LAS平台Vibe Data Processing:AI驱动的数据处理新范式
在 AI 驱动业务创新的浪潮中,企业数据生态正面临根本性重构。据权威分析,2025 年全球数据总量将突破 180ZB,其中 80%为非结构化数据(图像、视频、音频等),而传统数据湖在处理多模态信息时有诸多不足,如存储与计算割裂导致 GPU 利用率低;跨模态治理时,文本、图像等异构数据需人工拼接处理链路;工具链断裂使 Copilot 生成的代码无法直接投产。
火山引擎多模态数据湖为此重构技术基座——通过 Lance 自研存储格式实现非结构化数据读写速度提升,依托 Ray 分布式引擎替代 Spark BSP 架构,以流水线计算将 GPU 利用率提升,更以自然语言交互内核打通从数据探索到模型落地的“最后一公里”。
这一变革直接催生了新的范式,在此模式下,工程师的核心价值正从编写代码转向定义问题,这正是 LAS 平台用 AI 原生引擎重构数据处理逻辑的起点。
本文将介绍火山引擎 LAS 平台的易用性功能,因该功能与当前热词“vibe”概念紧密关联且暂无精准中文表述,故命名为 Vibe Data Processing 。这本质上是通过融合数据处理、IDE 与大语言模型,构建满足用户数据处理诉求的完整流程。
工程师工作流的 AI 化变革
当前工程师工作方式正经历历史性转折。AI 不仅改变了工具形态,更重塑了核心工作流与竞争力,具体体现为三大变革:

编码辅助的质变:三年前,开发者依赖 IDE 语法提示、查阅文档与手动编码仍是常态;如今 92%的开发者将 AI 编程助手作为日常“副驾驶”。这不仅是工具升级,更是工作模式的颠覆——工程师通过自然语言与 AI 协作,由其生成逻辑片段、解释函数甚至编写测试,实现从“人操作工具”到“人机协同编程”的范式迁移。
核心能力要求重构:语言语法、算法、调试等硬技能逐渐让位于 AI 驾驭能力:需掌握精准描述需求的 Prompt 工程能力,高效判断与修正 AI 生成代码的 Judger 能力,以及将 AI 无缝整合工作流的实践能力。工程师核心价值正从编写代码转向定义问题、指导 AI 和架构创新。
技术进化的加速依赖:Scaling Law 推动模型理解力、代码生成力等能力指数级提升。工程师能否用 AI 赋能工作流,已成为区分效率与创新力的关键标尺。
在 AI 时代,数据开发面临全新挑战。传统工具无法满足 AI 辅助编程的深度集成需求,数据源集成需从“连得上”升级为“融得顺”。
过去数据探查只需对接 MySQL 或者 Hive,如今微调模型需串联 SaaS API、日志流、Iceberg 湖、Redis 缓存及 GPU 集群上的 Parquet 冷数据,这些分布在多云与边缘节点的数据要求 IDE 能像查询本地文件般操作远端数据快照,同时自动完成 Schema 对齐、权限映射与缓存预热。
多元异构数据管理需实现一站式“探改治发”。在 AI IDE 中,类似“近 7 天用户行为表有无新增字段”的自然语言探查成为刚需,这要求数据目录、血缘、质量等能力内嵌编辑器,且需兼容文本、图像、音频等非结构化数据。
工具链一体化也亟待突破,Copilot 秒级生成的 PySpark 作业需无缝衔接版本控制 Git、CI/CD、集群调试器和监控系统,理想状态是 AI IDE 借助 MCP Agent 等方式在编辑器内部把这些流程都串完成。通过自然语言的方式使用各种各样的 Tool。
Vibe Data Processing 的核心革新
针对上述挑战,LAS 推出 Vibe Data Processing 范式,当数据量指数级增长、分析训练需求日益复杂时,传统数据处理模式正成为瓶颈。而 Vibe Coding 将用 AI 原生引擎重构这一切。它的核心使命是:让业务需求直接驱动数据价值。
Vibe Data Processing 通过四层革新实现业务需求直驱数据价值:
自然语言驱动入口用户输入“聚合近三个月华北区销售数据”等指令,AI 实时解析语义、生成代码并连接多源数据,动态感知“时间范围与上次一致”等上下文,彻底消除重复配置。
自适应计算引擎面对海量数据,AI 自主拆解任务流程(如分区清洗→并行聚合),动态分配资源并在 Pandas/Spark 间智能切换。自修复能力自动处理类型冲突或缺失值,减少 90%调试中断。
可进化智能清洗用户通过“删除重复订单 ID”等描述,AI 调用预置算子构建流水线。每次操作抽象为可复用算子,系统主动推荐同类流程(如“复用地址标准化”),支持文本、图像多模态统一处理。
数据与模型闭环进化高质量数据训练评估模型并反向优化清洗规则,异常模式实时更新算子库。人类专家关键节点监督,AI 持续学习决策逻辑,所有过程通过自然语言注释保障可解释性。
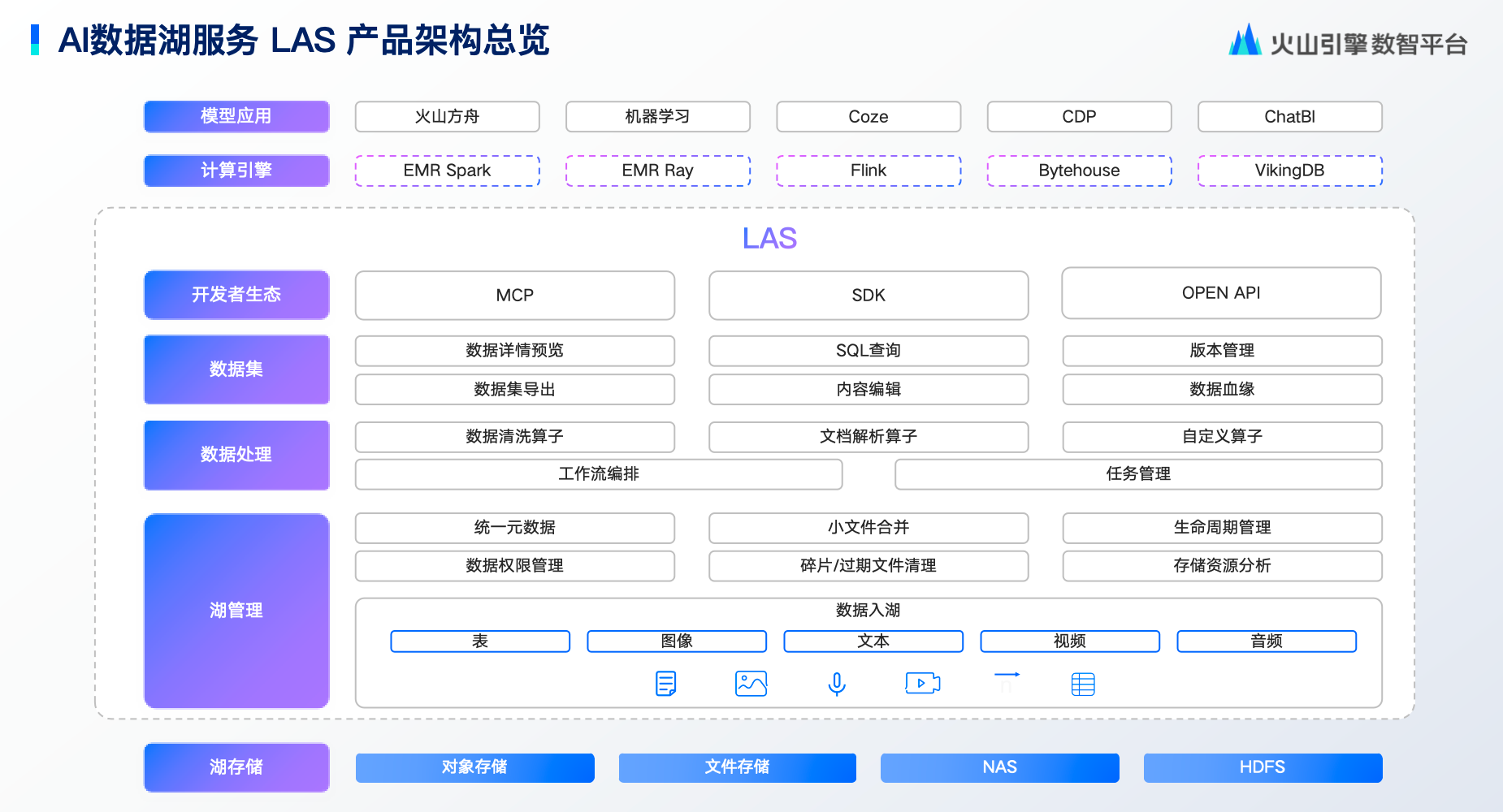
该范式由分层架构实现,LAS 平台架构提供实现基础。从底层看,数据存储层支持对象存储、文件存储等介质,根据数据加载需求动态优化存储方式,高性能需求调度至高速存储,成本敏感场景切换经济方案。
湖管理层集成元数据统一管理、小文件合并与生命周期管理,其突破在于对文本、图像等非结构化数据实现与传统数仓同级的精细治理。数据集管理层提供清洗转换能力,确保输出到训练阶段的数据质量。
顶层的训练推理层无缝对接方舟、机器学习等平台,实现数据集一键调用。用户可通过 MCP、SDK、OpenAPI 或可视化控制台全生命周期管理数据。
LAS 的核心优势体现在三个维度:
AI 原生设计:原生支持 PyTorch、TensorFlow 框架,打通火山引擎训练平台,实现“数据就绪即训练”。
多模态数据枢纽:统一存储文本/图像/音频/视频,自研湖格式读写速度较 Parquet 提升 40%,智能元数据分层支持 AI 按语义调用资源。
AI 数据闭环:数据回流、清洗、训练、反馈全链路自动流转,用户行为数据经 TOS 接入后,30 分钟完成处理并推送训练,当天启动模型训练,迭代周期从天级压缩至小时级。

MCP 技术实现与落地支撑
Model Context Protocol (MCP) 是实现落地的关键技术。MCP 是一套标准化数据上下文管理体系,其架构设计包含安全三层防护,用户请求经 ALB 应用负载均衡器过滤异常流量后,由网关动态路由至最近服务节点并签发 STS 安全令牌,最终实现私有数据的安全访问。
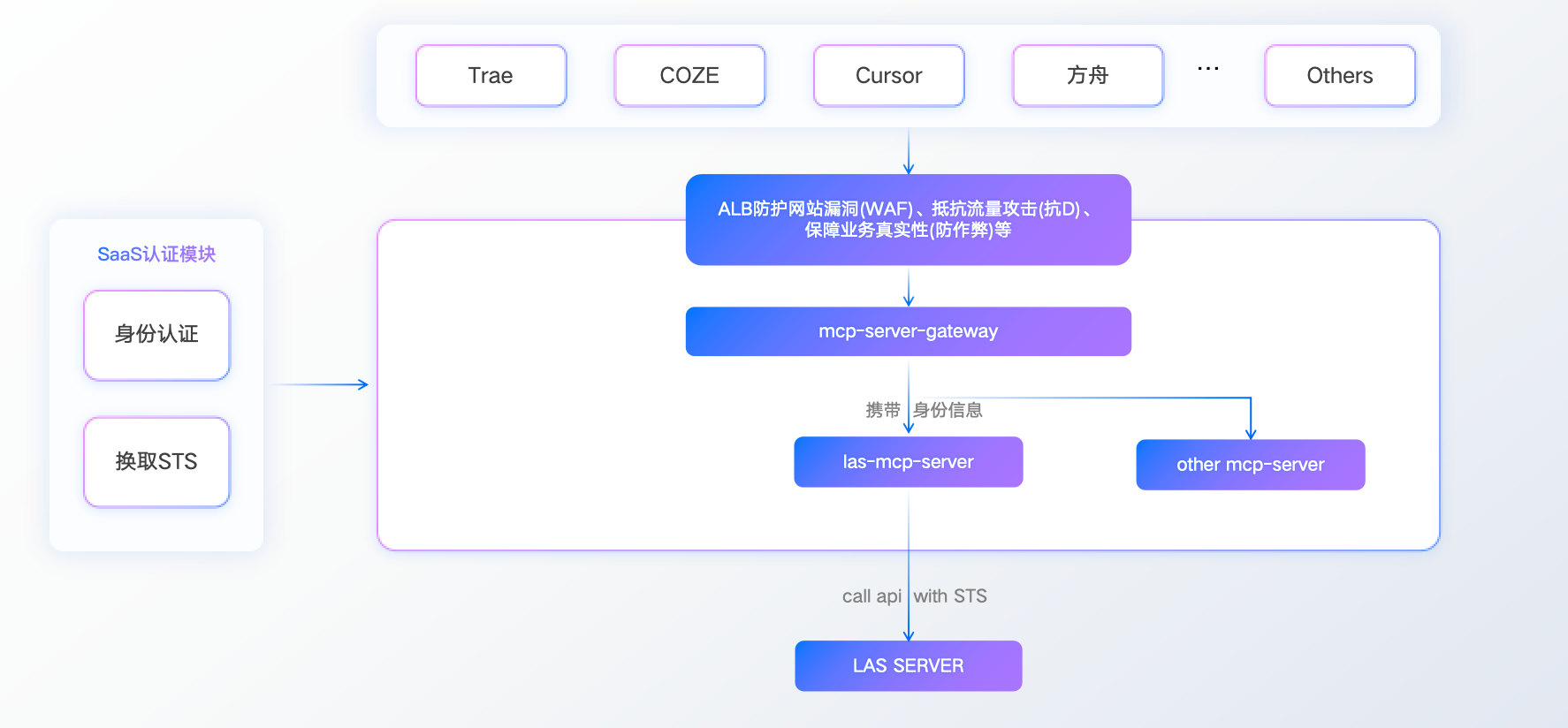
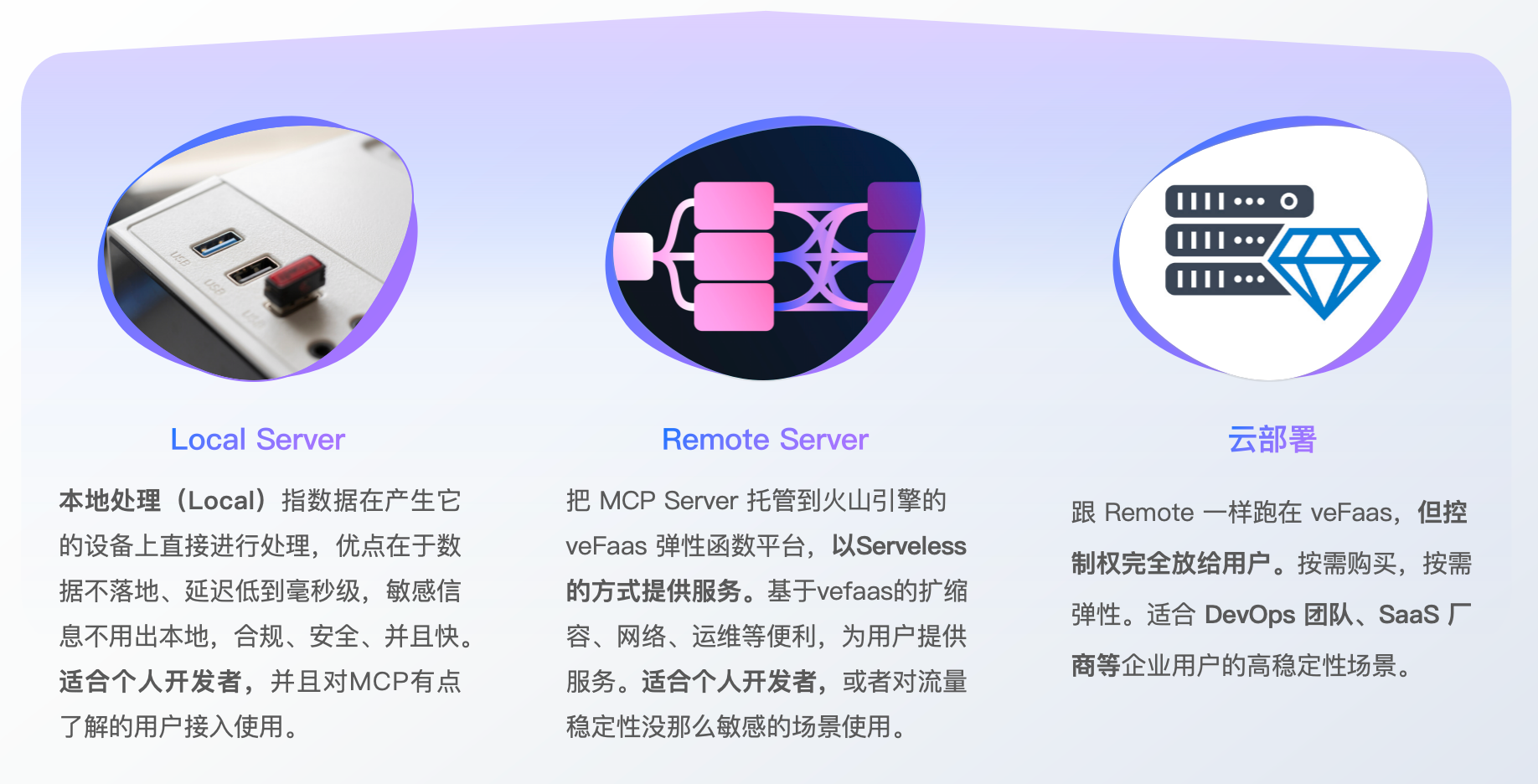
接入方式有以下三种:
Local Server:本地运行保障毫秒级延迟,数据不出内网。
Remote Server:基于 veFaas 提供 Serverless 服务,按需扩缩容。
云部署:托管于 veFaas 但用户完全控制,适配企业高稳定场景。
MCP 的本质是全生命周期编排协议,将数据管理、开发机、工作流等抽象为可编排节点,使自然语言指令可自动调度权限与资源。
为支撑 Vibe Data Processing 生态,LAS 提供算子编写 DemoProject 工程。该工程以开箱即用代码库覆盖主流数据处理场景,开发者可改写模板快速构建流水线;
更深度集成 AI 开发范式:结构化存储的海量案例形成知识图谱,通过 IDE 检索增强技术实现用户需求与历史实践的智能关联,开发者通过自然语言描述即可获得最优方案推荐。

同时,LAS 查询服务提供高性能独占方案:流量鉴权模块实时校验 Token 防越权访问;水平扩展能力以 30 秒粒度弹性伸缩;向量化执行+GPU 混合计算将 TP90 延迟压至 100 毫秒内,彻底解决资源争抢问题。

用户可通过火山引擎官网、AI 数据湖服务首页或方舟体验中心接入 MCP 功能,典型场景如通过 LAS + TRAE + MCP 调用 DOUBAO 图文模型自动完成照片标注。
结语
面对数据总量激增且 80%为非结构化数据的现实挑战,传统数据湖在处理多模态信息时暴露了效率、治理与工具链的瓶颈。
火山引擎 LAS 平台提出的 Vibe Data Processing 理念,通过 Lance 存储格式、Ray 分布式引擎提升非结构化数据处理效率,特别是自然语言交互内核的设计,显著简化了从数据探索到模型部署的流程。
这一技术范式正在重新定义数据处理的价值逻辑,使工程师能够更专注于定义问题而非编写底层代码,同时结合自适应计算引擎、可进化智能清洗以及数据与模型的闭环进化,让业务需求直接、高效地驱动数据处理过程。
在 LAS 平台的支撑下,通过 MCP 协议提供的标准化数据上下文管理和灵活接入能力,确保了数据访问的安全性与流程的顺畅性。LAS 架构自身提供的 AI 原生设计、多模态数据枢纽及高效 AI 数据闭环特性,共同为这一新模式打下了坚实基础。
总体而言,Vibe Data Processing 代表了数据处理领域适应 AI 时代需求的一种演进方向。它聚焦于提升工程师的工作效率,优化人机协作模式,并致力于缩短数据价值转化的路径。这种技术方式正在改变数据处理的方式,数据处理的核心竞争力,将越来越倚重通过自然语言精准定义需求和指导 AI 的能力。
未来属于用语言塑造代码,而非用代码限制语言的人。