[自动化Adapt] 回放策略 | AI模型驱动程序
第八章:回放策略
欢迎回来,OpenAdapt探索者~
在第七章:隐私保护(擦除)中,我们学习了OpenAdapt如何保护录制内容中的敏感信息。在此之前,我们了解了录制数据的存储方式(第六章:数据库管理),以及原始事件如何被精炼为有意义的操作(第五章:事件处理与合并)。
现在让我们探讨最激动人心的部分:让OpenAdapt实际执行我们录制的任务!
假设我们已录制了填写在线表单的过程。当需要OpenAdapt重复此任务时,它是如何知道具体执行方式的?它会像鹦鹉学舌般逐像素复现鼠标点击和按键操作吗?还是能像智能助手般理解任务目标,在界面稍有变化时自动适应?
若采用像素级精确回放,当遇到以下情况时将面临挑战:
- 浏览器窗口位置偏移
- 按钮坐标发生数像素变动
- 列表项顺序调整
这时"像素完美"的回放就可能失败!这正是OpenAdapt需要回放策略的根本原因。
什么是回放策略?
回放策略可视为OpenAdapt执行自动化任务的"战术手册",每种策略代表不同的工作流回放方法。它们指导系统如何解析和执行已录制的操作序列。
为何需要多种策略?
就像优秀教练需要针对不同场景制定战术手册,OpenAdapt的多样化策略源于自动化任务的差异性:
- 可靠性:确保在界面微调时仍能稳定执行
- 适应性:像智能助手般理解上下文,执行类似"点击’提交’按钮"的抽象指令
- 高效性:快速精准完成目标操作
以网站登录自动化为例:
- 简单策略直接点击固定坐标的"登录"按钮(位置不变时有效)
- 智能策略通过视觉识别定位按钮(适应界面布局变化)
回放策略实践指南
使用回放策略的流程非常直观。在终端执行如下命令:
python -m openadapt.replay <策略名称> --timestamp=<录制时间戳>
参数说明:
<策略名称>:指定战术手册类型(如NaiveReplayStrategy/VanillaReplayStrategy/VisualReplayStrategy)--timestamp:指定目标录制时间戳(通过python -m openadapt.list查询)
应用示例:
使用基础策略回放最新录制:
python -m openadapt.replay NaiveReplayStrategy
使用智能策略执行指定录制(20230101_123456)并附加自然语言指令:
python -m openadapt.replay VisualReplayStrategy --timestamp=20230101_123456 --instructions="先点击'登录'按钮,再在用户名字段输入'myuser'"
部分AI驱动策略支持通过--instructions参数用自然语言调整回放行为。
策略执行机制
执行openadapt.replay命令时,系统会按以下流程展开工作:
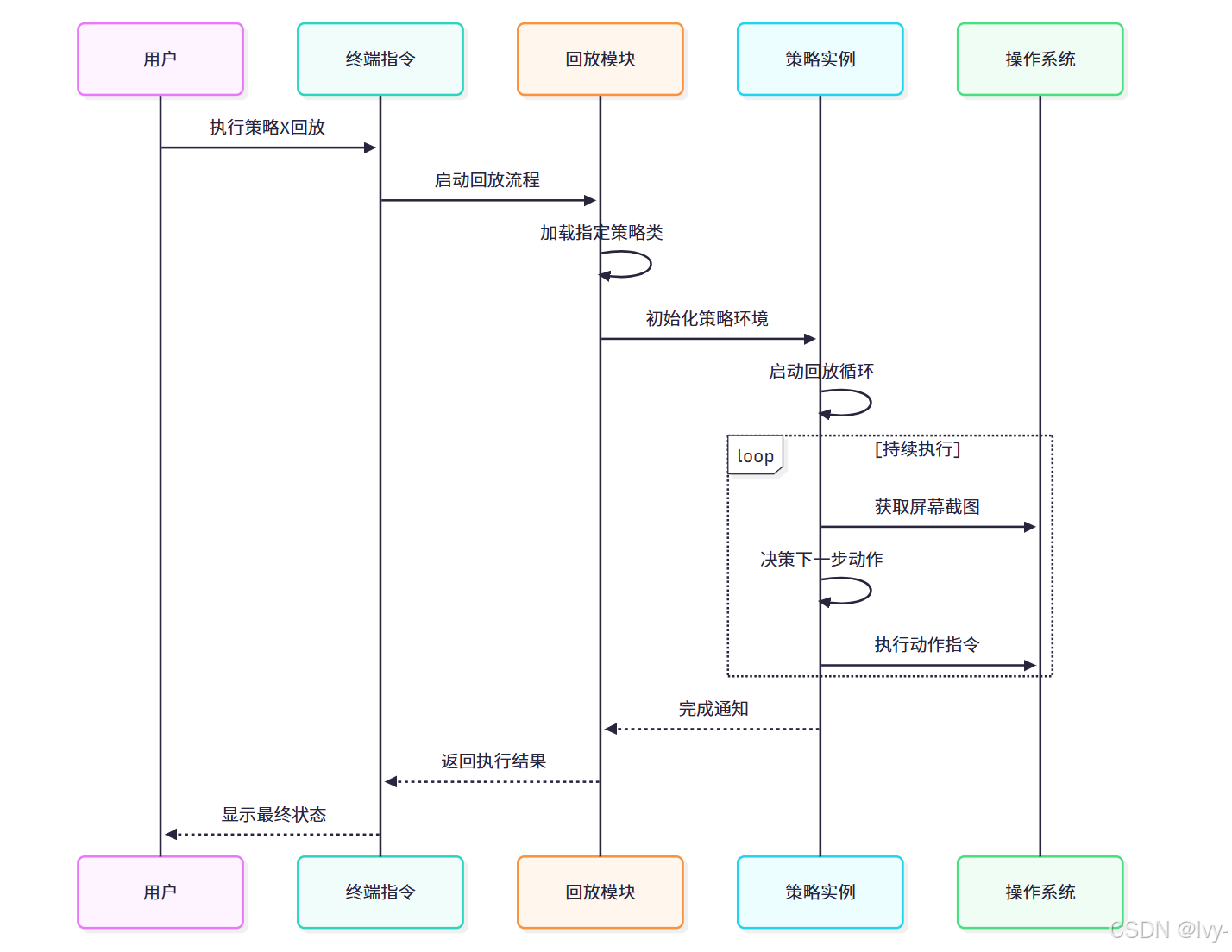
核心入口文件:openadapt/replay.py
该模块负责初始化回放流程:
# 简化版openadapt/replay.py
import fire
from openadapt import utils
from openadapt.db import cruddef replay(strategy_name: str,timestamp: str | None = None,recording = None,**kwargs: dict,
) -> bool:session = crud.get_new_session(read_only=True)# 获取指定录制数据recording = crud.get_recording(session, timestamp) if timestamp else crud.get_latest_recording(session)# 动态加载策略类strategy_class = utils.get_strategy_class_by_name()[strategy_name]# 实例化并执行策略strategy = strategy_class(recording, **kwargs)strategy.run()return Trueif __name__ == "__main__":fire.Fire(replay)
策略注册中心:openadapt/strategies/init.py
该文件集中管理所有可用策略:
# 策略目录文件
from .base import BaseReplayStrategy
from .naive import NaiveReplayStrategy
from .vanilla import VanillaReplayStrategy
from .visual import VisualReplayStrategy
from .visual_browser import VisualBrowserReplayStrategy
策略基类:openadapt/strategies/base.py
定义所有策略的通用框架:
# 策略基类实现
from abc import ABC, abstractmethod
from pynput import keyboard, mouse
from openadapt import models, playbackclass BaseReplayStrategy(ABC):def __init__(self, recording: models.Recording, **kwargs) -> None:self.recording = recordingself.keyboard_controller = keyboard.Controller()self.mouse_controller = mouse.Controller()@abstractmethoddef get_next_action_event(self, screenshot: models.Screenshot, window_event: models.WindowEvent) -> models.ActionEvent:passdef run(self) -> None:while True:current_screenshot = models.Screenshot.take_screenshot()current_window_event = models.WindowEvent.get_active_window_event()try:action_event = self.get_next_action_event(current_screenshot, current_window_event)playback.play_action_event(action_event, self.mouse_controller, self.keyboard_controller)except StopIteration:break
具体策略实现
基础策略:NaiveReplayStrategy
该策略机械复现录制动作:
# 简单回放策略实现
import time
from openadapt import models, strategiesclass NaiveReplayStrategy(strategies.base.BaseReplayStrategy):def __init__(self, recording: models.Recording, **kwargs) -> None:super().__init__(recording)self.action_event_idx = -1self.processed_events = recording.processed_action_eventsself.prev_timestamp = Nonedef get_next_action_event(self, screenshot: models.Screenshot, window_event: models.WindowEvent) -> models.ActionEvent | None:self.action_event_idx += 1if self.action_event_idx >= len(self.processed_events):raise StopIteration()action_event = self.processed_events[self.action_event_idx]# 保持原始时间间隔if self.prev_timestamp:time.sleep(action_event.timestamp - self.prev_timestamp)self.prev_timestamp = action_event.timestampreturn action_event
智能策略范例
VanillaReplayStrategy(AI基础版)
# AI驱动策略实现
from openadapt import adapters, models, strategiesclass VanillaReplayStrategy(strategies.base.BaseReplayStrategy):def __init__(self, recording: models.Recording, instructions: str = "") -> None:super().__init__(recording)self.instructions = instructionsself.action_history = []# 使用AI解析录制内容self.recording_description = self.describe_recording(recording)def get_next_action_event(self, current_screenshot: models.Screenshot, current_window_event: models.WindowEvent) -> models.ActionEvent | None:# 调用AI模型决策下一步action_event = self.generate_action_event(current_screenshot,current_window_event,self.recording.processed_action_events,self.action_history,self.instructions)self.action_history.append(action_event)return action_event
VisualReplayStrategy(视觉增强版)
# 视觉策略实现
from openadapt import adapters, models, strategies, visionclass VisualReplayStrategy(strategies.base.BaseReplayStrategy):def __init__(self, recording: models.Recording, instructions: str) -> None:super().__init__(recording)self.modified_actions = self.apply_replay_instructions(recording.processed_action_events,instructions)self.recording_action_idx = 0def get_next_action_event(self, active_screenshot: models.Screenshot, active_window: models.WindowEvent) -> models.ActionEvent:# 视觉分割定位元素modified_reference_action = self.modified_actions[self.recording_action_idx]if modified_reference_action.name in common.MOUSE_EVENTS:active_window_segmentation = self.get_window_segmentation(modified_reference_action)# 计算目标元素坐标target_centroid = active_window_segmentation.centroids[target_segment_idx]modified_reference_action.mouse_x, modified_reference_action.mouse_y = self.calculate_coordinates(target_centroid)return modified_reference_action
策略对比矩阵
| 策略名称 | 工作原理 | 适应性 | AI依赖 | 最佳场景 |
|---|---|---|---|---|
| NaiveReplayStrategy | 精确复现录制动作 | 无 | 否 | 稳定环境的基础测试 |
| VanillaReplayStrategy | AI解析上下文决策动作 | 中 | 是 | 需要语境理解的常规任务 |
| VisualReplayStrategy | 视觉分割识别界面元素 | 高 | 是 | 界面频繁变化的复杂应用 |
| VisualBrowserReplayStrategy | 结合DOM解析与视觉分析 | 极高 | 是 | 动态网页元素的精准自动化 |
本章总结
我们深入探讨了OpenAdapt的回放策略体系,从基础复现到智能决策的多层次实现。理解不同策略在get_next_action_event方法中的差异化实现,能帮助我们根据具体场景选择最优自动化方案。接下来我们将揭秘驱动这些智能策略的AI模型工作机制。
下一章:AI模型驱动
第九章:AI模型驱动程序
在第八章:回放策略中,我们学习了OpenAdapt如何使用不同的"剧本"来自动化任务,从简单重复到智能的AI驱动适配。我们提到了像VanillaReplayStrategy和VisualReplayStrategy这样的策略如何利用人工智能来"看"屏幕并"决定"下一步操作。
但OpenAdapt实际上是如何与GPT-4、Google Gemini或Anthropic Claude等强大AI模型"对话"的?它们都使用相同的"语言"吗?不完全!每个AI模型都有自己独特的请求接收和响应返回方式。
想象我们有一个高智商团队,每个成员说不同语言(比如英语、西班牙语、法语)。如果要给他们分配任务,就需要为每个成员配备翻译对吗?
这正是AI模型驱动程序在OpenAdapt中解决的问题。
什么是AI模型驱动程序?
AI模型驱动程序可以看作**“翻译器"或"连接器”**,使OpenAdapt能与各种强大AI模型无缝通信。OpenAdapt核心逻辑无需学习每个AI模型的独特"语言"(API),只需通过这些驱动程序即可。
为什么需要这个?
当OpenAdapt的智能回放策略需要询问AI模型(比如"屏幕上有什么?“或"下一步该点击哪里?”)时,会发送请求。但不同AI模型需要不同格式的请求,并以不同方式响应。
没有AI模型驱动程序,OpenAdapt的代码将变得非常混乱和复杂,充满针对每个AI的特定指令。如果出现新AI模型或现有模型改变"语言",就需要重写核心代码。
AI模型驱动程序通过标准化方式解决这个问题:
- 发送提示:将请求(可包含文本甚至截图图像!)打包成特定AI模型理解的格式
- 接收响应:将AI模型的响应翻译回OpenAdapt易用的格式
目标是使OpenAdapt的AI集成:
- 模块化:轻松切换不同AI模型
- 灵活性:添加新AI模型无需更改核心逻辑
- 可靠性:确保跨AI模型的稳定通信
以核心示例说明:OpenAdapt使用AI模型分析当前屏幕截图并确定VisualReplayStrategy中的下一步操作。AI模型驱动程序正是实现与AI模型对话的关键组件。
如何使用AI模型驱动程序(简易方式)
作为用户,我们通常不直接与AI模型驱动程序交互。它们默默在后台工作,为更高级的回放策略提供动力。
我们主要通过配置设置与AI模型驱动程序交互,特别是为要使用的AI服务提供必要的API密钥。
可以通过OpenAdapt的Web仪表盘完成:
首先启动仪表盘:
python -m openadapt.app.dashboard.run
浏览器打开仪表盘后,导航到"设置"部分。在"API密钥"类别下,会看到各AI服务的字段:
OPENAI_API_KEY:用于GPT-4o、GPT-4 Vision等模型GOOGLE_API_KEY:用于Google Gemini模型ANTHROPIC_API_KEY:用于Anthropic Claude模型REPLICATE_API_TOKEN:用于Replicate托管的模型
只需将对应服务的API密钥粘贴到相应字段。
如果提供多个API密钥会怎样?
OpenAdapt很智能!当AI驱动的回放策略需要与AI模型通信时,会按预设顺序尝试使用驱动程序。如果首个(如OpenAI)失败或未配置,将自动尝试下一个(如Google、Anthropic)。这提供了内置回退机制,使自动化更健壮。
AI模型驱动程序:通信枢纽
(AI在自动化领域的运用)
当回放策略需要AI协助时(如分析截图),AI模型驱动程序的工作流程:
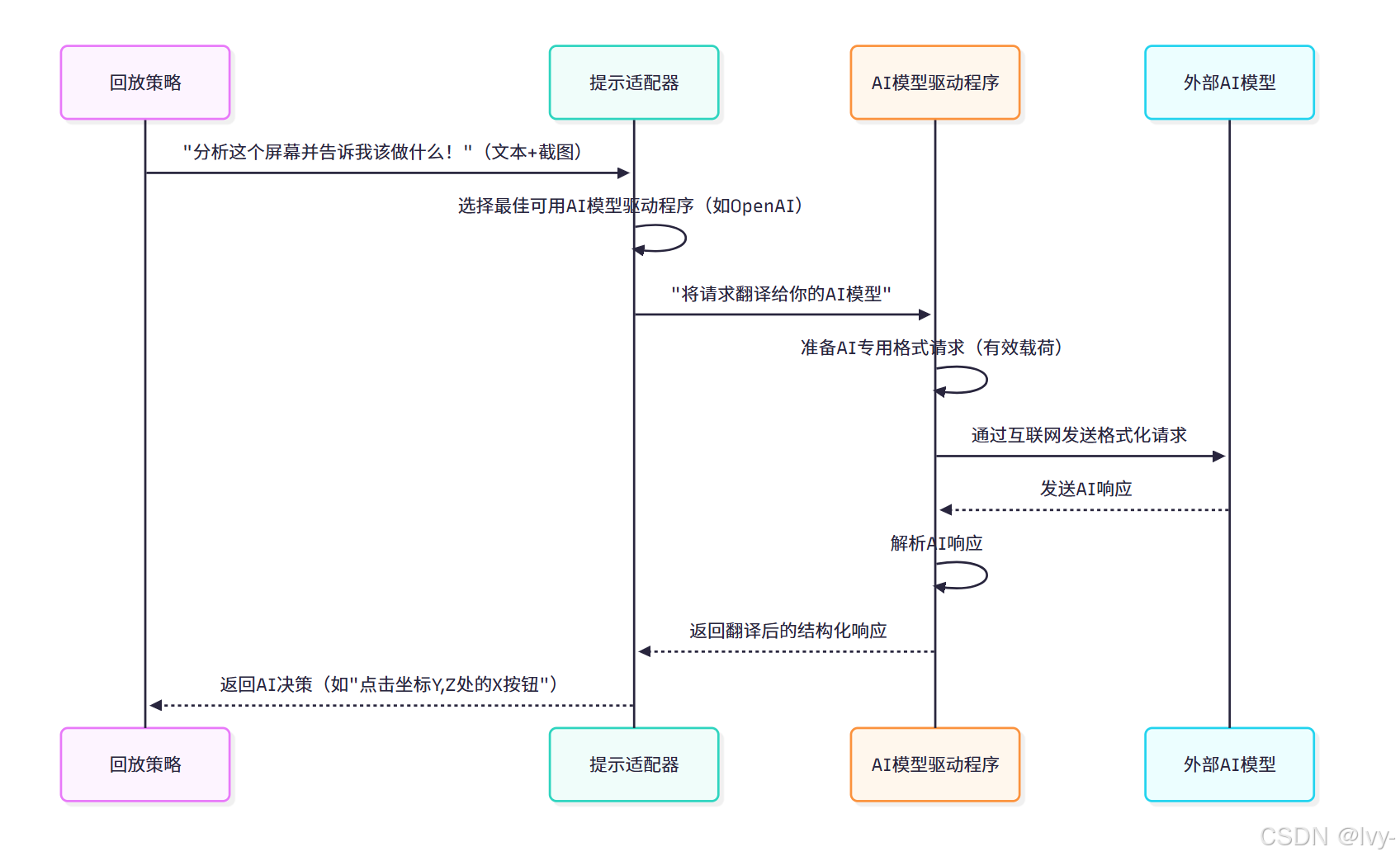
该流程显示回放策略不直接与OpenAI或Google对话,而是通过提示适配器使用正确的AI模型驱动程序处理具体AI通信。
openadapt/adapters/prompt.py:主协调器
协调与不同AI模型通信的核心组件位于openadapt/adapters/prompt.py。该文件包含prompt函数,作为OpenAdapt各模块(如回放策略)向AI模型提问的通用入口。
# 摘自openadapt/adapters/prompt.py(简化版)from typing import Type
from PIL import Imagefrom openadapt.custom_logger import logger
# 导入特定AI模型驱动程序
from openadapt.drivers import anthropic, google, openai# 定义驱动程序尝试顺序
DRIVER_ORDER: list[Type] = [openai, google, anthropic]def prompt(text: str,images: list[Image.Image] | None = None,system_prompt: str | None = None,
) -> str:"""按优先级顺序尝试从各服务获取提示完成"""text = text.strip()for driver in DRIVER_ORDER: # 按偏好顺序遍历驱动程序try:logger.info(f"尝试驱动程序: {driver.__name__}")# 调用特定AI模型驱动程序的'prompt'方法return driver.prompt(text, images=images, system_prompt=system_prompt)except Exception as e:logger.error(f"驱动程序 {driver.__name__} 失败,错误: {e}")continue # 尝试下一个驱动程序raise Exception("所有驱动程序均未能提供响应")
这个prompt函数是关键。它遍历DRIVER_ORDER列表,尝试从每个AI模型驱动程序获取响应。
这就是设置多个API密钥能提供回退的原因!每个driver(如openai、google)都有自己的prompt函数,知晓如何与其特定AI通信。
具体翻译器:openadapt/drivers/*.py
openadapt/drivers/文件夹中的每个文件(如anthropic.py、google.py、openai.py)都是专用的AI模型驱动程序。它们是真正的"翻译器",处理准备特定AI模型请求、通过互联网发送请求和解析响应的具体细节。
以openadapt/drivers/openai.py的简化示例,说明如何向OpenAI模型(如GPT-4o)发送文本和图像:
# 摘自openadapt/drivers/openai.py(简化版)from PIL import Image
import requests # 用于通过互联网发送请求
from openadapt import cache, utils
from openadapt.config import config # 获取API密钥MODEL_NAME = "gpt-4o" # 该驱动程序对话的特定AI模型@cache.cache() # OpenAdapt缓存AI响应以加速
def create_payload(prompt: str,system_prompt: str | None = None,images: list[Image.Image] | None = None,model: str = MODEL_NAME,
) -> dict:"""按OpenAI专用格式准备数据"""messages = [{"role": "user", "content": [{"type": "text", "text": prompt}]}]# 添加图像(转换为base64格式)images = images or []for image in images:base64_image = utils.image2utf8(image) # 转换为网页友好格式messages[0]["content"].append({"type": "image_url", "image_url": {"url": base64_image}})if system_prompt: # 添加AI初始指令messages = [{"role": "system", "content": [{"type": "text", "text": system_prompt}]}] + messagesreturn {"model": model, "messages": messages}@cache.cache()
def get_response(payload: dict,api_key: str = config.OPENAI_API_KEY, # 从OpenAdapt配置获取API密钥
) -> dict:"""向OpenAI发送格式化请求并返回原始响应"""headers = {"Content-Type": "application/json","Authorization": f"Bearer {api_key}",}response = requests.post("https://api.openai.com/v1/chat/completions", # OpenAI专用地址headers=headers,json=payload, # 发送准备的数据)result = response.json()if "error" in result:raise Exception(result["error"]["message"])return resultdef prompt(prompt_text: str, # 重命名以避免冲突system_prompt: str | None = None,images: list[Image.Image] | None = None,max_tokens: int | None = None,
) -> str:"""供其他OpenAdapt模块调用的公共方法"""payload = create_payload(prompt_text,system_prompt,images,max_tokens=max_tokens,)result = get_response(payload)# 从AI响应中提取实际文本内容return result["choices"][0]["message"]["content"]
这个OpenAI驱动程序的简化代码展示了关键步骤:
create_payload:将prompt文本和images(转换为base64格式)按OpenAI API要求的JSON结构整理get_response:使用requests库将payload发送到OpenAI专用服务器地址,使用OPENAI_API_KEY认证prompt:openadapt/adapters/prompt.py调用的主公共方法,协调创建载荷和获取响应步骤,从复杂JSON输出提取实际文本响应
anthropic.py和google.py有类似文件,各自包含针对相应AI模型API定制的create_payload、get_response和prompt函数。
AI模型驱动程序概览
以下是OpenAdapt常用AI模型驱动程序摘要:
| 驱动程序文件 | AI模型 | 用途 | 关键配置 |
|---|---|---|---|
openadapt/drivers/openai.py | GPT-4 Vision、GPT-4o | 连接OpenAdapt与OpenAI多模态模型 | OPENAI_API_KEY |
openadapt/drivers/google.py | Gemini Pro Vision、Gemini 1.5 Pro | 连接OpenAdapt与Google Gemini模型 | GOOGLE_API_KEY |
openadapt/drivers/anthropic.py | Claude 3.5 Sonnet | 连接OpenAdapt与Anthropic Claude模型 | ANTHROPIC_API_KEY |
openadapt/adapters/replicate.py | Replicate.com托管的模型(如Llama) | 连接Replicate平台模型 | REPLICATE_API_TOKEN |
注:openadapt/adapters/replicate.py在此列为"驱动程序",因为它同样处理外部AI通信,尽管结构与直接驱动程序略有不同。
结论
我们现在已了解AI模型驱动程序在OpenAdapt中的关键作用!这些驱动程序作为不可或缺的"翻译器",使OpenAdapt的先进回放策略能与各类强大AI模型通信。
通过理解如何配置API密钥,以及OpenAdapt如何利用prompt.py协调器和具体驱动程序文件实现与外部AI的信息收发,我们已完整掌握OpenAdapt实现智能自适应自动化的机制。
本章完成了对OpenAdapt核心概念的深入探讨。现在我们已经全面理解OpenAdapt如何记录操作、组织数据、理解GUI界面、管理设置、处理事件、存储信息、保护隐私,以及通过各类AI驱动的策略智能回放任务。
END ★,°:.☆( ̄▽ ̄):.°★ 。