【CVPR2025】Mr.DETR: 通过多路线训练机制改进DETR,并进行“one to one”和“one to many”的预测
CVPR 2025 Open Access Repository
作者单位是香港大学和美团
🥇概述
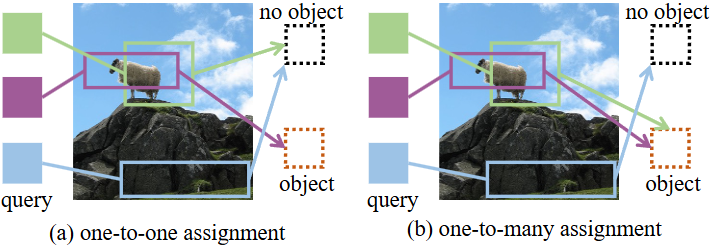
“one to one”顾名思义就是每个真实框对应一个单独的预测框,剩下的与任何对象无关的预测由背景进行监督。“one to many”是允许每个真实框可以与多个预测框匹配,这也是基于卷积的目标检测的常规操作。
文章指出现有方法通过结合辅助一对多分配来增强检测转换器的训练。作者将模型视为一个多任务框架,同时执行一对一和一对多的预测。因为他们研究了 Transformer 解码器中每个组件在这两个训练目标中的作用,包括自注意力、交叉注意力和前馈网络。结果表明,解码器中的任何独立组件都可以有效地同时学习两个目标,即使共享其他组件。这一发现使得作者提出了一种多路由训练机制,该机制具有一对一预测的主要途径和两个用于一对多预测的辅助训练路线。通过一种新颖的有指导意义的自我注意力来增强训练机制,该自我注意力动态地灵活地引导对象查询进行一对多预测。在推理过程中删除辅助路由,确保对模型架构或推理成本没有影响。
文章首先构建了一个多任务框架(一对一和一对多预测),结合实验验证transformer decoder中每个组件对一对一和一对多分配的作用,包括独立自注意力、交叉注意力和前馈网络,以研究哪些组件可以提高主要路线的性能。
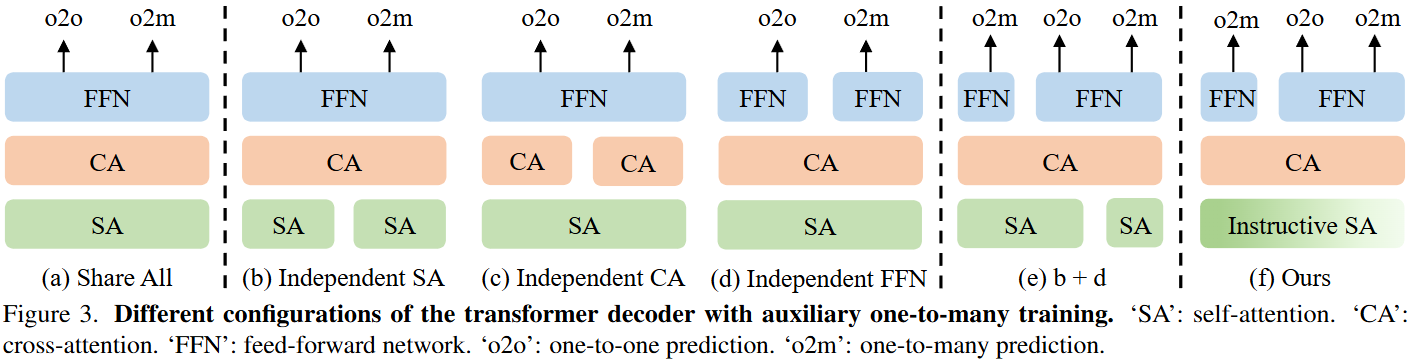
图(a)可以看出来最直接的方法是获得具有共享组件的两个任务的预测结果,但是在Table1中,当两个任务之间共享所有组件时,合并一对多分配会降低最初的一对一预测的性能。
图(b)-(d)是为两个训练目标构建了具有独立自注意力、交叉注意力和FFN的多任务框架去增强主路的性能(o2o),作者发现任何独立组件都显著有利于一对一预测的主路,那怕共享了其他组件,在Table1的(3)-(5)中。
文章构建了一个多路径训练机制,将多个辅助训练路径结合起来,每个辅助训练路径都有一个独立的组成部分。具体来说,主路用于一对一预测,而每条辅助路径具有不同的独立组件,用于一对多预测。在图3(e)中,分别使用独立自注意力和FFN将辅助训练与主路相结合。在Table1中对各组合的性能进行了实验验证。我们发现,当涉及具有独立交叉注意的辅助路由时,可能由于独立交叉注意力的缓慢收敛而降低了主路的性能。图3(e)中的组合优于其他变体。
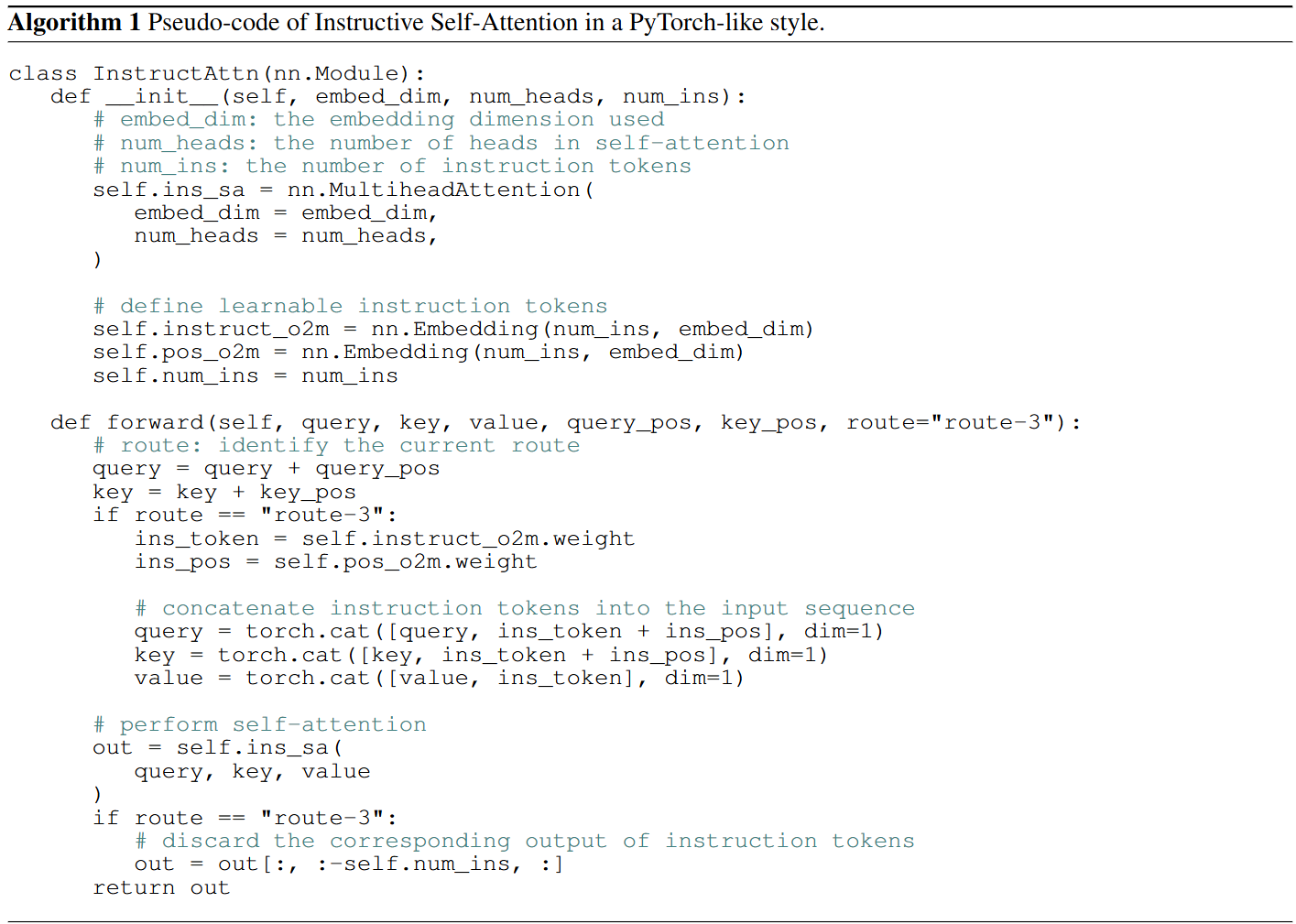
为了进一步减少辅助训练路线中新的可训练参数,并增强所有路线之间的参数共享,文章提出了一种新的有指导意义的自注意力机制,图3(f)。
文章提出的方法包括三条训练路线,一条用于一对一预测的主要路线,以及两条具有指导性自注意力和独立FFN的辅助路线。第一个辅助路线由与主路中的自注意力共享所有参数,它包含了一个可以学习的token,叫做指令token,附加到输入对象queries中的自注意力中了。
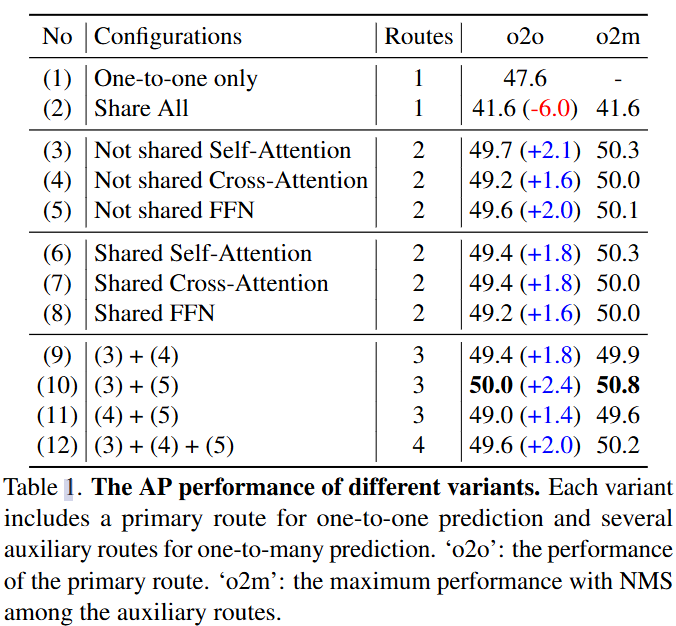
object queries和指令token一起进行自注意力的计算,使指令token能够指导查询进行一对多预测。考虑到FFN是一个简单的两层MLP,文章直接在第二个辅助路线中使用独立的FFN。在推理过程中,两条辅助训练路线被丢弃,保证了模型架构和推理时间与基线模型保持一致。
文章有三个贡献:
1、首先,在多任务框架中,文章通过经验证明,即使在共享其他组件的情况下,解码器中的任何独立组件都可以有效地同时学习一对一和一对多目标;
2、其次,在上述见解的基础上,文章提出了一种多路径训练机制,并通过所提出的指导性自注意力机制增强它,动态灵活地指导object queries进行一对多预测;
3、第三,在COCO 2017数据上进行了广泛的实验。
🥈方法
一句话概括就是将之前目标检测中的一对多匹配策略使用在基于DETR的目标检测器上。匹配分数是根据预测值
和真值
定义的:
![]()
🎑多路径训练
根据概述的这些发现,文章所提出的方法(多路径训练方法)包括三条训练路线。在三条路线中共享object queries、分类和回归头。route-2是一对一预测的主要路径,与基线模型相同。route-1和route-3是用于一对多预测的辅助训练路径,在推理过程中被丢弃。
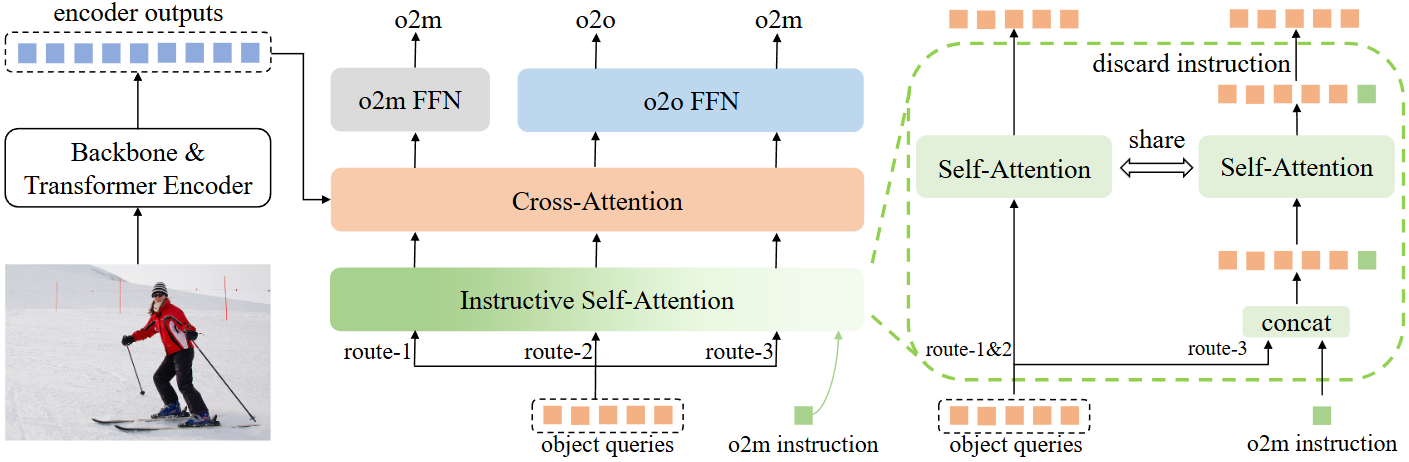
一对一预测的主路线,图中route-2的架构和训练目标与基线模型相同。具体来说,对于route-2,给定object queries ,那么query的输出就可以定义为:
![]()
式中SA、CA和分别代表自注意、交叉注意和FFN。route-2的查询输出中的由
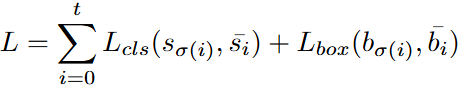 一对一分配监督。在推理过程中,保留route-2来实现一对一的预测,没有任何额外的开销。
一对一分配监督。在推理过程中,保留route-2来实现一对一的预测,没有任何额外的开销。
route-1是独立的FFN辅助路线,它的query输出可以写为:
![]()
route-3是具有指导性的自注意力机制的辅助路线,query输出可以写为:
![]()
🎨Instructive self-attention
route-3将可学习的指令token合并到object query Q中,创建一个组合序列
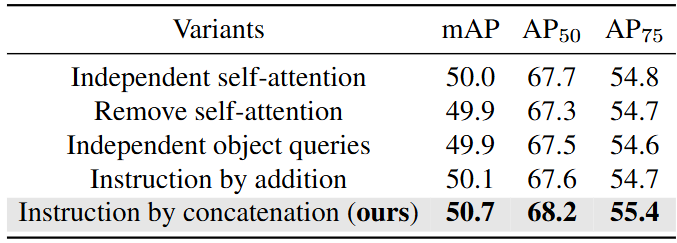
。如图(a)所示,最简单的方法包括使用一组单独的查询作为输入,以促进一对多预测。为了提高跨不同路由的object query的兼容性,作者引入了可学习的token作为指令,描绘预测目标。如图(b)所示,通过加法将这些指令token合并到共享object query中。这种方法需要与查询计数相等的固定数量的指令token。与加法方法不同,文章中使用的方法通过连接来调整指令object query,从而提供了更大的灵活性。如图(c)所示,这种灵活性不仅扩展到指令token的数量,而且还允许这些学习到的token通过自动态的将信息传递给object query。对组合序列进行自注意力计算,但是在自注意力之后,指示标记的相应输出被丢弃,因为它们不是用于对象定位的。
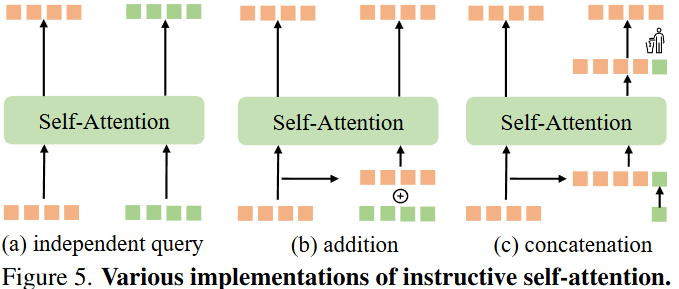
指令token就是文章构建的m个可学习的tokens,最初,这些指令令牌通过concat连接到自注意力机制的输入序列,形成一个输入查询的复合集
。随后,对这些组合查询执行自注意力计算。由于附加的指令token不用于对象定位,因此它们的输出在自注意力被丢弃,仅用于向对象查询传递信息。route-3的输出Q3写为:
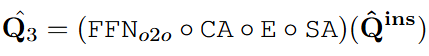
🎡实验
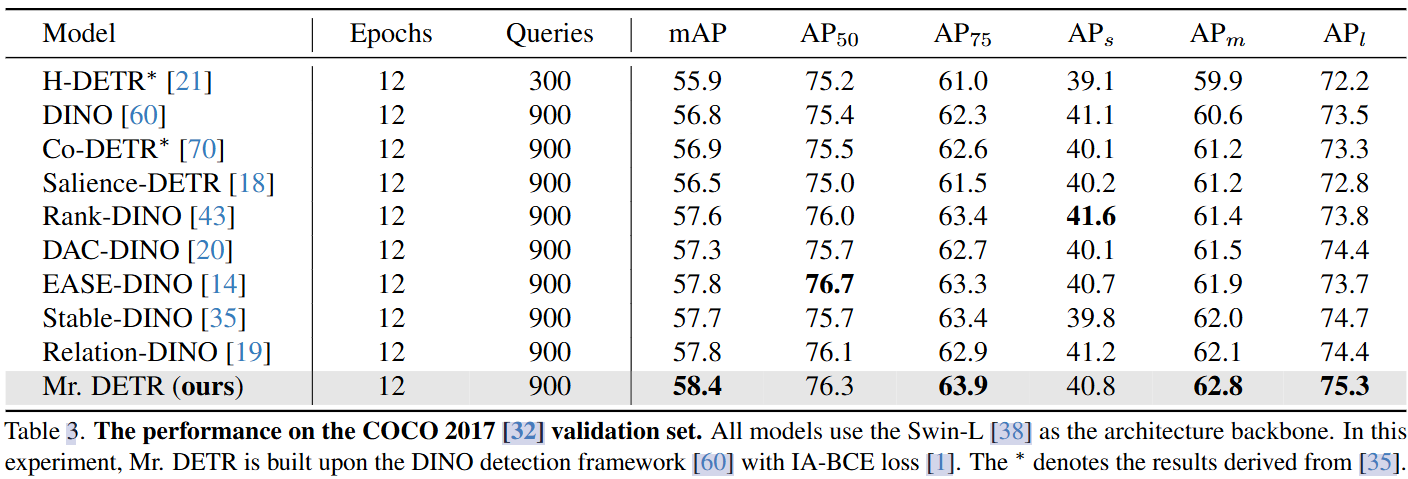
在COCO 2017进行了实验,以ResNet-50和Swin-L作为在ImageNet上预训练的主干进行了所有实验,采用和DINO和Deformable DETR一样的数据增强策略。
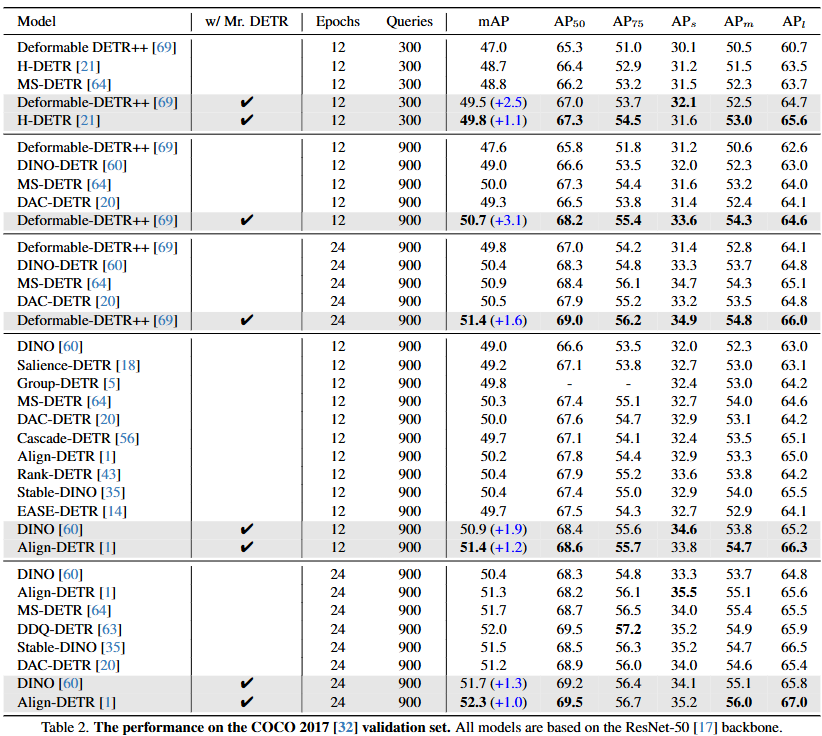

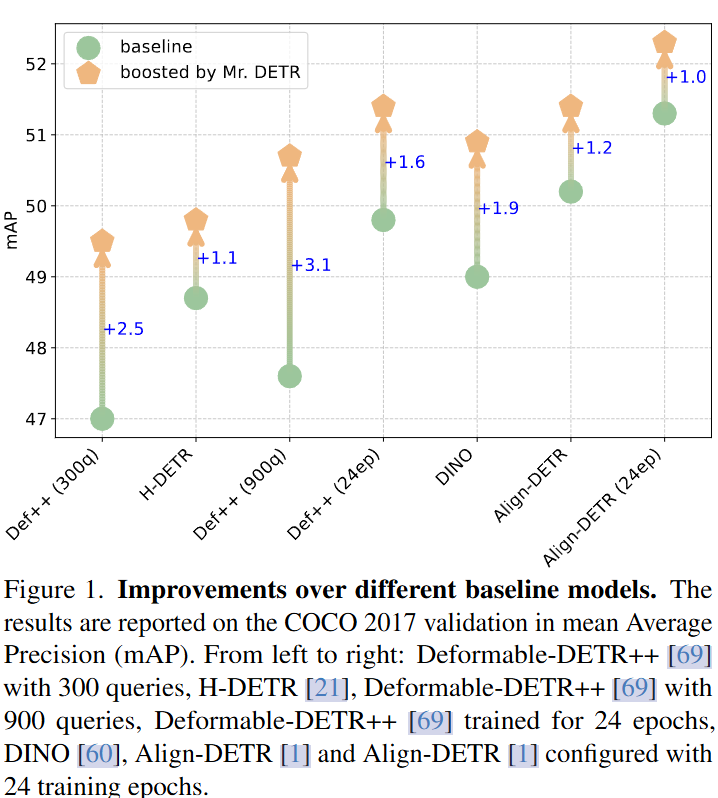
文章实验一致地展示了不同基线模型的改进。使用 Swin-L 主干的进一步实验,Mr.DETR表现出来了很不错的性能。
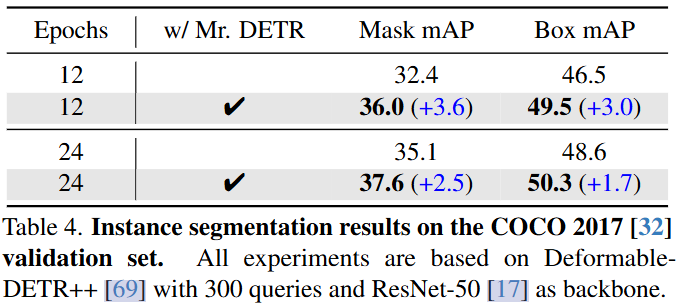
作者将该方法与实例分割任务的检测Transformer体系结构相结合。为简单起见,一对一和一对多分配都只考虑box和分类成本,这与检测Transformer是一致的。
一对一预测的主路线参数受益于一对多预测的辅助路线训练。使用文章提出的多路由方法训练 Deformable-DETR++,并在不同解码器层的引导自注意力中可视化注意力图。为了可视化,作者使用300个对象查询并设置10个指令token。下图也显示显示,当300个对象查询作为查询,10个指令token作为键时,几乎所有300个对象查询都表现出强烈的指令token激活。这表明指令token有效地将信息传递给对象查询和随后的网络层,帮助模型实现一对多预测。

为了评估每个辅助路线的贡献,作者进行了消融研究。具有独立FFN的route-1将基线模型的mAP提高了2.0%。实验结果表明,route-3比Deformable-DETR++提高了2.8%[69],突出了文章提出的指导性自注意力机制的有效性。

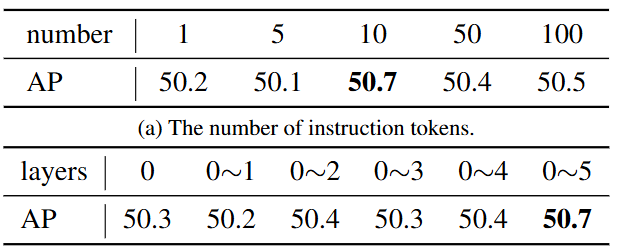
为了进一步减少route -3中的可训练参数,并增强与主路的参数共享,作者引入了指令机制。在下表中,评估了指令机制不同设计的性能。
文章还探讨指令token的不同配置。检查了改变指令token数量的影响,如表a所示。结果表明,性能随着指令token数量的增加而提高。接下来,在表b中研究跨不同解码器层合并指令token的效果。实验结果表明,当所有层都使用指令token时,可以获得最佳性能。各层的指令token对引导对象查询向一对多目标查询有很大的帮助,文章根据经验将其数量设置为10。