大模型|极简说清“数据并行”
在深度学习模型的分布式训练中,数据并行和模型并行是两种最常用的并行策略,核心目的是解决 “数据量大” 或 “模型太大” 导致的训练效率低、甚至无法训练的问题。
数据并行(Data Parallelism)的概念
核心逻辑:“多设备保存完整模型、拆分数据并行计算” 。
当训练数据量非常大(比如一次训练出要处理百万级样本)单卡(如 GPU)处理速度慢时,将数据拆分到多个设备(如多 GPU)上,每个设备上都保存完整的模型副本。每个设备用自己分到的部分数据独立计算梯度,然后所有设备的梯度汇总、平均,再同步更新所有设备上的模型参数。
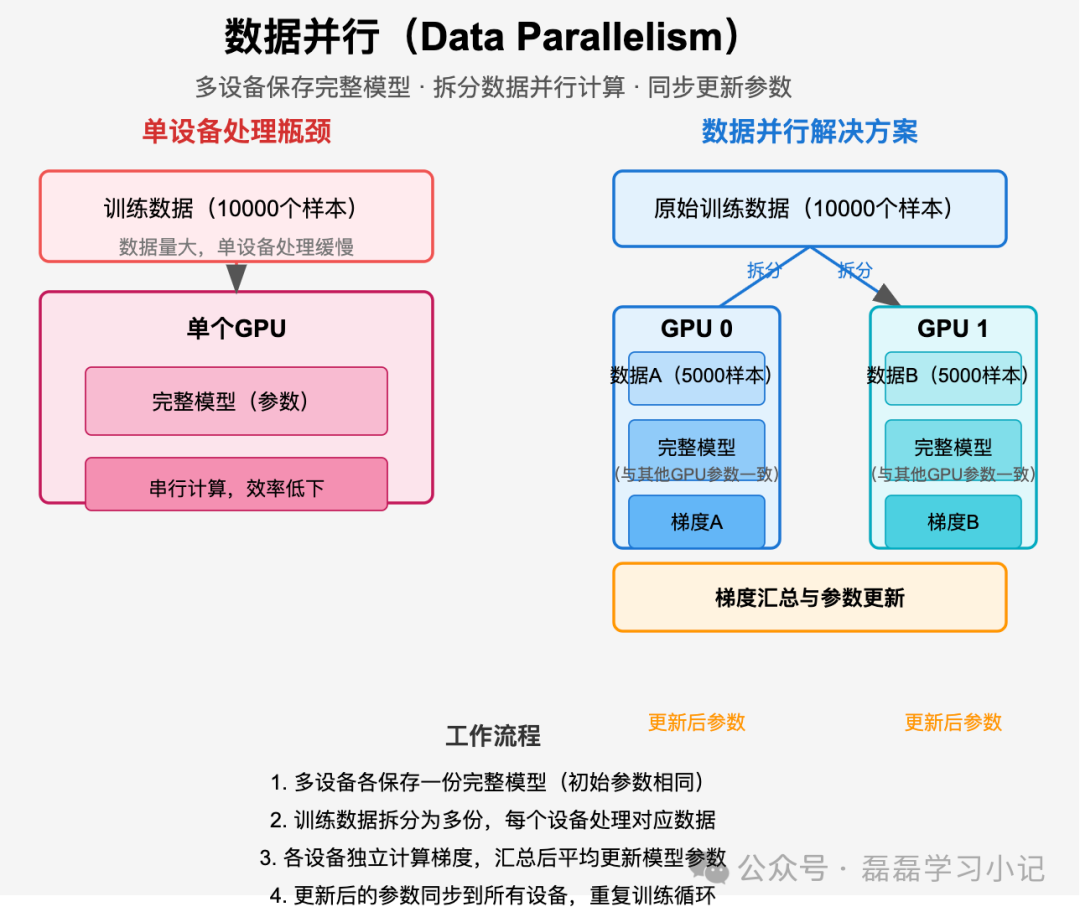
1、通俗理解
可以想象成 “多人合作抄同一本书”:
一本书(模型)有很多页(数据),1 个人抄太慢,于是找 3 个同学帮忙。
每个人手里都有这本书的完整副本(每个设备有完整模型),但各自只抄其中几页(每个设备处理部分数据)。
抄完后,每个人会发现自己抄的部分有错误(计算出梯度),大家把错误汇总到一起(梯度平均),然后所有人一起根据汇总的错误修正自己手里的书(同步更新模型)。
2、核心区别
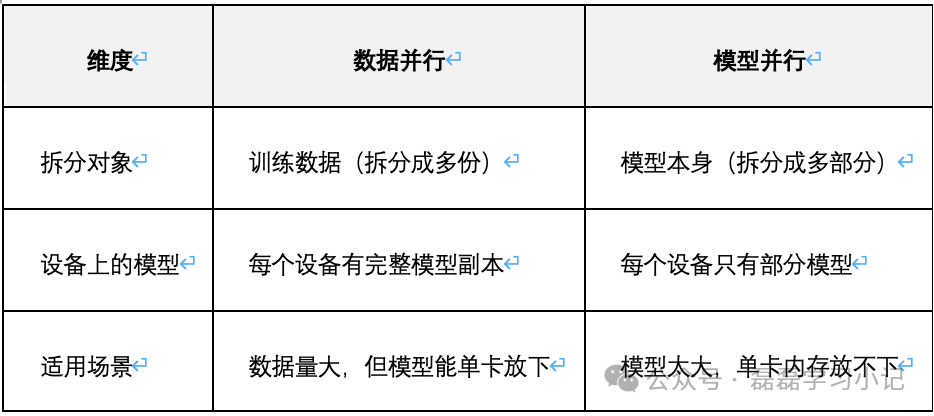
实际训练中,大模型(如 GPT、LLaMA)常同时使用两种策略:既拆分数据(加快处理速度),又拆分模型(解决单卡放不下的问题)。
更多关于“流水线并行”和“张量并行”等内容,请查看wx 扫下图,查看合集:“AI 大模型探索”
