训练模型时梯度出现NAN或者inf
参考:
训练模型时梯度出现NAN或者INF(禁用amp的不同level)_grad norm inf-CSDN博客
Got a nan loss and gradient norm when training swin-l on imagenet22k with O1 · Issue #82 · microsoft/Swin-Transformer
Got a nan loss and gradient norm when training swin-l on imagenet22k with O1 · Issue #82 · microsoft/Swin-Transformer
首先查找原因:找到是在哪一层断开了梯度
实现代码:
# loss 数值诊断
if torch.isnan(loss) or torch.isinf(loss):print("❌ Loss 出现 NaN/Inf")# 梯度诊断
for name, param in model.named_parameters():if param.grad is not None:if torch.isnan(param.grad).any():print(f"❌ {name} 梯度中存在 NaN")elif torch.isinf(param.grad).any():print(f"⚠️ {name} 梯度中存在 Inf")
排查可能原因:
1. 模型中存在未初始化或未更新的参数(层)
2. 除以0或者log引起
3.输入数据存在你nan或者inf
4. 学习率过大造成梯度不稳定
5.数据类型问题
由于梯度更新使用了AMP,加之具体问题:前1-2个epoch的grad norm出现 nan, 后面又稳定了,偶尔又会出现inf。合理怀疑是数据类型的问题。
PyTorch 的 AMP(自动混合精度) 默认支持动态切换精度。它会在前向和后向传播中自动判断是否切换为 float16 精度,以节省显存并加速计算。在使用 AMP 时,通常采用以下几种机制来选择精度:
按操作动态调整精度:AMP 会根据具体操作的数值稳定性来选择 float32 或 float16,对于稳定性较好的操作(如矩阵乘法)使用 float16,对精度要求较高的操作(如归一化)则保留 float32。
GradScaler 动态调整梯度缩放:AMP 默认使用 GradScaler 对梯度进行缩放,以避免因 float16 造成的数值下溢(过小梯度被舍去)。
这种自动化过程旨在最大程度保持数值稳定性,并降低显存需求。只需使用 torch.cuda.amp.autocast 上下文管理器和 GradScaler,AMP 就能完成动态精度切换


import torch
from torch.cuda.amp import GradScaler, autocast# ========= 训练前配置部分 =========
# 默认使用 AMP(float16),可通过命令行参数禁用或修改精度选项
use_amp = not args.disable_amp
amp_dtype = torch.float16 # 可选:torch.bfloat16, torch.float16if args.amp_opt_level == 'O0':use_amp = False
elif args.amp_opt_level == 'O1':amp_dtype = torch.float16
elif args.amp_opt_level == 'O2':amp_dtype = torch.float16
elif args.amp_opt_level == 'O3':amp_dtype = torch.float16
elif args.amp_opt_level == 'bf16':amp_dtype = torch.bfloat16
else:amp_dtype = torch.float16 # 默认 fallback# AMP梯度缩放器(避免数值下溢)
scaler = GradScaler(enabled=use_amp)# ========= 模型初始化 =========
model = MyModel()
model = model.to(device)# 如果使用 bfloat16,可考虑转换模型参数
if amp_dtype == torch.bfloat16 and use_amp:model = model.to(dtype=torch.bfloat16)# ========= 训练过程 =========
for epoch in range(num_epochs):model.train()for batch in dataloader:inputs, targets = batchinputs = inputs.to(device)targets = targets.to(device)if amp_dtype == torch.bfloat16 and use_amp:inputs = inputs.to(dtype=torch.bfloat16)targets = targets.to(dtype=torch.bfloat16)optimizer.zero_grad()with autocast(enabled=use_amp, dtype=amp_dtype):outputs = model(inputs)loss = criterion(outputs, targets)if use_amp:scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:loss.backward()optimizer.step()print(f"Epoch {epoch} finished.")# ========= 验证及日志 =========
# 可加入日志记录:记录grad norm是否为nan,或loss是否稳定
def log_gradient_norm(model):total_norm = 0.0for p in model.parameters():if p.grad is not None:param_norm = p.grad.data.norm(2)if torch.isnan(param_norm) or torch.isinf(param_norm):print("⚠️ Gradient contains NaN or Inf")total_norm += param_norm.item() ** 2total_norm = total_norm ** 0.5print(f"Gradient norm: {total_norm:.4f}")
解决方案:
1. 禁用自动混合精度(AMP):
如果你不依赖于 bfloat16 的性能优化,可以选择禁用 AMP。你可以在你的主函数中设置 --disable_amp 参数,或者在代码中直接注释掉与 GradScaler 和 autocast 相关的代码。这将避免因 bfloat16 引起的问题。
. --disable_amp
类型: 布尔型(action='store_true')
功能: 如果指定了这个参数,将会禁用 PyTorch 的自动混合精度功能。在训练过程中,这意味着模型将会使用全精度(通常是 float32)进行计算,而不使用混合精度。
适用场景: 在调试或遇到精度问题时,可以选择禁用 AMP。
2. 使用 bfloat16:
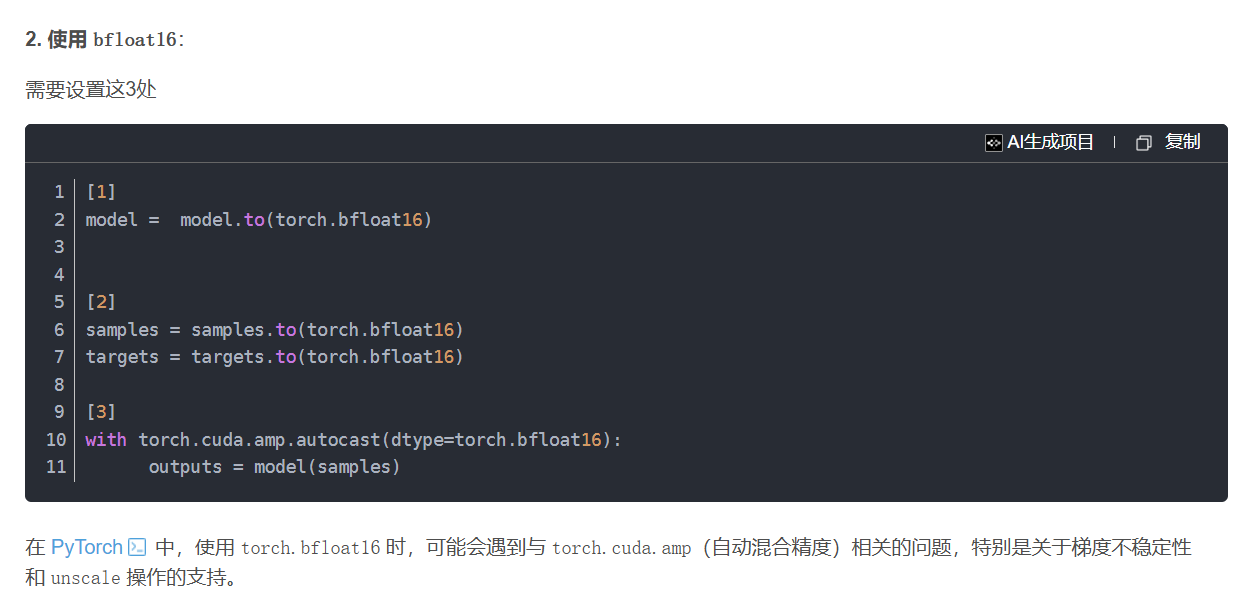
3.设置级别

| 模式 | 推荐设置 | 使用场景 |
|---|---|---|
| 禁用 AMP | --disable_amp 或 --amp-opt-level O0 | 调试/排查数值问题最稳妥 |
| 安全混合精度 | --amp-opt-level O1(默认) | 高性能但更安全的float16使用方案 |
| 激进混合精度 | --amp-opt-level O2 | 对性能要求较高,模型已测试数值稳定时使用 |
| bfloat16 | --amp-opt-level bf16 + A100以上GPU | 更高稳定性的混合精度方案,适用于新硬件 |
| 强制float16 | --amp-opt-level O3 | 实验阶段或推理速度要求极高但需谨慎 |