运维系统构建
在管理 300 台服务器 的运维体系中,Ansible、Jenkins 和 Zabbix 可以协同工作,形成一个 自动化、可观测、可编排 的运维闭环。以下是它们的分工和协作方案:
1. 三大工具的核心功能
工具 | 核心功能 | 适用场景 |
|---|---|---|
Ansible | 批量配置管理、自动化任务执行(无 Agent,SSH 或 API 驱动) | 批量部署软件、修改配置、服务启停、日志收集等 |
Jenkins | CI/CD 流水线、任务调度、自动化触发(与 Ansible 联动) | 定期巡检、定时任务、灰度发布、灾备演练等 |
Zabbix | 监控告警、性能指标收集、故障自愈(实时感知服务器状态) | 监控 CPU/内存/磁盘、服务可用性、自动触发告警或修复脚本 |
2. 协同运维架构
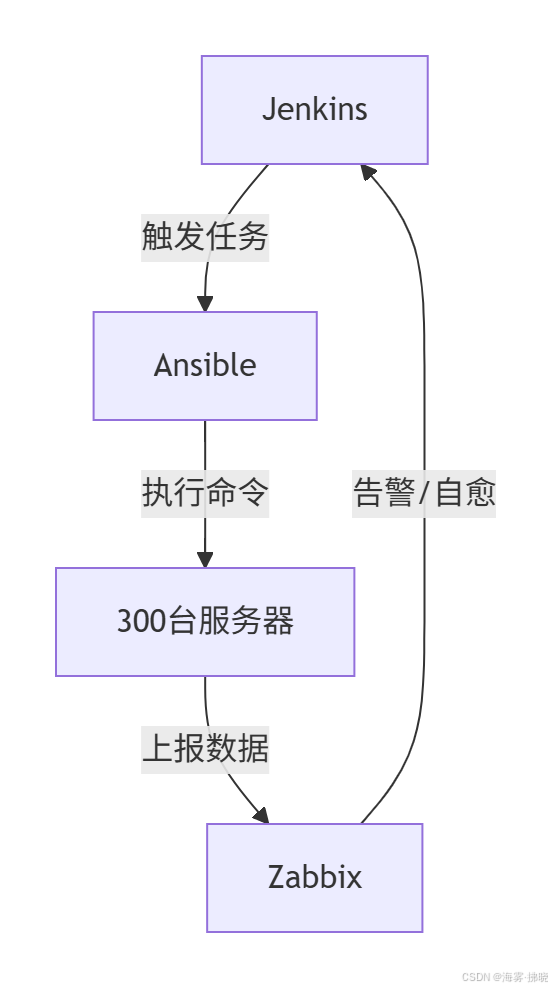
graph TD A[Jenkins] -->|触发任务| B[Ansible] B -->|执行命令| C[300台服务器] C -->|上报数据| D[Zabbix] D -->|告警/自愈| A
关键协作流程
配置管理(Ansible)
用 YAML Playbook 定义服务器状态(如安装 Nginx、配置防火墙)。
通过 Inventory 分组管理 300 台服务器(如按业务线、环境分组)。
示例:批量更新所有服务器的时区
- hosts: alltasks:- name: Set timezone to Asia/Shanghaitimezone:name: Asia/Shanghai
自动化调度(Jenkins)
通过 Jenkins Pipeline 调用 Ansible Playbook,实现:
定时任务(如每天凌晨清理日志)。
事件触发(如 Git 提交后自动部署)。
示例:每周巡检所有服务器
pipeline {agent anytriggers { cron('0 3 * * 1') } // 每周一凌晨3点stages {stage('Server Check') {steps {ansiblePlaybook(playbook: 'check_server_health.yml',inventory: 'inventory/production')}}} }
监控指标:
基础资源(CPU/内存/磁盘)。
服务状态(Nginx/MySQL 是否存活)。
告警规则:
当磁盘使用率 >90% 时,触发 Jenkins 执行 Ansible 清理脚本。
自动修复:
通过 Zabbix 的 Action 调用 Ansible API 重启服务。
3. 具体实施步骤
(1) Ansible 集中化管理
Inventory 分组:
# inventory/production [web] web[1:100].example.com ansible_user=deploy[db] db[1:50].example.com ansible_user=admin[all:vars] ansible_ssh_private_key_file=~/.ssh/ops_key
Role 复用:
使用
ansible-galaxy创建标准化角色(如nginx、docker)。
(2) Jenkins 自动化流水线
集成 Ansible:
安装 Ansible Plugin,直接在 Pipeline 中调用 Playbook。
关键场景:
发布流程:代码提交 → 测试环境部署 → 生产环境灰度发布。
灾备演练:定期通过 Jenkins 触发 Ansible 切换流量。
(3) Zabbix 监控与联动
自动发现:
用 Zabbix 的 自动注册 功能动态添加新服务器。
告警联动:
触发条件:Nginx 进程消失 执行动作:调用 Ansible Playbook 重启 Nginx
仪表盘:
展示全局健康状态(如 300 台中异常节点数量)。
4. 优势与收益
维度 | 效果 |
|---|---|
效率 | 手工操作减少 90%(如批量更新 300 台服务器仅需 1 条命令)。 |
一致性 | 所有服务器配置通过 Ansible 标准化,避免“雪花服务器”。 |
可观测 | Zabbix 实时监控,5 分钟内发现故障并触发告警。 |
可扩展 | 新增服务器只需加入 Inventory,无需重复配置。 |
5. 避坑指南
Ansible:
使用
ansible-lint检查 Playbook 语法。通过
--limit分组分批执行,避免同时操作 300 台导致 SSH 拥堵。
Jenkins:
设置 Pipeline 超时时间,避免长时间任务阻塞。
Zabbix:
优化触发器阈值,避免告警风暴(如使用聚合告警)。
通过 Ansible(配置) + Jenkins(调度) + Zabbix(监控) 的黄金组合,300 台服务器的运维工作将变得高效、透明且可回溯。