[AI 生成] hive 面试题
hive 面试题
以下是 Hive 面试的核心知识点梳理,涵盖架构原理、SQL优化、数据管理和性能调优等高频考点,附详细解析和场景案例:
一、架构与核心概念
1. Hive 执行流程
图表
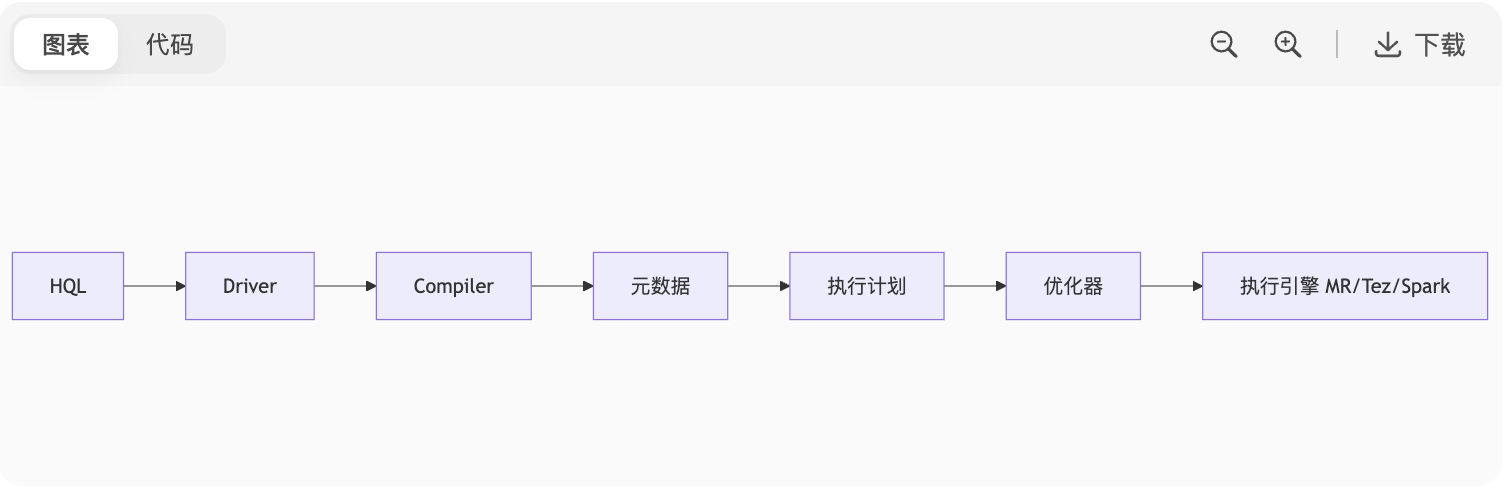
核心组件:
Driver:接收 HQL,管理生命周期
MetaStore:存储表结构、分区等元数据(独立部署防锁争用)
执行引擎:默认 MR,可切换 Tez/Spark
2. Hive vs RDBMS
| 特性 | Hive | RDBMS |
|---|---|---|
| 数据规模 | PB级 | TB级 |
| 延迟 | 分钟级+ | 毫秒级 |
| 事务 | 支持(Hive 0.13+) | 完善支持 |
| 索引 | 有限(位图/Compact索引) | B树/Hash索引 |
3. 内部表 vs 外部表
| 特性 | 内部表(Managed) | 外部表(External) |
|---|---|---|
| 数据存储 | Hive 管理目录 | 用户指定路径 |
| 删除表 | 元数据+数据文件全删 | 仅删元数据 |
| 适用场景 | 临时表/中间结果 | 多系统共享数据 |
二、SQL 与优化
4. Hive 优化策略
| 优化方向 | 具体方法 |
|---|---|
| 数据倾斜 | set hive.groupby.skewindata=true;(两阶段聚合) |
| MapJoin | set hive.auto.convert.join=true;(小表<25MB自动广播) |
| 压缩存储 | 使用 ORC/Parquet + Snappy 压缩 |
| 向量化查询 | set hive.vectorized.execution.enabled=true;(减少CPU开销) |
5. 分区 vs 分桶
| 机制 | 分区(Partition) | 分桶(Bucket) |
|---|---|---|
| 原理 | 按目录划分(如dt=20230101) | 按哈希值分文件(CLUSTERED BY user_id) |
| 优化点 | 减少全表扫描 | 提升Join/Sampling效率 |
| 最大数量 | 无限制(但过多导致NameNode压力) | 受桶数限制(建表时指定) |
6. 窗口函数实战
sql
-- 计算每个部门销售额排名(允许并列) SELECT dept_id, emp_name, sales,RANK() OVER (PARTITION BY dept_id ORDER BY sales DESC) AS rank FROM sales_table;
考点:RANK() vs DENSE_RANK() vs ROW_NUMBER()的区别
三、数据管理
7. 数据导入导出方式
| 方式 | 命令/场景 |
|---|---|
| 本地导入 | LOAD DATA LOCAL INPATH '/data/file' INTO TABLE t1; |
| HDFS导入 | LOAD DATA INPATH 'hdfs://path' [OVERWRITE] INTO TABLE t1; |
| 动态分区 | INSERT OVERWRITE TABLE t2 PARTITION(dt) SELECT ..., dt FROM t1; |
| CTAS | CREATE TABLE t3 AS SELECT ... FROM t2; |
8. 小文件问题解决
原因:HDFS 小文件导致 NameNode 内存压力
解决方案:
sql
-- 合并Map输出 SET hive.merge.mapfiles = true; -- 合并Reduce输出 SET hive.merge.mapredfiles = true; -- 合并后文件大小 SET hive.merge.size.per.task = 256000000; -- 256MB
9. 复杂数据类型操作
sql
-- 解析JSON数组(假设logs字段为:'{"actions":[{"type":"click","time":100},{"type":"view","time":50}]}')
SELECT get_json_object(logs, '$.actions[0].type') AS first_action,explode(split(regexp_replace(get_json_object(logs, '$.actions[*].type'), '[\\[\\"]', ''), ',')) AS action_type
FROM log_table;考点:explode()、get_json_object()、split()组合用法
四、性能调优
10. Explain 执行计划解读
sql
EXPLAIN SELECT dept_id, AVG(salary) FROM emp GROUP BY dept_id;
关键输出:
Map Operator Tree:扫描哪些表Reduce Operator Tree:是否触发ShufflePartition:分区剪裁是否生效(Pruned Paths)
11. Join 优化场景
| 场景 | 优化方案 |
|---|---|
| 大表 Join 大表 | 分桶表 + SMB Join(Sort Merge Bucket Join) |
| 小表 Join 大表 | MapJoin(自动或手动/*+ MAPJOIN(small_table) */) |
| 倾斜表 Join | set hive.optimize.skewjoin=true; + hive.skewjoin.key=100000(热点Key阈值) |
12. 参数调优清单
sql
-- 控制Reducer数量(避免过多小文件) SET hive.exec.reducers.bytes.per.reducer=256000000; -- 每个Reducer处理256MB-- ORC索引加速查询 SET hive.optimize.index.filter=true; -- 启用ORC布隆过滤器-- 启用CBO(Cost-Based Optimizer,Hive 2.0+) SET hive.cbo.enable=true; SET hive.compute.query.using.stats=true;
五、高级特性与实战
13. Hive ACID 事务实现
条件:表必须为分桶表 + ORC存储 +
TBLPROPERTIES('transactional'='true')操作:
sql
UPDATE employees SET salary = 8000 WHERE id = 101; DELETE FROM employees WHERE dept = 'HR';
14. Hive on Spark vs Hive on Tez
| 引擎 | 优点 | 缺点 |
|---|---|---|
| MR | 稳定 | 慢(磁盘I/O多) |
| Tez | DAG执行(减少中间落盘) | 内存管理复杂 |
| Spark | 内存计算 + 生态统一 | 部署复杂(版本兼容问题) |
15. Hive LLAP(Live Long and Process)
原理:常驻守护进程(缓存数据 + 执行计算)
效果:亚秒级响应(交互式查询)
启用:
SET hive.server2.mode=llap;
六、高频故障排查
16. MetaStore 连接失败
现象:
Failed to connect to MetaStore server...解决:
检查 MetaStore 服务状态
验证
hive-site.xml配置:xml
<property><name>hive.metastore.uris</name><value>thrift://metastore_host:9083</value> </property>
17. OOM(内存溢出)
场景:Reduce 阶段数据倾斜
解决:
sql
-- 增加Reducer内存 SET mapreduce.reduce.memory.mb=8192; SET mapreduce.reduce.java.opts=-Xmx6144m;
💡 面试技巧:
被问优化时,先讲分析思路(如通过
EXPLAIN看执行计划),再给具体方案强调生产经验(如:“曾用动态分区+ORC压缩将查询速度提升5倍”)
区分场景作答(例如:“小文件问题在实时数仓用Hudi解决,离线数仓用
hive.merge参数”)
HQL 面试题
以下是 Hive SQL(HQL)的高频面试题及深度解析,涵盖复杂查询、性能优化和实战场景,助你系统性备战:
一、复杂查询与函数
1. 行列转换
场景:将学生成绩表 scores(name, subject, score)转为姓名+科目列形式
sql
-- 行转列(Pivot) SELECT name,MAX(CASE WHEN subject='Math' THEN score END) AS math,MAX(CASE WHEN subject='English' THEN score END) AS english FROM scores GROUP BY name;-- 列转行(Unpivot) SELECT name, 'Math' AS subject, math AS score FROM pivot_table UNION ALL SELECT name, 'English' AS subject, english AS score FROM pivot_table;
2. 连续登录用户统计
场景:在登录表 user_logins(user_id, login_date)中找出连续登录7天的用户
sql
SELECT user_id, MIN(login_date) AS start_date, MAX(login_date) AS end_date FROM (SELECT user_id, login_date,login_date - INTERVAL DENSE_RANK() OVER(PARTITION BY user_id ORDER BY login_date) DAY AS grpFROM user_logins ) t GROUP BY user_id, grp HAVING COUNT(*) >= 7;
关键点:
DENSE_RANK()生成连续序号日期减序号构造连续标识组(
grp)
二、性能优化技巧
3. 数据倾斜优化
场景:大表 orders 的 user_id 存在热点 Key
sql
-- 方案1:MapJoin 广播小维度表 SELECT /*+ MAPJOIN(user_info) */ o.order_id, u.user_name FROM orders o JOIN user_info u ON o.user_id = u.user_id;-- 方案2:随机盐桶(两阶段聚合) SELECT user_id, SUM(cnt) AS total_orders FROM (SELECT CONCAT(user_id, '_', CAST(RAND()*10 AS INT)) AS salted_id, COUNT(*) AS cntFROM ordersGROUP BY CONCAT(user_id, '_', CAST(RAND()*10 AS INT)) ) t GROUP BY user_id;
4. 分区剪裁失效案例
错误写法(导致全表扫描):
sql
SELECT * FROM sales WHERE YEAR(dt)=2023; -- 分区字段dt为字符串格式'20230101'
正确优化:
sql
SELECT * FROM sales WHERE dt BETWEEN '20230101' AND '20231231';
原理:直接使用分区字段范围过滤,避免函数转换。
三、窗口函数实战
5. Top N 分析
场景:计算每个部门薪资最高的3名员工(允许并列)
sql
SELECT dept_id, emp_name, salary FROM (SELECT dept_id, emp_name, salary,DENSE_RANK() OVER(PARTITION BY dept_id ORDER BY salary DESC) AS rkFROM employee ) t WHERE rk <= 3;
6. 环比增长率计算
场景:计算每日销售额相比前一天的增长率
sql
SELECT dt, sales,(sales - LAG(sales,1) OVER(ORDER BY dt)) / LAG(sales,1) OVER(ORDER BY dt) AS growth_rate FROM daily_sales;
四、高级特性应用
7. JSON 数据解析
场景:解析日志表 log 中的 JSON 字段 ext_info(格式:{"device":"Android","os_version":"10"})
sql
SELECT get_json_object(ext_info, '$.device') AS device,get_json_object(ext_info, '$.os_version') AS os_version FROM log;
8. 复杂数组操作
场景:统计订单表 orders 中每个用户的订单ID列表
sql
SELECT user_id, COLLECT_LIST(order_id) AS order_ids -- COLLECT_SET 去重 FROM orders GROUP BY user_id;
五、执行计划与调优
9. Explain 分析
sql
EXPLAIN FORMATTED SELECT dept_id, AVG(salary) FROM employee GROUP BY dept_id;
关注要点:
STAGE DEPENDENCIES:阶段依赖关系Reducer Number:是否合理(hive.exec.reducers.bytes.per.reducer控制)Statistics:数据统计信息(需ANALYZE TABLE收集)
10. MapJoin 触发条件
sql
-- 手动指定 MapJoin(小表在右侧) SELECT /*+ MAPJOIN(b) */ a.id, b.name FROM big_table a JOIN small_table b ON a.id = b.id;-- 参数控制自动转换 SET hive.auto.convert.join=true; SET hive.mapjoin.smalltable.filesize=25000000; -- 小表阈值25MB
六、生产陷阱规避
11. 动态分区优化
sql
-- 启用动态分区 SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict;-- 避免小文件(合并Reduce输出) SET hive.merge.mapredfiles=true; SET hive.merge.size.per.task=256000000; -- 256MB
12. OOM 问题解决
场景:Reduce 阶段内存溢出
sql
-- 增加Reducer内存 SET mapreduce.reduce.memory.mb=8192; SET mapreduce.reduce.java.opts=-Xmx6144m;-- 启用倾斜优化 SET hive.groupby.skewindata=true;
附:高频考点速记
| 类型 | 核心语法 |
|---|---|
| 去重统计 | COUNT(DISTINCT uid) → 改用 GROUP BY uid 避免单Reducer瓶颈 |
| 分页查询 | ROW_NUMBER() OVER() AS rn WHERE rn BETWEEN 1001 AND 1010 |
| 空值处理 | COALESCE(col, 0) 替代 NVL() |
| 时间函数 | DATE_ADD(dt, 7), DATEDIFF(end, start) |
💡 面试技巧:
写复杂 HQL 前先口述逻辑(如:“先用窗口函数分组排序,再过滤TopN”)
被问优化时强调数据特征(如:“当热点Key占比超60%时采用随机盐桶”)
区分执行引擎差异(如:“Tez引擎下DAG优化可减少Shuffle落盘次数”)