RAG中的评估指标总结:BLEU、ROUGE、 MRR、MAP、nDCG、Precision@k、Recall@k 等
在构建现代信息检索系统(如 RAG、问答系统、搜索引擎、推荐系统)时,评估检索器的性能是至关重要的一步。选择合适的评估指标能帮助我们准确判断系统的优劣,进而优化排序、召回质量和用户体验。本文将系统性地介绍主流检索指标,包括其原理、示例和适用场景。
1. BLEU(Bilingual Evaluation Understudy)
用途:主要用于机器翻译、文本生成等任务,评估生成文本与参考文本的相似程度。
原理:
BLEU 基于n-gram 匹配,计算生成文本中有多少 n-gram 与参考文本中的 n-gram 匹配。
支持 1-gram 到 4-gram 的加权平均。
引入了brevity penalty(简短惩罚),防止模型生成非常短但准确的片段得高分。
式简化版:
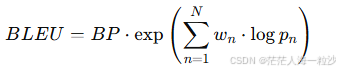
: 第 n 阶 n-gram 的精确率
: 权重,通常为均分
BP: brevity penalty
示例:
参考句子:
the cat is on the mat
生成句子:
the cat is on mat
1-gram 匹配:5 个词中有 4 个匹配("the", "cat", "is", "on")
2-gram 匹配:4 个 2-gram 中有 2 个匹配("the cat", "cat is")
BLEU 分数:约 0.75(简化计算)
2. ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
用途:主要用于文本摘要、问答等生成任务。
原理:
ROUGE 更侧重于召回率(recall),衡量参考答案中有多少 n-gram 被生成答案覆盖。
常见变体:
ROUGE-N:n-gram 的召回率(如 ROUGE-1,ROUGE-2)
ROUGE-L:最长公共子序列(LCS)
ROUGE-W:带权 LCS
ROUGE-1 的定义与公式
ROUGE-1 衡量的是生成文本中与参考文本之间 unigram(单词)级别的重叠。它强调的是召回率(Recall):

变量说明:
重叠的 unigram 数量:生成文本中与参考文本匹配的单词数(不重复计数)
参考文本中的 unigram 总数:参考答案总共有多少个词
示例:
参考文本:
the cat is on the mat
生成文本:
the cat is on mat
参考文本的 unigram 数:6(the, cat, is, on, the, mat)
去重参考文本(可选,不常用):5(the, cat, is, on, mat)
重叠 unigram 数量:5(the, cat, is, on, mat)
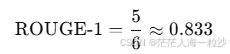
注意:默认情况下 ROUGE-1 计算的是召回率(也有变体计算 F1 分数或 Precision)
3. MRR(Mean Reciprocal Rank)
用途:常用于信息检索、问答系统中,用于衡量正确答案在候选列表中的排名。
原理:
对于每个查询,计算第一个相关(正确)答案的排名的倒数,然后对所有查询取平均。
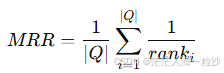
:第 i 个查询中,第一个正确答案的排名
示例:
假设有三个查询:
正确答案在第 1 位 → reciprocal = 1
正确答案在第 3 位 → reciprocal = 1/3
正确答案在第 2 位 → reciprocal = 1/2
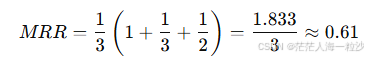
4. MAP(Mean Average Precision)是什么?
MAP 是衡量多个检索结果中,相关项排序整体质量的指标。
它不仅考虑你是否找到了正确答案,还关注它们的排名位置和完整性。
MAP 的评估原理(分两步):
第一步:计算 Average Precision(AP)
对于每个查询,AP 是该查询中多个正确答案的「加权精确率」,越早出现越高权重。
具体计算方式:
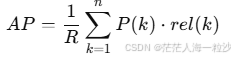
R:该查询的相关文档总数(即 ground truth 数量)
n:检索结果的总数(比如 top 10)
P(k):前 k个结果中的 precision(准确率)
rel(k):如果第 k 个结果是相关的,为 1;否则为 0
注意:只有当第 k 个文档是相关时,才把 P(k) 纳入计算
第二步:对多个查询取平均 → 得到 Mean Average Precision
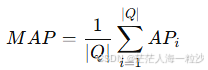
示例讲解(一个查询)
假设检索返回以下结果(10 个文档):
[0, 1, 0, 1, 1, 0, 0, 0, 1, 0]
对应的 ground truth 中有 4 个相关文档(在位置 2、4、5、9)
步骤:
| Rank | rel(k) | P(k) |
|---|---|---|
| 1 | 0 | - |
| 2 | 1 | 1/2 = 0.5 |
| 3 | 0 | - |
| 4 | 1 | 2/4 = 0.5 |
| 5 | 1 | 3/5 = 0.6 |
| 6–8 | 0 | - |
| 9 | 1 | 4/9 ≈ 0.444 |
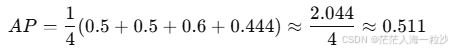
MAP 的优势
更全面地评价所有正确答案的排序质量
非常适用于:
信息检索
问答系统(多个候选文档)
文本匹配
推荐系统
5. nDCG:Rerank 排序的首选指标
原理:
nDCG 考虑排名靠前的正确答案更重要,尤其适合有相关性等级的任务。
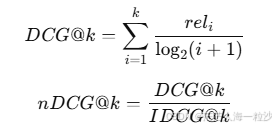
是该位置文档的“相关性标签”(如 0,1,2,或 soft score)
IDCG是最理想排序的 DCG(即把正确的放最前面)非常适合用于判断:是否把正确文档排在前面,排得越前,分越高
举个例子
假设 Ground Truth 有两个正确文档(doc2 和 doc4),我们 rerank 后得到如下排序:
[doc4, doc1, doc2, doc5, doc3]
我们给出以下 relevance 分数(0-1 表示是否相关):
relevance = [1, 0, 1, 0, 0]
那么:
MRR = 1/1 = 1.0(doc4 是第 1 个就是正确答案)
MAP = (1/1 + 2/3)/2 ≈ 0.83
nDCG@5 = 1.761 / 1.861 ≈ 0.946
可以看出:nDCG 给了高度评价,因为两个相关项都排得靠前。
6. Precision@k
原理:
衡量前 k 个结果中正确文档的比例。
公式:
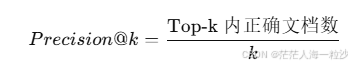
示例:
Top-5 结果中有 3 个正确:Precision@5 = 3/5 = 0.6
适用范围:
精度导向的检索评估
推荐系统
7. Recall@k
原理:
衡量 top-k 中找到了所有正确答案的比例。
公式:

示例:
正确答案有 4 个,top-10 中命中 3 个。
Recall@10 = 3/4 = 0.75
适用范围:
重召回优先的任务,如 QA 文档覆盖
8. Hit@k
原理:
前 k 个结果中是否命中至少一个正确答案。
公式:
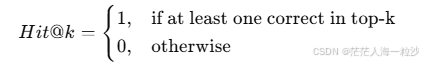
示例:
Top-3 命中 doc2:Hit@3 = 1
适用范围:
快速评估检索是否"有用"
检索器评估常用指标一览
| 指标 | 衡量内容 | 是否考虑多个正确答案 | 排名敏感 | 常用于 |
|---|---|---|---|---|
| Recall@k | 前 k 个中是否覆盖了所有正确答案 | ✅ 是 | ❌ 否 | QA, RAG 检索评估 |
| Precision@k | 前 k 个中有多少是正确的 | ✅ 是 | ❌ 否 | 检索与召回 |
| MRR | 第一个正确答案排名的倒数 | ❌ 否(只看第一个) | ✅ 是 | QA 单答案 |
| MAP | 所有正确答案的排名质量 | ✅ 是 | ✅ 是 | 多答案检索任务 |
| nDCG@k | 正确答案分数随排名衰减的加权值 | ✅ 是(带权) | ✅ 是 | 检索排序优化 |
| Hit@k | Top-k 中是否至少包含一个正确答案 | ✅ 是(但不计精度) | ❌ 否 | 简易评估 |