MySQL Redo Log浅析
一、背景
MySQL的InnoDB引擎通过内存中的数据操作来提升数据库性能。然而,一旦数据库意外宕机,尚未刷盘的内存数据就可能会丢失。这对于大多数应用来说是不能容忍的的。为了保证即使发生故障也能恢复数据,InnoDB 引入了 重做日志(Redo Log) 机制。
二、Redo Log 简介
2.1 Redo Log的结构
InnoDB 将重做日志划分为多个 日志块(log block),每个块大小固定为 512 字节,如下图所示(原图省略):
每个日志块由三部分组成:头部(head)、正文(body)、尾部(tail)。
2.2 日志块结构
- head(头部,12 字节)
| 字段 | 长度 | 说明 |
|---|---|---|
HDR_NO | 4字节 | 当前日志块的唯一编号,从1开始递增 |
HDR_DATA_LEN | 2字节 | 表示当前块中已经使用的字节数,初始值为 12(即仅包含头部),写满后为 512 |
* FIRST_REC_GROUP | 2字节 | 记录当前块中第一个由 Mini-Transaction(简称 MTR) 生成的 redo log entry 的偏移量 |
* CHECKPOINT_NO | 4字节 | 当前日志块所属的检查点编号 |
-
Body(正文,496 字节)
存储具体的
redo log entry,即事务对数据的修改内容。 -
Tail(尾部,4 字节)
CHECKSUM(4字节):用于校验日志块内容是否正确。
2.3 Redo Log Entry的结构
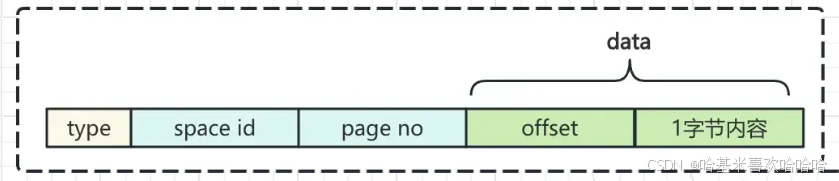
Redo Log 实际上记录的是每个事务对数据页的修改行为。每一条重做日志条目(redo log entry)包含以下结构:
- type:日志的类型,表示具体的修改行为。
- space id:表空间的编号,指示数据修改发生在哪个表空间中。
- page no:修改的数据页编号。
- data:日志的实际内容,记录修改的细节。
例如,如果 type 是 MLOG_1BYTE,就表示该日志条目记录了在某个页的某个偏移位置写入了 1 个字节的数据。
⚠️ 注意:这只是最简单的重做日志类型。实际的数据页还包含页眉、页脚和其他元数据。修改页面上的数据通常涉及更新页面上的许多字段。因此,InnoDB设计了几种复杂类型的重做日志,本质上是自定义规则——不用硬记。
三、Redo Log分组提交(Mini-Transaction)
在实际运行中,一个 SQL 语句可能会修改多个数据页和索引页,会生成多个不同 page no 的日志条目。为了实现原子性,这些日志必须作为一个整体一次性写入。InnoDB 引入了 Mini-Transaction(MTR) 概念,作为 redo log 的最小提交单元。
每组 MTR 的最后一条日志类型固定为 MLOG_MULTI_REC_END,InnoDB 通过这个标识将多个 MTR 区分开来。
空间利用优化
问题:仅有一条日志条目也必须加上MLOG_MULTI_REC_END吗,这样是否会造成空间浪费?。
答:针对这种情况,InnoDB 对 type 字段进行了设计优化。type 的定义使用一个字节的后 7 位(即支持 128 种类型,目前有50多种)表示日志类型。最前面的 1 位用于标识该日志是否是独立的单条记录。
此外,日志块头部的FIRST_REC_GROUP会记录当前块中第一个 MTR 的偏移地址,用于后续恢复时的分组解析。
四、Redo Log写入流程
4.1 写缓存
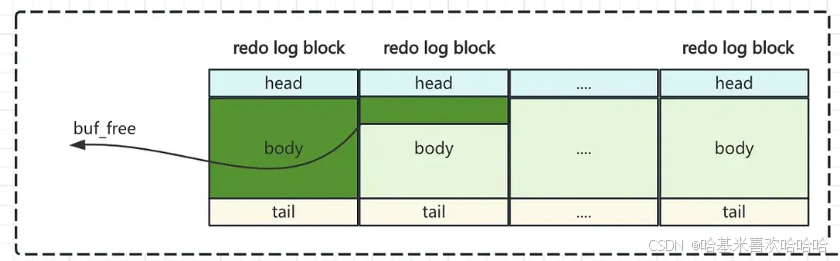
InnoDB 在内存中维护 redo log。前面所说的 redo log block 就是内存中的格式。
当生成一条新的 redo log,它会被顺序追加到 redo log buffer(重做日志缓冲区)中。InnoDB 会维护一个全局变量 buf_free,表示下一个可写入的位置。
⚠️ 注意
- 每次写入MTR时,并不是立即写入每个单独的重做日志条目。
- 单个事务可能会生成多个MTR,这些MTR可能交错写入缓冲区写入重做日志缓冲区。
4.2 写磁盘
(1)磁盘结构
日志最终要写入磁盘,以便数据库重启后可以恢复。在实际生产环境中,可以配置多个 redo log 文件(如三个 1GB 文件),这些文件循环使用。Redo Log 落盘的磁盘结构如下图。
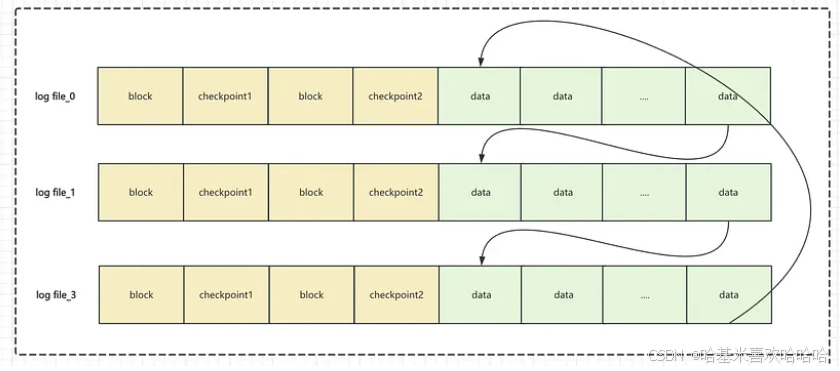
双Checkpoint 机制
磁盘上有两个 checkpoint(检查点)。我的理解是一个有助于优化并发性能,而另一个作为后备,以防出现意外问题(检查点更新期间出现异常,导致使该检查点无法使用)。
(2)写盘时机
InnoDB提供了innodb_flush_log_at_trx_commit参数用于控制重做日志缓冲区中的数据何时刷新到磁盘。
| 参数值 | 说明 |
|---|---|
| 0 | 事务提交时不立即刷盘,由后台线程异步完成(可能导致数据丢失)。 |
| 1 | 每次事务提交时立刻刷盘,确保数据持久性(默认推荐)。 |
| 2 | 提交时写入操作系统 的缓冲区,但不保证立即刷盘到物理磁盘。如果MySQL服务崩溃,但操作系统仍然正常工作,操作系统仍然可以将缓冲的数据刷新到磁盘。 |
⚠️ 注意:当设置为 1 时,某个事务刷盘时可能会将其他尚未提交事务的日志也一并刷入磁盘。因为每个MTR都被写入重做日志缓冲区,因此不同的事务可能具有重叠的重做日志条目
五、LSN 与 Checkpoint
Redo Log 是“环形”写入结构,终究会写满,因此需要重用旧的空间。为了安全回收已写入磁盘页面的redo log空间,同时减少宕机恢复所需的操作量,InnoDB 引入了 LSN(Log Sequence Number)日志序列号 和 Checkpoint(检查点) 的机制。
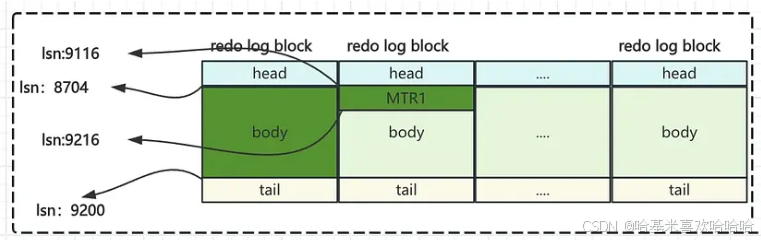
5.1 LSN 的值
LSN 实质上就是当前日志写入的“字节偏移值”,即 redo log 的总写入长度。从初始值 8704 开始,随着写入不断递增。早期版本使用 4 字节无符号整数表示 LSN,从 MySQL 5.6.3 起升级为 8 字节无符号整数,几乎无限大,仅受配置限制。
5.2 恢复流程(Checkpoint起作用的部分)
Redo Log 的核心作用在于MySQL崩溃后数据恢复。
InnoDB 会执行以下流程进行恢复:
- 在重做日志文件中找到最近的检查点,获取其对应的 LSN,LSN小于此值的任何数据页都已刷新到磁盘,无需重做。
- 恢复过程从检查点号小于找到的LSN的块开始,重做操作从那里开始。由于重做日志是逐条存储的,因此可以逐页执行数据恢复。
- 通过按
space_id和page_no对日志进行分组来加速此过程,允许一次恢复一页。
⚠️ 注意:某些页面可能已经刷新到磁盘,但检查点尚未更新。在这种情况下,InnoDB会比较存储在每个页面中的记录最近修改的LSN值(称为n_m值),以确定是否需要恢复。
六、总结
- Redo Log 是由多个连续的 512 字节块组成,每块包含头部、正文和尾部;
- 事务的修改操作首先写入内存中的 redo log buffer,随后在一定条件下刷新至磁盘上的 redo log 文件中;
- 多个 redo log 文件采用循环写入的方式,因此写入顺序且高效;
- InnoDB 通过 checkpoint 机制不断将内存脏页刷盘,并更新对应 LSN,以便宕机恢复时无需重放全部日志;
- Redo Log 能确保事务在提交后,即使数据库宕机也不会丢失数据,保证事务的持久性;
- 通过提前写入 redo log,InnoDB 允许多个事务并发提交,从而提升系统并发性能。