dbeaver导入数据及配置讲解
导入数据教程:
前提.csv文件:且只能导入一个sheet
点击下一步
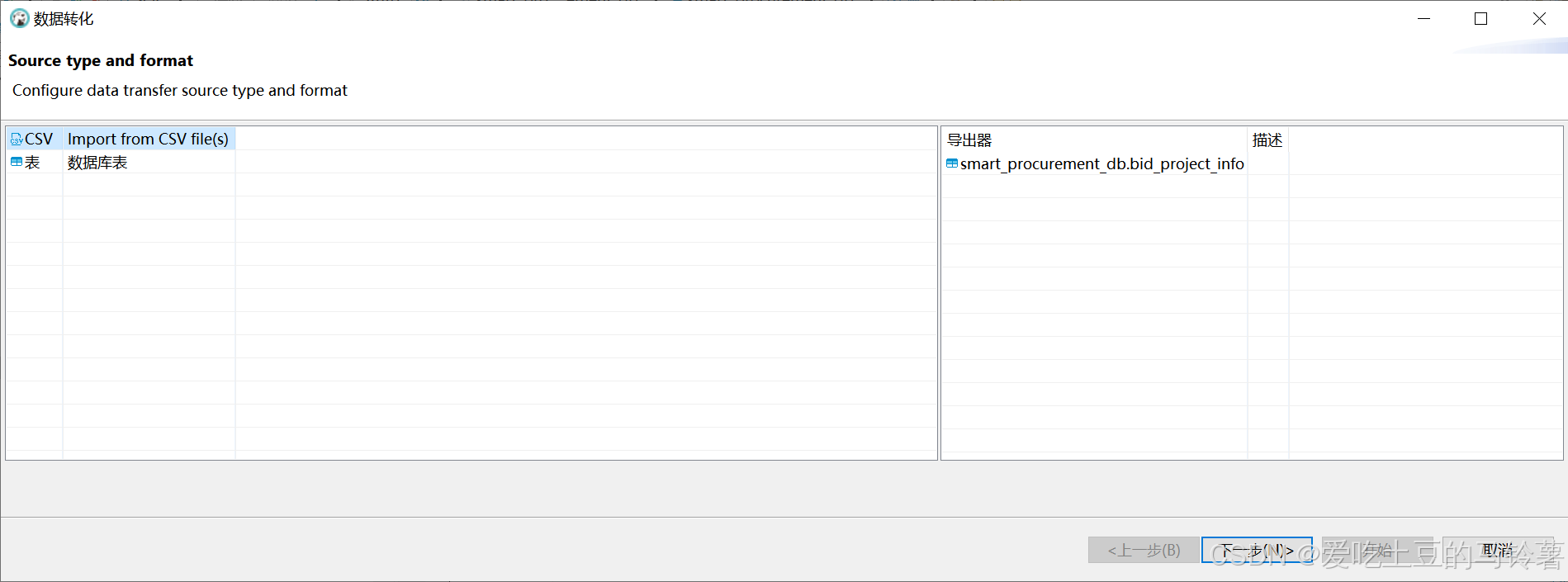
选中导入的.csv文件
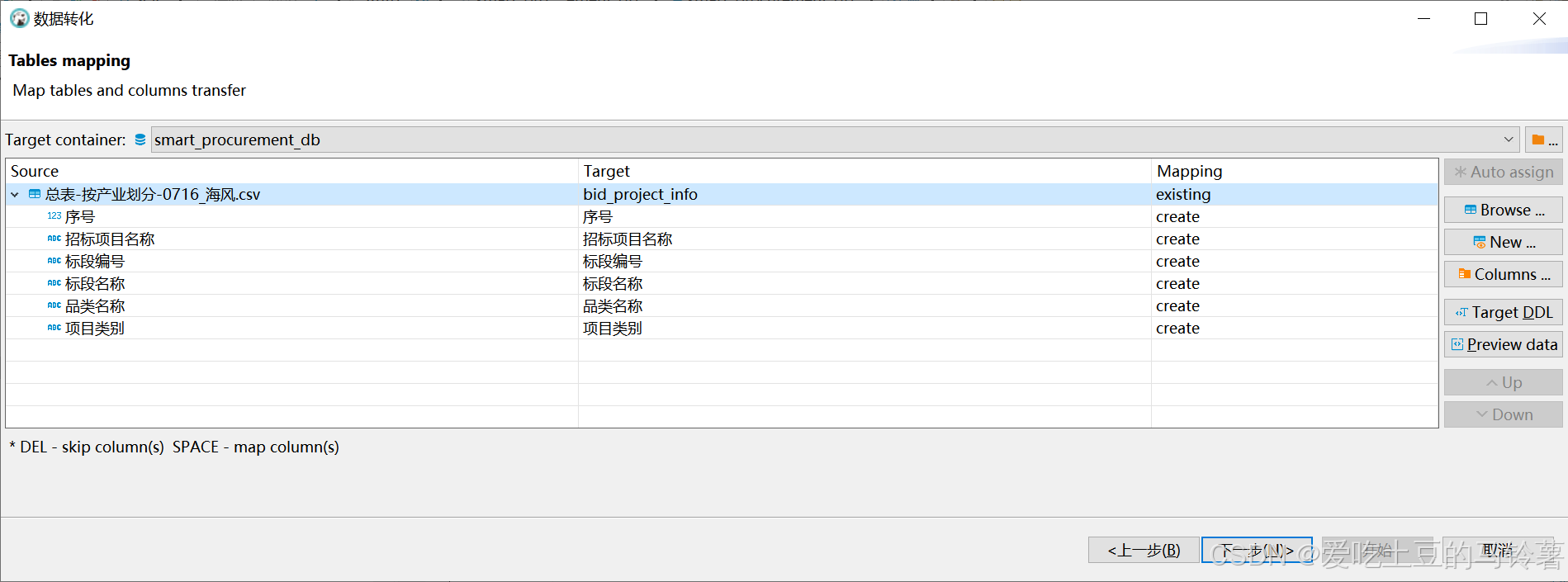
对应好数据字段和表字段,感觉不需要导入的可以skip
配置一下,下面有介绍:
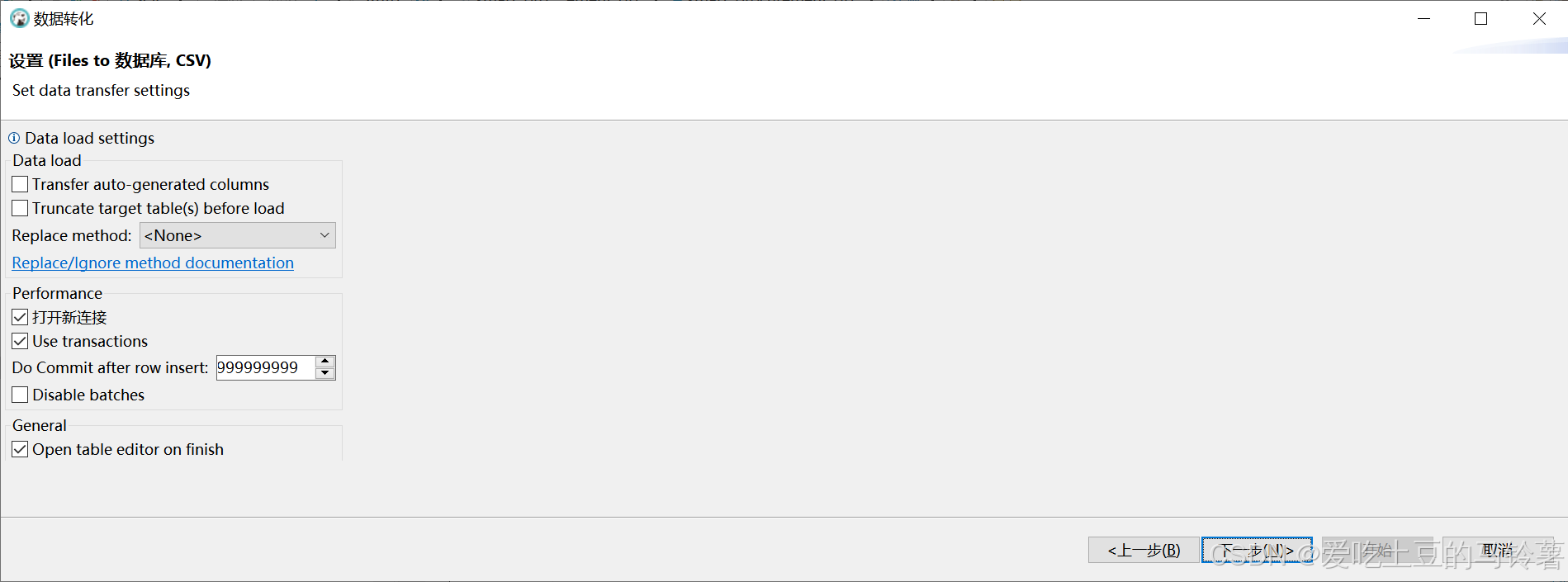
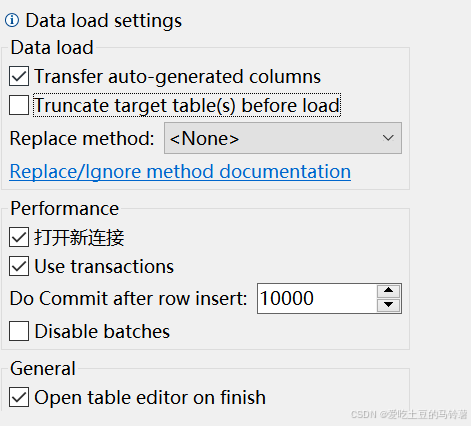
以下为你详细解析这些数据加载相关功能的含义与作用:
数据加载(Data load)部分
-
Transfer auto - generated columns(传输自动生成的列)
- 含义:若目标表存在数据库自动生成的列(比如数据库自动维护的自增主键
id、时间戳列create_time,由数据库默认规则生成值 ),勾选后,数据加载时这些列会参与传输、处理(插入/更新流程里,保留或适配其自动生成逻辑 );不勾选则会跳过,不处理这些自动生成列相关的数据。 - 场景:迁移数据时,想保留数据库自动生成的主键、时间戳等逻辑,就勾选;若需自定义覆盖这些列值,可结合其他配置,或不勾选此选项。
- 含义:若目标表存在数据库自动生成的列(比如数据库自动维护的自增主键
-
Truncate target table(s) before load(加载前截断目标表)
- 含义:“Truncate(截断)” 是数据库操作,会清空目标表所有数据(比
DELETE更高效,且不触发触发器,会重置自增计数器 )。勾选后,执行数据加载前,先清空目标表;不勾选则保留表中已有数据,新数据按配置的 “替换/忽略策略(Replace method)” 处理(如增量插入、冲突更新等 )。 - 场景:做全量数据同步/初始化加载,要清空旧数据、重新灌入,就勾选;做增量更新,需保留历史数据,则不勾选。
- 含义:“Truncate(截断)” 是数据库操作,会清空目标表所有数据(比
-
Replace method: (替换方法:<无>)
- 含义:决定数据加载时,遇到新旧数据冲突(主键重复等 )的处理逻辑。选
<None>时,通常按数据库默认冲突规则(如插入冲突则报错终止 );若选其他策略(如Replace会覆盖旧数据,Ignore会跳过冲突行 ),则按对应逻辑处理。 - 场景:全量覆盖场景选
Replace;增量更新、跳过冲突数据选Ignore;想严格校验冲突、报错终止,保持<None>用数据库默认行为。
- 含义:决定数据加载时,遇到新旧数据冲突(主键重复等 )的处理逻辑。选
-
Replace/Ignore method documentation(替换/忽略方法文档)
- 含义:点击可查看 “替换/忽略策略” 详细说明文档,包含每种策略逻辑、适用场景、与数据库交互细节等,帮你选合适冲突处理方式。
- 场景:配置数据加载,不确定选哪种 “替换/忽略” 策略时,点此查阅,辅助决策。
性能(Performance)部分
-
打开新连接(Open new connection,界面显示为中文,英文一般对应表述 )
- 含义:数据加载时,是否新建独立数据库连接。勾选则启用新连接,与当前其他数据库操作(如界面查询 )的连接隔离;不勾选则复用已有连接(若支持 )。
- 场景:数据加载任务复杂、数据量大,怕影响现有数据库连接的操作(如业务查询 ),就勾选新建连接;简单小量加载,为减少连接资源开销,可复用连接(若系统支持 )。
-
Use transactions(使用事务)
- 含义:事务是数据库保证操作原子性的机制(一组操作要么全成功,要么全回滚 )。勾选后,数据加载操作会包裹在事务里;失败时,已执行的插入/更新会回滚,保证数据一致性;不勾选则可能按语句逐条执行,部分成功会导致数据不一致。
- 场景:数据完整性要求高(如财务、订单数据同步 ),必须勾选;一些允许部分失败、追求极致性能的日志类数据加载,可权衡是否关闭(但风险高 )。
-
Do Commit after row insert: 10000(每插入 10000 行后提交)
- 含义:控制事务提交频率。每插入 10000 行数据,就提交一次事务(持久化到数据库 );若中途失败,已提交的批次数据保留,未提交的回滚。值越小,提交越频繁,事务开销大但数据更及时落库;值越大,性能高但失败时回滚范围大。
- 场景:加载超大规模数据,为平衡性能和风险,设合理值(如 10000 );小数据量加载,可减小值(如 1000 ),让数据更快落库。
-
Disable batches(禁用批处理)
- 含义:“批处理(Batches)” 是将多条数据操作(插入/更新 )打包成一个批次,一次性发给数据库执行,提升效率。勾选 “Disable batches” 则关闭批处理,数据操作逐条执行,性能会降低(尤其大数据量时 )。
- 场景:数据库对批处理支持不好(旧版本、自定义存储过程冲突 ),或需调试、定位单行数据问题,可勾选禁用;追求性能、大数据量加载,保持不勾选,用批处理加速。
常规(General)部分
Open table editor on finish(完成后打开表编辑器)
- 含义:数据加载任务执行完毕,自动打开目标表的编辑器界面,方便你直接查看、校验加载后的数据(浏览表结构、数据内容,快速核对结果 )。
- 场景:做数据加载验证、调试,想立即看结果,就勾选;加载任务是自动化流程一部分,无需人工干预查看,可不勾选,减少界面自动弹窗操作。
这些功能相互配合,能灵活控制数据加载的全流程(从数据处理逻辑,到性能调优,再到结果校验 ),适配不同业务场景(全量/增量、性能优先/安全优先等 )的需求 。