Java,八股,cv,算法——双非研0四修之路day23
目录
昨日总结
今日计划
算法——逆波兰表达式
算法——滑动窗口最大值(逆天的单调队列解法)
JVM
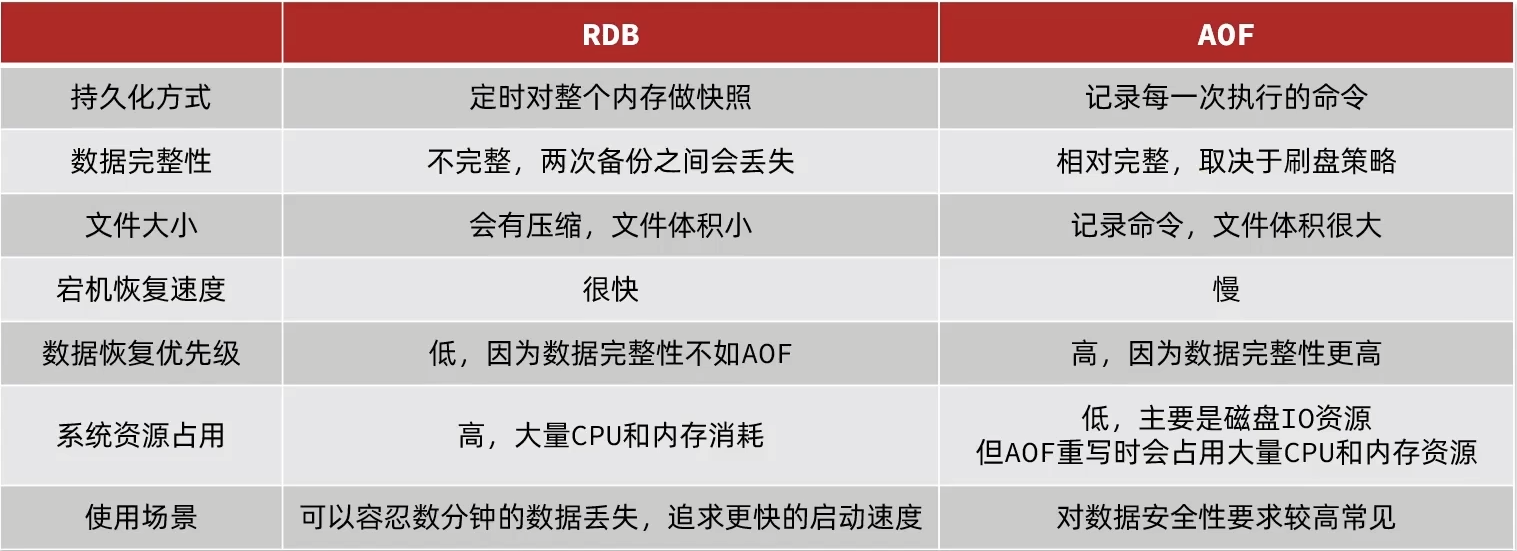
分布式缓存
Redis持久化
Redis主从集群
Redis哨兵
Redis分片集群结构
昨日八股答案
今日八股
昨日总结
- redis高级篇(分布式缓存),JVM课程学习
- cv(停滞中)
- 背诵小林coding--Java并发面试篇(6/6)
- 代码随想录——逆波兰表达式,滑动窗口最大值(逆天的单调队列解法)
今日计划
- redis高级篇(分布式缓存+多级缓存),JVM底层原理
- cv(停滞中)
- 背诵小林coding--Java并发面试篇(1/5)
- 代码随想录——前k个高频元素,二叉树的递归与非递归遍历
算法——逆波兰表达式
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。 - 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
示例 1:
输入:tokens = ["2","1","+","3","*"] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
输入:tokens = ["4","13","5","/","+"] 输出:6 解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
class Solution {public int evalRPN(String[] tokens) {//思路一点没有,全是语法错误。注意:push操作最好在case中完成,不要单拿出来。而且不要一上来就取栈的元素,否则可能//会抛出NoSuchElementException异常。//初始一个栈,方便出栈计算//Stack 类是一个泛型类,它只能存储引用类型,而 int 是基本数据类型,需要借助自动装箱机制将 int 转换为其对应的包装类 Integer 来实现入栈操作。Deque<Integer> stack = new LinkedList<Integer>();for(String index : tokens) {int one,two,res = 0;switch(index) {case "+" :one = stack.pop();two = stack.pop();res = two + one;stack.push(res);break;case "-" :one = stack.pop();two = stack.pop();res = two - one;stack.push(res);break;case "*" :one = stack.pop();two = stack.pop();res = two * one;stack.push(res);break;case "/" :one = stack.pop();two = stack.pop();res = two / one;stack.push(res);break;default :stack.push(Integer.valueOf(index));break;}}return stack.pop();}
}算法——滑动窗口最大值(逆天的单调队列解法)
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 :
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7]
//利用双端队列手动实现单调队列
/*** 用一个单调队列来存储对应的下标,每当窗口滑动的时候,直接取队列的头部指针对应的值放入结果集即可* 单调队列类似 (tail -->) 3 --> 2 --> 1 --> 0 (--> head) (右边为头结点,元素存的是下标)*/
class Solution {public int[] maxSlidingWindow(int[] nums, int k) {ArrayDeque<Integer> deque = new ArrayDeque<>();int n = nums.length;int[] res = new int[n - k + 1];int idx = 0;for(int i = 0; i < n; i++) {// 根据题意,i为nums下标,是要在[i - k + 1, i] 中选到最大值,只需要保证两点// 1.队列头结点需要在[i - k + 1, i]范围内,不符合则要弹出while(!deque.isEmpty() && deque.peek() < i - k + 1){deque.poll();}// 2.既然是单调,就要保证每次放进去的数字要比末尾的都大,否则也弹出while(!deque.isEmpty() && nums[deque.peekLast()] < nums[i]) {deque.pollLast();}deque.offer(i);// 因为单调,当i增长到符合第一个k范围的时候,每滑动一步都将队列头节点放入结果就行了if(i >= k - 1){res[idx++] = nums[deque.peek()];}}return res;}
}
JVM
- JVM中表示两个class对象是否为同一个类:首先类的完整类名必须一致,包括包名;加载这个类的ClassLoader必须相同,否则这两个类的对象是不相等的
- JVM必须指到一个类型是由启动加载器加载的还是用户类加载器加载的。一是因为采用双亲委派机制,需要保证类的加载顺序。二是防止与启动类加载器的核心类库同名,防止核心类被篡改。
- 灰色区域是每个线程独立拥有的,红色是每个进程(虚拟机实例)对应一份,同时红色也是线程共享的部分

- JVM的垃圾回收主要集中在堆区和方法区,栈是没有GC(垃圾回收)的,他垃圾回收就是进站出站。
- PC没有GC,也没有OOM(内存不足异常)
- 栈是运行时的单位(程序如何运行,如何处理数据等等问题),堆是存储的单位(数据的存储问题,数据怎么放,放在哪等)
- 栈存在OOM内存溢出,但不存在GC
分布式缓存
Redis持久化
- RDB异步持久化:
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。
fork操作就是在复制页表(与操作系统知识紧密相关)
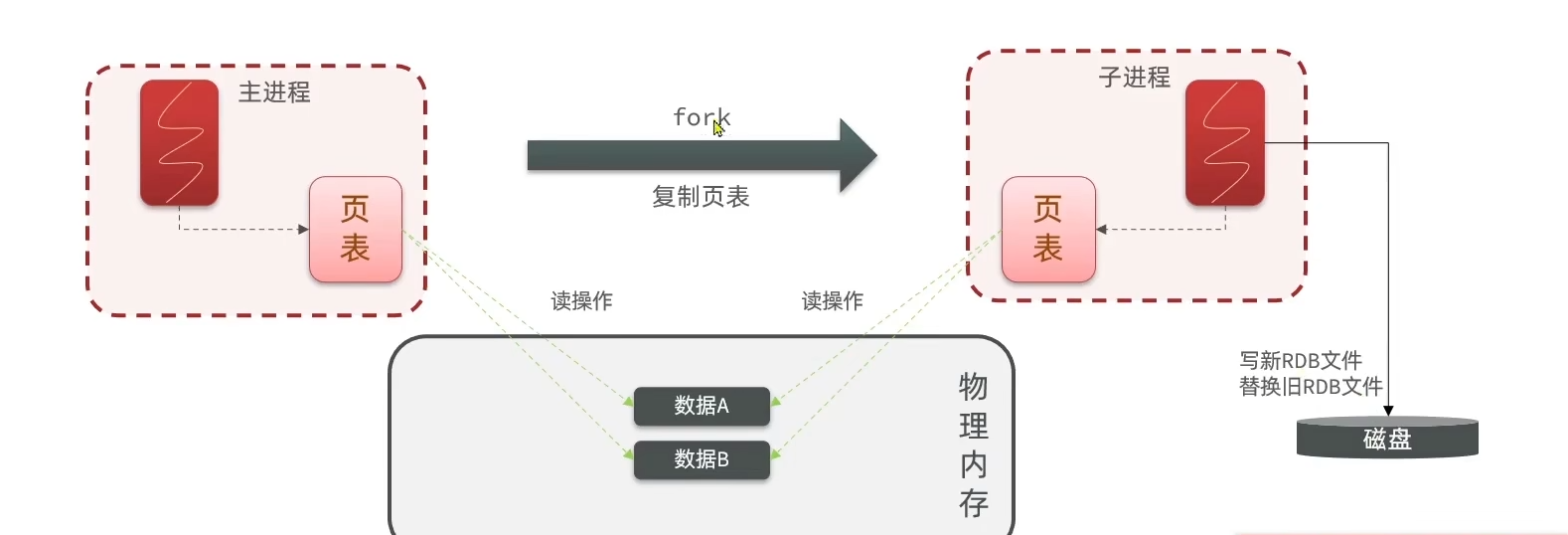
缺点: RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险。fork紫禁城、压缩、写出RDB文件都比较耗时
- AOF持久化:
redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
Redis主从集群
数据同步原理
全量同步流程图
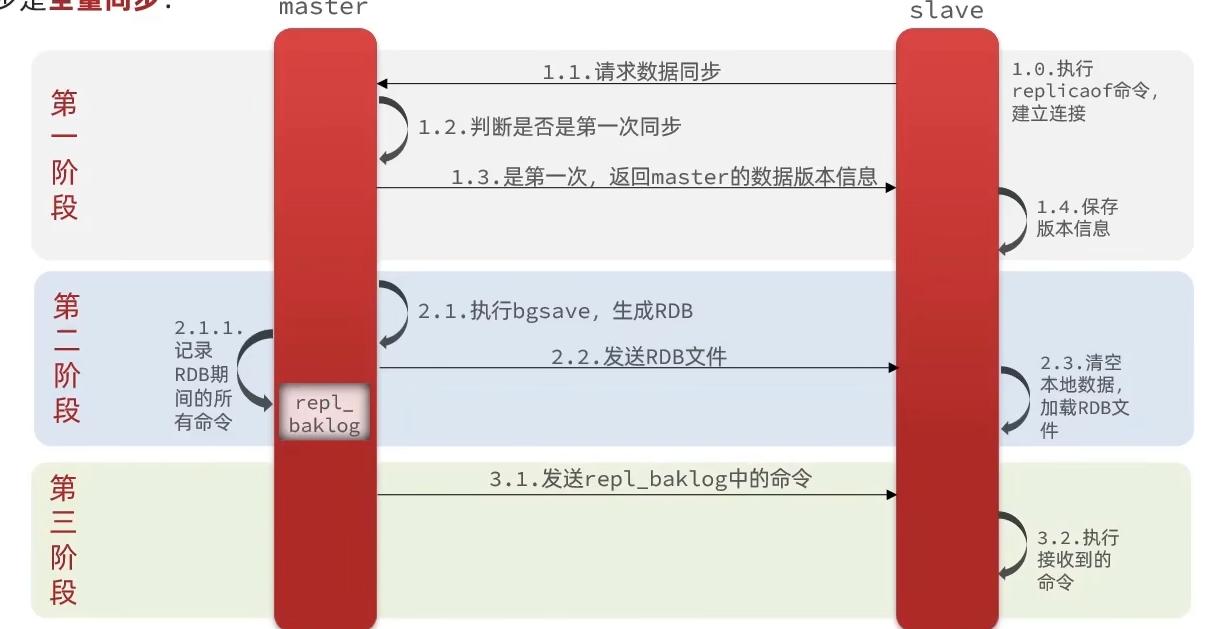
全量同步的流程
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
增量同步流程图

注意:repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
主从集群就数据同步问题的优化
- 在master中配置repl-diskless-syncyes启用无磁盘复制,避免全量同步时的磁盘lO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
总结
全量与增量同步区别
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repL_baklog中从offset之后的命令给slave
什么时候执行全量同步
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
Redis哨兵
背景:在redis主从集群中如果主节点发生了宕机,可以采用Redis哨兵来实现主从集群的自动故障恢复。
作用:
- Sentinel监控主从节点是否正常工作
- 如果主节点发成故障,Sentinel将一个从节点升为主节点。故障恢复后,也以新的主节点为主
- 通知客户端节点地址发生变更,通过访问Sentinel来查询是否发生变更。(RedisTemplate已经实现了查询节点是否变更的更新,只需调用即可,其中还可配置主从读写分离操作)
Redis分片集群结构
背景:单主从和哨兵可以解决高可用、高并发读的问题,但无法解决高 并发写和海量数据存储的问题,因此分片集群结构来解决
特征:
- 集群中有多个主节点,每个主节点保存不同的数据
- 每个主节点(master)都可以有多个从节点
- 主节点之间通过ping检测彼此的健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
昨日八股答案
- Voliatle关键字的作用,可以保证线程安全吗
Voliatle可以保证各线程的可见性。类似于全局变量,他的修改,在局部方法中都会看到他的变化。当一个线程修改了volatile修饰的变量的值,其他线程能够立即看到最新的值,从而避免了线程之间的数据不一致。
但是他无法保证线程的安全性,需要sunchronized或锁机制来实现原子性和安全性的保证。
- Voliatle与Synchronized的比较
Synchronized是一种互斥行的同步机制,保证资源限制一个线程去访问。
Voliatle是一种轻量级的同步机制,同上。也防止指令重排序。。
- 介绍一下线程池工作的原理
工作的原理是根据线程池的容量,来判断任务的执行。
大概得工作流程是:当任务发出后,需要判断线程池是否在运行,否则拒绝任务,是则下一步判断。判断剩余线程数是否还有空间,是则添加线程并执行任务,否则进入阻塞队列的判断。阻塞队列也满,则进入最大线程数的判断,未满,则进入阻塞队列;如果达到了最大线程数,则拒绝任务。否则执行任务。
今日八股
-
JVM的内存模型架构
-
JVM中堆栈的区别
-
JVM方法区中方法的执行过程
-
程序计数器的作用,为什么是私有的
-
