人工智能基础知识笔记十五:文本分块(Chunk)
1、 文本分块(Chunk)简介
将长文本切割为多个逻辑连续的短文本单元,每个单元称为一个"Chunk"。类似将一本厚书拆分成若干章节,每章节独立阅读但内容连贯。
分块的关键参数
| 参数 | 说明 | 典型值 |
| Chunk Size | 每个块的长度(按字符、单词或Token计算) | 256-2048 tokens |
| Chunk Overlap | 相邻块之间的重叠部分长度(防止上下文断裂) | 10-20% of chunk size |
| Separator | 分割文本的标识(如换行符、句号、章节标题) | \n\n, 。, ## |
2、 为什么要分块(Chunk)
2.1、模型记忆的物理限制
把LLM想象成一个学生,它的"短期记忆"容量有限(比如只能记住最近128K单词)。
就像上课时,老师讲的内容太多(比如300页PPT),学生不可能一次性记住所有内容。把300页PPT拆成每次只讲10页,学生就能分批消化。
2.2、上下文窗口的数学本质
每个LLM都有固定的"上下文窗口",相当于它的"记忆槽位"。例如:GPT-3.5:4k tokens ≈ 3000汉字, Claude 3:200k tokens ≈ 15万字。
如果处理约200万字的书,即使Claude 3也需要分块:
总字数 2,000,000 ÷ 200,000 = 至少分10块3、 分块(Chunk)的作用
3.1、分块可以解决"遗忘症"问题
假设你让LLM总结一部长篇小说,但一次性输入全部内容,示例代码如下:
# 错误示范(不分组)
full_novel = "第一章...第100章" # 假设超过模型限制
response = llm("请总结以下小说:" + full_novel)
# 实际结果:模型只能"记住"最后几章,总结完全遗漏开头信息截断的结果导致输入的信息不全,进而导致最终的结果与预期不一致。
分块的处理正确姿势如下:
# 正确做法
chunks = split_into_chunks(full_novel, chunk_size=model_max_length)
summaries = []
for chunk in chunks:summary = llm("请总结这部分:" + chunk)summaries.append(summary)
final_summary = combine(summaries) # 合并各块总结就像看电影时,每次暂停后重看前30秒,确保剧情连贯。
# 带重叠的分块(滑动窗口)
chunk_size = 1000 # 每块1000字
overlap = 200 # 重叠200字[块1: 1-1000字] [块2: 801-1800字] # 前200字与块1重复[块3: 1601-2600字]...3.2、分块提高效率
注意力机制的计算量:与文本长度的平方成正比(O(n²))。处理2000 tokens的计算量 ≈ 4倍于1000 tokens,可降低计算负担。对比如下:

GPU处理长文本时需要存储所有中间状态,分块后显存占用大幅降低。处理1k tokens的块比10k tokens节省约100倍内存(近似值)。
3.3、分块提高匹配的精度和效率
小块文本能更精准匹配查询问题。(例如搜索"爱因斯坦生日"时,直接命中相关段落而非整本书)。
4、 分块(Chunk)的原则
句子完整性:永远不在句号/问号中间切断
段落一致性:同一段落尽量放在同个块中
实体连续性:人名/地名/数字不被分割
优先按段落/句子分割,其次按空格/字符, LangChain的实现代码如下:
from langchain.text_splitter import RecursiveCharacterTextSplitter# 优先按段落/句子分割,其次按空格/字符
splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。", "?", "!", " ", ""]
)5、 分块(Chunk)的种类
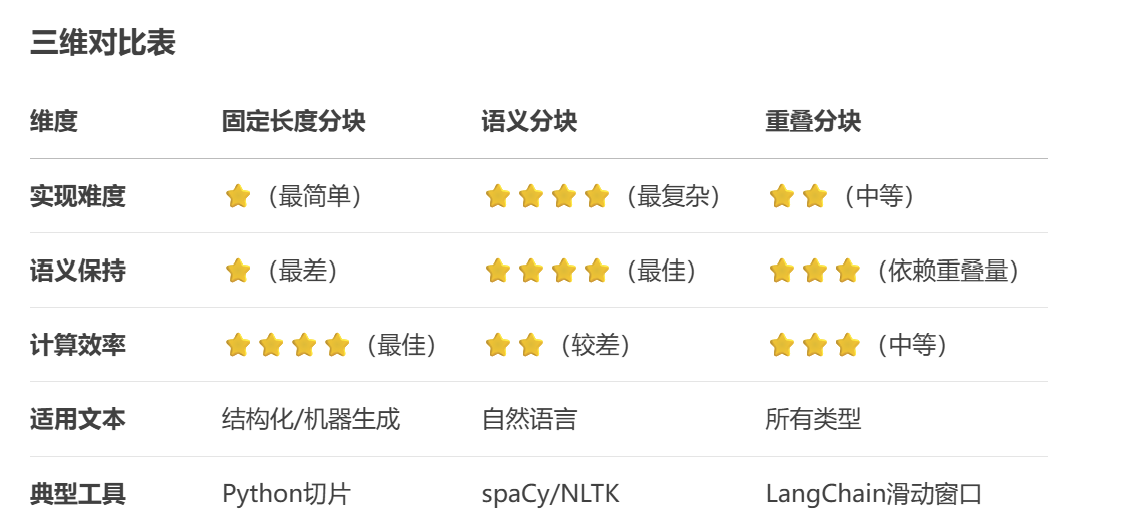
5.1 固定长度分块(Fixed-size Chunking)
顾名思义,固定长度分块就是把所有的块分解成的长度是一样的。示例代码如下:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("gpt-4")
text = "..." # 输入文本# 按Token数分块
tokens = tokenizer.encode(text)
chunk_size = 512
chunks = [tokens[i:i + chunk_size] for i in range(0, len(tokens), chunk_size)]
decoded_chunks = [tokenizer.decode(chunk) for chunk in chunks]优点:
- 实现简单:只需按字符/token数切割,无需复杂逻辑
def fixed_chunk(text, chunk_size=500):return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]- 计算可预测:每块大小一致,便于资源分配(如GPU显存管理)
- 适合规则文本:对日志文件、代码等结构化数据效果较好。例如:切割Apache日志文件时,每块固定500行。
缺点:
- 语义断裂风险:可能从句子/单词中间切断。
- 信息密度不均:某些块可能包含大量空白/无意义内容(如表格间隔区域)。
- 超长内容处理差:遇到无法分割的超长元素(如Base64编码图像)会直接截断。
适用场景:
预处理阶段快速分块
处理已知格式的机器生成文本(如CSV、JSON)
5.2 语义分块(Semantic Chunking)
句子分割:使用NLTK的
sent_tokenize或spaCy的句法分析。段落感知:检测
\n\n或Markdown标题(如## 章节)。
常用的语义分块工具对比如下:
| 工具 | 优点 | 缺点 |
| NLTK | 简单易用 | 对中文支持较弱 |
| spaCy | 支持多语言、精度高 | 需要预训练模型 |
| LangChain | 内置RecursiveTextSplitter | 依赖其他库 |
优点:
- 保持逻辑完整:按自然语言单位(句子/段落)分割。
- 提升模型理解:每个块是完整语义单元,减少歧义;有研究显示:语义分块使QA任务准确率提升15-20%。
- 自适应长度:根据内容密度动态调整(短段落→小块,长章节→大块)。
缺点:
- 实现复杂:需要NLP工具识别语义边界(如spaCy):
import spacy
nlp = spacy.load("zh_core_web_sm")
doc = nlp(text)
chunks = [sent.text for sent in doc.sents] # 按句子分割- 性能开销大:语义分析可能需要额外50%处理时间。
- 特殊格式干扰大:列表、代码块等非标准结构可能导致错误分割。
适用场景:
正式文档处理(论文、合同)
需要高精度语义保持的任务(如法律条款分析)
5.3 重叠分块(Sliding Window)
设窗口大小W=500,步长S=400,则重叠部分O=W-S=100。第n个块的起始位置:start_pos = n * S。可视化如下:
[块1: 0-500] [块2: 400-900] [块3: 800-1300]...优点:
- 上下文连贯:重叠部分保留关键信息。
- 降低边界效应:重要内容出现在块中间而非两端时,模型识别率更高。实验数据:重叠10-20%可使关键信息召回率提升30%
- 兼容其他策略:可与固定长度/语义分块结合使用。
缺点:
- 冗余计算:重叠部分被重复处理,增加10-25%计算成本。
- 存储膨胀:向量数据库中相同内容可能存储多次。
- 重叠量难确定:太少无效,太多浪费(需通过AB测试调整)。
适用场景:
问答系统(RAG)
长文档连贯性要求高的场景(如小说情节分析)
6、 分块(Chunk)的策略
6.1 动态分块(Dynamic Chunking)
规则示例:
代码文件:按函数/类分块(检测
def或class关键字)论文:按章节分块(识别"Abstract","Introduction"等标题)
实现库:
langchain.text_splitter支持多种文档类型(Markdown, HTML等)。
6.2 混合分块策略
组合方案:
先用语义分割器按段落分块
对过长的段落再用固定长度细分
from langchain.text_splitter import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200,separators=["\n\n", "\n", "。", " "]
)
chunks = splitter.split_text(text)6.3 分块质量评估
评估指标:
边界完整性:分块是否切断实体(如人名、公式)
语义一致性:使用句子嵌入余弦相似度检查块内一致性
7、 分块(Chunk)的注意事项
7.1 如何选择最佳分块大小?
采用不断实验方法:
在目标任务(如问答准确率)上测试不同尺寸(256/512/1024)
观察效果与成本的平衡点
7.2 分块导致关键信息丢失怎么办?
解决方案:
增加重叠:将
chunk_overlap从10%提升至25%关键信息复制:人工标注重要段落,确保它们出现在多个块中
7.3 处理非结构化数据(如PDF)的注意事项
特殊处理:
先提取纯文本(用
PyPDF2或pdfminer)处理换行符问题(PDF中的换行可能是排版而非语义分割)