使用DrissionPage实现xhs笔记自动翻页并爬取笔记视频、图片
使用DrissionPage实现xhs笔记自动翻页并爬取笔记视频、图片
声明:
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请私信作者立即删除!
- 近期小红书xs又更新了,刚好最近需要爬取某博主下的笔记信息,时间比较仓促,于是使用拽神来实现数据爬取的目的
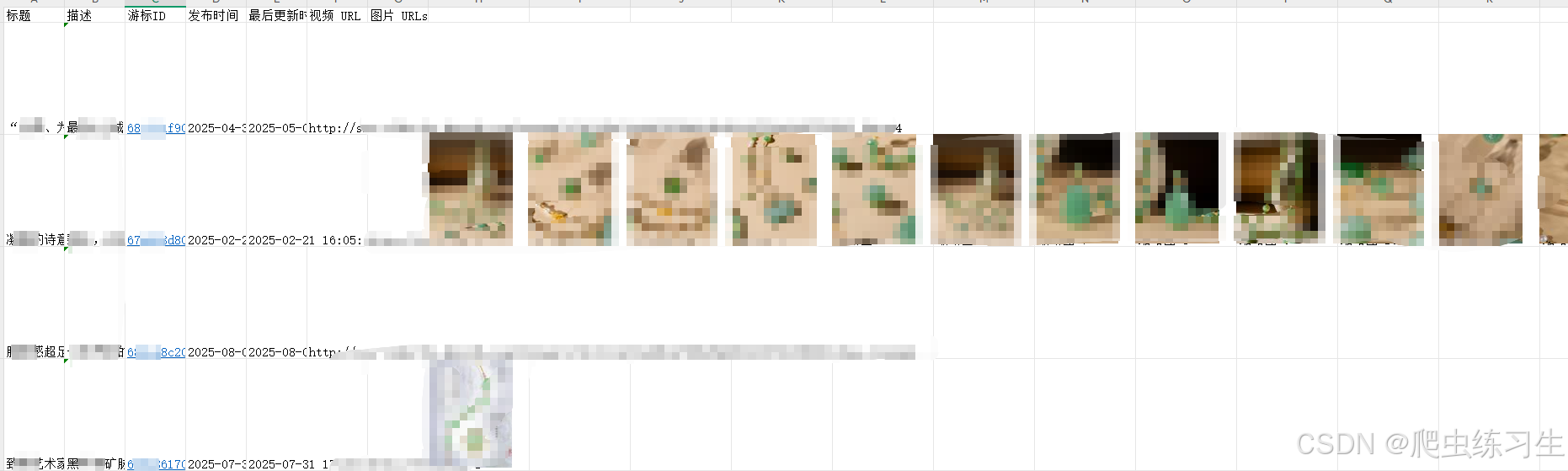
- 爬取数据效果图如下:
爬取标题、描述、发布时间、最后更新时间、视频以及图片
图片需要保持在对应文章行中,排在最后列,并且视频和图片需要下载到本地,在游标ID列上做超链接,点击可以跳转对应的图片或视频
话不多说,开干
首先我们需要想一下,如果不通过代码,我们平常从网站上获取这些信息,实现我们的数据需求,都需要哪些操作?
- 打开目标网站,登录
- 登录后查找指定博主,进入主页
- 点击文章,进入详情界面,可以获取标题、描述、发布时间、视频或图片等信息
- 关闭上一个文章界面,继续点击下一个,重复操作
- 滑