“Why“比“How“更重要:层叠样式表CSS
在开始之前,我们先抛出一些问题:
CSS是在什么背景下出现的?
你知道我们常说的CSS3标准是按模块推出的吗?
为什么入门要从盒模型开始?
CSS是如何参与浏览器中渲染部分的?
一、CSS的历史
CSS目前一共迭代了CSS1.0、2.0两个版本,目前正在全面迈向3.0。
CSS 1.0
1991年2月W3C发布一个有关样式的标准CSS1.0。这个版本包含了font(字体)的相关属性、颜色与背景的相关属性、文字的相关属性、box的相关属性。
CSS 2.0
1998年5月,CSS2.0推出。推荐内容和表现效果分离的方式,开始使用样式表结构。
(将HTML和CSS分离,通过导入CSS文件到HTML文件,使用外联样式表)
CSS 3.0
CSS3.0标准并没有被W3C官方统一并推出。
2001年,W3C着手开始准备开发CSS第三版规范。但我们很难谈论CSS3.0标准。
CSS3.0的新特性是被构建为一系列(理论上)相互独立的模块(百度百科指出共计32个独立模块),而不是整体的单一的规范。
“模块化 CSS3 的基本原理是,每个模块都可以按照自己的速度工作,而且特别重要的(或流行的)模块可以按照 W3C 的进度前进,而不会受到其他模块的阻碍。”
二、对HTML元素分类标准
CSS依赖于元素,但并不是所有元素都是平等的。
HTML元素名称更多是语义上的区别,不同元素之间设置属性进行转换达到相同的效果。
浏览器默认对HTML元素添加默认的属性导致语义不同元素有不同的CSS效果(User Agent Stylesheet)
维度一:替换元素和非替换元素
替换元素(Replaced Element)
- 内容由外部资源定义
- 尺寸受内在属性约束
- 渲染时替换内容区域
<img src="image.jpg"> <!-- 图像资源 -->
<video controls></video> <!-- 视频资源 -->
<iframe src="..."></iframe> <!-- 嵌套文档 -->
<input type="image"> <!-- 图像按钮 -->
<embed type="..."> <!-- 插件内容 -->非替换元素(Nonreplaced Element)
- 内容直接包含在文档中
- 完全由CSS控制表现
- 支持伪元素修饰
<div>文本内容</div> <!-- 块级容器 -->
<span>行内文本</span> <!-- 行内文本 -->
<p>段落元素</p> <!-- 文本段落 -->
<button>按钮</button> <!-- 表单按钮 -->
<ul><li>列表项</li></ul> <!-- 列表结构 -->维度二:块级元素和行内元素
块级元素:
- 默认占满整行
- 可以设置宽高/边距
- 强制前后换行
/* 标准块元素 */
div, p, h1-h6, section, main/* 列表相关 */
ul, ol, li, dl, dd/* 表格结构 */
table, tr /* (特例) */行内元素:
- 默认跟随文本流
- 不强制换行
- 尺寸由内容决定
/* 文本级元素 */
span, strong, em, a, code/* 表单元素 */
input, textarea, label/* 替换元素 */
img, video /* (同时也是替换元素) */三、CSS学习重点清单
- 与模块相关:重点「外联样式」(了解行内样式、内部样式),参考文章:在HTML中CSS三种使用方式_html 内部css-CSDN博客
- 盒子模型(所有内容都被渲染成一个矩形框,这个矩形框就是盒子模型),了解怪异盒模型
- 选择器的优先级(属性的应用规则)
- 字体font
- 背景background
- 等等等等
四、浏览器渲染主线程如何解析CSS的?
官方定义:在 CSS 中,视觉格式化模型(visual formatting model)描述了用户代理如何获取文档树,并将其处理后显示在视觉媒体上。
浏览器渲染主线程如何解析CSS的过程就是视觉格式化模型。
1. 解析HTML,生产DOM和CSSOM
在渲染主线程将HTML解析为DOM和CSSOM树。
面对CSS的多种样式,如行内、内部样式、外部样式以及浏览器默认的User Agent StyleSheet,共计四种类型。
每一个这类关键词,都会在CSSOM树根节点下添加一个孩子节点。
可以在浏览器控制台打印document.styleSheets查看这颗树的节点。
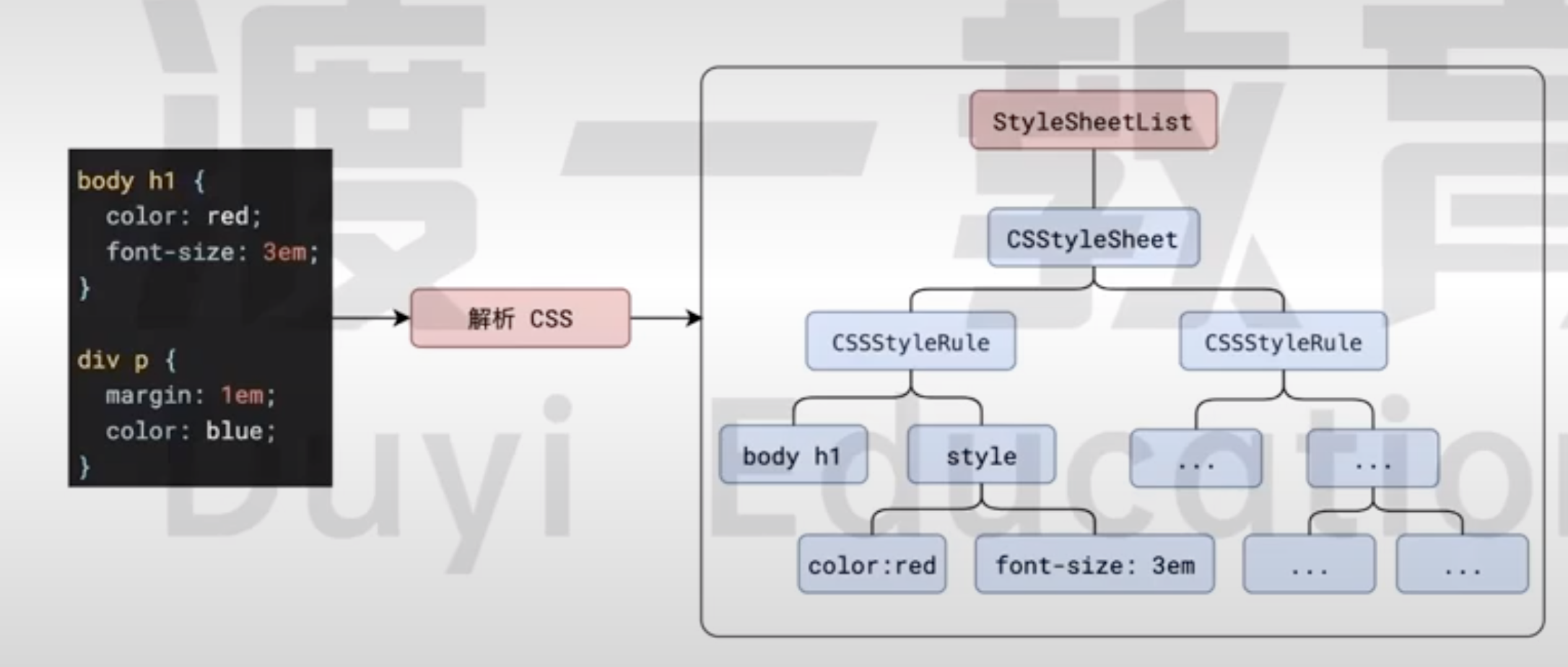
图片来源:渡一教育
2. 样式计算
在浏览器解析HTML后生存DOM和CSSOM树之后下一个阶段是计算样式,生成Computed Style:
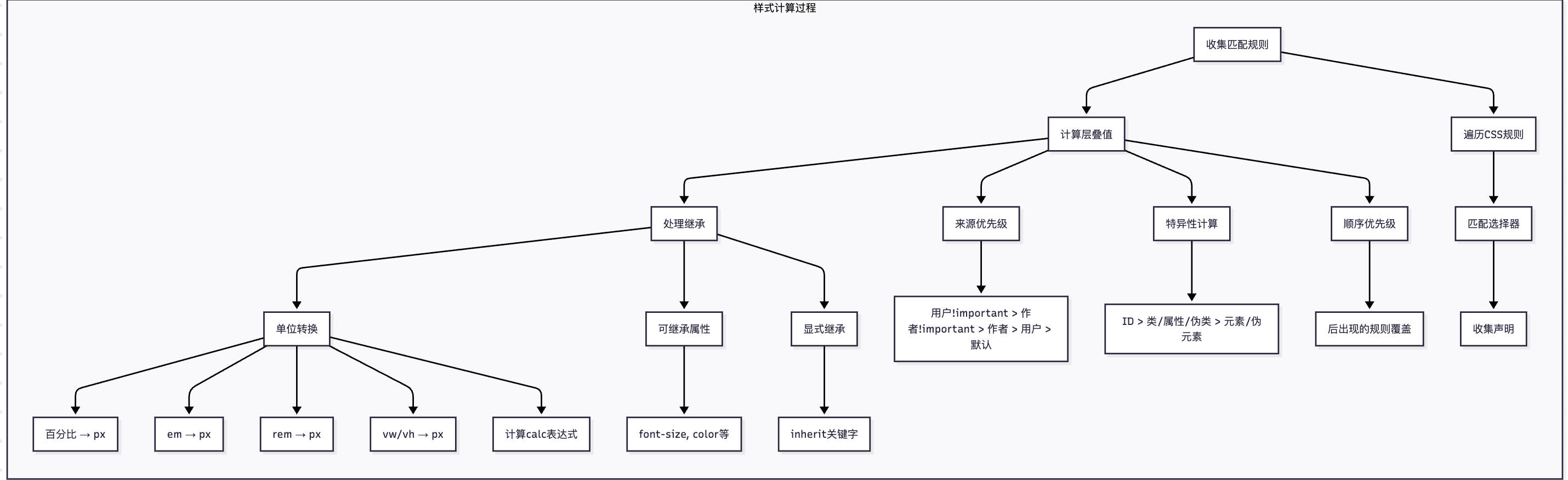
1. 样式规则匹配(Style Rule Matching)
浏览器会遍历DOM树中的每个节点,并为每个节点匹配所有适用的CSS规则(来自CSSOM)。这包括:
- 内联样式(
style属性) - 内部样式表(
<style>标签) - 外部样式表(
<link>引入的CSS文件) - 用户代理样式(浏览器默认样式)
匹配规则基于CSS选择器:
(明白为什么选择器很重要了吧?)
- 浏览器会从CSS规则中选择与当前DOM节点匹配的选择器。
- 匹配过程通常是从右向左进行(例如,对于选择器
.box p,先找到所有p元素,再检查其祖先是否有.box)。
2. 层叠(Cascading)
当多个规则匹配同一个元素时,浏览器需要解决冲突,确定哪个规则的样式属性应该生效。这遵循CSS层叠规则:
- 来源重要性:
!important> 用户代理样式 < 用户样式 < 作者样式(开发者写的样式)< 作者!important< 用户!important - 特异性(Specificity):计算选择器的权重,通常按以下顺序:
- 内联样式(权重最高)
- ID选择器
- 类选择器、属性选择器、伪类
- 元素选择器、伪元素(权重最低)
- 书写顺序:后出现的规则覆盖前面的规则(在相同来源和特异性的情况下)。
3. 继承(Inheritance)
某些CSS属性如果没有显式指定,会从父元素继承(如font-size, color等)。浏览器会检查父元素的Computed Style,并将可继承的属性传递给子元素。
4. 默认值(Default Values)
如果没有任何规则指定某个属性,则使用该属性的默认值(例如,width默认为auto,font-size默认为medium)。
5. 计算值(Computed Values)
在计算过程中,浏览器会将所有相对单位转换为绝对单位:
em→pxrem→px%→ 根据父元素的对应属性计算vw/vh→px(基于视口尺寸)- 颜色值(如
rgb(),hsl())转换为rgba() - 简化
calc()表达式
注意:此时计算的是Computed Value,而不是最终用于渲染的Used Value(布局后确定的值)。例如:
width: 50%→ 计算值仍然是50%(因为还不知道父元素宽度)- 在布局阶段之后,才会计算出实际的像素值(Used Value)。
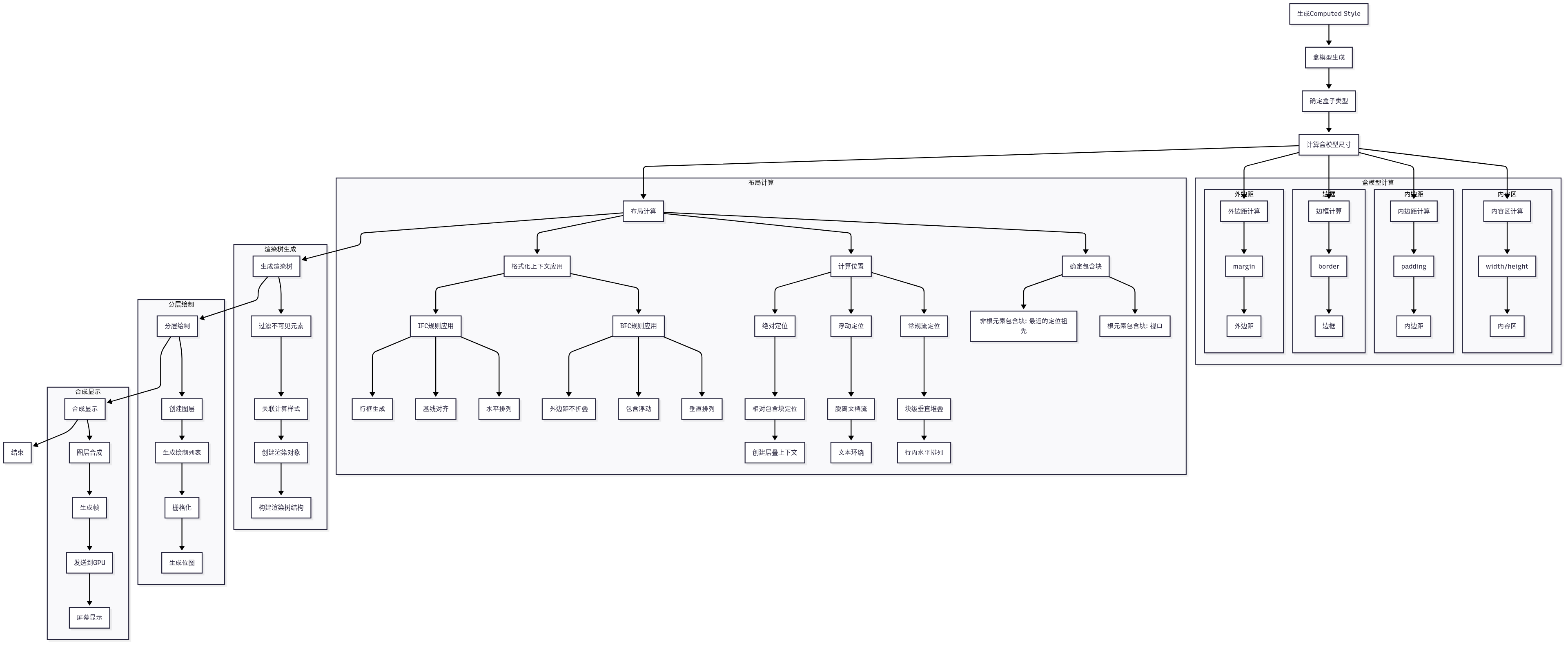
3.盒模型生成
. 确定盒子类型(基于display属性)
浏览器根据元素的display属性确定盒子类型:
-
块级盒子:
- 生成块级格式化上下文(BFC)
- 垂直排列,占据整行宽度
- 可设置宽高、内外边距
- 示例元素:
<div>,<p>,<h1>-<h6>
-
行内盒子:
- 生成行内格式化上下文(IFC)
- 水平排列,不换行
- 尺寸由内容决定
- 示例元素:
<span>,<a>,<strong>
-
行内块盒子:
- 混合特性:外部行内,内部块级
- 可设置宽高,水平排列
- 生成BFC
- 示例元素:
<img>,<button>,<input>
-
特殊盒子:
- 弹性盒子:生成弹性格式化上下文(FFC)
- 网格盒子:生成网格格式化上下文(GFC)
- 表格盒子:生成特殊表格布局
- 匿名盒子:包裹未包含在元素中的文本内容

4.计算盒模型->布局计算->渲染树生成->分层绘制->合成显示
计算盒模型生成盒子结构
每种盒子类型生成对应的矩形结构。浏览器根据计算样式计算盒模型的四个区域,context-padding-border-margin。
特殊处理:替换元素、表格、弹性/网格布局
生成最终盒模型:综合所有计算结果