vLLM:彻底改变大型语言模型推理延迟和吞吐量
大型语言模型 (LLM) 已经彻底改变了无数应用,从聊天机器人和内容生成,到代码助手和数据分析。然而,在生产环境中部署和服务这些庞然大物面临着巨大的挑战:巨大的计算需求、内存效率低下以及对闪电般快速响应的需求。vLLM 是一个开源库,它迅速成为高效 LLM 推理和服务的颠覆者。
在这篇详细的博客文章中,我们将探讨
- 是什么让 vLLM 如此强大?
- 深入研究其创新架构
- 了解为什么它是任何想要大规模部署 LLM 的人的首选。
- vLLM的Python代码实现
LLM 推理的瓶颈:传统方法为何不奏效
在深入探讨vLLM之前,让我们先了解一下它旨在解决的问题。传统的LLM服务通常面临两大障碍:
- 内存囤积和碎片化: LLM 依赖于“注意力机制”,该机制需要为每个生成的 token 存储一个“键值 (KV) 缓存”。此 KV 缓存会消耗大量的 GPU 内存。现有框架通常会为这些缓存分配连续的内存块,即使这些缓存并未得到充分利用,这会导致:
- 内部碎片:由于实际序列长度短于保留长度,导致分配块内的空间浪费。
- 外部碎片:已分配块之间未使用的间隙太小,即使总可用内存很大,也无法供新请求使用。这种内存浪费直接导致硬件成本上升和批处理大小减小。
- 低效的批处理(静态批处理):标准推理系统通常使用静态批处理,即将请求分组为固定大小的批处理并一起处理。问题在于,LLM 响应的长度是可变的。如果批处理中的一个序列提前完成,GPU 通常处于空闲状态,等待最长的序列完成之后再处理下一个批处理。GPU 资源的这种利用不足会导致:高延迟:用户会遇到延迟,尤其是在聊天机器人等实时应用程序中。吞吐量降低:即使硬件理论上具有容量,每秒处理的请求也更少。
这些限制使得大规模部署 LLM 既昂贵又低效,阻碍了生成 AI 的全部潜力。
核心技术:LLM服务的范式转变
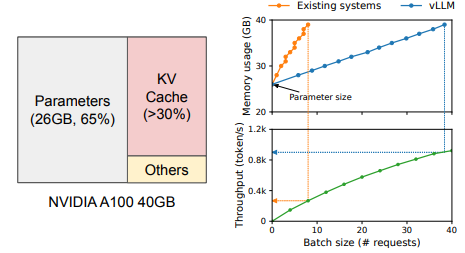
加州大学伯克利分校的研究人员开发的 vLLM 通过两项突破性创新解决了这些关键挑战:分页注意力和连续批处理。
1. 分页注意力机制:彻底改变 KV 缓存管理
受操作系统中虚拟内存和分页系统的启发,分页注意力机制重新构想了键值缓存的管理方式。与保留大块连续数据块不同,分页注意力机制具有以下特点:
- 将 KV 缓存划分为固定大小的“块”(页面):类似于操作系统管理内存的方式,KV 缓存被分解为更小、统一的块。
- 动态分配块:这些块仅在需要时按需分配,并且可以分散在 GPU 内存中。这完全消除了外部碎片。
- 有效管理内存共享:如果多个请求共享相同的前缀(例如,“告诉我有关[主题]的信息”),则分页注意力机制可以在所有请求之间共享该公共前缀的 KV 缓存块,从而显著减少内存重复。
分页注意力的影响:
- 大幅节省内存:通过几乎消除内存碎片并实现内存共享,vLLM 与传统方法相比,可实现高达90% 的键值缓存内存浪费减少。这意味着您可以将更大的模型加载到现有 GPU 上,或使用相同硬件处理更多并发请求。
- 更大的批次大小:通过更高效的内存利用率,vLLM 可以处理更大的批次大小,从而实现更高的吞吐量。
2. 连续批处理:最大化 GPU 利用率
分页注意力机制优化了内存,而连续批处理机制则优化了计算。与静态批处理不同,vLLM 的连续批处理机制会在请求到达并完成时动态处理它们:
- 迭代级调度: vLLM 无需等待整个批次完成,而是在模型前向传递的每次迭代中持续安排新请求或推进现有请求。
- 动态槽位填充:一旦序列完成生成令牌,其 GPU“槽位”就会变为可用。vLLM 会立即用新请求或当前批次中需要进一步处理的另一个序列填充此槽位。
连续批处理的影响:
- 更高的吞吐量:通过保持 GPU 持续忙碌并最大限度地减少空闲时间,连续批处理显著提高了 vLLM 每秒可处理的请求数量。基准测试通常显示,与 Hugging Face Transformers 相比,吞吐量高出 24 倍。
- 更低的延迟:新请求不必等待完整批次的累积,从而缩短响应时间,这对于交互式应用程序尤其重要。
- 提高 GPU 利用率:最大化资源,实现更具成本效益的部署。
超越核心创新:vLLM 的丰富功能集
vLLM 不仅仅涉及分页注意力和连续批处理;它是一个全面的 LLM 服务解决方案,包含为生产就绪而设计的功能:
- 与 OpenAI 兼容的 API 服务器: vLLM 提供了一个内置的 API 服务器,该服务器模拟了 OpenAI API 协议。这使得只需更改端点即可轻松将现有应用程序(使用 OpenAI 客户端构建)切换到使用自托管的 vLLM 实例。
- 广泛的模型兼容性:它与 Hugging Face Hub(Llama、Mistral、Gemma、Phi、Qwen 等)的大量流行开源 LLM 无缝集成,使其适用于各种用例。
- 优化的 CUDA 内核: vLLM 利用高度优化的自定义 CUDA 内核(如 Flash Attention 和 Flash Infer)通过减少开销和融合操作进一步提高 NVIDIA GPU 的性能。
- 多 GPU 和多主机支持:对于更大的模型或更高的工作负载,vLLM 支持在单台机器内的多个 GPU 上甚至在集群中的多台机器上分布模型和工作负载,从而实现大规模可扩展性。
- 量化支持:为了进一步减少内存占用并提高推理速度,vLLM 支持各种量化方法(FP8、INT8、AWQ、GPTQ、bitsandbytes),让您能够平衡速度和准确性。
- 动态 LoRA:支持动态低秩自适应 (LoRA),增强缓存,简化定制模型的部署和管理。
- 令牌流: vLLM 支持实时逐个令牌输出,这对于聊天机器人等交互式 AI 应用程序至关重要,可提供更流畅的用户体验。
- 前缀缓存(零开销): vLLM V1 中默认启用此功能,通过缓存这些前缀的 KV 缓存,可显著加快共享公共前缀的请求的推理速度,即使在较低的缓存命中率下,性能也几乎不会下降。
- 多模式性能增强:最近的版本对多模式模型进行了大量优化,包括预处理缓存和编码器缓存。
- 开发人员友好:
LLM尽管内部结构复杂,vLLM 仍为离线批量推理(通过类)和在线服务(通过命令)提供了简单的 APIvllm serve。 - 活跃的开源社区: vLLM 受益于充满活力和活跃的开源社区,确保持续改进、错误修复以及对新模型和功能的支持。
- 内存囤积和碎片化: LLM 依赖于“注意力机制”,该机制需要为每个生成的 token 存储一个“键值 (KV) 缓存”。此 KV 缓存会消耗大量的 GPU 内存。现有框架通常会为这些缓存分配连续的内存块,即使这些缓存并未得到充分利用,这会导致:
- 内部碎片:由于实际序列长度短于保留长度,导致分配块内的空间浪费。
- 外部碎片:已分配块之间未使用的间隙太小,即使总可用内存很大,也无法供新请求使用。这种内存浪费直接导致硬件成本上升和批处理大小减小。
- 低效的批处理(静态批处理):标准推理系统通常使用静态批处理,即将请求分组为固定大小的批处理并一起处理。问题在于,LLM 响应的长度是可变的。如果批处理中的一个序列提前完成,GPU 通常处于空闲状态,等待最长的序列完成之后再处理下一个批处理。GPU 资源的这种利用不足会导致:
- 高延迟:用户会遇到延迟,尤其是在聊天机器人等实时应用程序中。
- 吞吐量降低:即使硬件理论上具有容量,每秒处理的请求也更少。
这些限制使得大规模部署 LLM 既昂贵又低效,阻碍了生成 AI 的全部潜力。
核心技术:LLM服务的范式转变
加州大学伯克利分校的研究人员开发的 vLLM 通过两项突破性创新解决了这些关键挑战:分页注意力和连续批处理。
1. 分页注意力机制:彻底改变 KV 缓存管理
受操作系统中虚拟内存和分页系统的启发,分页注意力机制重新构想了键值缓存的管理方式。与保留大块连续数据块不同,分页注意力机制具有以下特点:
- 将 KV 缓存划分为固定大小的“块”(页面):类似于操作系统管理内存的方式,KV 缓存被分解为更小、统一的块。
- 动态分配块:这些块仅在需要时按需分配,并且可以分散在 GPU 内存中。这完全消除了外部碎片。
- 有效管理内存共享:如果多个请求共享相同的前缀(例如,“告诉我有关[主题]的信息”),则分页注意力机制可以在所有请求之间共享该公共前缀的 KV 缓存块,从而显著减少内存重复。
分页注意力的影响:
- 大幅节省内存:通过几乎消除内存碎片并实现内存共享,vLLM 与传统方法相比,可实现高达90% 的键值缓存内存浪费减少。这意味着您可以将更大的模型加载到现有 GPU 上,或使用相同硬件处理更多并发请求。
- 更大的批次大小:通过更高效的内存利用率,vLLM 可以处理更大的批次大小,从而实现更高的吞吐量。
2. 连续批处理:最大化 GPU 利用率
分页注意力机制优化了内存,而连续批处理机制则优化了计算。与静态批处理不同,vLLM 的连续批处理机制会在请求到达并完成时动态处理它们:
- 迭代级调度: vLLM 无需等待整个批次完成,而是在模型前向传递的每次迭代中持续安排新请求或推进现有请求。
- 动态槽位填充:一旦序列完成生成令牌,其 GPU“槽位”就会变为可用。vLLM 会立即用新请求或当前批次中需要进一步处理的另一个序列填充此槽位。
连续批处理的影响:
- 更高的吞吐量:通过保持 GPU 持续忙碌并最大限度地减少空闲时间,连续批处理显著提高了 vLLM 每秒可处理的请求数量。基准测试通常显示,与 Hugging Face Transformers 相比,吞吐量高出 24 倍。
- 更低的延迟:新请求不必等待完整批次的累积,从而缩短响应时间,这对于交互式应用程序尤其重要。
- 提高 GPU 利用率:最大化资源,实现更具成本效益的部署。
超越核心创新:vLLM 的丰富功能集
vLLM 不仅仅涉及分页注意力和连续批处理;它是一个全面的 LLM 服务解决方案,包含为生产就绪而设计的功能:
- 与 OpenAI 兼容的 API 服务器: vLLM 提供了一个内置的 API 服务器,该服务器模拟了 OpenAI API 协议。这使得只需更改端点即可轻松将现有应用程序(使用 OpenAI 客户端构建)切换到使用自托管的 vLLM 实例。
- 广泛的模型兼容性:它与 Hugging Face Hub(Llama、Mistral、Gemma、Phi、Qwen 等)的大量流行开源 LLM 无缝集成,使其适用于各种用例。
- 优化的 CUDA 内核: vLLM 利用高度优化的自定义 CUDA 内核(如 Flash Attention 和 Flash Infer)通过减少开销和融合操作进一步提高 NVIDIA GPU 的性能。
- 多 GPU 和多主机支持:对于更大的模型或更高的工作负载,vLLM 支持在单台机器内的多个 GPU 上甚至在集群中的多台机器上分布模型和工作负载,从而实现大规模可扩展性。
- 量化支持:为了进一步减少内存占用并提高推理速度,vLLM 支持各种量化方法(FP8、INT8、AWQ、GPTQ、bitsandbytes),让您能够平衡速度和准确性。
- 动态 LoRA:支持动态低秩自适应 (LoRA),增强缓存,简化定制模型的部署和管理。
- 令牌流: vLLM 支持实时逐个令牌输出,这对于聊天机器人等交互式 AI 应用程序至关重要,可提供更流畅的用户体验。
- 前缀缓存(零开销): vLLM V1 中默认启用此功能,通过缓存这些前缀的 KV 缓存,可显著加快共享公共前缀的请求的推理速度,即使在较低的缓存命中率下,性能也几乎不会下降。
- 多模式性能增强:最近的版本对多模式模型进行了大量优化,包括预处理缓存和编码器缓存。
- 开发人员友好:
LLM尽管内部结构复杂,vLLM 仍为离线批量推理(通过类)和在线服务(通过命令)提供了简单的 APIvllm serve。 - 活跃的开源社区: vLLM 受益于充满活力和活跃的开源社区,确保持续改进、错误修复以及对新模型和功能的支持。
vLLM 架构概览(V1 引擎)
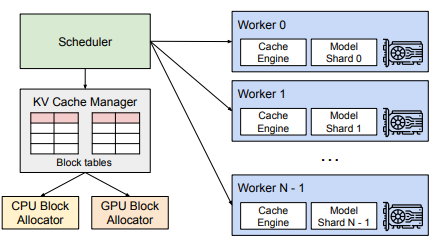
vLLM 高效的核心在于其 V1 引擎架构,该架构分离了关注点并优化了执行:
- AsyncLLM:一个异步包装器,用于处理与 OpenAI 兼容服务器的通信、提交请求和检索输出。它还管理标记化和去标记化。
- EngineCore:推理引擎的核心,负责调度请求、分配令牌以及执行模型的前向传递。它运行一个繁忙的循环,不断从内部队列中提取数据,并将结果推送到输出队列。
- 调度器: EngineCore 内部实现连续批处理算法的组件。它维护等待和正在运行的请求队列,并智能地决定在每个步骤中处理哪些请求,以在固定令牌预算内最大化 GPU 利用率。
- 模型执行器:协调跨多个 GPU 工作进程的模型加载和执行(通常利用 Ray 进行分布式计算)。
- 模型运行器:每个 GPU 工作器都有一个模型运行器,用于加载模型并执行前向传递、准备输入张量并利用 CUDA 图形捕获等优化。
- KV Cache Manager:负责管理 GPU 上的分页 KV 缓存的模块,根据需要为所有请求动态分配块。
这种模块化设计,特别是将 CPU 密集型任务与核心引擎核心隔离,允许更大程度的操作重叠,从而进一步提高吞吐量。
代码实现
首先,你需要安装 vLLM。建议在虚拟环境中进行安装。
pip install vllm transformers accelerate使用 LLM 类进行离线批量推理
from vllm import LLM, SamplingParams
import os
# --- Configuration ---
MODEL_NAME = "HuggingFaceH4/zephyr-7b-beta"
# If you're using a gated model (like Llama-2), you'll need to log in to Hugging Face
# via `huggingface-cli login` in your terminal or by setting the HF_TOKEN environment variable.
# os.environ["HF_TOKEN"] = "YOUR_HF_TOKEN"
# --- Define Sampling Parameters ---
sampling_params = SamplingParams(temperature=0.7, # Controls randomness. Lower for more deterministic, higher for more creative.top_p=0.9, # Nucleus sampling: only consider tokens that sum up to this probability mass.max_tokens=256, # Maximum number of tokens to generate per output.presence_penalty=0.1, # Penalize new tokens based on whether they appear in the text so far.frequency_penalty=0.1, # Penalize new tokens based on their frequency in the text so far.stop=["<|endoftext|>"] # Optional: define stop sequences
)
# --- Initialize the LLM Engine ---
print(f"Loading model: {MODEL_NAME}...")
llm = LLM(model=MODEL_NAME,dtype="auto",gpu_memory_utilization=0.9, # Adjust if you need to reserve GPU memory for other processesenable_lora=True, # Set to True if you plan to use LoRA adaptersmax_model_len=4096, # Adjust based on your model's context window and VRAM
)
print("Model loaded successfully!")
# --- Prepare Input Prompts ---
# A list of prompts to generate responses for.
prompts = ["Hello, my name is","The capital of France is","Write a short, creative story about a robot who discovers art.","Explain the concept of quantum entanglement in simple terms.",
]
# --- Generate Outputs ---
# vLLM's generate method is highly optimized for batch processing.
print("\nGenerating outputs...")
outputs = llm.generate(prompts, sampling_params)
# --- Process and Print Results ---
print("\n--- Generated Results ---")
for i, output in enumerate(outputs):prompt = output.promptgenerated_text = output.outputs[0].textfinish_reason = output.outputs[0].finish_reasonnum_prompt_tokens = len(output.prompt_token_ids)num_generated_tokens = len(output.outputs[0].token_ids)print(f"--- Prompt {i+1} ---")print(f"Prompt: {prompt!r}")print(f"Generated Text: {generated_text!r}")print(f"Finish Reason: {finish_reason}")print(f"Tokens (Prompt/Generated): {num_prompt_tokens}/{num_generated_tokens}")print("-" * 30)使用与 OpenAI 兼容的 API 服务器进行在线服务
步骤 1:打开终端并运行以下命令。这将下载模型(如果尚未缓存)并启动服务器。
python -m vllm.entrypoints.openai.api_server --model HuggingFaceH4/zephyr-7b-beta --port 8000 --host 0.0.0.0 --dtype auto步骤 2:查询 API 服务器(Python 客户端)
可以使用openaiPython 客户端库与 vLLM 服务器交互,因为它被设计为与 OpenAI 兼容。
from openai import OpenAI
import time# --- Configuration for vLLM API Server ---
openai_api_key = "" # vLLM's API server doesn't require an actual API key by default
openai_api_base = "http://localhost:8000/v1" # Replace with your server's IP if not local
# --- Initialize OpenAI Client ---
client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)
# --- Define a Chat Conversation ---
messages = [{"role": "system", "content": "You are a helpful and concise assistant."},{"role": "user", "content": "What is the primary function of the human heart?"},
]
# --- Define Sampling Parameters for Chat Completions ---
# These are passed in the `create` call.
generation_params = {"temperature": 0.7,"top_p": 0.9,"max_tokens": 100,"stream": True # Set to True for streaming responses
}
print(f"Sending request to vLLM server at {openai_api_base}...")
start_time = time.time()
# --- Send Request and Stream Response ---
try:response_stream = client.chat.completions.create(model=MODEL_NAME.split('/')[-1], # Use the model name portion onlymessages=messages,**generation_params)print("\n--- Streaming Response ---")full_response_content = ""for chunk in response_stream:if chunk.choices and chunk.choices[0].delta.content:print(chunk.choices[0].delta.content, end="", flush=True)full_response_content += chunk.choices[0].delta.contentprint("\n") # Newline after streamingend_time = time.time()print(f"\nTime taken for streaming: {end_time - start_time:.2f} seconds")# --- Example without streaming ---print("\n--- Non-Streaming Response Example ---")start_time_no_stream = time.time()response_no_stream = client.chat.completions.create(model=MODEL_NAME.split('/')[-1],messages=[{"role": "user", "content": "Tell me a fun fact about cats."}],temperature=0.8,max_tokens=50,stream=False)end_time_no_stream = time.time()print(response_no_stream.choices[0].message.content.strip())print(f"\nTime taken for non-streaming: {end_time_no_stream - start_time_no_stream:.2f} seconds")
except Exception as e:print(f"An error occurred: {e}")print("Ensure the vLLM API server is running at the specified address and port.")何时使用 vLLM?
vLLM 是各种 LLM 部署场景的绝佳选择,尤其是在以下情况下:
- 高吞吐量至关重要:需要满足大量并发用户请求(例如,聊天机器人、虚拟助手或大规模内容生成)。
- 低延迟至关重要:开发的应用程序需要 LLM 的快速响应(例如,实时交互式体验)。
- 成本效益是首要任务:希望最大限度地利用昂贵的 GPU 资源并降低硬件成本。
- 您是自托管 LLM:与使用第三方 LLM 服务相比,咱需要对数据隐私和模型定制有更多的控制权。
- 您正在使用开源 LLM:它与 Hugging Face 模型的广泛兼容性使其成为利用最新开源进展的理想选择。
结论
vLLM 代表了大型语言模型服务领域的重大飞跃。它通过创新的分页注意力机制和连续批处理机制,解决了内存管理和批处理方面的根本挑战,实现了前所未有的吞吐量和效率。其强大的功能集、易用性和活跃的社区使其成为希望在生产环境中部署强大且经济高效的 LLM 应用程序的开发者和组织不可或缺的工具。如果真的想大规模地实现 LLM,vLLM 无疑是工具包中不可或缺的库。