Yarn Application 日志总结
前言
总结整理 Yarn 任务运行日志。主要解决:
- Web UI 查看运行中 yarn 任务对应的所有 container 的日志
- Web Ui 查看已经结束的历史 yarn 任务对应的 所有 container 的日志
- 任务异常结束后,如果日志聚合失败,保留 NodeManager 本地日志
版本
- Flink 1.15.3
- Hadoop 3.4.1、3.1.4
运行中的日志
命令行
在命令中查看:
yarn logs -applicationId <application ID>
Web UI
Resource Manager Web UI 默认端口:8088
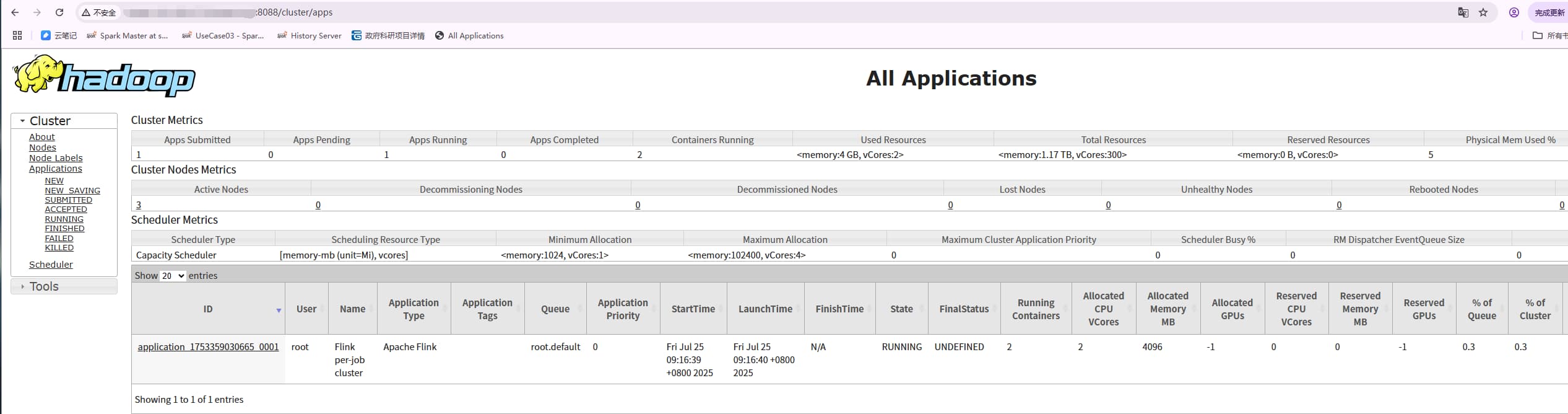
3.4.1 和 3.1.4 的 Web UI 界面稍微有所不同:
3.4.1:
3.1.4:
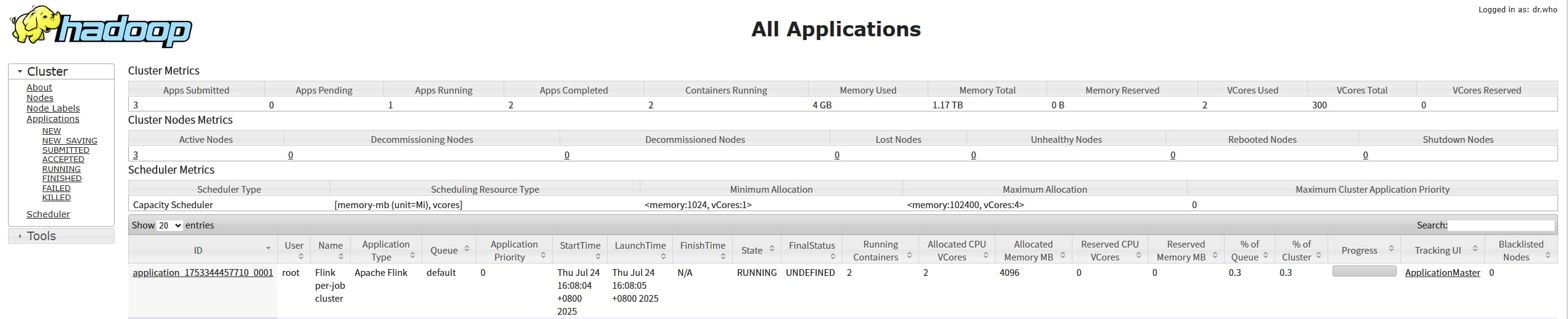
点击 Application ID,进到详情页,这里只能看 ApplicationMaster 的日志,对应 Flink 则为 JobManager,点击 jobmanager.log 就可以查看详细的JobManager日志。
对应地址:http://nodemanagerIp:8042/node/containerlogs/container_1753359030665_0001_01_000001/root

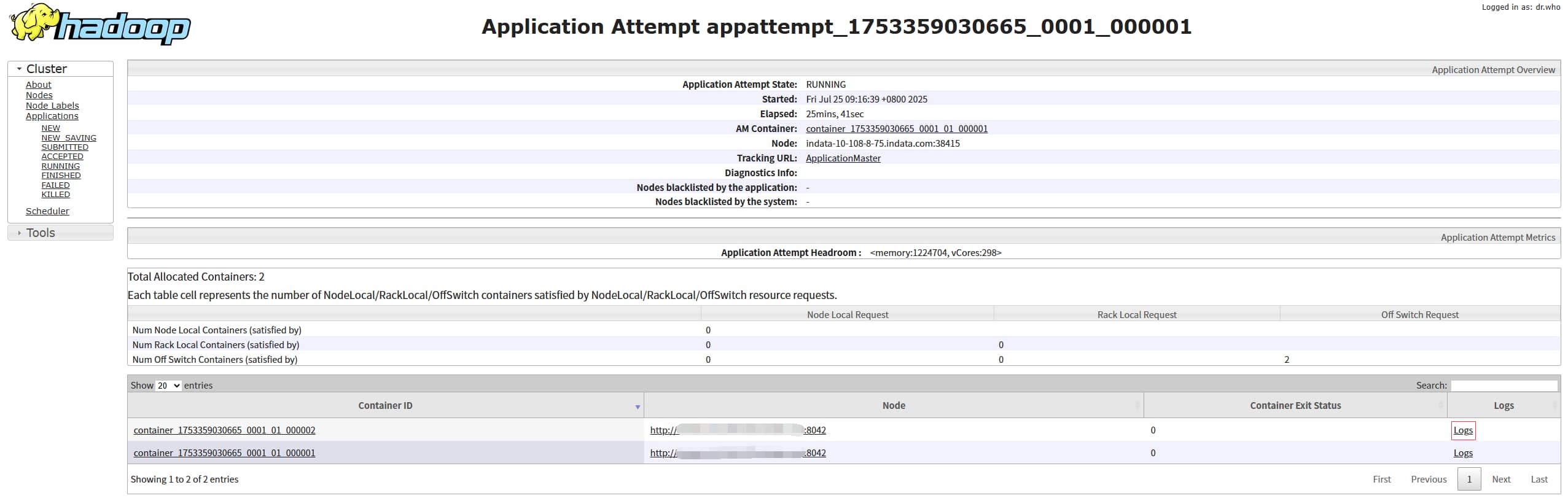
其他 container 的日志对应 flink 的 taskmanager :点击 Attempt Id, 进到 Attempt 详情页,就可以看其他 container的日志了,containerId 是和 attemptId 绑定的,一个yarn 任务如果有失败重试的话会有多个 attemptId。
对应地址:http://nodemanagerIp:8042/node/containerlogs/container_1753359030665_0001_01_000002/root

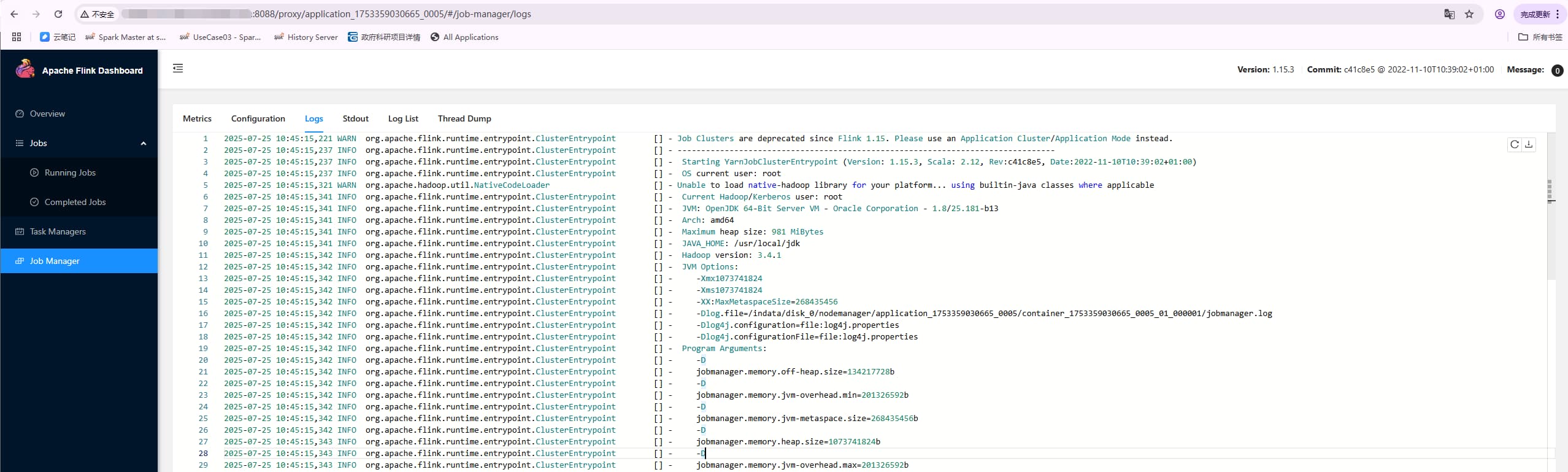
当然运行中的日志也可以通过 flink web ui 查看:resourceMangerIp:8088/proxy/applicationId
日志存储路径
本地
运行中任务日志存储在本地,由参数 yarn.nodemanager.log-dirs 决定,比如:
<property><name>yarn.nodemanager.log-dirs</name><value>/indata/disk_0/nodemanager</value>
</property>
- 那么本地路径为 /indata/disk_0/nodemanager/applicationId
- 一个 yarn 任务有多个 container ,不同的 container 可能在相同的 nodemanager 也可能在不同的 nodemanager ,本地日志需要去 container 对应的 nodemanager 机器查看
- 如果运行中的任务对应的本地日志文件被意外删除,那么无论通过命令行还是 Web UI 都将看不到日志了

聚合
相关参数:
<!-- 开启日志聚合 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 日志聚合HDFS目录 -->
<property><name>yarn.nodemanager.remote-app-log-dir</name><value>/app-logs</value>
</property>
yarn 任务结束后会将本地日志聚合到对应的 hdfs 路径下,这里的路径为 /app-logs ,其实在任务运行中,该任务对应的路径已经存在了,只不过文件为空,大小为0

历史任务日志
上面提到了 yarn 任务结束后会将本地日志聚合到对应的 hdfs 路径下 ,所以我们在任务结束后也可以查看任务日志
命令行
在命令中查看:
yarn logs -applicationId <application ID>
Web UI
与运行中的任务有两个不同点:一个是点击logs 后 如果没有配置 yarn.log.server.url ,访问地址一样,但是会提示需要配置 Log Server url ,看不到任何日志 ,

yarn.log.server.url 配置参数:
<property><name>yarn.log.server.url</name><value>http://JobHistoryServerIp:19888/jobhistory/logs</value></property>这里的 JobHistoryServerIp:19888 是 mapreduce.jobhistory.webapp.address 对应的地址:
mapred-site.xml
<!-- 配置 MapReduce JobHistory Server HTTP地址, 默认端口19888 --><property><name>mapreduce.jobhistory.webapp.address</name><value>0.0.0.0:19888</value></property>所以还要在对应节点启动 MapReduce JobHistory Server ,启动命令:
mapred --daemon start historyserver
这样再点击 logs ,就可以看到对应的日志了,但是地址已经变了:http://JobHistoryServerIp:19888/jobhistory/logs/nodemanagerIp:40879/container_1753359030665_0001_01_000001/container_1753359030665_0001_01_000001/root
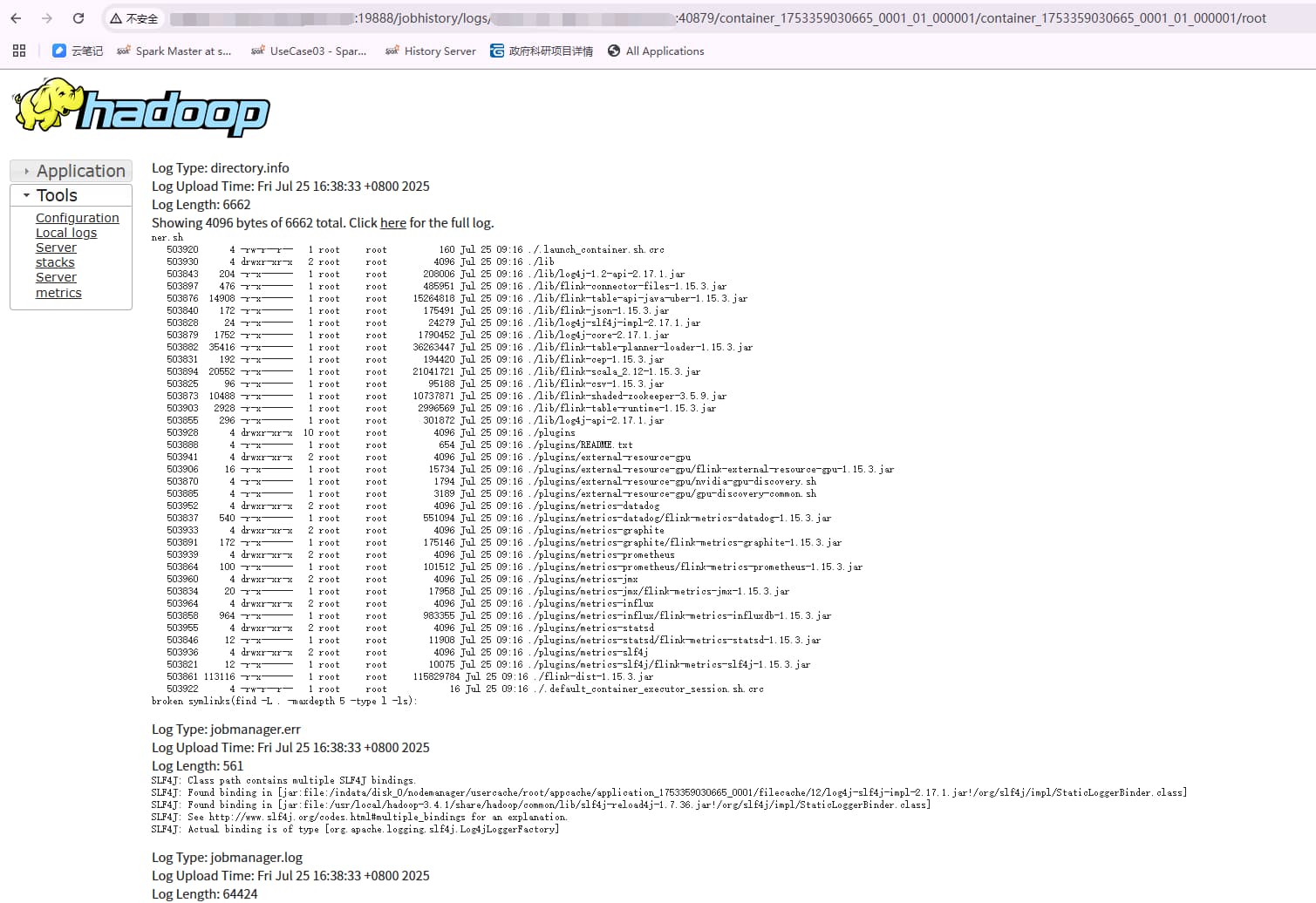
另一个不同点是,任务结束后 Attempt 详情页是看不到 container 的,也就是Attempt 详情页只能看到运行中的 container,这样我们就没法直接看另一个 container 对应的 taskmanager 日志了。
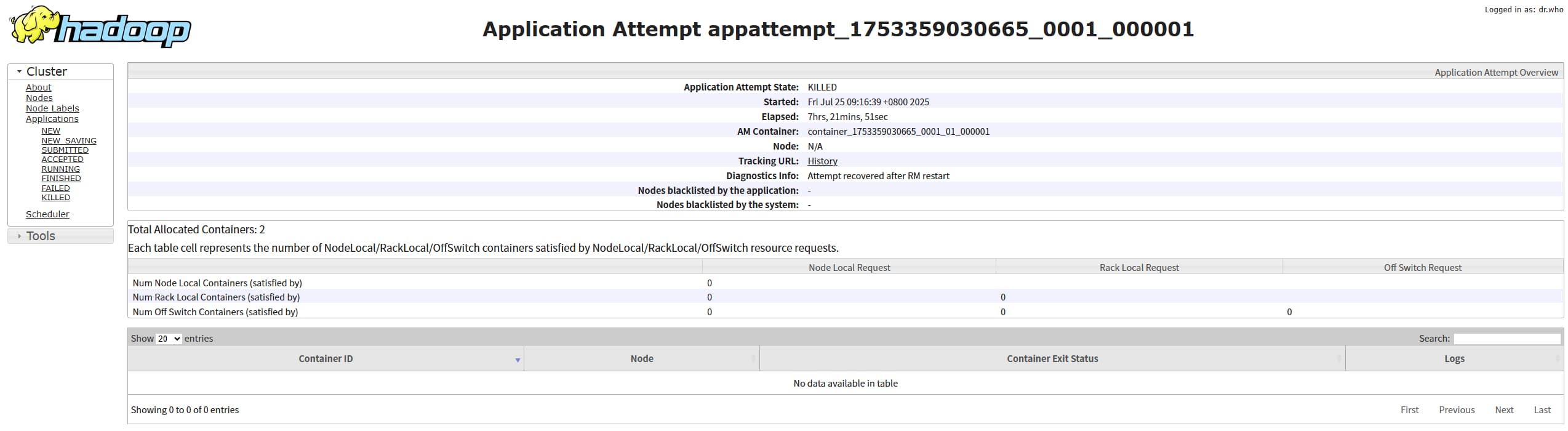
那么该怎么看呢?其实只要我们知道对应的 nodemanagerIp、port、containerId 就可以了,最开始查到如下命令:
yarn container -list <Attempt ID>
但是他只能查看运行中的 container

最终通过命令:
yarn logs -applicationId <Application Id> -show_application_log_info
这样根据返回的信息,就可以得到taskmanager 对应的历史地址 url了。

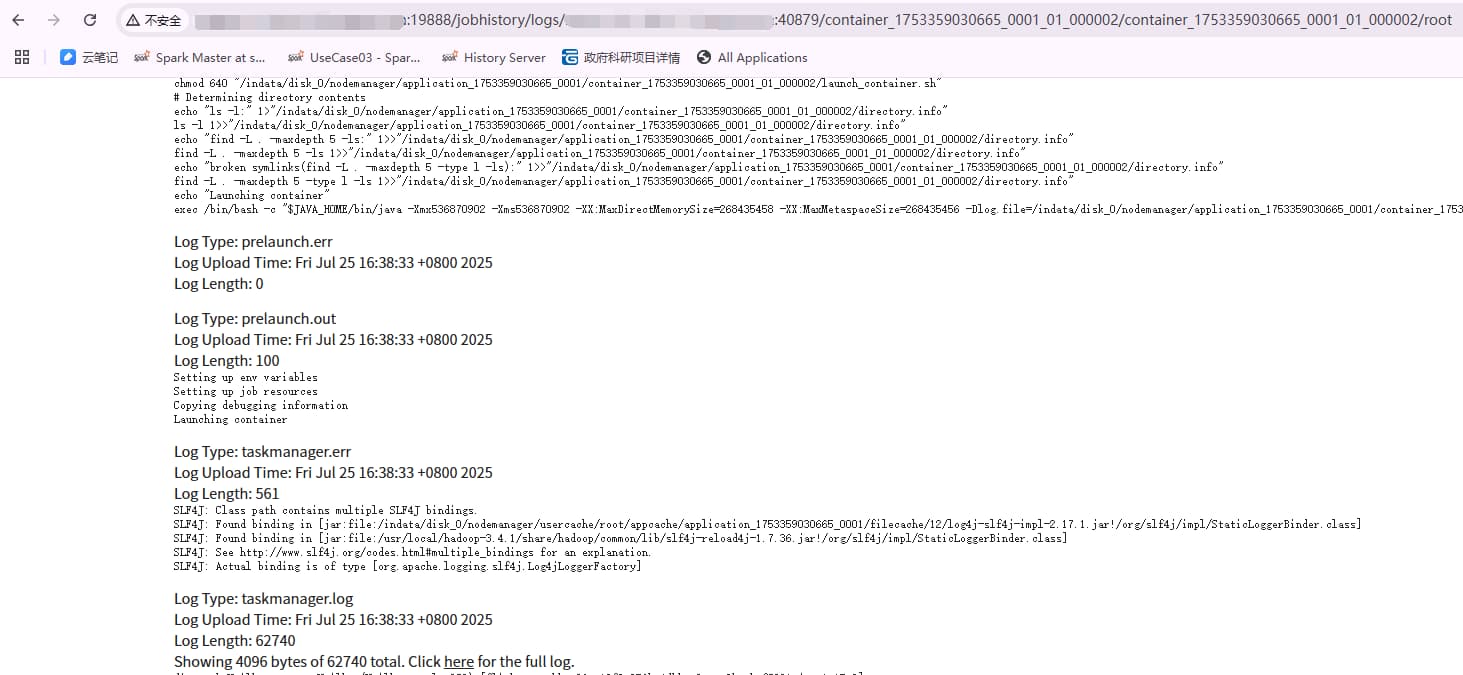
日志文件
对于历史任务,默认参数下(已开启日志聚合),在任务结束时会将本地日志聚合到HDFS路径下,本地的日志文件会立马删除。

其他参数
保留时间
<!-- 聚合日志保留时间,默认 -1 即不删除 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>2592000</value>
</property><!-- nodemanager 任务完成后本地日志保留时间,默认 0 即不保留 -->
<!-- 有时会遇到任务异常结束后,日志聚合没成功,这时就需要保留本地日志,方便分析原因 -->
<property><name>yarn.nodemanager.delete.debug-delay-sec</name><value>86400</value>
</property><!-- 保留用户日志的时长(以秒为单位),但需注意该参数仅在日志聚合功能关闭时才适用 -->
<property><name>yarn.nodemanager.log.retain-seconds</name><value>86400</value>
</property>
日志路径
<property><description>运行中的任务日志对应的本地存储路径</description><name>yarn.nodemanager.log-dirs</name><value>/indata/disk_0/nodemanager</value>
</property><property><description>Where to aggregate logs to. 默认值 /tmp/logs</description><name>yarn.nodemanager.remote-app-log-dir</name><value>/app-logs</value>
</property><property><description>The remote log dir will be created at {yarn.nodemanager.remote-app-log-dir}/${user}/{thisParam}</description><name>yarn.nodemanager.remote-app-log-dir-suffix</name><value>logs</value>
</property><property><name>yarn.log-aggregation.TFile.remote-app-log-dir-suffix</name><value>logs</value>
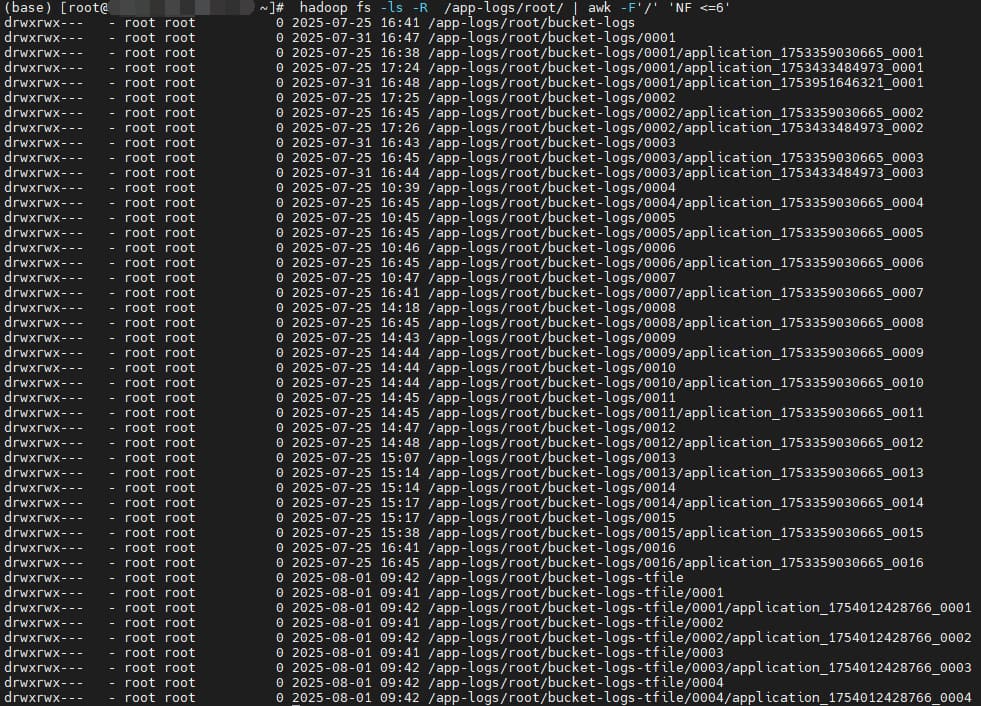
</property> 这里主要是想总结一下聚合日志路径格式:
在没有配置 yarn.log-aggregation.TFile.remote-app-log-dir-suffix 时:
Hadoop 3.1.4 : ${yarn.nodemanager.remote-app-log-dir}/${user}/${yarn.nodemanager.remote-app-log-dir-suffix}-tfile/${appId}
Hadoop 3.4.1 : ${yarn.nodemanager.remote-app-log-dir}/${user}/bucket-${yarn.nodemanager.remote-app-log-dir-suffix}-tfile/${bucketDir}/${appId}
HDP 3.1.1.3.1.0.0-78 : ${yarn.nodemanager.remote-app-log-dir}/${user}/${yarn.nodemanager.remote-app-log-dir-suffix}/${appId}
对应到上面的参数:
Hadoop 3.1.4 : /app-logs/${user}/logs-tfile/${appId}
Hadoop 3.4.1 : /app-logs/bucket-${user}/logs-tfile/${appId}
HDP 3.1.1.3.1.0.0-78 :/app-logs/${user}/logs/${appId}
可以看到开源的 3.1.4 版本在 yarn.nodemanager.remote-app-log-dir-suffix 后面加了 -tfile、开源的 3.4.1 版本又加了 bucket-,但我不喜欢加 tfile这种格式,更喜欢 HDP 的格式,于是我搜了一下 3.1.4 查看为啥会加默认加 -tfile,最后发现通过添加 yarn.log-aggregation.TFile.remote-app-log-dir-suffix 就可以去掉 -tfile 从而实现我想要的格式效果。
注意:修改日志路径不仅要重启 Yarn,还要重启 MapReduce JobHistory Server
相关源码
3.1.4 版本:
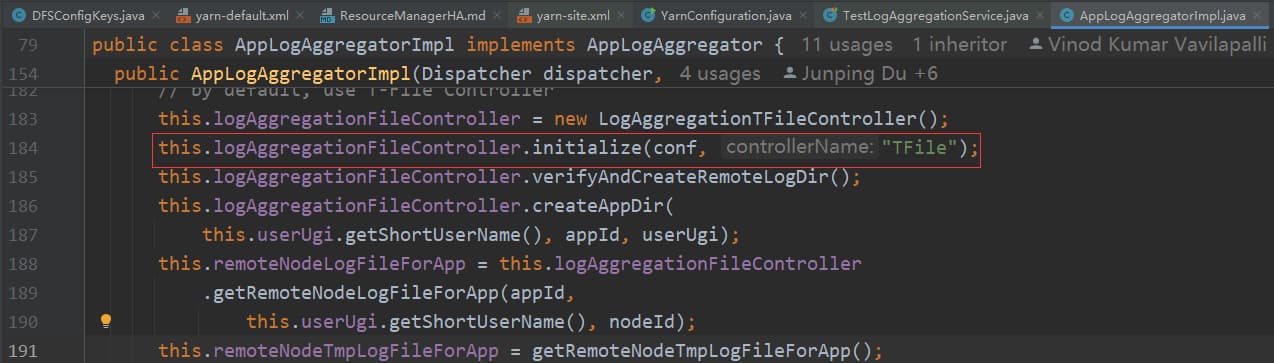
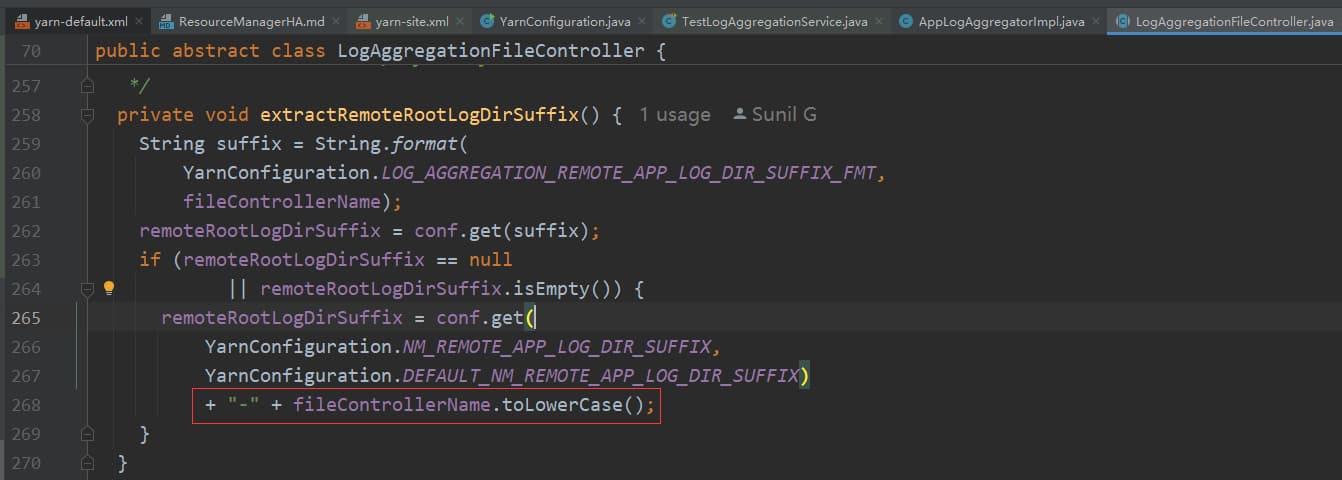
public static final String YARN_PREFIX = "yarn.";
public static final String LOG_AGGREGATION_REMOTE_APP_LOG_DIR_FMT= YARN_PREFIX + "log-aggregation.%s.remote-app-log-dir";/** Prefix for all node manager configs.*/
public static final String NM_PREFIX = "yarn.nodemanager.";
public static final String NM_REMOTE_APP_LOG_DIR_SUFFIX = NM_PREFIX + "remote-app-log-dir-suffix";
主要逻辑就是先判断有没有设置 yarn.log-aggregation.TFile.remote-app-log-dir-suffix 如果有的话,则 remoteRootLogDirSuffix 取值为 ${yarn.log-aggregation.TFile.remote-app-log-dir-suffix} ,如果没有则 remoteRootLogDirSuffix 取值为 ${yarn.nodemanager.remote-app-log-dir-suffix}-tfile
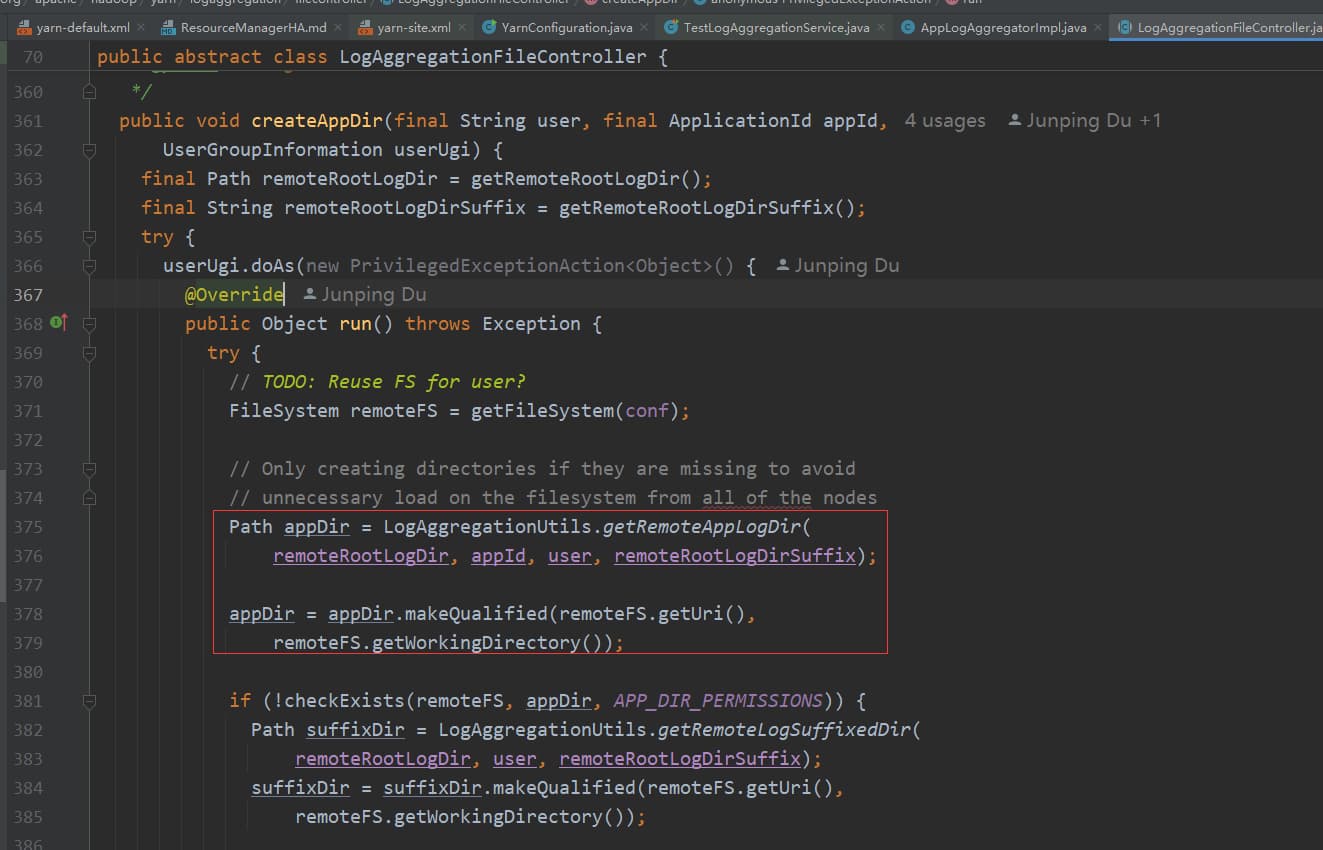
3.4.1 版本因为多了一层 ${bucketDir} ,所以当设置了 yarn.log-aggregation.TFile.remote-app-log-dir-suffix 其对应的值为 bucket-${yarn.log-aggregation.TFile.remote-app-log-dir-suffix} ,对应代码:
public static Path getRemoteAppLogDir(Path remoteRootLogDir,ApplicationId appId, String user, String suffix) {return new Path(getRemoteBucketDir(remoteRootLogDir, user, suffix,appId), appId.toString());}public static Path getRemoteBucketDir(Path remoteRootLogDir, String user,String suffix, ApplicationId appId) {int bucket = appId.getId() % 10000;String bucketDir = String.format("%04d", bucket);return new Path(getRemoteLogSuffixedDir(remoteRootLogDir,user, suffix), bucketDir);}public static Path getRemoteLogSuffixedDir(Path remoteRootLogDir,String user, String suffix) {suffix = getBucketSuffix() + suffix;return new Path(getRemoteLogUserDir(remoteRootLogDir, user), suffix);}public static String getBucketSuffix() {return BUCKET_SUFFIX;}private static final String BUCKET_SUFFIX = "bucket-";
效果截图
3.1.4 :

3.4.1 :
NodeManager 端口
<property><description>Ephemeral ports (port 0, which is default) cannot be used for the NodeManager's RPC server specified via yarn.nodemanager.address as it can make NM use different ports before and after a restart. This will break any previously running clients that were communicating with the NM before restart. Explicitly setting yarn.nodemanager.address to an address with specific port number (for e.g 0.0.0.0:45454) is a precondition for enabling NM restart.临时端口(默认端口0)不能用于通过yarn.nodemanager.address指定的NodeManager的RPC服务器,因为这会导致NM在重启前后使用不同的端口。这将中断重启前与NM通信的任何正在运行的客户端。将yarn.nodemanager.address显式设置为具有特定端口号(例如0.0.0.0:45454)的地址是启用NM重启的先决条件。</description> <name>yarn.nodemanager.address</name><value>0.0.0.0:45454</value>
</property>
默认参数时:
<property><description>The address of the container manager in the NM.</description><name>yarn.nodemanager.address</name><value>${yarn.nodemanager.hostname}:0</value>
</property><property><description>The hostname of the NM.</description><name>yarn.nodemanager.hostname</name><value>0.0.0.0</value>
</property>
除了上面说的会中断重启前与NM通信的任何正在运行的客户端,还会导致不同的 yarn 任务历史日志对应的端口不同:

这样访问起来比较麻烦,可以通过配置固定端口号来解决这个问题。
