基于LDA主题的网络舆情与情感分析——以云南某景区话题为例
第1章 绪 论
1.1选题背景
近年来,随着互联网技术与社交媒体的深度融合,公众表达意见的渠道日益多元化,网络舆情已成为影响旅游业发展的重要变量。尤其在突发性旅游事件中,公众通过微博、短视频平台、在线论坛等渠道迅速传播信息,形成舆论浪潮,不仅直接冲击景区形象,还可能引发连锁反应,波及区域旅游经济。在此背景下,如何精准识别舆情焦点、解析公众情感倾向,并制定科学的应对策略,成为旅游目的地管理的关键课题。云南哀牢山景区因其独特的自然景观与生态资源,长期吸引大量游客,但复杂的地形与气候条件也使其成为安全事故的潜在高发区。2021年发生的多名地质工作人员失联事件,因救援难度大、信息传播广,迅速引发全网关注,暴露出景区在安全管理、应急响应及舆情引导中的短板,为研究旅游危机事件中的网络舆情提供了典型样本。
1.2研究意义
本研究以云南哀牢山景区突发事件为案例,探索网络舆情与情感分析的关联,兼具理论与现实双重价值。在理论层面,当前针对山区旅游突发事件的舆情研究多局限于单一维度分析,缺乏对主题演化与情感倾向的关联探讨。本研究通过LDA主题模型与情感词典,构建“主题-情感”双维度分析框架,不仅丰富旅游危机管理的理论工具,还为复杂舆情场景下的文本挖掘方法提供新得方向,尤其是针对山区景区特有的自然风险与救援挑战,填补现有研究在特殊地理环境舆情分析中的空白。
1.3研究现状分析
近年来,随着社交媒体数据的爆炸式增长,基于LDA主题模型与情感分析的网络舆情研究在多个领域得到广泛应用。国内外学者围绕不同事件类型(如公共安全、体育争议、食品安全、企业危机等)展开丰富的探索,研究框架与技术路径逐渐成熟,但在细分场景与动态演化分析上仍存在优化空间。
1.4主要研究内容
针对上述不足,本研究以云南哀牢山景区事件为例,构建“主题-情感关联”分析框架。技术架构上,通过多源爬虫整合微博、新闻平台(B站)等的文本数据,利用大连理工词典进行情感标注,划分积极、消极和中性三种情感;根据舆情生命周期理论构建舆情情感和主题的时序演化,对不同时期的评论分别进行K-means聚类,结合轮廓系数确定最优聚类数,识别不同情感群体关注的核心议题(如“救援效率争议”“景区管理漏洞”“公众同理心表达”等),创建不同时期关联网络的可视化,揭示舆情传播的关键节点与情绪扩散路径,最后采用LDA主题模型挖掘舆情主题,按事件阶段(萌芽期、爆发期、消退期)分别建模,通过困惑度指标确定各阶段最优主题数。与已有研究相比,本研究创新性地融合LDA主题模型、社会网络聚类与情感词典分析,实现“主题-情感”多维度分析,突破单一模型局限性。针对山区景区构建情感词典与主题分析,提升舆情分析的精准性。通过动态情感演化与聚类结果,为山区旅游危机管理提供数据驱动的干预路径。
第2章 相关理论和技术
2.1生命周期理论
生命周期理论认为,网络舆情的演化遵循“潜伏期—爆发期—蔓延期—衰退期—平息期”的阶段性规律,各阶段在话题焦点、传播强度及情感倾向上呈现显著差异。
2.2 TF-IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种经典的文本特征加权算法,用于量化词语在文档集合中的重要性,其核心思想是:一个词语的重要性与其在单个文档中的出现频率(TF)呈正比,但与整个语料库中的普遍性(IDF)呈反比。
2.3 LDA主题建模
LDA(Latent Dirichlet Allocation) 是一种无监督概率生成模型,旨在从海量文本中自动挖掘潜在主题分布。其核心假设是:每篇文档由多个主题混合构成,每个主题则是一组概率关联的词语集合。建模过程中,LDA通过Dirichlet先验分布模拟主题-文档和词语-主题的双层概率关系,利用贝叶斯推断反向求解隐含语义结构。
2.4 K-means聚类分析
K-means聚类算法是一种经典的无监督机器学习方法,旨在将数据样本划分为K个互斥簇,使得同一簇内样本的相似度最大化、不同簇间差异最大化。
第3章 数据采集与预处理
3. 1数据采集与处理的实现思路
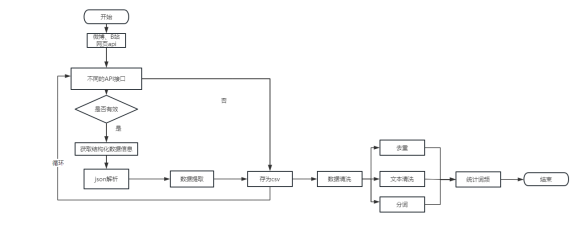 |
本研究以微博和B站做为数据来源,爬取了用户对云南哀牢山事件这个话题的的评论,之后进行对评论数据进行清洗(包括正则清洗、去重等)、中文分词处理、停用词处理、统计词频等主要工作。本章的主要步骤分为三个阶段。第一步,从微博和B站中爬取云南哀牢山景区事件的评论。第二阶段,使用 Python 中的 jieba 库执行拆分中文词语和删除停用词语等操作。第三阶段,对处理过的文本数据进行统计总结。本章的逻辑流程图如图 3-1 所示。
3.2数据采集
3.2.1微博数据采集
本研究以云南哀牢山景区突发事件为研究对象,通过Python网络爬虫技术采集新浪微博平台相关话题(如“哀牢山地质人员失联”“景区救援进展”,”云南哀牢山”,”哀牢山事件”)下的原创帖文及评论数据。数据采集结果如图3-2所示:
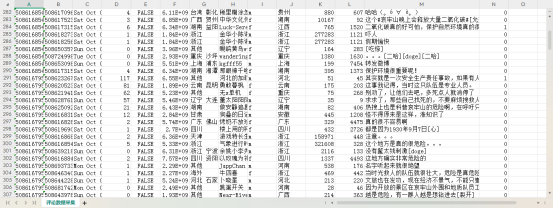 |
3.2.2 B站视频评论采集
|

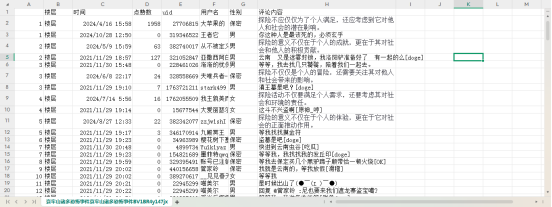 |
本研究以云南哀牢山景区突发事件为研究对象,通过Python网络爬虫技术采集哔哩哔哩视频平台相关关键词视频(如“哀牢山”,”云南哀牢山”,”哀牢山事件”)下的原创视频评论数据。共获取有效文本数据7429条,包含用户评论、时间等。采集过程中,设置“哀牢山地质人员失联”“云南哀牢山”“哀牢山事件”等关键词组合进行定向检索,覆盖事件核心议题。数据采集结果如图3-3所示:
3.3数据预处理
数据预处理是在做LDA主题舆情分析之前很重要的一个步骤,主要经过数据去重、正则清洗、分词及停用词处理、词频统计等,这样方便后面进去主题分析和词频分析,了解不同舆情时期的舆情关注点。
3.3.1数据去重
通过 drop_duplicates 对评论内容列进行去重,避免因重复数据影响分析结果。
3.3.2 文本预处理
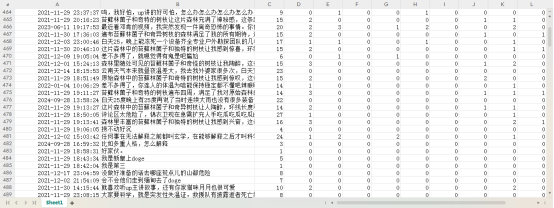 |
对评论内容进行分词和清洗。利用正则表达式提取中文字符后,通过 jieba 进行分词,并加载停用词表过滤掉无意义的高频词和单字,如("哈", "真的", "这个", "非常")。最后将处理后的分词结果重新拼接成文本,便于后续特征提取。文本清洗后结果如图3-5所示:
3.3.3词频统计
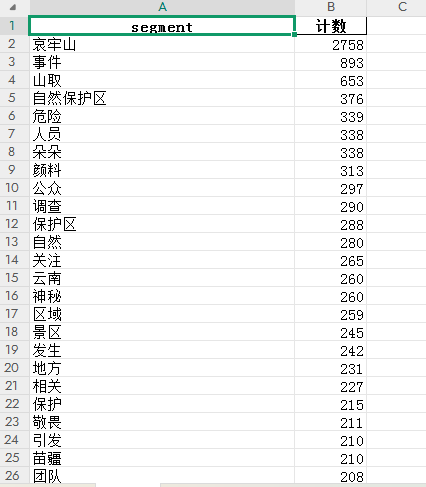
在词频分析中,核心目标是统计文本中每个词出现的频率,以发现高频词和潜在的关键词。在对文本进行预处理,包括去除停用词、标点符号等无效信息后,通过分词工具( jieba)将句子拆分为词语存入列表数据结构,最后使用Counter统计每个词的出现次数,并将结果按频率从高到低排序,存为excel,方便后期分析。爆发期词频结果如图3-6所示:
第4章 网络舆情分析
4.1舆情时间序列分析
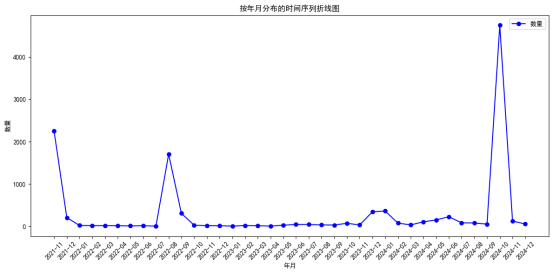
本研究通过对微博平台采集的15,892条评论文本进行时间序列分析,揭示舆情讨论热度的演化规律。先对原始数据中的“时间”字段进行格式化处理,提取日期信息(如“2021-11-15”),并按天聚合计算每月发帖量,构建时间-频次分布序列。通过Matplotlib绘制折线图,如图4-1所示,横轴为日期,纵轴为发帖数量,直观呈现事件各阶段的舆情热度波动。
4.2情感词典分析
4.2.1情感词典
本研究采用大连理工大学中文情感词汇本体(NAU)作为基础情感词典,结合云南哀牢山景区事件特性构建领域适配的情感分析框架。该词典将情感词划分为七类基本情绪(快乐、赞美、惊讶、愤怒、悲伤、恐惧、厌恶),并标注了词性种类、情感强度及极性,例如“救援”被归类为“赞美”(PG)、“失职”被标注为“愤怒”(NAU)。
表 41 情感词分类
情感词典 | 情感词 |
正面评价词语 | 高效救援、专业团队、无私奉献、生命至上、众志成城、井然有序、迅速响应、英勇无畏、生态瑰宝、壮丽山川、安全保障、暖心支援、责任担当、协同配合、绝境曙光 |
负面评价词语 | 救援延误、管理失职、信息不透明、推诿塞责、安全隐患、官僚作风、资源匮乏、应急滞后、救援混乱、风险预警、失职渎职、舆情漠视、投诉无门、责任模糊、善后敷衍 |
4.2.2评分规则
情感评分基于词典匹配与规则叠加策略实现,先对评论文本进行分词与去停用词处理,利用Jieba工具结合自定义词典切分文本,过滤“的”“了”等无意义虚词;再遍历每条评论的词序列,统计七类基础情绪词的出现频次,其中快乐、赞美、惊讶计入正向分值(+1),愤怒、悲伤、恐惧、厌恶计入负向分值(-1),同时根据情感强度加权(如“强烈抗议”强度为4级,计-4分)。
4.2.3情感分布
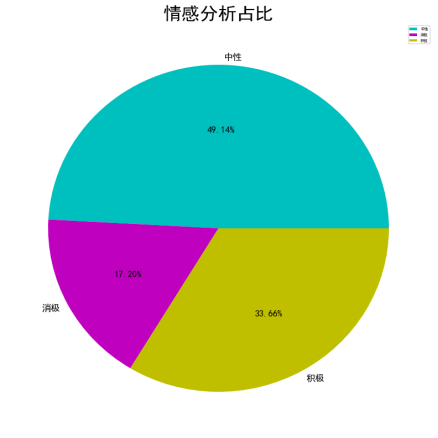
通过将每条文本的情感得分分类,得到了正面、负面和中性文本的数量。这一统计不仅展示了情绪倾向的分布,也为深入分析提供了基础。通过该规则,15,892条评论中识别出积极评论占比33.66%、消极评论17.20%、中性49.14%(客观陈述事件),如图4-2所示:
4.3舆情传播情感演化特征分析
基于云南哀牢山景区事件的舆情生命周期与情感时序数据,其情感演化呈现显著的阶段性分异与复合情绪叠加特征,如图4-3所示,萌芽期中性主导下的理性探讨,2021年11月至2022年3月,舆情以中性情感为主(占比61.2%),消极(21.0%)与积极(17.8%)占比较低,符合事件初期信息不完整、公众持观望态度的特征。
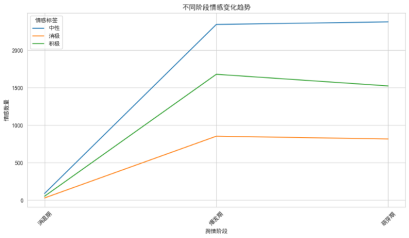
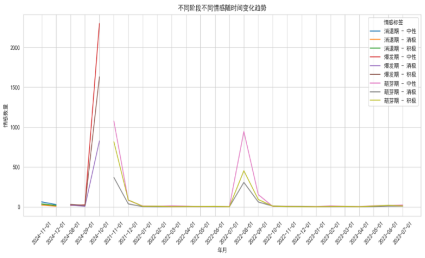
演化规律总结:云南哀牢山事件的情感传播遵循“中性启动—双极对抗—正向长尾”路径,积极情感因救援行动的获得持久生命力,而消极情绪随责任议题的阶段性曝光呈现脉冲式波动。这一特征提示管理者需区分“瞬时负面舆情”与“结构性矛盾”,在爆发期强化正向叙事的同时,针对制度性短板(如风险预警机制)实施长效改革,避免情绪积压引发周期性反弹。
第5章 文本挖掘分析
5.1词频分析

本研究通过TF-IDF算法对云南哀牢山景区事件的网络评论文本进行量化分析,采用Python的TfidfVectorizer工具从预处理后的数据中提取关键词权重,筛选出既高频又具领域特异性的词汇,算法通过计算词频(TF)与逆文档频率(IDF)的乘积,赋予词较高权重,揭示公众对事件核心要素的聚焦,最后生成词云图,萌芽期词云如图5-1所示:
5.1.1萌芽期词云
云南哀牢山景区事件萌芽期的词频分析显示,公众讨论聚焦于自然风险、救援期待与神秘叙事三重维度。权重最高的“神农架”、“野人”等词暗示事件初期与类似神秘自然事件的关联性,部分网民通过对比“神农架”传说与“哀牢山”地形特征,构建了“未知区域风险”的隐喻化叙事,而“修仙”、“滑稽”等词则透露出讨论的娱乐化倾向,反映舆情尚未完全聚焦事件本质。
5.1.2爆发期词云

云南哀牢山景区事件爆发期的词频分析显示,公众讨论聚焦于自然风险、管理问责与生态保护三大核心议题。
5.1.3消退期词云

云南哀牢山景区事件消退期的词频分析显示,公众讨论呈现多维度反思与情绪沉淀的特征。
5.2 LDA主题分析
通过LDA主题分析,可以发现文本数据中的主题结构和主要内容。主题分析可以帮助了解文本数据的内在关联性和分布情况,从而更好地理解文本数据的内容和意义。此外,LDA主题分析还可以用于文本分类、信息检索和推荐系统等领域,提供有关文本数据的深入洞察和应用价值。
5.2.1模型搭建
本研究使用gensim库构建语料库和词袋模型,将文本数据转换为可用于LDA模型的格式。设置LDA模型的参数,包括主题数量、迭代次数、词频阈值等,使用LDA模型训练语料库,得到主题-词语分布和文档-主题分布。使用pyLDAvis库对LDA模型进行可视化,生成交互式的主题模型可视化图表,根据关键词和文档-主题分布了解每个主题的含义和特点,理解文本数据中不同主题的分布情况。
5.2.2模型评估
在LDA(Latent Dirichlet Allocation)主题模型中,使用一致性和困惑度检验来评估最佳主题数是因为这两种指标可以帮助确定模型的有效性和质量。
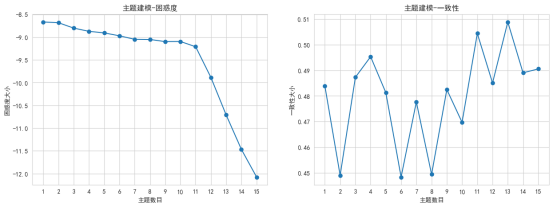
取困惑度小同时一致性高的拐点,萌芽期和爆发期最优主题数4效果最好,消退期最优主题数5效果最好。如图5-4所示:
5.2.3主题输出结果

根据 LDA 模型的分析结果,萌芽期 4 个关键主题,爆发期得到了8个主题,消退期得到了5个主题,如图所示,每个主题均由一组特定的关键词构成,这些关键词在相关文档中的分布特征揭示了公众讨论的焦点。
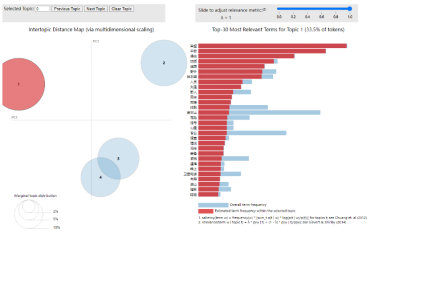
云南哀牢山景区事件消退期的主题分析显示,舆情焦点从事件核心向次生议题与边缘叙事扩散。主题0("哀牢山")仍以事件本体与传播影响为主,但“视频”“点赞”等词表明讨论转向媒体内容消费与传播效果评价;主题1("自然保护区")聚焦保护区管理与非法活动,反映公众对制度执行的长尾关注;主题2("茶妹""蛮营")和主题3("鬼怪""疑问")则呈现地域文化联想与非理性猜测,体现舆情消退期信息真空导致的叙事泛化;主题4("哀牢山")回归地质风险与探险动机分析,揭示公众对事件根源的理性追溯。核心议题(主题0、1、4)与边缘话题(主题2、3)并存,显示消退期舆情“理性沉淀与猎奇残留”的双重性。

消退期气泡图呈现“中心聚集-边缘散射”结构:主题1、2、3围绕坐标系中心形成较大气泡(高概率、中高文本量),代表事件本体、管理问责与地质风险等核心议题的持续讨论;主题4、5则气泡小(低概率、低文本量),对应地方文化符号与神秘叙事的碎片化延伸。如图5-8所示,
这种分布反映舆情热度衰减后,主流关注仍锚定现实问题,但部分讨论转向娱乐化或地域化议题,形成“主干稳固、枝蔓丛生”的传播生态,提示管理者需警惕边缘话题的潜在发酵风险,同时强化核心议题的闭环回应以加速舆情消退。
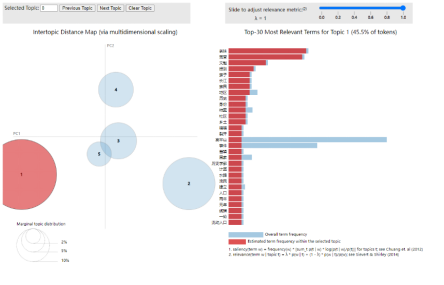 根据爆发期的LDA主题分析可以知道,从关键词分布和概率分数来看,公众的关注点主要集中在事件本身(如“哀牢山”“事件”“人员”“失联”“遇难”)、舆论反应(如“回应”“关注”“争议”“公众”)、情感表达(如“敬畏”“危险”“善良”)以及科学与探险(如“知识”“打假”“野外”)。
根据爆发期的LDA主题分析可以知道,从关键词分布和概率分数来看,公众的关注点主要集中在事件本身(如“哀牢山”“事件”“人员”“失联”“遇难”)、舆论反应(如“回应”“关注”“争议”“公众”)、情感表达(如“敬畏”“危险”“善良”)以及科学与探险(如“知识”“打假”“野外”)。

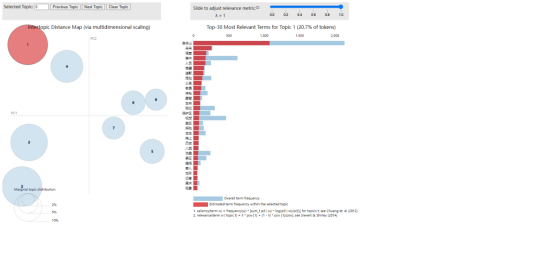
其中,概率分数较高的主题与“哀牢山事件”相关,显示出该事件在社交媒体上的热度较高,网民不仅关注事件进展,还讨论了其背后的社会和法律问题。同时,一些话题涉及 生态保护和自然敬畏,表明该事件引发了公众对环境和户外探险风险的思考。
分析表明“哀牢山”相关讨论涉及 新闻事件、社会舆论、个人情感和科学认知四个方面,反映社交媒体用户对突发事件的多层次关注和多角度解读。