集合数据类型Map和Set
一. 基本概念与集合常见模型
概念:
- Map: 是一种键值对集合。它允许你使用任何类型的值(对象、函数、基本类型)作为键(key)来关联一个值(value)。Map 会记住键的原始插入顺序。
- Set: 是一种唯一值集合。它允许你存储任何类型的唯一值(对象、函数、基本类型)。每个值在 Set 中只出现一次。Set 也会记住值的原始插入顺序。
两种模型: - Key-Value 模型(键值对模型)
- 纯 Key 模型(唯一标识模型)
左侧为键值对模型,右边为唯一标识模型
二. Map的详解
Map是一个接口无法直接创建对象,因此要创建Map的集合类对象应用TreeMap或HashMap(Set 接口继承自 Collection,而Map不继承与Collection),并且Map采用的是键值对模型
1)TreeMap与HashMap
以key和value都是int为例的模拟实现
public class HashBuck {static class Node {public int key;public int val;public Node next;public Node(int key,int val) {this.key = key;this.val = val;}}public Node[] array;public int usedSize;public HashBuck() {array = new Node[10];}public void put(int key,int val) {int index = key%array.length;Node cur = array[index];//检查重复值while (cur != null) {if (cur.key == key) {//Set中无需更新值,但是哈希表会更新valcur.val = val;return;}cur = cur.next;}Node a = new Node(key, val);a.next = array[index];array[index] = a;usedSize++;//扩容机制if(loadFactor() >= 0.75) {resize();}}public double loadFactor() {// 固定公式,一般以0.75作为临界return usedSize*1.0 / array.length;}public void resize() {Node[] tmp =new Node[array.length*2];//!!!关键点,重新哈希(由于扩容,数组长度改变因此数据额位置改变)for (int i = 0; i < array.length; i++) {Node cur = array[i];//由于是链表加顺序表结构,因此要两层循环一层遍历链表一层遍历顺序表while (cur != null) {Node curNext = cur.next;int index = cur.key%tmp.length;//注意头插逻辑,易错易忘cur.next = tmp[index];tmp[index] = cur;cur = curNext;}}array = tmp;}public int get(int key) {int index = key % array.length;Node cur = array[index];while (cur != null) {if(cur.key == key) {return cur.val;}cur = cur.next;}return -1;}}
注意:
- TreeMap中的Key必须可比较否则会抛出异常(因为TreeMap的操作的实现多依赖于比较)
- HashMap的key是自定义对象( Java 内置的包装类(Integer、Double 等)不用)时必须同时重写 equals() 和 hashCode() 方法
2)注意事项
- Map中的Key是唯一的,不可以重复,但是value是可以重复的
- 当进行插入操作时出现了相同的Key,将进行更新操作(将key对应的value变为后插入的value)
- 当要对key进行修改时,只可以通过删除原数据后重新插入
- TreeMap的key不可以为null(因为TreeMap的操作依赖于比较,用null)
- HashMap 基于哈希表实现,其核心是通过键的 hashCode() 计算存储位置,不依赖键的排序或比较(当键为 null 时,HashMap 会将其哈希值固定为 0,并将其存储在哈希表的第 0 个桶)
三. Set详解
Set 接口继承自 Collection,其核心特性与 Map 的 “键(key)” 高度一致,并且Set采用的是唯一标识模型
1)TreeSet与HashSet
底层数据结构,有序性,对null的支持等性质与HashMap,TreeMap一致。
注意:
TreeSet 内部维护了一个 TreeMap 实例,并将所有元素作为 TreeMap 的 key 存储,而 TreeMap 的 value 则固定为一个静态常量(PRESENT,一个Object类)—— 这个 value 没有实际意义,仅用于占据 TreeMap 中 value 的位置,确保 key 的唯一性被利用
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E> {// 底层依赖的 TreeMapprivate transient NavigableMap<E, Object> m;// 固定的 value,所有元素共享(无实际意义)private static final Object PRESENT = new Object();// 构造器:初始化底层 TreeMappublic TreeSet() {this.m = new TreeMap<>(); // 默认使用元素的自然排序}public TreeSet(Comparator<? super E> comparator) {this.m = new TreeMap<>(comparator); // 使用自定义比较器}// 添加元素:本质是往 TreeMap 中 put 一个键值对(key 为元素,value 为 PRESENT)public boolean add(E e) {// TreeMap 的 put 方法会返回旧值:若 key 不存在,返回 null(添加成功);若已存在,返回旧值(添加失败)return m.put(e, PRESENT) == null;}// 其他方法(如 remove、contains)均委托给 TreeMap 的对应方法public boolean contains(Object o) {return m.containsKey(o); // 判断 TreeMap 中是否存在该 key}public boolean remove(Object o) {return m.remove(o) == PRESENT; // 移除 TreeMap 中对应的 key,判断是否成功}
}
2)注意事项
- Set 接口继承自 Collection而Map不继承与Collection接口
- Set常用于对集合元素去重(Map也可以做到,但仅有去重需求时Set仅有Key内存开销更小)
- 其余基本同Map一致
四. 二叉搜索树
二叉搜索树(Binary Search Tree,简称 BST)是一种特殊的二叉树,其核心特性是节点值的有序性,这使得它的查找、插入、删除等操作效率显著高于普通二叉树。它是许多高级数据结构(如红黑树、AVL 树)的基础,也是TreeMap、TreeSet等 Java 集合的底层实现基础(实际为平衡 BST)
对于任意节点 node:
- 其左子树中所有节点的值均小于 node 的值;
- 其右子树中所有节点的值均大于 node 的值;
- 左子树和右子树本身也必须是二叉搜索树
- 通常约定不存在值相等的结点
二叉搜索树的模拟实现:
public class BinarySearchTree {static class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int val) {this.val = val;}}TreeNode root = null;public boolean nodeSearch(int key) {TreeNode cur = root;while (cur != null) {if (cur.val > key) {cur = cur.left;}else if (cur.val < key) {cur = cur.right;}else {return true;}}return false;}public boolean insert(int key) {TreeNode cur = root;TreeNode parent = null;TreeNode a = new TreeNode(key);if (cur == null) {TreeNode root = a;return true;}while (cur != null) {if (cur.val > key) {parent = cur;cur = cur.left;}else if (cur.val < key) {parent = cur;cur = cur.right;}else {return false;}}if (parent.val > key) {parent.left = a;}else {parent.right = a;}return true;}public void remove(int key) {TreeNode cur = root;TreeNode parent = root;//循环找到要删除的结点while (cur != null) {if (cur.val > key) {parent = cur;cur = cur.left;}else if (cur.val < key) {parent = cur;cur = cur.right;}else {//删除逻辑单独处理removeNode(parent,cur);return;}}}public void removeNode(TreeNode parent,TreeNode cur) {//三种情况,三种情况内部又存在多种特殊情况//1.删除结点是叶子结点无左右子树if (cur.left == null && cur.right == null) {if (cur == root) {root = null;}else if (parent.val > cur.val) {parent.left = null;}else {parent.right = null;}//2.删除的结点有左右子树之一}else if (cur.left == null) {if (cur == root) {root = cur.right;}else if (parent.left == cur) {parent.left = cur.right ;}else if (parent.right == cur){parent.right = cur.right;}}else if (cur.right == null) {if (cur == root) {root = cur.left;}else if (parent.left == cur) {parent.left = cur.left ;}else if (parent.right == cur){parent.right = cur.left;}//3.删除的结点左右子树都存在}else {TreeNode targetParent = cur;TreeNode target = cur.left;//!!!!会出现特殊情况,即未进入循环while(target.right != null) {targetParent = target;target = target.right;}/*由于循环内:targetParent = target;target = target.right;正常情况下target为targetParent的右结点,但是如果没进入循环:TreeNode targetParent = cur;TreeNode target = cur.left;*///!!!两种易错情况cur.val = target.val;if (target == targetParent.left) {targetParent.left = target.left;} else {targetParent.right = target.left;}}}
}五. 哈希表
概念:
哈希表(Hash Table,也叫散列表)是一种通过键(Key)直接访问值(Value) 的数据结构,其核心特性是平均时间复杂度为 O (1) 的查找、插入和删除操作,这使得它成为计算机科学中效率最高的数据结构之一
注意:
- HashMap是哈希表的典型实现
- 哈希表的本质是用数组(连续内存空间)存储数据,但通过 “哈希函数” 将 “键(Key)” 转换为数组的索引,从而实现 “直接定位” 元素的效果
核心流程:
- 哈希函数(Hash Function):对键 key 进行计算,得到一个哈希值(整数),再通过取模等操作映射为数组的索引 index。
- 存储:将键值对 (key, value) 存储在数组的 index 位置
- 查找:通过相同的哈希函数计算 key 的索引,直接访问数组该位置获取值
底层逻辑:
数组 + 链表 / 红黑树(解决冲突)
1)哈希函数详解
哈希函数(Hash Function)是哈希表的 “核心引擎”,它负责将任意类型的键(Key) 转换为哈希值(Hash Value)—— 一个固定范围的整数,最终映射为哈希表数组的索引。
哈希函数的设计目标是减少哈希冲突(不同键映射到同一哈希值),同时保证计算高效。一个优质的哈希函数需满足以下条件:
1. 确定性(Deterministic)同一键必须始终计算出相同的哈希值。
2. 高效性(Efficient)计算哈希值的过程必须快速(时间复杂度为 O (1) 或 O (k),k 为键的长度),不能成为哈希表操作的性能瓶颈。
3. 均匀性(Uniform Distribution)哈希值需均匀分布在预设范围内(如 [0, capacity-1],capacity 为哈希表数组长度),避免集中在某一区间
2)哈希冲突
概念:
哈希冲突(Hash Collision)是哈希表(Hash Table)中常见的现象,指两个不同的键(Key)通过哈希函数(Hash Function)计算后,得到了相同的哈希值(Hash Value),导致它们需要映射到哈希表中的同一个位置
发生的原因:
哈希函数的作用是将任意长度的输入(键)映射到固定长度的输出(哈希值,通常对应哈希表的索引),
通常由于可能要存放的键的数量通常远大于哈希表的容量
1.冲突的避免
- 设计合理的哈希函数(见上方所述哈希函数设计规则)
- 负载因子调节
负载因子 = 哈希表中已存储的元素数量(size) / 哈希表的容量(capacity)
负载因子过低(如 0.1):哈希表容量远大于元素数量,空间浪费严重,但冲突率极低(几乎不会有多个元素挤在同一桶中),操作效率高(接近 O (1))
负载因子过高(如 1.0):哈希表容量接近元素数量,空间利用率高,但冲突率急剧上升(大量元素挤在同一桶中,链表 / 红黑树变长),操作效率下降(可能退化至 O (n))
注意:
- 负载因子的调节目标是:在可接受的空间开销下,最小化哈希冲突,保证哈希表的高效操作
默认负载因子是0.75(在统计意义上,能让哈希冲突的概率保持在较低水平(通过大量实验验证),同时空间浪费可控) - 由于储存数据不可改变,因此对负载因子的调节是对哈希表容量的调节

2. 冲突的解决闭散列
开放地址法(在哈希表内部解决冲突,也叫闭散列)和链地址法(在哈希表外部扩展空间解决冲突,也叫开散列)
- 当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去
- 如何找到“下一个”空位置?(二次探测的公式里的±常数是冲突发生的次数)

注意: - 闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷
- 不能直接删除元素(否则会导致后续探测的元素 “断链”),需标记为 “已删除”(逻辑删除),这会增加空间管理复杂度
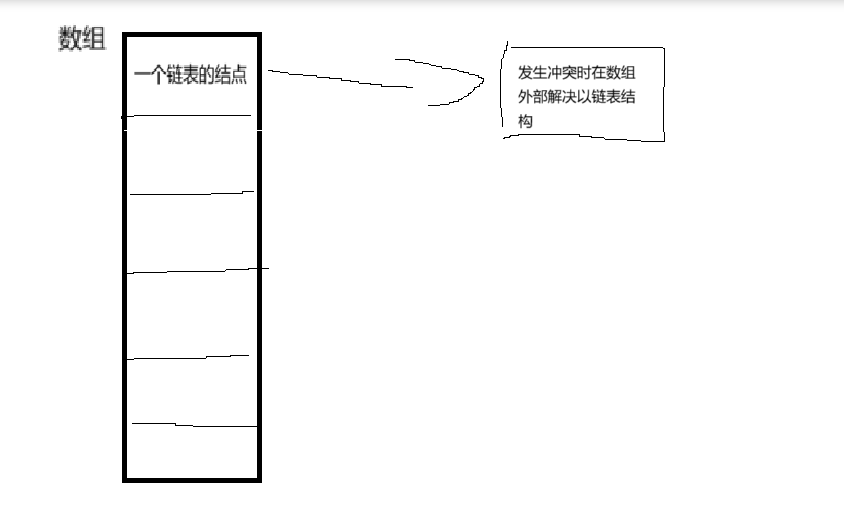
3.冲突的解决开散列
- 哈希表是一个大小为 m 的数组 table,每个元素 table[i] 是一个链表的头节点。元素 key 计算哈希地址 h(key) 后,直接插入到 table[h(key)] 对应的链表中(即数据加链表的结构)
- 元素存储在链表 / 树中,哈希表数组仅作为 “索引”,空间利用率更高(负载因子可大于 1),且不会产生闭散列的 “聚集现象
- 对数据进行操作时逻辑简单
- java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)
图例
3)注意事项
- 虽然哈希表一直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数,所以,通常意义下,我们认为哈希表的插入/删除/查找时间复杂度是
O(1) - Java 中计算哈希值实际上是调用的类的 hashCode 方法,进行 key 的相等性比较是调用 key 的 equals 方法。所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须覆写 hashCode 和 equals 方法,而且要做到 equals 相等的对象,hashCode 一定是一致的