机器学习之朴素贝叶斯
在机器学习领域,朴素贝叶斯算法以其简单高效、易于实现的特点占据着重要地位。无论是文本分类、垃圾邮件过滤还是情感分析,朴素贝叶斯都展现出了强大的实用价值。本文将带您深入了解朴素贝叶斯算法的核心原理、常见模型、实现过程以及实际应用场景。
一、朴素贝叶斯的基本概念
朴素贝叶斯(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。它的 “朴素” 之处在于假设所有特征之间是相互独立的,这一假设虽然简化了计算,但在很多实际场景中依然能取得较好的分类效果。
贝叶斯定理是朴素贝叶斯算法的核心基础,其公式如下:
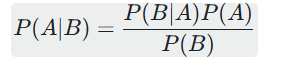
其中, ![]() 表示在事件 B 发生的条件下事件 A 发生的概率,称为后验概率;
表示在事件 B 发生的条件下事件 A 发生的概率,称为后验概率;![]() 是事件 A 发生的先验概率;
是事件 A 发生的先验概率;![]() 是在事件 A 发生的条件下事件 B 发生的概率,称为似然度;
是在事件 A 发生的条件下事件 B 发生的概率,称为似然度;![]() 是事件 B 发生的边际概率。
是事件 B 发生的边际概率。
案例一:
现分别有 A、B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,
在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球,
问这个红球是来自容器 A 的概率是多少?

案例二:
一座别墅在过去的 20 年里一共发生过 2 次被盗事件。
别墅的主人有一条狗,
狗平均每周晚上叫 3 次,
叫在盗贼入侵时狗的概率被估计为 0.9,
问题是:在狗叫的时候发生入侵的概率是多少?

二、朴素贝叶斯的核心原理
(一)特征条件独立性假设
如前所述,朴素贝叶斯假设各个特征之间是相互独立的。也就是说,对于给定类别的情况下,各个特征的取值互不影响。这一假设极大地简化了计算,使得我们可以将联合概率分解为各个特征的条件概率的乘积。
假设样本有 n 个特征 ![]() ,类别为 y,则在特征条件独立假设下:
,类别为 y,则在特征条件独立假设下:
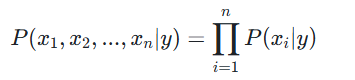
(二)分类决策规则
朴素贝叶斯分类器在进行分类时,会选择后验概率最大的类别。根据贝叶斯定理和特征条件独立性假设,后验概率可以表示为:
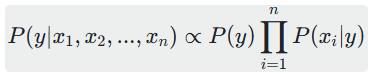
由于![]() 对于所有类别都是相同的,在比较后验概率大小时可以忽略不计,只需要比较
对于所有类别都是相同的,在比较后验概率大小时可以忽略不计,只需要比较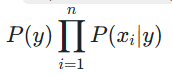 的大小。
的大小。
三、朴素贝叶斯的优缺点
(一)优点
1.算法简单高效,计算量小,适合处理大规模数据集。
2.对缺失数据不敏感,具有较好的鲁棒性。
3.当特征条件独立假设成立时,分类性能较好。
4.可以给出后验概率,提供了分类的可信度信息。
(二)缺点
1.特征条件独立假设在现实中往往不成立,可能会影响分类效果。
2.对训练数据中的极端值和噪声较为敏感。
3.无法学习特征之间的相互作用关系。
四、实例:使用朴素贝叶斯进行文本分类
1、项目背景与目标
我们将使用 20 类新闻数据集(20newsgroups)中的 4 个类别(计算机图形、医学、政治、曲棍球)作为研究对象,通过多项式朴素贝叶斯算法构建文本分类模型,实现对新闻文本的自动分类,并评估模型性能。
2、完整代码实现与解析
(一)数据加载与预处理
首先需要导入必要的库并加载数据集:
from sklearn.datasets import fetch_20newsgroups# 选择部分类别进行训练和测试,减少计算量
categories = ['comp.graphics', 'sci.med', 'talk.politics.misc', 'rec.sport.hockey']# 加载训练集和测试集
train_data = fetch_20newsgroups(subset='train', categories=categories, remove=('headers', 'footers', 'quotes'))
test_data = fetch_20newsgroups(subset='test', categories=categories, remove=('headers', 'footers', 'quotes'))# 查看数据信息
print("训练集文档数量:", len(train_data.data))
print("测试集文档数量:", len(test_data.data))
print("类别名称:", train_data.target_names)关键说明:
fetch_20newsgroups是 scikit-learn 内置的数据集加载函数,包含大量新闻组文档
remove参数移除了文档中的标题、页脚和引用内容,这些内容往往包含通用信息,会干扰分类模型的学习
通过打印数据信息,我们可以了解数据集的基本情况,比如这里训练集有 2257 篇文档,测试集有 1502 篇文档,包含 4 个类别
运行后输出如下:

(二)文本特征提取
文本数据是一种非结构化数据,需要转换为结构化的数值特征才能被机器学习模型处理。这里我们使用 TF-IDF 方法进行特征提取:
from sklearn.feature_extraction.text import TfidfVectorizer# 初始化TF-IDF向量器
tfidf_vectorizer = TfidfVectorizer(max_features=5000) # 只保留5000个最常见的词汇# 对训练集和测试集进行特征提取
X_train = tfidf_vectorizer.fit_transform(train_data.data)
X_test = tfidf_vectorizer.transform(test_data.data)# 标签
y_train = train_data.target
y_test = test_data.target核心原理:
TF-IDF(词频 - 逆文档频率)是一种常用的文本特征提取方法,它能反映一个词在文档集中的重要程度
max_features=5000表示只保留 5000 个出现频率最高的词汇,这样可以在减少特征维度的同时,保留大部分有用信息
对训练集使用fit_transform,既学习词汇表又进行转换;对测试集使用transform,复用训练集的词汇表,这是为了避免数据泄露,保证模型评估的公正性
转换后得到的X_train和X_test是稀疏矩阵,其中X_train的形状为 (2257, 5000),表示 2257 个训练样本,每个样本有 5000 个特征。
(三)构建并训练朴素贝叶斯模型
接下来我们使用多项式朴素贝叶斯算法构建分类模型并进行训练:
from sklearn.naive_bayes import MultinomialNB# 初始化多项式朴素贝叶斯模型
model = MultinomialNB()# 训练模型
model.fit(X_train, y_train)算法特点:
MultinomialNB是专为离散特征设计的朴素贝叶斯实现,非常适合处理文本分类问题
训练过程主要是计算两个概率:
先验概率:每个类别的出现概率
条件概率:每个词在各个类别中的出现概率(内置拉普拉斯平滑,避免概率为 0 的情况)
朴素贝叶斯算法的训练速度非常快,即使面对高维特征也能高效处理
(四)模型评估
模型训练完成后,我们需要在测试集上评估其性能:
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 对测试集进行预测
y_pred = model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
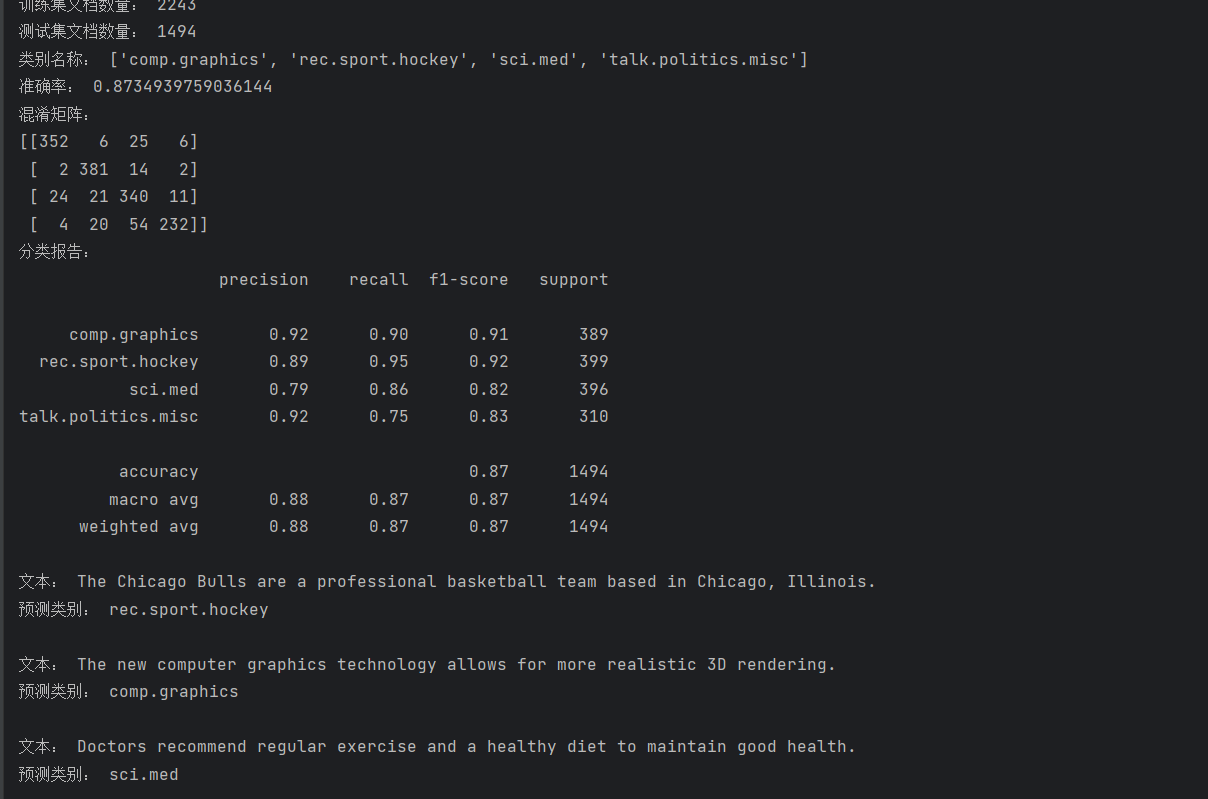
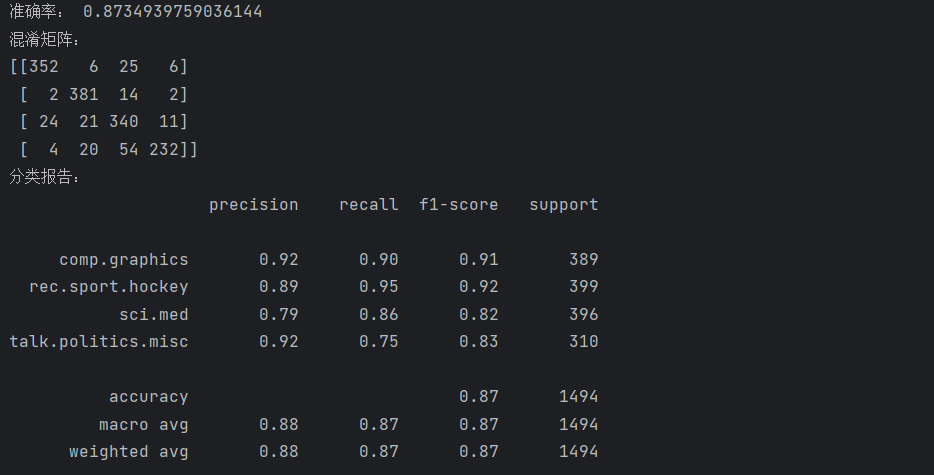
print("准确率:", accuracy)# 打印混淆矩阵
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))# 打印分类报告
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=test_data.target_names))评估指标解读:
准确率(Accuracy):表示模型正确分类的样本占总样本的比例,这里我们的模型准确率约为 0.852
混淆矩阵:直观展示了各类别之间的预测情况,对角线元素表示正确分类的样本数,非对角线元素表示错分的样本数
分类报告:包含精确率、召回率和 F1 值等指标:
精确率:预测为某类的样本中,实际属于该类的比例
召回率:实际属于某类的样本中,被正确预测的比例
F1 值:精确率和召回率的调和平均,综合反映模型的分类性能
运行后输出如下:
(五)使用模型进行新文本预测
训练好的模型可以用于对新的文本进行分类预测:
# 新文本
new_texts = ["The Chicago Bulls are a professional basketball team based in Chicago, Illinois.","The new computer graphics technology allows for more realistic 3D rendering.","Doctors recommend regular exercise and a healthy diet to maintain good health."
]# 将新文本转换为特征向量
X_new = tfidf_vectorizer.transform(new_texts)# 预测类别
y_new_pred = model.predict(X_new)# 输出预测结果
for text, pred in zip(new_texts, y_new_pred):print("文本:", text)print("预测类别:", test_data.target_names[pred])print()预测结果分析:
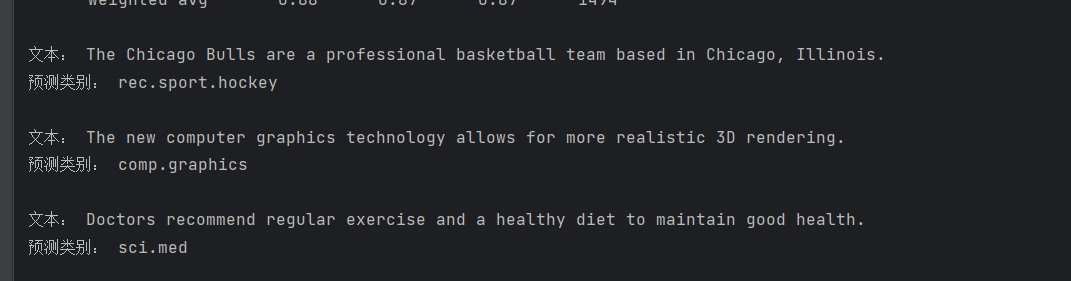
第二和第三个文本都被正确分类,因为它们包含了明显的类别关键词,如 "graphics" 和 "Doctors"
第一个文本是关于篮球的,却被分类到了 "rec.sport.hockey"(曲棍球)类别,这是因为篮球和曲棍球同属体育领域,模型仅通过词频特征难以区分,体现了朴素贝叶斯算法的局限性
完整代码及运行结果如下:
from sklearn.datasets import fetch_20newsgroups# 选择部分类别进行训练和测试,减少计算量
categories = ['comp.graphics', 'sci.med', 'talk.politics.misc', 'rec.sport.hockey']# 加载训练集和测试集
train_data = fetch_20newsgroups(subset='train', categories=categories, remove=('headers', 'footers', 'quotes'))
test_data = fetch_20newsgroups(subset='test', categories=categories, remove=('headers', 'footers', 'quotes'))# 查看数据信息
print("训练集文档数量:", len(train_data.data))
print("测试集文档数量:", len(test_data.data))
print("类别名称:", train_data.target_names)
from sklearn.feature_extraction.text import TfidfVectorizer# 初始化TF-IDF向量器
tfidf_vectorizer = TfidfVectorizer(max_features=5000) # 只保留5000个最常见的词汇# 对训练集和测试集进行特征提取
X_train = tfidf_vectorizer.fit_transform(train_data.data)
X_test = tfidf_vectorizer.transform(test_data.data)# 标签
y_train = train_data.target
y_test = test_data.target
from sklearn.naive_bayes import MultinomialNB# 初始化多项式朴素贝叶斯模型
model = MultinomialNB()# 训练模型
model.fit(X_train, y_train)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 对测试集进行预测
y_pred = model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)# 打印混淆矩阵
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))# 打印分类报告
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=test_data.target_names))
# 新文本
new_texts = ["The Chicago Bulls are a professional basketball team based in Chicago, Illinois.","The new computer graphics technology allows for more realistic 3D rendering.","Doctors recommend regular exercise and a healthy diet to maintain good health."
]# 将新文本转换为特征向量
X_new = tfidf_vectorizer.transform(new_texts)# 预测类别
y_new_pred = model.predict(X_new)# 输出预测结果
for text, pred in zip(new_texts, y_new_pred):print("文本:", text)print("预测类别:", test_data.target_names[pred])print()