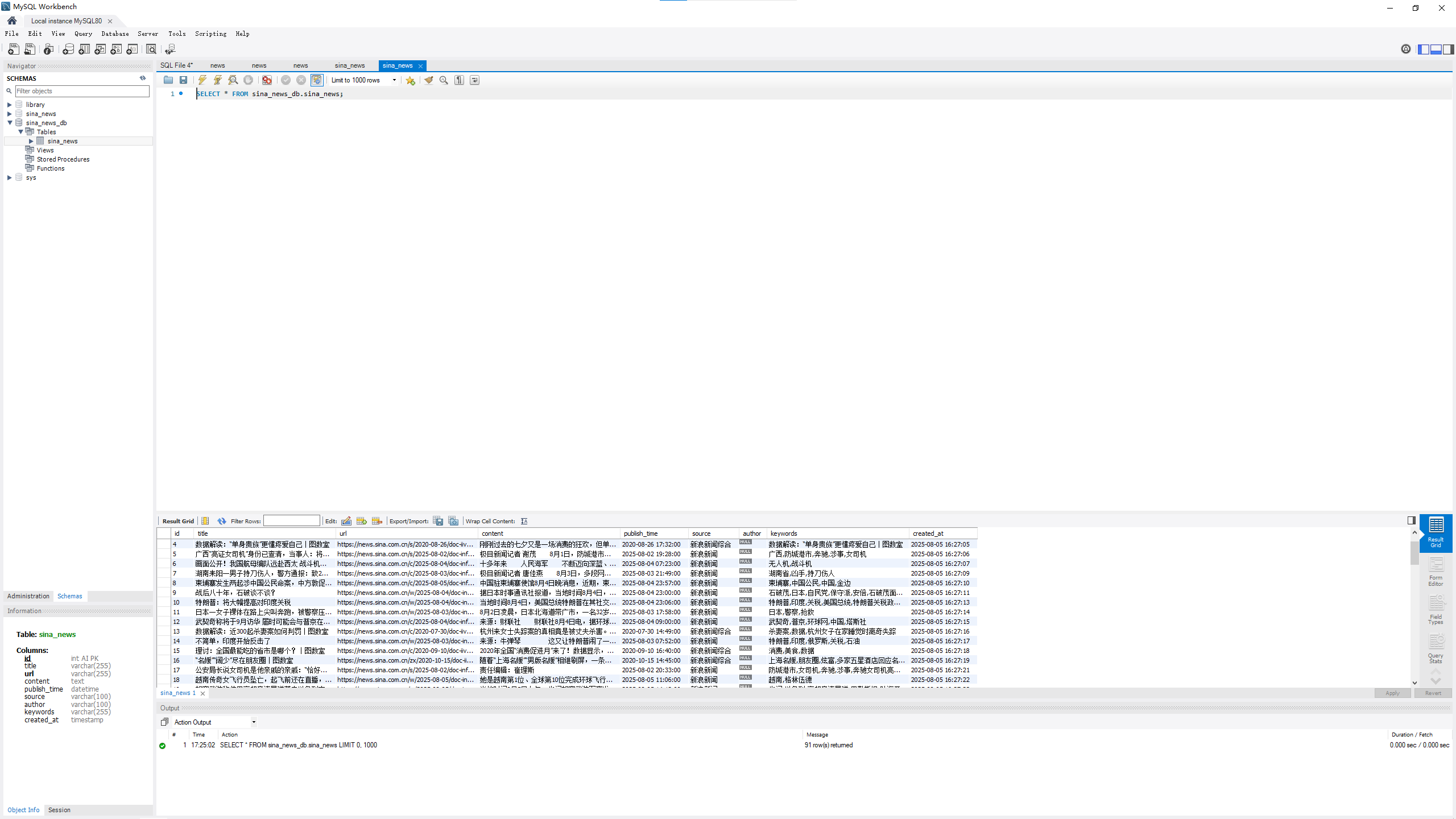
新浪新闻获取
# 新浪新闻爬虫项目## 项目简介
这是一个使用Scrapy框架开发的新浪新闻爬虫,能够爬取新浪新闻网站的新闻内容,并将数据保存到MySQL数据库中。## 项目结构
```
sina_news_spider/
├── scrapy.cfg # 项目配置文件
├── sina_news_spider/
│ ├── __init__.py
│ ├── items.py # 数据模型定义
│ ├── middlewares.py # 中间件
│ ├── pipelines.py # 数据处理管道
│ ├── settings.py # 项目设置
│ └── spiders/
│ ├── __init__.py
│ └── sina_news_crawler.py # 爬虫实现
├── create_database.sql # 数据库创建脚本
└── README.md # 项目说明
```## 数据库配置
1. 运行`create_database.sql`脚本创建数据库和表结构:```bashmysql -u root -p < create_database.sql```2. 修改`settings.py`中的数据库连接信息:```python# MySQL数据库配置MYSQL_HOST = 'localhost'MYSQL_USER = 'root'MYSQL_PASSWORD = 'your_password'MYSQL_DATABASE = 'sina_news_db'MYSQL_PORT = 3306```## 运行爬虫
1. 进入项目目录:```bashcd sina_news_spider```2. 运行爬虫:```bashscrapy crawl sina_news_crawler```## 数据说明
爬取的新闻数据包括以下字段:
- `title`: 新闻标题
- `url`: 新闻链接
- `content`: 新闻内容
- `publish_time`: 发布时间
- `source`: 新闻来源
- `author`: 作者
- `keywords`: 关键词爬虫文件
import scrapy
from sina_news_spider.items import SinaNewsItem
import re
from datetime import datetimeclass SinaNewsCrawlerSpider(scrapy.Spider):name = "sina_news_crawler"allowed_domains = ["news.sina.com.cn"]start_urls = ["https://news.sina.com.cn"]def parse(self, response):# 提取新闻分类链接 - 使用更通用的选择器category_links = response.css('a[href*="news.sina.com.cn/"]::attr(href)').extract()for link in category_links:# 只爬取国内、国际、财经、科技等主要新闻分类if re.search(r'news.sina.com.cn/[a-z]+/', link) or re.search(r'sina.com.cn/[a-z]+/', link):# 确保链接是完整的if not link.startswith('http'):link = 'https:' + link if link.startswith('//') else 'https://news.sina.com.cn' + linkyield scrapy.Request(url=link, callback=self.parse_category)def parse_category(self, response):# 提取新闻列表链接 - 使用更通用的选择器news_links = response.css('a[href*="news.sina.com.cn/"]::attr(href)').extract()# 也尝试提取class包含news的div中的链接news_links += response.css('div[class*="news"] a::attr(href)').extract()# 去重news_links = list(set(news_links))for link in news_links:# 过滤掉不是新闻详情页的链接if re.search(r'news.sina.com.cn/[a-z]+/\d{4}-\d{2}-\d{2}/', link) or re.search(r'sina.com.cn/[a-z]+/\d{4}-\d{2}-\d{2}/', link):# 确保链接是完整的if not link.startswith('http'):link = 'https:' + link if link.startswith('//') else 'https://news.sina.com.cn' + linkyield scrapy.Request(url=link, callback=self.parse_detail)# 提取下一页链接 - 使用更通用的选择器next_page = response.css('a[href*="page="]::attr(href)').extract_first()if not next_page:next_page = response.css('a:contains("下一页")::attr(href)').extract_first()if next_page:# 确保链接是完整的if not next_page.startswith('http'):next_page = 'https:' + next_page if next_page.startswith('//') else response.urljoin(next_page)yield scrapy.Request(url=next_page, callback=self.parse_category)def parse_detail(self, response):item = SinaNewsItem()# 提取标题 - 使用更通用的选择器item['title'] = response.css('h1::text').extract_first()if not item['title']:item['title'] = response.css('title::text').extract_first()# 提取链接item['url'] = response.url# 提取内容 - 使用更通用的选择器content_paragraphs = response.css('div.article p::text').extract()if not content_paragraphs:content_paragraphs = response.css('div.main-content p::text').extract()if not content_paragraphs:content_paragraphs = response.css('div.text p::text').extract()item['content'] = ''.join(content_paragraphs).strip()# 提取发布时间 - 使用更通用的选择器publish_time_text = response.css('span.date::text').extract_first()if not publish_time_text:publish_time_text = response.css('meta[name="publishdate"]::attr(content)').extract_first()if not publish_time_text:publish_time_text = response.css('time::text').extract_first()if publish_time_text:# 格式化为标准时间格式try:if '年' in publish_time_text and '月' in publish_time_text and '日' in publish_time_text:publish_time = datetime.strptime(publish_time_text, '%Y年%m月%d日 %H:%M')elif '-' in publish_time_text:publish_time = datetime.strptime(publish_time_text.split(' ')[0], '%Y-%m-%d')else:publish_time = datetime.strptime(publish_time_text, '%Y%m%d%H%M')item['publish_time'] = publish_time.strftime('%Y-%m-%d %H:%M:%S')except:item['publish_time'] = publish_time_textelse:item['publish_time'] = ''# 提取来源 - 使用更通用的选择器item['source'] = response.css('span.source::text').extract_first()if not item['source']:item['source'] = response.css('meta[name="source"]::attr(content)').extract_first()if not item['source']:item['source'] = '新浪新闻'# 提取作者 - 使用更通用的选择器item['author'] = response.css('span.byline::text').extract_first()if not item['author']:item['author'] = response.css('meta[name="author"]::attr(content)').extract_first()# 提取关键词keywords = response.css('meta[name="keywords"]::attr(content)').extract_first()item['keywords'] = keywords if keywords else ''# 只有当标题和内容都存在时才 yield itemif item['title'] and item['content']:yield item
items.py
import scrapyclass SinaNewsItem(scrapy.Item):# 新闻标题title = scrapy.Field()# 新闻链接url = scrapy.Field()# 新闻内容content = scrapy.Field()# 发布时间publish_time = scrapy.Field()# 来源source = scrapy.Field()# 作者author = scrapy.Field()# 关键词keywords = scrapy.Field()pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# 导入MySQL相关库
import pymysql
from itemadapter import ItemAdapterclass MySQLPipeline:def __init__(self, host, user, password, database, port):self.host = hostself.user = userself.password = passwordself.database = databaseself.port = portself.connection = Noneself.cursor = None@classmethoddef from_crawler(cls, crawler):# 从配置文件中获取数据库连接信息return cls(host=crawler.settings.get('MYSQL_HOST'),user=crawler.settings.get('MYSQL_USER'),password=crawler.settings.get('MYSQL_PASSWORD'),database=crawler.settings.get('MYSQL_DATABASE'),port=crawler.settings.get('MYSQL_PORT'))def open_spider(self, spider):# 连接数据库self.connection = pymysql.connect(host=self.host,user=self.user,password=self.password,database=self.database,port=self.port,charset='utf8mb4')self.cursor = self.connection.cursor()def close_spider(self, spider):# 关闭数据库连接self.cursor.close()self.connection.close()def process_item(self, item, spider):# 插入数据到数据库try:sql = """INSERT INTO sina_news (title, url, content, publish_time, source, author, keywords)VALUES (%s, %s, %s, %s, %s, %s, %s)"""values = (item.get('title'),item.get('url'),item.get('content'),item.get('publish_time'),item.get('source'),item.get('author'),item.get('keywords'))self.cursor.execute(sql, values)self.connection.commit()except Exception as e:spider.logger.error(f"数据库插入错误: {e}")self.connection.rollback()return itemclass SinaNewsSpiderPipeline:def process_item(self, item, spider):return item
settings.py
# MySQL数据库配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_DATABASE = 'sina_news_db'
MYSQL_PORT = 3306# 启用ITEM_PIPELINES
ITEM_PIPELINES = {'sina_news_spider.pipelines.MySQLPipeline': 300,
}
-- 创建数据库
CREATE DATABASE IF NOT EXISTS sina_news_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;-- 使用数据库
USE sina_news_db;-- 创建新闻表
CREATE TABLE IF NOT EXISTS sina_news (id INT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(255) NOT NULL,url VARCHAR(255) NOT NULL UNIQUE,content TEXT,publish_time DATETIME,source VARCHAR(100),author VARCHAR(100),keywords VARCHAR(255),created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;