使用Java爬取xxx律师协会网站上公开的律所信息并导出到Excel
1. 引言:介绍背景和目的 2. 技术栈:使用的库(Jsoup, Apache POI) 3. 实现步骤: a. 分析目标网站结构 b. 分页爬取数据 c. 数据解析与存储 d. 导出Excel 4. 完整代码(带详细注释) 5. 可能遇到的问题及解决方案 6. 结语注意:由于是公开博客,我们需要提醒读者遵守网站的robots.txt,尊重网站数据的使用条款,不要过度爬取。下面开始撰写博客:
使用Java爬取成都市律师协会律所信息并导出Excel
本文将分享一个实用的Java爬虫案例,通过Jsoup+POI技术实现成都市律师协会网站律所信息的自动化采集与Excel导出。
一、代码背景与需求
在法务行业调研中,需要获取成都市所有律师事务所的公开信息,包括:
律所名称
负责人
主管司法局
执业许可证号
联系电话
办公地址
目标网站采用分页展示(共218页),手动复制效率低下,因此开发此自动化采集程序。
二、技术栈与工具
| 技术/工具 | 用途 |
|---|---|
| Jsoup | HTML解析和数据提取 |
| Apache POI | Excel文件生成 |
| Java 8+ | 基础编程语言 |
| Maven | 依赖管理 |
Maven依赖:
<dependencies><!-- Jsoup HTML解析 --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.14.3</version></dependency><!-- Apache POI Excel操作 --><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.0</version></dependency>
</dependencies>三、实现思路详解
1. 网站结构分析
通过浏览器开发者工具分析目标网站:
分页URL模式:
https://www.cdslsxh.org/lvsuo?page={页码}单页律所容器:
div.zz-loop-item关键信息选择器:
名称:
a.zz-text.zz-comp-content div其他信息:
div.zz-comp-text
2. 爬虫核心流程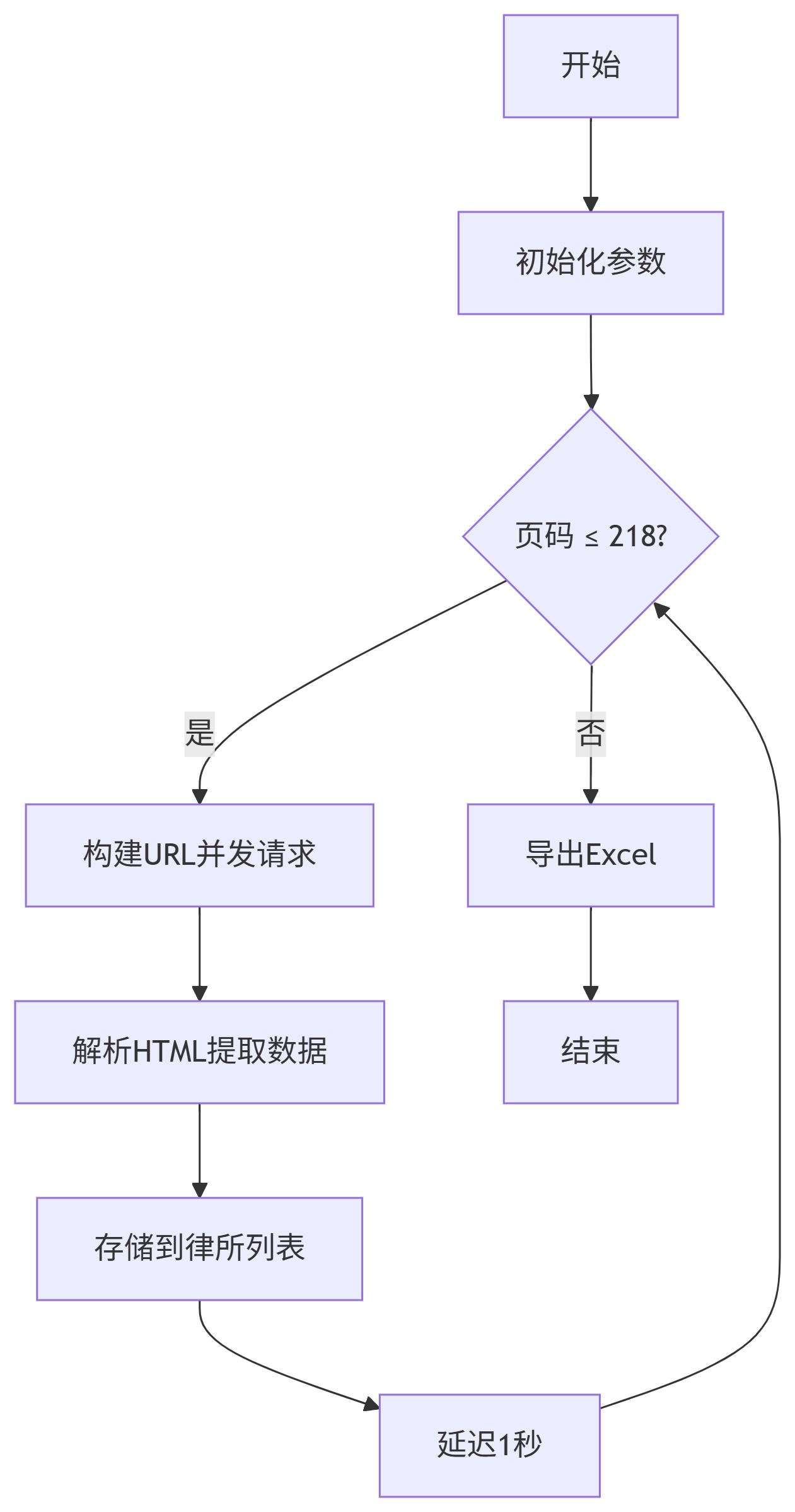
3. 关键技术点
(1)防反爬策略
Document doc = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64)...") // 模拟浏览器.referrer("https://www.cdslsxh.org") // 设置来源页.timeout(30000) // 30秒超时.get();(2)数据提取方法
private static String extractValue(Element parent, String label) {Elements elements = parent.select("div.zz-comp-text");for (Element elem : elements) {if (elem.text().contains(label)) {return elem.text().replace(label, "").trim();}}return "";
}(3)Excel导出优化
// 创建加粗表头样式
CellStyle headerStyle = workbook.createCellStyle();
Font font = workbook.createFont();
font.setBold(true);
headerStyle.setFont(font);// 自动调整列宽
for (int i = 0; i < headers.length; i++) {sheet.autoSizeColumn(i);
}四、完整实现代码
五、常见问题与解决方案
请求被拒绝(403错误)
解决方案:更新User-Agent和Referrer
扩展:添加Cookie和随机延迟
数据提取不全
检查点:网站结构是否更新
调试方法:保存HTML快照分析
// 调试时保存HTML Files.write(Paths.get("debug.html"), doc.html().getBytes());
六、注意事项
法律与道德约束
遵守网站
robots.txt规则控制请求频率(≥1秒/页)
仅用于学习研究,禁止商用
程序优化方向
增加代理IP支持
实现断点续爬功能
添加邮件通知机制
扩展应用
适配其他律师协会网站
集成SpringBoot作为定时任务
添加数据库存储支持
七、执行效果
运行程序后:
控制台实时显示采集进度
最终生成结构化的Excel文件
输出路径:
D:\work\律所信息汇总.xlsx
通过此项目,我们实现了:
高效获取218页律所数据(约5分钟)
自动化数据清洗与格式化
专业级的Excel报表输出
技术总结:本案例展示了Java在网络爬虫领域的强大能力,通过合理的架构设计,可以高效解决实际工作中的数据采集需求。读者可在此基础上扩展更多实用功能。