从大数据视角理解时序数据库选型:为何选择 Apache IoTDB?

目录
- 一、什么是时序数据库?为什么你需要它?
- 🔧典型应用场景:
- 二、时序数据库选型维度有哪些?
- 三、为什么推荐 Apache IoTDB?
- 🧠 Apache 顶级项目,工业 IoT 场景原生支持
- 🚀 性能与压缩并重:写快、存省、查灵
- 🧩 接口友好,生态打通
- ⚙️ 插件化扩展 + 分布式能力
- 四、TimechoDB 企业版适合谁?
- 💼 企业级增强特性
- 🌐 典型落地场景
- 五、横向观察:开源 TSDB 海外趋势 & IoTDB 的生态位
- 六、写在最后:开源即力量,IoTDB 值得一试
一、什么是时序数据库?为什么你需要它?
随着万物互联、智能制造、工业互联网的迅速发展,企业正在被大量"连续变化"的数据包围——温度、湿度、电流、电压、价格、点击、调用日志、AI 模型状态…这些都是典型的时序数据(Time Series Data)。
时序数据库(TSDB) 专门用于存储、查询和分析这类以“时间戳”为主键的数据。相比传统数据库,它具备更强的数据压缩率、更快的写入速度,以及针对“时间维度”的聚合与查询优化能力。
🔧典型应用场景:
- 工业制造中的传感器采集系统
- 电力、水务、能源等行业的采集网关
- 互联网服务的调用日志、系统指标
- 金融系统中的价格与波动趋势
- AI 模型推理过程日志与 Token 消耗追踪
在这些场景中,数据量庞大、采集频率高、历史查询频繁,通用关系型数据库显然力不从心,需要一套专门的基础设施。
二、时序数据库选型维度有哪些?
在实际应用中,开发者和数据架构师在选择 TSDB 时,会优先考虑以下几个关键维度:
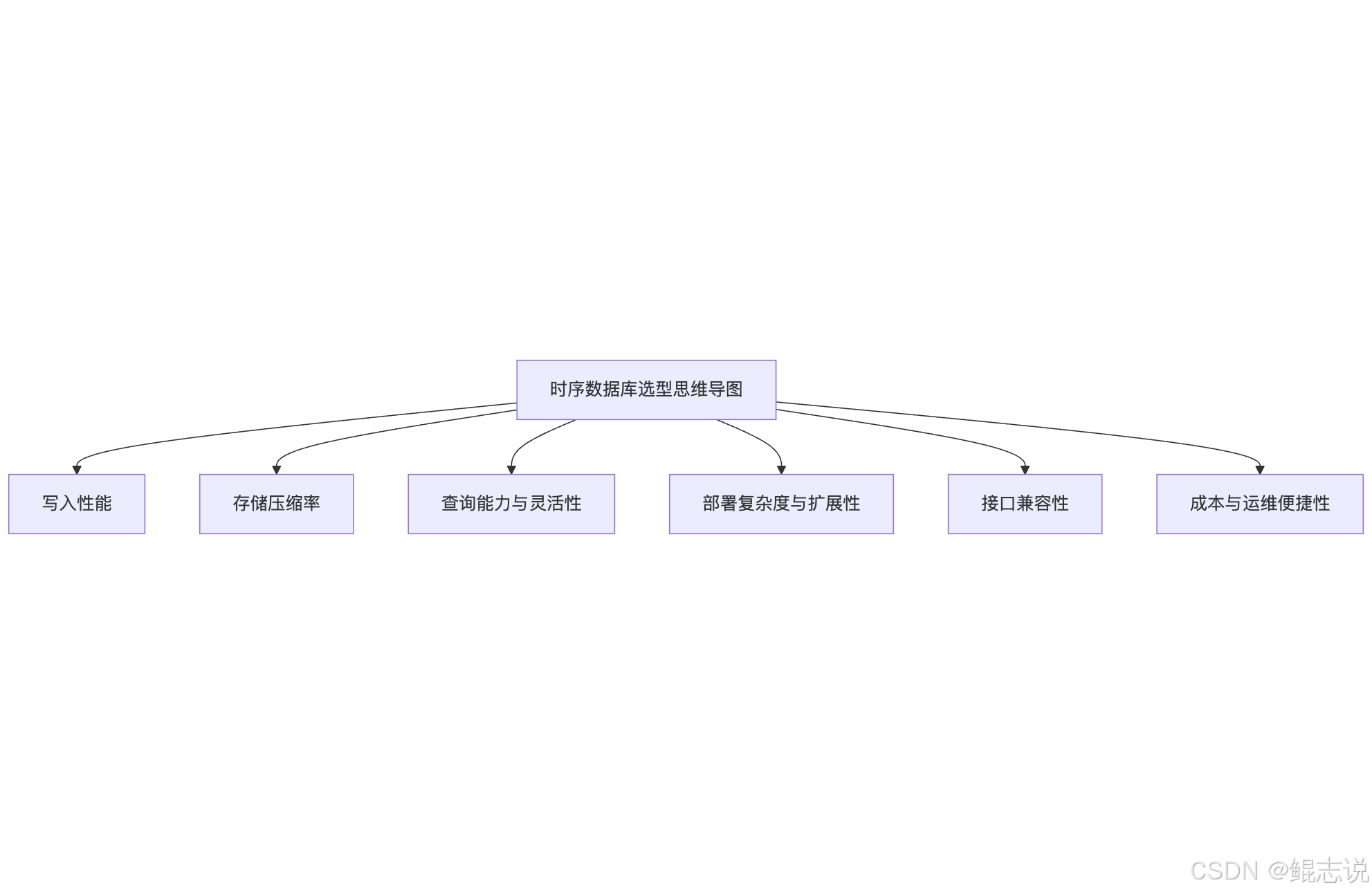
- 写入性能:是否支持百万级写入并发?是否能稳定支持高频数据采集?
- 压缩能力:长周期数据的压缩效率如何?是否支持自动清理与归档?
- 查询能力:是否支持 SQL 类语言?是否具备丰富的时序函数?
- 部署与扩展性:单机够用吗?是否能平滑迁移到分布式?
- 接口支持:是否支持 JDBC、REST API、Python SDK、Grafana 插件?
- 生态兼容性:能否与 Spark、Flink、Kafka 等大数据组件打通?
三、为什么推荐 Apache IoTDB?
🧠 Apache 顶级项目,工业 IoT 场景原生支持
IoTDB 是由清华大学主导研发的开源时序数据库,并于 2020 年正式成为 Apache 顶级项目。与通用 TSDB 相比,IoTDB 从一开始就为高频采集、大规模设备连接、嵌入式部署等工业 IoT 场景量身打造。
🚀 性能与压缩并重:写快、存省、查灵
- 支持 百万级写入 TPS(按设备+时间索引高效组织)
- 内置高压缩比的 TSFile 列式存储格式
- 原生支持 纳秒级时间戳精度
- 多种聚合、下采样、滑动窗口查询能力
🧩 接口友好,生态打通
- 兼容标准 SQL-like 查询语言(支持 GROUP BY、FILTER、ORDER)
- 提供 JDBC、REST API、Python/Node.js/Go SDK
- 原生适配 Grafana 插件,轻松可视化监控
⚙️ 插件化扩展 + 分布式能力
- 支持 用户自定义函数(UDF) 与 触发器机制
- 单机部署即可落地应用,平滑升级至分布式集群
- 分布式版本下 ConfigNode + DataNode 架构清晰,便于扩容与管理
四、TimechoDB 企业版适合谁?
如果你是企业用户,或正在面临大规模工业数据、生产级别稳定性需求,Timecho(IoTDB 企业发行版)提供了更成熟的配套方案:
💼 企业级增强特性
- 多副本机制与容灾能力
- 分布式权限管控与租户隔离
- 异常自动报警、可视化配置平台
- 混合部署与国产化平台兼容(支持国产 CPU)
🌐 典型落地场景
- 能源/电网公司:设备状态采集与告警联动
- 轨道交通:列车运行信息、车载数据
- 智能制造园区:设备联网、远程监测
- 智慧城市/园区:海量边缘设备协同
📝 企业官网:https://timecho.com
五、横向观察:开源 TSDB 海外趋势 & IoTDB 的生态位
当前国际上流行的时序数据库如 InfluxDB、OpenTSDB、Prometheus 等各有优势,但也存在:
- InfluxDB 商业闭源趋势明显,部署复杂
- Prometheus 偏指标监控,不适合工业/海量采集
- OpenTSDB 依赖 HBase,部署与运维门槛较高
相比之下,Apache IoTDB 保持开源纯净、架构轻量、部署简单、面向未来场景演进,非常适合国产化与私有化部署需求。
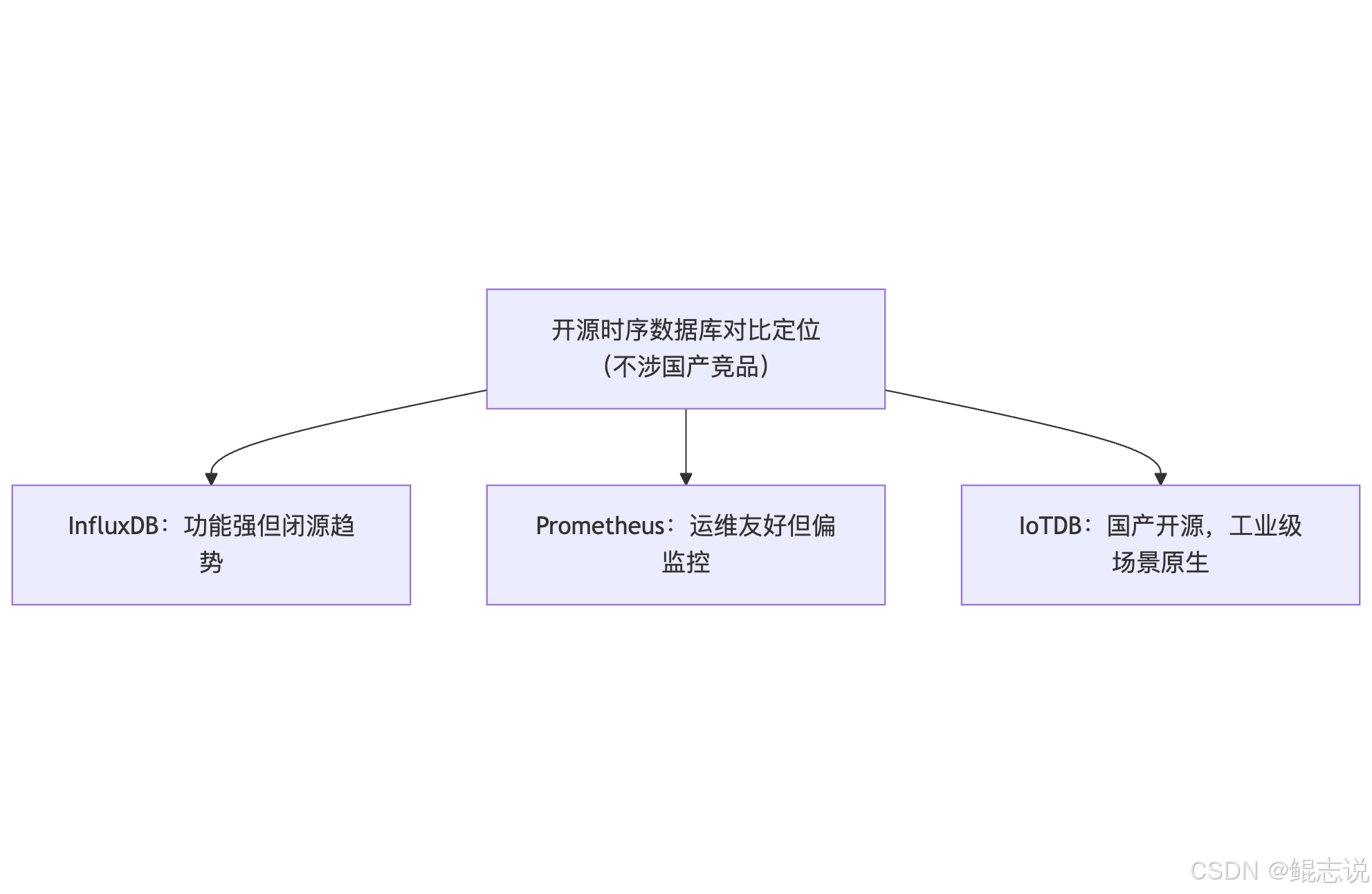
IoTDB 既可作为大数据平台中的底层存储引擎,也可作为时序分析的中间层,天然具备高度扩展性。
六、写在最后:开源即力量,IoTDB 值得一试
随着数据驱动业务的时代加速到来,选择一款合适的时序数据库,不再是纯粹的性能竞赛,而是兼顾部署、生态、灵活性、可持续性的发展战略选择。
Apache IoTDB 作为国内走向 Apache 社区的顶级项目,在保持技术先进性的同时,也不断拓展商业生态边界。
📥 下载链接:https://iotdb.apache.org/zh/Download/
🌐 企业版官网:https://timecho.com
无论你是想构建自己的设备数据平台,还是寻找更专业的时序存储解决方案,IoTDB 都是你值得一试的优选方向。