TrackVLA——开放世界下的四足具身视觉跟踪EVT(智能跟随):集目标识别与轨迹规划为一体的VLA,不怕高动态与遮挡
前言
我们在不止一个项目中遇到过这样的需求:“ 开放空间跟随导航:能够对移动跟随目标进行路径导航,并保持一定的跟随距离;支持自定义跟随距离;输出跟随导航路径 ”
故关注到了本文要介绍的TrackVLA
- 一方面,个人觉得TrackVLA还是有落地价值的,不像有的论文 发完就没然后了——有的论文就是为了发而发 或者为了毕业而发 即便在GitHub上放了点代码(开源不彻底) 也没人维护issue 更不用说该工作的迭代 改进 延续了。毕竟作者们可能已经毕业 从事别的方向,这点 其实挺可惜的
那怎么做到延续性呢,一者,在公司里进一步做在校时的方向『也欢迎来我司七月在线做具身』,二者,开源彻底 让更多同行follow自己的工作,进一步改进以发扬光大 - 二方面,负责任的讲,关注到不代表就能在我们的需求场景中落地好,只是关注顺带解读下,至于能否落地好,得看业内同行的实践,或者我们到时实践落地时 是否会用到该模型
顺带,感慨个事,我司今25年前7个月 客户不少
- 但有一客户则不巧,他们与我们进行一两月的技术交流、线上会议,最后来办公室现场考察,在他们的反复论证中,我们证明了自己的技术实力
- so,我司成为了500万标的候选,可前期大半年 都得垫资采购硬件,垫资人力研发成本
我如果今年拿了融资 还行,但今年还没拿融资,故只能找个有融资的挑大头总之,找我们作定开的集团客户源源不断,如有兴趣合作:共同为某个客户/订单研发的,欢迎私我——当然 九成的客户还是会按比例来付款的
PS,如想做、在做、曾做导航方向的,欢迎私我一两句简介,邀你进「七月具身:VLN为代表的人形导航交流群」
第一部分 TrackVLA
1.1 引言、相关工作
1.1.1 引言
如TrackVLA原论文所说,具身视觉跟踪(Embodied visual tracking,简称EVT) [1,2,3,4,5,6]要求智能体持续跟踪指定目标,这是具身人工智能(AI)[7]的一项基础能力,并在机器人领域中有着广泛需求[8,9]
该任务之所以极具挑战性,主要源于其对两项高度关联技能的依赖:
- 目标识别,即准确识别并区分目标的能力
- 轨迹规划,即确定实现高效跟踪的最优动作的能力。在严峻的遮挡和高度动态场景等复杂条件下,识别与规划之间的相互作用尤为考验系统性能
为了实现强健的具身视觉跟踪,现有方法[1,2,3,4,5,10]通常将识别与轨迹规划解耦,分别采用检测模型和规划模型来应对这一挑战。这些方法受益于视觉基础模型[11,12,13]和策略学习技术(如模仿学习[14]和强化学习[3,15])的快速进展
尽管早期已取得一定进展,但这些方法仅限于在相对开放区域内进行类别级别的跟踪。这主要是由于其松散耦合的设计导致识别模型与规划模型之间的误差积累——例如,错误的识别会导致错误的规划,反之亦然
为了实现目标识别与轨迹规划的协同作用,一个通用模型必须同时具备识别和跟踪能力
对此,来自1Peking University、2 GalBot、3 Beihang University、4 Beijing Normal University、5 Beijing Academy of Artificial Intelligence的研究者提出了TrackVLA,这是一种集成目标识别与轨迹规划于一体的视觉-语言-动作模型
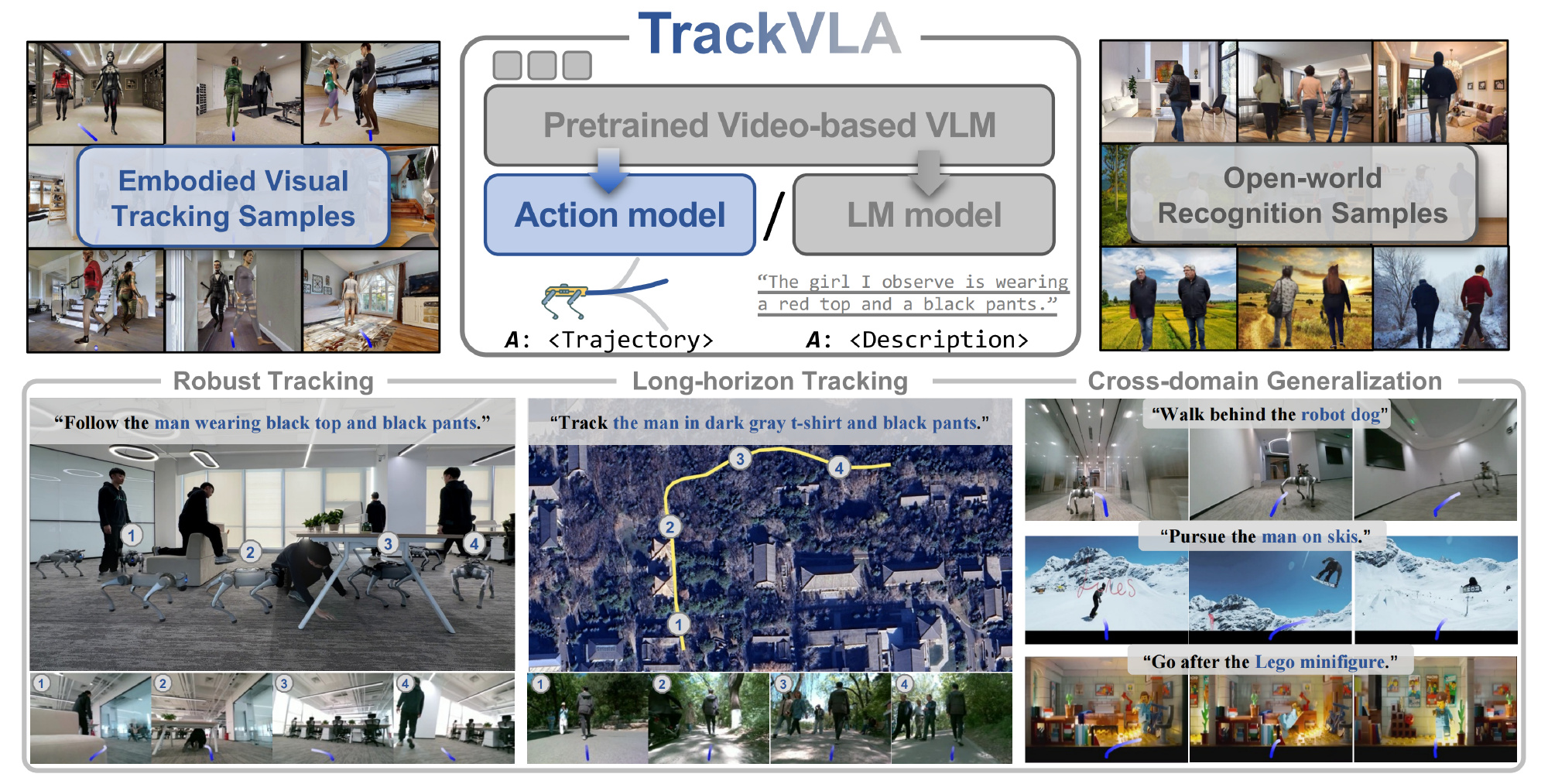
- 其对应的paper为:TrackVLA: Embodied Visual Tracking in the Wild
其作者包括:
Shaoan Wang1, 2*, Jiazhao Zhang1, 2*, Minghan Li2, Jiahang Liu2, Anqi Li1, 2,
Kui Wu3, Fangwei Zhong4, Junzhi Yu1, Zhizheng Zhang2, 5†, He Wang1, 2, 5† - 其项目地址为:pku-epic.github.io/TrackVLA-web
其GitHub地址为:github.com/wsakobe/TrackVLA
具体而言,这两个任务均采用相同的token编码和大语言模型(LLM)前向机制来预测下一个token,而解码过程则依赖于具体任务
- 在识别任务中,TrackVLA使用语言建模头进行文本响应解码;
在规划任务中,TrackVLA利用基于锚点的扩散头生成航路点轨迹
两个任务采用联合训练方式,从而优化TrackVLA,实现识别与规划的紧密耦合 - 为了使TrackVLA具备识别与规划能力,作者收集了85.5万条视频识别样本和85.5万条机器人跟踪样本
在识别方面,作者基于公开的ReID数据集[16]构建了一个人体识别数据集,并利用了开放世界的VQA数据集[17, 18, 19]
对于具身视觉跟踪数据,作者从自研的具身视觉跟踪基准(EVT-Bench)中收集样本,该基准包含100多个高保真类人虚拟体在模拟场景中随机移动
识别和跟踪样本均按照不同难度级别采集,以实现对TrackVLA的全面训练
1.1.2 相关工作:涉及具身视觉跟踪、具身导航、VLA
第一,对于具身视觉跟踪
该任务要求智能体基于视觉观测持续追踪动态目标,依赖于精准的目标识别和最优的轨迹规划。在实际应用中,跟随人类 [21,22,23] 是该领域研究最为广泛的场景
- 尽管许多最新研究 [9,15,24,25,26,27,28,29] 将感知与规划解耦为两个独立模块——通常通过引入视觉基础模型 [11] 提升感知能力,并利用强化学习进行规划——但由于检测与规划的分离,常常导致误差累积,且训练效率较低
为了解决这一问题,一些方法借助离线强化学习 [6,30]提高训练效率 - 然而,上述方法普遍不支持自然语言输入,这极大限制了其在实际人机交互场景中的应用。为克服这一局限,Uni-NaVid [14] 提出了视觉-语言-动作(VLA)模型,通过大规模模仿学习实现了基于仿真的人类跟随
然而,其依赖离散动作空间,限制了在复杂真实环境中的适应能力
相比之下,TrackVLA 将目标识别与轨迹规划整合至统一训练框架,实现了两者的协同优化,且具备鲁棒的感知能力和灵活的运动控制,并在实际应用中展现出卓越的具身视觉跟踪性能
第二,对于具身导航
具身导航[31,32,33,34,35,36]是具身人工智能领域的一个基础课题,要求智能体能够主动在环境中导航,以完成给定的自然语言指令
- 近年来,具身导航取得了显著进展,催生了多种子任务,包括视觉-语言导航[14,37,36]、目标导航[38,39,40,41]以及具身问答[42,43]等
然而,目前大多数具身导航任务都是为静态室内环境设计的,忽视了现实世界环境本质上的动态特性 - 在本研究中,作者聚焦于一个具有挑战性的具身导航任务:具身视觉跟踪(EVT),该任务要求智能体在高度动态且存在遮挡的环境中识别并持续跟踪移动目标
第三,对于视觉-语言-动作模型
鉴于视觉-语言模型(VLMs)[44,45,46,47]令人印象深刻的泛化能力,视觉-语言-动作(VLA)模型通过为预训练的VLMs扩展动作生成能力,正受到具身智能(embodied AI)社区的日益关注
- 近期,众多研究已探讨了VLA模型在操作[48,49,50,51,52,53,54]和导航[14,36,55]等任务中的应用,展示了其卓越的泛化能力。然而,大多数现有的VLA模型受限于推理效率,并且主要在低动态环境下进行评估
- 与以往的VLA模型相比,TrackVLA在高度动态环境中表现出更优异的性能,并在具身视觉跟踪这一具有挑战性的任务中展现出强大的推理能力
1.2 方法
- 具身视觉追踪任务的表述
作者将具身视觉追踪任务表述为:在每个时间步
给定一条自然语言指令(描述特定目标的外观),以及由一系列帧组成的第一人称RGB观测序列
智能体需要输出下一步动作,以便在未知环境中持续跟随所描述的目标
其中,为动作空间,包括智能体的线速度
和角速度
。当智能体能够始终与目标保持适当的跟随距离(1–3米)并面向目标时,任务即被视为成功
- TrackVLA 概述
如图2所示——输入一段视频和一条语言指令,TrackVLA输出机器人跟踪轨迹或识别问题的答案
TrackVLA 通过引入用于轨迹规划和目标识别的并行预测分支,扩展了基于视频的 VLM/VLA 方法 [56,36,14]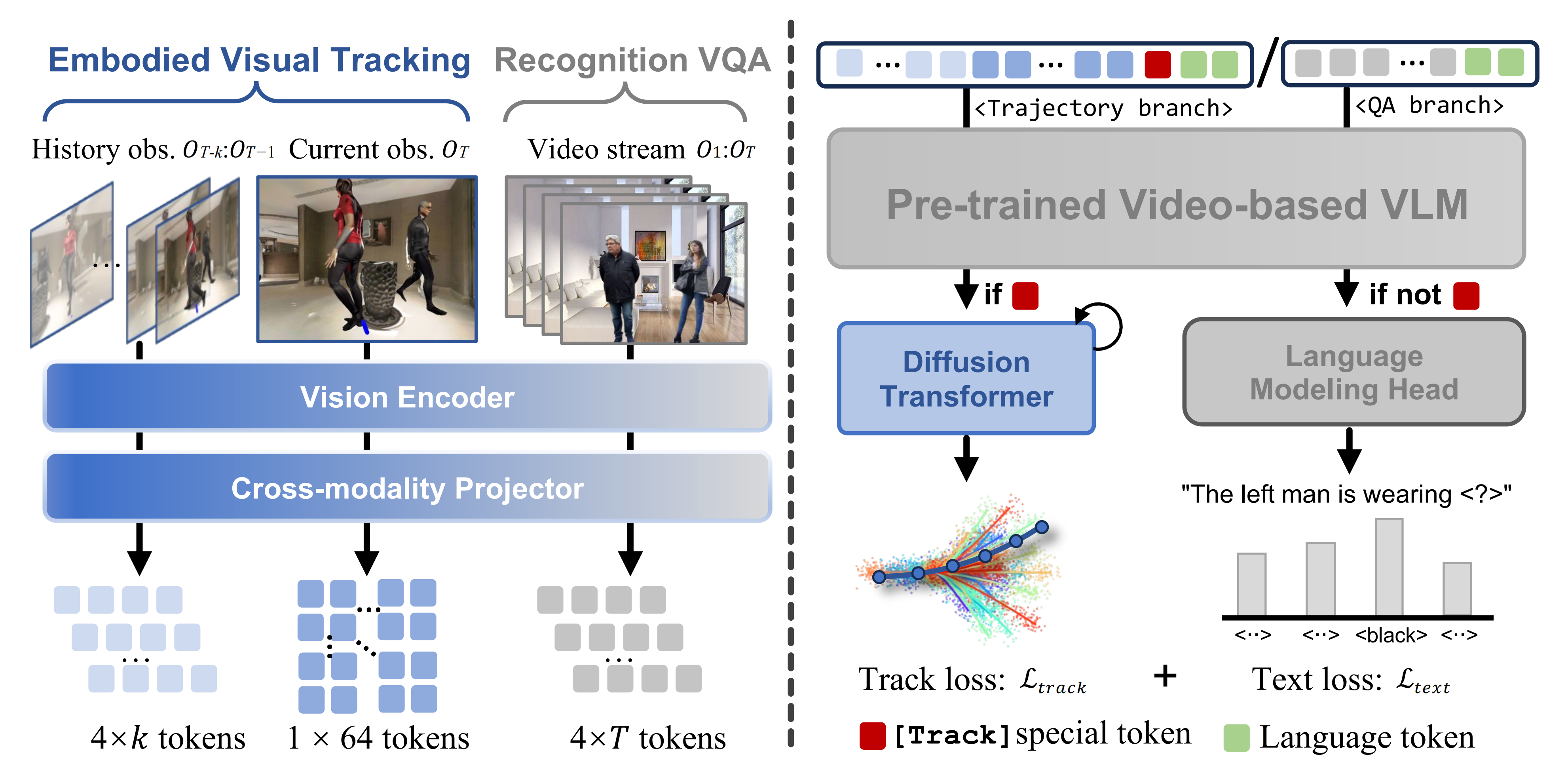
在轨迹规划方面,TrackVLA 组织在线捕获的视频数据,将历史和当前观测结合起来,并与跟踪指令及特殊跟踪token拼接
随后,一个Diffusion transformer将LLM「使用 Vicuna-7B [47] 实现」的输出token解码为路径点
1.2.1 TrackVLA 架构:涉及观测编码、LLM的前向传播、基于锚点的扩散动作模型
首先,对于观测编码
- 给定以自我为中心的 RGB 序列
,作者采用预训练的视觉编码器『EVA-CLIP [57]』提取视觉特征
其中 N 表示 patch 数量(设置为 256),C 表示嵌入维度 - 为了解决这一问题,作者对视觉特征应用网格池化策略[36,14](如图2左),以生成更紧凑的表示
具体来说,作者使用两种分辨率尺度
其中提供细粒度观测,而
提供粗粒度观测
为了在token 长度和性能之间实现最佳平衡
为确保跟踪过程中推理速度的一致性,作者采用滑动窗口机制,仅保留最新的帧(在他们的实现中设置为32)
- 对于具身视觉跟踪,作者将视觉token序列结构化为:
- 而对于针对视频问答(VQA)识别任务,作者将序列构建为:
最后,按照已有的视觉-语言模型(VLMs)[58,56],作者采用跨模态投影器——一个两层的MLP),将视觉特征投影到大型语言模型的潜在空间中:
其次,对于大型语言模型前向传播
作者将视觉token 与语言tokens
(为跟踪任务添加一个特殊的[Track] token)进行拼接,并将其输入到LLM中(见图2右),以获得预测的
随后,对预测的token根据不同任务进行不同处理具体取决于任务——由[Track] token的存在与否决定
- 对于识别任务,作者采用标准的语言建模头,将token自回归地解码为词汇表中的单词[59]
- 而对于跟踪任务,
作为动作头(diffusion transformer)模型的条件输入,为导航生成航点轨迹
最后,对于基于锚点的扩散动作模型
作者采用了一种基于锚点的扩散模型 [60],该模型通过从预定义锚点进行去噪来生成路径点「We em-ploy an anchor-based diffusion model [60] that per-forms denoising from predefined anchors to generate waypoints」
这些预定义锚点为模型提供了初步的粗略轨迹,从而显著减少了所需的去噪迭代次数,实现了相较于原始扩散策略 [33,61] 5倍的加速
如图3所示
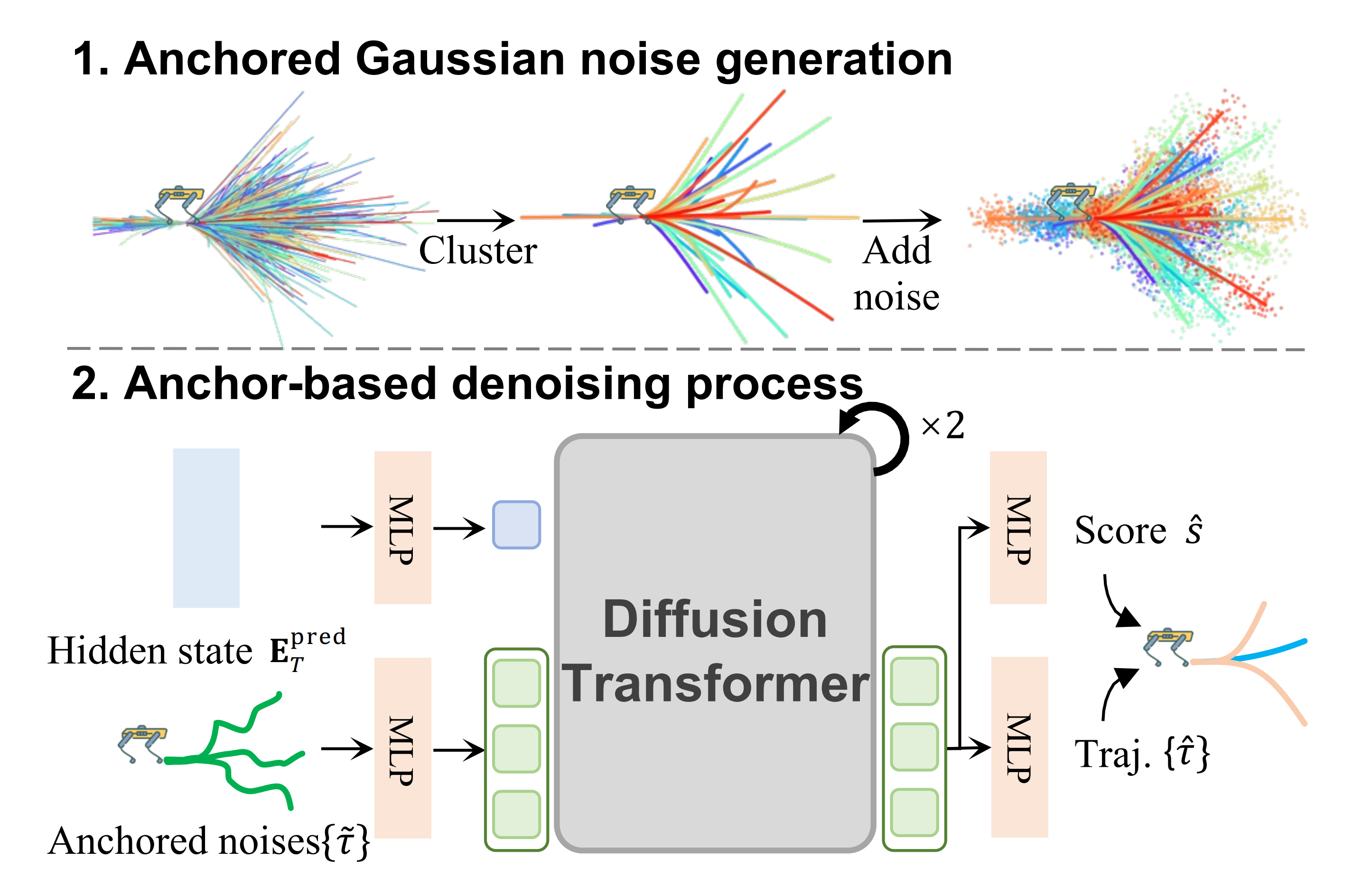
- 作者首先收集训练数据中的所有轨迹,并利用 K-means 聚类 [62] 得到一组轨迹锚点
,M表示锚点的数量
每个锚点表示一个机器人轨迹模式,其中
是每条轨迹中的航路点数量
- 然后作者对每个锚点添加高斯噪声以生成带噪锚点
作者的动作模型接收带噪锚点集合
以及条件
输出:去噪后的轨迹以及对应的轨迹分类分数
对于每个样本,作者将距离真实轨迹最近的锚点轨迹标记为正样本(snearest=1),其余的全部标记为负样本(selse=0)
然后,共同优化轨迹回归损失和得分预测损失,跟踪损失定义如下
其中,λ 是一个平衡参数。在这里,作者采用 Diffusion Transformer(DiT)[63]进行去噪,并且基于锚点的扩散策略仅需两个去噪步骤
对于一批输入序列,总体训练损失 L 定义为跟踪损失和文本预测损失
的加权组合,公式为
,其中
也是一个平衡参数。更多细节见附录
1.2.2 实现细节:训练细节、推理细节
- 训练细节
训练过程中,遵循视觉-语言建模(VLM)[58]的标准做法,仅训练一个 epoch。此外,整个训练过程中视觉编码器的参数保持冻结
与传统的视觉-语言模型(VLMs)类似,TrackVLA 采用了两阶段训练流程
- 在第一阶段,利用大量图像-文本描述数据 [58] 训练视觉编码器的投影器,以使视觉嵌入空间与大语言模型(LLM)的潜在空间对齐
- 在第二阶段,联合训练视觉投影器、大语言模型以及动作模型,使用多种训练数据的混合
在训练过程中,作者将动作模型的扩散调度最多截断为 1000 步中的 50 步,用于扩散轨迹锚点,这仅会引入极少量的噪声。TrackVLA 在配备有 24 块 NVIDIA H100 GPU 的集群服务器上进行了约 15 小时的训练,总计 360 GPU 小时
视觉编码器(EVA-CLIP [57])和大语言模型(Vicuna-7B [47])均使用各自的预训练权重进行初始化,并且在整个训练过程中视觉编码器保持冻结状态
- 按照标准的视觉语言模型(VLM)实践,仅对模型进行一个 epoch 的训练
- 训练过程中采用 2e-5 的学习率、总批量大小为 196,并使用余弦学习率调度和线性预热
- 优化器选择 AdamW。详细参数设置见表 5
- 推理细节
在推理阶段,使用特殊token [Track] 来指示当前任务
当存在 [Track] token时,LLM 仅执行一步自回归,并将输出的隐藏状态传递给动作模型以预测轨迹
作者采用 DDIM [64] 的更新规则进行去噪,仅需两步,并选择与最高分对应的轨迹
作为最终输出。否则,LLM 将进行完整的自回归解码,根据视觉观测回答给定的问题
更多细节见附录
在推理过程中,每一帧输入图像会被调整为224×224的尺寸,并输入到视觉编码器中。在获得视觉token后,模型会根据任务类型对标记进行组织
- 对于具身视觉跟踪任务,作者会在指令token前添加一个特殊的[Track]标记,并仅对大语言模型(LLM)执行一步自回归推理
随后,将LLM最终层的隐藏状态输出传递给动作模型
作者对轨迹锚点应用1000步扩散中的10步,并使用DDIM进行2步去噪,最终得到一组预测轨迹及其对应的分数向量
选择分数最高的锚点对应的轨迹作为最终输出- 对于视觉问答(VQA)任务,作者遵循LLM的标准自回归解码流程,语言建模头将预测的token detokenizes为文本答案。详细参数设置见表5
1.3 数据收集
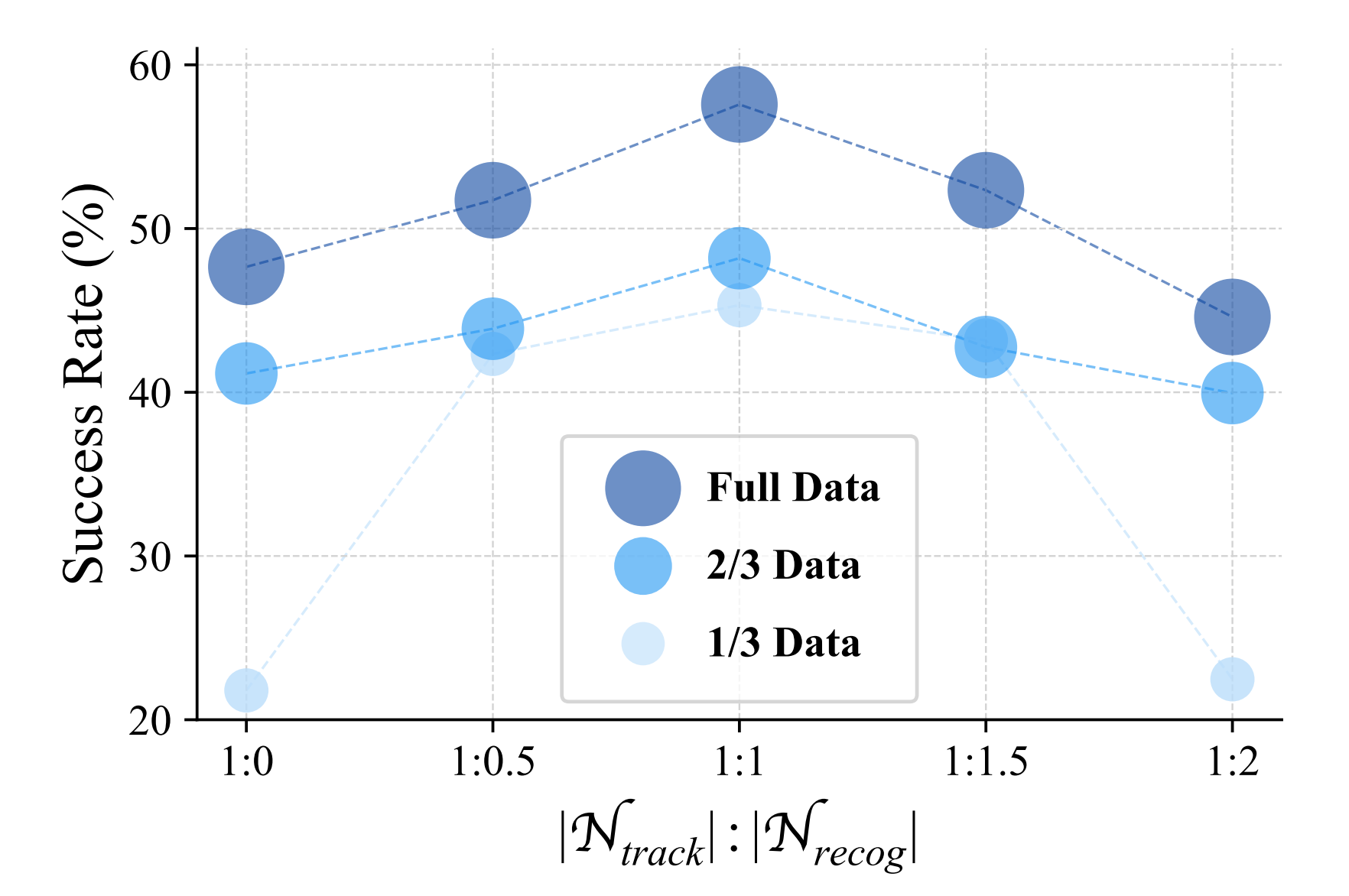
为了训练他们的并行分支TrackVLA,作者收集了体感视觉跟踪数据(85.5万条样本)和基于视频的问题回答数据(85.5万条样本),他们通过实验证明,1:1的比例能够带来最佳性能(见图6)
- 对于跟踪样本,他们开发了一个定制的虚拟化身跟随模拟器,并收集了涵盖各种挑战性场景的多样化数据集
- 对于识别样本,他们构建了一个视频问答数据集,要求智能体在复杂背景和干扰物中描述或区分目标对象
1.3.1 具身视觉跟踪数据
首先,对于具身视觉跟踪模拟器
作者基于 Habitat 3.0 [9] 构建了具身视觉跟踪模拟器,该平台提供了现成的碰撞检测和渲染仿真引擎。作者的主要改进包括两个方面:
- 拟人化虚拟人生成
他们实现了一套全自动化流程,用于生成和标注多样化的拟人化虚拟人(见图4 (A))
具体而言,他们采用 SMPL-X 人体模型,并通过随机形体和随机采样的 UV 纹理贴图(ATLAS 数据集 [65])初始化虚拟人
随后,利用视觉-语言模型 Qwen-VL2.5 [66] 获取虚拟人的对应文本描述 - 自然人类行为
他们为每个虚拟人分配一系列需要依次到达的目标,并设定其行走状态可切换。行走速度从自然人类步行速度区间 [1.0 m/s - 1.5 m/s][67] 中随机采样
此外,采用 ORCA 算法 [68]实现动态避障与响应式交互,从而使行为更加自然。更多细节请参见附录
其次,对于具身视觉跟踪基准
基于他们的模拟器,他们构建了具身视觉跟踪基准EVT-Bench,以全面评估具身视觉跟踪能力
- 作者生成了100个多样化的人形化身及其对应描述,并利用了来自HM3D [69]和MP3D [70]的804个场景环境
- 总共生成了25,986个实验过程,并随后划分为训练集和测试集,确保化身与场景在两个子集中无重叠
训练集包含703个场景下的21,771个实验过程,测试集则包含101个未见过场景下的4,215个实验过程
为全面评估算法在不同场景下的性能,EVT-Bench被划分为三个难度递增的子任务类别。每个子任务包含7,257个训练实验过程和1,405个测试实验过程。作者在下方列出了每个类别的跟踪任务
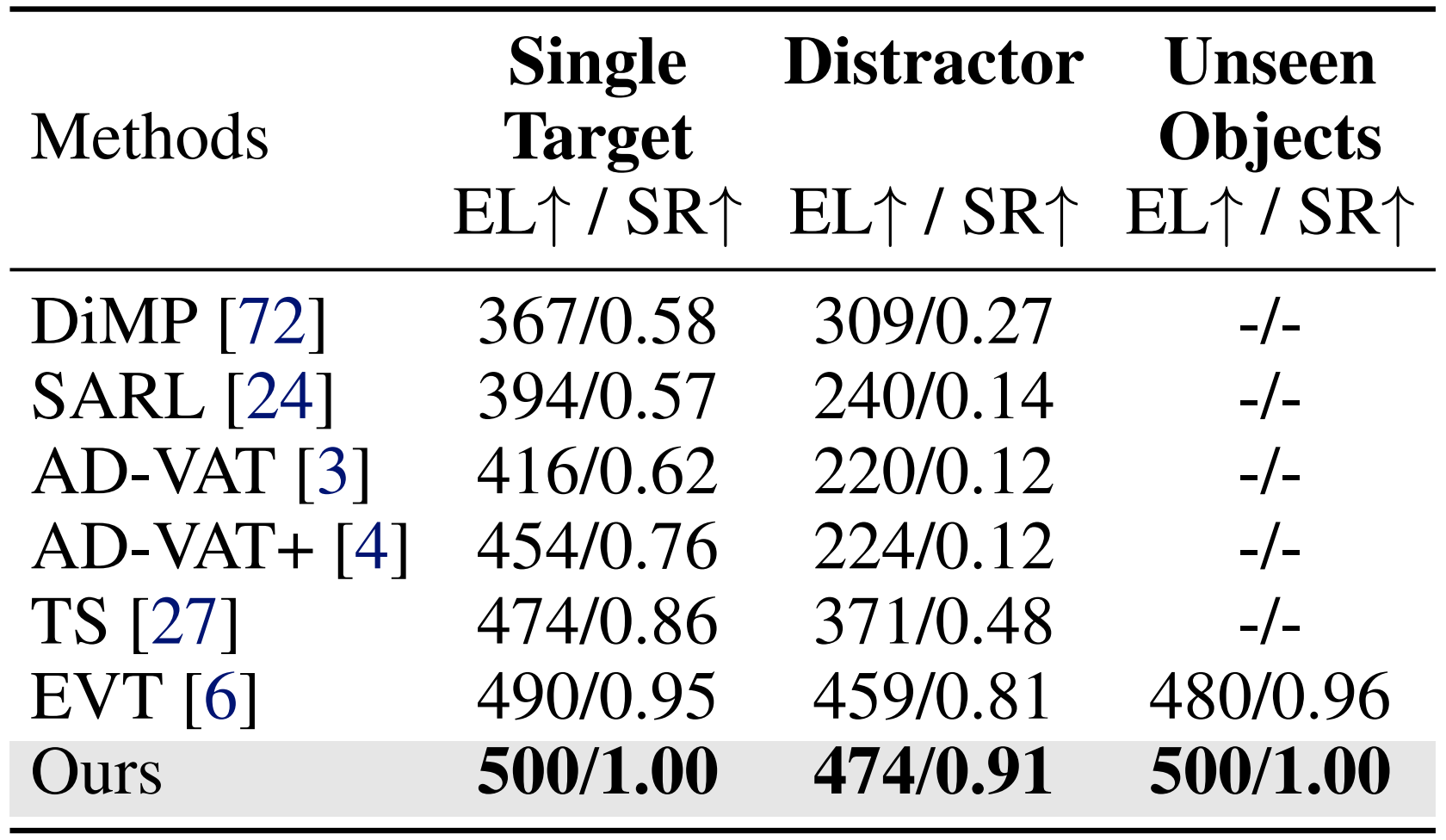
- 单目标跟踪(STT)通过诸如“跟随这个人/男人/女人”这样的简单指令,评估模型的基础跟随能力
- 分心跟踪(DT)通过对目标的细致描述来评估模型的识别能力,例如“跟随穿黑色西装、白色腰带的浅肤色男子”
- 歧义跟踪(AT)评估模型在存在外观完全相同的干扰目标时,识别正确目标的能力。此类指令有意设置为含糊不清,例如“跟随你看到的第一个人”
最后,对于跟踪数据采集
作者在EVT-Bench训练集划分中收集了88.5万条具身视觉跟踪样本,涵盖了三个不同难度的子任务。每个样本包含导航历史(RGB序列)、目标描述以及相应的专家轨迹τgt。关于基准和数据采集的更多细节详见附录。EVT-Bench将会公开发布,以惠及研究社区
1.3.2 视频问答数据集
尽管作者付出了大量努力,融入了多样化的虚拟人物和室内场景,但跟踪样本依然局限于合成环境
为了使 TrackVLA 具备开放世界识别能力(不仅限于跟踪样本),作者进一步收集了共计 85.5 万条识别样本,并与跟踪样本联合训练
具体来说,识别型视频问答(VQA)样本包括 36.2 万条人体识别样本和 49.3 万条开放世界 VQA 样本
- 对于人体识别VQA数据,利用SYNTH-PEDES [16]这一大规模人物-文本数据集,构建了VQA样本,使TrackVLA能够在包含随机组合人物主体和背景场景的视频中识别或描述个体。每个样本通过将1至3个随机选择的人体图像置于不同背景上生成,配以文本描述,详细说明每个人的属性、相对空间位置,以及他们是否为同一身份
- 除了人体识别样本外,作者还引入了公开可用的VQA样本[18,17,19],这些样本提供了开放世界的描述。这些样本提升了TrackVLA识别开放世界目标的能力。(见表1)
// 待更