python:非常流行和重要的Python机器学习库scikit-learn 介绍
scikit-learn 是如此重要,是Python 机器学习的瑞士军刀,以至于我们需要单独对它进行一些介绍。scikit- learn 包含众多顶级机器学习算法,它主要有六大类的基本功能,分别是分类、回归、聚类、数据降维、模型选择和数据预处理。
Scikit-learn 核心模块给大家统计如下。
1. 数据预处理与特征工程
| 功能类别 | 主要函数/类 | 关键参数 | 应用场景 | 版本增强 |
|---|---|---|---|---|
| 标准化缩放 | StandardScaler | with_mean, with_std | 高斯分布数据预处理 | 0.12+ |
MinMaxScaler | feature_range | 神经网络输入归一化 | 0.13+ | |
RobustScaler | quantile_range | 含异常值数据 | 0.17+ | |
| 编码转换 | OneHotEncoder | drop, sparse_output | 类别特征转换 | 0.20+ 增强 |
OrdinalEncoder | categories | 有序类别编码 | 0.20+ | |
LabelEncoder | - | 目标变量编码 | 初始版本 | |
| 缺失值处理 | SimpleImputer | strategy, fill_value | 缺失值填补 | 0.20+ 重构 |
KNNImputer | n_neighbors, weights | 基于近邻的缺失值填补 | 0.22+ | |
| 特征生成 | PolynomialFeatures | degree, interaction_only | 特征多项式扩展 | 0.10+ |
FunctionTransformer | func, inverse_func | 自定义特征转换 | 0.17+ | |
| 特征选择 | SelectKBest | score_func, k | 基于统计检验的特征选择 | 0.13+ |
RFE (递归特征消除) | estimator, n_features_to_select | 包裹式特征选择 | 0.16+ |
2.分类算法
| 算法类型 | 实现类 | 关键超参数 | 时间复杂度 | 适用数据规模 |
|---|---|---|---|---|
| 线性模型 | LogisticRegression | C, penalty, solver | O(n_samples * n_features) | 10^6样本 |
Perceptron | penalty, alpha | O(n_samples * n_features) | 10^6样本 | |
| 支持向量机 | SVC | C, kernel, gamma | O(n_samples^2 * n_features) | 10^4样本 |
NuSVC | nu, kernel | O(n_samples^2 * n_features) | 10^4样本 | |
| 决策树 | DecisionTreeClassifier | max_depth, criterion | O(n_samples * n_features * log(n_samples)) | 10^5样本 |
| 集成方法 | RandomForestClassifier | n_estimators, max_depth | O(n_estimators * n_samples * n_features * log(n_samples)) | 10^6样本 |
GradientBoostingClassifier | learning_rate, max_depth | O(n_estimators * n_samples * n_features) | 10^5样本 | |
AdaBoostClassifier | n_estimators, algorithm | O(n_estimators * n_samples * n_features) | 10^5样本 | |
| 神经网络 | MLPClassifier | hidden_layer_sizes, activation | O(n_samples * n_features * hidden_units) | 10^5样本 |
| 朴素贝叶斯 | GaussianNB | var_smoothing | O(n_classes * n_features) | 10^6样本 |
MultinomialNB | alpha | O(n_classes * n_feature |
3.回归算法
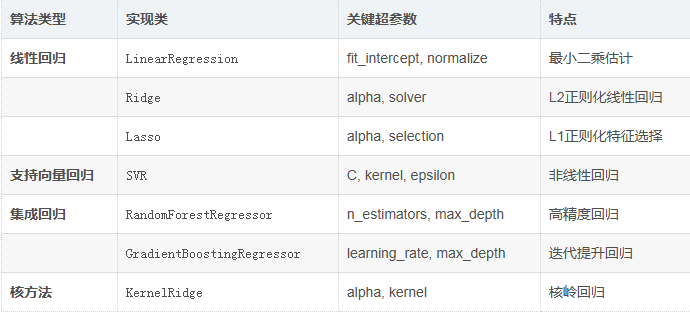
4.聚类算法
| 算法类型 | 实现类 | 关键超参数 | 适用场景 | 创新版本 |
|---|---|---|---|---|
| 划分聚类 | KMeans | n_clusters, init | 球形簇、均匀大小 | 0.23+ 优化 |
MiniBatchKMeans | batch_size | 大规模数据 | 0.13+ | |
| 密度聚类 | DBSCAN | eps, min_samples | 任意形状簇、噪声识别 | 初始版本 |
| 层次聚类 | AgglomerativeClustering | n_clusters, linkage | 簇层次结构分析 | 0.14+ |
| 谱聚类 | SpectralClustering | n_clusters, affinity | 图结构数据 | 0.15+ |
| 高斯混合 | GaussianMixture | n_components | 概率软聚类 | 0.18+ |
5.降维与流形学习
| 算法类型 | 实现类 | 关键超参数 | 降维能力 | 计算复杂度 |
|---|---|---|---|---|
| 矩阵分解 | PCA | n_components, svd_solver | 线性降维 | O(n_samples^2 * n_features) |
TruncatedSVD | n_components, algorithm | 稀疏数据降维 | O(n_samples * n_features) | |
| 流形学习 | TSNE | perplexity, learning_rate | 可视化降维 | O(n_samples^2 * n_features) |
Isomap | n_neighbors, n_components | 非线性降维 | O(n_samples^2 * n_features) | |
| 特征选择 | FactorAnalysis | n_components, svd_method | 隐变量提取 | O(n_samples^2 * n_fe |
6.模型验证
| 工具类 | 主要功能 | 关键参数 | 输出类型 |
|---|---|---|---|
cross_val_score | 自动交叉验证评分 | scoring, cv | 评分数组 |
cross_validate | 多指标交叉验证 | scoring, return_train_score | 结果字典 |
learning_curve | 生成学习曲线数据 | train_sizes, cv | 训练/验证得分 |
7.超参数优化
| 工具类 | 优化策略 | 适用场景 | 并行能力 |
|---|---|---|---|
GridSearchCV | 网格搜索 | 小参数空间 | 全并行 |
RandomizedSearchCV | 随机搜索 | 大参数空间 | 全并行 |
HalvingGridSearchCV | 连续减半搜索 | 大规模参数空间 | 部分并行 |
8.评估指标
| 指标类型 | 分类指标 | 回归指标 | 聚类指标 |
|---|---|---|---|
| 基础指标 | accuracy_score | mean_squared_error | adjusted_rand_score |
| 概率指标 | roc_auc_score | r2_score | silhouette_score |
| 多类别指标 | f1_score (average=macro) | explained_variance_score | calinski_harabasz_score |
| 不平衡数据 | balanced_accuracy_score | mean_absolute_percentage_error | davies_bouldin_sco |
伙伴们可以保存使用。
请大家点赞 、收藏和加关注吧。