多模态大模型的原理
目录
- 引言
- 一、什么是多模态大模型
- 二、多模态大模型的原理
- 三、多模态经典论文
- 四、多模态模型有哪些
引言
近期在重点攻坚多模态大模型的相关应用,诸如AIGC 视频生成大模型的调研。首先我们会先关心多模态大模型的实现原理是什么、它和自然语言文本大模型NLP的区别是什么、什么样的模型称为多模态、市面上的多模态大模型有哪些。
通过本文大家能对多模态模型的原理有所感知,理解与文本模型的区别。
多模态模型通过整合多种数据模态(如文本、图像、音频、视频等),实现跨模态的理解与生成,其核心原理是将异构数据映射到统一语义空间并进行联合推理。

一、什么是多模态大模型
多模态大模型的核心目标就是让模型能够理解、关联并生成来自多种不同模态(如文本、图像、音频、视频等)的信息,模仿人类通过多种感官综合理解世界的方式。
通俗的理解就是,比如“狗”,它可以分别用 图片、文字、视频、音频(叫声)来表达。这些不同的形态就是 多模态。一个模型能同时处理不同模态之间的内容理解或生成,就是多模态。
比如Bert模型就不属于多模态,它只处理文本。我们之前介绍过的文章《通俗理解CLIP模型如何实现图搜图乃至文搜图》中的图文匹配模型 - - CLIP模型就是典型的多模态模型。文中介绍的原理 - - 模态对齐和对比学习也正是理解多模态模型原理的核心。
下文我们来进一步详细了解多模态大模型的原理。
二、多模态大模型的原理
以下是其核心原理和关键技术的拆解:
- 核心思想:统一表示与对齐
- 核心挑战: 不同模态的数据天然具有不同的结构和特征(文本是离散符号序列,图像是像素网格,音频是时间序列波形)。如何让模型理解它们之间的关联?
- 解决方案: 将不同模态的数据映射到一个共享的语义空间或统一的表示空间。
- 统一编码: 模型学习将不同模态的输入(如图片、文字、声音)转换成具有相似语义含义的向量表示。例如,“狗”这个词的向量表示,和一张狗图片的向量表示,以及狗叫声的向量表示,在语义空间里应该非常接近。
- 模态对齐: 通过训练数据(尤其是成对的多模态数据,如“图片-描述文本”、“视频-字幕”、“音频-文字记录”),模型学习到不同模态之间元素的对应关系。例如,图像中的某个区域对应描述文本中的某个词。
我们回顾前面的文章中对CLIP模型算法原理的解释:
模型的目标是将匹配的图像-文本对在语义空间中拉近,而将不匹配的图像-文本对推远。模型通过对比学习进行预训练,这样我们就能得到一个能表示内容向量的模型。之后,图像和文本就映射到了同一语义空间,使得图像和文本可以直接进行相似性匹配,从而也实现了零样本分类。
CLIP论文:Learning Transferable Visual Models From Natural Language Supervision
- 核心架构:Transformer 的扩展与融合
- 基石:Transformer: 如同单模态大模型(如GPT、BERT),Transformer的自注意力机制是多模态大模型的基础架构。它能有效处理序列数据,并捕捉长距离依赖关系。
- 模态融合策略: Transformer如何同时处理不同模态?主要有几种融合方式:
- 早期融合(输入层融合):
- 将不同模态的原始或浅层特征(如图像块嵌入、词嵌入)拼接或相加在一起,形成一个混合序列输入给一个共享的Transformer编码器。
- 优点: 简单直接,允许模态在很早期就交互。
- 缺点: 不同模态特征维度、语义级别可能差异很大,直接融合效果不佳;序列可能变得非常长(如图像块很多),计算开销大。
- 例子: 一些早期的Vision-Language模型。
- 中期融合(编码器层融合 / 交叉注意力):
- 主流方式! 每个模态先通过各自独立的编码器(如ViT处理图像,BERT处理文本)提取高级特征。
- 然后,在Transformer的中间层引入交叉注意力机制。
- 交叉注意力: 让一个模态(Query)去“注意”另一个模态(Key, Value)的信息。例如,在生成图像描述时,文本解码器在生成某个词时可以“注意”图像编码器输出的相关视觉特征区域。
- 优点: 灵活性高,允许模态间进行细粒度的、有选择的交互;能更好地捕捉复杂关系;各模态编码器可以单独预训练。
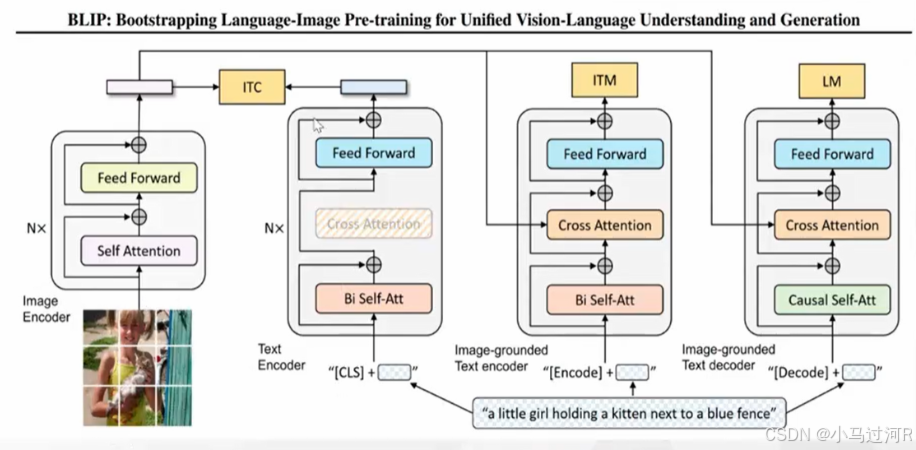
- 例子: Flamingo, BLIP, LLaVA, MiniGPT-4 等。CLIP虽无显式交叉注意力层,但其对比学习目标隐含地实现了模态对齐(可视为一种特殊的融合)。
- 晚期融合(输出层融合):
- 不同模态完全独立处理,各自得到最终表示(如分类结果、嵌入向量)。
- 在最后阶段(如预测层或决策层)才将这些独立的表示拼接、平均、投票或通过一个小型网络进行融合。
- 优点: 结构简单,易于实现。
- 缺点: 模态间缺乏深层交互,难以捕捉复杂依赖关系。
- 例子: 一些简单的多模态分类模型。
- 早期融合(输入层融合):
-
关键训练技术:
- 大规模多模态预训练: 这是多模态大模型能力的基石。在海量的、未标注或弱标注(如网络爬取的图片-Alt文本对、视频-字幕对)数据上进行训练。
- 预训练任务(目标函数): 设计任务迫使模型学习模态对齐和统一表示:
- 掩码建模的扩展:
- 掩码语言建模: 随机遮盖文本部分单词,让模型根据上下文(文本+图像/音频)预测被遮盖的词。
- 掩码图像建模: 随机遮盖图像块,让模型根据剩余图像块和文本预测被遮盖的块。
- 掩码跨模态建模: 同时遮盖部分文本和部分图像区域,让模型进行联合预测。
- 图文/跨模态匹配:
- 对比学习: 极其重要!(如CLIP的核心)。模型学习判断一个图像-文本对是否匹配(正样本)还是不匹配(负样本)。目标是将匹配对的嵌入拉近,不匹配对的嵌入推远。这直接学习到跨模态的语义对齐。
- 匹配分类: 直接训练模型判断给定的图像-文本对是否匹配。
- 图文描述/生成:
- 图像描述: 给定图像,生成描述文本(自回归或非自回归)。
- 文本到图像生成: 给定文本描述,生成图像(通常是扩散模型或GAN,但多模态大模型可以为其提供文本理解)。
- 视觉问答: 给定图像和问题,生成答案(文本)。
- 基于图像的对话: 围绕图像进行多轮对话。
- 跨模态检索: 给定一个模态的查询(如图像),检索另一个模态的相关项(如文本描述)。
- 掩码建模的扩展:
-
统一表示的实现:嵌入与投影
- 模态特定编码器: 每个模态有自己的编码器(如ViT/BEiT处理图像,BERT/RoBERTa处理文本,Whisper处理音频),负责将原始数据转换为初始的特征向量序列。
- 投影层: 通常在每个模态编码器之后,会有一个(或多个)线性层或小型神经网络(投影层),将这些模态特定的特征向量投影到共享的语义空间。这个投影层在对比学习等任务中至关重要,确保不同模态的向量在同一个空间内可比。
-
涌现能力与推理:
- 通过在大规模多模态数据上的预训练,模型不仅能完成预训练任务,还能展现出强大的零样本和少样本能力。例如:
- 给CLIP一张它从未见过的类别图片和一组文本标签,它能选出最匹配的标签(零样本图像分类)。
- 给LLaVA或Gemini一张图和一个复杂问题,它能结合图文信息进行推理并回答。
- 这种能力源于模型在预训练过程中学习到的通用语义表示和跨模态关联知识。
- 通过在大规模多模态数据上的预训练,模型不仅能完成预训练任务,还能展现出强大的零样本和少样本能力。例如:
总结原理流程:
- 输入处理: 不同模态数据通过各自专用的编码器(ViT, BERT等)转换为特征向量序列。
- 投影对齐: 特征向量序列通过投影层映射到共享的语义空间。
- 模态融合与交互: (通常通过带交叉注意力的Transformer架构)让不同模态的特征在共享空间内进行深度交互和信息互补。模型学习不同模态元素间的对齐关系(如词-图块)。
- 大规模预训练: 使用各种自监督任务(掩码建模、对比学习、生成任务等)在海量数据上训练模型,核心目标是学习统一的语义表示和跨模态对齐。
- 输出/任务适应: 预训练好的模型可以通过微调或提示(Prompting)适应各种下游任务(VQA, 图像描述, 图文检索, 多模态对话, 文本生成图等)。强大的预训练模型甚至能直接零样本或少样本执行新任务。
面临的挑战:
- 数据饥渴与质量: 需要海量高质量、对齐的多模态数据,获取和清洗成本高。
- 模态不平衡与缺失: 某些模态(如3D、触觉)数据稀缺;处理模态缺失(如只有图没有文)的情况。
- 计算成本: 训练和推理极其耗费算力。
- 模型偏见与安全: 训练数据中的偏见会放大;生成有害或误导性多模态内容的风险更高。
- 可解释性: 理解模型内部如何关联不同模态信息仍然困难。
- 长视频/复杂场景理解: 处理长时序依赖和复杂场景交互仍有难度。
多模态大模型是AI走向更通用智能的关键一步,其原理核心在于利用Transformer的强大表示能力和自注意力机制,结合精心设计的预训练任务(尤其是对比学习),将异构的多模态数据对齐到一个共享的语义空间中,从而实现跨模态的理解、推理与生成。
三、多模态经典论文
| UNITER | Universal Image-Text Representations | GitHub - ChenRocks/UNITER: Research code for ECCV 2020 paper “UNITER: UNiversal Image-TExt Representation Learning” |
| CLIP | Learning Transferable Visual Models From Natural Language Supervision | GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image |
| ALBEF | Align before Fuse: Vision and Language Representation Learning with Momentum Distillation | GitHub - salesforce/ALBEF: Code for ALBEF: a new vision-language pre-training method |
| VILT | ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision | GitHub - dandelin/ViLT: Code for the ICML 2021 (long talk) paper: “ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision” |
| VLMO | VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts | https://link.zhihu.com/?target=https%3A//github.com/microsoft/unilm/tree/master/vlmo |
| BLIP | BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | https://link.zhihu.com/?target=https%3A//github.com/salesforce/BLIP |
| BeitV3 | Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks | https://link.zhihu.com/?target=https%3A//github.com/microsoft/unilm/tree/master/beit3 |
| Beit | BEIT: BERT Pre-Training of Image Transformers | https://link.zhihu.com/?target=https%3A//github.com/microsoft/unilm/tree/master/beit |
| MAE | Masked Autoencoders Are Scalable Vision Learners | https://link.zhihu.com/?target=https%3A//github.com/facebookresearch/mae/tree/main |
| SD | High-Resolution Image Synthesis with Latent Diffusion Models | https://link.zhihu.com/?target=https%3A//github.com/CompVis/latent-diffusion |
| DIT | Scalable Diffusion Models with Transformers | https://link.zhihu.com/?target=https%3A//github.com/facebookresearch/DiT |
四、多模态模型有哪些
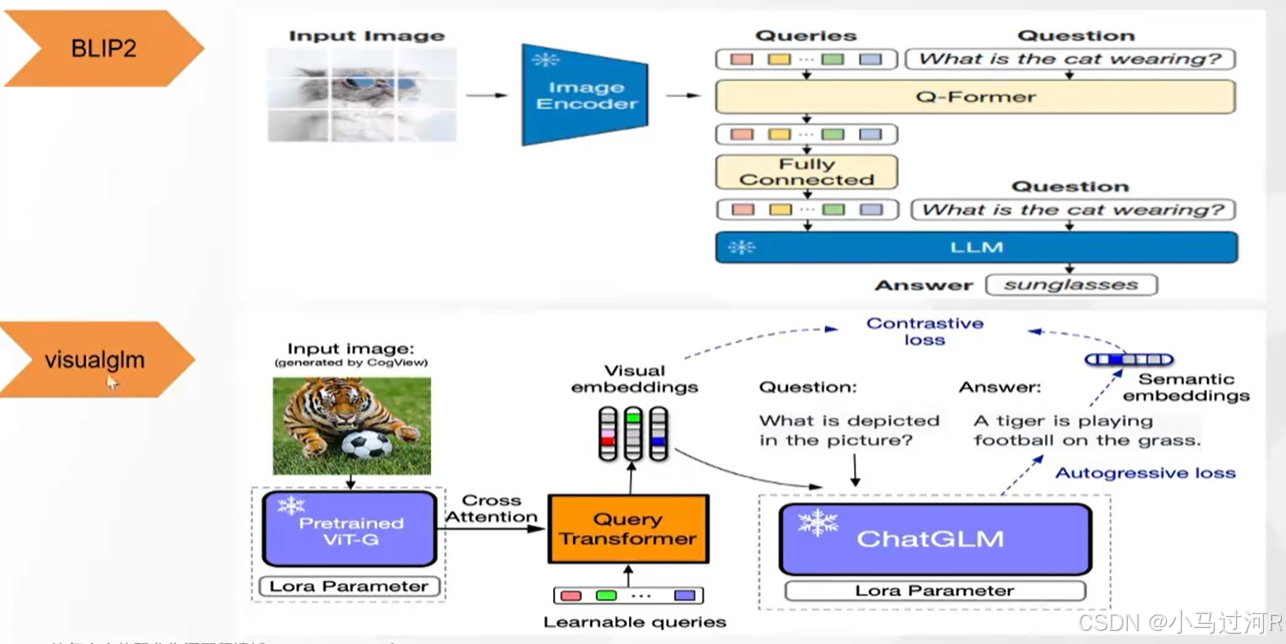
这里列出了一些市面上公开的信息供参考,诸如CLIP(图文匹配模型)、BLIP(一个模型解决了两个问题,图文匹配和文字生成)、BLIP2(图文问答,理解图片),DALL-E(生成式模型,文生图)、可灵(生成视频)、即梦(生成视频)、混元(生成视频)等等,当然还有很多模型就无法一一列出了。
🔍 以下是2021年CLIP发布后具有代表性的多模态模型列表:
| 模型名称 | 提出机构/时间 | 核心创新点 | 典型应用场景 | 技术特点对比(区别于CLIP) |
|---|---|---|---|---|
| FLIP | Meta/2022 | 融合图像注释信息(目标检测框、属性标签)增强图文对齐能力 | 复杂视觉语言任务 | 引入结构化视觉标注,细粒度理解更优 |
| SigLIP | Google/2023 | 建立"签名"空间实现跨模态特征匹配,采用新型相似度计算方式 | 跨模态检索、多语言场景 | 计算效率提升30%,支持低资源语言 |
| ImageBind | Meta/2023 | 以图像为桥梁连接6种模态数据(深度图、音频等)实现跨模态语义传递 | 多传感器数据融合 | 模态扩展性突破,支持非图文模态对齐 |
| 4M-21 | EPFL/2023 | 多模态掩码预训练框架,支持图像/文本/3D点云等7种模态联合建模 | 工业检测、自动驾驶 | 首个通用模态掩码预训练架构 |
| Flamingo | DeepMind/2022 | 统一Transformer处理交错图文序列,实现上下文感知的多模态对话 | 交互式AI助手、教育场景 | 序列建模能力突出,支持长上下文理解 |
| BLIP | Salesforce/2022 | 提出噪声数据过滤机制及多任务预训练框架,提升图文匹配鲁棒性 | 图文生成、视觉问答 | 首创Captioning与Filtering联合优化机制 |
| LLaVA系列 | 威斯康星大学/2023 | 端到端视觉指令微调框架,实现文本引导的细粒度视觉理解 | 多模态对话、场景分析 | 首次实现视觉-语言指令对齐的通用模型架构 |
| QWen-VL | 阿里云/2023 | 融合视觉定位与细粒度理解的多任务架构,支持中文开放域视觉推理 | 中文图文交互、文档理解 | 优化中文开放域能力,支持超长上下文输入 |
| GroundingDINO | 清华&深度求索/2023 | 联合图文编码器实现开放世界目标检测,无需检测框标注 | 工业质检、开放环境感知 | 零样本检测能力突破,支持自然语言定位提示 |
| CLIP-VG | 中科院/2024 | 通过自步课程学习实现CLIP在视觉定位任务的迁移,伪标签可靠性提升14.8% | 自动驾驶、机器人导航 | 保持CLIP零样本能力,新增定位功能 |
| EVA-CLIP | 智谱AI/2024 | 中文优化版CLIP,中文图文匹配准确率提升22% | 中文互联网内容理解 | 专为中文语义空间设计 |
| Kosmos-1 | 微软/2023 | 统一文本/图像/音频的模态感知框架,支持思维链推理 | 通用人工智能探索 | 实现跨模态上下文学习能力 |
| Kosmos-2.5 | 微软/2024 | 扩展至文本+图像+语音+视频四模态,引入时空建模模块 | 跨媒体内容生成、虚实交互 | 支持视频时序理解与生成 |
🔍 多模态模型全景对比表(2023-2025)
| 模型名称 | 推出时间 | 开发机构 | 核心创新 | 关键技术 | 开源情况 | 典型应用场景 |
|---|---|---|---|---|---|---|
| MaPLe | 2023年 | 多伦多大学 | 分层多模态提示学习,提升跨域泛化能力 | 视觉-文本提示耦合机制 | ✅ 开源 | 细粒度图像分类、跨域迁移 |
| Step-3 | 2025年7月 | 阶跃星辰 | MoE架构(321B总参数/38B激活参数),动态路由优化视觉-语言专家模块 | MFA注意力机制、AFD解耦系统 | ✅ 全开源 | 工业质检、医疗影像诊断 |
| Lumina-DiMOO | 2025年7月 | 华为昇腾+上海AI Lab | 全球首个离散扩散统一架构,替代传统扩散模型,采样速度提升10倍 | 昇腾MindSpeed MM套件、流匹配优化 | ✅ 训练代码开源 | 文生视频、跨模态内容创作 |
| Gemma 3 | 2025年3月 | Google DeepMind | 轻量级多模态(1B-27B),5:1本地-全局注意力架构,内存消耗降75% | Pan & Scan图像裁剪、QK-norm归一化 | ✅ 开源 | 移动端图文理解、长文档分析 |
| Skywork UniPic | 2025年7月 | 昆仑万维 | 自回归统一框架,深度融合图像理解、生成与编辑 | MAR编码器+SigLIP2双主干 | ✅ 开源 | 创意设计、图像修复 |
| Janus-Pro | 2025年1月 | DeepSeek | 双编码器架构(SigLIP理解+VQ生成),三段式高效训练(弃用ImageNet) | 任务感知注意力头、合成美学数据 | ✅ 开源 | 多模态问答、可控图像生成 |
| IDEA | 2025年8月 | IDEA研究院 | 无训练跨模态适配器,增强CLIP细粒度特征捕捉 | 图像描述增强、轻量投影层(T-IDEA) | ✅ 开源 | 少样本分类、边缘设备部署 |
| M-CLIP | 2024年初 | 腾讯 | 多任务时空适配器(TED-Adapter + 文本Adapter) | 视频帧间差异建模、短文本语义优化 | ❌ 未开源 | 视频动作识别、体育分析 |
| BLIP3-o | 2025年5月 | Salesforce | 理解(自回归)+生成(扩散)统一,CLIP特征替代像素生成 | Flow Matching、顺序训练策略 | ✅ 全开源 | 医疗影像分析、学术图表生成 |
| OpenVision | 2025年8月 | OpenVision 社区 | 全开源视觉编码器家族,渐进分辨率训练(84→384px) | Recap-DataComp-1B数据集 | ✅ 全开源 | 无人机识别、学术研究平台 |
多模态大模型原理的介绍先告一段落了,接下来小马会尝试AIGC的一些模型选择和技巧经验分享,欢迎交流。