深度学习入门Day7:Transformer架构原理与实战全解析
一、开篇:注意力机制的全面进化
从昨天的基础注意力到今天的主角Transformer,我们正站在现代NLP革命的中心。2017年提出的Transformer架构不仅彻底改变了自然语言处理领域,更在计算机视觉、语音识别等多模态任务中展现出惊人潜力。今天我们将拆解这一划时代架构,并通过HuggingFace生态实现工业级应用。
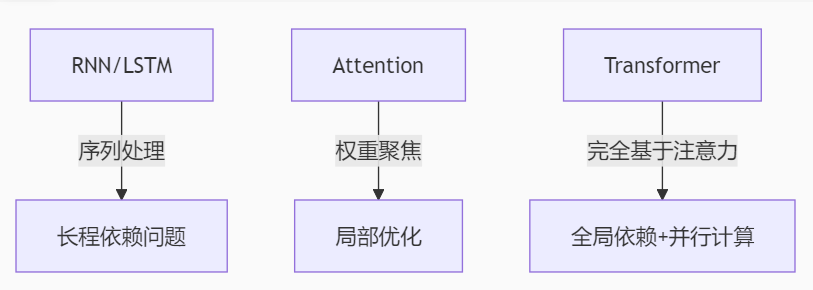
二、上午攻坚:Transformer核心原理
2.1 自注意力机制数学本质
Scaled Dot-Product Attention公式:
def attention(Q, K, V, mask=None):# Q/K/V形状: (batch_size, num_heads, seq_len, head_dim)d_k = Q.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)attn_weights = F.softmax(scores, dim=-1)output = torch.matmul(attn_weights, V)return output, attn_weights关键概念解析:
- Q (Query):当前关注点的表示
- K (Key):待检索项的表示
- V (Value):实际返回的信息
- 缩放因子 √d_k:防止点积过大导致softmax梯度消失
2.2 多头注意力实现
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.head_dim = d_model // num_headsself.W_q = nn.Linear(d_model, d_model)self.W_k = nn.Linear(d_model, d_model)self.W_v = nn.Linear(d_model, d_model)self.out = nn.Linear(d_model, d_model)def forward(self, Q, K, V, mask=None):batch_size = Q.size(0)# 线性变换 + 分头Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)K = self.W_k(K).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)V = self.W_v(V).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)# 计算注意力scores, attn_weights = attention(Q, K, V, mask)# 拼接多头结果concat = scores.transpose(1,2).contiguous().view(batch_size, -1, self.d_model)output = self.out(concat)return output, attn_weights2.3 位置编码可视化
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(1), :]位置编码特性:
- 使用正弦/余弦函数的组合
- 每个位置有唯一编码
- 能够泛化到比训练更长的序列
三、下午实战:HuggingFace生态应用
3.1 BERT文本分类实战
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments# 加载预训练模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 数据预处理
def encode_texts(texts, labels, max_length=128):return tokenizer(texts, truncation=True, padding='max_length', max_length=max_length, return_tensors='pt')train_encodings = encode_texts(train_texts, train_labels)
val_encodings = encode_texts(val_texts, val_labels)# 训练配置
training_args = TrainingArguments(output_dir='./results',num_train_epochs=3,per_device_train_batch_size=16,evaluation_strategy="epoch",save_strategy="epoch",logging_dir='./logs'
)trainer = Trainer(model=model,args=training_args,train_dataset=train_encodings,eval_dataset=val_encodings
)trainer.train()3.2 命名实体识别(NER)实现
from transformers import BertForTokenClassification# 加载NER专用模型
model = BertForTokenClassification.from_pretrained('bert-base-uncased',num_labels=len(tag2id), # 实体类型数量ignore_mismatched_sizes=True
)# 特殊处理子词标签
def align_labels_with_tokens(labels, word_ids):new_labels = []current_word = Nonefor word_id in word_ids:if word_id != current_word:current_word = word_idlabel = -100 if word_id is None else labels[word_id]new_labels.append(label)elif word_id is None:new_labels.append(-100)else:label = labels[word_id]new_labels.append(label)return new_labels3.3 注意力可视化分析
from bertviz import head_view# 可视化注意力
def show_attention(text):inputs = tokenizer(text, return_tensors='pt')outputs = model(**inputs, output_attentions=True)attention = outputs.attentionshead_view(attention, tokenizer.convert_ids_to_tokens(inputs['input_ids'][0]))show_attention("The cat sat on the mat")常见注意力模式:
- 位置关注:相邻token间强关联
- 句法关注:动词-宾语等语法关系
- 语义关注:同义词/反义词关联
四、晚上探索:Transformer变体宇宙
4.1 三大主流架构对比
以下为重新打印的格式化表格内容:
模型类型 | 代表 | 核心特点 | 适用场景
----------|------|----------|----------
Encoder | BERT | 双向上下文表征 | 分类/标注
Decoder | GPT | 自回归生成 | 文本生成
Seq2Seq | T5 | 编码器-解码器 | 翻译/摘要
4.2 Vision Transformer实现
from transformers import ViTModel# 图像分块处理
class ViTForImageClassification(nn.Module):def __init__(self, num_labels=10):super().__init__()self.vit = ViTModel.from_pretrained('google/vit-base-patch16-224')self.classifier = nn.Linear(self.vit.config.hidden_size, num_labels)def forward(self, pixel_values):outputs = self.vit(pixel_values=pixel_values)logits = self.classifier(outputs.last_hidden_state[:, 0, :])return logits4.3 模型优化技巧
混合精度训练:
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler()
with autocast():outputs = model(inputs)loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()梯度累积:
accum_steps = 4
for step, batch in enumerate(train_loader):outputs = model(**batch)loss = outputs.loss / accum_stepsloss.backward()if (step+1) % accum_steps == 0:optimizer.step()optimizer.zero_grad()五、学习总结与明日计划
5.1 今日核心成果
✅ 实现自注意力和多头注意力机制
✅ 掌握BERT微调流程(分类/NER任务)
✅ 可视化分析不同注意力头模式
✅ 了解Transformer三大变体架构特点
5.2 待解决问题
❓ 相对位置编码与绝对位置编码的优劣
❓ 稀疏注意力机制的实际应用
❓ 模型蒸馏(Knowledge Distillation)技巧
5.3 明日学习重点
- 生成对抗网络(GAN)基本原理
- 扩散模型(Diffusion)的渐进去噪过程
- 实现简单的图像生成模型
- 比较不同生成模型的特性
六、资源推荐与延伸阅读
1. The Illustrated Transformer:最直观的Transformer图解
2. HuggingFace课程:手把手学习现代NLP
3. BERT原论文:预训练革命的起点
4. Transformer家族图谱:全面了解各种变体
七、工程实践建议
1. 批处理优化技巧:
# 动态填充
tokenizer(texts, padding=True, truncation=True, max_length=512, return_tensors="pt")# 使用DataCollator
from transformers import DataCollatorWithPadding
collator = DataCollatorWithPadding(tokenizer=tokenizer)2. 模型保存与加载:
# 保存
model.save_pretrained("./model_save")
tokenizer.save_pretrained("./model_save")# 加载
model = BertModel.from_pretrained("./model_save")3. 推理优化:
# 使用ONNX Runtime加速
torch.onnx.export(model, inputs, "model.onnx")
ort_session = ort.InferenceSession("model.onnx")
outputs = ort_session.run(None, input_dict)下篇预告:《Day8:生成模型革命—从GAN到扩散模型》
将探索AI生成内容的魔法世界,并实现自己的图像生成器!