Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(含代码实现)
论文阅读笔记:[Swin Transformer: Hierarchical Vision Transformer using Shifted Windows]
状态: 🟢 已精读
1. 元数据 (Metadata)
| 条目 | 内容 |
|---|---|
| 年份 | 2021 |
| 论文链接 | https://arxiv.org/abs/2103.14030 |
| 代码链接 | https://github. com/microsoft/Swin-Transformer (官方实现) https://github. com/microsoft/Swin-Transformer (复现) |
| 我的标签 | 多模态基础 计算机视觉 |
2. 摘要与核心问题 (Abstract & Core Problem)
本文提出了一种基于ViT改进的Transformer,称为Swin Transformer,其可以和ViT类似将Transformer从语言领域调整为有差异的视觉领域。为了解决这些差异,本文提出了一种用Shifted Window计算的分层Transfomer,Shifted Window方案通过将自注意力计算限制在不重叠的局部窗口(W-MSA),同时还允许跨窗口连接(SW-MSA),从而带来更高的效率。
这种分层结构具有在各种尺度上建模的灵活性,并且具有相对于图像大小的线性计算复杂性。
Swin Transformer的这些特性使其在广泛的视觉任务兼容,
- 图像分类(ImageNet-1K上的87.3 top-1精度)和密集预测任务,
- 目标检测(COCO testdev上的58.7框AP和51.1掩码AP)
- 语义分割(ADE20K val上的53.5 mIoU)。
其性能以显著优势超越之前的先进模型:在 COCO 上分别提升 +2.7% 边界框 AP 和 +2.6% 掩码 AP,在 ADE20K 上提升 +3.2% mIoU,彰显了基于 Transformer 的模型作为视觉骨干网络的潜力。分层设计和移位窗口方法也被证明对全 MLP 架构有益。
- 论文要解决什么问题?
- Transformer架构在视觉任务中的计算效率问题,故提出一个W-MSA的一个计算方式。
MHA计算复杂度与图像大小的平方成正比。而W-MSA计算复杂度成线性大小。 - 标准Vision Transformer缺乏层次化结构
原始的ViT是一种“平坦”结构,全程使用单一尺度的图像块,无法像卷积神经网络(CNN)那样生成多尺度的特征金字塔。这种金字塔结构对于处理图像尺度变化至关重要。因此,论文需要为Transformer引入这种分层设计。
3.通用的视觉骨干网络
论文旨在提出一个可以像ResNet那样,作为各种视觉任务(从图像分类到密集预测)统一骨干网络的Transformer架构。它证明其在跨越分类、检测、分割等多种任务上均能实现卓越的性能,而不仅仅是擅长其中某一项。
核心主张或贡献是什么?
本文提出一种层次化的Transformer架构和一种计算量优化的WS-MSA
- 分层化Transformer 架构
设计了像 CNN 一样具有多尺度特征金字塔的 Transformer 结构。通过合并图像块,模型在深层生成分辨率更低、感受野更大的特征图。

- W-MSA机制
W-MSA通过将自注意力计算限制在局部非重叠窗口内,将计算复杂度从标准Transformer的二次降低至线性,解决了Transformer处理高分辨率图像时的计算瓶颈。 - WS-MSA机制
为突破局部窗口无信息交互的限制,本文引入了移位窗口注意力(SW-MSA)。该机制与常规的窗口注意力(W-MSA)在连续Transformer块中交替使用,通过在空间维度上位移窗口边界,在不增加计算复杂度的前提下实现了跨窗口的信息交互,从而获得了强大的全局建模能力。
3. 背景知识 (Background)
前置知识/术语:
- CNN and variants (VGG, ResNet): 理解卷积神经网络、层次化特征金字塔、感受野等基本概念是基础,因为Swin Transformer的目标就是替代它们作为通用骨干网络。
- Self-attention/Transformers: 标准Transformer编码器的结构,特别是多头自注意力机制 的计算原理和其O(n²)的计算复杂度。
- Vision Transformer (ViT): 作为将纯Transformer应用于视觉的开创性工作,必须了解其将图像分割为图像块、使用位置编码、以及缺乏归纳偏置等特点。
- 密集预测任务: 如目标检测和语义分割,这类任务需要对每个像素进行预测,通常需要高分辨率、多尺度的特征图。
相关工作简要回顾:
(论文中提到的相关工作是哪些?它们有什么局限性?)
Vision Transformer (ViT): 将图像分割为固定大小的块,线性嵌入后直接输入标准Transformer编码器。在大规模数据集上预训练后,在图像分类任务上展现出强大性能。
- 局限性:
- 计算复杂度高: 自注意力机制相对于图像块数量的平方级复杂度,使其难以处理需要高分辨率特征图的密集预测任务(如检测、分割)。
- 缺乏层次化结构: 全程使用单一尺度的图像块,无法像CNN一样生成多尺度的特征金字塔,这限制了其处理多尺度视觉实体和直接适配现有任务框架的能力。
- 需要大规模数据预训练: 由于缺少CNN固有的归纳偏置(如平移不变性、局部性),对数据量的需求更大。
4. 方法/模型 (Methodology/Model)
4.1 总体架构
Swin Transformer体系结构的概述如图3所示,它说明了Tiny版本。

Swin Transformer 通过多个阶段逐步下采样,同时增加通道维度,以构建一个金字塔式的特征层次。
具体流程如下:
- 首先,输入图像经由 Patch Partition 模块被划分为一系列不重叠的 4×44 \times 44×4 图像块,每个块被展平并视为一个Token。由此,每个Token的原始特征维度为 4×4×3=484 \times 4 \times 3 = 484×4×3=48,即对应块内所有像素RGB值的拼接。随后,通过一个线性嵌入层将这些原始像素特征投影到一个预设的、维度为 CCC 的隐空间,以进行后续的Transformer处理。
# Patch Parition
def to_2tuple(x):"""将输入转换为二维元组"""if isinstance(x, (tuple, list)):if len(x) == 2:return tuple(x)elif len(x) == 1:return (x[0], x[0])else:# 如果是整数、浮点数等标量return (x, x)# Patch Partition
class PatchPartition(nn.Module):def __init__(self,in_channels = 3,patch_size = 4,embed_dim = 96,norm_layer = None):super().__init__()patch_size = to_2tuple(patch_size)self.patch_size = patch_sizeself.embed_dim = embed_dimself.conv = nn.Conv2d(in_channels=in_channels,out_channels=embed_dim,kernel_size= patch_size,stride = patch_size,)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = nn.Identity()def forward(self, x):_, _, H, W = x.size()if W % self.patch_size[1] != 0:# 如果宽度不能被patch宽度整除,需要在右侧填充x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))if H % self.patch_size[0] != 0:# 在底部填充: (0, 0, 0, pad_h)x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))# 可以进行patch 操作了# b c h w -> b e h / p w / px = self.conv(x)Wh, Ww = x.size(2), x.size(3)# b c h w -> b c h*w -> b h*w cx = x.flatten(2).transpose(1, 2)x = self.norm(x)# b h*w c -> b c h*w -> b c h wx = x.transpose(1, 2).view(-1, self.embed_dim, Wh, Ww)# b h* w cx = x.flatten(2).transpose(1, 2)return x
- 层次特征提取及变换
第1阶段:
在获得线性嵌入后的图像块 Token(数量为 H4×W4\frac{H}{4} \times \frac{W}{4}4H×4W)后,模型在此分辨率上应用一系列 Swin Transformer 模块进行特征学习。此阶段与前述的 Patch Partition 和线性嵌入层共同构成 阶段 1,输出特征图形状为 H4×W4×C\frac{H}{4} \times \frac{W}{4} \times C4H×4W×C。
// An highlighted block
var foo = 'bar';
第2阶段
本阶段旨在通过降低分辨率、增加通道数来构建特征金字塔,其核心操作如下:
块合并:将阶段 1 输出特征图中每个 2×22 \times 22×2 的相邻区域进行拼接,使通道数从 CCC 增至 4C4C4C
特征投影:通过线性层将拼接后的特征从 4C4C4C 维投影至 2C2C2C 维,完成下采样与特征压缩
class PatchMerging(nn.Module):r""" Patch Merging Layer.Args:dim (int): Number of input channels.norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x, H, W):"""x: B, H*W, C"""B, L, C = x.shapeassert L == H * W, "input feature has wrong size"x = x.view(B, H, W, C)# padding# 如果输入feature map的H,W不是2的整数倍,需要进行paddingpad_input = (H % 2 == 1) or (W % 2 == 1)if pad_input:# to pad the last 3 dimensions, starting from the last dimension and moving forward.# (C_front, C_back, W_left, W_right, H_top, H_bottom)# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))# x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]x = self.norm(x)x = self.reduction(x) # [B, H/2*W/2, 2*C]return x
特征增强:将处理后的 Token(分辨率为 H8×W8\frac{H}{8} \times \frac{W}{8}8H×8W,维度为 2C2C2C)输入后续 Swin Transformer 块中进行进一步变换与增强
图中下方数字即为将该阶段执行次数
其中1阶段和2, 3,4阶段的区别仅其为 Linear Embedding而2,3,4为Patch Merging
通过以上四个阶段的处理,模型最终生成具有多尺度分辨率的层次化特征表示,其特性与典型卷积网络(如ResNet)的特征图分辨率完全一致。
这一设计使得Swin Transformer能够直接替换现有计算机视觉任务中的主干网络,为各类视觉任务提供强大的特征提取基础。保证该模型的通用性
4.2 Swin Transformer block
Swin Transformer是通过将标准Transformer块中的多头自注意力模块替换为基于Shifted Window的模块构建而成,其他层保持不变。如图3(b)所示,一个Swin Transformer块包含一个基于Shifted Window的多头自注意力模块,其后是一个2层MLP,中间使用GELU非线性激活函数。在每个多头自注意力模块和每个MLP之前都应用层归一化,并在每个模块之后应用残差连接。

4.2.1 Window based Self-Attention(W-MSA)
为解决标准 Transformer 自注意力在视觉任务中的计算瓶颈,文中提出基于非重叠窗口的自注意力计算。该方法将图像均匀划分为多个不重叠的局部窗口,仅在每个窗口内部进行自注意力运算。
假设每个窗口包含 M×MM \times MM×M 个图像块,整张图像包含 h×wh \times wh×w 个图像块,则全局多头自注意力与基于窗口的多头自注意力的计算复杂度分别为:Ω(MSA)=4hwC2+2(hw)2CΩ(W-MSA)=4hwC2+2M2hwC\begin{aligned} \Omega(\text{MSA}) &= 4hwC^2 + 2(hw)^2C \\ \Omega(\text{W-MSA}) &= 4hwC^2 + 2M^2hwC \end{aligned} Ω(MSA)Ω(W-MSA)=4hwC2+2(hw)2C=4hwC2+2M2hwC其中公式(1)的计算复杂度与图像块数量 hwhwhw 呈二次方关系,而公式(2)在窗口大小 MMM 固定时与 hwhwhw 呈线性关系。当 hwhwhw 较大时,全局自注意力计算代价难以承受,而基于窗口的自注意力则具有良好的可扩展性。
4.2.2 Shifted Window based Self-Attention (SW-MSA)
连续块中的移位窗口划分方法:基于窗口的自注意力模块缺乏跨窗口的连接,这限制了其建模能力。为在保持非重叠窗口高效计算的同时引入跨窗口连接,我们提出了一种移位窗口划分方法,该方法在连续的Swin Transformer块中交替使用两种划分配置。如图2所示,第一个模块采用从左上角像素开始的常规窗口划分策略,将8×8特征图均匀划分为4个2×2的窗口(每个窗口大小为4×4)。随后,下一个模块采用的窗口配置相对于前一层进行了偏移,窗口从常规划分位置位移了(⌊M/2⌋, ⌊M/2⌋)个像素。

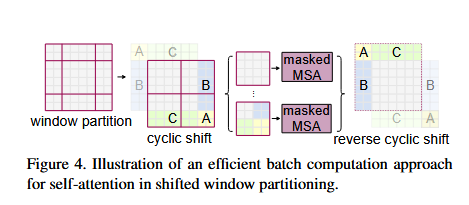
移位窗口划分中自注意力机制的高效批处理
图4展示了移位窗口划分中自注意力机制的高效批处理方法。其中,W-MSA与SW-MSA分别表示采用常规与移位窗口配置的基于窗口的多头自注意力。移位窗口划分通过引入相邻非重叠窗口间的连接,被证实在图像分类、目标检测等任务中具有显著效果。
然而,移位窗口划分会引入窗口数量增加的问题——从常规划分的 ⌈h/M⌉×⌈w/M⌉\lceil h/M \rceil \times \lceil w/M \rceil⌈h/M⌉×⌈w/M⌉ 个窗口变为移位后的 (⌈h/M⌉+1)×(⌈w/M⌉+1)(\lceil h/M \rceil + 1) \times (\lceil w/M \rceil + 1)(⌈h/M⌉+1)×(⌈w/M⌉+1) 个窗口,且部分窗口尺寸小于 M×MM \times MM×M。若采用填充较小窗口至 M×MM \times MM×M 并掩码填充值的原始方案,在常规划分窗口数较少时(如 2×22 \times 22×2)将导致计算量大幅增加(2×2→3×32 \times 2 \rightarrow 3 \times 32×2→3×3,增长至2.25倍)。
为此,我们提出一种向左上方向循环移位的高效批处理方案(图4)。该移位操作使单个批处理窗口可能包含特征图中不相邻的多个子窗口,通过掩码机制将自注意力计算限制在各子窗口内部。此循环移位策略使批处理窗口数量与常规划分情况下保持一致,从而在实现跨窗口连接的同时维持了计算高效性。
以下展示了Swin Transformer的模型参数,分为四中不同规模:Tiny、Small、Base、Larger。

5. 结论
-
主要贡献:
- 提出通用骨干网络:首次证明了纯Transformer架构可以作为计算机视觉的通用骨干网络,在图像分类、目标检测、语义分割等任务上全面超越当时最佳的CNN模型。
- 提出分层架构:设计了层次化的Transformer,能够像CNN一样输出多尺度特征图,使其能够直接兼容于各种密集预测任务。
- 提出高效注意力机制:引入了基于移位窗口的自注意力(SW-MSA),通过局部窗口计算和跨窗口连接,在实现强大建模能力的同时,将计算复杂度从图像尺寸的平方级降至线性级。
-
局限性:
- 论文中并未明确提及模型的主要局限性,但根据其设计可以推断:移位窗口的机制在小窗口尺寸下可能仍无法建立非常长程的依赖关系。
- 相对于极简的ViT,其结构更为复杂,引入了窗口划分、循环移位、掩码等操作。
6. 个人总结
本文中比较创新就是将图像提取多层次信息,图像具有更强的空间冗余性和局部相关性。对于许多视觉任务(例如,识别一张图片中是否包含“猫”),我们并不总是需要建立所有像素之间的全局联系,过度依赖全局注意力会导致大量计算浪费。
Swin Transformer 正是基于这一洞察,在 ViT 的框架上进行改进。它通过引入 局部窗口注意力(W-MSA) 和 移位窗口注意力(SW-MSA) 的交替机制,前者将计算限制在局部窗口内,后者同时巧妙地引入跨窗口连接。这种设计在保留Transformer强大建模能力的前提下,显著降低了计算复杂度,swin-Transformer 成为替代CNN的下一代通用视觉骨干网络。