[AI]从零开始的SDXL LORA训练教程
一、前言
在前面的文章内容中,教了大家如何安装ComfyUI并且进行最基本的出图操作,相信大家在使用的过程中一定也遇到了一些问题,比如提示词无法识别,或者是画不出自己想要的角色等等。遇到这样的情况,我们就需要对原本的绘图模型进行微调。目前比较常见的大模型微调办法就是LORA,我们可以通过相对较少的数据集,相对较少的硬件占用和相对较少的训练时间训练出我们想要的角色或者画风。那么本次教程,就来教大家如何从零开始训练一个LORA吧!
二、声明
我并不是SD绘图方面的专家,也没有对SD的大模型有专业研究,文章中部分内容可能源于我的个人理解,如果出现不准确的地方还请指正。本次教程并不注重原理,主要想教大家的是如何快速调出自己想要的LORA。
三、资料的准备
本次教程中会使用到的模型与训练时使用的图片我都会教大家如何下载与制作,当然,如果你不想去网络上下载模型,想直接体验LORA的训练,可以通过下方的链接下载我准备的资料:
链接: https://pan.baidu.com/s/1ADCN6Py64lfeoDeDkPyhfg?pwd=clxm 提取码: clxm
下载完资料以后就可以进行下面的步骤了。
四、训练前的准备
在训练LORA之前,我们需要进行一些训练环境的准备以及图片的预处理,这里大致分为下面几个步骤,训练底模的下载,训练环境的搭建以及训练数据集的准备。
1.训练底模的下载
我们目前在画图领域使用较多的模型是SD1.5 与SDXL1.0,随着技术的迭代,许多大佬使用SDXL模型训练出了基于不同风格以及不同优化的大模型。对此,我们可以直接在SDXL底模的基础上训练LORA,也可以在大佬们已经训练出的大模型上继续训练,但是请注意一点,如果你在某个大模型上训练了LORA,这个LORA可能就只在这个大模型上表现得比较好,虽然底层都是基于SDXL,但仍然会出现一些细微的差距。本次我们的训练就基于SDXL1.0模型进行,往后只要是训练SDXL的模型都可以看本次教程。下面来教大家如何下载SDXL1.0模型,这里我们可以直接在浏览器中搜索“hf-mirror”:
这里我们搜索到的第一个就是模型网站了,当然,你也可以点击下方的链接进入:
hf-mirror:HF-Mirror
因为这是Hugging face的镜像站,不需要代理也能打开。进入以后,就可以看到下面的界面了:
我们可以直接在上方的搜索框中搜索“stabilityai/stable-diffusion-xl-base-1.0”:
输入并回车以后就可以看到以下界面了:
这里搜到的第一个就是我们需要的SDXL1.0模型了,我们点击进入。
进入以后,可以看到以下界面:
随后我们点击界面上方的“Files and versions”:
点击以后可以看到以下界面:
往下滑就能找到我们想要的模型了:
点击了要下载的模型以后,我们就可以看到下面的界面,我们点击download下载模型:
点击下载以后过一会儿浏览器就会弹出下载了:
模型下载完成以后如图所示:
这里我们的模型随便放一个路径就行,后面我们再进行处理。
如果你下载了我给的资料,那么这个模型被放到了资料文件夹下的“模型”文件夹中:
至此,我们的底模就下载完成了。
2.VAE转码模型的下载
VAE在我们画图是作为编解码器使用,在编码时,VAE将RGB图片转换到潜空间向量,在解码时VAE将潜空间向量转换为RGB图片。在模型训练时也一样,我们需要借助VAE将图片转换到潜空间向量模型才能进行学习。SDXL底模内置了fp32的VAE,我们可以不外置VAE直接训练,但是fp32的训练对于一些性能不是那么超前,显存不是那么大的显卡来说是非常困难的,训练不仅缓慢,还可能直接训练失败。所以,为了进行fp16精度训练,我们需要为我们的模型外置一个fp16的VAE编解码器。
这里我们同样在“hf-mirror”搜索“madebyollin/sdxl-vae-fp16-fix”,搜索结果如图所示:
这里我们直接进入第一个即可,进入以后,可以看到以下界面:
这里我们点击“Files and versions”:
点击以后,可以看到以下界面:
我们这里要下载的是“sdxl.vae.safetensors”:
点击了要下载的模型以后,我们就可以看到下面的界面,我们点击download下载模型:
过一会儿浏览器就会弹出下载了:
下载完成以后,如图所示:

如果你下载了我的资料,VAE模型被放到了资料文件夹下的“模型”文件夹:
至此,我们的VAE转码模型就下载完成了。
3.SD-Trainer部署
这里我们的LORA训练框架为了方便使用的是“秋葉aaaki”的“SD-Trainer”整合包,后面的训练操作都是基于“SD-Trainer”进行的,所以这一步非常关键。
我们点击下方链接来到SD-Trainer的Github主页:
SD-Traine:Akegarasu/lora-scripts: SD-Trainer. LoRA & Dreambooth training scripts & GUI use kohya-ss's trainer, for diffusion model.
打开以后,可以看到下面的界面:
随后我们点击右上角的“code”:
然后点击“HTTPS”:
我们直接复制这里的克隆链接即可:
然后我们打开终端使用“git clone”命令把项目克隆下来:
git clone https://github.com/Akegarasu/lora-scripts.git如果克隆失败,可以使用下方的命令配置一下代理:
git config --global http.proxy http://192.168.112.22:7890
git config --global https.proxy http://192.168.112.22:7890项目克隆下来得到以下文件夹:
 如果你下载了我的资料,那么这个文件夹被放到了资料文件夹下的“SD-Trainer”文件夹下:
如果你下载了我的资料,那么这个文件夹被放到了资料文件夹下的“SD-Trainer”文件夹下:
至此,我们的“SD-Trainer”就获取完成了。
这里我们运行项目需要使用到python或者python的虚拟环境,因为整合包在被创建时会在项目目录下新建一个venv虚拟环境,所以这里不用担心自己的环境乱了。如果你还不会安装python或者python的虚拟环境,可以看下面的文章,注意这里我们安装python时需要3.10版本:
python的安装:[python]我们应该如何正确的安装和卸载python?(详细)_windows python安装与卸载-CSDN博客
miniconda虚拟环境安装:[python]我们应该如何安装Miniconda虚拟环境?(详细)_miniconda创建虚拟环境-CSDN博客
当我们装好python或者python的虚拟环境以后就可以进行下面的步骤了,这里我使用miniconda进行演示,这里我们使用下面的命令新建conda虚拟环境:
conda create -n SD-Trainer python=3.10虚拟环境创建完成以后,执行下面的命令进入虚拟环境:
conda activate SD-Trainer进入虚拟环境以后,我们执行项目目录下的依赖安装脚本安装“SD-Trainer”所需的依赖:
./install.ps1执行以后,依赖安装脚本就会自动创建一个venv虚拟环境,并且在这个环境中安装库:
如果你被提示该文件没有数字签名,无法执行时,执行下面的命令临时放宽策略:
Set-ExecutionPolicy Bypass -Scope Process -Force如果安装时出现了网络引起的错误,则使用下面的安装脚本:
./install-cn.ps1依赖安装脚本会自动从网络上下载python包并且安装到venv虚拟环境中。可能需要一些时间。
依赖安装完成以后,脚本会提示我们已经安装完成了:
安装完成以后,我们执行项目目录下的“run_gui.ps1”脚本即可启动WebUI了:
./run_gui.ps1运行以后,脚本会自动启动WebUI并帮我们打开。
只要WebUI自己启动了就说明我们的“SD-Trainer”部署成功了。后面我们数据集的制作与训练都会在这个WebUI进行。
4.数据集的准备
完成了上面的步骤,我们就可以来准备我们用于训练的数据集了。SDXL LORA的训练特别是对于动漫人物的训练,并不需要多少数据集,20-40张就差不多够了。我们需要对这些图像进行统一处理,比如将图片分辨率裁剪为一样的,将ARGB的图片转换为RGB以及为图片的打标。当然,本次教程只讲如何训练LORA,后面诸如训练参数的调整以及训练数据集的优化我们放到下一篇教程再讲。
这里我以“原神”中的“若娜瓦”为例,首先,我们需要在“SD-Trainer”的项目目录下新建一个名为“dataset”的目录,用于存放我们训练需要使用到的数据集:
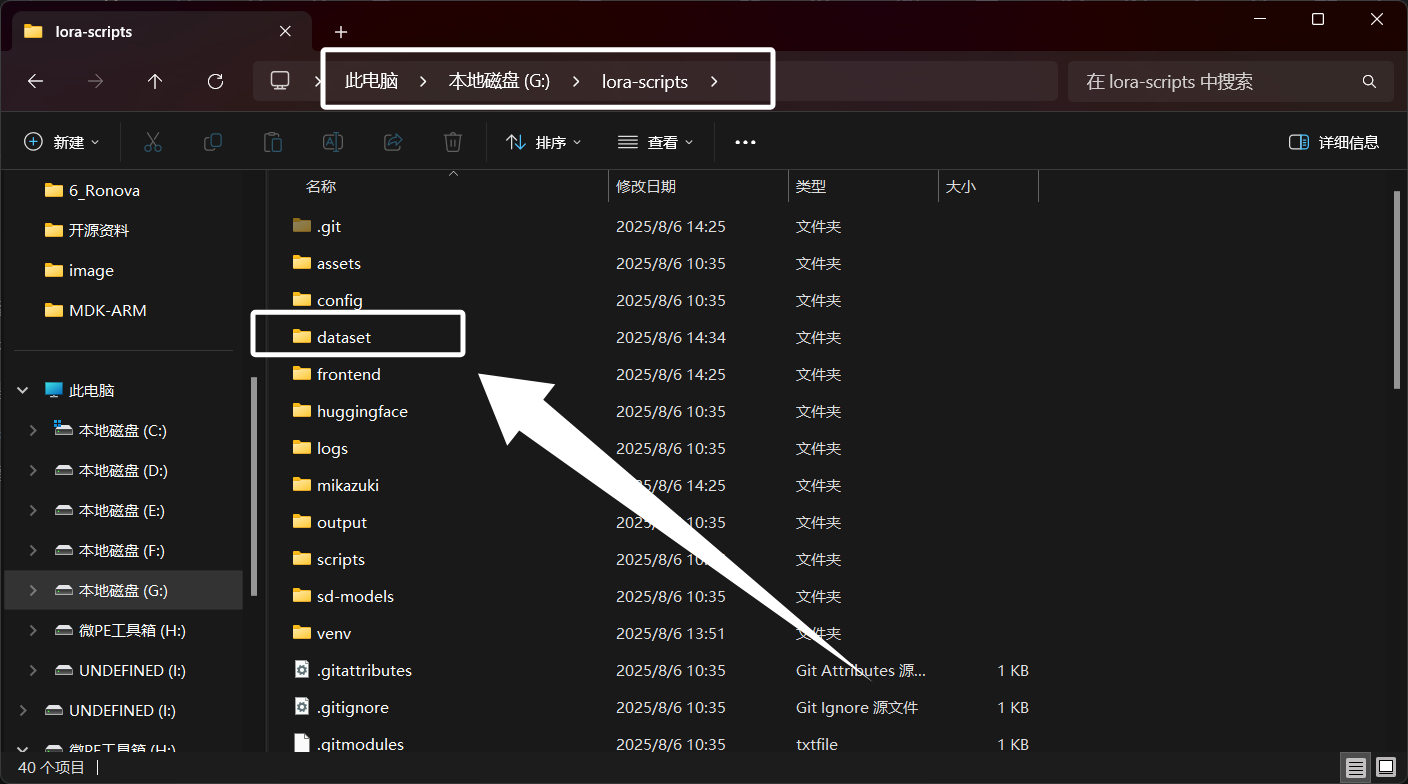
然后我们在“dataset”目录中新建一个用角色英文名命名的文件夹,表示我们要训练这个角色的LORA,后面也会将训练数据集以及训练结果都放到这个文件夹中:
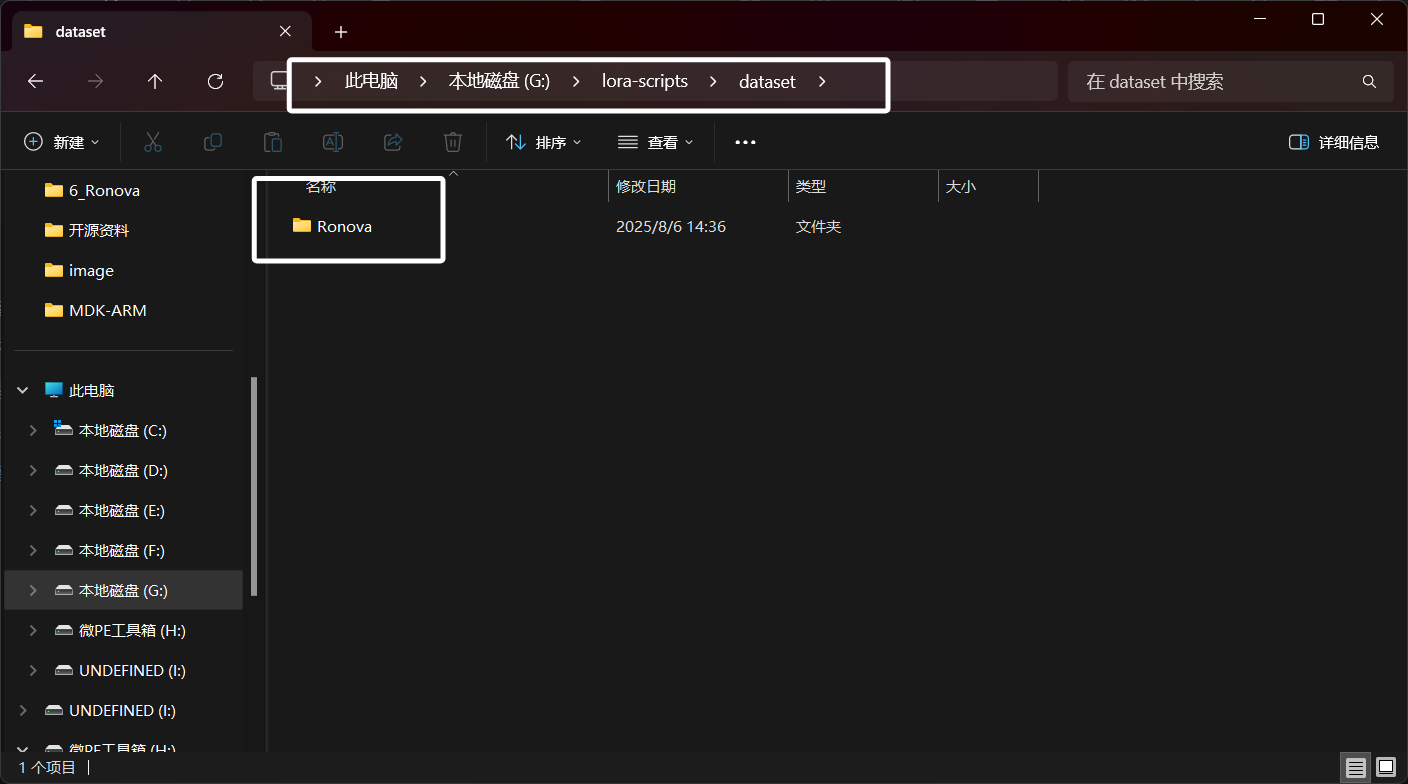
因为这里“若娜瓦”的英文名为“Ronova”,所以我这里文件夹也叫“Ronova”。
完成以后,我们在“Ronova”文件夹下新建一个文件夹名为“image”,这个文件夹用于存放我们找到的与这个角色相关的图片:
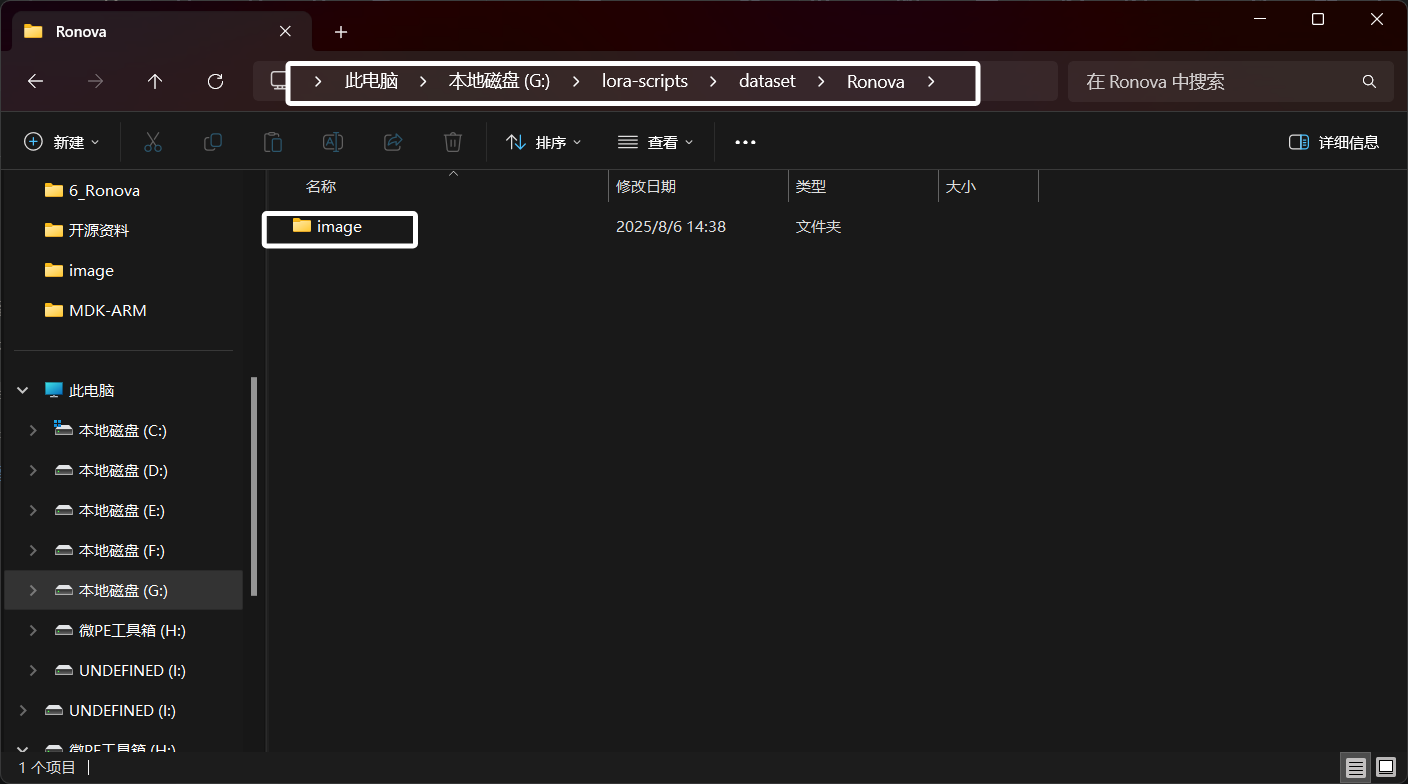
这里我们将角色图片放入“image”文件夹以后如图所示:
现在我们需要对图片进行一些预处理,这里我们首先需要将图片都转换为PNG格式的,我们可以在“image”目录下新建一个名为“ToPNG.py”的python文件,然后填入下方脚本:
import os
from PIL import Image# 支持的输入格式
SUPPORTED_FORMATS = ('.jpg', '.jpeg', '.bmp', '.gif', '.tiff', '.webp')def convert_images_to_png_and_delete_originals(directory='.'):for filename in os.listdir(directory):if filename.lower().endswith(SUPPORTED_FORMATS):file_path = os.path.join(directory, filename)try:with Image.open(file_path) as img:base = os.path.splitext(filename)[0]new_filename = base + '.png'new_path = os.path.join(directory, new_filename)img.convert('RGBA').save(new_path, 'PNG')print(f"已转换: {filename} -> {new_filename}")# 删除原文件os.remove(file_path)print(f"已删除原文件: {filename}")except Exception as e:print(f"无法处理 {filename}: {e}")if __name__ == '__main__':convert_images_to_png_and_delete_originals()
脚本会自动查找与它同级目录下的图片,发现其它格式统一转换为PNG格式并且删除原本的文件。如果运行脚本时缺少库,使用下面的命令安装:
pip install Pillow然后我们还需要在“image”目录中新建一个名为“convert_rgba_to_rgb.py”的文件,用于将RGBA类型的文件转换为RGB,新建完成以后,我们在py文件中写入下面的内容:
import os
from PIL import Imageinput_folder = r"./"
output_folder = r"../image_converted"
os.makedirs(output_folder, exist_ok=True)image_extensions = [".png", ".jpg", ".jpeg", ".webp", ".bmp"]def convert_image(file_path, save_path):with Image.open(file_path) as im:if im.mode == "RGBA":print(f"Converting: {file_path} (mode: RGBA ➜ RGB)")im = im.convert("RGB")else:print(f"Skipping: {file_path} (mode: {im.mode})")im.save(save_path)def process_folder():for filename in os.listdir(input_folder):if any(filename.lower().endswith(ext) for ext in image_extensions):src_path = os.path.join(input_folder, filename)dst_path = os.path.join(output_folder, filename)try:convert_image(src_path, dst_path)except Exception as e:print(f"Failed to process {filename}: {e}")if __name__ == "__main__":process_folder()print("✅ 转换完成!")
完成以后如图所示:
这个脚本会将转换完成的图片存放到“Ronova”文件夹下的“image_converted”文件夹下。不需要转换的图片脚本也会帮我们复制到“image_converted”文件夹中:
这样,我们“image_converted”下的图片就全部符合规范了。后续我们操作也是操作“image_converted”的图片。
当图片的颜色通道被我们统一以后,就可以开始裁剪图片了,我们需要将图片的分辨率裁剪为一样的。这里我们需要用到“stable diffusion WebUI”,我们同样可以使用“秋葉aaaki”的整合包,因为启动非常简单,我这里就不多说了,“stable diffusion WebUI”启动以后如图所示:
这里我们裁剪图片需要用到“stable diffusion WebUI”中的后期处理,我们直接点击“后期处理”:
点击以后,我们就能看到以下界面了:
这里我们需要选择“后期处理”中的“批量处理文件夹”:
这里的输入目录就直接把我们一开始处理好的“image_converted”目录的绝对路径填进来:
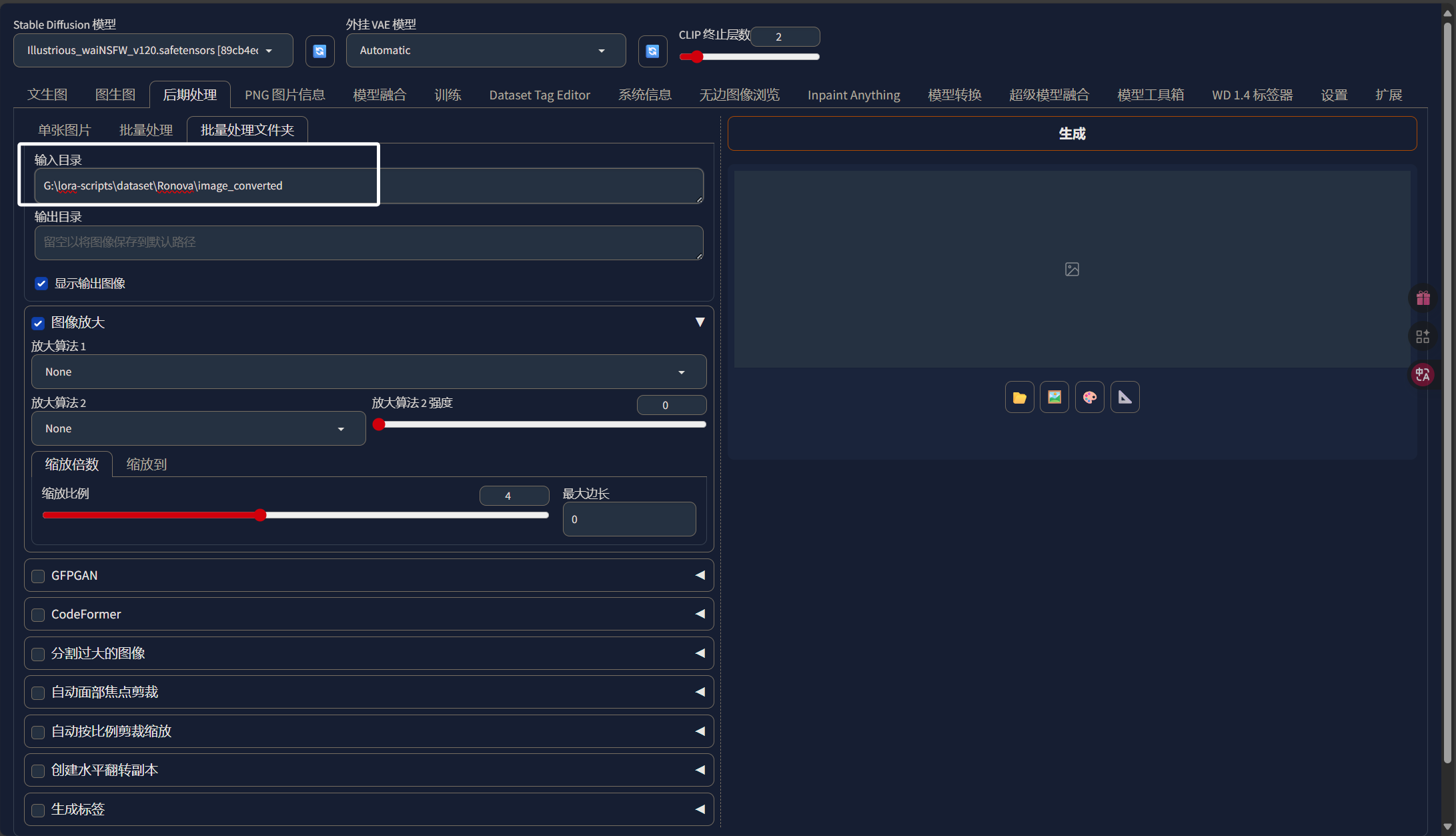
这里输出目录我们可以把图片输出到“Ronova”文件夹下名为“image_cut”的目录中,表示被裁剪过的图片:
下面我们将“图像放大”勾选:
然后再选择“缩放到”:
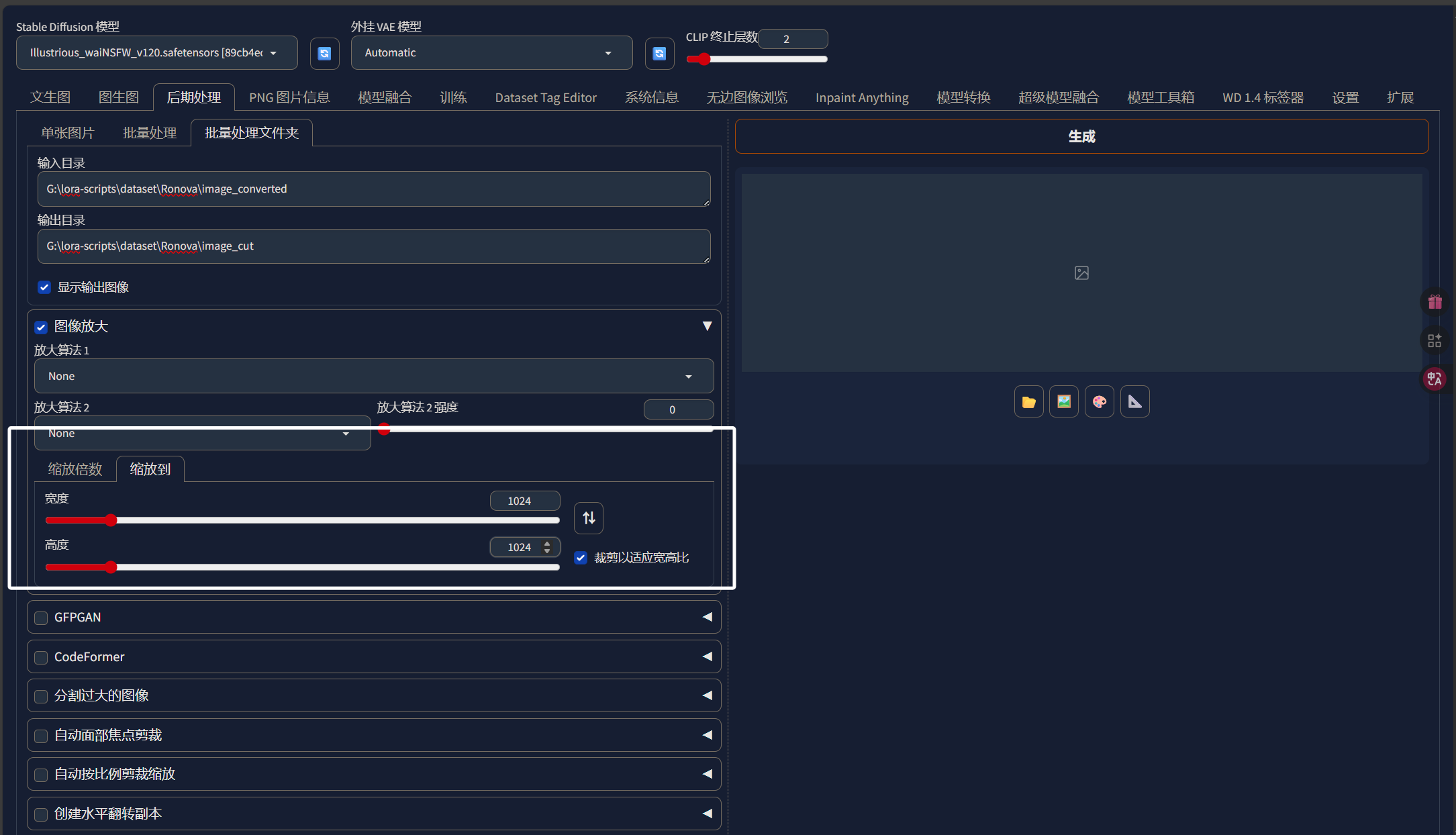
这里我选择将我的图像都缩放到1024x1024,因为SDXL的底模就是基于这个分辨率训练的,我们训练LORA时使用这个分辨率应该也会取得比较好的效果。如果你的显存小于16G,那么还是建议512x512分辨率。这里需要注意的是如果你裁剪的是1024x1024分辨率,需要保证每张图片的分辨率都大于1024x1024。
然后我们再将“自动面部焦点裁剪”勾上:
这里“自动面部焦点裁剪”的参数我们不需要调整。这样图像裁剪的配置差不多就完成了,我们直接点击“生成”即可:
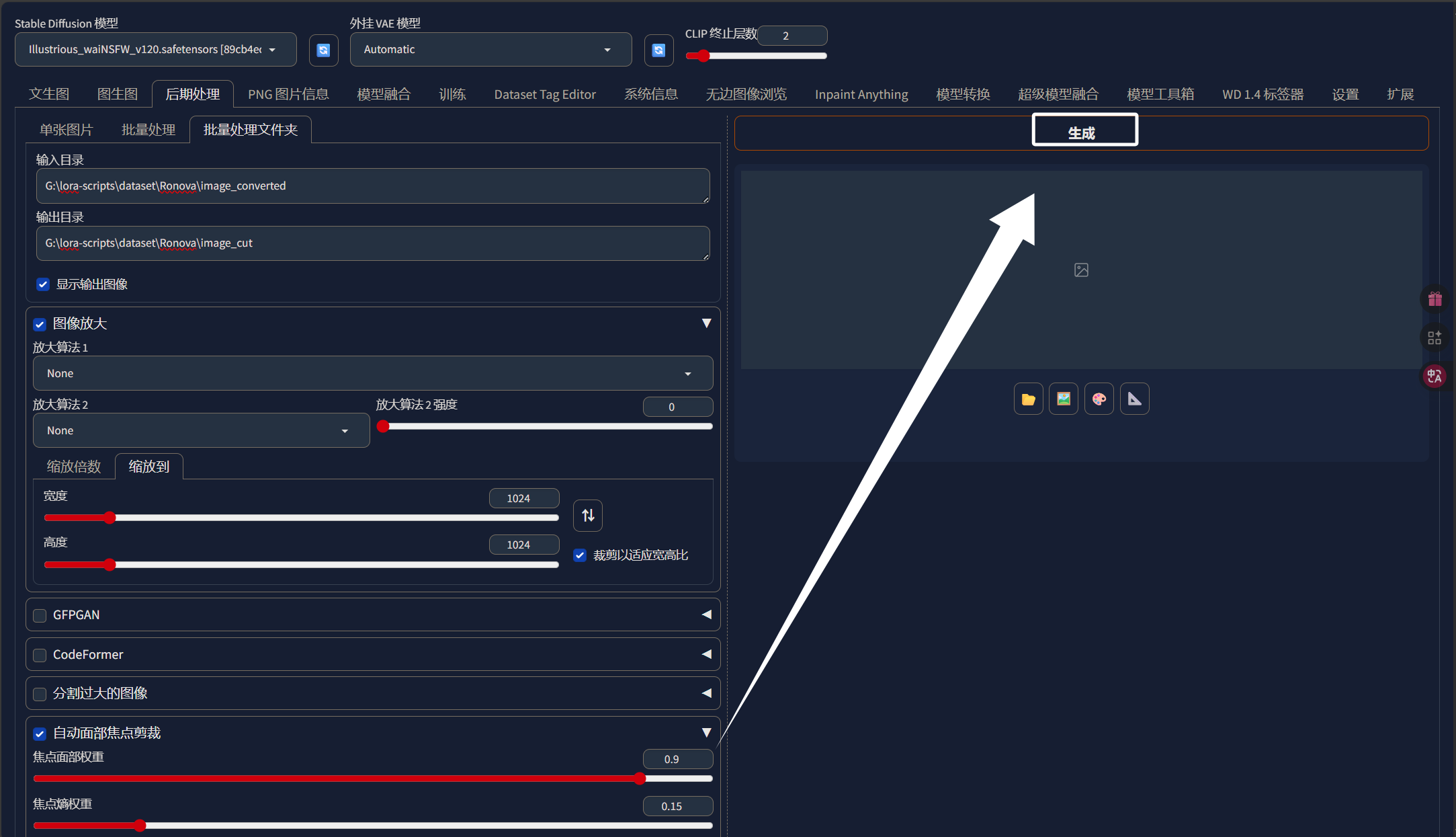
裁剪完成以后,我们就可以来到“Ronova”目录下的“image_cut”文件夹,我们可以看到我们的图片被裁剪为正方形了并且分辨率为1024x1024:
图像裁剪完成以后,我们就可以对图片进行打标签处理了。这里我们还需要使用到“stable diffusion WebUI”中的标签器,我们直接点击“stable diffusion WebUI”中的“WD 1.4标签器”,点击以后可以看到以下界面:
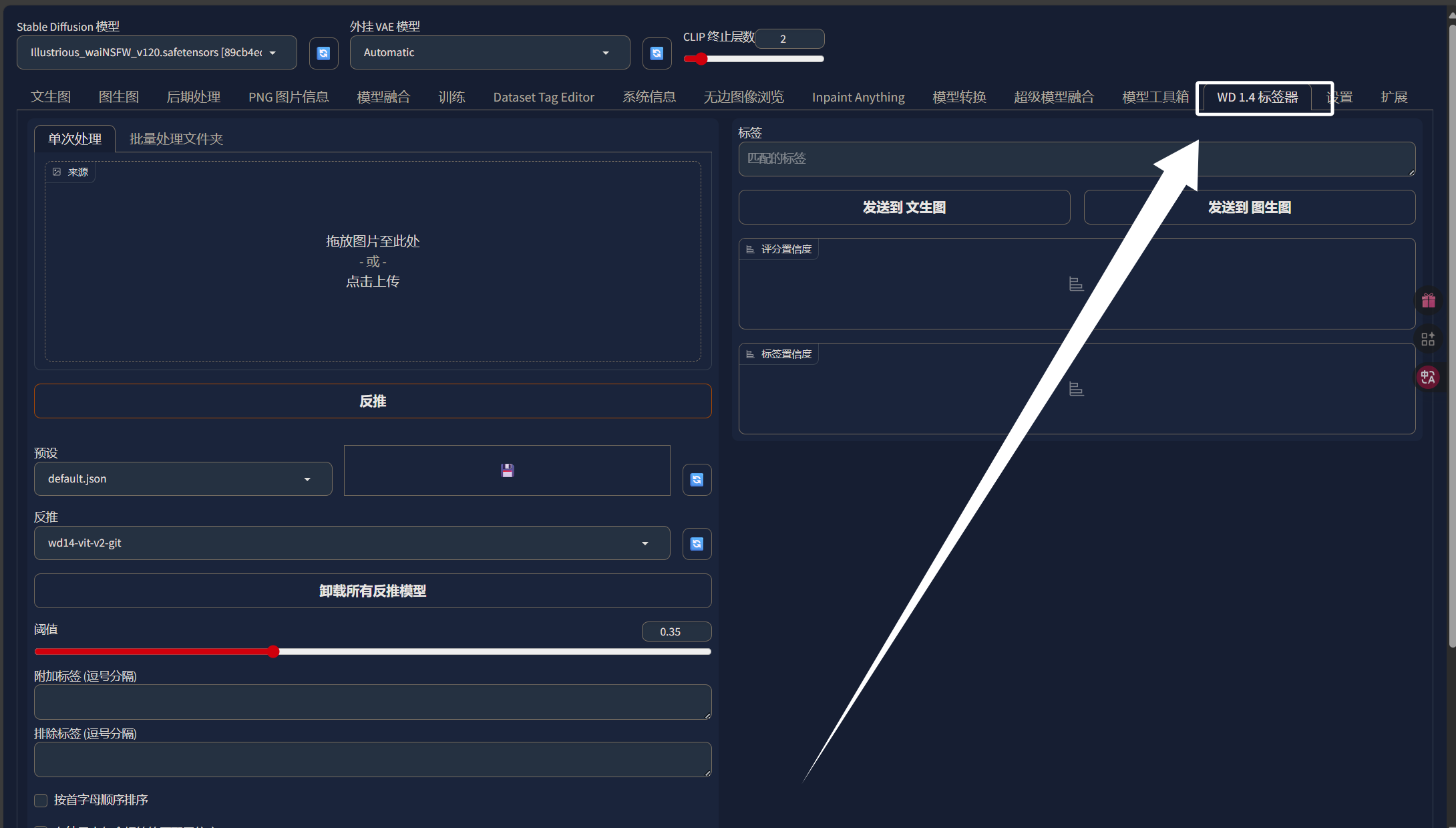
这里我们同样选择“批量处理文件夹”:
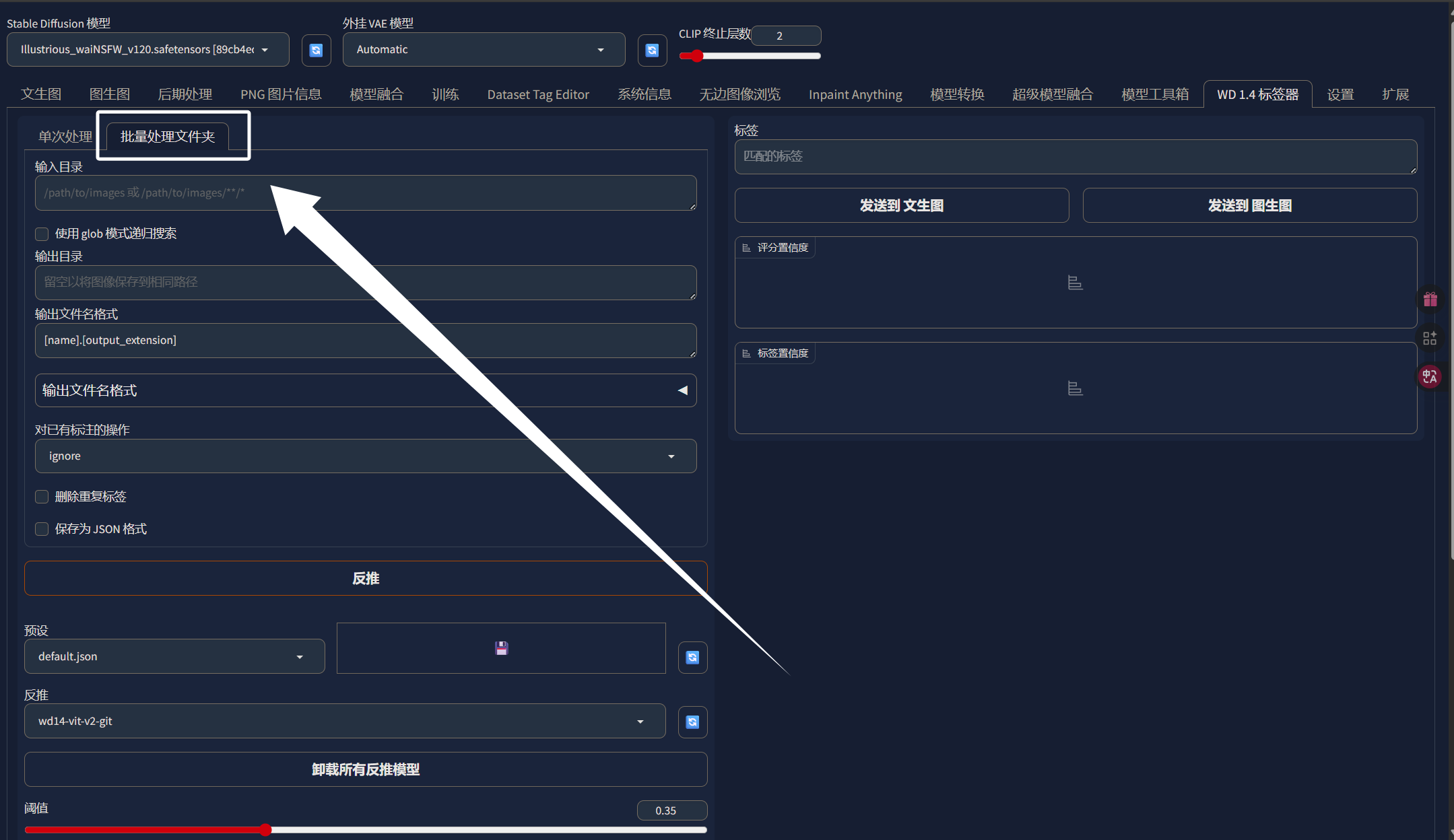
输入目录就是我们刚刚裁剪完的图片的目录即“image_cut”:
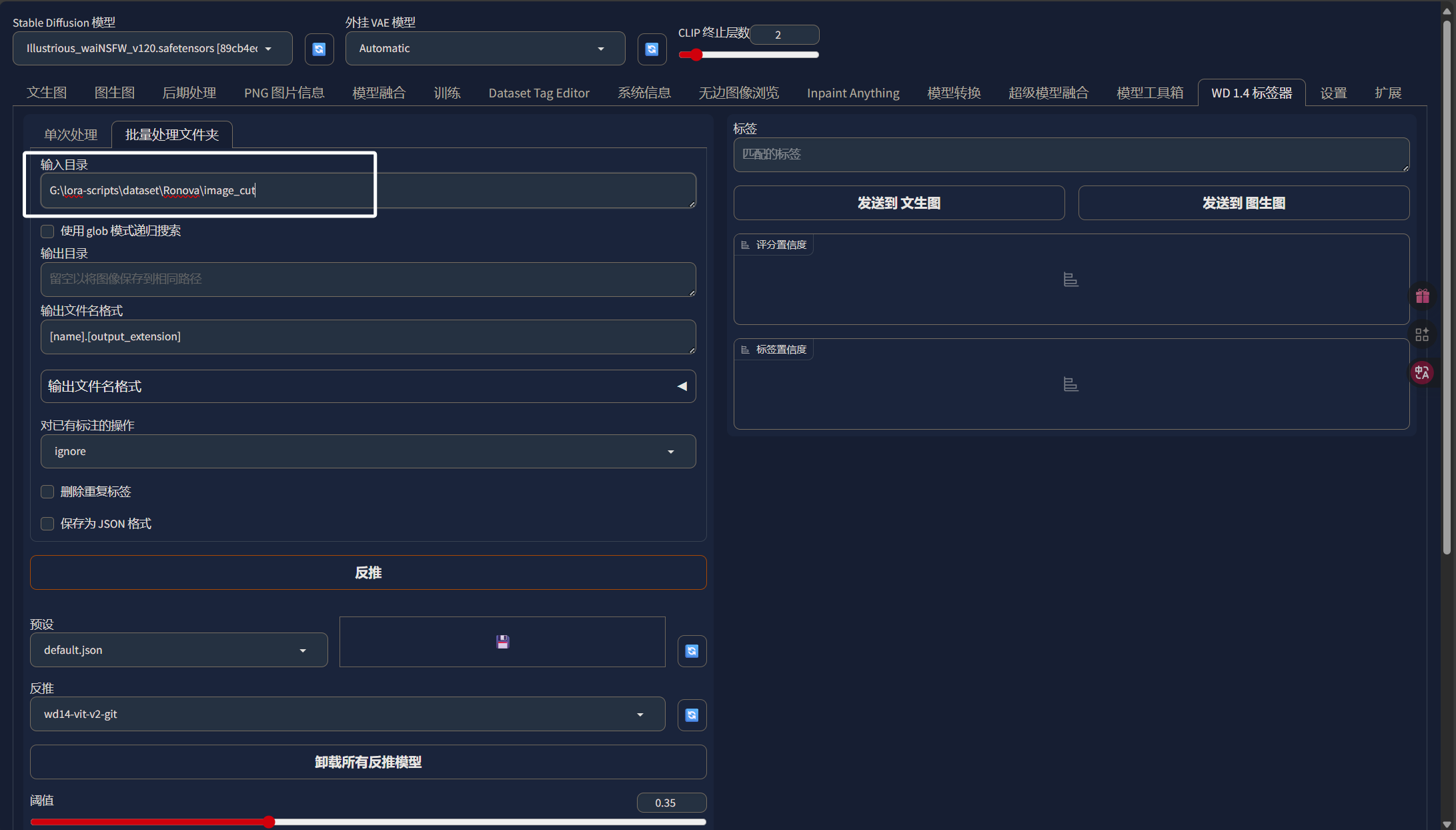
输出目录的话,我们直接输出到“Ronova”文件夹下的“image_label”目录中:
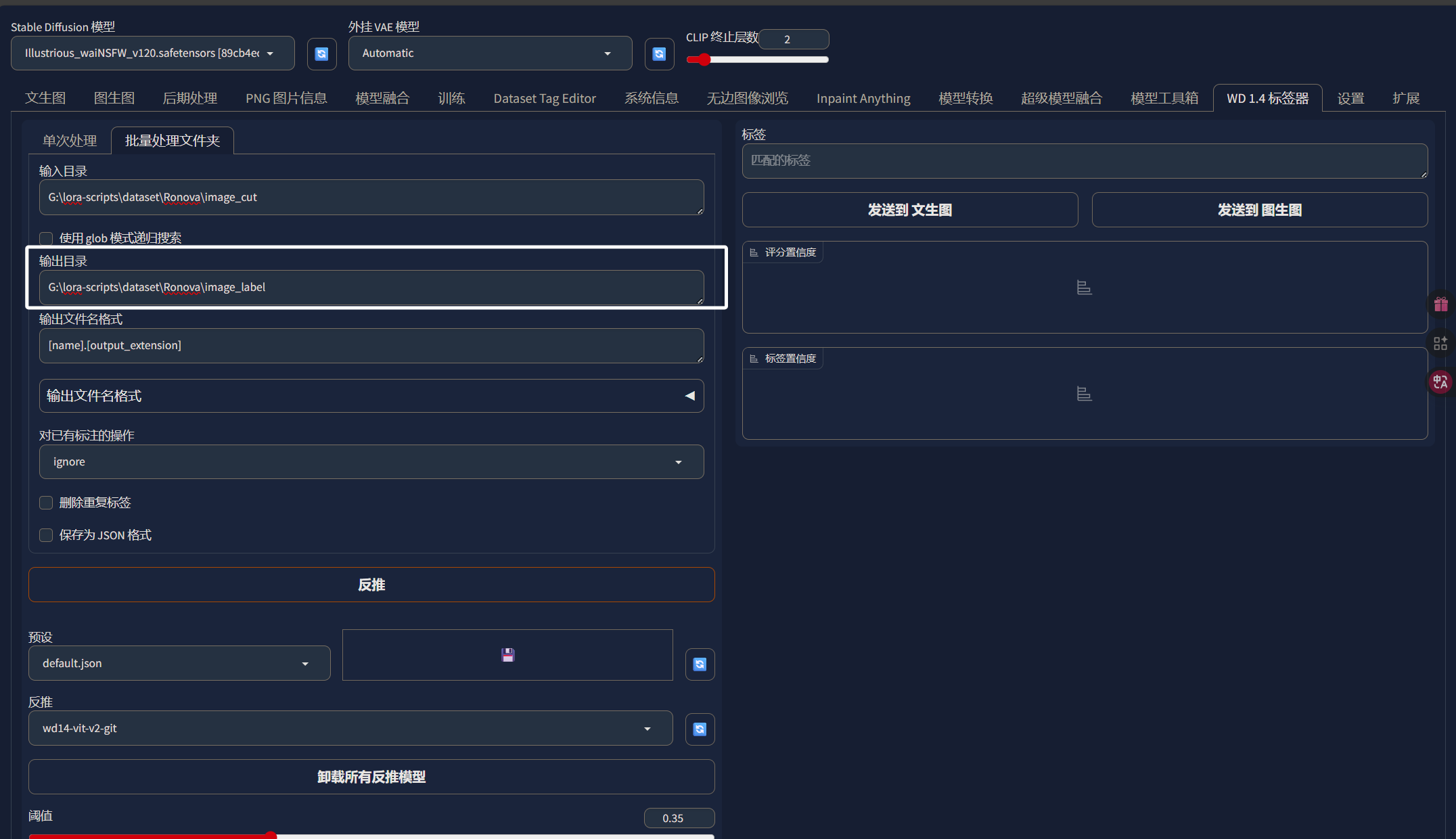
设置完输入、输出目录以后,我们来到下面在“附加标签”中写上我们角色的英文名,后续也会当作我们LORA的触发词:
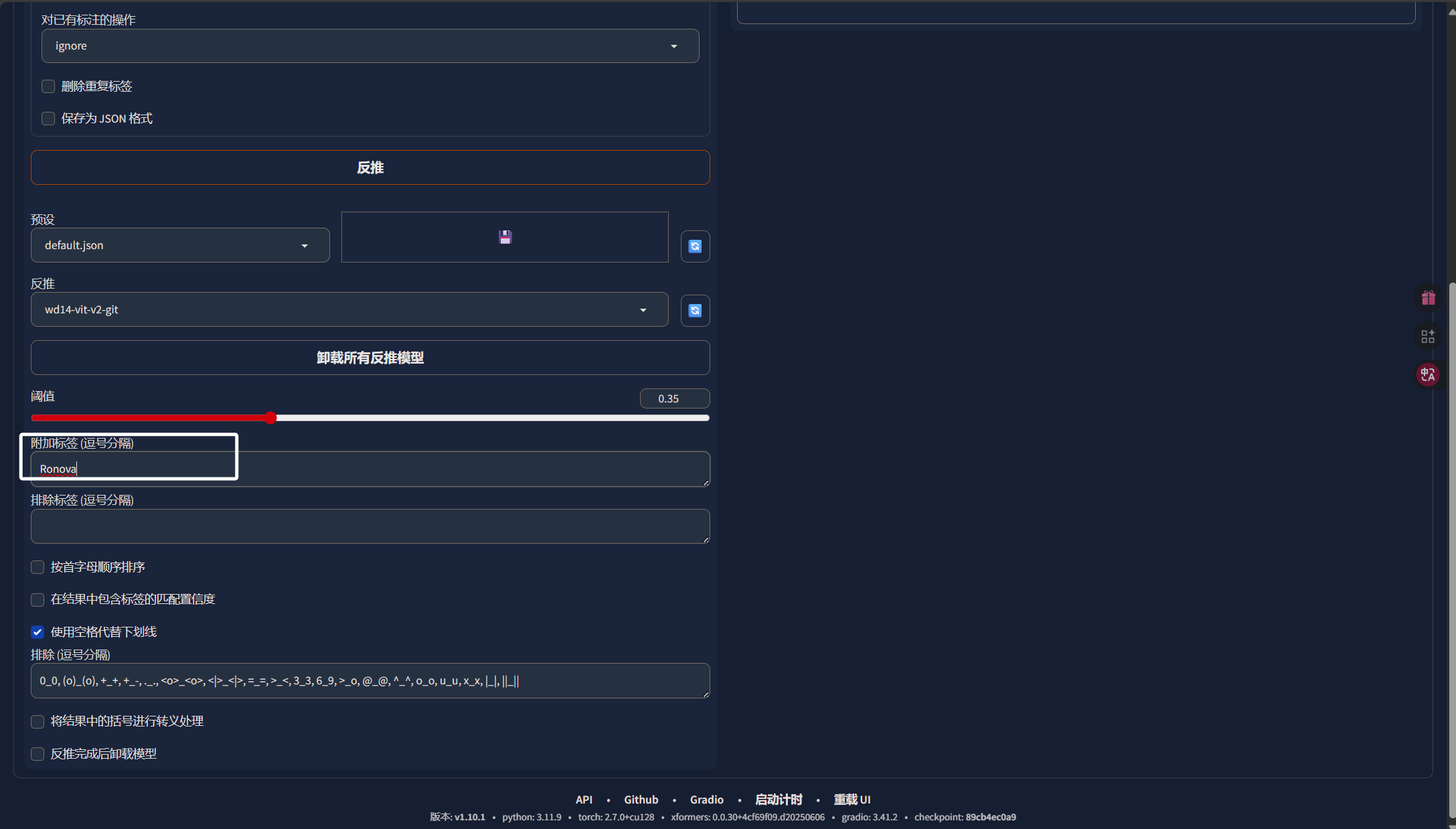
完成上卖弄的步骤以后,我们直接点击“反推”,这样就可以为我们的图片打上标签了:
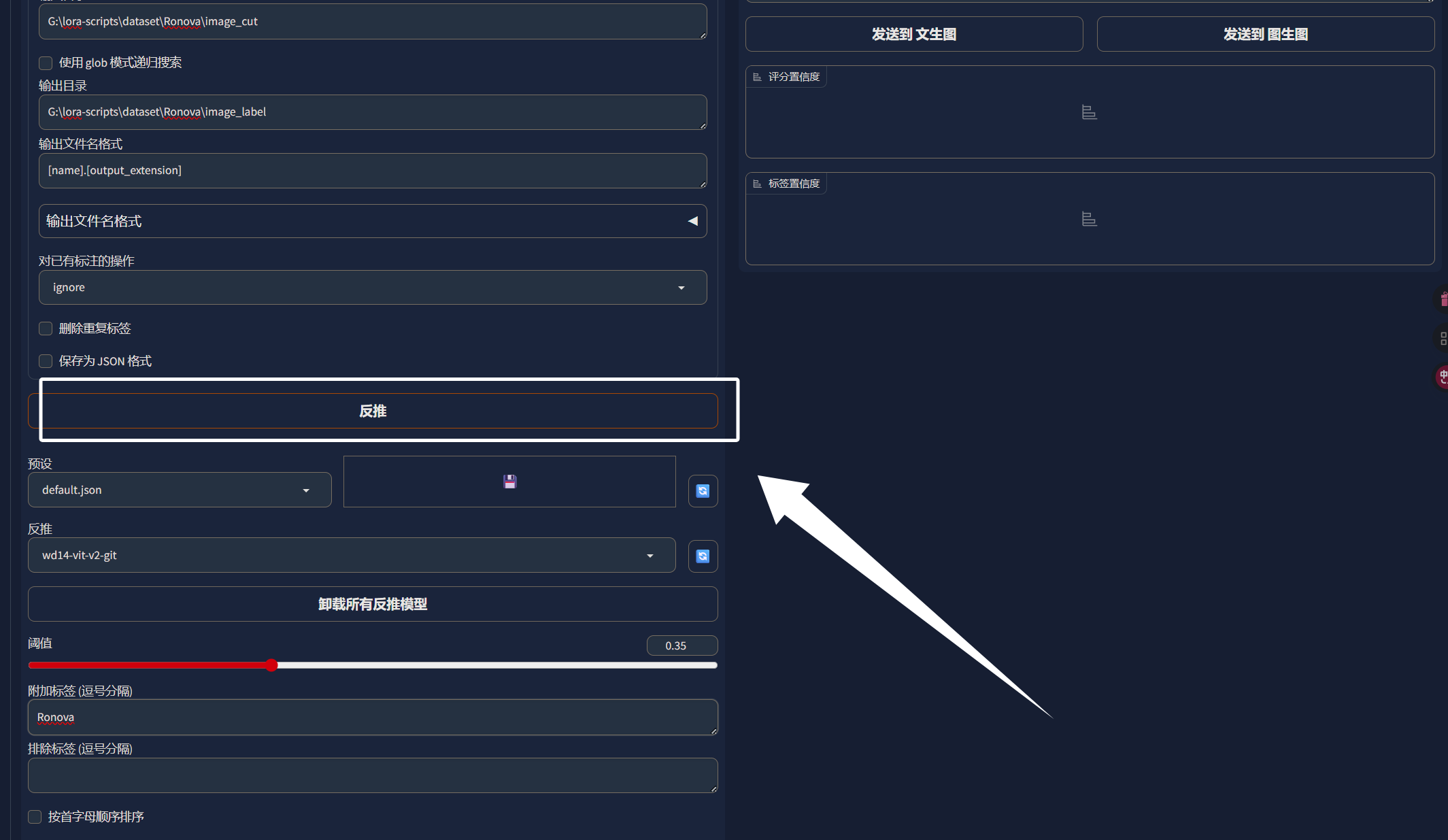
标签生成完成以后,我们就可以看到这里标签器为我们每一张图片都生成了一个文本文件:
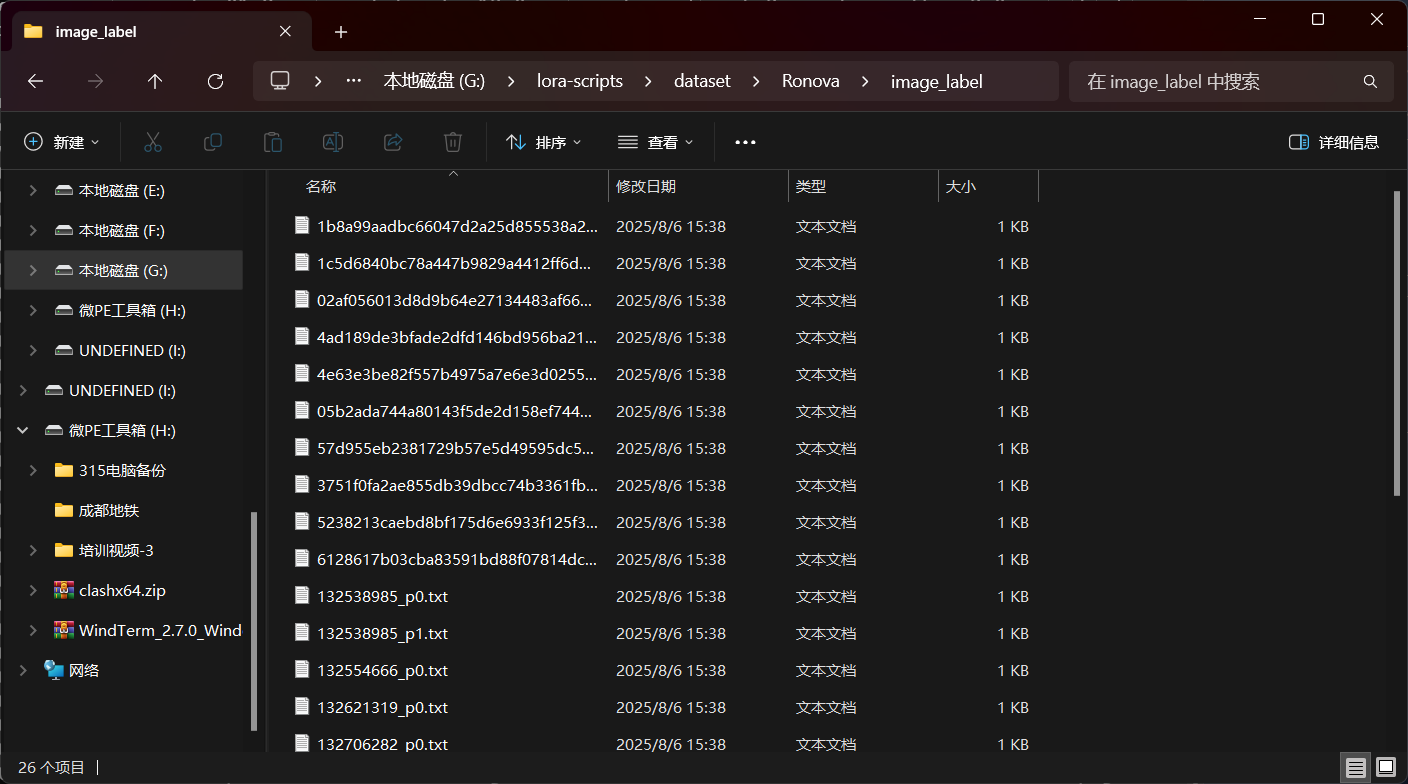
我们把“image_cut”中的图片复制到“image_label”中,我们的数据集就制作完成了:
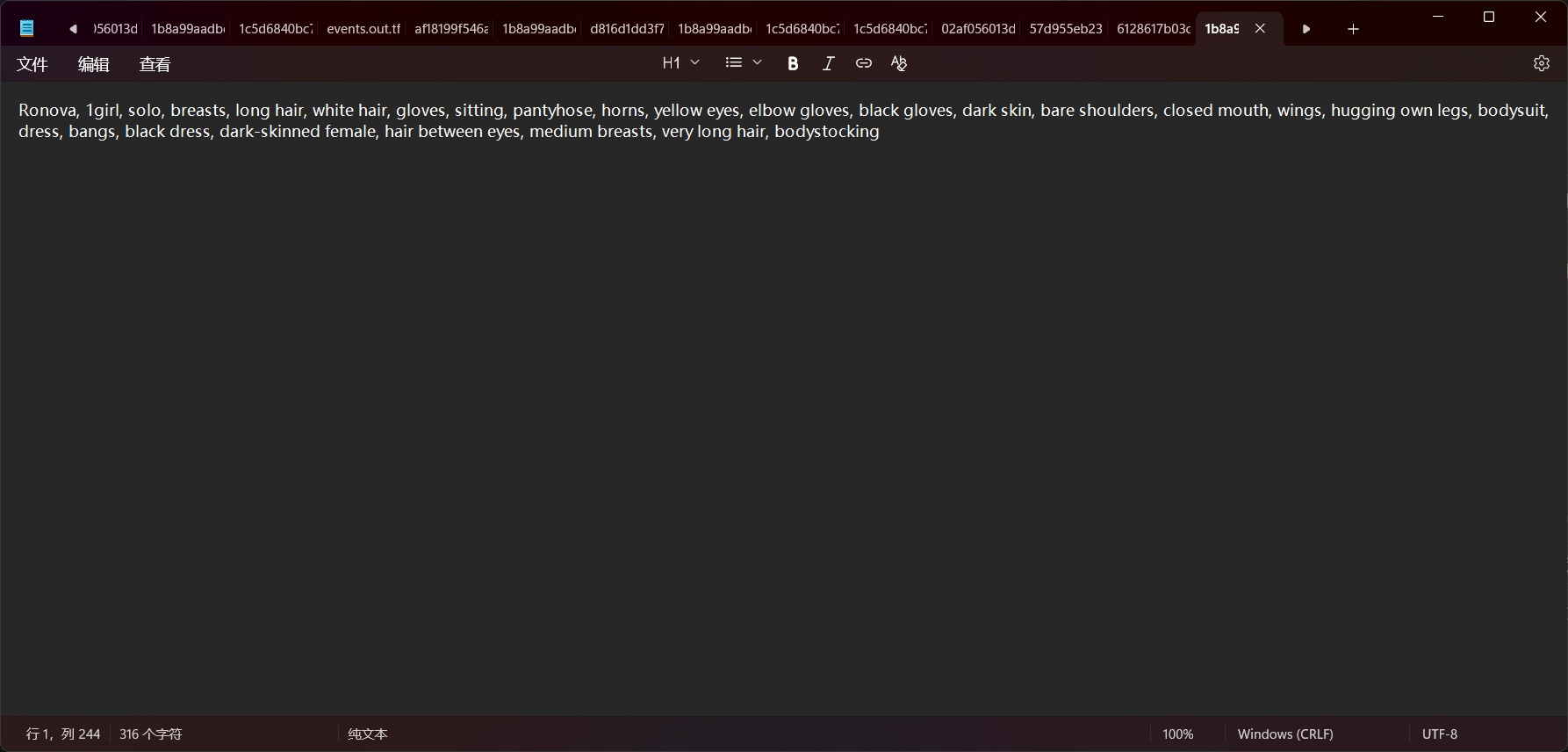
我们可以随意打开一个文本文件看一下,可以发现我们的附加标签被加到了第一个,后面的标签则是用来描述图像的:
至此,我们的训练LORA要使用到的数据集就准备完成了,后续我们就会对"iamge_label"这个文件夹进行操作了。
五、SDXL LORA的训练
前面忙活了这么久,终于可以开始训练了,这里我们在“Ronova”文件夹下新建一个名为“LORA”的文件夹用于存放我们训练所需的内容:
我们在“LORA”文件夹中新建“image”,“model”,“log”文件夹,分别用于存放我们的数据集以及训练所产出的模型以及日志文件:
这里我们再进入“LORA”文件夹下的“image”文件夹中新建一个名为“6_Ronova”的文件夹:
这里一定要看清路径。
我们将之前的“image_label”目录中的所有内容复制到这个名为“6_Ronova”的文件夹中:
完成这个步骤以后,我们就可以打开“SD-Trainer”的WebUI了:
这里我们选择“专家”模式:
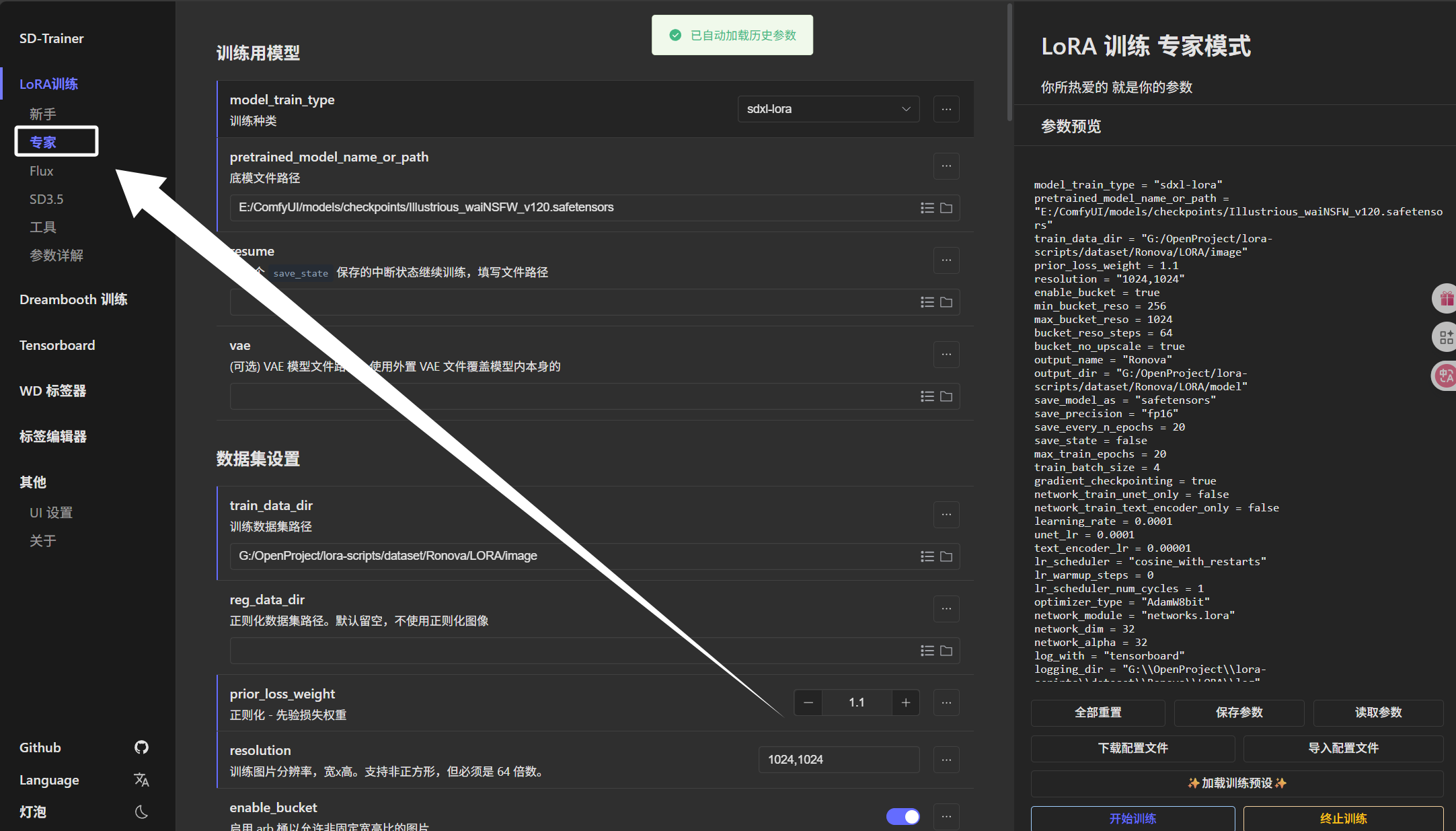
训练种类这里我们选择“sdxl-lora”:
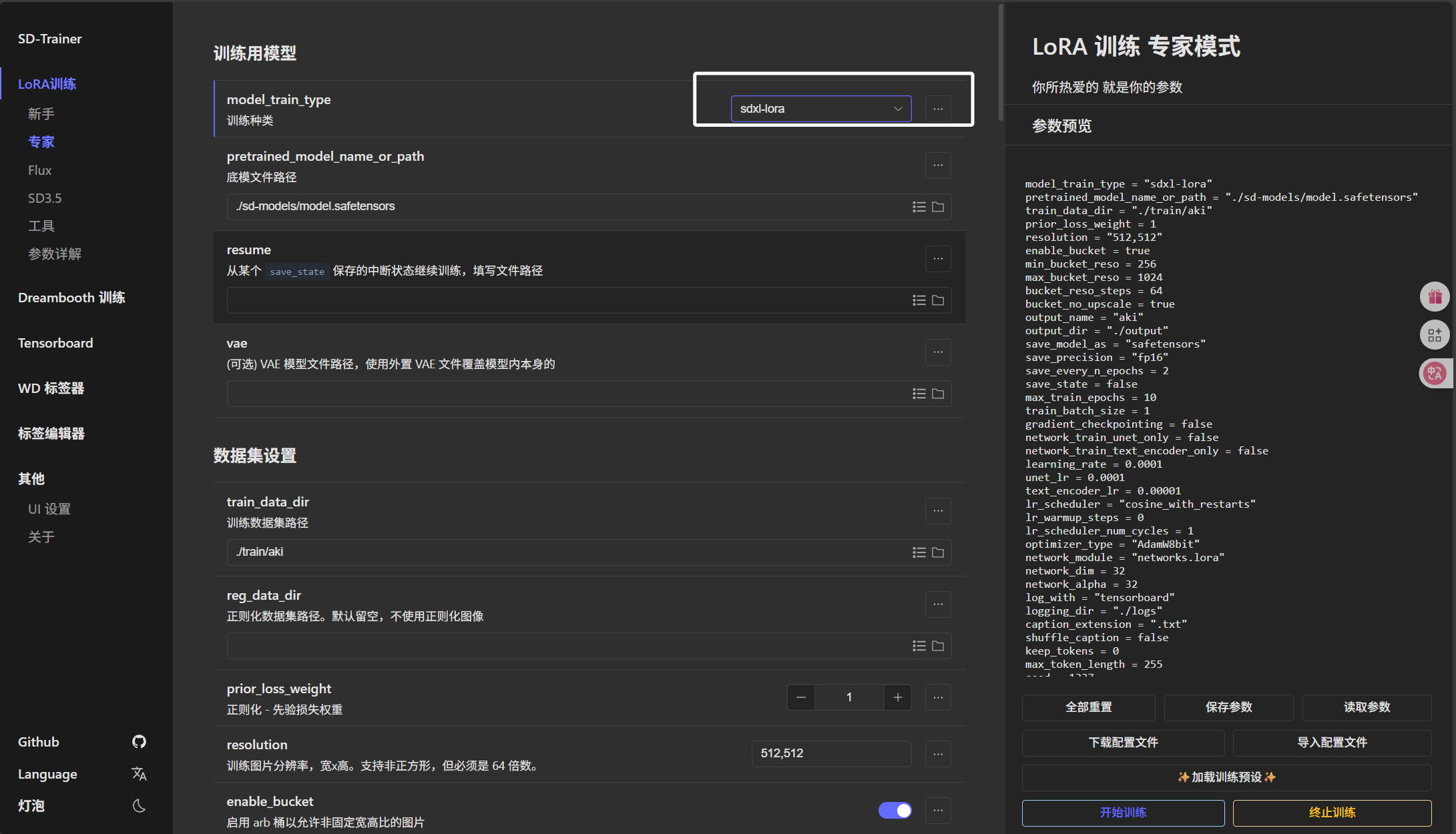
这里的“底模文件路径”我们直接把我们下载的“sd_xl_base_1.0.safetensors”模型选择进来即可:
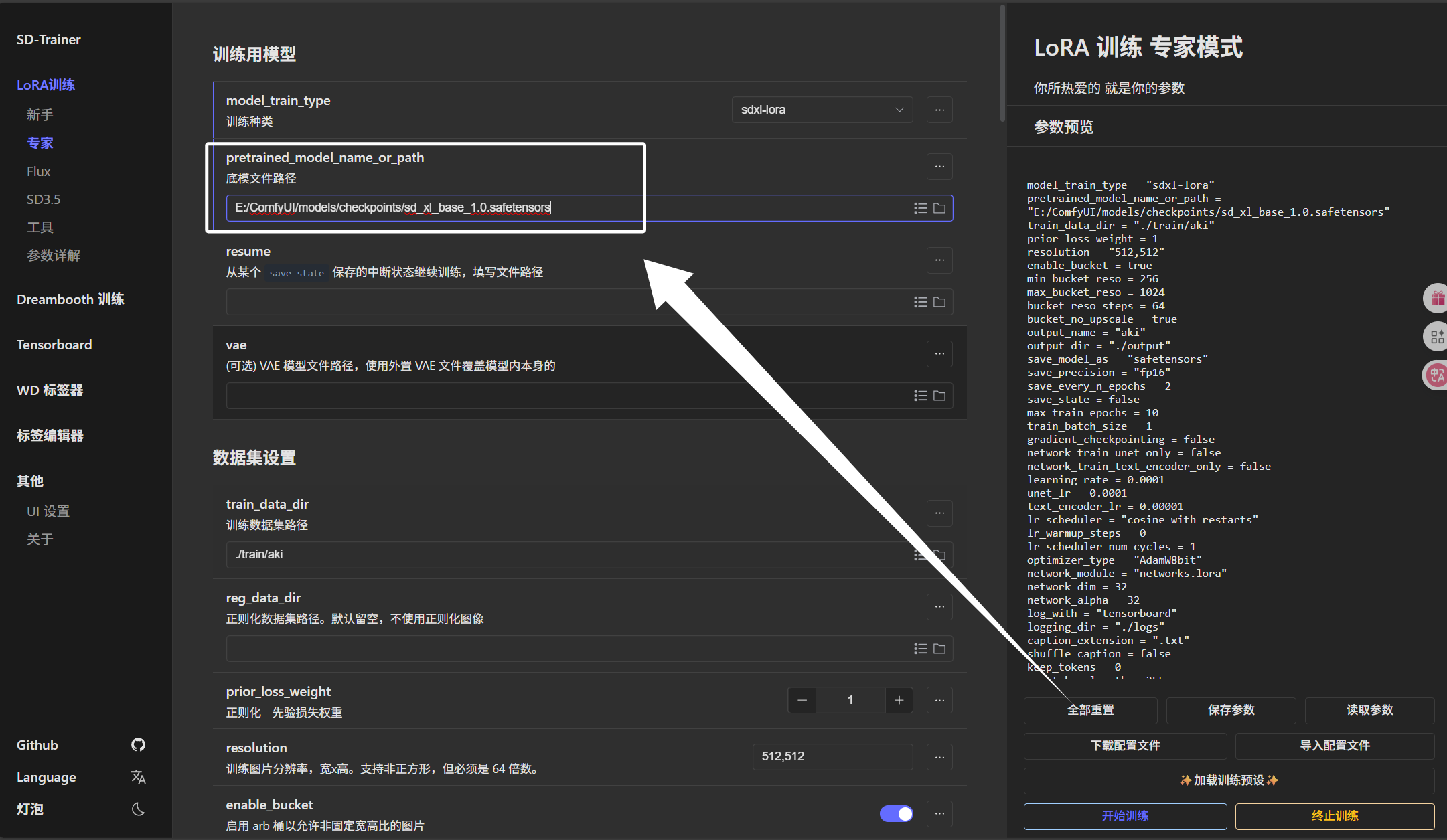
然后我们看到下面的“vae”,我们把我们下载的“sdxl.vae.safetensors”模型选择进来即可:
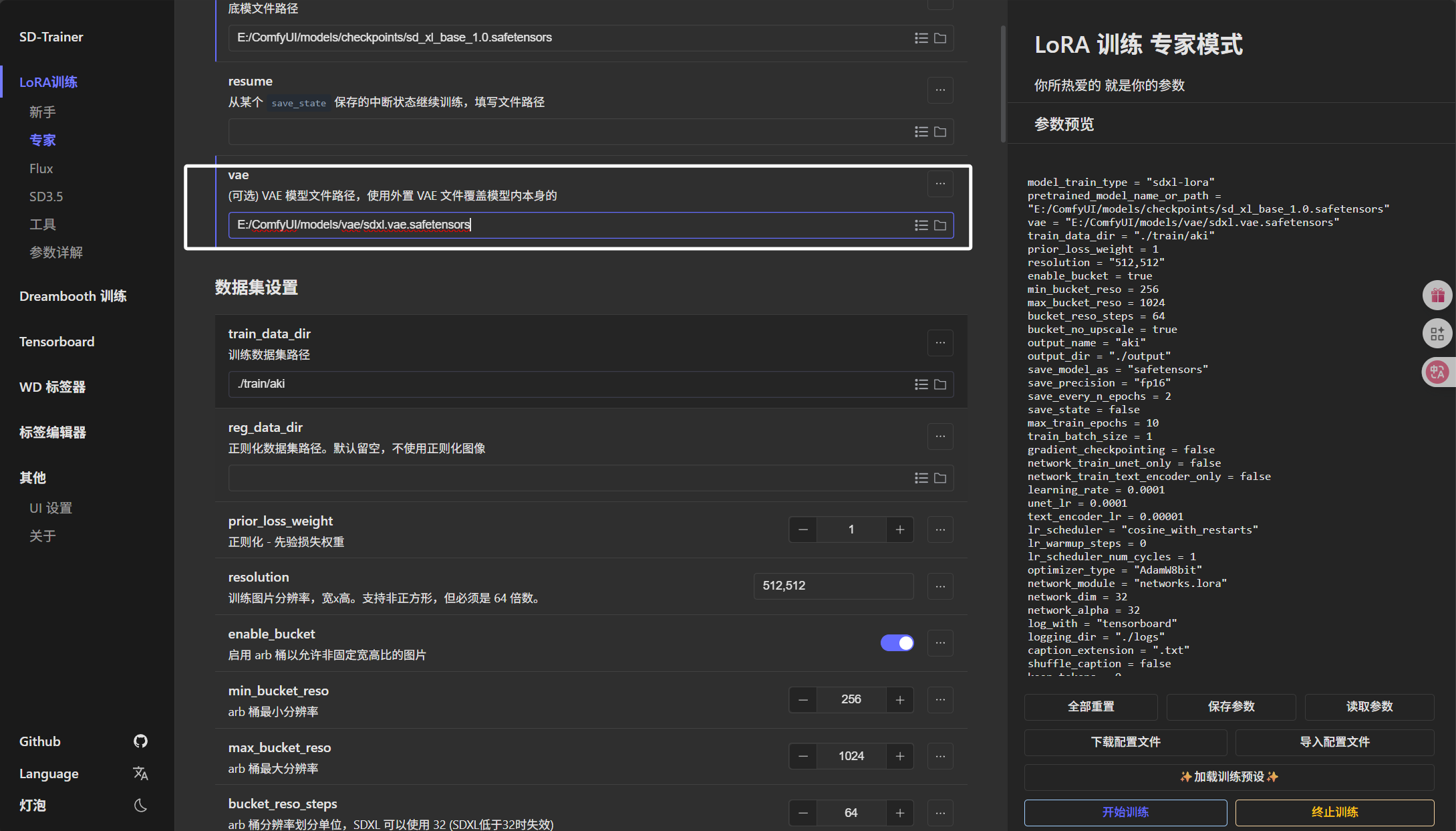
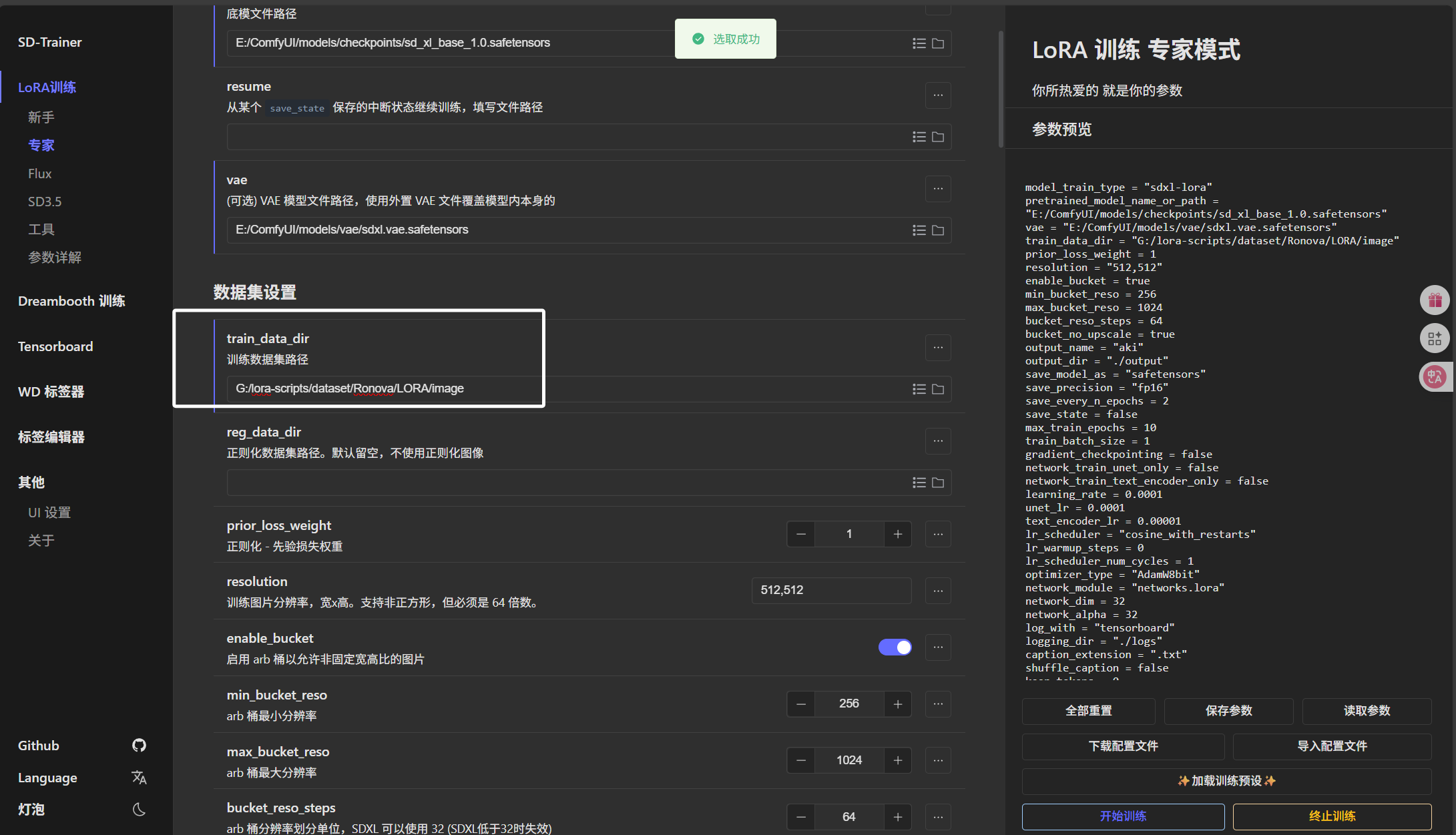
然后就是下方的“训练数据集路径”,这里我们需要把“Ronova”目录下的“LORA/image”选择进来,注意这里路径到“image”结束,不要把“6_Ronova”选择进来了:
然后就是下方的“训练图片分辨率”,这里大家根据自己裁剪的大小进行填写即可:
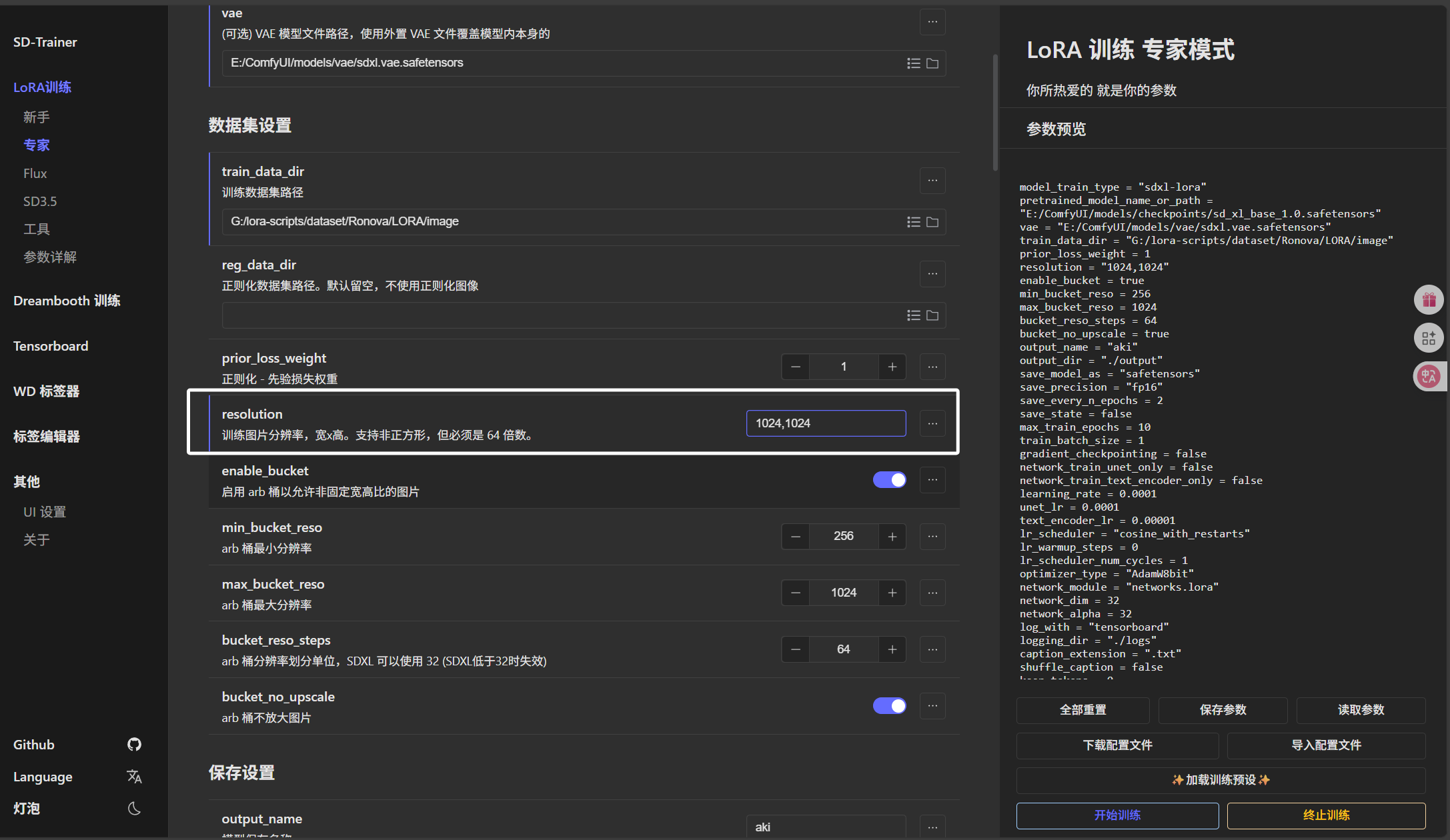
然后就是下方的“模型保存名称”,我们直接写角色英文名即可:
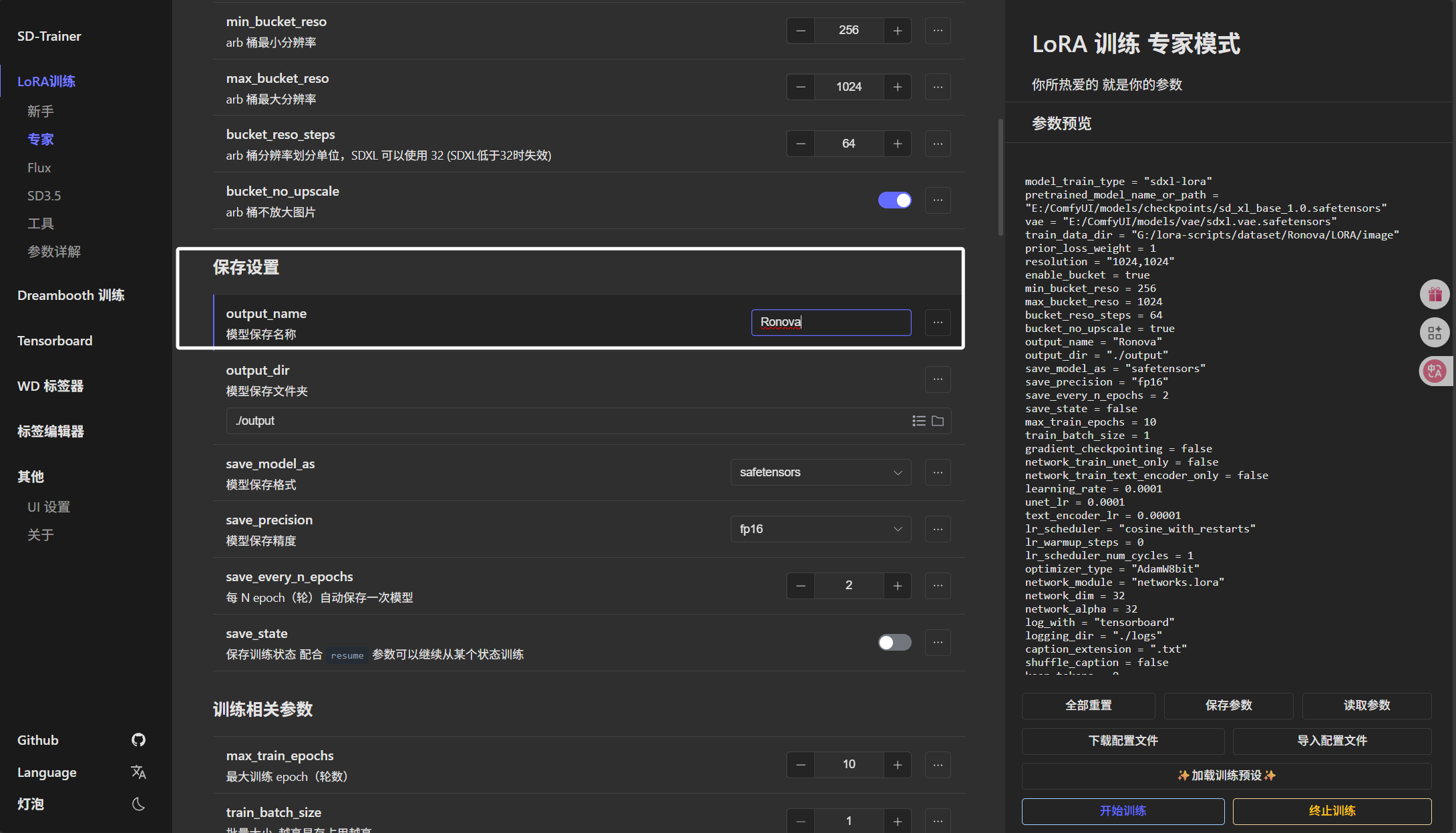
模型保存文件夹我们选择到“Ronova”文件夹下的“LORA\model”文件夹:
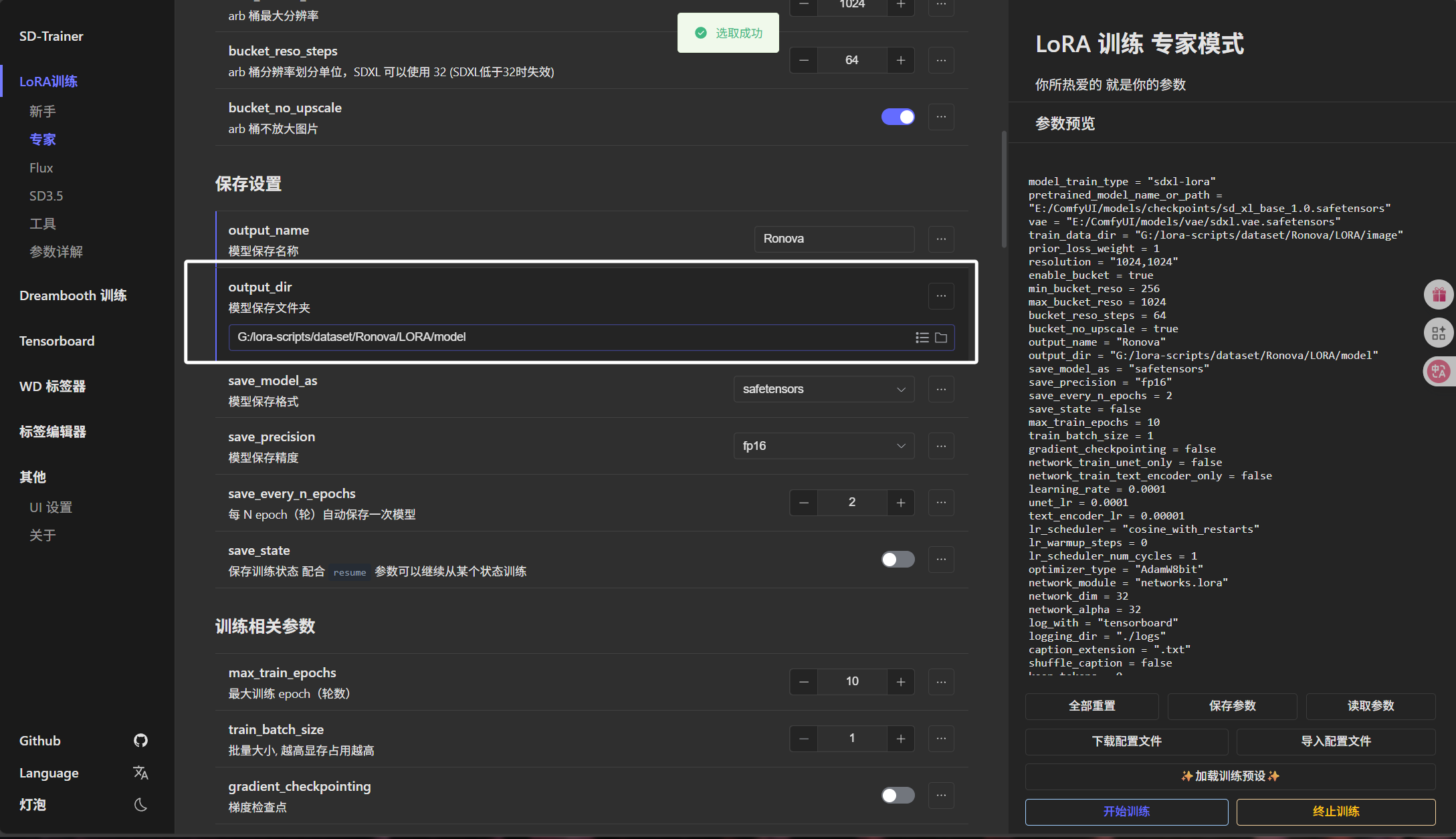
模型保存精度我们这里选择“fp16”:
这里的最大训练轮数10-20次即可,具体如何计算训练轮数我们下次教程再讲:
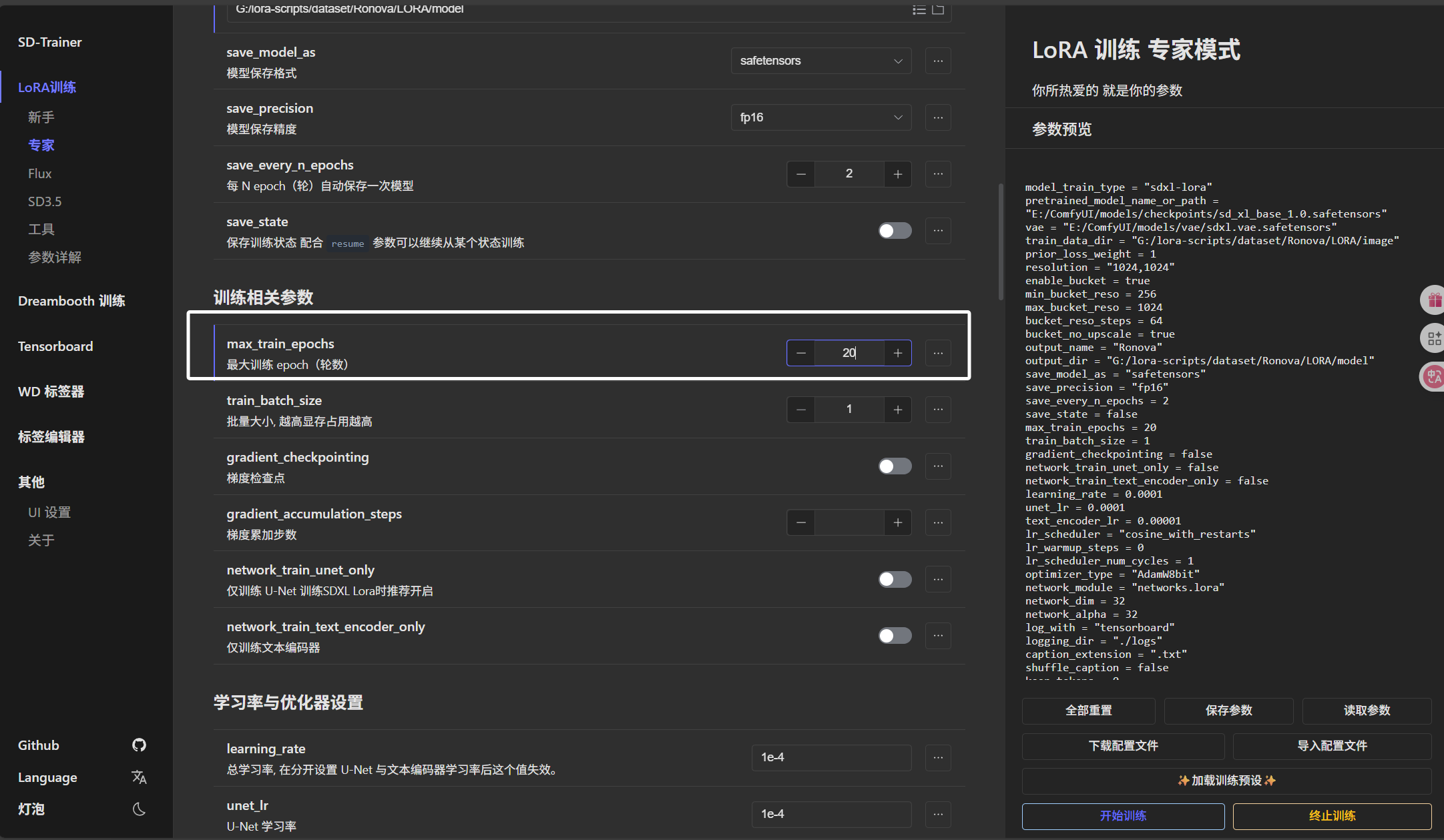
批量大小根据自己显存和图片分辨率来定,可以多次尝试,得到一个合适的值:
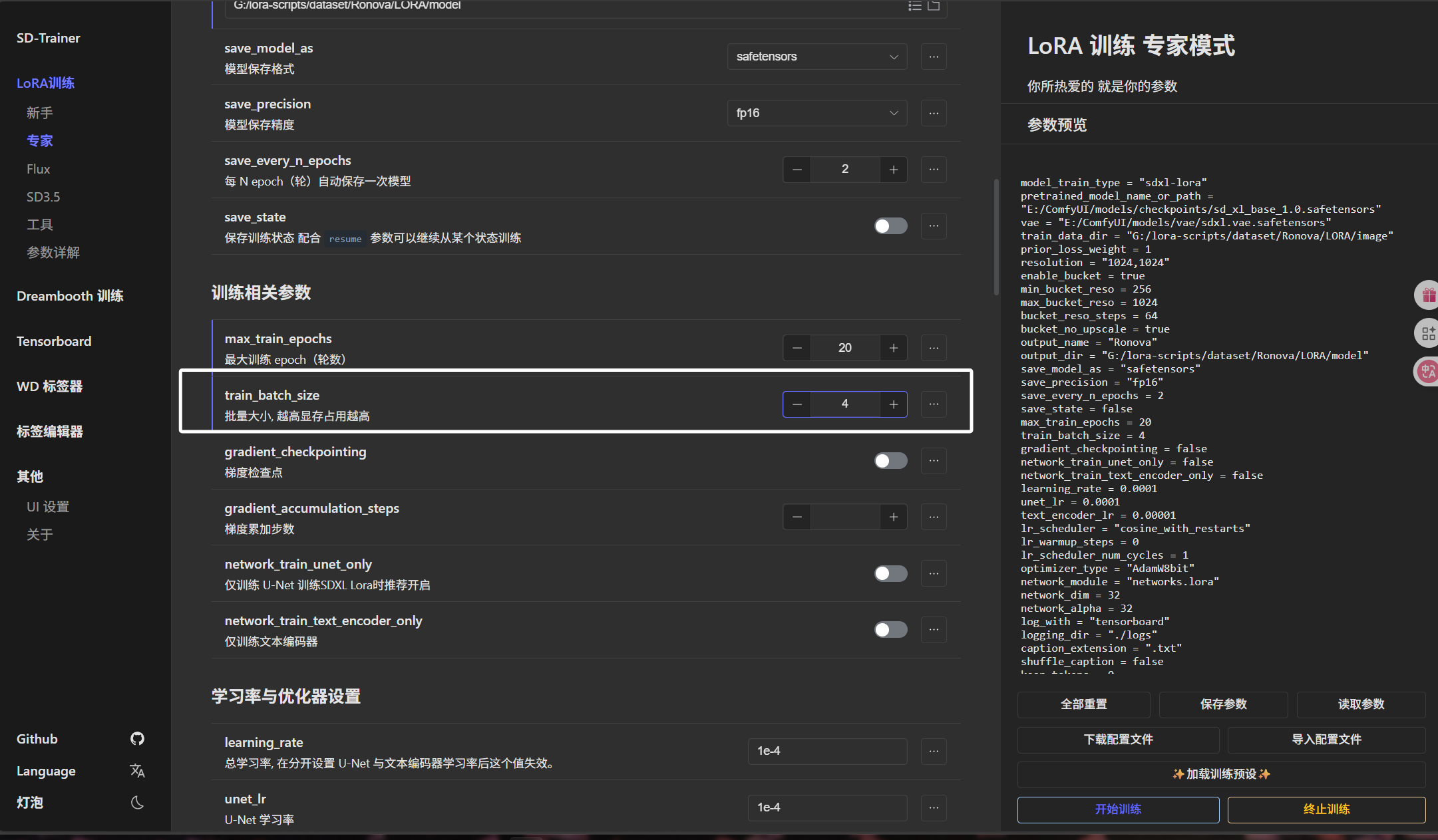
下方的“日志保存文件夹”我们直接将“Ronova”文件夹下的“LORA/log”文件夹的绝对路径填写进来:
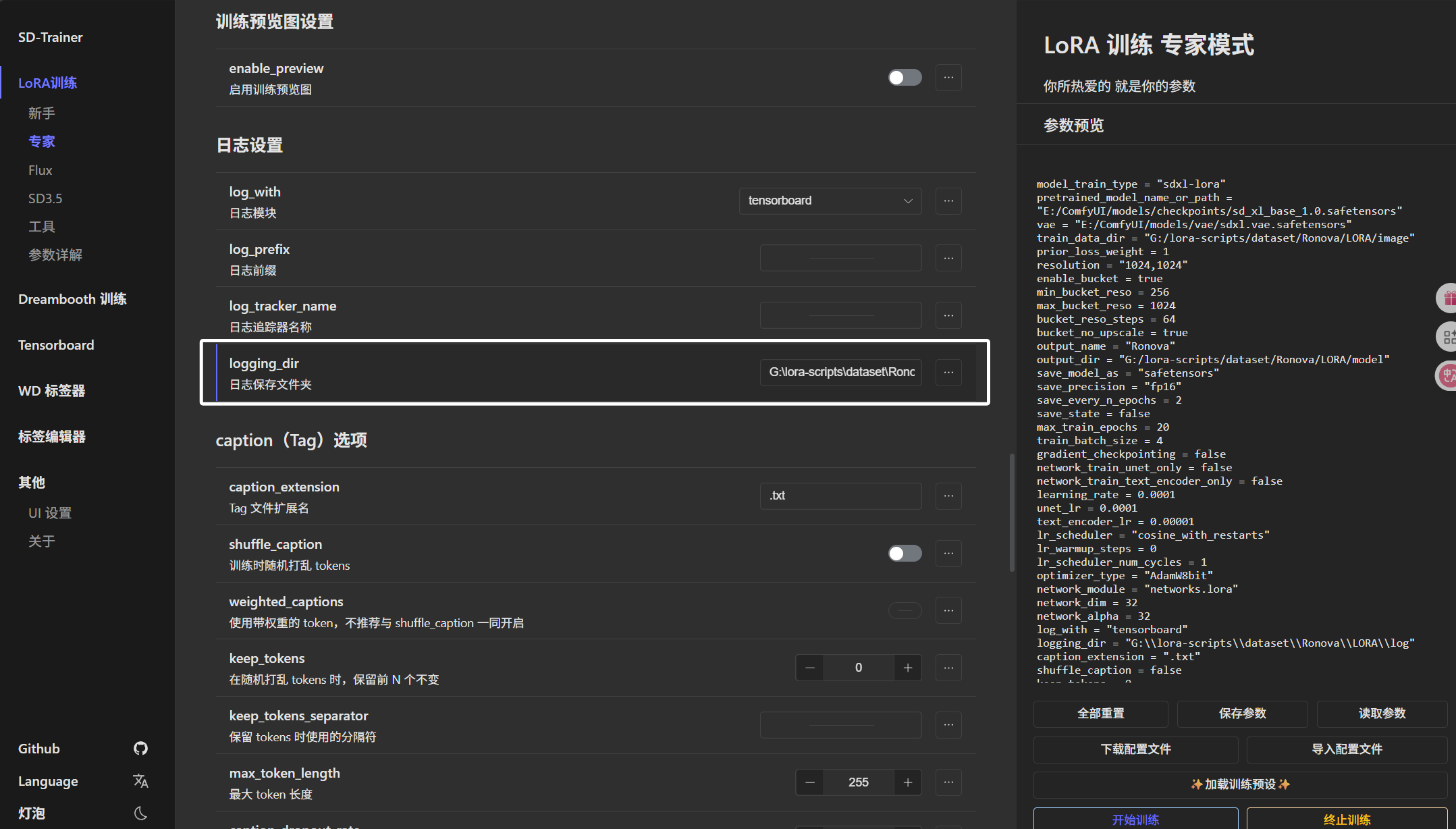
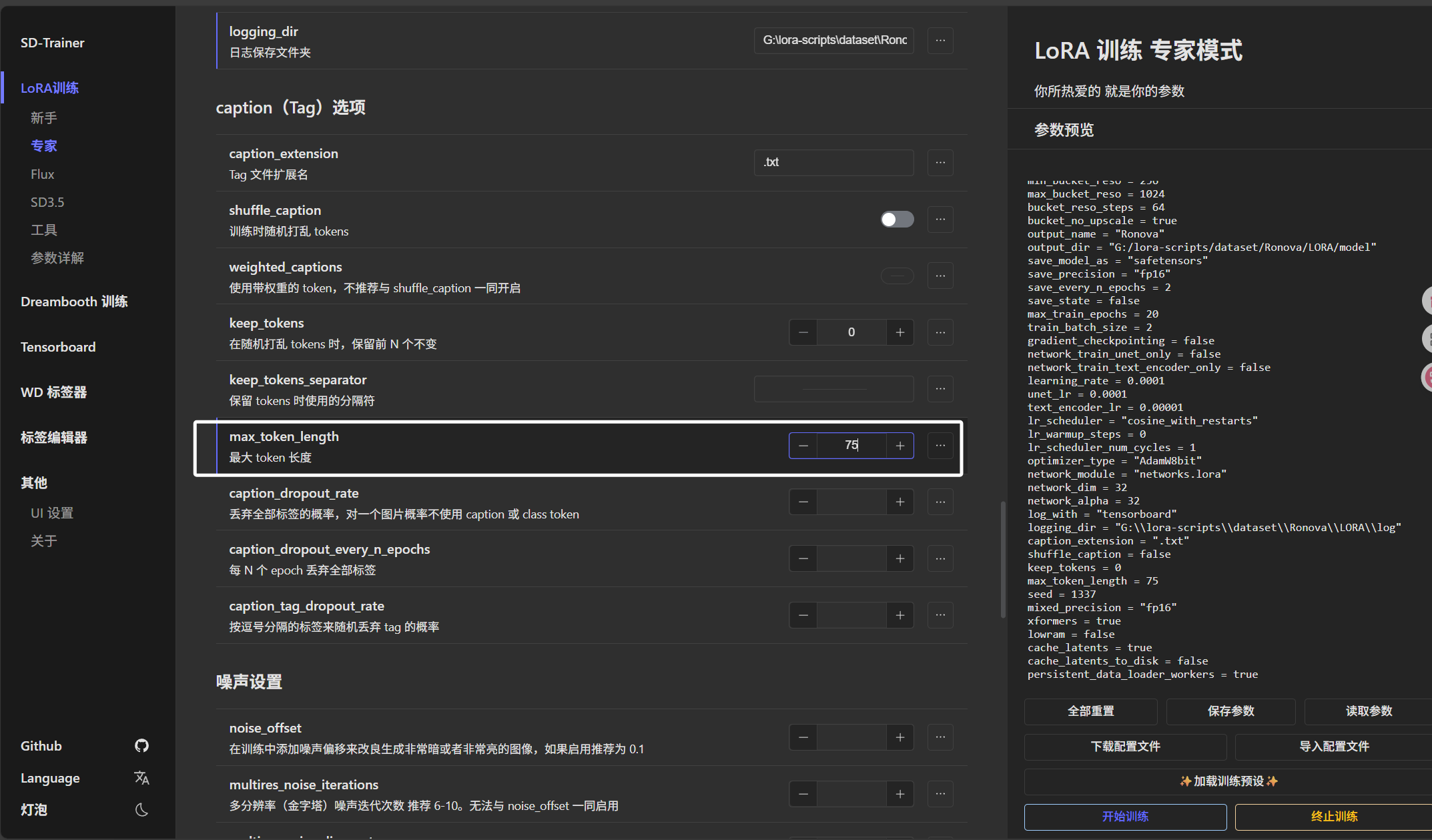
这里“最大token长度”我们配置为75:
后面的“训练混合精度”我们选择“fp16”:
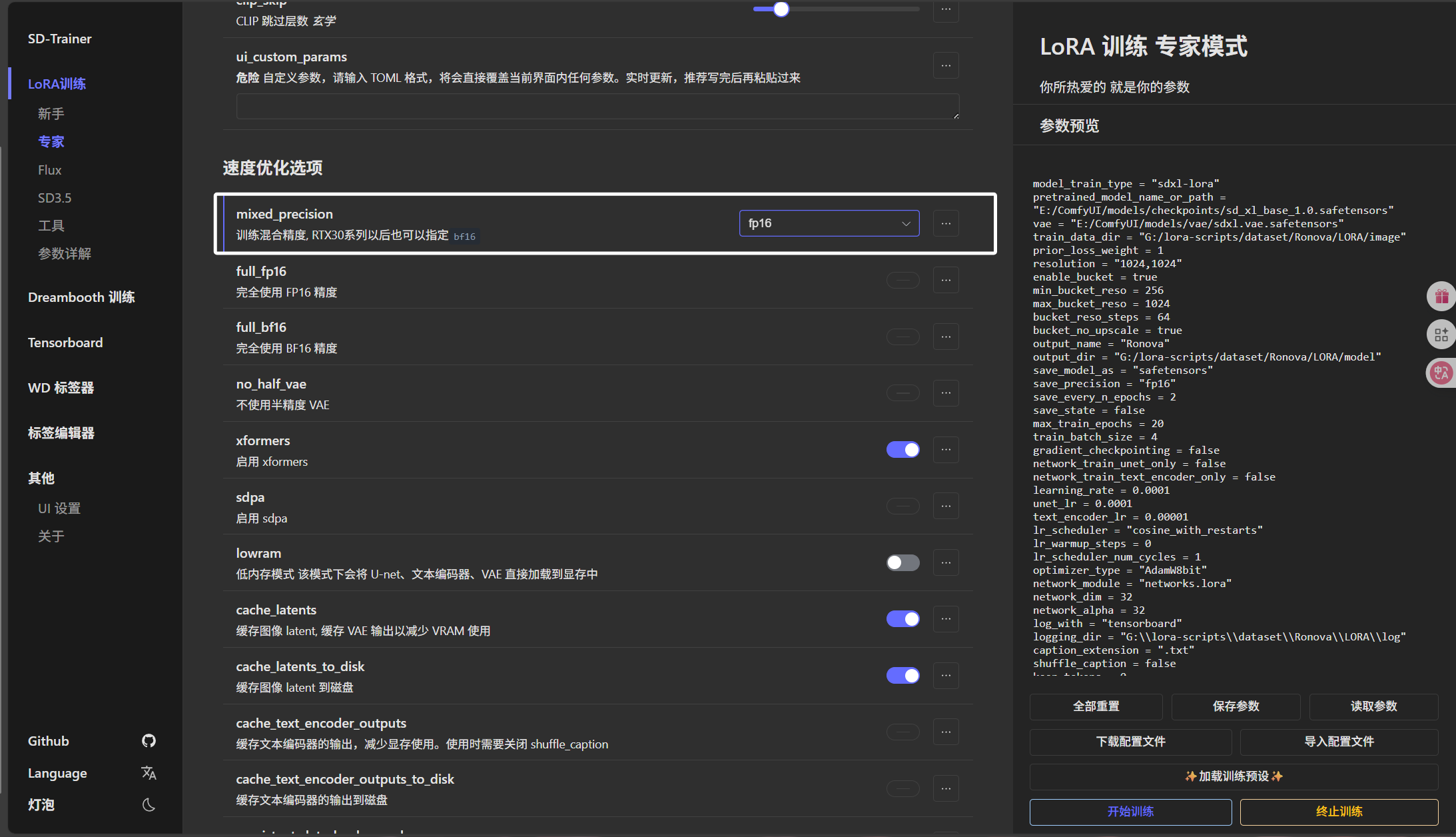
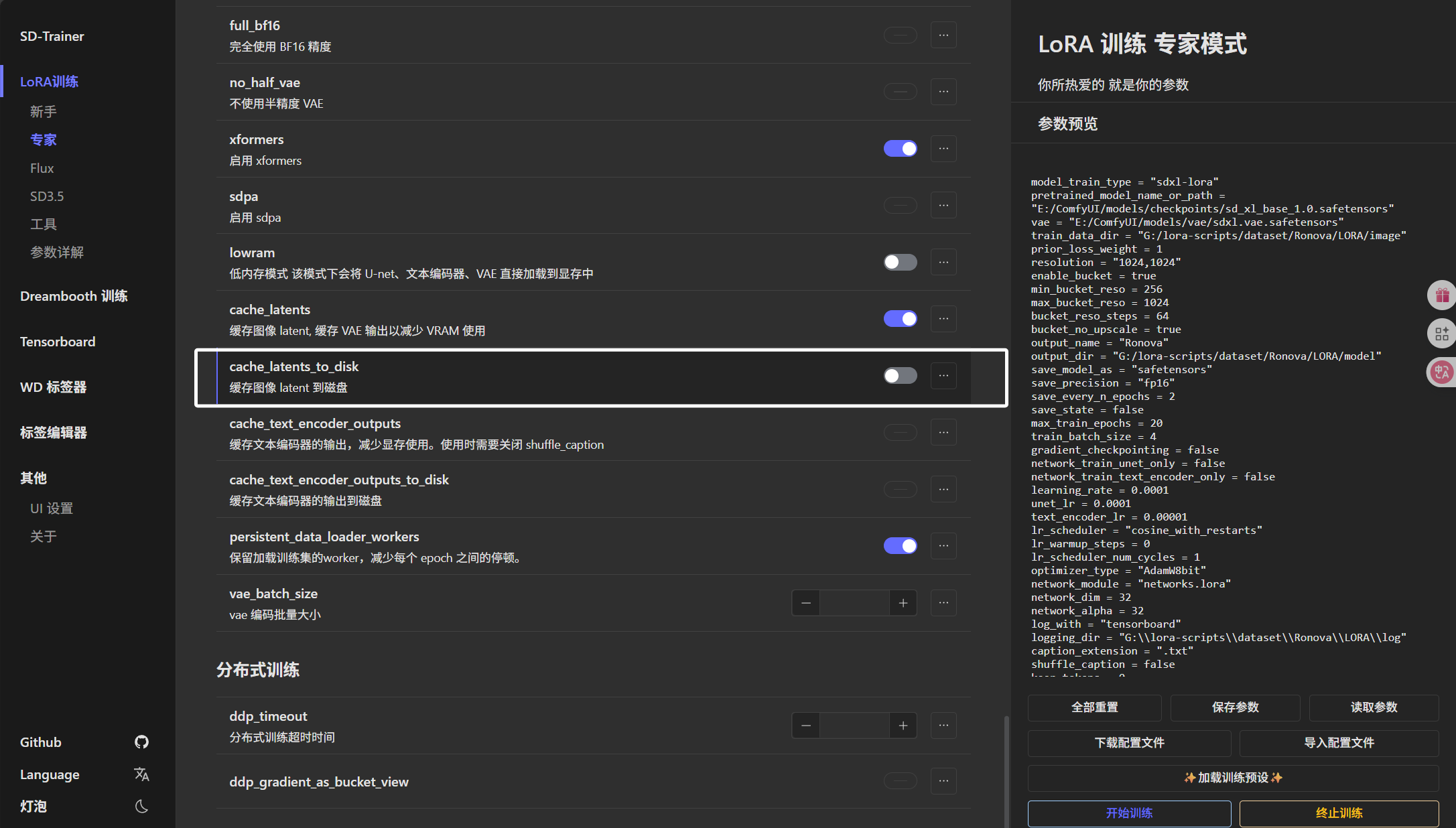
最后我们把“缓存图像 latent 到磁盘”配置为关:
配置完上面这些参数以后,我们直接点击“开始训练”:
过一会儿我们就能在终端中看到训练开始的日志了:

当我们看到这样的日志时,训练就开始了:
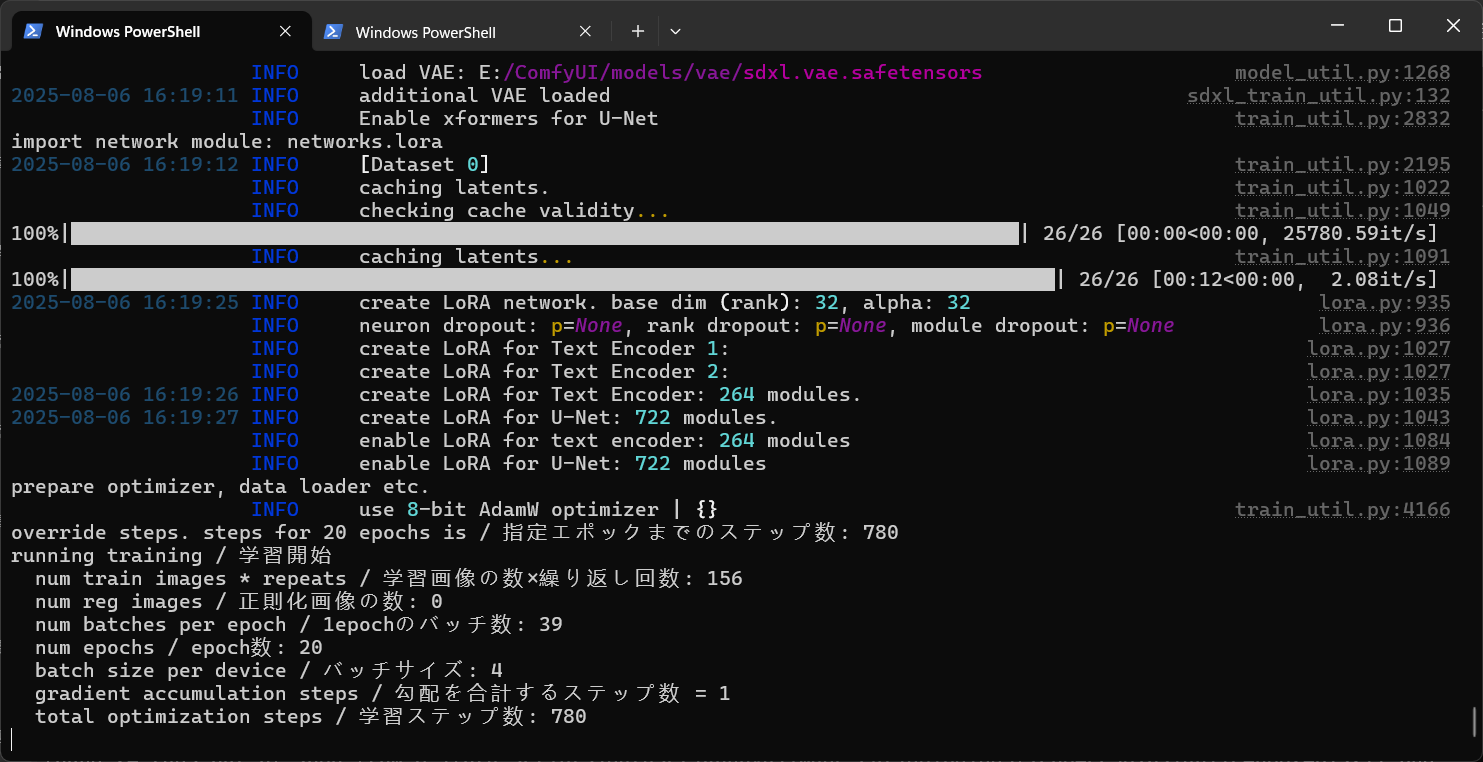
开始训练以后就会出现训练的速度以及预计时间: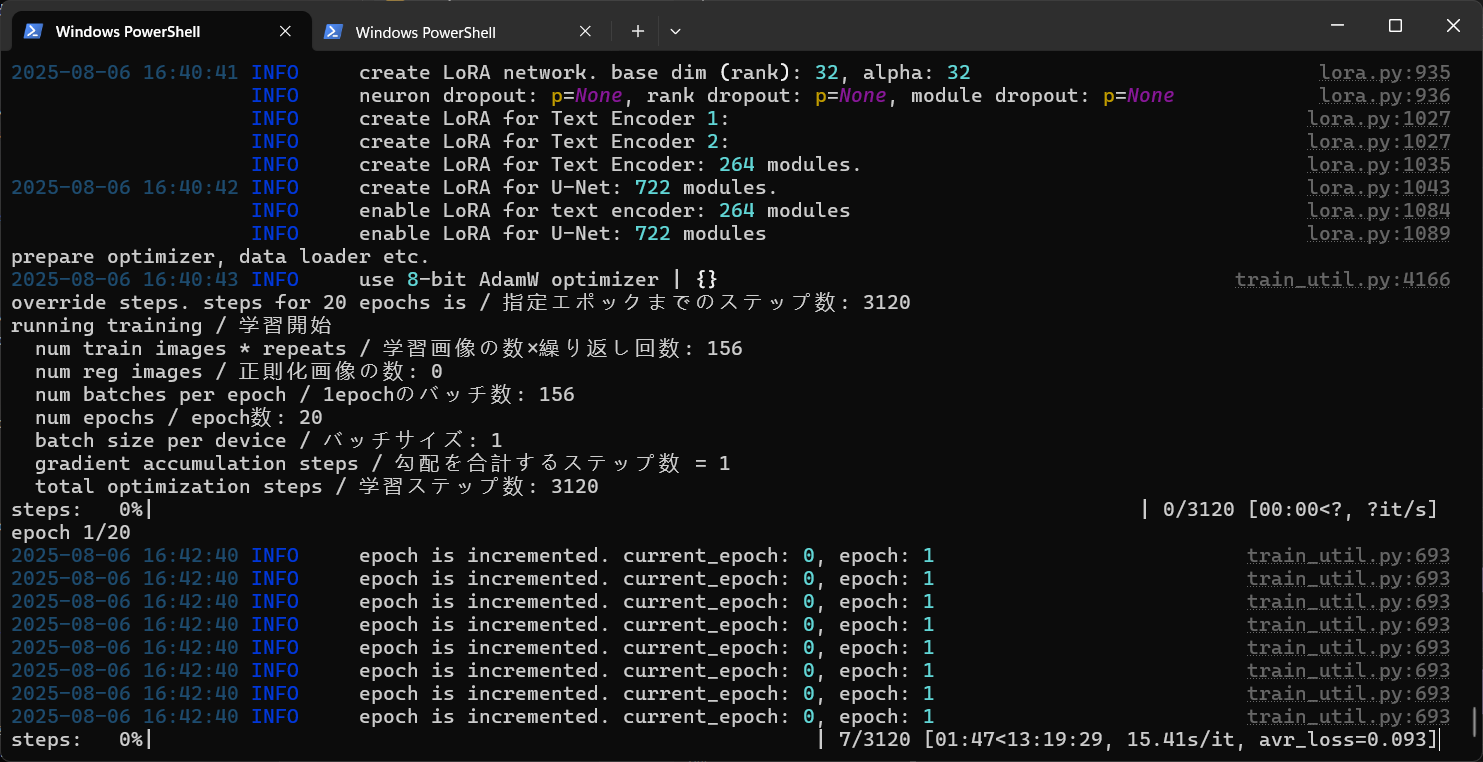
预计的时间一般不是最终的时间,实际训练完成大约2小时左右。
训练完成以后如图所示:
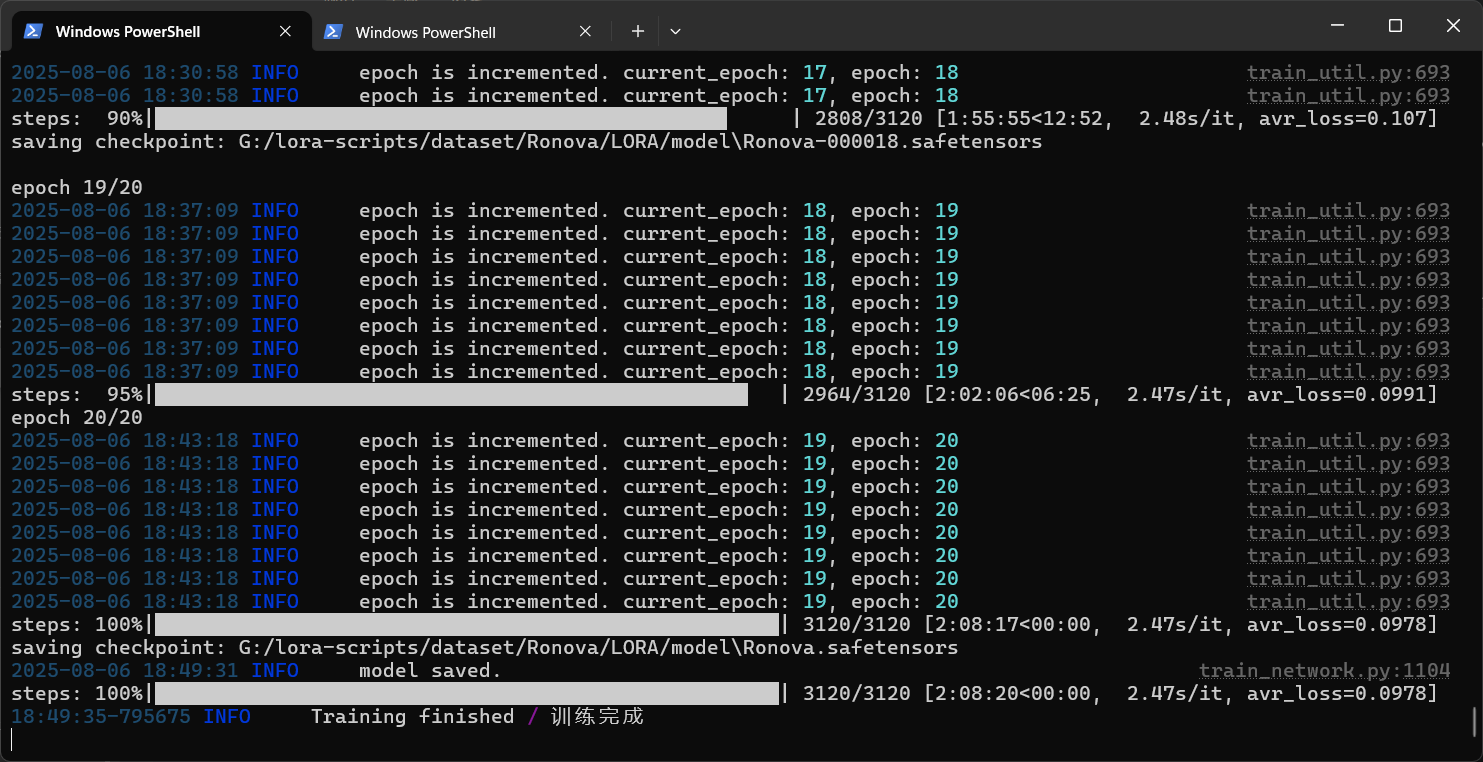
因为我们没有调整训练参数,所以这次训练使用了两个小时。后面会教大家如何调参数让我们的训练在一小时左右。
训练完成以后,我们前往“Ronova”文件夹下的“LORA/model”文件夹下就可以看到我们训练出来的模型了:
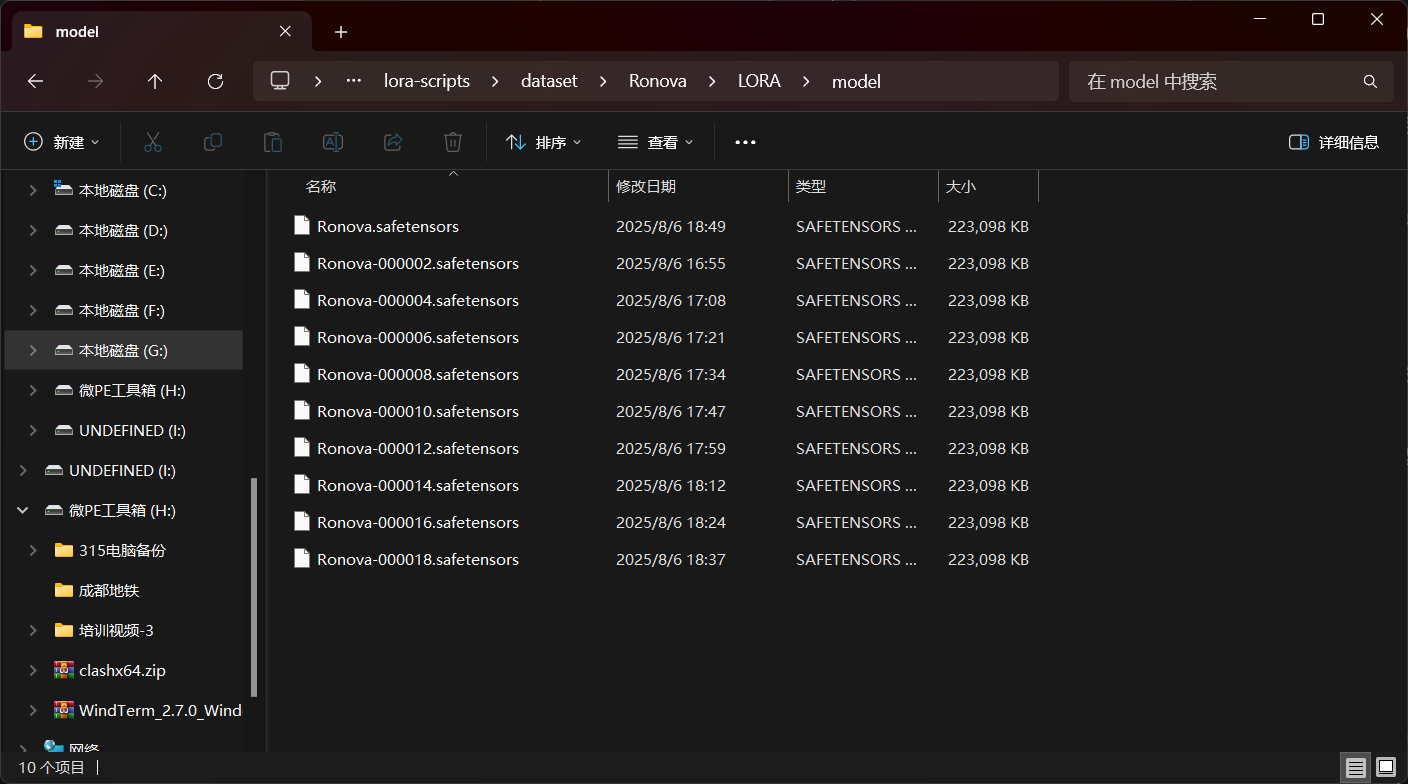
因为训练时每两步保存一次,所以我们训练中产生的模型都被保存下来了,当然,这些模型肯定都是有用的,下期教程会教大家如何使用,这里我们直接使用最后产出的“Ronova.safetensors”模型即可。
这里我们同样使用“SD WebUI”进行推理,当然,如果你熟悉ComfyUI的话也可以。
我们将SDXL的底模与我们训练出来的LORA放到“SD WebUI”对应的目录中:
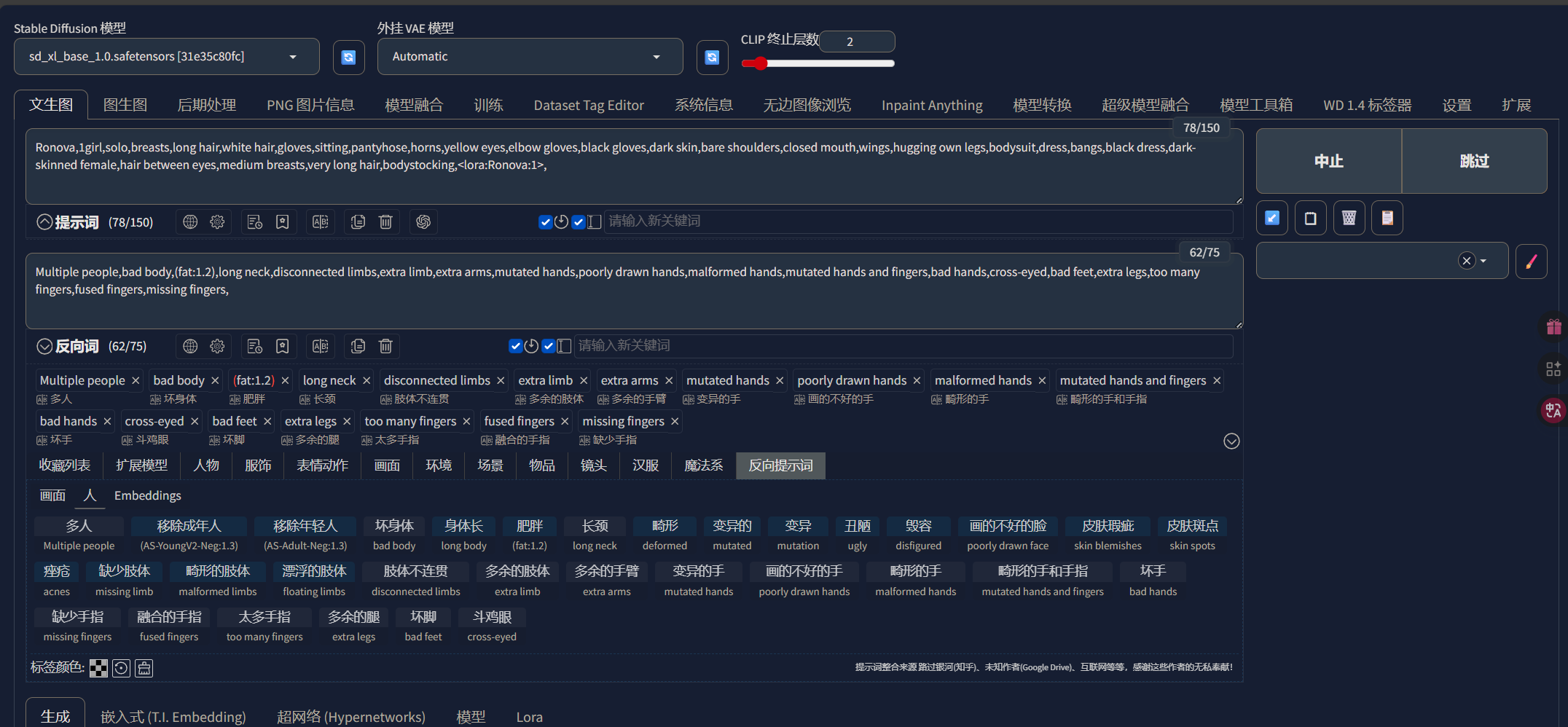
我们直接在“SD WebUI”中加载模型与LORA,随后输入正向提示词,这里的正向提示词我们可以直接复制我们反推出来的标签,然后随意加一些反向提示词,因为训练时分辨率使用的是1024x1024所以出图我同样使用这个分辨率:
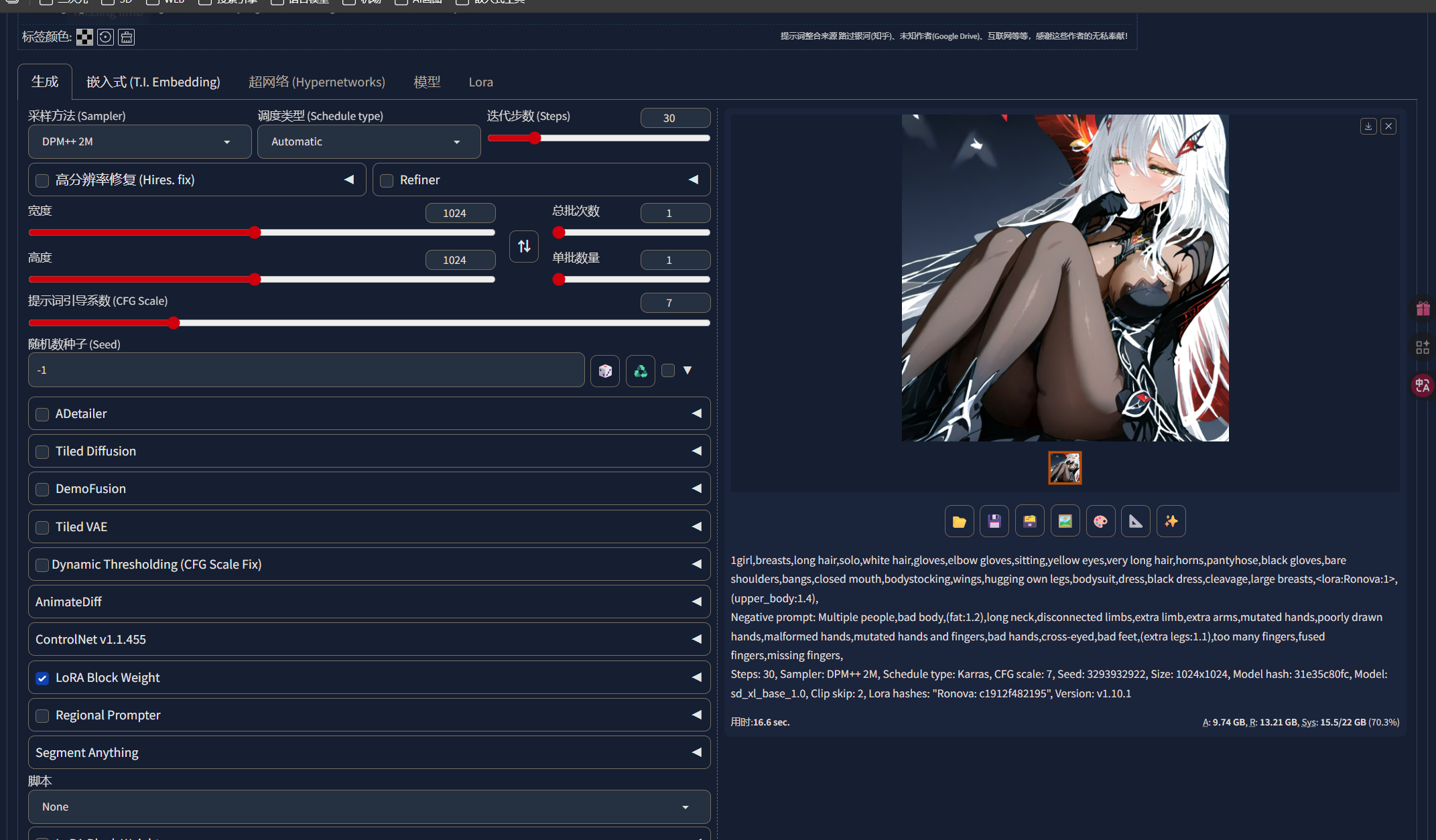
我们可以发现,LORA已经基本学会了“若娜瓦”的角色特征,并且能够基本还原角色了,说明我们的LORA训练是成功的:
至此,我们的SDXL LORA训练就完成了。
六、结语
在本次教程中,我们学习了如何从零到一的训练一个LORA,尽管我们目前训练出来的LORA还有许多问题,但是不用着急,在下一篇教程中,会教大家如何一一解决这些问题,从而提高我们出图的质量,那么最后,感谢大家的观看!