VAE学习笔记
模型结构:
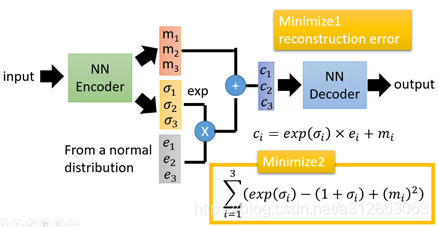
(m1,m2,m3)是数据经过encoder 得到的编码
(σ1,σ2,σ3)是控制噪音干扰程度的编码,就是为随机噪音码(e1,e2,e3)分配权重
损失函数2:如果没有对σi 的限制 生成的图片会希望噪音对自身生成图片的干扰越小,于是分配给噪音的权重越小,这样只需要将(σ1,σ2,σ3)赋为接近负无穷大的值就好了,直观上也能看出来在σi=0处取最小
VAE原理:
首先VAE认为 所有数据都是由某个隐藏变量生成的 学会了这个隐藏变量的分布 就可以生成数据。
关键步骤:
Encoder:把输入数据压缩成隐藏变量的分布参数(均值和方差),直接输出固定值会导致生成能力变差 输出分布可以随机采样增加多样性。
重参数化技巧:解决直接采样不可导问题 改用以下方式 。
z = μ + σ * ε, 其中 ε ~ N(0, 1)
Decoder:把隐藏变量 z 还原成数据(如生成新图片)。
损失函数:
重构损失以及KL散度,KL散度主要是限制σ不要跑偏,保证生成多样性。
基础代码实现:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torch.nn.functional as F
from torchvision.utils import save_imageclass VAE(nn.Module):def __init__(self, input_size, latent_size):super(VAE, self).__init__()#编码器层self.fc1 = nn.Linear(input_size, 512)self.fc2 = nn.Linear(512, latent_size)self.fc3 = nn.Linear(512, latent_size)#解码器层self.fc4 = nn.Linear(latent_size, 512)self.fc5 = nn.Linear(512, input_size)def encode(self, x):x = F.relu(self.fc1(x)) #编码器的隐藏表示mu = self.fc2(x)logvar = self.fc3(x)return mu, logvardef reparameterize(self, mu, logvar):std = torch.exp(0.5*logvar)eps = torch.randn_like(std)return mu + eps*stddef decode(self, z):z = F.relu(self.fc4(z)) #将潜在变量Z解码为重构图像return torch.sigmoid(self.fc5(z)) #将隐藏表示映射回输入图像大小 用sigmoid激活 产生重构图像def forward(self, x):mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)out = self.decode(z)return out , mu, logvardef loss_function(recon_x, x, mu, logvar):MSE = F.mse_loss(recon_x, x.view(-1,input_size), reduction='sum')KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())return MSE + KLDif __name__ == '__main__':batch_size = 64epochs = 50sample_interval = 10learning_rate = 1e-3input_size = 784latent_size = 256device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])train_dateset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(train_dateset, batch_size=batch_size, shuffle=True)model = VAE(input_size, latent_size).to(device)optimizer = optim.Adam(model.parameters(), lr=learning_rate)for epoch in range(epochs):model.train()train_loss = 0for batch_idx, (data, target) in enumerate(train_loader):data = data.to(device)data = data.view(-1,input_size)predict ,mu, logvar = model(data)loss = loss_function(predict, data, mu, logvar)train_loss += loss.item()optimizer.zero_grad()loss.backward()optimizer.step()train_loss =train_loss / len(train_loader)print('Epoch [{}/{}], Loss: {:.2f}]'.format(epoch + 1, epochs, train_loss))if (epoch+1) % sample_interval == 0:torch.save(model.state_dict(), f'./VAE{epoch+1}.pth')model.eval()with torch.no_grad():pic_num=10sample = torch.randn(pic_num, latent_size).to(device)sample_img = model.decode(sample)save_image(sample_img.view(pic_num,1,28,28), './sample'+str(pic_num)+'.png' , nrow = int(pic_num/2))