从一到无穷大 #51:突破阿姆达尔定律:COZ因果剖析与串行优化八法
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 串行优化的原则和方法
- COZ
- 结束语
引言
本来这周末打算看下Fuzzing Test相关的点,但是在简单浏览了USENIX ATC 2024 的WingFuzz后,发觉需要写一点代码来验证一些想法,我并不是排斥去做一个小的原型,只是恰逢关键时间节点,整个人懒洋洋的,实在是不想动脑子,其次工作中遇到了一些代码上难解的问题,整个人也并不想在解决工作问题前浪费过多心力,遂选择了SOSP2015 COZ: Finding Code that Counts with Causal Profiling 和 OSDI2025 Principles and Methodologies
for Serial Performance Optimization两篇优化相关的论文放松下疲惫的大脑。
其实算着时间今天是完不成这篇随笔的,因为今天下午六点组了去深圳湾踢球的局,回家不知道是什么时候了,可惜又逢暴雨天,也正好是给了我机会完成这篇文章。
也不知是不是真的懈怠,写完上面这句就去小房间刷短视频了,随着女朋友奶声奶气的“诶呀,现在家里还有一个人在学习,不要吵”,哈哈哈,好吧,还是写完这篇文章再去刷短视频吧。
性能优化长久以往的“标准范式”便是基于oprofile, perf, gprof 生成火焰图,然后基于开发人员对于代码的熟练程度,领域知识与创造性,给出性能优化的方法,然后实施性能优化,检查是否符合预期,循环往复。
这里面有几个问题,基于工具找到热点后,修复是否可以判断可以真的提升性能?优化单个函数,操作对于整体执行的优化有多少(瓶颈转移)?优化本身除了基于工程师的创造力是否有通用模版可以使用?
上述问题的答案都是:是
设想未来整个优化流程——从性能监测,解决方案设计,代码生成,性能评估——都将实现自动化。
- Continuous Profiling + LLM:自动性能瓶颈发现,生成采样范围
- COZ:确定热点优化对于全局的影响,找到有效的优化点
- LLM + sysGPT + Prompt:分析代码给出现有的实现方式,给出串行代码性能优化建议,并生成详细的Prompt
- Claude-4-sonnet:高质量代码生成
以华为的CodeArts Doer为例,其实现了六个Agent,覆盖了软件周期的全流程:
- 团队助手Agent(Timmy):定义项目目标,分解任务为“前端开发”和“后端开发”。
- 产品助手Agent(Pony):输入需求“开发一个用户登录页面”,生成需求文档。
- 开发助手Agent(David):在IDE中输入“用户登录页面代码”,生成HTML和JavaScript代码。
- 测试助手Agent(Cindy):输入测试需求“测试用户登录功能”,生成测试用例并执行测试。
- Committer助手Agent(Oliver):提交代码前,进行代码质量检查,确保代码符合规范。
- 项目管理与监控Agent(Mike):跟踪项目进度,监控项目风险。
基础理论已经具备,按照这个思路,后续性能优化Agent,监控Agent(告警智能分析,也会衍生出对底层监控基础设施的更高要求)也会如雨后春笋般涌现。
确实只会代码的初级工程师存在的必要被大幅度降低了。
串行优化的原则和方法
根据阿姆达尔定律(Amdahl’s law )[5],一个程序的性能最终受限于其必须串行执行的部分。
尽管现在有很多并行计算技术,但优化串行任务仍然是实现显著性能提升的关键。然而,性能优化的过程往往依赖于工程师的直觉和个人经验,缺乏一套系统化的理论和方法来指导实践
提升顺序工作负载的系统性能可以看做:优化任务序列SnS_nSn,以最终减少运行时间F(Sn)F(S_n)F(Sn)。这样来看的话有三种策略性方法:
- 移除某个任务
- 序列中的任务为更快的实现
- 对任务重新排序
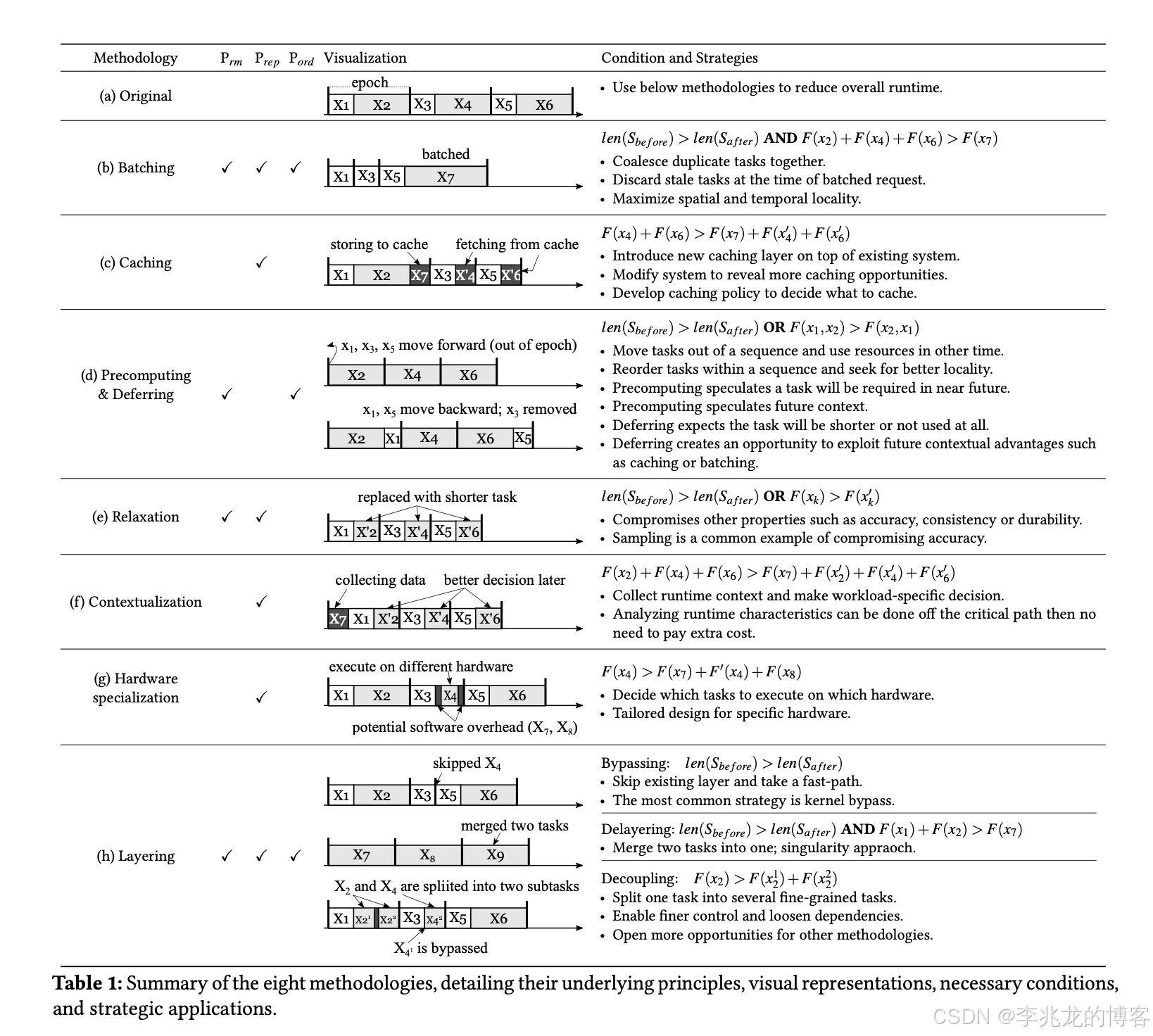
论文对过去十年OSDI和SOSP发表的477篇文章执行分类,提炼其优化成果,结果表示下面八种思路概括了所有的优化方式:
- batching
- caching
- precomputing
- defering
- relaxation
- contextualization
- hard-ware specialization
- layering:这个概念比较泛,Bypassing,Delayering,Decoupling都被归类到这一类中
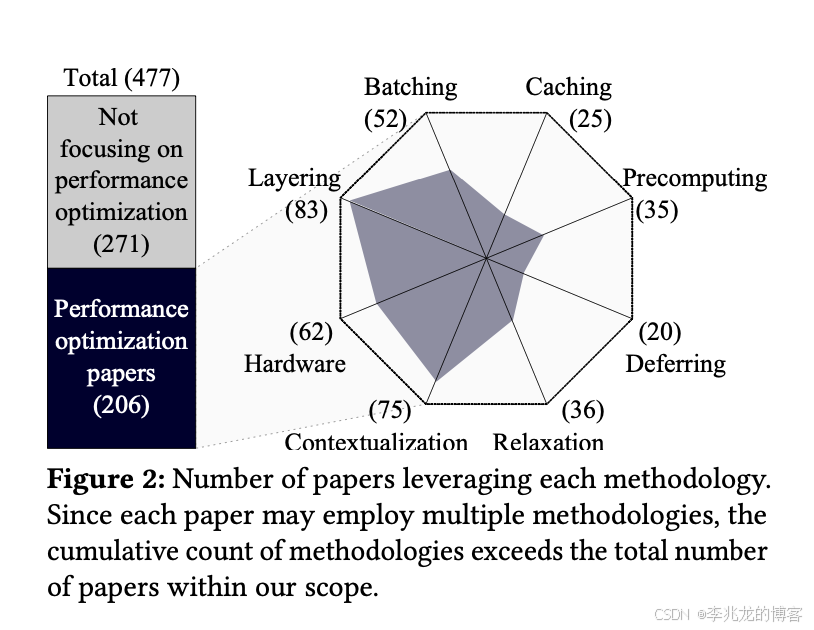
271篇文章不涉及顺序性能优化,剩下的优化方案都可以被归类到八种方法中来。
仔细一想我们团队这些年来做的优化,确实都可以被归类进来,这事实上给了我们在做性能优化时一个方向,比如现在我们做了哪些事情,如果还有没有命中这八种中的某一种,就可以往上靠下。
论文中其实也是这个思路,总结了2013-2022的全部论文,对GPT-4o做了微调,称为sysGPT。

COZ
SOSP2015的最佳论文奖,其对于分析过程称为Causal Profiling,羡慕人家的造词能力。

其关键洞察是现有的性能分析工具存在弊端:
- 误导性指示:某段代码执行时间长,并不意味着优化它能提升整体性能。例如,在文件下载时显示加载动画的代码可能与下载代码耗时相近,但优化加载动画对整体执行时间无影响。
- 并行程序盲区:在多线程程序中,传统工具难以识别关键路径。如图 1 所示的多线程程序中,函数a()和b()分别耗时 6.7 秒和 6.4 秒,传统工具(如 gprof)会报告两者占比相近(55.20% 和 45.19%),但实际上完全优化a()仅能提升 4.5% 性能(因b()成为新瓶颈),优化b()则无效果。
- 无法量化优化潜力:传统工具仅报告现状,无法预测优化某段代码的具体效果,开发者需依赖自身对程序的理解推测
不妨我们自己先想想,如何衡量优化了一段代码后全局性能是否有提升呢?
- 很显然代码必须要跑起来,不然没法衡量对于全局的影响;
- 其次当前代码还没实现加速,自然没法知道加速后对于其他代码的影响
- 那么当前代码的时延是固定的,那么其他代码执行的慢一点就相对快了,就可以达到这个效果
- 使用Ptrace监控进程,统计到这一段代码的执行数N和执行时间T,NT就是这段代码的总执行时间,那么其他代码只要总体慢个NT*0.5,那么就相当于这段代码加速了50%了
- 最简单的思路就是触发指定代码段的时候其他线程就sleep,但是可能会触发非常多次,这就导致其他线程要频繁sleep
- 如果能采样,把N次执行合并成一次Sleep让其他线程执行就好了
以上就是论文的核心Virtual Speedup




- n是代码的执行总数
- P事采样周期
- t是一次的执行时间
- s是采样到需要加速的次数(其他线程sleep)
- 最终△t就是实际加速的比例,与P有关,d是一次加速的时间,所以如果想要加速25%,就插入一个采样周期四分之一的时延
这个公式非常重要。
我简单玩了下COZ这个项目,只能说年老失修,主代码已经两三年没动过了,甚至于代码分析的页面也会直接跳转到github首页。
公司的开发机上并没有现成的包,好在整个项目并不难部署,web的部署也比较简单,就是没有教程,我解决以后顺便回馈社区了[7]:

cd viewer && python3 -m http.server 8080 部署COZ web的方式
./coz run — ./benchmarks/sqlite-modified/sqlite-bench-modified
可以看到还是可以比较清晰的看出应该优化哪些代码的,但是这个思路在大型项目中是否有效我持怀疑态度,因为线程太多了,引用各种各样的三方库,有着各种各样的线程管理,这里如果可以分析出哪些现成线程终止有影响,哪些线程终止没有影响就好了,但是现阶段比较像玩具,无法在工业界大规模使用,也好理解,毕竟是学术成果不是工业界验证多年的。
结束语
感叹我们正处于巨大的变革当中,奇点的到来也并不温和,自ChatGPT发布仅三年时间,行业的发展已经是沧海桑田,但好在基础架构还是足够稳健,混口饭吃短时间看倒不是问题。
参考:
- CodeArts Doer 智能助手
- AI Coding 又进化了!王炸!
- SOSP2015 COZ: Finding Code that Counts with Causal Profiling
- OSDI2025 Principles and Methodologies for Serial Performance Optimization
- 阿姆达尔定律
- plasma-umass coz
- cos issue 255