python:以支持向量机(SVM)为例,通过调整正则化参数C和核函数类型来控制欠拟合和过拟合
应网友伙伴的要求,写一篇文章,介绍如何调整机器学习算法欠拟合与过拟合的。有关欠拟合与过拟合请大家先学习前面的有关博文
python机器学习:评价智能学习算法性能与效果的常见术语:不收敛、过拟合、欠拟合、泛化能力、鲁棒性一句话、一张图给您说明白,机器学习算法搞的明明白白的-CSDN博客文章浏览阅读1.2k次,点赞43次,收藏13次。机器学习中的关键概念解析,理解这些概念有助于优化算法设计和应用效果:不收敛指算法无法找到最优解,表现为损失函数持续波动或发散;欠拟合是模型过于简单,未能捕获数据规律;过拟合则是模型过度记忆训练数据,泛化能力差。泛化能力衡量模型在新数据上的表现,而鲁棒性则评估模型对数据干扰的抵抗能力。提高模型性能需针对不同问题采取相应策略:调整学习率、优化算法、正则化、数据增强等方法可改善不收敛和过拟合问题;增加训练数据、使用交叉验证能提升泛化能力;对抗训练和鲁棒损失函数则有助于增强鲁棒性。https://blog.csdn.net/hlnzxl/article/details/149747294?spm=1001.2014.3001.5501下面开始我们的分享。
目录
一、功能介绍
二、控制欠拟合和过拟合的常用方法
三、程序设计流程及源代码
四、应用建议
一、功能介绍
以支持向量机(SVM)为例,通过调整正则化参数C和核函数类型来控制欠拟合和过拟合,最终达到比较理想的状态。
二、控制欠拟合和过拟合的常用方法
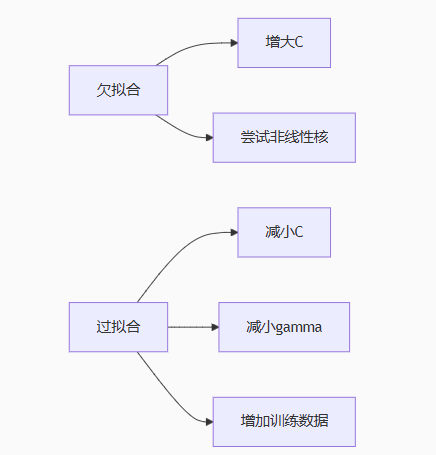
对于支持向量机SVM来说,控制欠拟合和过拟合的常用方法:
1. 正则化参数(如SVM中的C):C越大,模型越复杂,容易过拟合;C越小,模型越简单,容易欠拟合。
2. 核函数的选择:线性核容易欠拟合,高斯核(RBF)容易过拟合(特别是gamma较大时)。
3. 其他:增加数据量、特征选择、交叉验证等。
注意啦,黄金法则:优先使用交叉验证选择C和gamma;从RBF核开始调试(适用大多数场景);
关注测试集表现而非训练集精度。如下图所示。
三、程序设计流程及源代码
程序设计流程:
1. 导入必要的库(numpy, matplotlib, sklearn)
2. 生成模拟数据(使用make_moons,一个非线性数据集)
3. 划分训练集和测试集
4. 定义不同的SVM模型(改变C和核函数)
5. 训练模型并评估在训练集和测试集上的准确率
6. 可视化决策边界
注意,我们创建四个模型,去感受欠拟合与过拟合: a. 线性核,C小(可能欠拟合) b. 线性核,C大(在线性核下可能仍然欠拟合,但会尝试拟合) c. RBF核,C小,gamma默认(可能欠拟合) d. RBF核,C大,gamma较大(可能过拟合)
具体python程序如下,每条语句均有详细的注释,方便伙伴们阅读。程序的运行效果见代码后。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 生成模拟数据:月亮形数据集(非线性问题)
X, y = datasets.make_moons(n_samples=500, noise=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建4种SVM模型对比
models = {# 欠拟合:线性核 + 强正则化 (C小)"Underfitting": svm.SVC(kernel='linear', C=0.01, random_state=42),# 平衡:线性核 + 适度正则化"Balanced_Linear": svm.SVC(kernel='linear', C=1, random_state=42),# 平衡:RBF核 + 适度正则化"Balanced_RBF": svm.SVC(kernel='rbf', C=1, gamma='scale', random_state=42),# 过拟合:RBF核 + 弱正则化 (C大) + 高gamma"Overfitting": svm.SVC(kernel='rbf', C=100, gamma=10, random_state=42)
}# 训练并评估模型
results = {}
for name, model in models.items():model.fit(X_train, y_train) # 训练模型train_acc = accuracy_score(y_train, model.predict(X_train)) # 训练集准确率test_acc = accuracy_score(y_test, model.predict(X_test)) # 测试集准确率results[name] = {"train_acc": train_acc, "test_acc": test_acc, "model": model}# 打印结果
print(f"{'Model':<20} {'Train Acc':<10} {'Test Acc':<10} Gap")
for name, res in results.items():gap = res["train_acc"] - res["test_acc"] # 过拟合指标:训练与测试的差距print(f"{name:<20} {res['train_acc']:.4f} {res['test_acc']:.4f} {gap:.4f}")# 可视化决策边界
def plot_decision_boundary(model, title):plt.figure(figsize=(6, 4))# 生成网格点h = 0.02x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))# 预测网格点类别Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)# 绘制边界和数据点plt.contourf(xx, yy, Z, alpha=0.8)plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k')plt.title(f"{title}\nTrain Acc: {results[title]['train_acc']:.2f}, Test Acc: {results[title]['test_acc']:.2f}")plt.show()# 可视化关键模型
plot_decision_boundary(models["Underfitting"], "Underfitting")
plot_decision_boundary(models["Balanced_RBF"], "Balanced_RBF")
plot_decision_boundary(models["Overfitting"], "Overfitting")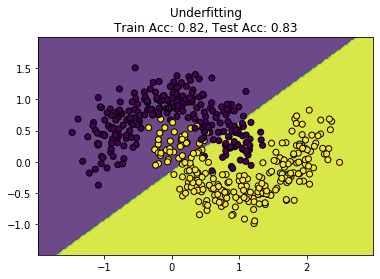
欠拟合效果图,训练数据和测试数据都没有达到好的结果
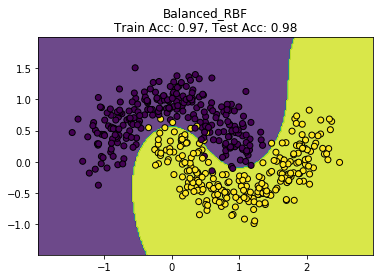
比较理想的效果,训练数据和测试数据都达到好的结果
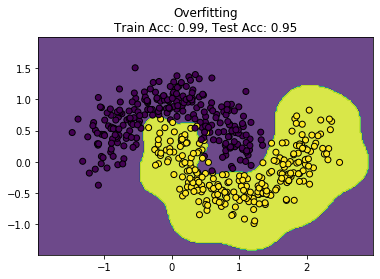
过拟合,训练数据更理想,测试数据相比训练数据差些
四、应用建议
好模型=测试集表现好+训练/测试差距小。我们可以把以下方法作为考虑欠拟合与过拟合的依据:
1.训练集准确率远小于自己的理想值 → 欠拟合
2.测试集准确率小于训练集准确率 → 过拟合(毕竟我们最终目的是为了应用,还是重点关注测试集的准确率)
以上就是本期博文全部内容,感谢伙伴们阅读。
请大家多多点赞、收藏和加关注。