AI - RAG知识库-进阶(一)
前面浅尝了一下,RAG检索增强生成工作流程:
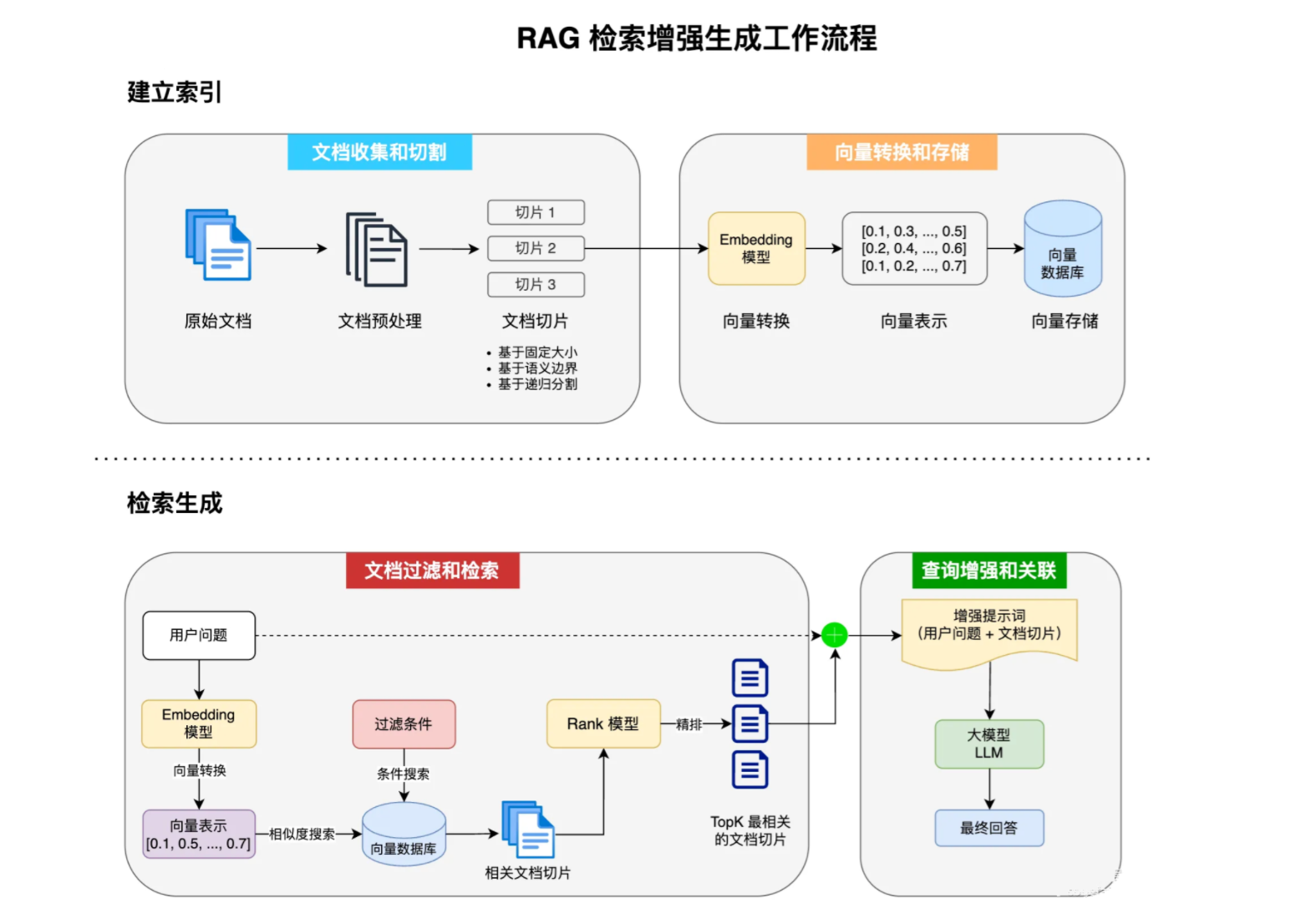
Spring AI也为RAG的工作流程的技术实现提供了支持.
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
RAG核心特性
(Retrieval-Augmented Generation)
文档收集和切割 - ETL
文档收集和切割阶段,我们要对自己准备好的知识库文档进行处理,然后保存到向量数据库中。
这个过程俗称ETL(抽取、转换、加载),Spring AI 提供了对ETL的支持,参考:ETL官网介绍
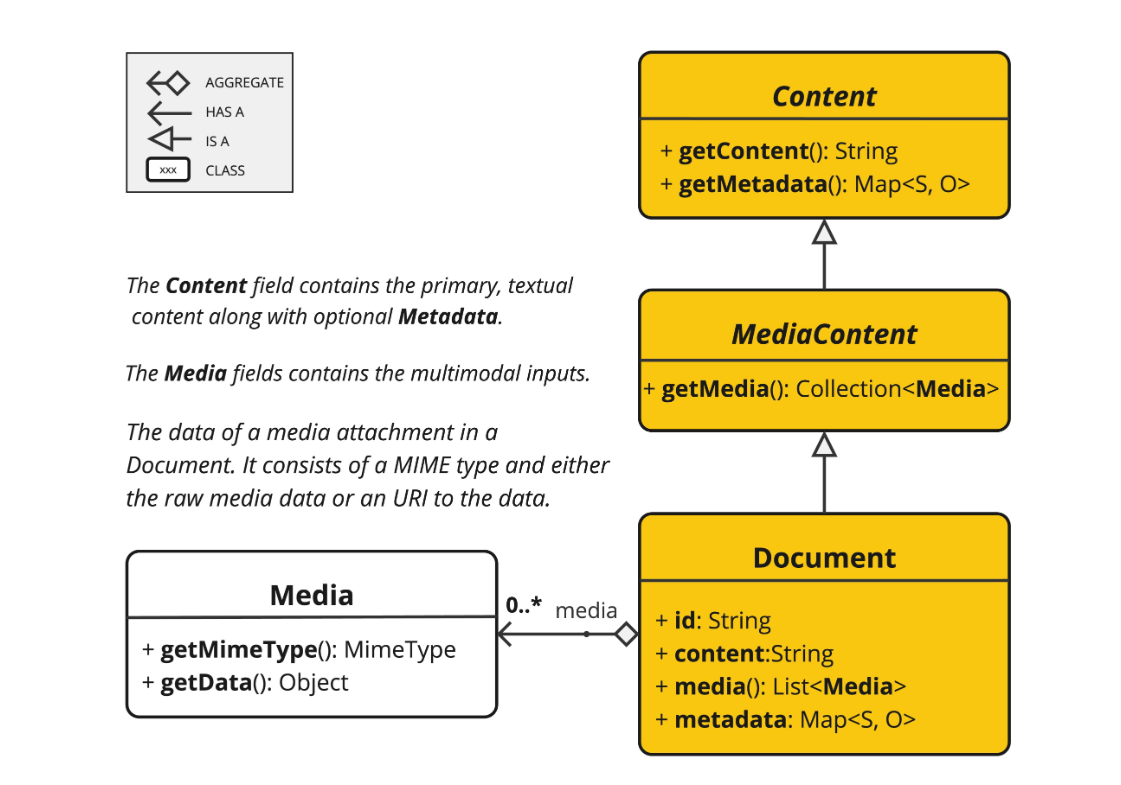
文档
什么是Spring AI中的文档?
文档不仅仅包含文本,还可以包含一系列元信息和多媒体附件:
ETL
抽取(Extract)、 转换(Transform)、加载(Load)
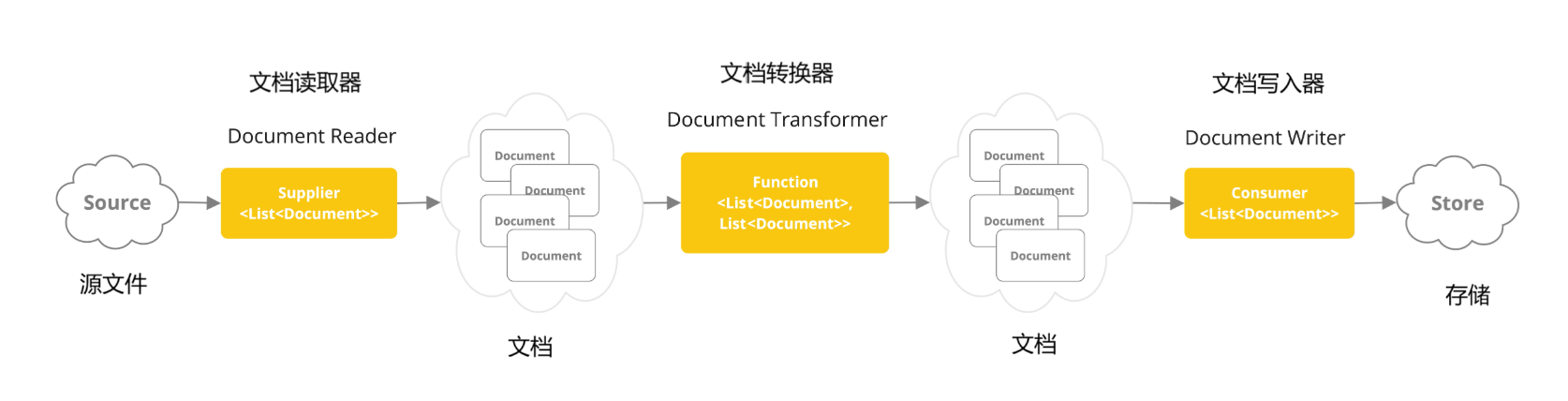
在Spring AI中,对Document的处理通常遵循一下流程:
- 读取文档:使用DocumentReader组件从数据源(如本地文件,网络资源,数据库等)加载文档。
- 转换文档:根据需求将文档转换为适合后续处理的格式,比如去除冗余信息,分词,词性标注等,可以使用DocumentTransformer组件实现。
- 写入文档:使用DocumentWriter将文档以嵌入向量的形式写入到向量数据库,或者以键值对字符串的形式把存在Redis等 k v 存储中。
流程如下图:
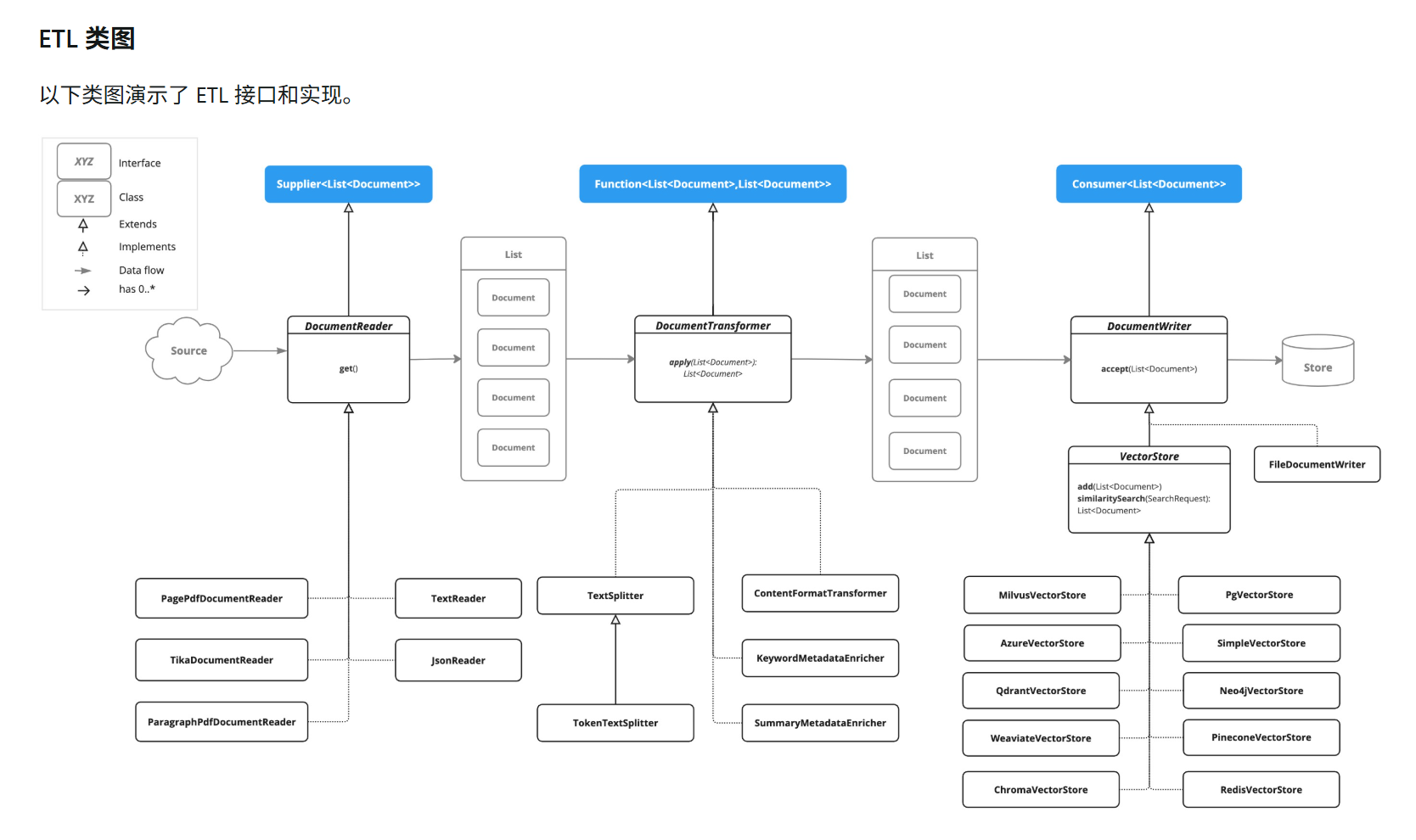
ETL3大组件
利用Spring AI实现ETL,核心就是使用学习三大组件:
DocumentReader:文档读取器
DocumentTransformer:文档转换器
DocumentWriter:文档写入/器
抽取(Extract)
Spring AI通过DocumentReader组件实现文档抽取,就是把文档加载到内存中。
源码中,DocumentReader接口实现了Supplier<List<Documet>>接口,主要负责从各种数据源读取数据转换为Document对象集合。
public interface DocumentReader extends Supplier<List<Document>> {default List<Document> read() {return get();}
}
实际开发中,我们可以直接使用Spring AI内置的多种DocumentReader实现类,用于处理不同类型的数据源。
1、JsonReader:读取JSON文档
2、TextReader:读取纯文本文件
3、MarkdownReader:读取Markdown文档
4、PDFReader:读取PDF文档,基于Apache PdBox库实现
- PagePdfDocumentReader:按照分页读取PDF
- ParagraphPdfDocumentReader:按照段落读取PDF
5、HtmlReader:读取HTML文档,基于jsoup库实现
6、TikaDocumentReader:基于Apache Tika库处理多种格式文档,更灵活
以JsonReader为例,支持JSON Pointers特性,能够快速指定从JSON文档中提取哪些字段和内容
// 从 classpath 下的 JSON 文件中读取文档@Componentclass MyJsonReader {private final Resource resource;MyJsonReader(@Value("classpath:products.json") Resource resource) {this.resource = resource;}// 基本用法List<Document> loadBasicJsonDocuments() {JsonReader jsonReader = new JsonReader(this.resource);return jsonReader.get();}// 指定使用哪些 JSON 字段作为文档内容List<Document> loadJsonWithSpecificFields() {JsonReader jsonReader = new JsonReader(this.resource, "description", "features");return jsonReader.get();}// 使用 JSON 指针精确提取文档内容List<Document> loadJsonWithPointer() {JsonReader jsonReader = new JsonReader(this.resource);return jsonReader.get("/items"); // 提取 items 数组内的内容}}此外,Spring AI Alibaba官方社区提供了更多的文档读取器,比如加载飞书文档,提取B站视频信息字母,加载邮件、Github官方文档、加载数据库等等。
转换(Transform)
Spring AI通过DocumentTransformer组件实现文档转换。
源码中,DocumentTransformer接口实现了Function<List<Document>>,List<Document>接口,负责将一组文档转换为另一组文档。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {default List<Document> transform(List<Document> documents) {return apply(documents);}
}文档转换是保证RAG效果的核心步骤,也即使如何将大文档合理拆分为便于检索的知识碎片,Spring AI提供了多种DocumentTransformer实现类,简单分为3类。
1、TextSplitter 文本分割器
其中 TextSplitter 是文本分割器的基类,提供了分割单词的流程方法:
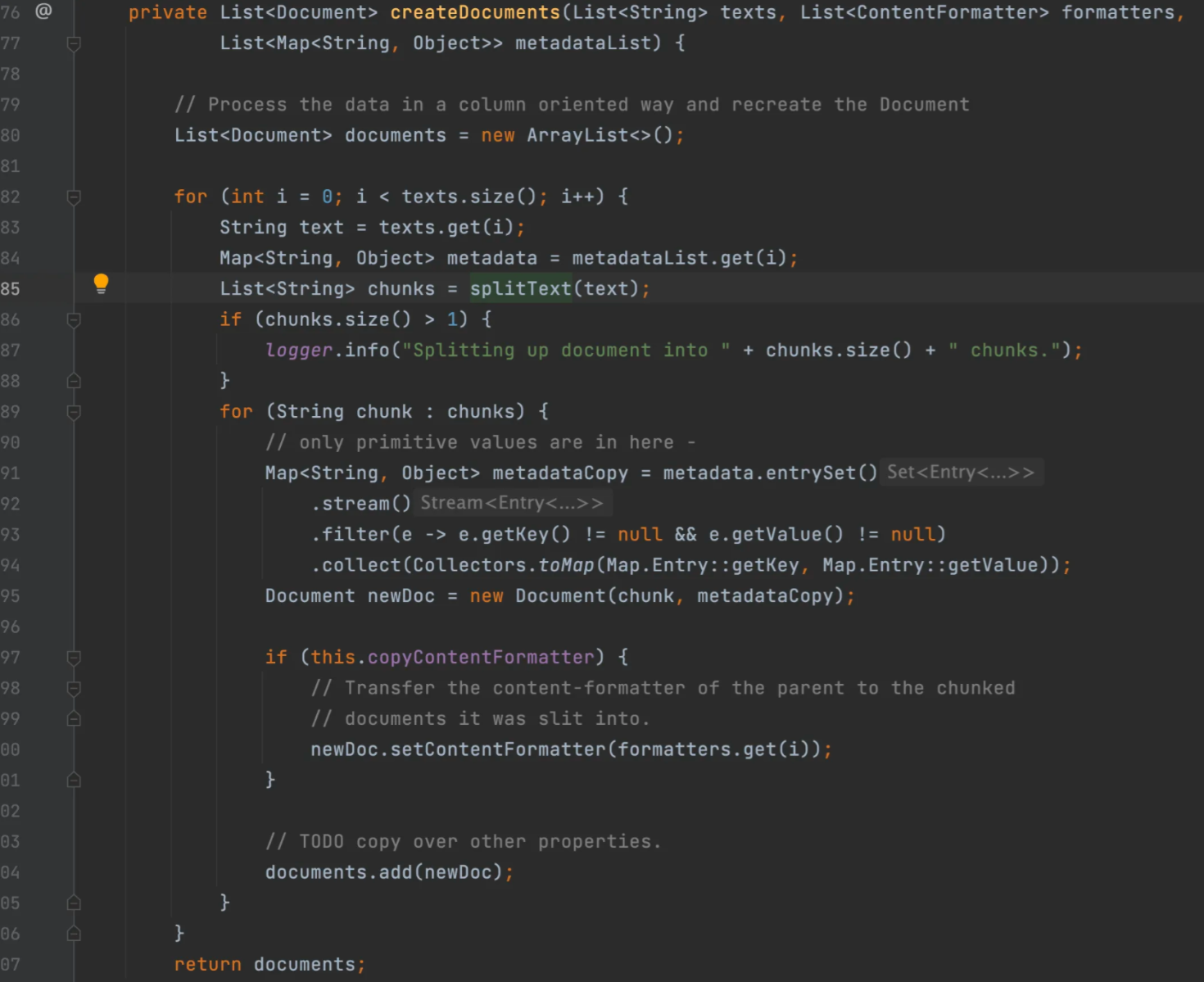
TokenTextsplitter 是其实现类,基于 Token 的文本分割器。它考虑了语义边界(比如句子结尾)来创建有意义的文本段落,是成本较低的文本切分方式。
@Component
class MyTokenTextSplitter {public List<Document> splitDocuments(List<Document> documents) {TokenTextSplitter splitter = new TokenTextSplitter();return splitter.apply(documents);}public List<Document> splitCustomized(List<Document> documents) {TokenTextSplitter splitter = new TokenTextSplitter(1000, 400, 10, 5000, true);return splitter.apply(documents);}
}TokenTextSplitter 提供了两种构造函数选项:
1.TokenTextsplitter():使用默认设置创建分割器。
2.TokenTextsplitter(int defaultchunksize, int minchunksizechars,int minchunkLengthToEmbed, int maxNumchunks,boolean keepseparator)
:使用自定义参数创建分割器,通过调整参数,可以控制分割的粒度和方式,适应不同的应用场景。参数说明:
defaultChunkSize:每个文本块的目标大小(以 token 为单位,默认值:800)。
minChunkSizeChars:每个文本块的最小大小(以字符为单位,默认值:350)。
minChunkLengthToEmbed:要被包含的块的最小长度(默认值:5)。
maxNumChunks:从文本中生成的最大块数(默认值:10000)。
keepSeparator:是否在块中保留分隔符(如换行符)(默认值:true)。
官方文档有对 Token 分词器工作原理的详细解释,可以简单了解下:
1.使用 CL100K BASE 编码将输入文本编码为 token。
2.根据 defaultChunkSize 将编码后的文本分割成块。
3.对于每个块:
- 将块解码回文本。
- 尝试在 minChunkSizeChars 之后找到合适的断点(句号、问号、感叹号或换行符)。
- 如果找到断点,则在该点截断块。
- 修剪块并根据 keepSeparator 设置选择性地删除换行符。
- 如果生成的块长度大于 minChunkLengthToEmbed,则将其添加到输出中。
4.这个过程会一直持续到所有 token 都被处理完或达到 maxNumChunks 为止。
5.如果剩余文本长度大于 minChunkLengthToEmbed,则会作为最后一个块添加。
2、MetadataEnricher 元数据增强器
元数据增强器的作用是为文档补充更多的元信息,便于后续检索,而不是改变文档本身的切分规则。
包括:
- KeywordMetadataEnricher:使用 Al 提取关键词并添加到元数据
- SummaryMetadataEnricher:使用 AI生成文档摘要并添加到元数据。不仅可以为当前文档生成摘要,还能关联前一个和后一个相邻的文档,让摘要更完整。
代码示例:
@Component
class MyDocumentEnricher {private final ChatModel chatModel;MyDocumentEnricher(ChatModel chatModel) {this.chatModel = chatModel;}// 关键词元信息增强器List<Document> enrichDocumentsByKeyword(List<Document> documents) {KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.chatModel, 5);return enricher.apply(documents);}// 摘要元信息增强器List<Document> enrichDocumentsBySummary(List<Document> documents) {SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel, List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));return enricher.apply(documents);}
}3、ContentFormatter 内容格式化工具
用于统一文档内容格式。官方并无太多介绍。
实现类DefaultContentFormatter的源码:
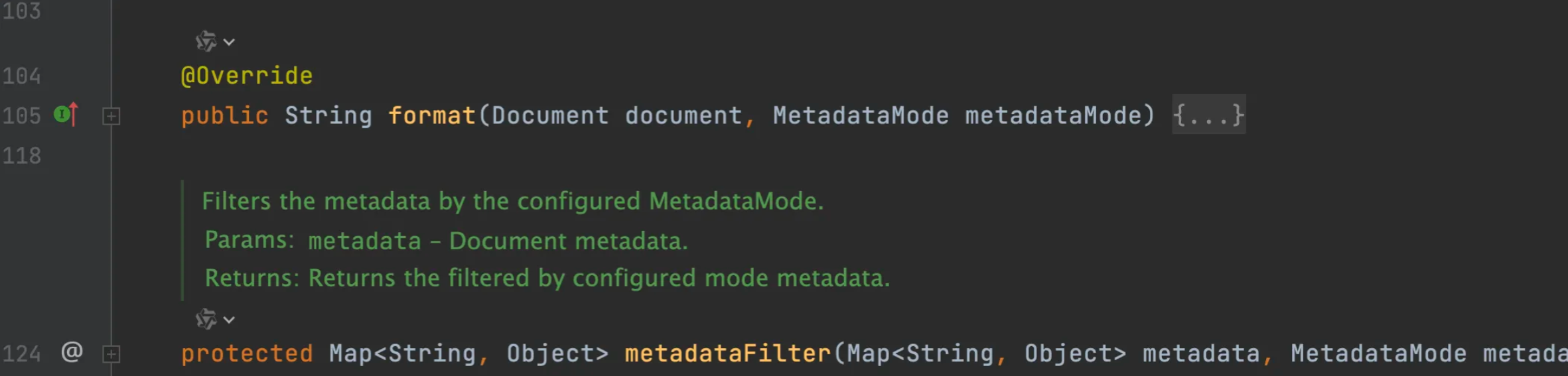
主要提供了3类功能:
1、文档格式化:将文档内容与元数据合并成特定格式的字符串,以便后续处理。
2、元数据过滤:根据不同的元数据模式(MetadataMode)筛选需要保留的元数据项:
- ALL:保留所有元数据
- NONE:移除所有元数据
- INFERENCE:用于推理场景,排除指定的推理元数据
- EMBED:用于嵌入场景,排除指定的嵌入元数据
3、自定义模板:支持自定义以下格式:
- 元数据库模板:控制每个元数据想的展示范式
- 元数据分隔符:控制多个元数据项之间的分割方式
- 文本模板:控制元数据的内容如何结合
该类采用Builder模式创建实例:
DefaultContentFormatter formatter = DefaultContentFormatter.builder().withMetadataTemplate("{key}: {value}").withMetadataSeparator("\n").withTextTemplate("{metadata_string}\n\n{content}").withExcludedInferenceMetadataKeys("embedding", "vector_id").withExcludedEmbedMetadataKeys("source_url", "timestamp").build();
// 使用格式化器处理文档
String formattedText = formatter.format(document, MetadataMode.INFERENCE);在RAG系统中,这个格式化器可以有以下作用:
1、提供上下文:将元数据(如文档来源,时间,标签等)与内容结合,丰富大语言模型的上下文信息
2、过滤无关信息:通过排除特定元数据,减少噪音,提高检索和生成质量
3、场景适配:为不同场景(如推理和嵌入)提供不同格式化策略
4、结构化输出:为AI模型提供结构化输入,使其能更好的理解和处理文档内容
加载(Load)
Spring AI 通过DocumentWriter组件实现文档加载(写入)。
DocumentWriter接口实现了Consumer<List<Document>>接口,负责处理后的文档写入到目标存储中:
public interface DocumentWriter extends Consumer<List<Document>> {default void write(List<Document> documents) {accept(documents);}
}Spring AI提供了2中内置的DocumentWriter实现:
1、FileDocumentWriter:将文档下入到文件系统
@Component
class MyDocumentWriter {public void writeDocuments(List<Document> documents) {FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);writer.accept(documents);}
}2、VectorStoreWriter:将文档写入到向量数据库
@Component
class MyVectorStoreWriter {private final VectorStore vectorStore;MyVectorStoreWriter(VectorStore vectorStore) {this.vectorStore = vectorStore;}public void storeDocuments(List<Document> documents) {vectorStore.accept(documents);}
}也可以同时将文档写入到多个存储,只需要创建多个Writer或者自定义Writer即可。
ETL流程示例
将上述3大组件结合起来,可以实现完整的ETL流程:
// 抽取:从 PDF 文件读取文档
PDFReader pdfReader = new PagePdfDocumentReader("knowledge_base.pdf");
List<Document> documents = pdfReader.read();
// 转换:分割文本并添加摘要
TokenTextSplitter splitter = new TokenTextSplitter(500, 50);
List<Document> splitDocuments = splitter.apply(documents);
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel, List.of(SummaryType.CURRENT));
List<Document> enrichedDocuments = enricher.apply(splitDocuments);
// 加载:写入向量数据库
vectorStore.write(enrichedDocuments);
// 或者使用链式调用
vectorStore.write(enricher.apply(splitter.apply(pdfReader.read())));通过这种方式,可以完成从原始文档到向量数据库的整个ETL过程,为后续的检索增强生成提供了基础。
向量转换和存储
向量存储是RAG应用中的核心组件,它将文档转为向量(嵌入)并存储起来,以便后续进行高效的相似性搜索。Spring AI官网提供了向量数据库接口:VectorStore和向量存储整合包,帮助开发者快速集成各种第三方向量储存,比如:Milvus、Redis、PGVector、Elasticsearch等。
VectorStore接口介绍
VectorStore是Spring AI中用于与向量数据库交互的核心接口,它继承自DocumentWriter,主要提供以下功能:
public interface VectorStore extends DocumentWriter {default String getName() {return this.getClass().getSimpleName();}void add(List<Document> documents);void delete(List<String> idList);void delete(Filter.Expression filterExpression);default void delete(String filterExpression) { ... };List<Document> similaritySearch(String query);List<Document> similaritySearch(SearchRequest request);default <T> Optional<T> getNativeClient() {return Optional.empty();}
}这个接口定义了向量存储基本操作,简单说即使CRUD。
- 添加文档到向量库
- 从向量库生成文档
- 基于查询进行相似度搜索
- 获取原生客户端(用于特定实现的高级操作)
搜索请求构建
Spring AI提供了SearchRequest类,用于构建相似度搜索请求
SearchRequest request = SearchRequest.builder().query("向AI提出问题?").topK(4) // 返回最相似的4个结果.similarityThreshold(0.7) // 相似度阈值,0.0-1.0之间.filterExpression("category == 'web' AND date > '2025-08-05'") // 过滤表达式.build();
List<Document> results = vectorStore.similaritySearch(request);SearchRequest提供了多种配置选项:
- query:搜索的查询文本
- topK:返回的最大结果数,默认为4
- similarityThreshold:相似度阈值,低于此值的结果会被过滤掉
- filterExpression:基于文档元数据的过滤表达式,语法有点类似SQL语句, 需要用到时查询Spring AI官方文档了解语法
向量储存的工作原理
在向量数据库中,查询与传统关系型数据库有所不同。
向量数据库执行的是相似性搜索,而非精准匹配。
1、嵌入转换:当文档被添加到向量数据库时,Spring AI会使用嵌入模型
(如OpenAI的text-embedding-ada-002)将文本转换为向量。
2、相似度计算:查询时,查询文本同样被转换为向量,然后系统计算此向量与存储中所有向量的相似度。
3、相似度度量:常用的相似度计算方法包括:
- 余弦相似度:计算两个向量的夹角余弦值,范围在-1到1之间
- 欧氏距离:计算两个向量减的直线距离
- 点积:两个向量的点积值
4、过滤与排序:根据相似度阈值过滤结果,并按相似度排序返回最相关文档
🙋♀️🌰
| 余弦相似度 |  |
| 欧氏距离 | 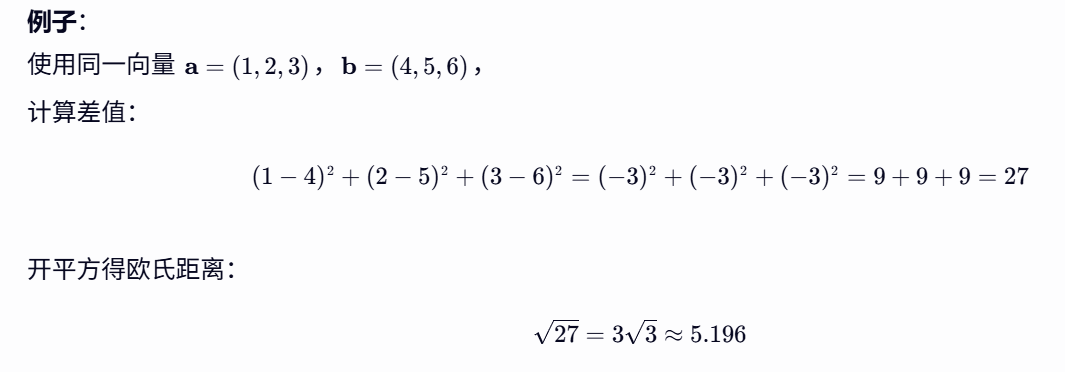 |
| 点积 |  |
支持的向量数据库
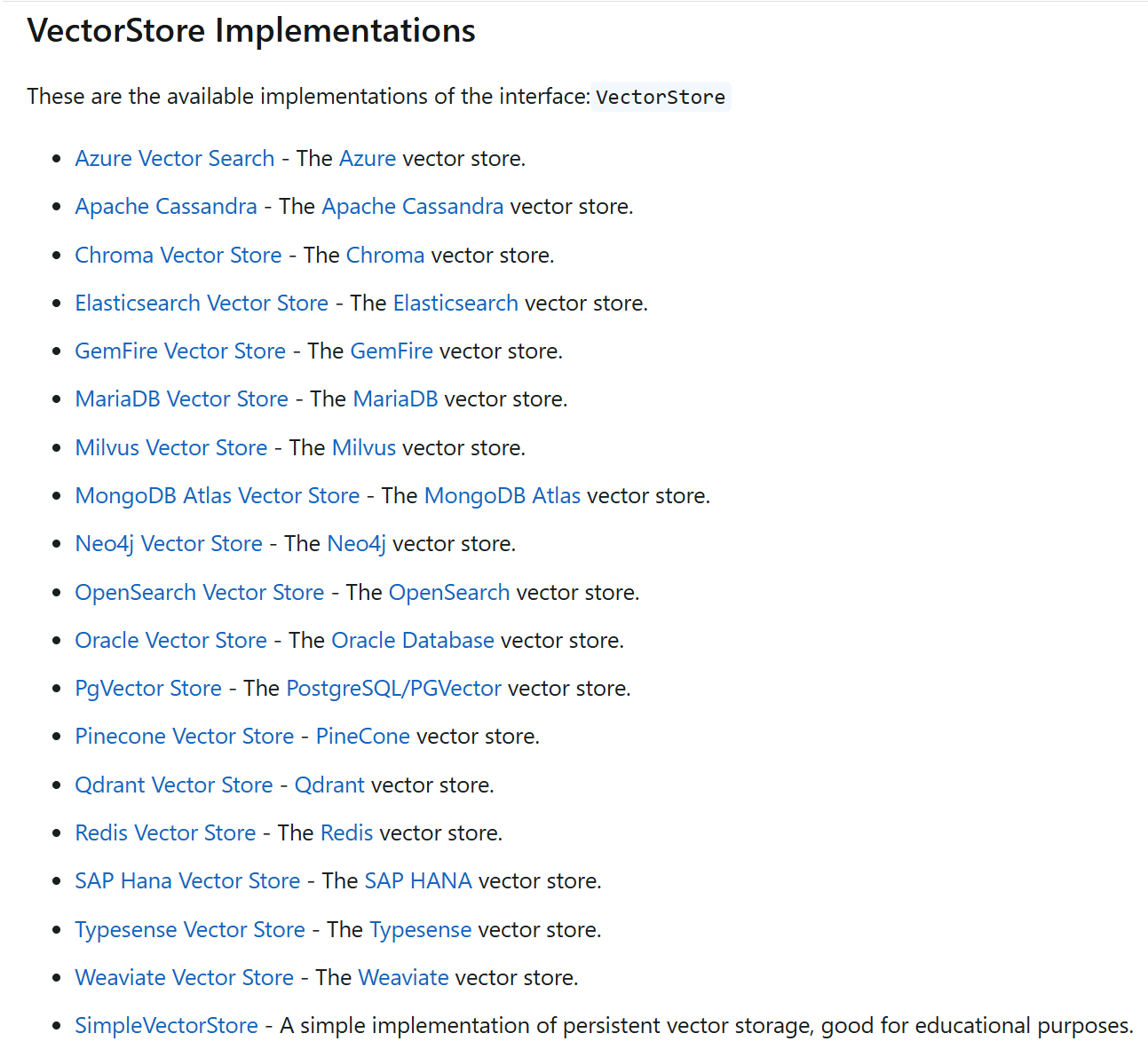 |  |
Spring AI支持多种向量数据库实现,对于每种Vector Store实现,都可以参考对应的官方文档进行整合,开发方法基本一直:
1、准备好数据源
2、引入不同的整合包
3、编写对应的配置
4、使用自动注入的VectorStore即可
Spring AI Alibaba已经继承了阿里云百炼平台,可以直接使用阿里云百炼平台提供的VectorStore API,无需自己搭建向量数据库了。
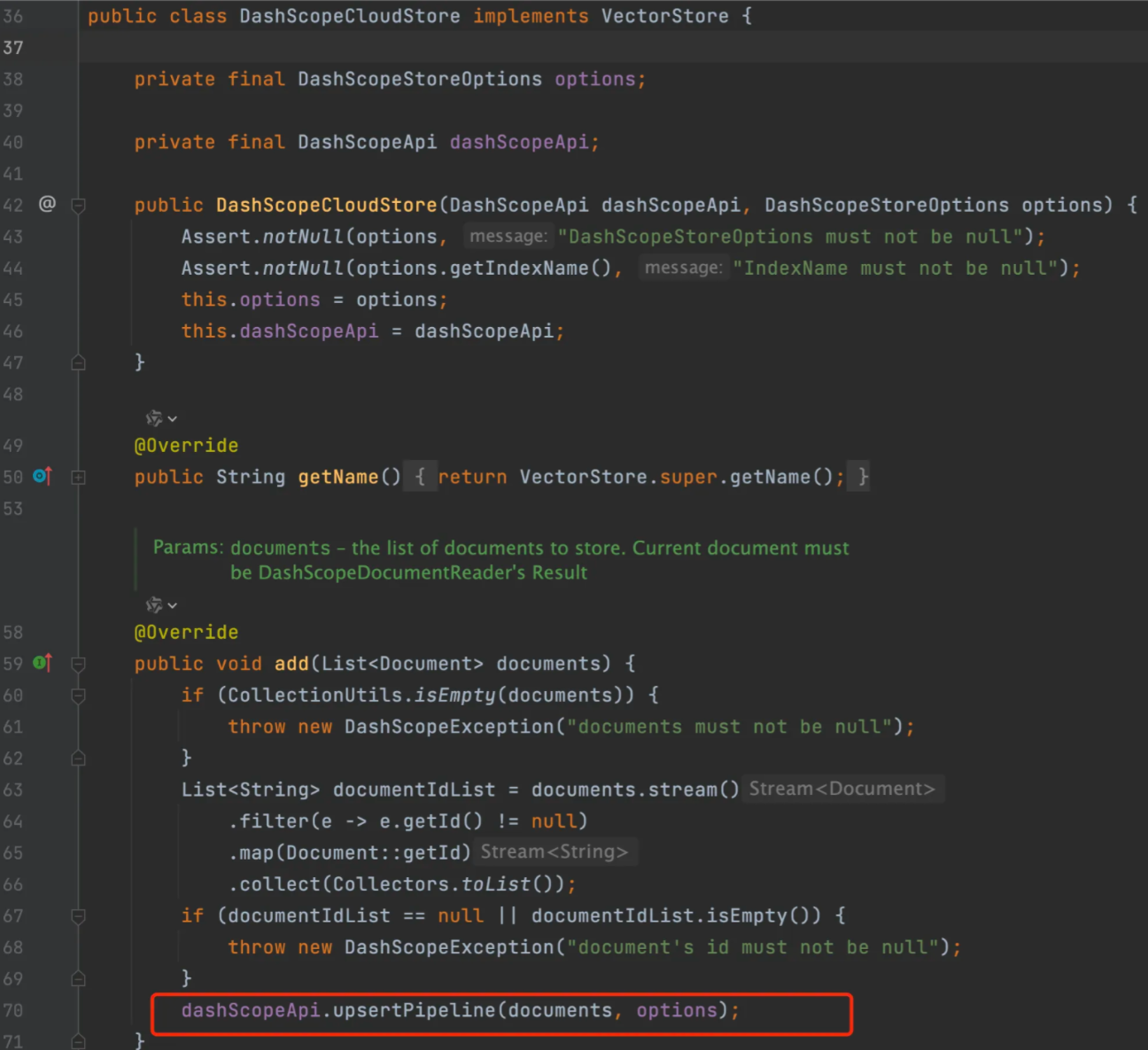
参考文档 Spring AI Alibaba官方文档,主要提供了DashScopeCloudStore类:

DashScopeCloudStore类实现了VectorStore接口,通过调用DashScope API来使用阿里云提供的远程向量存储:
基于PGVector实现向量存储
PGVector是经典数据库PostgreSQL的扩展,为PostgreSQL提供了存储和检索高维向量数据的能力。
为什么会使用它来实现向量存储?因为很多传统业务都会把数据存储在这种关系型数据库中,直接给原有的数据库安装扩展就能实现向量相似度搜索、而不需要额外整一套向量数据库,成本得到降低,所有该方案也是实现RAG的主流方案之一。
准备PostgreSQL数据库,并为其添加扩展。
方式一、在本地或服务器安装可以参考如下文章:
Linux服务器快速安装PostgreSQL 15与pgvector向量插件实践
宝塔 PostgreSQL 安装 pgvector 插件实现向量存储
方式二、更方便的形式——使用现成的云数据库。可以用阿里云PostgreSQL官网,开通Serverless版本,按用量计费,性价比高一些。
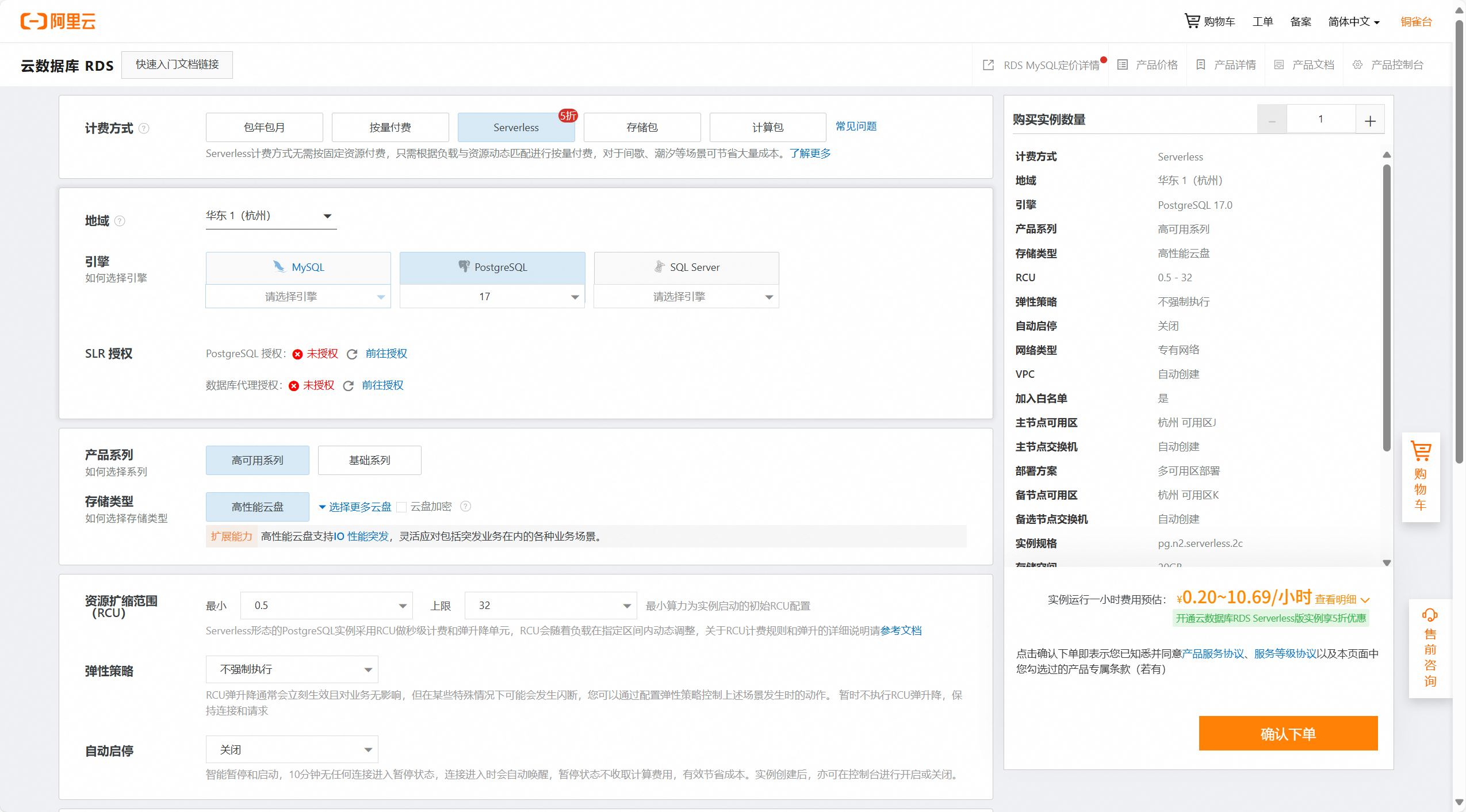
1、开通云服务,填写配置
2、开通成功后进入控制台创建账号
3、安装vector插件,测试连接
4、参考Spring AI官方文档整合PGVector,先引入依赖,版本号可在Maven中央仓库查找
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-pgvector</artifactId><version>1.0.0-M7</version>
</dependency>编好配置,建立数据库连接:
spring:datasource:url: jdbc:postgresql://改为你的公网地址/yu_ai_agentusername: 改为你的用户名password: 改为你的密码ai:vectorstore:pgvector:index-type: HNSWdimensions: 1536distance-type: COSINE_DISTANCEmax-document-batch-size: 10000 # Optional: Maximum number of documents per batch注意。在不确定向量维度的情况下,建议不要指定dimensions配置。如果未明确指定,PgVectorStore将从提供的EmbeddingModel中检索维度,维度在表场景时设置为前入列。
如果更改维度,则必须重新创建Vector_store表。不过最好提前明确你要使用的钱入维度值,手动建表,会可靠一些。
正常情况下,就可以使用自动注入的VectorStore了,系统会自动创建表:
@Autowired
VectorStore vectorStore;
List<Document> documents = List.of(new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),new Document("The World is Big and Salvation Lurks Around the Corner"),new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));
// Add the documents to PGVector
vectorStore.add(documents);
// Retrieve documents similar to a query
List<Document> results = this.vectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(5).build());初始化VectorStore,引入3个依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><scope>runtime</scope>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pgvector-store</artifactId><version>1.0.0-M6</version>
</dependency>编写配置类,自己构造PgVectorStore,不用Starter自动注入:
@Configuration
public class PgVectorVectorStoreConfig {@Beanpublic VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {VectorStore vectorStore = PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel).dimensions(1536) // Optional: defaults to model dimensions or 1536.distanceType(COSINE_DISTANCE) // Optional: defaults to COSINE_DISTANCE.indexType(HNSW) // Optional: defaults to HNSW.initializeSchema(true) // Optional: defaults to false.schemaName("public") // Optional: defaults to "public".vectorTableName("vector_store") // Optional: defaults to "vector_store".maxDocumentBatchSize(10000) // Optional: defaults to 10000.build();return vectorStore;}
}启动类要排除自动加载,否则会报错;
@SpringBootApplication(exclude = PgVectorStoreAutoConfiguration.class)
public class YuAiAgentApplication {public static void main(String[] args) {SpringApplication.run(YuAiAgentApplication.class, args);}}编写单元测试类,验证效果:
@SpringBootTest
public class PgVectorVectorStoreConfigTest {@ResourceVectorStore pgVectorVectorStore;@Testvoid test() {List<Document> documents = List.of(new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),new Document("The World is Big and Salvation Lurks Around the Corner"),new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));// 添加文档pgVectorVectorStore.add(documents);// 相似度查询List<Document> results = pgVectorVectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(5).build());Assertions.assertNotNull(results);}
}
以Debug模式运行,文档检索成功,并且给出了相似度得分:
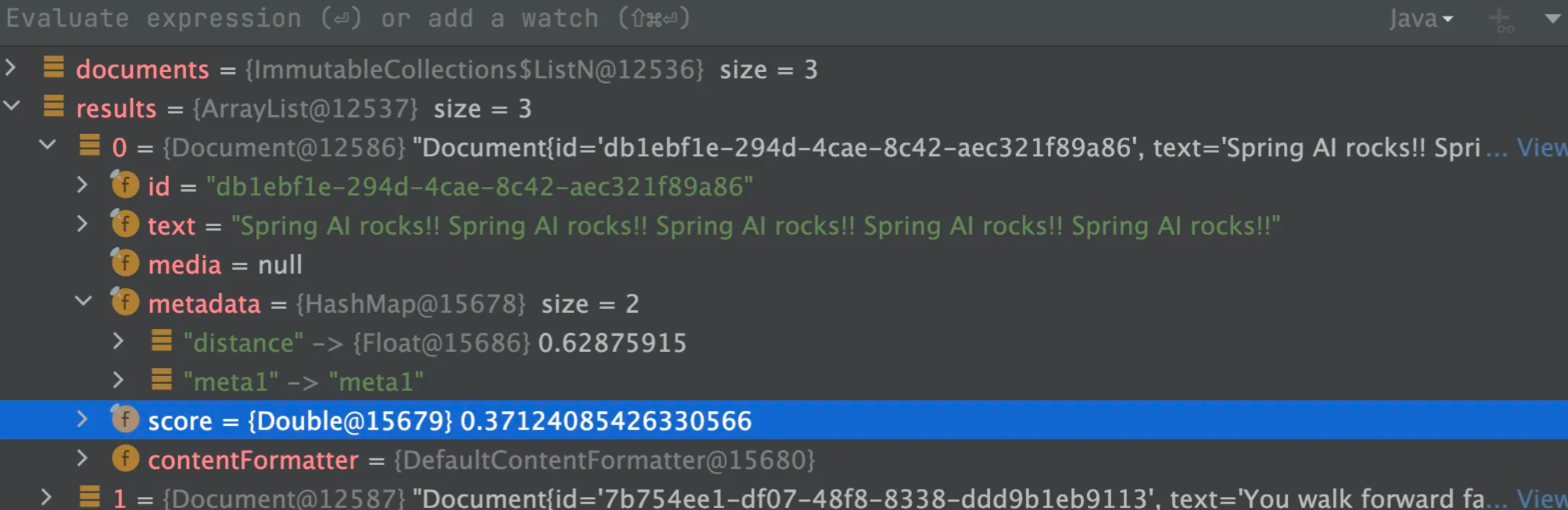
至此PgVectorStore就整合成功了。
扩展 - 批处理策略
在使用向量存储时,可能要嵌入大量文档,如果一次性处理存储大量文档,可能会导致性能问题,甚至出现错误导致数据不完整。
🙋♀️🌰
嵌入模型一般有一个最大标记限制,通常成为上下文窗口大小(Context window size),限制单个嵌入请求中可以处理的文本量。如果在一次调用中转换过多文档可能直接导致报错。
为此,Spring AI实现了批处理策略(Batching Strategy),将大量文档分解为较小的批次,使其适合嵌入模型的最大上下文窗口,还可以提高性能并更有效地利用API速率限制。
Spring AI 通过BatchingStrategy接口提供改功能,该接口允许基于文档的标记技术并分批助理文档
public interface BatchingStrategy {List<List<Document>> batch(List<Document> documents);
}该接口定义了一个单一方法batch,他接受一个文档列表并返回一个文档批次列表。
Spring AI提供了一个名为TokenCountBatchingStrategy的默认实现。这个策略为每个文档估算Token数,将文档分组到不超过最大输入token数据的批次中,如果单个文档超过次限制,则抛异常。这样就确保了每个批次不超过计算出的最大输入token数据。
自定义TokenCountBatchingStrategy,示例:
@Configuration
public class EmbeddingConfig {@Beanpublic BatchingStrategy customTokenCountBatchingStrategy() {return new TokenCountBatchingStrategy(EncodingType.CL100K_BASE, // 指定编码类型8000, // 设置最大输入标记计数0.1 // 设置保留百分比);}
}除了使用默认策略外,也可以自己实现BatchingStrategy:
@Configuration
public class EmbeddingConfig {@Beanpublic BatchingStrategy customBatchingStrategy() {return new CustomBatchingStrategy();}
}比如,使用的向量数据库每秒只能插入1万条数据,就可以通过实现BatchingStrategy控制速率,还可以进行额外的日志记录和异常处理。
文档过滤和检索
Spring AI官方声称提供了一个“模块化”的RAG架构,用于优化大模型回复的准确性。
简单说,就是把整个文档过滤检索阶段拆分为:检索前,检索时,检索后,分别针对每个阶段提供了可自定义的组件。
- 在预检索阶段,系统接收用户的原始查询,通过查询转换和查询扩展等方法进行优化,输出增强的用户查询。
- 在检索阶段,系统使用增强的查询从知识库中搜索相关文档,可能涉及多个检索源的合并,最终输出一组相关文档。
- 在检索后阶段,系统对检索到的文档进行进一步处理,包括排序、选择最相关的子集以及压缩文档内容,输出经过优化的相关文档集。
预检索:优化用户查询
预检索阶段负责处理和优化用户的原始查询,以提高后续检索质量。Spring AI提供了多种查询处理组件。
查询转换 - 查询重写
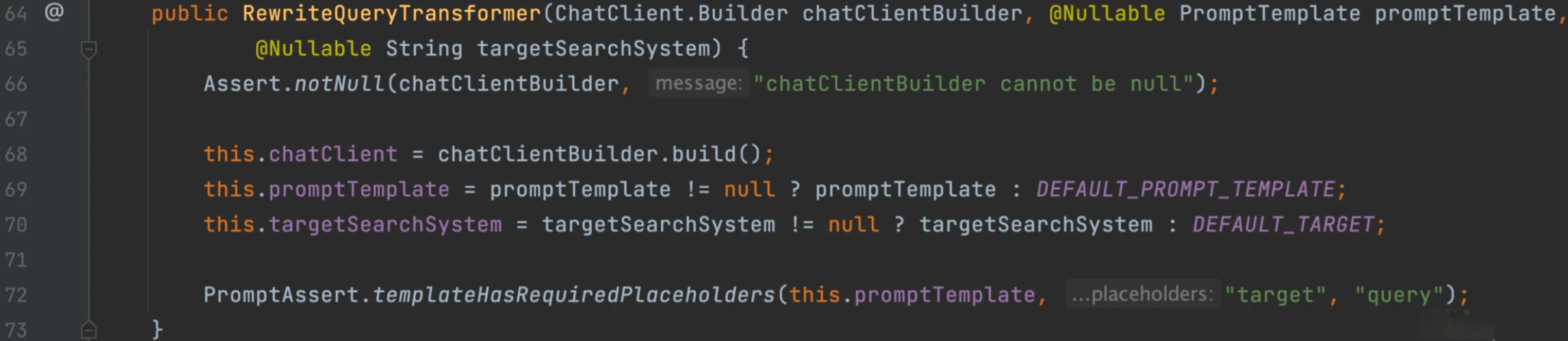
RewriteQueryTransformer使用大语言模型对用户的原始查询进行改写,使其更加清晰和详细。当用户查询含糊不清或者包含无关信息时,这种方法特别有用。
Query query = new Query("这是干啥啊?");
QueryTransformer queryTransformer = RewriteQueryTransformer.builder().chatClientBuilder(chatClientBuilder).build();
Query transformedQuery = queryTransformer.transform(query);实现原理很简单,从源码中能看到改写查询的提示词:
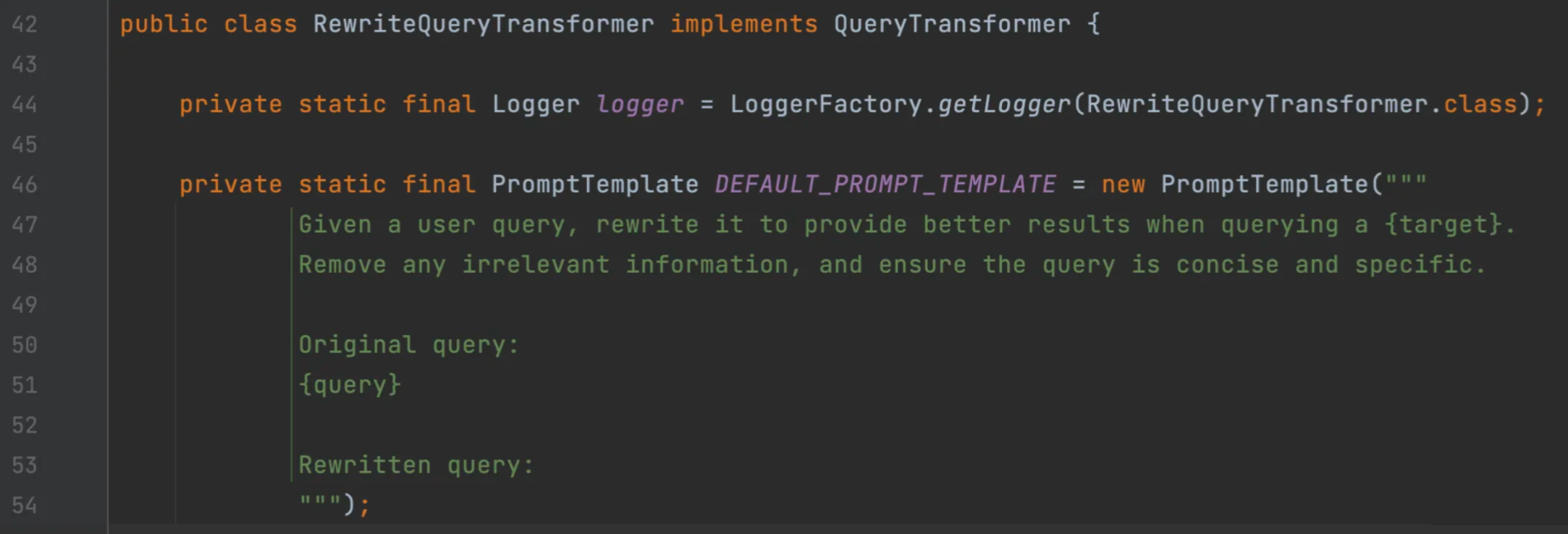
也可以通过构造方法的 promptTemplate 参数自定义该组件使用的提示板。
查询转换 - 查询翻译
TranslationQueryTransformer将查询翻译成嵌入模型支持的目标语言。如果查询已经是目标语言,则保持不变。对于嵌入模型是针对特定语言训练而用户查询使用不同语言的情况非常有用,便于实现国际化应用。
示例代码如下:
Query query = new Query("hi, who is coder yupi? please answer me");
QueryTransformer queryTransformer = TranslationQueryTransformer.builder().chatClientBuilder(chatClientBuilder).targetLanguage("chinese").build();
Query transformedQuery = queryTransformer.transform(query);语言可以随意指定,因为看源码我们会发现,查询翻译器也是通过给AI一段Prompt来实现翻译,也可以自定义翻译的Prompt:
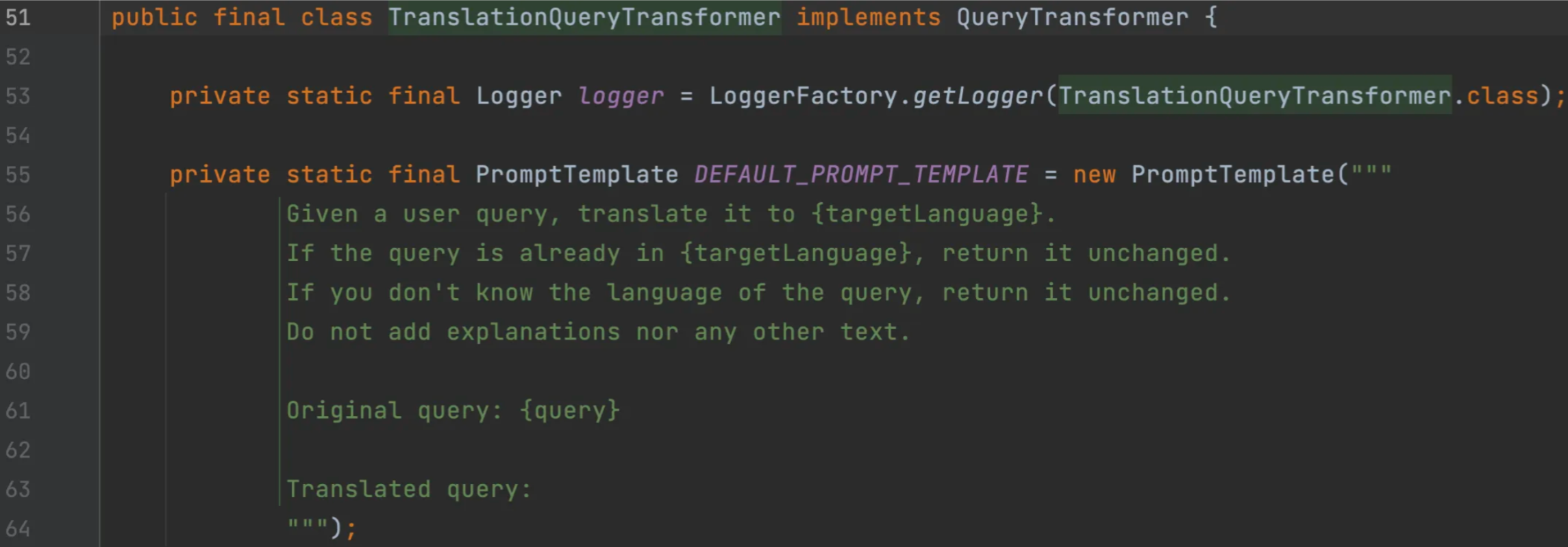
查询转换 - 查询压缩
CompressionQueryTransformer使用大语言模型对话历史和后续查询压缩成一个独立的查询,类似于概括总结。适用于对话历史较长且后续查询与对话上下文相关的场景。
示例代码:
Query query = Query.builder().text("遇到老赖怎么办?").history(new UserMessage("老赖怎么生存?"),new AssistantMessage("老赖的最终结果")).build();
QueryTransformer queryTransformer = CompressionQueryTransformer.builder().chatClientBuilder(chatClientBuilder).build();
Query transformedQuery = queryTransformer.transform(query);查看源码,同样可以定制Prompt模版:
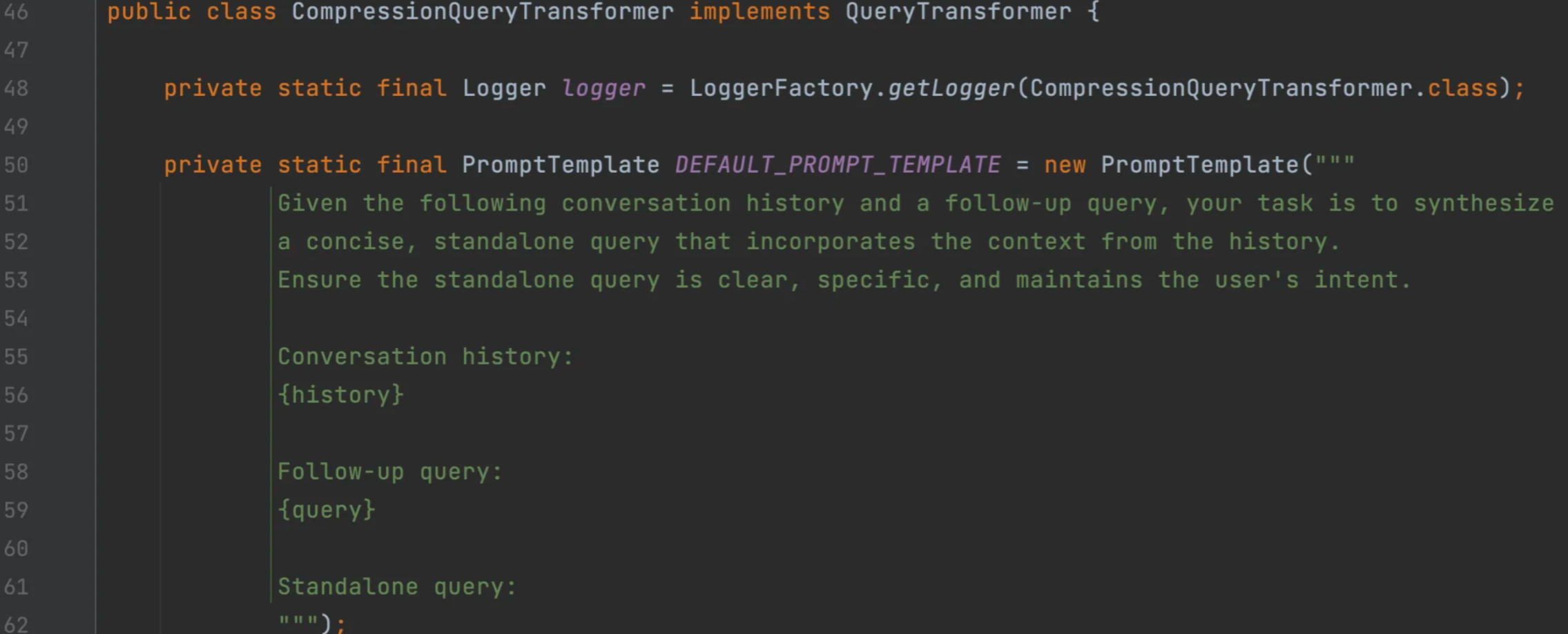
查询扩展 - 多查询扩展
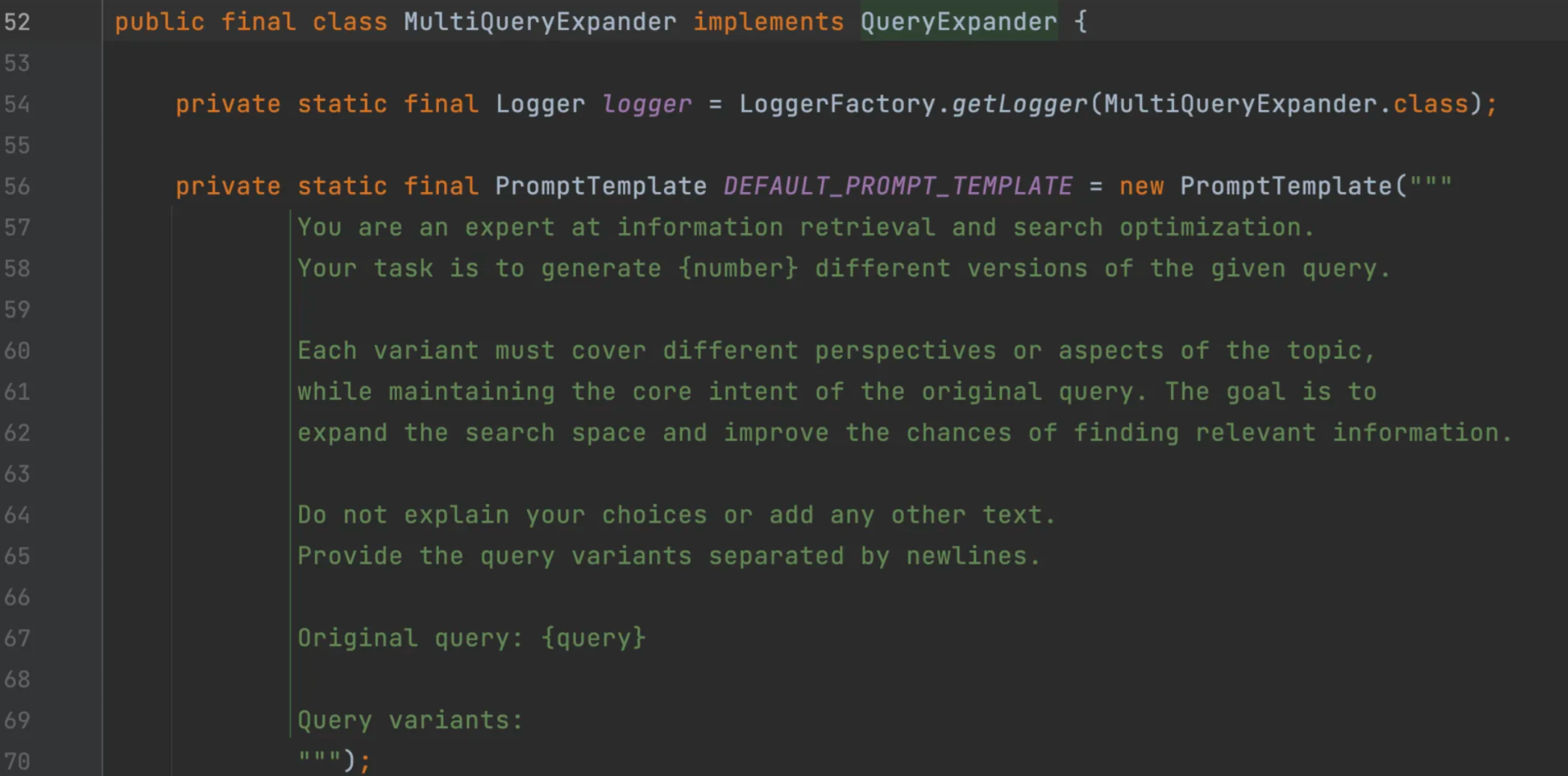
MultiQueryExpander使用大语言模型将个查询扩展为多个语义上不同的变体,有助于检索额外的上下文信息变增加找到相关结果的机会。就理解为我们在网上搜索东西的时候,可能一种关键词搜不到,就会尝试一些不同的关键词。
示例代码:
MultiQueryExpander queryExpander = MultiQueryExpander.builder().chatClientBuilder(chatClientBuilder).numberOfQueries(3).build();
List<Query> queries = queryExpander.expand(new Query("高速上车速多少,监控测速测不出来?"));这个问题,可能会被扩展为:
- 请问,小客车在限速120km/h的高速上,车速为多少,测速监控无法测出实际速度?
默认情况下,会在扩展查询列表中包含原始查询。可以在构造时通过 includeorigina1 方法改变这个行为:
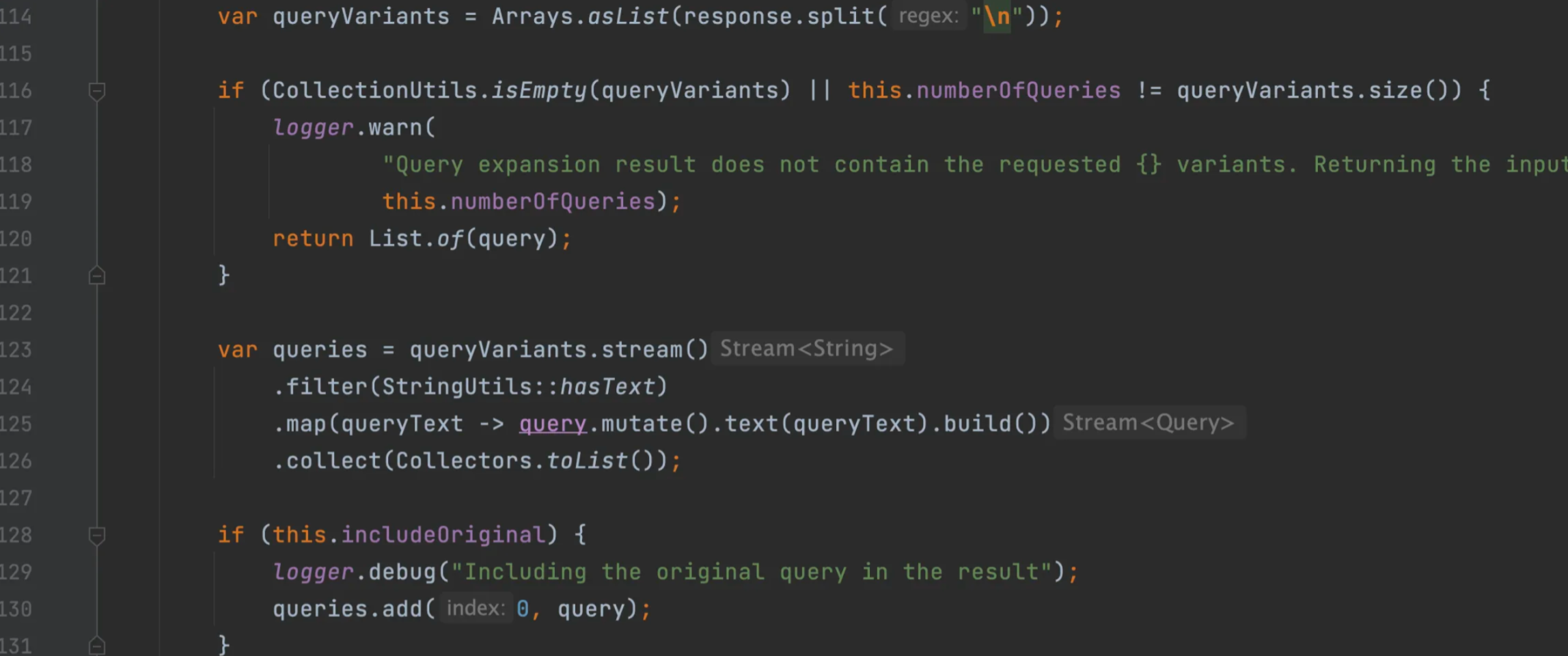
MultiQueryExpander queryExpander = MultiQueryExpander.builder().chatClientBuilder(chatClientBuilder).includeOriginal(false).build();查看源码,会先调用 AI得到查询扩展,然后按照换行符分割:
检索:提高查询相关性
检索模块负责从存储中查询出检索最相关的内容。
文档搜索
前面了解过DocumentRetriever的概念,这是Spring AI 提供的文档检索器。每种不同的存储方案都可以有自己的文档检索器实现类,比如VectorStoreDocumentRetriever,从向量存储中检索与输入查询语义相似的文档。他支持基于元数据的过滤、设置相似度阈值,设置返回的结果数。
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder().vectorStore(vectorStore).similarityThreshold(0.7).topK(5).filterExpression(new FilterExpressionBuilder().eq("type", "web").build()).build();
List<Document> documents = retriever.retrieve(new Query("这是谁啊,这么漂亮?"));上述代码中的filterException可以灵活的指定过滤条件,也可以通过构造Query对象的FILTER_EXCEPTION参数动态指定过滤表达式:
Query query = Query.builder().text("这是谁啊?").context(Map.of(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "type == 'boy'")).build();
List<Document> retrievedDocuments = documentRetriever.retrieve(query);文档合并
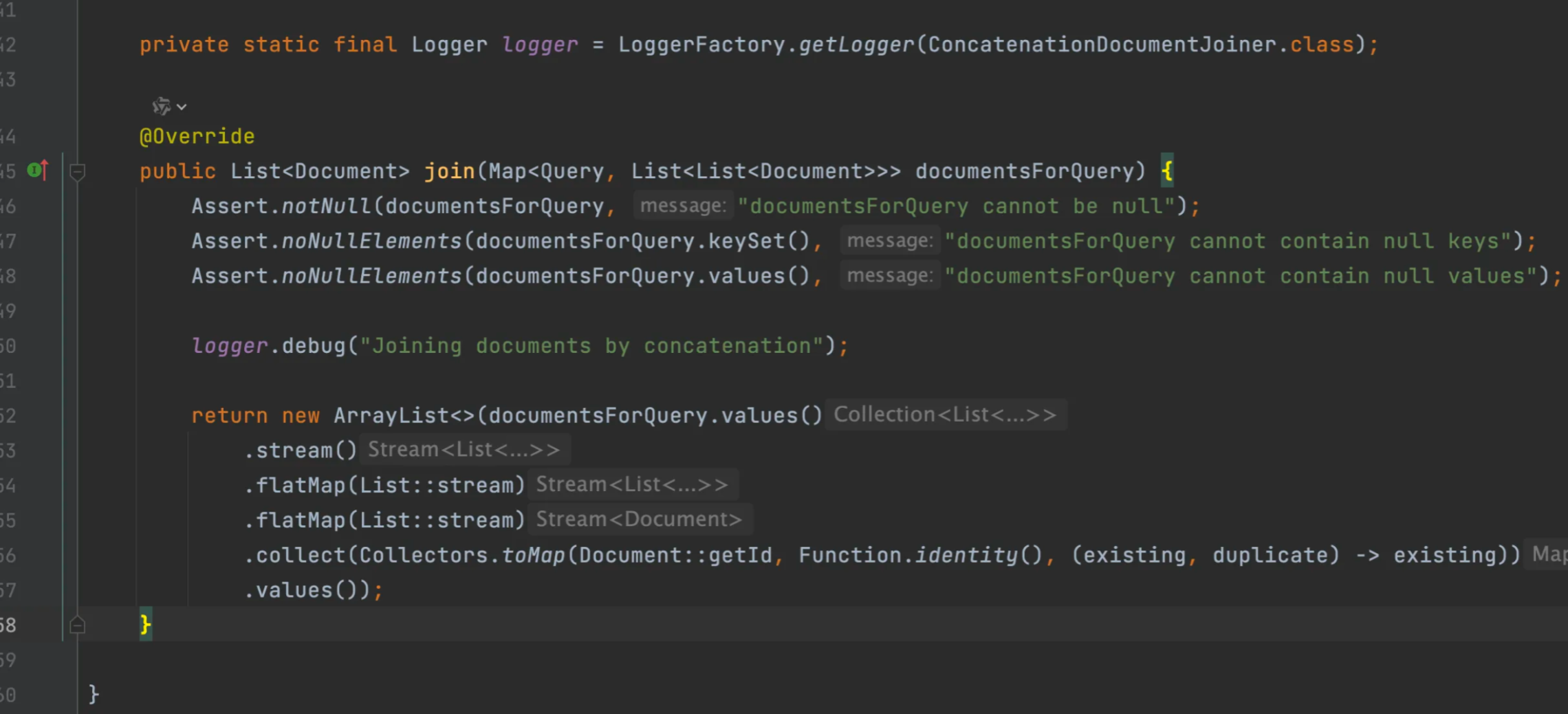
Spring AI内置了ConcatenationDocumentJoiner文档合并器,通过连接操作,将基于多个查询和来自多个数据源检索到文档合并成单个文档合集。在遇到重复文档时,会保留首次出现的文档,每个文档的分数保持不变。
Map<Query, List<List<Document>>> documentsForQuery = ...
DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();
List<Document> documents = documentJoiner.join(documentsForQuery);查看源码,说是“连接”,其实就是把Map展开为二维列表、再把二维列表展开成文档列表,最后进行去重。
检索后:优化文档处理
检索后模块负责处理检索到的文档,以实现最佳生成结果。他们可以解决“都是在中间”的问题、模型上下文长度限制,以及减少信息中的噪音和冗余。
包括:
- 根据与查询的相关性对文档进行排序
- 删除不相关或冗余的文档
- 压缩每个文档的内容以减少噪音和冗余
这块官方文档讲解较少,且更新很快,不作研究。
查询增强和关联
生成阶段是RAG流程的最终环节,负责将检索到的文档与用户查询结合起来,为AI提供必要的上下文,从而生成更准确,更相关的回答。
前面用过Spring AI提供的2中实现RAG查询增强的Advisor,分别是QuestionAnswerAdvisor和RetrievalAugmentationAdvisor。
QuestionAnswerAdvisor查询增强
当用户问题发送到AI模型时,Advisor会查询向量数据库来获取与用户问题相关的文档,并将这些文档作为上下文附加到用户查询中。
用法:
ChatResponse response = ChatClient.builder(chatModel).build().prompt().advisors(new QuestionAnswerAdvisor(vectorStore)).user(userText).call().chatResponse();可以使用建造者模式配置更精细的参数,比如文档过滤条件:
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)// 相似度阈值为 0.8,并返回最相关的前 6 个结果.searchRequest(SearchRequest.builder().similarityThreshold(0.8d).topK(6).build()).build();此外,QuestionAnswerAdvisor还支持动态过滤表达式,可以在运行时根据需要调整过滤条件:
ChatClient chatClient = ChatClient.builder(chatModel).defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore).searchRequest(SearchRequest.builder().build()).build()).build();// 在运行时更新过滤表达式
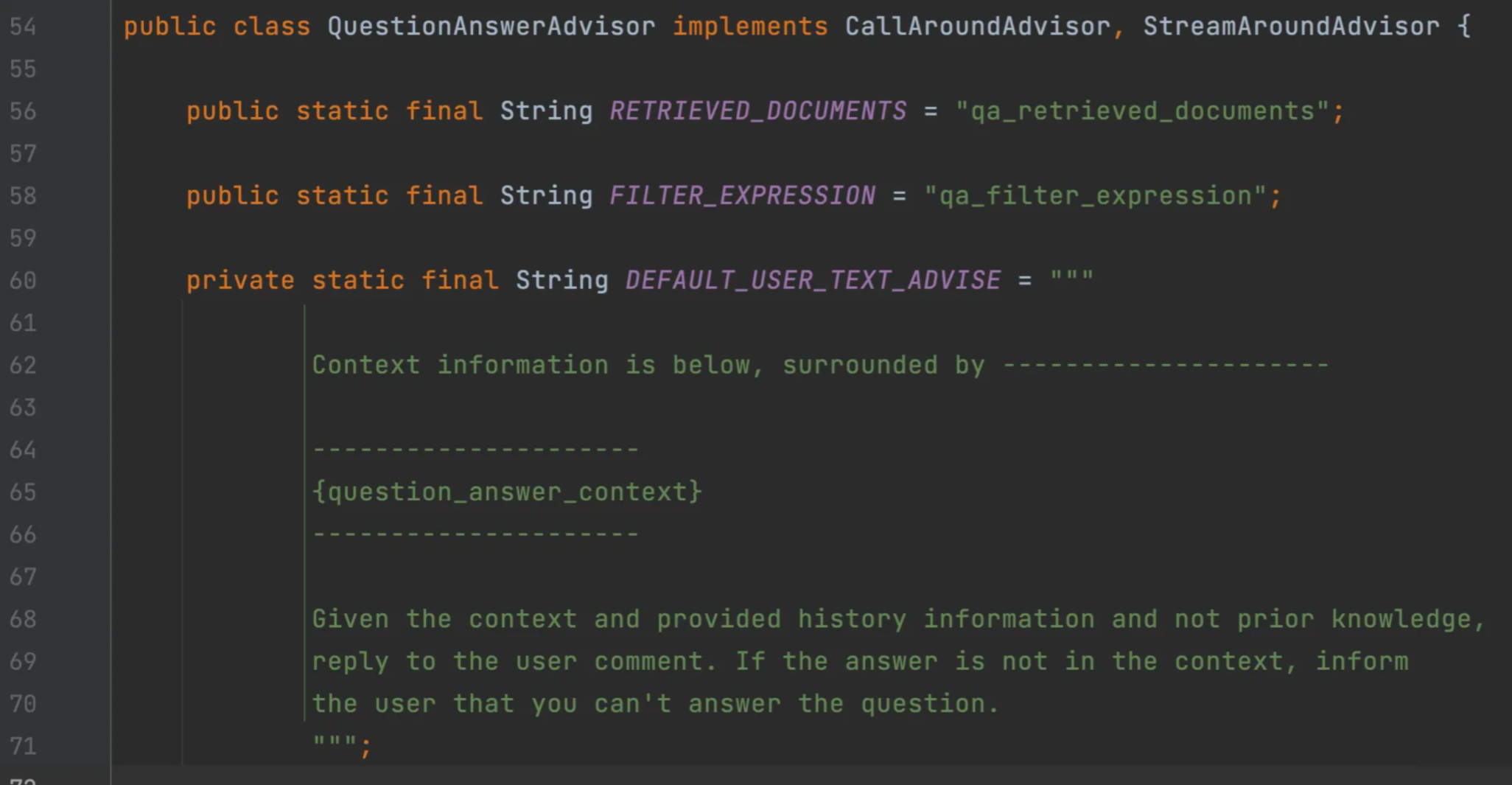
String content = this.chatClient.prompt().user("伤心了,难过了,不想努力了!").advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'web'")).call().content();QuestionAnswerAdvisor的实现原理,把用户提示词和检索到的文档等上下文信息拼成一个新的Prompt,再调用AI:
也可以自定义提示词模板,控制如何将检索到的文档与用户查询结合:
QuestionAnswerAdvisor qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore).promptTemplate(customPromptTemplate).build();RetrievalAugmentationAdvisor查询增强
Spring AI提供的另一种RAG实现方式,它基于RAG模块化架构,提供了更多的灵活性和定制选项
最简单的RAG流程可以通过一下方式实现:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder().documentRetriever(VectorStoreDocumentRetriever.builder().similarityThreshold(0.50).vectorStore(vectorStore).build()).build();
String answer = chatClient.prompt().advisors(retrievalAugmentationAdvisor).user(question).call().content();上述代码中,配置了VectorStoreDocumentRetriever文档检索器,用于向量存储中检索文档。然后将这个Advisor添加到ChatClient的请求中,让它处理用户的问题。
RetrievalAugmentationAdvisor还支持跟高级的RAG流程,比如结合查询转换器:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder().queryTransformers(RewriteQueryTransformer.builder().chatClientBuilder(chatClientBuilder.build().mutate()).build()).documentRetriever(VectorStoreDocumentRetriever.builder().similarityThreshold(0.50).vectorStore(vectorStore).build()).build();上述代码中,添加了一个RewriteQueryTransformer,他会在检索之前重写用户的原始查询,使其更加明确和详细,从而提高检索的质量。
ContextualQueryAugmenter空上下文处理
默认情况下,RetrievalAugmentationAdvisor不允许检索的上下文为空。当没有找到相关文档时,他会指示模型不要回答用户查询。这是一种保守的策略,可以防止模型在没有足够信息的情况下生成不准确的回答。
但在某些场景下,我们可能希望即使在没有相关文档的情况下也可能为用户提供回答,比如即使没有特定知识库支持也能回答的通用问题。可以通过配置ContextualQueryAugmenter上下文查询增强器来实现。
示例代码:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder().documentRetriever(VectorStoreDocumentRetriever.builder().similarityThreshold(0.50).vectorStore(vectorStore).build()).queryAugmenter(ContextualQueryAugmenter.builder().allowEmptyContext(true).build()).build();通过设置allowEmptyContext(true);,允许模型在没有找到相关文档的情况下也生成回答。
查看源码,发现有2处Prompt的定义,分别为正常情况下对用户提示词的增强,以及上下文为空时,使用的提示词:
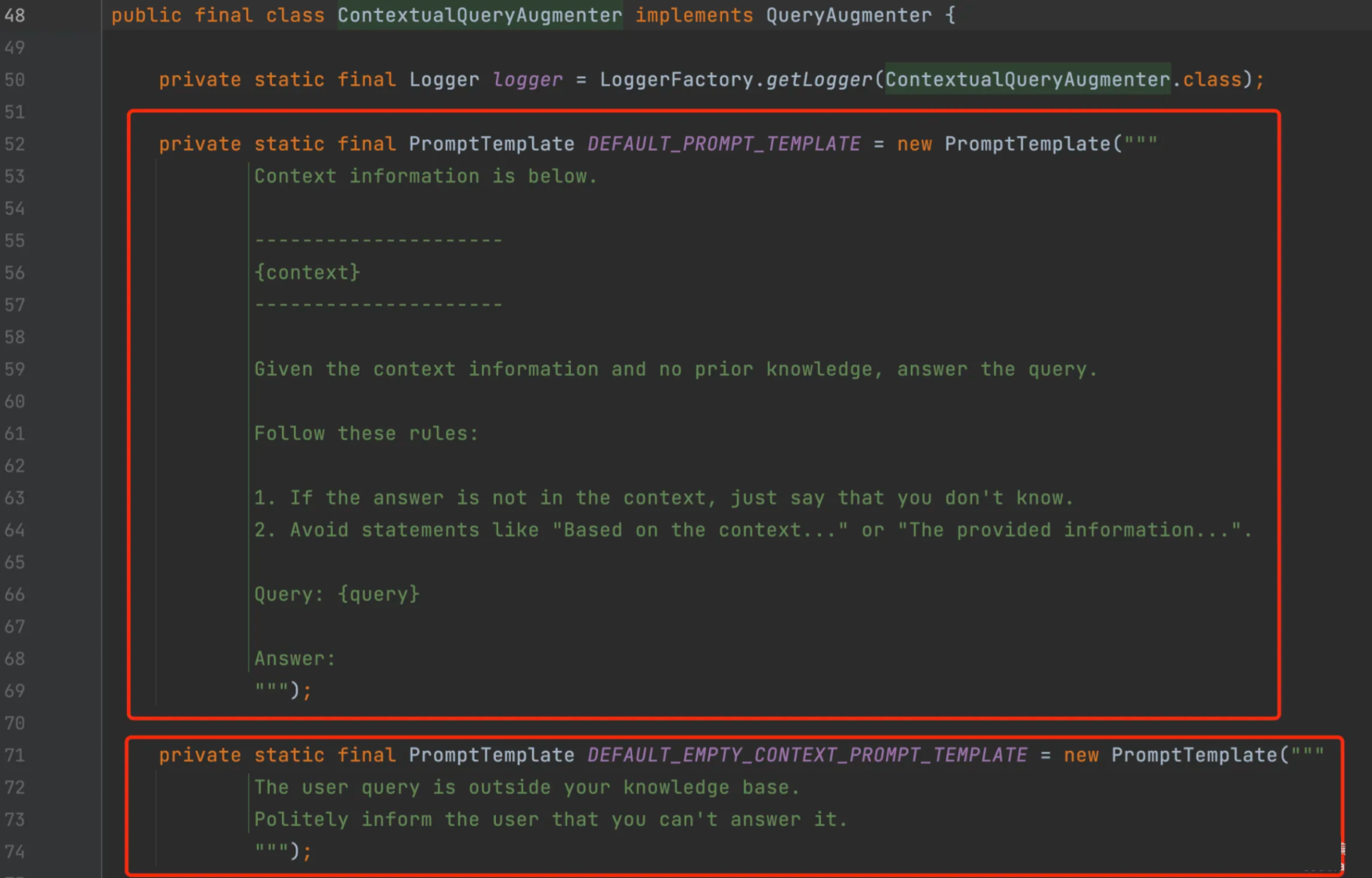
为了提供更友好的错误处理机制,ContextualQueryAugmenter允许我们自定义提示模板,包括正常情况下使用的提示模板和上下文为空时使用的提示模板:
QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder().promptTemplate(customPromptTemplate).emptyContextPromptTemplate(emptyContextPromptTemplate).build();通过定制emptyContextPromptTemplate,我们可以知道模型在没有找到相关文档时如何回应用户,比如礼貌的即使无法回答的原因,并可能引导用户尝试其他问题或提供更多信息。