阿里 Qwen-Image:开源 20B 模型引领图像生成新纪元,中文渲染超越 GPT-4o!
I. 引言
阿里巴巴通义团队于 2025 年 8 月 4 日正式开源了通义万相(Qwen-Image),这是一款 200 亿参数的多模态扩散 Transformer(MMDiT)图像基础模型,标志着通义系列在大型语言模型(LLMs)成功之后,向多模态 AI 领域的重大拓展 。这一开源举措使其成为 DALL-E 2/3、Midjourney 和 GPT-4.1 等现有专有模型的直接竞争者,为业界提供了免费且可访问的高性能替代方案 。(Analytics Vidhya)

Logo
通义万相的核心亮点在于其卓越的文本渲染能力、精准的图像编辑功能以及在各项基准测试中的出色表现。在文本渲染方面,该模型在处理复杂文本,特别是中文文本时,展现出显著优势,超越了 LongText-Bench、ChineseWord 和 CVTG-2K 等专业基准测试中的现有先进模型(参见如下图) 。
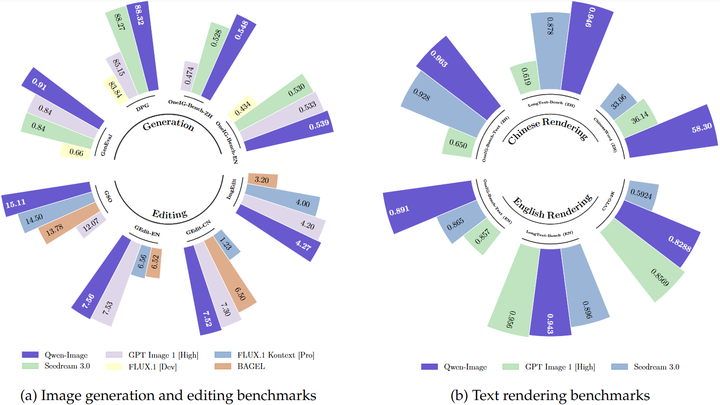
Qwen-Image exhibits strong general capabilities in both image generation and editing
它能高保真地处理多行布局、段落级语义和精细细节,无论是字母语言(如英语)还是表意语言(如中文)均表现出色 。在图像编辑方面,通义万相在修改过程中能出色地保持语义一致性和视觉真实感,支持风格迁移、对象插入或移除、细节增强、图像内文本修改乃至人体姿态操控等多种高级操作 。在综合基准测试中,通义万相在图像生成(GenEval、DPG、OneIG-Bench)和图像编辑(GEdit、ImgEdit、GSO)方面均与顶级模型持平或领先 。
发布背景及其在快速演进的 AI 格局中的定位
通义万相的发布是阿里巴巴一项重要的战略举措,旨在顺应开源 AI 模型日益加速的采用趋势。目前,89% 使用 AI 的组织都在利用开源 AI 解决方案,其中 66% 的组织认为开源模型比专有模型更具成本效益 。这一趋势使得通义万相能够有效捕捉并服务于那些优先考虑灵活性和成本效益而非专有功能的市场细分领域 。

通义万相发布
通义万相进入了一个竞争激烈的生成式 AI 市场,其中模型在性能基准测试中的排名直接影响其采用决策。该模型旨在直接挑战 OpenAI 的 GPT-4.1/GPT-4o、DALL-E 和 Midjourney 等专有模型的市场主导地位 。通义万相作为“开源权重”模型的反复强调,不仅仅是一个描述性事实,更是一个核心战略优势。在日益两极分化、一边是封闭专有系统、另一边是开放灵活的替代方案的市场中,通义万相的可访问性可以促进开发者和企业的广泛采用。这提供了一个引人注目的价值主张:高性能而没有供应商锁定或过高的经常性成本,这可能导致先进图像生成能力的“平民化”,并围绕该模型形成一个强大的社区,类似于 Stable Diffusion 所产生的影响。
🧠 媒体与专家解读
1. 开源与创新性
Qwen-Image 的开源性(Apache 2.0 授权)使其成为开发者和创作者的有力工具。它不仅在图像生成方面表现出色,还在文字渲染方面取得了突破,特别是在处理中文字符方面,表现优于许多现有模型。(WinBuzzer)

Qwen-Image demos
2. 技术架构与性能
该模型采用了先进的 MMDiT 架构,结合了 Qwen2.5-VL 视觉语言模型进行语义编码,并使用变分自编码器(VAE)进行像素级重构。这种双重编码机制使得 Qwen-Image 在图像编辑时能够精确地保持语义一致性和视觉真实性。在多项公开基准测试中,Qwen-Image 在图像生成和编辑任务上均表现出色,特别是在长文本、中文字符和复杂排版的渲染方面,超越了现有的先进模型。(Qwen)
3. 应用场景与实用性
Qwen-Image 在创建海报、幻灯片、商店橱窗展示等需要精确文字渲染的图像方面表现尤为出色。它支持中英文混排、各种字体和复杂布局,能够生成高质量的图像,满足专业内容创作的需求。(xugj520.cn)
4. 开放生态与未来展望
Qwen-Image 的开源发布是阿里巴巴在 AI 领域开放生态建设的一部分,展示了其在图像生成和编辑方面的实力。未来,Qwen-Image 还计划推出专门的图像编辑版本,进一步扩展其应用场景。
🔗 试用与资源
-
官方博客与技术报告:Qwen-Image: Crafting with Native Text Rendering
-
模型下载与试用:
-
Hugging Face
-
ModelScope
-
GitHub
II. 技术实力:能力与架构
A. 核心架构创新
通义万相的核心架构建立在三个关键组件之上,共同赋予其卓越的性能。
-
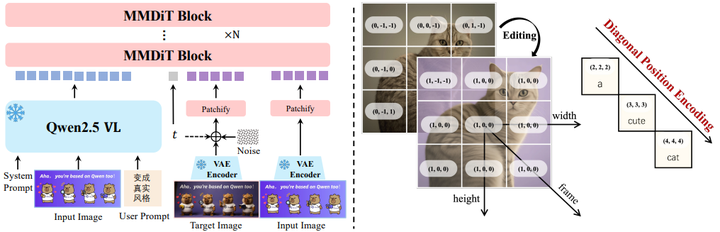
多模态扩散变压器(MMDiT)骨干网络:通义万相的核心是其200亿参数的MMDiT架构。这种架构的独特之处在于它能够同时理解和处理多种数据类型,特别是文本和图像。它有效地结合了扩散模型的优势——将噪声输入细化为连贯图像——以及Transformer模型的优势,后者擅长管理文本和视觉元素之间的复杂关系(参考下图)。
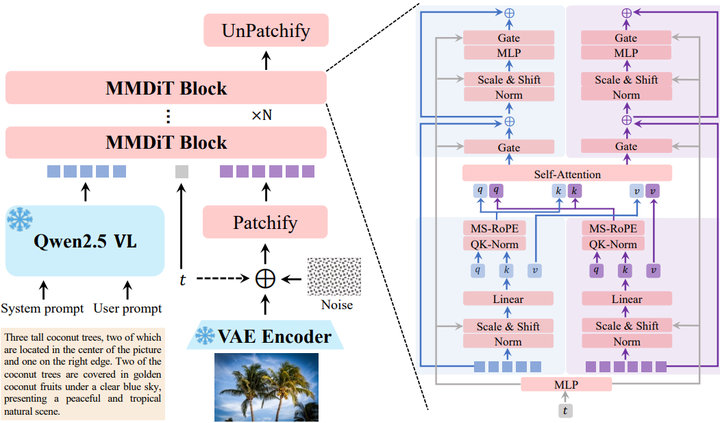
Overview of the Qwen-Image architecture
-
通义千问 2.5-VL MLLM 和微调 VAE 的作用:通义千问 2.5-VL 模型是文本输入特征提取的关键模块 。选择该模型基于三个主要原因:首先,通义千问 2.5-VL 的语言和视觉空间已对齐,使其比纯语言模型更适合文本到图像任务;其次,它在不显著降低性能的情况下保持了强大的语言建模能力;第三,它支持多模态输入,从而实现更广泛的功能,包括图像编辑 。通义万相使用通义千问 2.5-VL 语言模型骨干网络最后一层隐藏状态的潜在表示作为用户输入的表示,并为纯文本输入和文本-图像输入设计了不同的系统提示以更好地引导模型 。一个经过定制微调的变分自编码器(VAE)作为图像分词器,负责将输入图像压缩成紧凑的潜在表示,并在推理过程中将其解码回可见图像 7。该 VAE 采用单编码器、双解码器架构(Wan-2.1-VAE),其中仅对图像解码器进行微调,而编码器保持冻结状态(如下图,arXiv)。这种设计旨在创建更通用的视觉表示,兼容图像和视频,将通义万相定位为未来视频模型的基础骨干 7。为了确保高重建保真度,特别是对于小文本和精细细节,解码器在内部的富文本图像语料库上进行了专门训练,包括真实世界文档和字母及表意语言的合成段落 7。
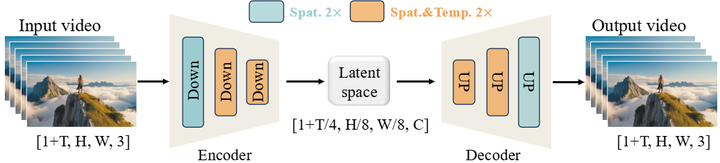
Wan-VAE Framework
-
多模态可伸缩旋转位置编码 (MSRoPE) 对文本集成的重要性: 多模态可伸缩旋转位置编码(MSRoPE)是一种新颖的位置编码方法,是集成在每个 MMDiT 块中的关键创新。MSRoPE 通过将文本输入视为具有相同位置 ID 的 2D 张量来解决多模态模型中长期存在的挑战,有效地将文本沿图像网格的对角线定位 。这种巧妙的设计使得 MSRoPE 能够利用图像侧的分辨率缩放优势,同时保持文本侧与 1D-RoPE 的功能等效性,从而无需确定文本的最佳位置编码,并关键性地防止模型将文本与视觉元素混淆 。MSRoPE 的引入是一项关键的技术进步。以往的多模态模型在区分文本与周围图像像素方面常常面临固有的困难,这通常导致文本失真或难以辨认。MSRoPE 将文本视为沿图像网格对角线对齐的 2D 张量的创新方法,直接解决了这一核心架构限制。这不仅仅是一个功能,它代表了一种根本性的工程解决方案,使得通义万相能够实现其“原生文本渲染”能力。这凸显了在无缝集成文本和图像模态方面对底层复杂性的深刻理解。
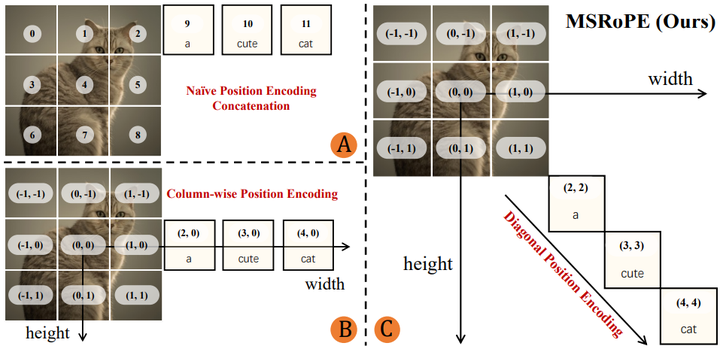
Multimodal Scalable RoPE (MSRoPE)
B. 强大的文本渲染
文本渲染的“七阶段过滤管道”和“三策略数据合成方法(纯渲染、组合渲染、复杂渲染)”(参考下图) 的详细描述,揭示了其强大的以数据为中心的工程理念。这不仅仅是获取大量数据集,还包括细致的策划、多阶段过滤以及特定数据类型(纯渲染、组合渲染、复杂渲染)的合成生成,以解决长尾分布和文本渲染等已知弱点。这种严格的方法表明,要实现 SOTA 性能,特别是在文本集成等具有挑战性和细微差别的领域,不仅需要先进的模型架构,还需要高度复杂和有针对性的数据工程。
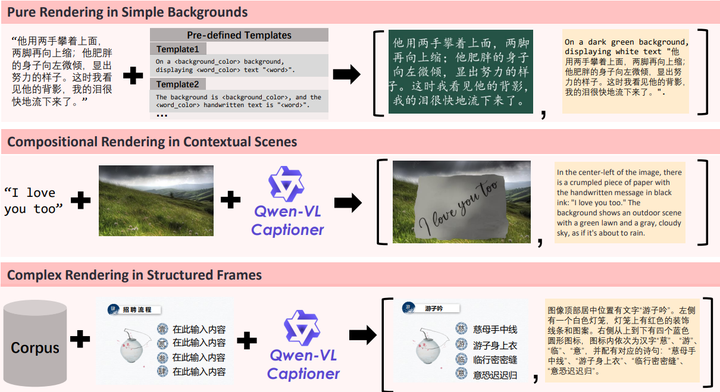
Pure Rendering,Compositional Rendering , and Complex Rendering
-
对多语言文本(中文和英文)的高保真支持: 通义万相以其卓越的复杂文本渲染能力而脱颖而出,能够高保真地保持中英文文本的准确性,包括图像中的混合语言文本 。
-
处理复杂布局、多行文本和段落级语义: 该模型能够稳健支持多行布局、段落级语义和精细文本细节 。演示案例包括生成带有精确文本布局的电影海报、准确渲染泛黄纸张上的手写诗,以及创建复杂的图表幻灯片 。这种先进的能力直接得益于其全面的数据管道(包括细致的数据收集、过滤、标注、合成和平衡)以及渐进式训练策略,该策略逐步引入从简单到复杂段落级描述的文本输入(参考下图) 。

Showcase of Qwen-Image in complex text rendering
C. 先进的图像编辑
-
编辑过程中语义意义和视觉真实感的持续保持:通义万相在图像编辑操作中,能出色地保持图像的语义意义和视觉真实感。这归因于其增强的多任务训练范式,确保了修改的连贯性和上下文适宜性 。其框架结构如下图:
Overview of the Image Editing (TI2I) task
-
多样化的功能: 该模型支持广泛的编辑操作,包括风格迁移、无缝对象插入或移除、细节增强、图像内精确文本编辑,甚至人体姿态操控 。这种控制水平使得专业级编辑触手可及,即使是普通用户也能轻松实现(参考下图)。

Qualitative comparison on object editing (addition, removal, and replacement)
D. 全面视觉理解
-
对象检测、语义分割和深度估计等任务的集成:它支持一系列图像理解任务,包括对象检测、语义分割、深度估计、边缘检测(Canny)、新视角合成和超分辨率(参考下图)。这种深度的视觉理解能力使模型能够准确解释和精确操控各种图像元素 8,使其成为视觉分析和其他计算机视觉应用的通用工具 。

Qwen-Image in general image understanding tasks
III. 性能分析与竞争格局
A. 基准测试中的主导地位
通义万相在多个图像生成、图像编辑和文本渲染基准测试中表现出色。
图像生成、图像编辑和文本渲染的详细性能
-
通用图像生成: 通义万相展现出持续强劲的性能,在关键基准测试中经常超越现有模型并达到最先进(SOTA)水平。例如,它在 GenEval 上得分 0.91,在 DPG 上得分 88.32(参考下图),在 OneIG-Bench 上得分 15.11。
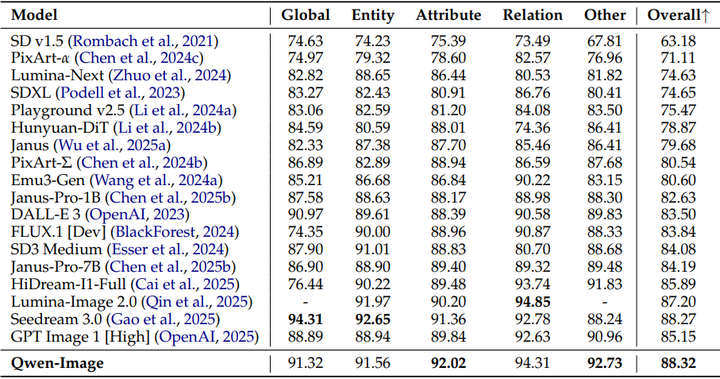
Quantitative evaluation results on DPG
-
图像编辑: 该模型在图像编辑基准测试中达到 SOTA 性能,在 GEdit-EN 和 GEdit-CN 上得分如下图,在 ImgEdit-EN 上得分 4.27。
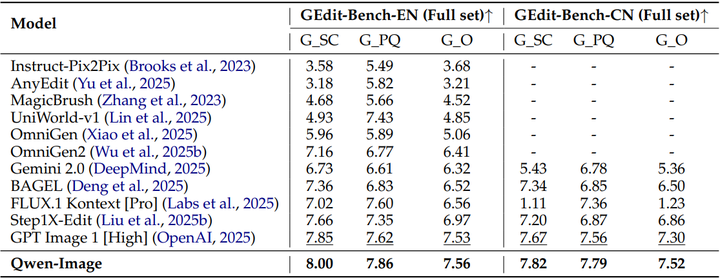
Comparison of Semantic Consistency (G_SC), Perceptual Quality (G_PQ), and Overall Score(G_O) on GEdit-Bench
-
文本渲染: 这是通义万相的突出领域,尤其是在中文文本生成方面。它在 LongText-Bench(英文:0.943,中文:0.946)(如下图)、ChineseWord(58.30)、TextCraft 和 CVTG-2K 等基准测试中显著优于竞争对手 。
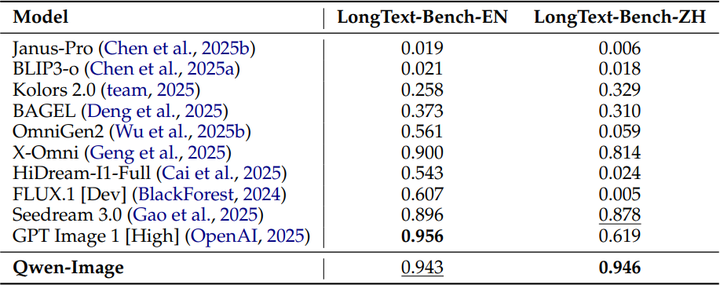
Quantitative evaluation results on LongText-Bench
B. 行业比较
通义万相作为 AI Arena 排行榜上“唯一进入前 10 的开源模型” ,是一项显著成就,使其成为许多人眼中领先的可访问模型。然而,用户反馈指出,在通用图像生成方面,特别是在复杂的信息图表方面,它仍存在一些“不足”和“在处理大量上下文时遇到困难”,这与它“近乎完美”的编辑能力形成对比。这表明“最先进”的定义是细致入微的:通义万相在特定任务(文本渲染、编辑一致性)和开源领域内是领先的,但在与 Imagen 4 Ultra 等顶级专有模型相比时,它可能尚未在所有图像生成任务中达到绝对领先。这创造了一种“对大多数用户足够好”与“绝对最佳”之间的动态,将影响其采用轨迹。
通义万相与专有模型(GPT-4.1/GPT-4o、DALL-E、Midjourney、Imagen 4 Ultra)的对比: 通义万相明确旨在挑战这些领先专有模型的霸主地位。虽然其文本渲染能力卓越,但 Analytics Vidhya 的用户评论表明,它在通用图像生成方面,特别是在复杂信息图表方面,仍需改进才能真正与 OpenAI、谷歌或 X 的模型在整体性能上匹敌 (Reddit)。GPT-4.1 和 Seedream3.0 被认为是通用生成和编辑基准测试中的有力竞争者。在文本集成方面,DALL-E 3 以其无缝集成文本并产生令人信服的 3D 效果而著称 。然而,通义万相的专门训练使其在处理复杂文本布局,特别是中文等表意文字方面具有独特的优势 。Midjourney 虽然在真实感、一致性和提示保真度方面表现出色,但在准确文本集成方面存在问题 。在 AI Arena 排行榜上,通义万相紧随 Imagen 4 Ultra 之后 (参考如下表)。

通义万相与领先模型对比分析(优势与劣势)
与其他开源模型(Seedream3.0、FLUX.1)的对比: 通义万相在各项基准测试中与 Seedream3.0 持平或领先,并显著优于 FLUX.1 3。值得注意的是,它的参数量(200 亿)也远大于 FLUX。
IV. 通义万相系列预期未来发展与优化
通义万相将发布专门的“编辑版本”,这明确“已列入我们的路线图并计划未来发布”,有望进一步增强其已然强大的编辑能力。对 LoRA(低秩适应)和其他微调工作流的支持“目前正在开发中,即将推出” ,这将显著提升其对开发者和定制应用场景的实用性和适应性。从通用图像生成到高度专业化和实用能力(如“卓越文本渲染”和“一致图像编辑”)的战略转变 ,标志着多模态 AI 领域的一个关键成熟阶段。早期生成模型通常侧重于新颖的艺术输出,而通义万相等新模型则明确解决了以往阻碍专业采用的实际痛点。对“保真度、对齐、多语言渲染、图像编辑、布局控制和严格遵循提示” 的强调,表明了从艺术实验到工业实用性的明确转变,使得 AI 工具在商业应用中更加可靠和可控。阿里巴巴的通义万相作为一款关键的开源 200 亿参数 MMDiT 模型,标志着多模态 AI 领域的重大进展。