SupChains技术团队:需求预测中减少使用分层次预测(五)
文章出自:Stop Using Segmented Forecasting | Medium
本篇文章探讨了传统的分段预测方法的缺陷,并提出了SKU逐个优化和全球机器学习模型作为更有效的替代方案。文章的技术亮点在于强调了分段预测的复杂性和不准确性,指出了如何通过个性化模型选择提升预测准确性。
该方法适用于需要高准确度和灵活应对市场变化的场景,尤其是供应链管理和库存优化。
SupChains技术团队的相关文章还有:
- SupChains技术团队零售产品销量预测建模方案解析(一)
- SupChains技术团队回答:模型准确率提高 10%,业务可以节省多少钱?(二)
- SupChains团队: 衡量Forecast模型结果在供应链团队内的传递质量(三)
- SupChains团队:供应链数据的异常特征管理指南(四)
文章目录
- 1 需求预测的变革
- 1.1 什么是分层次及其用途?
- 1.2 分层次在预测中的缺陷
- 2 替代分层次的方法
- 2.1 方案一:基于 SKU-by-SKU 优化的统计预测引擎
- 2.2 方案二:全局机器学习模型
- 3 案例研究与实践应用洞察
- 3.1 SKU 优化案例
- 3.2 全局机器学习案例
- 4 结论
1 需求预测的变革
随着技术和数据分析的进步,需求预测正经历重大变革。传统且广泛使用的先对产品进行分层次,再对每个层次应用不同预测技术的方法,可能不再是最有效或最准确的方式。
本文首先探讨分层次方法的缺陷,然后介绍两种替代方案——统计优化引擎和机器学习,这些方法有望显著提升您的预测策略。
1.1 什么是分层次及其用途?
分层次是将元素根据共同属性或模式划分为不同类别的做法。供应链从业者常用此方法对产品进行分类。
SKU(库存单位)通常基于历史销售量、波动性或盈利能力等特征进行分组,比如传统的 ABC 或 ABC XYZ 分层次技术。分类产品本身并非坏事,但关键在于如何分类、何时复审以及分类的具体用途。虽然分层次可用于多种目的(如制定库存策略或客户/供应商评估),本文仅聚焦于利用分层次来设定预测模型。
在需求预测中,分层次可用于两项任务:
- 优先安排计划人员的工作和审核,注意不要用历史销量作 ABC,历史需求波动作 XYZ。
- 为不同层次分配特定预测模型(本文主题)。该方法基于假设同一类别内产品具有相似的需求特征,如趋势、季节性或偶发需求,因此可用相同模型预测,例如季节性移动平均法。此技术通过将 SKU 绑定到特定模型,硬性加速统计预测过程。
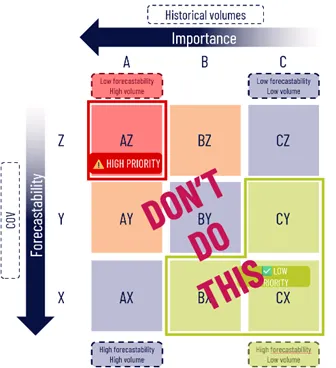
“ABC” 和 “ABC XYZ” 分别代表以下英文含义:- **ABC**: - A = **Always**(或有时解释为“最重要的”类别) - B = **Better**(中等重要类别) - C = **Common**(较低重要类别) 其实 ABC 分类主要是按产品价值或销售额划分,英文中常直接称为 **ABC Classification** 或 **ABC Analysis**。- **ABC XYZ**: - **XYZ**:按需求波动性划分,具体为: - X = **eXcellent predictability**(需求稳定,可预测性高) - Y = **Yielding some variability**(需求有一定波动) - Z = **Zero predictability**(需求高度波动,难以预测)因此,**ABC** 是基于价值的分类,**ABC XYZ** 是结合价值(ABC)和需求波动性(XYZ)两个维度的复合分类方法。
1.2 分层次在预测中的缺陷
尽管部分咨询公司和软件供应商支持分层次,但其缺点明显:
-
增加复杂性
对 SKU 进行聚类为预测流程带来额外复杂度。团队需决定最佳分层次方法(ABC、ABC XYZ 或基于机器学习的聚类)、确定分层次数量,并定期更新产品分配。此过程资源消耗大且难以长期管理,尤其是人员流动时。用机器学习(如 K-means)生成聚类还需选择和计算相关特征,且结果往往与简单 ABC XYZ 类似,特别是只用少数特征时。 -
分层次过于简化
作为简化工具,分层次无法准确反映单个 SKU 的需求行为。它假设同一分层次内所有 SKU 需求模式相似(趋势、季节性、促销敏感度),但需求受促销、定价、缺货、生命周期和节假日等多因素驱动,复杂且多变,难以归纳为少数类别。多数公司靠带偏见的人为判断或随意规则制定分层次和模型分配,且通常未做对比测试,导致准确度低。 -
准确度不足
评估预测模型质量的公平方法是与统计基准比较。遗憾的是,分层次或聚类策略常难以明显优于基准,难以证明其复杂性合理性。正如之前文章所示,预测准确度与业务价值(库存和服务水平)直接相关,而分层次技术无法带来提升。
鉴于复杂度提升、过度简化和准确率不足,分层次方法应被淘汰,转而采用更优预测方法。接下来,我们探讨两种替代方案:
- 统计预测引擎
- 全局机器学习模型
2 替代分层次的方法
本节介绍两种高效替代分层次预测的方法——使用统计预测引擎或全局机器学习模型。这些方法不仅提升准确度,还便于实施。
2.1 方案一:基于 SKU-by-SKU 优化的统计预测引擎
此方案是部署一个统计预测引擎,对每个 SKU 单独优化。引擎分两步操作:
- 先调优多个模型
- 再选出最佳模型
此法称为“最佳拟合选择”,即为每个 SKU 选出最合适的预测模型,考虑其独特需求特征。相比简化分层次法,此定制化方法能显著提升准确度。且最佳拟合仍可清晰解释预测结果,揭示趋势和季节性等因素。
季节性约束
许多企业面临因天气、节假日、业务周期、产品引入和促销引起的季节性波动。若能识别受季节影响的产品组,可限定优化引擎仅在季节模型中选择最佳模型。这类似于分层次但无其弊端,不是强制某个模型,而是在季节模型集合中选出最佳。
虽说部署预测引擎有吸引力,但供应链专业人士可能担忧计算时间和模型月度波动风险。以下为应对方法:
-
计算时间
三大实质性动作可显著缩短计算时间:- 高效编码:通过智能且优化的代码实现快速执行,能减少 100 倍以上计算时间。例如,2020 年协助客户实现每周 10 万条预测,几分钟内完成,无需云计算或并行处理。
- 并行处理:充分利用计算机资源,轻松提升 2 至 4 倍速度。
- 云计算:虽能加速,但复杂且昂贵,需专门团队实现。云计算无法弥补低效代码的性能瓶颈。
许多软件供应商仍用过时编码,导致性能缓慢,误导认为预测本质慢,从而错误支持分层次以加速。
-
模型波动
有人担心每月(或每周)对每个 SKU 优化会导致模型频繁变化,即模型波动。此问题可通过:- 鲁棒优化:用多期样本外验证和多指标确保模型选择稳定。
- 设定变更阈值:限制模型变更频率,避免无谓波动。
- 季节性约束:对季节性产品仅选季节模型。
实践中,模型波动投诉极少,表明此忧虑多为误解或配置不当。且即使固定模型,预测本身也会随新数据波动,正如名言:“事实变了,我也要变,你呢?”预测引擎需随事实更新。
2.2 方案二:全局机器学习模型
全局机器学习模型是另一更优替代方案。此类模型利用机器学习算法(或称 AI)从所有 SKU 中识别模式和关系。这里“全局”指模型学习整个数据集的共性模式,如“促销提升需求”或“过去需求增长趋势将持续”。优点是即使是新品或未促销产品也能较好泛化。
注意,全局模型不必学习产品间相互关系(如 A 产品需求增,B 产品增),除非显式告知。且全局模型不代表单一顶层预测,而是用单一模型生成细粒度预测。
建议避免“局部”机器学习模型,即为每个 SKU 单独训练模型。局部模型因数据量有限(单品数据点少)难以有效学习,效果往往不如简单方法。若供应商声称用机器学习,务必确认采用全局模型。
利用业务驱动因素
机器学习优势显著:
- 能捕捉传统方法忽视的复杂需求模式(季节性、趋势、周期),通常超越统计优化引擎。
- 即使数据有限,也能实现惊人准确度。
- 容易整合促销、价格、缺货和市场营销等多种业务驱动因素,通常新增驱动可降低 1% 至 5% 预测误差。
- 优化后模型几乎无需人工干预,自动运行。
破解黑箱疑虑
机器学习常被批评为黑箱,但可用模型解释技术破解:
- 特征重要性:树模型能计算输入特征(如业务驱动、历史订单模式)重要性。虽知促销重要,但不直接说明促销具体影响。
- 场景分析:通过对比不同业务场景(如有无折扣)预测,量化驱动因素影响。
最后提醒,机器学习非灵丹妙药。直接把需求数据丢进神经网络无效。需特征工程、模型选择和调优专业知识,否则难超越移动平均。
总结,SKU 优化和全局机器学习均为传统分层次的优良替代,带来更高准确度和流程简化。
3 案例研究与实践应用洞察
本节介绍上述替代方法的实际应用案例,展示它们在制造、医药分销等行业的成功,体现其广泛适用性和显著效益。
3.1 SKU 优化案例
许多软件厂商采用全局优化引擎。例如, SKU Science 平台即用此法,详见其 Ocean Spray 案例。SKU 优化适合大规模 SKU 组合,如 2020 年我们为一家在线零售商实现了 10 万条周预测,数据复杂且多季节性,短生命周期。
案例具体网址:
https://www.skuscience.com/customer-stories/ocean-spray/
Ocean Spray 缺乏将其销售团队的表现与统计预测进行比较的工具,导致预测准确性经常出现错误,并且由于缺乏比较指标,几乎没有改进的空间。
他们迫切需要提高预测准确性、降低库存水平并拥有可靠的 KPI 来跟踪其需求计划流程绩效。通过这样做,他们可以通过提高客户服务水平和减少体力劳动来节省资金。
3.2 全局机器学习案例
我在博客分享了多个行业的全局机器学习案例,预测准确度较统计基准提升 20% 至 30%
举一个例子:ML-driven forecasts for a manufacturer with promotions
ML
4 结论
总结,基于分段的供应链产品预测已显简陋和过时。本文介绍了两种强大替代方案:SKU 优化和全局机器学习模型。二者均承诺提升准确度、简化流程、具备良好适应性,适用于多行业和多种需求模式。
预测的未来属于这些先进模型。它们能学习复杂模式、随时间自适应并整合多业务驱动,带来显著收益。案例研究证明,无论制造、分销还是零售,这些方法均能大幅提升预测水平。
我们鼓励企业探索这些替代方案,重塑预测思路,提升准确率,优化流程。