之间的自由参数,其控制两种策略之间的权衡。
任何方法、其他参考文献、Nature Portfolio报告摘要、源数据、扩展数据、补充信息、致谢、同行评审信息;作者贡献和竞争利益的详细信息;以及数据和代码可用性声明,请访问https://doi.org/10.1038/s41586-025-09215-4。
Psych-101 is publicly available on the Huggingface platform at https:// huggingface.co/datasets/marcelbinz/Psych-101. The test set is accessible under a CC-BY-ND-4.0 licence through a gated repository at https:// huggingface.co/datasets/marcelbinz/Psych-101-test.
Centaur is available on the Huggingface platform at https://huggingface. co/marcelbinz/Llama-3.1-Centaur-70B-adapter. The extra code needed to reproduce our results is available at https://github.com/marcelbinz/ Llama-3.1-Centaur-70B.
以上内容全部使用机器翻译,如果存在错误,请在评论区留言。欢迎一起学习交流!
郑重声明:
- 本文内容为个人对相关文献的分析和解读,难免存在疏漏或偏差,欢迎批评指正;
- 本人尊重并致敬论文作者、编辑和审稿人的所有劳动成果,若感兴趣,请阅读原文并以原文信息为准;
- 本文仅供学术探讨和学习交流使用,不适也不宜作为任何权威结论的依据。
- 如有侵权,请联系我删除。xingyezn@163.com