大模型推理引擎总结
论文:A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
Github:https://github.com/sihyeong/Awesome-LLM-Inference-Engine
大型语言模型(LLMs)广泛应用于聊天机器人、代码生成器和搜索引擎中。思维链、复杂推理、代理服务等工作负载通过反复调用模型,显著增加了推理成本。并行化、压缩和缓存等优化方法已被采用以降低成本,但多样化的服务需求使得选择合适的方法变得困难。最近,专门的 LLM 推理引擎已成为将优化方法集成到面向服务的基础设施中的关键组件。然而,关于推理引擎的系统性研究仍然缺乏。本文对 25 个开源和商业推理引擎进行了全面评估。我们从易用性、易部署性、通用支持性、可扩展性以及对吞吐量和延迟敏感计算的适用性等方面检查了每个推理引擎。此外,我们通过研究每个推理引擎支持的优化技术来探索其设计目标。同时,我们评估了开源推理引擎的生态系统成熟度,并分析了商业解决方案的性能和成本策略。我们概述了未来的研究方向,包括对复杂 LLM-based 服务的支持、对各种硬件的支持以及增强的安全性,为研究人员和开发人员在选择和设计优化的 LLM 推理引擎方面提供实用指导。我们还提供了一个公共存储库,以持续跟踪这个快速发展领域的动态:https://github.com/sihyeong/Awesome-LLM-Inference-Engine。
1 引言(Introduction)
大型语言模型(LLMs)正被广泛应用于各种服务中,如聊天机器人、代码生成和搜索引擎,其中著名的例子包括 OpenAI 的 ChatGPT [5]、GitHub Copilot [84] 和 Google Gemini [86]。在这些成功的基础上,众多新的模型和服务迅速涌现;然而,这种扩张在大规模部署和服务 LLMs 方面带来了新的挑战。
最近的趋势,如以推理为中心的测试时缩放 [124, 226] 和基于 LLM 的 AI 代理 [92, 134],显著增加了基于 LLM 的应用程序的计算需求和推理调用次数。以推理为中心的测试时缩放用多步推理或迭代自我验证取代了单遍答案生成,以提高输出质量。也被称为思维链(CoT)[259]、自一致性 [45] 和测试时推理 [98],这些方法通过每个查询多次调用模型来提高准确性,从而增加了延迟和计算成本。同时,像 AutoGPT [26] 和 LangChain [126] 这样的基于 LLM 的 AI 代理自主规划一系列任务来满足单个用户请求,在单个会话中反复调用模型。因此,推理效率对于实际部署面向推理的 LLMs 和 AI 代理变得至关重要。
为了管理 LLMs 不断增长的推理成本,各种优化技术已被采用,如量化 [61]、轻量级架构 [268] 和知识蒸馏(KD)[271]。然而,在大规模服务中,提示长度、查询类型和输出格式的多样性通常意味着单一的优化方法无法覆盖所有场景。因此,提供多种优化策略并处理推理过程的 LLM 推理引擎,已成为直接影响服务质量和成本的关键基础设施组件。
尽管像 PyTorch [201] 和 TensorFlow [1] 这样的通用深度学习框架 —— 最初设计用于支持从卷积神经网络(CNNs)到循环神经网络(RNNs)的广泛模型 —— 被广泛用于 LLM 推理,但它们优先考虑广泛的硬件和架构兼容性。因此,它们不包括针对 LLMs 或顺序解码的各种专门优化。在这些框架上运行大规模模型可能导致性能下降和资源使用率提高,这凸显了对专用推理解决方案的需求。
为了满足这一需求,越来越多的专门 LLM 推理引擎应运而生。它们提供了批处理、流式传输和注意力优化等通用框架中通常不具备的功能。然而,每个引擎针对不同的硬件,如图形处理器(GPUs)和 LLM 加速器,优化范围从模型压缩到内存卸载,预期用例从实时对话系统到大规模文本生成不等。结果,该生态系统发展迅速且分散,使得确定每个引擎支持哪些优化方法以及它们在各种条件下的性能如何变得困难。因此,迫切需要对 LLM 推理引擎及其提供的优化技术进行全面的回顾和比较。
大多数现有的关于 LLM 优化的调查(表 1)都集中在特定方法上,如模型压缩或硬件加速,因此没有充分探索各个推理引擎支持哪些优化技术。此外,许多这些调查遗漏了最近发布的商业引擎。例如,Chitty-Venkata 等人 [48] 和 Yuan 等人 [281] 专注于基于 Transformer 的模型压缩,而 Park 等人 [200] 和 Zhu 等人 [301] 详细研究了压缩方法。同样,Xu 等人 [268]、Xu 等人 [267] 和 Wang 等人 [254] 等研究讨论了 LLM 推理或服务的优化策略系统,但它们缺乏对每个引擎的设计和实现的详细检查。因此,文献中仍然存在一个空白,即需要一份不仅呈现当前 LLM 推理引擎格局,而且系统地将其专门特征与其实现的优化技术联系起来的调查。
| 调查 | 范围 | 所回顾的推理引擎数量 | 局限性 |
| Chitty-Venkata 等,JSA(2023)[48] | 高效推理 - 架构设计、知识蒸馏、剪枝、量化 | ✘ | 仅涵盖高效推理的优化技术 |
| Miao 等,ArXiv(2023)[173] | 高效模型服务 - 解码算法、架构设计、模型压缩、量化、并行计算、内存管理、请求调度、内核优化 | 10 | 仅涵盖并行计算、迭代调度、注意力内核支持以及推理引擎的主要特征概述 |
| Bai 等,ArXiv(2024)[27] | 资源高效模型 - 架构设计、预训练、微调、推理优化、系统设计 | ✘ | 仅涵盖用于高效推理的模型端优化技术 |
| Xu 等,ArXiv(2024)[268] | 资源高效基础模型 - 基础模型、架构设计、资源高效算法、资源高效系统 | 23 | 提供了关于云和边缘环境中的训练和推理支持以及推理优化技术的信息,但缺乏对推理引擎的详细描述。 |
| Park 等,ArXiv(2024)[200] | 模型压缩 - 剪枝、量化、知识蒸馏、低秩近似、参数共享、架构设计 | ✘ | 仅涵盖模型压缩技术 |
| Yuan 等,ArXiv(2024)[281] | 高效推理 - 模型压缩、快速解码算法、编译器 / 系统优化、硬件优化 | ✘ | 仅涵盖高效推理的优化技术 |
| Zhu 等,TACL(2024)[301] | 模型压缩 - 量化、剪枝、知识蒸馏、低秩分解 | ✘ | 仅涵盖模型压缩技术 |
| Wang 等,ArXiv(2024)[254] | 模型压缩和高效推理 - 量化、剪枝、知识蒸馏、架构设计、框架 | 6 | 重点解释优化特征而非推理引擎本身,并且包括过时的推理引擎 |
| Zhou 等,ArXiv(2024)[298] | 高效推理 - 数据级优化、架构设计、模型压缩、推理引擎、服务系统 | 18 | 从推理优化和服务优化的角度探讨优化技术,但仅描述有限的技术集 |
| Wan 等,TMLR(2024)[249] | 高效模型 - 模型优化方案、数据选择 / 工程、框架 | 18 | 描述了推理引擎的训练、微调及推理支持以及关键特征,但采取更全面的视角而非专门关注推理 |
| Li 等,ArXiv(2024)[132] | 硬件视角的推理优化 - 硬件架构(CPU、GPU、FPGA、ASIC、PIM/NDP)、量化、稀疏性、推测解码、同构 / 异构协作 | ✘ | 仅涵盖用于高效推理的硬件感知优化技术 |
| Xu 等,CSUR(2025)[267] | 资源高效算法 - 注意力优化、架构设计、预训练、微调、推理算法、模型压缩、分布式训练、服务 | 18 | 涵盖训练和推理支持,但缺乏对推理引擎的充分描述 |
| Zheng 等,CSUR(2025)[296] | 高效模型 - 模型压缩、运行时优化、设备上应用 | 8 | 仅简要涵盖移动和桌面支持及相关优化技术 |
为了填补这一空白,本文采用以框架为中心的视角,深入研究了一系列 LLM 推理引擎,并对每个引擎实现的优化技术进行了分类。特别是,它映射了这些引擎如何处理量化、KD、缓存和并行化等方法,使读者能够快速识别符合特定要求的引擎。本文还包括了旧调查中未涵盖的最近发布的商业引擎,比较了它们的架构目标、硬件目标和显著特征。目的是为需要构建或操作高性能、成本效益高的 LLM 服务的研究人员和工程师提供实用见解。
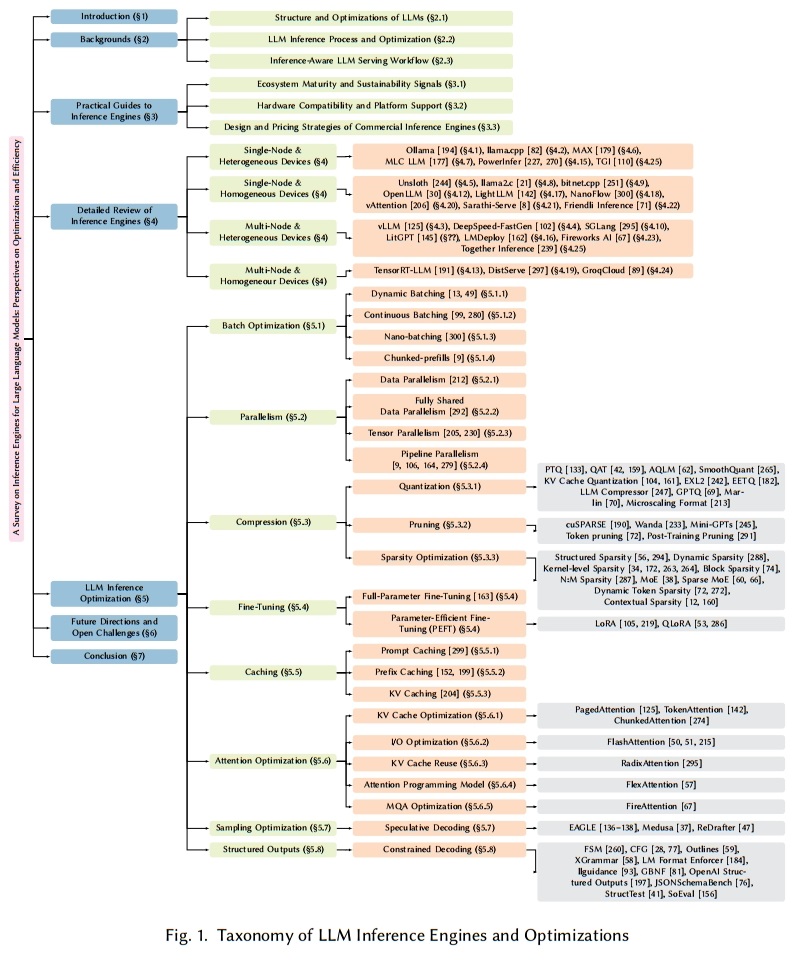
如图 1 所示,本文系统地组织了主要的 LLM 推理引擎及其各自的优化方法。第 2 节概述了基于解码器的 Transformer 架构、注意力机制和标准 LLM 推理过程的核心方面。第 3 节全面回顾了领先的 LLM 推理引擎,包括生态系统、硬件和操作系统(OS)支持。特别是,讨论了商业产品,以帮助读者找到适合其自身服务环境和部署目标的解决方案。为此,我们分析了推理引擎的各个方面,包括它们的生态系统、可用性以及它们的对边缘和服务器环境中的硬件及平台的支持。第 4 节详细讨论了各种大型语言模型推理引擎的架构以及每个引擎所提供的特定于推理的优化特性。第 5 节对当前推理引擎中发现的基本推理优化技术进行了分类 —— 涵盖批处理优化(§5.1)、并行化(§5.2)、模型压缩(§5.3)、微调(§5.4)、缓存(§5.5)、注意力优化(§5.6)、采样优化(§5.7)和结构化输出(§5.8)—— 同时也探讨了新兴趋势。通过综合这些技术,本章帮助读者选择最符合其服务需求的推理引擎。基于这些讨论,第 6 节探讨了大型语言模型推理引擎发展的未来方向和主要挑战。具体而言,我们研究了大型语言模型的持续演变以及推理引擎如何适应这些变化,并特别关注安全性和跨多样化硬件平台的兼容性。我们从多个方面提出了观点,包括推理引擎优化策略、推理安全性以及对多样化硬件平台和架构的支持。最后,第 7 节对本文进行了总结。
2 背景(Backgrounds)
为了提高 LLM 推理的效率,不仅要选择适合该领域的模型,还要选择和优化适当的推理引擎,同时采取多样化的整体开发方法。本节从推理的角度审视 LLMs,展示模型压缩和部署策略等任务如何与推理引擎无缝集成,以实现快速且经济高效的服务。
首先,我们回顾仅解码器 Transformer 架构,以及各种注意力机制和与高效推理相关的考虑因素。其次,我们解释推理过程,重点关注预填充和解码阶段,并从推理引擎的角度强调相应的优化技术。最后,我们结合这些元素,全面概述推理和服务部署的整个流程。
2.1 LLMs 的结构和优化(Structure and Optimizations of LLMs)
LLM 架构类型。基于 Transformer 架构 [246],LLMs 大致可分为三种类型:仅解码器、编码器 - 解码器和仅编码器模型。编码器 - 解码器模型首先对整个输入进行编码,然后在每个步骤使用带有交叉注意力的解码器,这导致推理期间更高的内存使用和更复杂的过程。仅编码器模型适用于分类或检索等任务,但由于它们针对一次性推理进行了优化,因此不适合逐令牌生成。
相比之下,仅解码器模型结构更简单,由于通过自回归训练具有强大的零样本性能 [253, 258],在最近的 LLMs 中被广泛采用。因此,本文主要关注仅解码器架构。
标准仅解码器架构。图 2 显示了仅解码器 Transformer 的架构。当接收到文本输入时,首先对其进行令牌化,然后通过嵌入层转换为高维向量。在这个阶段,添加位置编码以纳入令牌顺序。生成的嵌入通过多个 Transformer 块,每个块包括多头注意力(MHA)、前馈网络(FFN)和残差连接。MHA 层将输入分割为查询(Q)、键(K)和值(V)向量,并在多个头中并行执行缩放点积注意力。在每个头中,计算 Q-K 相似度分数并应用于 V,聚合结果。因果掩码确保只关注先前生成的令牌,实现自回归上下文学习。接下来,FFN 层通过应用线性变换、将其扩展到更高维空间并使用激活函数(例如 ReLU [6]、GELU [100] 或 SiLU [63]),然后将其缩减回原始维度,来细化注意力输出。这一系列操作增加了模型的表示能力。MHA 和 FFN 层都采用残差连接和层归一化。残差连接减轻了深度网络中的梯度消失问题 [282],层归一化保持输出分布稳定,促进更平滑的训练。
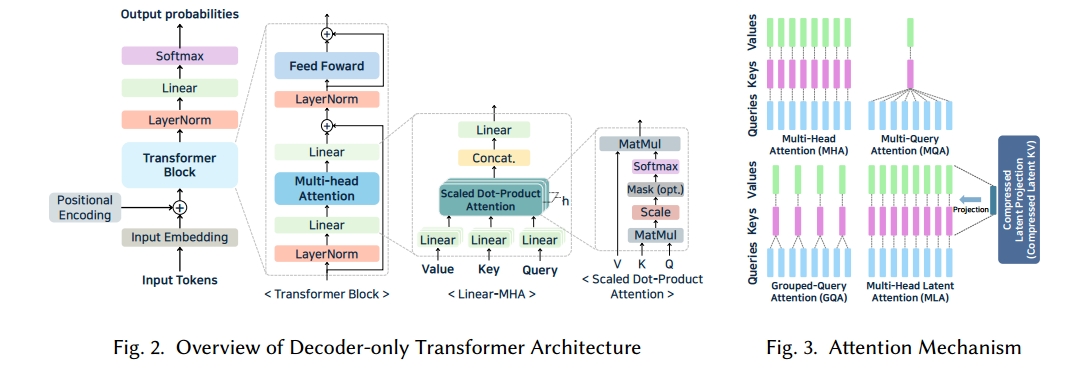
在Transformer 块操作完成后,每个输入令牌生成一个隐藏状态,该状态被归一化并用于预测文本生成中的下一个令牌。然后,隐藏状态通过线性层,产生词汇表上的对数向量。应用 softmax 函数将这些对数转换为概率分布,选择概率最高的令牌作为下一个令牌。这个过程迭代重复以生成最终文本。
注意力结构变体。在标准 Transformer 中,采用了 MHA,但最近已引入如图 3 所示的修改来提高推理效率。在 MHA 中,Nh 个头部中的每个头部都使用自己的 Q、K、V 矩阵,使模型能够学习不同的子空间表示。然而,增加头部数量也会扩大推理期间的 KV 缓存大小,因为必须存储所有 K 和 V 值。为了解决这个问题,提出了多查询注意力(MQA)[218]。MQA 保留多个查询头,同时在所有头之间共享一组 K 和 V,从而将 KV 缓存减少到大约 MHA 所需的 1/Nh。尽管这种方法可能会略微降低表达能力,但它显著减少了内存使用。分组查询注意力(GQA)[11] 采取中间立场,在头组之间而不是在所有头之间共享 K 和 V。通过调整组的数量(Ng),开发人员可以在内存效率和模型性能之间取得平衡。最近,DeepSeek-v2 [147] 引入了多头潜在注意力(MLA),将多个头的 K 和 V 压缩为共享的潜在向量。这种设计进一步最小化缓存大小,同时保持准确性。由于这些替代注意力机制改变了 KV 缓存的大小和结构,推理引擎必须相应地适应。例如,MQA 和 GQA 需要反映共享 K 和 V 的缓存管理,而 MLA 涉及重建压缩的 K 和 V。因此,推理引擎的兼容性可能因模型的注意力结构而异。
位置嵌入、令牌化和归一化的变体。在 LLMs 中,关键的架构变体包括位置嵌入的类型、令牌器的选择以及归一化层的放置。即使是著名的 LLMs 也采用不同的配置:BLOOM [261] 使用带线性偏置的注意力(ALiBi)[207],而 Llama [88, 240, 241] 和 Mistral [114] 采用旋转位置嵌入(RoPE)[232]。令牌器的选择在不同模型之间也有所不同 ——GPT 变体通常使用字节对编码(BPE)令牌器 [302],而 Llama [88, 240, 241] 和 T5 [209] 依赖于基于 SentencePiece 的单字令牌器 [123]。其他架构差异包括归一化层的放置 [210]。
2.2 LLM 推理过程和优化(LLM Inference Pro cess and Optimization)
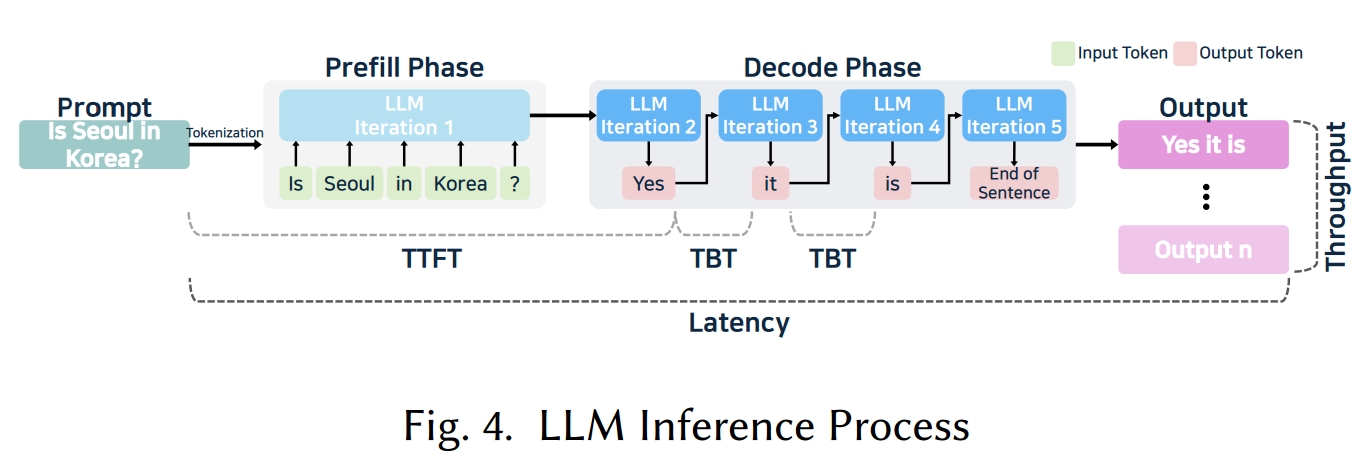
LLM 推理通过对用户的输入文本进行令牌化并生成后续令牌,直到满足停止标准(例如,令牌限制或序列结束(EOS)命令)。如图 4 所示,这个过程包括两个主要阶段:基于输入生成第一个令牌的预填充阶段,以及顺序生成其余令牌的解码阶段。
预填充阶段。该阶段处理输入文本,计算每个样本的最后一个令牌的隐藏状态,从而捕获输入的上下文和语义含义。在仅解码器 Transformer 模型中,该阶段包括令牌化、嵌入和 Transformer 块计算。对所有输入令牌执行注意力和 FFN 操作。在这一步中,注意力大约与序列长度 n 的平方成正比(O(n)),FFN 的复杂度随着中间层的大小而增加,导致大规模的数组到数组计算。用于捕获所有输入令牌之间关系的 Q、K 和 V 立即生成,将大量数据加载到内存中进行密集计算。
例如,如图 4 所示,如果用户输入是 “Is Seoul in Korea?”,它被令牌化为 [Is, Seoul, in, Korea, ?],映射到唯一的令牌值,如 [101, 4523, 1102, 2342, 63]。然后将位置嵌入应用于这些令牌 ID,将它们转换为高维向量(例如,[[0.1, 0.2, ...], [0.3, 0.5, ...], ...])。这些向量经过注意力和 FFN 计算,使模型能够学习令牌之间的上下文关系并细化它们的表示。最后,最后一个令牌(?)的隐藏状态被存储,用于解码阶段,在该阶段中它指导后续令牌的生成。
解码阶段。该阶段基于预填充阶段计算的隐藏状态,迭代生成新令牌,遵循自回归过程,其中一次只生成一个令牌。在这个阶段,Transformer 块的最终隐藏状态通过线性变换和 softmax 函数,产生词汇表上的概率分布。选择概率最高的令牌并附加到输入序列。在整个过程中,K 和 V 以及输入和输出令牌存储在 GPU、系统内存或缓存中。由于必须反复访问和更新 K 和 V,解码阶段通常成为内存带宽的限制因素。尽管注意力计算类似于预填充阶段,但频繁引用先前生成的令牌会增加延迟,并且要访问的数据随着序列长度线性增长。
具体而言,在解码阶段,使用预填充阶段中保存的最后一个令牌(?)的隐藏状态来预测下一个令牌。例如,当注意力机制处理新生成的令牌时,Transformer 块产生最终的隐藏状态,然后将其线性投影到词汇表上的对数向量。应用 softmax 后,选择最可能的单词(例如 “Yes”)并附加到现有序列。重复此过程可以生成完整的响应,如图 4 所示的 “Yes it is”。
系统术语。LLM 系统的性能术语如图 4 和附带的表 2 所示。首次令牌生成时间(TTFT)衡量从接收用户请求到生成第一个令牌所花费的时间。它对系统给用户的响应速度感知尤其重要。令牌间时间(TBT)是指生成每个后续令牌所需的时间。它通常被描述为输出令牌每秒(TPOT),即解码期间的平均令牌生成速度。此外,端到端延迟表示用户查询的总响应时间,可以计算为:延迟 = TTFT +(TBT × 令牌数量)。虽然延迟提供了响应能力的总体衡量标准,但吞吐量显示系统可以同时处理多少用户请求。
| 指标 | 定义 | 用户视角 | 优化技术 |
| 首次令牌生成时间(TTFT) | 模型生成第一个令牌所需的时间 | 最直接影响用户对响应速度的感知 | 批处理(§5)、内核融合、提示缓存(§5.5.1)、推测解码(§5.7) |
| 令牌间时间(TBT) | 每个后续令牌之间的时间间隔 | 反映后续令牌的生成速度 | KV 缓存(§5.5.3)、内核融合、注意力优化(§5.6)、量化(§5.3.1) |
| 端到端延迟 | 从客户端请求到完整响应的总时间 | 反映整体响应时间和用户体验 | 批处理(§5)、KV 缓存(§5.5.3)、剪枝(§5.3.2)、推测解码(§5.7)、FlashAttention(§5.6.2) |
| 吞吐量 | 单位时间内处理的令牌数量 | 代表系统的处理能力 | 批处理(§5)、预填充优化(§5.1.4)、并行化(TP/PP)(§5.2)、量化(§5.3.1) |
从阶段角度来看,预填充阶段影响 TTFT,解码阶段影响 TBT。预填充阶段的延迟随着输入长度的增加而增加,但可以通过并行计算来减少。另一方面,解码阶段的延迟随着生成的令牌数量的增加而增加,并且对用户体验有更直接的影响。
优化。考虑到这些性能指标,LLM 推理引擎对预填充和解码阶段采用了各种定制优化技术。大多数引擎使用 KV 缓存来避免解码期间的冗余计算,通过重用缓存的上下文并仅对最新令牌进行新操作。最近,已引入连续批处理 [280] 和混合批处理 [117] 等技术,以进一步提高解码阶段的效率,将来自多个请求的预填充和解码操作分组,以更好地利用 GPU 资源。
此外,许多推理引擎通过内核融合和特定于硬件的计算内核减少解码期间的每个令牌开销。内核融合将诸如 LayerNorm、矩阵乘法和激活函数等操作合并到单个 GPU 内核中,减少内存访问和内核启动开销。
量化 [61] 是另一项关键优化。通过以 8 位或 4 位整数而不是 16 位或 32 位浮点格式表示模型参数,内存使用和带宽需求下降,特别是在解码期间。量化模型可以在相同硬件上缓存更多令牌并处理更多并发请求,通常会提高计算速度。
一般而言,缓存、批处理、内核优化和量化是优化 LLM 推理服务中的令牌吞吐量和最小化延迟的基础。在推理引擎中提供对这些技术的强大支持对于提供高质量、可扩展的 LLM 解决方案至关重要。
2.3 推理感知的 LLM 服务工作流(Inference-Aware LLM Serving Workflow)
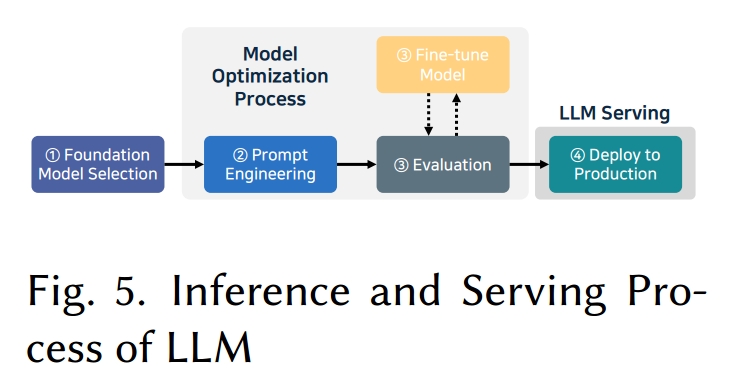
LLM 开发通常包括收集训练数据、在大型语料库上预训练,然后对齐和评估生成的模型。对于生产,推理通常依赖于预训练的基础模型 [268]。这个完整的流程通常被称为 LLM Operations(LLMOps),如图 5 所示,包括四个阶段。
1、模型选择(Model selection)。选择与服务级别要求、性能需求和可用硬件相匹配的模型和推理引擎,对于成功部署 LLM 至关重要。一个模型可能非常适合目标领域,但与特定的推理引擎不兼容 —— 因此必须同时考虑这两个因素。在选择推理引擎时,同样重要的是评估预期的用户并发量和服务级别目标(SLO),然后选择能够满足必要的延迟和吞吐量目标的解决方案。最终,推理引擎的设计原则和实现决定了可实现的性能、集成的易用性和总体易用性。
2、提示工程(Prompt engineering)。这一步涉及优化模型的提示方式和部署方式。提示设计可以显著影响模型性能,因为开发人员精心设计系统消息和用户提示,以确保一致、高质量的输出。这种做法被称为提示工程 [275],它指导模型产生期望的响应,而不需要额外的计算。例如,结构良好的系统提示可以调整模型的语气或减少不适当的响应,减少推理期间的试错,并有助于更稳定的操作。在开发过程中,提示模板经过迭代测试和修订,以便在生产中,模型以最少的进一步调整实现预期输出。3
3、模型评估和微调(Evaluation and fine-tuning)。提示设计完成后,必须评估模型以验证它是否达到所需的性能水平。如果没有,可以应用微调来提高准确性或特定领域的能力。例如,指令微调 [284] 可以使用指令响应数据集训练模型,以提高准确性或与领域相关的响应。其他技术包括提示微调 [130],它将任务优化的向量添加到输入嵌入中,以及前缀微调 [248],它通过在所有层的隐藏状态中插入可训练参数来修改模型。如果模型大小超过可用硬件,可以使用量化来压缩激活或权重。训练后量化 [69, 133, 265] 基于校准数据集计算缩放参数,或者,量化感知训练 [确保模型尽管权重精度低但仍保持准确性。
4 部署(Deployment)。一旦 LLM 在微调后达到期望的性能水平,就应该为生产部署做好准备。此时的一个关键决策涉及在云应用程序编程接口(API)或本地托管之间进行选择。云 API(即外部 LLM 服务)提供快速设置和随工作负载变化进行扩展的灵活性,但它们依赖于外部基础设施,可能引发数据隐私问题。由于每个查询都通过网络传输,延迟增加,使得云 API 可能不适合对延迟敏感的用例。另一方面,在本地托管 LLMs 可以避免这些问题,并显著减少延迟。消除网络开销加快了响应时间,将数据保存在内部系统中提高了隐私性。此外,本地托管允许对模型参数和硬件配置进行细粒度控制。尽管它可能需要大量的基础设施投资,但对于大规模服务,这种方法可能更经济。考虑到这些因素,在开发早期考虑部署方法是有利的。从一开始就使模型与预期的推理环境保持一致(例如,通过量化 [61] 或 KD [271])并选择适当的推理引擎可以简化流程。
3 推理引擎实用指南(Practical Guides to Inference Engines)
本节通过检查几个关键方面,提供了关于选择 LLM 推理引擎的实用指导。首先,我们关注生态系统成熟度和可持续性信号,例如引擎的开发、许可和社区支持方式。接下来,我们讨论硬件兼容性和平台支持,重点关注引擎是针对边缘设备还是服务器环境。然后,我们探讨商业推理引擎的设计和定价策略,包括成本考虑和内存使用。最后,我们提出 LLM 推理引擎的硬件感知分类,根据它们的目标用途(边缘或服务器)、设备类型和性能目标对引擎进行比较。
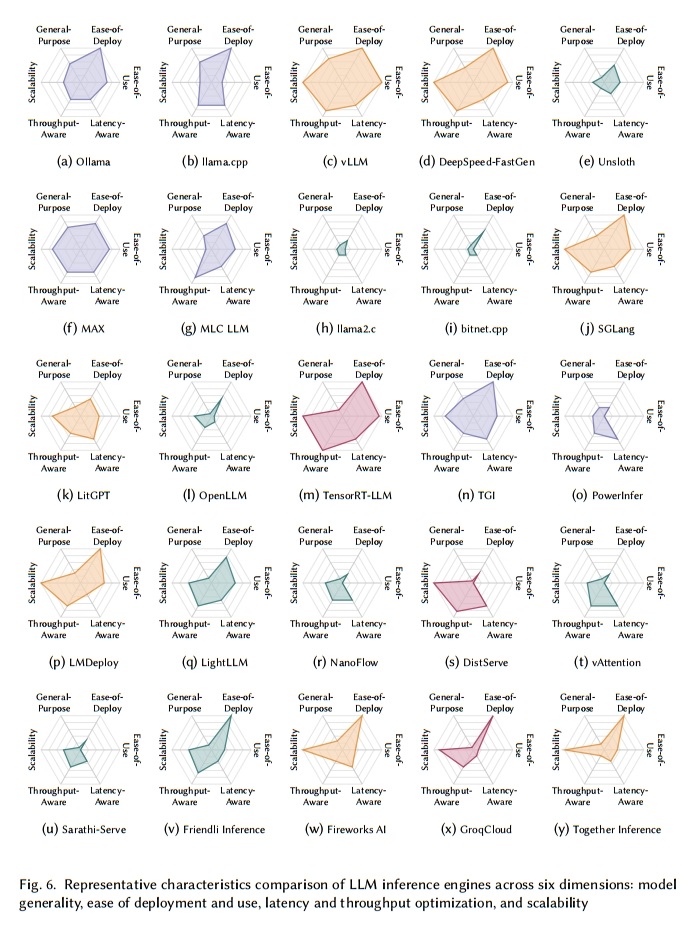
表 3 总结了本文中研究的 LLM 推理引擎,图 6 直观地展示了每个引擎的特征。通用性是一个综合指标,源于表 3 中支持的模型数量和表 4 中的硬件平台范围。分数越高,表示与各种模型和硬件的兼容性越广。

易部署性衡量引擎通过 Python 包安装程序(pip)、Debian 高级包工具(APT)、Homebrew [170]、通过源代码构建、Docker [55] 或 Conda [19] 环境或预构建二进制文件进行安装的难易程度。评分越高,表示安装和部署越简单、快速。
易用性评估文档质量和用户社区活动水平(如表 3 所示)。
延迟感知和吞吐量感知分别代表每个引擎对特定于延迟和吞吐量的优化技术的支持,基于表 2(§2)中的指标和表 7(§5)中的优化特征。值越高意味着在这些方面有更强的优化能力。
最后,可扩展性表示引擎适应边缘、服务器和多节点环境的有效程度。分数越高,表示适合大规模 LLM 工作负载。
对于商业推理引擎,一些指标分数可能较低,因为它们依赖于公开可用的信息。
通过参考图 6,用户可以确定哪种 LLM 推理引擎最符合他们的服务需求和部署设置。
3.1 生态系统成熟度和可持续性信号(Ecosystem Maturity and Sustainability Signals)
本节讨论与 LLM 推理引擎现状相关的非技术指标。如表 3 所示,LLM 推理引擎可分为开源和闭源商业工具。对于开源工具,我们基于开发和维护组织的类型、开放软件许可证以及用户支持的成熟度来分析可持续性。
开发和维护组织。开源推理引擎主要由大型科技公司、初创公司、社区或学术机构开发和维护。在接受调查的 21 个推理引擎中,按组织类型划分的推理引擎数量为:学术(6 个)、初创公司(6 个)、大型科技公司(5 个)和社区(4 个)。虽然差异不大,但这表明 LLM 推理引擎正由各种组织开发和维护。无论组织如何,大多数开源项目使用 MIT 或 Apache 2.0 等宽松许可证,使其易于采用和使用。
由社区团体维护的项目可能面临长期维护的挑战,这可能限制新技术的集成。一些由大型科技公司或初创公司领导的项目,如 Unsloth [244]、MAX [179]、OpenLLM [30] 和 TensorRT-LLM [191],只发布部分源代码。
虽然开源引擎由大型科技公司、初创公司、社区和学术界等不同群体开发,但大多数商业 LLM 推理引擎由初创公司开发和运营。这是因为初创公司可以快速行动,开发专门技术,通过差异化的高性能服务更快地进入市场。
用户偏好。我们使用 GitHub 统计数据(如总星数、日均增长率和一段时间内的星增长趋势)来衡量用户对开源 LLM 推理引擎的偏好。在本研究中,如果一个项目平均每天获得超过 25 个星,我们认为它非常受欢迎。像 Ollama [194](209.6)、llama.cpp [82](102.6)、DeepSpeed-FastGen [102](72.6)和 Unsloth [244](74.1)、bitnet.cpp [251](53.0)、vLLM [125](55.2)等项目符合这一标准,并且总星数达数万,表明社区的高度关注和快速采用。
另一方面,一些项目总星数多,但最近增长较慢。例如,TGI [110]、TensorRT-LLM [191] 和 OpenLLM [30] 各有超过 10K 星,但它们的日增长率低于 25,并且在初始激增后增长曲线持平。这可能表明它们早期受到关注,但现在难以维持社区兴趣。可能的原因包括可用性有限或生态系统封闭。
这种分析有助于估计项目的未来增长潜力,为选择用于实际或研究用途的引擎提供长期视角。
易用性。我们基于文档质量和用户论坛的可用性来评估 LLM 推理引擎的用户友好性。我们的分析表明,像 vLLM [125]、DeepSpeed-FastGen [102]、TensorRT-LLM [191] 等顶级项目提供了写得很好的文档,vLLM [125]、MAX [179]、LitGPT [145] 有活跃的社区渠道(如 Discord、论坛),使入门和故障排除更容易。这与它们的高星数和快速用户采用密切相关。
相比之下,bitnet.cpp [251]、OpenLLM [30]、PowerInfer [270]、NanoFlow [300]、DistServe [297] 等项目的文档有限或缺乏社区渠道。这也反映在它们缓慢的星增长中,表明用户的入门门槛较高。文档差且没有论坛的项目往往受欢迎程度较低,增长较慢。
这些结果表明,除了技术性能外,用户支持系统是引擎选择和社区增长的重要因素。
开发活动。我们基于 GitHub 提交趋势和支持的模型数量来评估 LLM 推理引擎的开发活动。通过同时考虑这两个指标,我们获得了比单纯计算提交更可靠的结果。像 llama.cpp [82]、vLLM [125] 和 DeepSpeed-FastGen [102] 等项目在提交历史中显示出一致且频繁的更新,同时支持广泛的 LLM 模型。另一方面,像 TGI [110] 和 TensorRT-LLM [191] 这样早期获得许多星的引擎,提交活动相对停滞,模型支持有限。这可能表明未来功能扩展的灵活性较低。特别是,像 OpenLLM [30] 和 PowerInfer [270] 这样支持的模型范围狭窄或只有短期提交活动的项目,显示出技术适应性有限的迹象,这可能对实际应用构成限制。
总体而言,GitHub 星数和提交活动显示出相似的模式,表明用户兴趣和活跃开发往往相辅相成。经常更新并支持多种模型的推理引擎更有可能长期得到良好维护。
3.2 硬件兼容性和平台支持(Hardware Compatibility and Platform Support)
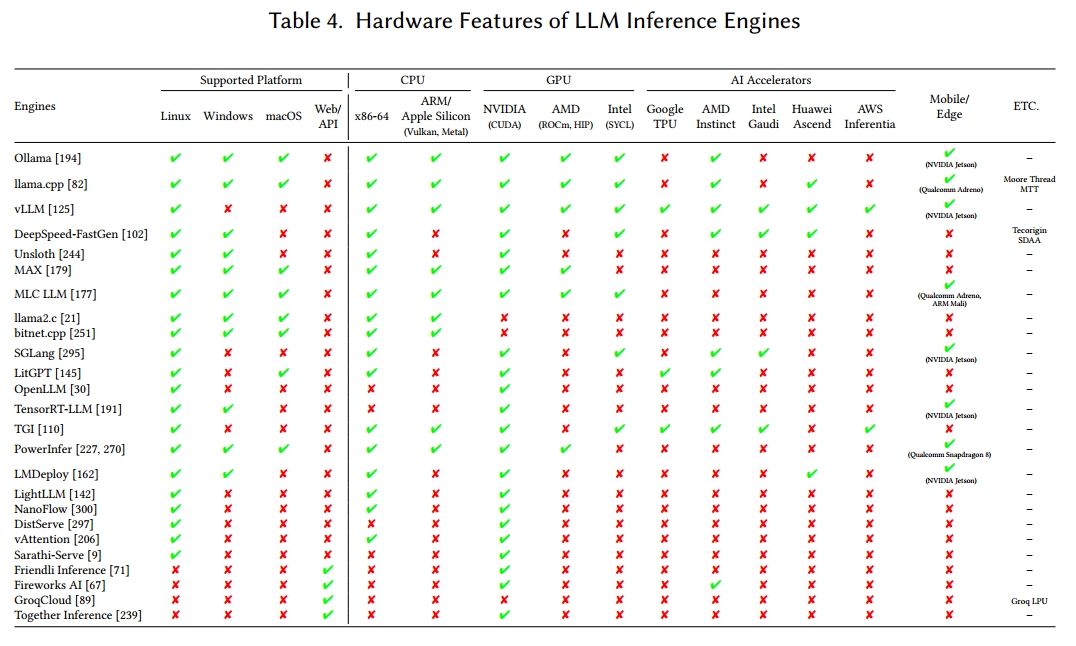
硬件和操作系统支持。如表 4 所示,每个推理引擎都有不同的设计目标和目标系统。一些推理引擎支持各种硬件类型,而另一些则针对单一平台进行了优化。这些硬件兼容性差异会影响与量化数据格式、内核融合以及多节点或多 GPU 配置支持等性能相关的特征。因此,为了获得最佳服务性能,应根据推理引擎与预期硬件设置的兼容性来选择它们。此外,表 4 总结了每个推理引擎的操作系统和硬件支持状态。
大多数推理引擎在 Linux 环境中运行,有些还额外支持 Windows 或 macOS。商业引擎通常提供基于 Web 的推理服务,但它们也支持本地部署。这些平台差异可能会影响开发复杂性和推理性能,具体取决于软件功能范围。
基于 CPU 的推理。虽然许多引擎包括基于 CPU 的推理,但非边缘聚焦的解决方案通常将 CPU 用于特定任务 —— 例如卸载操作或处理模型权重 —— 而不是作为主要计算资源。
边缘和服务器环境。在边缘设备(例如,移动设备和物联网(IoT)系统)上,有限的计算和内存资源要求推理引擎专注于轻量级设计。这些引擎减小模型大小并应用量化等技术,以最小化内存使用并在低功耗硬件上启用执行。面向移动和边缘的引擎可能需要完全在 CPU 上运行,或利用片上系统(SoC)平台中嵌入的 AI 加速器,如神经处理单元(NPUs)或数字信号处理器(DSPs)。例如,Apple Core ML [24] 和 Google AI Edge SDK [87] 允许将 Transformer 操作部署到消费设备上的专用硬件。边缘推理引擎包括 Ollama [194]、llama.cpp [82] 和 MLC LLM [177],特别是 MLC LLM 为各种边缘硬件提供编译器技术。
相反,服务器端推理引擎针对多 GPU 环境进行了优化,以处理大量请求。它们依靠模型和管道并行等分布式计算技术将大型模型分布在设备上,并使用大批次大小和动态调度来最大化硬件利用率。随着英特尔 Max [112]、谷歌 TPU [116]、AMD Instinct [225] 和英特尔 Gaudi [118] 等 AI 加速器被用作推理服务器中 NVIDIA GPU 的替代品,越来越多的引擎提供异构硬件后端。服务器推理引擎包括 TensorRT-LLM [191]、vLLM [125]、DeepSpeed-FastGen [102] 等,并提供针对吞吐量或延迟的优化技术。

可扩展性和设备类型。图 7 根据表 3 中的推理引擎的硬件特征对它们进行了分组。X 轴区分对单一设备类型与多种类型的支持,而 Y 轴显示每个引擎是否支持单节点或多节点配置。单个节点通常包括 1 到 8 个 GPU,而多节点系统连接多个这样的节点。
单节点推理引擎强调节点内针对 CPU、消费级 GPU 或边缘 / IoT 设备的优化。Ollama [194] 和 llama.cpp [82] 专注于消费级硬件(例如,笔记本电脑和 PC),MLC LLM [177] 旨在在各种边缘平台上进行高效推理。相比之下,多节点推理引擎处理节点间和节点内计算,优化多用户工作负载的可扩展性和性能。属于这一类别的代表性推理引擎包括 vLLM [125]、TensorRT-LLM [191] 和 SGLang [295]。
支持异构设备的推理引擎可以在 GPU 之外的多种硬件类型上运行,允许开发人员根据应用需求选择硬件。相比之下,仅支持同构设备的引擎 —— 例如专门针对 NVIDIA GPU 或 Groq LPU [4] 的引擎 —— 可以通过自定义内核和低级优化提供高性能,尽管它们较窄的硬件支持可能限制可移植性。
3.3 商业推理引擎的设计和定价策略(Design and Pricing Strategies of Commercial Inference Engines)
云服务和模型覆盖范围。商业推理引擎提供基于云的服务,与许多开源解决方案相比,简化了 LLM 应用程序和底层硬件的设置。特别是,Friendli Inference [71]、Fireworks AI [67] 和 Together Inference [239] 支持比大多数开源推理引擎更广泛的模型范围,涵盖不仅包括大型语言模型,还包括图像、音频和多模态模型,而且它们有助于快速采用新发布的模型。
商业推理引擎的一个关键优势在于,它们能够根据服务规模提供定制化的各种模型和硬件支持,从而降低服务器部署与维护的成本和复杂性。与部分开源引擎不同 —— 这些开源引擎的维护可能不稳定,且若资源受限,其许可模式可能转向付费 —— 商业服务通常会在特定时间段内保证更新和功能增强,以此确保长期可靠运行。
硬件的多样性与专业化。在这些服务中,Friendli Inference [71] 和 Together Inference [239] 专注于优化针对 NVIDIA GPU 的推理,而 GroqCloud [89] 则利用专有 Groq LPU 人工智能加速器 [4]。Fireworks AI 支持更广泛的硬件,包括 AMD Instinct MI300X [225],并通过相关认证满足隐私和可靠性标准。
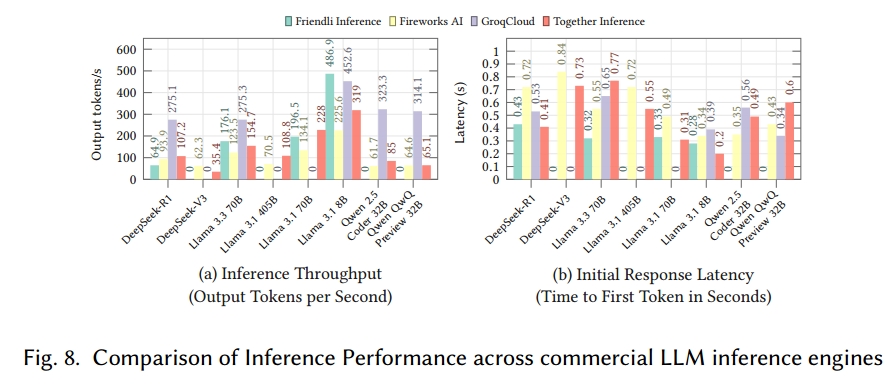
性能与成本的权衡。选择商业引擎时,还需考虑硬件支持和成本。商业推理引擎通常通过实施批处理优化、请求流水线等技术追求低延迟和高吞吐量,与开源方案相比,这些技术能实现更快、更便捷的部署。图 8 和表 5 展示了使用不同商业引擎时,各类模型(例如,推理模型(DeepSeekR1 [96])、混合专家模型(MoE)(DeepSeek-V1 [31])、大规模模型(Llama 3 [88])、代码生成模型(Qwen 2.5 Coder [111])、多模态模型(Qwen QWQ [236]))的推理性能和成本 [25]。此外,表 6 汇总了各商业引擎提供的硬件成本。即使使用相同的硬件,成本也可能因各引擎的内核和计算优化程度而有所不同。
4 推理引擎详细综述(Detaile d Review of Inference Engines)
本节将详细介绍表 3 中列出的 25 种推理引擎。对于每种引擎,我们都会描述其架构、关键特性和独特之处,还会逐一阐释图 6 中六轴雷达图所呈现的各引擎代表性特征。
4.1 Ollama
Ollama [194] 是一款基于 Go 编程语言 [85] 的推理引擎,旨在让用户在本地环境中运行大型语言模型,即便是没有技术背景的用户也能轻松测试和部署模型。因此,它主要面向单 GPU 设置,而非多 GPU 系统,其核心后端依托 llama.cpp。
Ollama 由客户端和服务器两个主要组件构成。客户端通过命令行界面(CLI)向服务器发送请求,服务器则包含一个 HTTP 服务器和 llama.cpp [82] 后端。HTTP 服务器负责管理客户端与服务器之间的通信,llama.cpp 后端则承担加载模型和处理推理请求的任务。
该推理引擎支持多种模型,如 Llama [88]、Falcon [14]、Mistral [114] 和 DeepSeek-R1 [96],而且能快速适配新发布的模型。它采用 GGUF [80] 和 Safetensors [108] 两种格式进行模型推理,并通过 Modelfile 提供模型定制功能。此外,Ollama 提供 REST API,允许用户通过 HTTP 请求管理和执行模型,适用于聊天、文本生成等应用场景。其集成选项包括 Open WebUI [195]、SwiftChat [17]、Google Cloud 和 oterm [278],这扩展了它在移动设备、云环境和本地环境中的部署能力。
不过,Ollama 更注重用户的可访问性,而非高级推理优化,这意味着它缺少内存优化、多 GPU 功能和多节点支持等特性。但作为补偿,它兼容性较强,不仅支持 NVIDIA GPU,还支持 AMD GPU 和 ARM 平台。
代表性特征总结
- 通用性【中等】:支持主流社区模型以及 NVIDIA 和 AMD GPU,但缺乏多 GPU 或边缘设备专用性。
- 易部署性【高】:通过 Homebrew、pip 或 Docker 可一键安装,设置极为简便。
- 易用性【中等】:简洁的 CLI 和 REST API,再加上 Open WebUI 等图形界面集成,降低了非专业人士的使用门槛。
- 延迟感知【中等】:未提供 Flash 或 KV 缓存优化,单令牌延迟较高。
- 吞吐量感知【中等】:仅在单 GPU 上运行,且无批处理策略,持续吞吐量受限。
- 可扩展性【中等】:专为本地单 GPU 使用而设计,无法扩展至多节点部署。
4.2 llama.cpp
llama.cpp [82] 是一个用于大型语言模型推理的 C++ 库,可在无 GPU 的情况下在 CPU 上运行模型。因此,它对外部软件的依赖极少,能在多种硬件架构上高效运行。它支持多种数据类型的量化(如 1.5 位、4 位、8 位),以减少内存使用并提高效率。
llama.cpp 还引入了 Georgi Gerganov 统一格式(GGUF)[80],用于简化大型语言模型的存储和部署。GGUF 将模型参数、结构和元数据整合到单个文件中,改进了 Georgi Gerganov 机器学习(GGML)[79] 格式,提供了更好的灵活性和兼容性。这种方式标准化了模型存储,简化了部署流程。
llama.cpp 支持 x86、ARM 和 NVIDIA GPU 等多种硬件平台,并使用 GGML 上下文配置这些后端。它提供硬件特定的内核和图形优化,以实现高效推理。此外,llama.cpp 通过子项目扩展了可用性,如用于命令行执行的 llama-cli、兼容 OpenAI API 的 HTTP 服务 llama-server,以及轻量级运行器 llama-run 和 llama-simple。
代表性特征总结
- 通用性【中等】:可在 x86、ARM CPU 和 NVIDIA GPU 上运行,支持多种量化格式,硬件覆盖范围较广。
- 易部署性【高】:单一静态二进制文件或最小化 CMake 构建,外部依赖几乎为零。
- 易用性【低】:虽有 CLI 辅助工具和类 OpenAI 服务器,但文档简洁且依赖社区支持。
- 延迟感知【中等】:可选的 FlashAttention 内核和 GPU 卸载功能,可降低高性能设备上的令牌延迟。
- 吞吐量感知【中等】:多线程和连续批处理提升了 CPU 吞吐量,但分布式支持有限。
- 可扩展性【低】:针对单节点执行进行了优化,缺乏原生集群功能。
4.3 vLLM
vLLM [125] 是一个高性能的大型语言模型服务库,专注于实现快速令牌生成和低延迟。其 PagedAttention 机制通过将 KV 缓存存储在非连续内存块中,提高了内存效率,避免了连续存储带来的碎片化问题。
vLLM 围绕用于异步请求处理的 AsyncLLM、兼容 OpenAI 的 API 服务器以及执行推理的 EngineCore 构建。基于 ZeroMQ [237] 的多进程 API 服务器实现了 AsyncLLM 和 API 层之间的操作重叠。EngineCore 包含调度和模型执行模块,能够并发处理 CPU 密集型任务(如令牌化、多模态输入管理和令牌解令牌化)以及主执行循环,从而提高吞吐量。其对称架构减少了进程间开销,并支持优化的张量并行性。
此外,vLLM 支持 FlashAttention-3 [215],以进一步降低推理延迟。它采用分布式系统架构分配多 GPU 工作负载,利用 MegatronLM 的张量并行性 [224]。除了 CPU 和 GPU 支持外,vLLM 还兼容 AWS Inferentia [15] 和 Google TPU [116],扩展了其在多模态推理中的能力。
代表性特征总结
- 通用性【高】:可在 GPU、TPU 和 AWS Inferentia 加速器上运行多种大型语言模型。
- 易部署性【高】:Docker 镜像和 pip 包简化了设置,但分布式配置仍需手动操作。
- 易用性【高】:兼容 OpenAI 的端点和活跃的社区,简化了应用集成。
- 延迟感知【中等】:FlashAttention-3 和 PagedAttention 有效降低了注意力计算延迟。
- 吞吐量感知【高】:AsyncLLM 调度和 ZeroMQ 多处理保持了较高的每秒令牌数。
- 可扩展性【高】:内置张量并行性,支持多 GPU 和多节点集群。
4.4 DeepSpeed-FastGen
DeepSpeed-FastGen [102] 是一款集成了微软 DeepSpeed Inference [18] 和 DeepSpeed 模型推理实现(MII)[176] 的大型语言模型推理引擎。它通过优化内存使用,实现了高效的模型推理。
DeepSpeed-FastGen 部署 DeepSpeed MII 作为其前端和后端,借助专用的查询 / 响应 API、连续批处理和模型管道等功能处理请求。在内部,它利用 DeepSpeed Inference 支持硬件优化内核(如 NVIDIA CUDA),以及 Blocked KV-Cache 和张量并行性。
其主要特色是 Dynamic SplitFuse 技术,该技术将长提示分割成更小的片段,并在多个前向传递中处理,从而提高吞吐量并减少延迟。通过保持一致的前向传递大小,系统处理效率得以提升。DeepSpeed-FastGen 还提供副本级负载均衡,将推理工作负载分布到多个节点。与单节点推理相比,多节点部署在查询处理方面可实现显著的速度提升。
代表性特征总结
- 通用性【中等】:DeepSpeed-MII 前端支持众多 HuggingFace 检查点和自定义模型。
- 易部署性【高】:提供容器化启动器,但仍需进行模型转换和注册。
- 易用性【高】:MII 风格的 API 清晰明了,但需要具备一定的 DeepSpeed 配置知识。
- 延迟感知【中等】:Dynamic SplitFuse 分割长提示,控制了最坏情况下的延迟。
- 吞吐量感知【高】:连续批处理、Blocked KV 缓存和张量并行性使 GPU 保持高利用率。
- 可扩展性【高】:副本级负载均衡支持高效的多节点服务。
4.5 Unsloth
Unsloth [244] 是一款专注于大型语言模型高效微调与推理的引擎。它通过低秩适应(LoRA)[105] 和量化 LoRA(QLoRA)[53] 等技术实现快速微调并减少内存使用,同时保持模型精度。所有内核均基于 OpenAI Triton [238] 实现,进一步提高了大型语言模型的执行速度。尽管 Unsloth 集成了 xFormers [172] 等模块以加速 Transformer 操作,但这种方式允许对注意力块和其他模块进行灵活定制,为多种使用场景提供了更强的适应性。
为了保证兼容性,Unsloth 支持 GGUF [80] 和 vLLM [125] 格式,并提供简单的 API 用于创建推理服务。然而,它目前仅在 NVIDIA GPU 上运行,且多 GPU 和多节点支持等高级优化功能仅在付费版本中提供。开源版本仅限于单 GPU 设置,支持的模型数量也有限。
代表性特征总结
- 通用性【低】:提供 GGUF 和 vLLM 模型格式,但目前仅限在 NVIDIA GPU 上运行。
- 易部署性【中等】:一次 pip 安装即可同时获得微调与推理功能。
- 易用性【中等】:高级 Python API 简单易用,但高级文档仍不完善。
- 延迟感知【中等】:Triton 融合内核缩短了注意力步骤,适度降低了令牌延迟。
- 吞吐量感知【低】:xFormers 集成有助于提升单 GPU 吞吐量;分布式执行需付费使用。
- 可扩展性【低】:开源版本仅在单 GPU 上运行,不包含多节点功能。
4.6 MAX
Modular Accelerated Xecution(MAX)[179] 是一个集成平台,旨在简化高性能 AI 端点的创建和部署,同时在多种硬件设置中保持灵活性。它提供图形编译器和运行时,能够通过硬件无关的库加速生成式 AI 模型。通过将模型编译为优化的计算图,MAX 提高了执行效率并减少了延迟,从而获得更好的性能。
MAX 基于 Mojo 编程语言 [178] 构建。Mojo 通过多级中间表示(MLIR)[128] 从 C、C++ 和 CUDA 中扩展 Python 的系统编程功能,使 CPU、GPU 和专用 AI 加速器能够实现高性能。
MAX 包含两个主要组件:MAX Engine(推理库和运行时)和 MAX Serve(模型部署服务工具)。MAX Serve 托管大型语言模型,并在本地和云环境中提供兼容 OpenAI API 的 REST 端点。它应用连续异构批处理和多步骤调度,以最大化 GPU 利用率并确保稳定性能,特别是对于大规模工作负载。在内部,MAX Serve 集成了 MAX Engine,该引擎利用其图形编译器和运行时在 CPU 和 GPU 上加速模型。
目前,MAX 支持在本地和云环境中处理推理工作负载,可在 CPU 和 NVIDIA GPU 上运行。
代表性特征总结
- 通用性【中等】:Mojo 的 MLIR 编译器从一个模型图面向 CPU、GPU 和未来的加速器。
- 易部署性【高】:提供 Docker 镜像和 CLI,但用户仍需将模型打包到 MAX Serve 中。
- 易用性【高】:REST 端点易于使用,但 Mojo 工具对新手而言尚处于初级阶段。
- 延迟感知【中等】:提前进行图形编译,融合内核并缩短关键路径。
- 吞吐量感知【中等】:连续异构批处理和多步骤调度使设备保持忙碌状态。
- 可扩展性【高】:可在本地和云机器上运行,支持实验性多 GPU。
4.7 MLC LLM
MLC LLM [177] 是一款用于大型语言模型的编译器和高性能部署引擎,旨在实现跨多个平台的模型开发、优化和部署。它不仅支持在 NVIDIA 和 AMD GPU 上进行推理,还支持在 iOS 和 Android 等移动设备和边缘设备上运行,将服务器和边缘环境统一为单一的大型语言模型引擎。所提供的 MLCEngine 在服务器环境中提供高吞吐量和低延迟,同时支持轻量级本地部署。
实现跨平台大型语言模型加速需要大量的 GPU 编程和运行时兼容性工作。为解决这一问题,MLC LLM 基于 Apache TVM [43] 构建,自动为每种硬件和平台生成 GPU 库。它集成了特定于大型语言模型的优化,如连续批处理 [280] 和推测解码 [131, 262],并采用 FlashInfer [276] 加速 NVIDIA GPU。MLC LLM 要么转换和量化基础模型权重,要么加载预转换的权重,使用 model-weights-mlc 模块进行算子融合、内存分配和硬件特定优化;然后,model-lib 组件为每个设备构建平台原生运行时。MLC LLM 提供多种部署模式,包括 Python API、兼容 OpenAI 的 API、REST 服务器和 WebLLM [214],确保在云和本地平台上具有广泛的可移植性。
代表性特征总结
通用性【中等】:单一引擎支持桌面、移动和 WebLLM 运行时,覆盖 NVIDIA 和 AMD GPU。
易部署性【高】:安装脚本自动为每个目标编译 TVM 内核。
易用性【中等】:Python 和 REST API 以及 Web 演示提供中等程度的集成难度。
延迟感知【中等】:FlashInfer 内核和连续批处理实现低延迟生成。
吞吐量感知【高】:推测解码和算子融合提高了 GPU 上的每秒令牌数。
可扩展性【中等】:为从边缘设备到云服务器生成原生运行时。
4.8 llama2.c
llama2.c [21] 是一款推理引擎,设计用于在单个 C 文件中运行小型基于 Llama2 [241] 的模型。它包含约 700 行 C 代码,能够加载用 PyTorch [201] 训练的模型进行推理。
该推理引擎专注于小规模领域,旨在用于教育用途,结构简单。它没有实现高级优化技术,仅包含大型语言模型推理所需的基本代码。并行处理仅限于基于 OpenMP 的多线程,且仅在 CPU 上运行,不支持 GPU 执行或分布式环境。
代表性特征总结
通用性【低】:仅在 CPU 上运行小型 Llama-2 检查点,用于教育和演示。
易部署性【低】:无需外部库,几秒钟即可编译,便于快速实验。
易用性【低】:约 700 行可读性强的 C 代码,易于学习和修改。
延迟感知【低】:仅存在基本的 OpenMP 线程处理,单令牌延迟较高。
吞吐量感知【低】:无批处理、GPU 支持或缓存管理,持续吞吐量低。
可扩展性【低】:专为单个 CPU 主机设计,无分布式或 GPU 使用途径。
4.9 bitnet.cpp
bitnet.cpp [251] 是一款在 1 位大型语言模型研究背景下开发的仅 CPU 推理引擎。它基于 llama.cpp [82] 构建,专注于三元模型(BitNet b1.58 [165])的快速、无损推理,同时最大限度地降低功耗。该项目提供三种内核类型(I2_S、TL1 和 TL2),针对 x86 和 ARM 处理器进行了优化。
I2_S 内核将全精度权重离线转换为两位格式,然后在推理期间恢复原始值,以加速通用矩阵 - 向量乘法(GEMV)操作。这种方法减少了内存和带宽需求,还提高了多线程系统的性能。TL1 内核将每两个权重压缩为一个四位索引,并采用基于 T-MAC [257] 方法的查找表(LUT),该表包含九个预计算的激活值,使大型模型即使在有限的线程环境中也能高效运行。TL2 将每三个权重压缩为一个五位索引,将模型大小缩小到 TL1 占用空间的六分之一,适用于内存或带宽受限的环境。
bitnet.cpp 仅支持本地 CPU 执行,并依赖多线程而非分布式并行来加速。除了 BitNet b1.58 [165],它还可以运行 Llama 3 8B [88] 和 Falcon 3 [64] 系列模型,但尚未支持更广泛的硬件平台或大规模分布式部署。
代表性特征总结
通用性【低】:仅在本地 CPU 上运行,支持的模型集较窄(BitNet b1.58 以及少数 Llama 3 和 Falcon 变体),因此整体硬件和模型多样性有限。
易部署性【中等】:作为自包含的 C++ 二进制文件提供,依赖项极少,几乎可在任何 x86 或 ARM 主机上快速安装。
易用性【低】:虽然 CLI 与 llama.cpp 非常相似,但文档和社区示例仍然稀少,增加了初次用户的学习难度。
延迟感知【低】:该引擎专注于减少内存带宽,而非专门的延迟技术;单令牌延迟仍由 CPU 核心速度决定。
吞吐量感知【低】:多线程 I2_S、TL1 和 TL2 内核使用 2 位至 5 位权重压缩,与全精度 CPU 基准相比,提高了 GEMV 吞吐量。
可扩展性【低】:所有加速都局限于一台多核服务器;不支持跨节点的多插槽或分布式执行。
4.10 SGLang
Structured Generation Language for LLMs(SGLang)[295] 是一个旨在高效执行大型语言模型的系统,旨在克服现有推理引擎的局限性,包括多模态输入处理、并行处理和 KV 缓存重用。为实现这一目标,SGLang 使用多调用结构,并引入了语言模型程序(LM Programs),支持各种模型类型(视觉、嵌入、奖励模型)以及多节点操作。
该推理引擎包括前端和后端(运行时),并提供兼容 OpenAI 的 API。SGLang 的前端用 Python 编写,允许使用常规控制流和库灵活编写 LM 程序,提高了开发人员的易用性。同时,后端应用执行优化,包括基于 RadixAttention 的 KV 缓存管理和带有压缩有限状态机的结构化解码,实现快速推理。这些方法使 SGLang 在吞吐量方面优于现有推理引擎,并在代理控制和逻辑推理等任务中表现出色。
SGLang 提供解释器和编译器。解释器将提示状态作为流进行管理,并异步处理基本操作,以提高同步性和并行性。它还跟踪程序执行路径,以便进行进一步的编译器优化。在将这些程序编译为计算图后,SGLang 图执行器重写图或建立静态执行计划。
为进一步优化,SGLang 采用零开销批处理调度器,类似于 NanoFlow 的纳米批处理策略 [300],以提高模型推理的并行性。它还具有缓存感知负载均衡器,提高前缀缓存命中率,从而提升整体吞吐量。
代表性特征总结
通用性【中等】:语言模型程序管理多模态模型并支持多节点执行。
易部署性【高】:使用前需要源代码编译和 CUDA 工具链配置。
易用性【中等】:Python 领域特定语言灵活,但引入了基于流的语义,存在一定学习曲线。
延迟感知【中等】:RadixAttention 和压缩有限状态解码降低了尾部延迟。
吞吐量感知【中等】:零开销批处理调度器最大限度地提高了操作重叠,实现了极高的吞吐量。
可扩展性【高】:缓存感知负载均衡支持集群执行,尽管工具仍在完善中。
4.11 LitGPT
LitGPT [145] 是一个端到端框架,涵盖微调、推理、测试和部署。它基于 nanoGPT [20]、Lit-LLaMA [144] 和 Lightning Fabric [143] 构建,支持预训练模型以实现快速原型设计。
LitGPT 可从单 GPU 扩展到多 GPU 和多节点环境,通过完全分片数据并行(FSDP)[292] 提供分布式并行性,并借助 FlashAttention-2 [50] 实现更快的计算。该框架还通过量化 [61] 和 LoRA [105] 进行内存和速度优化,并且可以通过 PyTorch/XLA 编译器 [208] 在 Google TPU 上运行大型语言模型。
代表性特征总结
- 通用性【低】:支持 NVIDIA GPU、AMD Instinct 和 Google TPU,但主要针对 NVIDIA GPU 进行了优化。
- 易部署性【中等】:可通过 pip 轻松安装,并提供预构建包。
- 易用性【中等】:提供简要手册,并通过论坛和聚会维持社区交流。
- 延迟感知【中等】:借助 FlashAttention-2、推测解码和 KV 缓存减少响应时间。
- 吞吐量感知【中等】:通过 FSDP 和批处理优化提高整体吞吐量。
- 可扩展性【高】:可从单 GPU 设置扩展到多 GPU 和多节点部署。
4.12 OpenLLM
OpenLLM [30] 是一个平台,通过简单命令即可轻松执行和部署开源大型语言模型和自定义模型。作为旨在克服 Ollama [194] 等现有平台在可扩展性和高负载问题上的云基解决方案,OpenLLM 以多用户支持、高吞吐量和低延迟为目标。这使其非常适合在云和本地服务器上部署大型语言模型以及构建基于大型语言模型的应用程序。其一个关键优势是通过自带云(BYOC)模型实现的数据安全性。
OpenLLM 提供兼容 OpenAI 的 API 服务器,简化了大型语言模型的执行,并采用 vLLM [125] 和 BentoML [29] 作为后端,以在大规模环境中保持高吞吐量。它使用 BentoML 开发的自定义文件格式 Bento,将源代码、模型、数据文件和依赖项打包到一个实体中。这些 Bento 对象可以转换为容器镜像,便于部署。
代表性特征总结
- 通用性【低】:结合 vLLM 和 BentoML 后端,可在云中运行各种开源模型。
- 易部署性【中等】:一条命令即可将模型转换为可在任何 BYOC 环境中部署的 Bento 镜像。
- 易用性【低】:CLI、Web UI 和类 OpenAI 端点大大缩短了应用集成时间。
- 延迟感知【低】:vLLM 的 FlashAttention 降低了核心延迟;可能仍存在额外的云开销。
- 吞吐量感知【中等】:Bento 容器持续批处理请求并横向扩展。
- 可扩展性【中等】:内置多租户支持,而多节点 GPU pod 需要自定义编排。
4.13 TensorRT-LLM
TensorRT-LLM [191] 是一款旨在优化 NVIDIA GPU 上推理的推理引擎,是 NVIDIA 的 NeMO [122] 端到端生成式 AI 开发生态系统的一部分。它包括编译和优化库,以提高模型推理性能。在编译过程中,TensorRT [189] 编译器分析计算图以选择最佳内核,并将它们融合以最小化内存开销。这可以最大限度地利用 CUDA 内核和 Tensor 核心,并支持各种低精度操作以实现更快的推理。
可使用 NVIDIA NeMo 或 PyTorch [201] 训练用于推理的模型,或从 Hugging Face 等平台获取预训练权重,并且必须使用模型定义 API 转换为与 TensorRT 兼容的格式。尽管 TensorRT-LLM 主要使用 TensorRT 作为其后端,但它还包括用于 NVIDIA Triton 推理服务器 [187] 的 Python 和 C++ 后端,提供端到端的在线大型语言模型部署解决方案。PyTorch 后端处于实验阶段。在 NVIDIA Collective Communication Library(NCCL)[186] 的支持下,TensorRT-LLM 通过多 GPU 环境中的张量并行和管道并行提供分布式推理。为了优化服务,飞行中批处理动态地将传入请求分组。
为了克服多节点环境中基于环的 All-Reduce 拓扑的性能限制,TensorRT-LLM 引入了一种多轮方法,利用 NVSwitch 的多播功能,将延迟降低多达 3 倍。然而,TensorRT-LLM 仅限于 NVIDIA GPU,限制了硬件的可扩展性。
代表性特征总结
- 通用性【低】:专门针对 NVIDIA GPU,硬件多样性有限。
- 易部署性【高】:尽管有辅助脚本,但模型转换和 Triton 后端注册增加了设置步骤。
- 易用性【高】:存在 Python 和 C++ 示例代码,但熟悉 NeMo 和 Triton 会有所帮助。
- 延迟感知【中等】:Tensor 核心上的内核融合提供了极低的单令牌延迟。
- 吞吐量感知【高】:飞行中批处理和管道并行在大型模型上保持高吞吐量。
- 可扩展性【高】:NVSwitch 多播和 NCCL 支持高效的多 GPU 和多节点部署。
4.14 Hugging Face TGI
Hugging Face Text Generation Inference(TGI)[110] 是一个用于部署和服务大型语言模型的工具包,支持各种推理工作负载,并与 vLLM [125] 和 TensorRT-LLM [191] 等后端集成。它适应各种硬件平台,包括 NVIDIA GPU、AWS Inferentia [15] 和 Intel Gaudi [118],让用户可以为其硬件选择合适的后端。TGI 的后端用 Rust 构建,支持流式传输和并发,高效处理大量大型语言模型流量。
TGI 包括三个关键组件:路由器、启动器和模型服务器。路由器是一个 HTTP 服务器,管理客户端请求(支持 Hugging Face 的自定义 API 和 OpenAI 消息 API),通过队列、调度器和内存块分配器对传入请求进行批处理。启动器启动一个或多个模型服务器,并根据来自路由器的参数对模型进行分片。模型服务器 —— 用 Python 实现 —— 接收基于 Google 远程过程调用(gRPC)[90] 的模型加载和推理请求。
为了优化推理,TGI 采用量化、RoPE 缩放 [155]、Safetensors [108] 和 Zero Config,可根据硬件和模型自动配置。它还利用 Flashinfer [276] 和 Flashdecoding [103] 在长提示上实现快速性能。为了可观测性,它与 Prometheus [243] 和 Grafana [39] 等工具连接。在多个设备上运行模型时,TGI 使用 NVIDIA NCCL [186] 进行同步。尽管它支持多设备推理的张量并行性,但目前只有某些大型语言模型兼容。
代表性特征总结
- 通用性【中等】:可更换的 vLLM 或 TensorRT-LLM 后端涵盖 NVIDIA、Inferentia 和 Gaudi 硬件。
- 易部署性【高】:单个启动器自动配置硬件并下载模型权重。
- 易用性【中等】:支持自定义 HF API 和 OpenAI 消息,带有内置监控钩子。
- 延迟感知【中等】:FlashInfer 和 Flashdecoding 加速长序列生成。
- 吞吐量感知【中等】:路由器和调度器持续批处理输入以应对高请求量。
- 可扩展性【高】:模型分片和 NCCL 允许跨节点进行多 GPU 服务。
4.15 PowerInfer
PowerInfer [227] 是通过扩展 llama.cpp [82] 构建的大型语言模型推理系统,旨在在单个消费级 GPU 上运行大型语言模型。不使用模型压缩技术运行大型语言模型通常会导致精度损失和内存限制。CPU-GPU 卸载方法遭受高 PCIe 延迟,这会减慢推理速度。此外,推测解码在小批量大小时效率低下,并且可能降低模型性能。
为了解决这些限制,PowerInfer 利用了大型语言模型中神经元激活遵循幂律分布的观察结果。它将频繁激活的神经元(热神经元)与不太活跃的神经元(冷神经元)分开。热神经元加载到 GPU 上进行快速计算,而冷神经元则在 CPU 上处理。这种设计减少了 GPU 内存使用,并最大限度地减少了 CPU-GPU 数据传输。PowerInfer 使用离线分析步骤,根据神经元的激活频率识别热神经元和冷神经元,并使用在线预测器确定每个输入激活哪些神经元。
PowerInfer 采用混合方法进行推理,包括离线和在线组件。在离线阶段,它分析神经元激活模式(Insight-1),并使用激活数据将神经元分为热和冷类别。然后,它通过整数线性规划(ILP)执行神经元分配优化,以最大限度地提高内存利用率。在在线组件中,根据预定义的策略将神经元分配给 GPU 或 CPU,并通过 GPU 和 CPU 执行器进行分布式计算。
PowerInfer 还引入了神经元感知稀疏算子,以克服现有稀疏计算库的局限性。这些算子可以直接处理神经元级别的不规则张量,无需格式转换,并且针对 GPU 和 CPU 执行进行了优化。
因此,PowerInfer 能够在不将模型完全加载到 GPU 内存中的情况下实现高效的大型语言模型推理,使其成为内存受限的本地环境的实用解决方案。
最近,PowerInfer-2 [270] 已被提出,以将这种方法进一步扩展到智能手机等移动设备。PowerInfer-2 将 PowerInfer 的功能扩展到涉及内存受限的移动设备的场景。依靠相同的热 - 冷神经元算法,它按神经元集群划分矩阵运算,并在 CPU 和 NPU 之间高效分配它们,实现 I/O 管道优化以加快推理速度。在离线阶段,PowerInfer-2 生成适应神经元激活模式、硬件约束和批量大小的执行计划。在在线推理阶段,它使用神经元缓存以及基于 NPU 的预填充阶段和 CPU-NPU 混合解码阶段,从而提高整体性能。
代表性特征总结
- 通用性【低】:扩展 llama.cpp 用于单个消费级 GPU 和桌面场景。
- 易部署性【低】:预构建的 Docker 镜像简化了在一个 GPU 上的设置。
- 易用性【低】:提供基本脚本,但神经元级调优仍然需要手动操作。
- 延迟感知【中等】:热 - 冷神经元分离消除了一些传输,但 PCIe 开销仍然存在。
- 吞吐量感知【中等】:神经元感知稀疏算子适度提高每秒令牌数。
- 可扩展性【低】:专为具有 CPU 辅助的单个 GPU 设计,没有集群能力。
4.16 LMDeploy
LMDeploy [162] 是一个推理和服务引擎,集成了多种优化技术,包括连续批处理 [280]、动态拆分和融合以及高性能 CUDA 内核。除了促进高效推理外,它还提供量化、微调以及跨多台机器和卡的多模型服务等功能,能够在各种情况下简单有效地部署服务。
为了支持交互式大型语言模型推理中的高吞吐量,LMDeploy 提供了一个名为 TurboMind 的引擎,该引擎基于 NVIDIA FasterTransformer [188] 构建。TurboMind 包括高效的大型语言模型实现、Persistent Batch 模块和 KV Cache Manager,所有这些都可通过简单的 API 访问。Persistent Batch 模块通过固定数量的批处理槽管理连续批处理。当请求到达时,它占用这些槽之一,完成后,槽被释放。同时,KV Cache Manager 作为内存池,应用最近最少使用(LRU)策略来决定在需要额外内存时驱逐哪个序列缓存。
除了 TurboMind,LMDeploy 还提供了一个名为 lmdeploy.pytorch 的开发者友好型引擎,该引擎提供类似 PyTorch 的环境,同时共享与 TurboMind 相同的服务接口。它通过由三个组件组成的 Engine 对象执行模型加载、适配器集成、缓存管理和并行处理。ModelAgent 封装模型,Scheduler 处理资源分配和序列跟踪,RequestManager 管理请求的输入和输出。特别是,Scheduler 使用类似于 vLLM 的 PagedAttention [125] 的机制来根据序列长度分配和释放块,并支持 S-LoRA [219],使多个 LoRA 适配器能够在有限的内存中运行。
尽管 LMDeploy 同时具有用于高性能推理的 TurboMind 和用于更轻松开发的 lmdeploy.pytorch,但它目前仅支持 NVIDIA GPU 环境。
代表性特征总结
- 通用性【低】:包括 TurboMind 和 PyTorch 引擎,但仍仅限 NVIDIA。
- 易部署性【高】:Docker 镜像和服务脚本简化了安装,尽管需要匹配驱动程序。
- 易用性【中等】:统一的 API 在高性能模式和开发模式之间切换。
- 延迟感知【中等】:KV 缓存 LRU 和动态拆分融合显著降低了提示延迟。
- 吞吐量感知【中等】:持久批处理和连续调度使 GPU 保持满负荷。
- 可扩展性【高】:支持每个节点多个 GPU;多节点编排仍处于实验阶段。
4.17 LightLLM
LightLLM [142] 是一个基于 Python 的轻量级且高度可扩展的大型语言模型推理引擎,旨在解决现有解决方案中的性能、调度和内存效率问题。它采用三进程异步协作方法,将令牌化、模型推理和去令牌化分开,以提高 GPU 利用率。
LightLLM 用 TokenAttention 取代了 PagedAttention [125],并引入了高效路由器调度。LightLLM 使用高效路由器根据处于预填充还是解码阶段,在令牌级粒度上管理 GPU 内存。该路由器采用自定义算法对令牌进行适当的批处理。此外,调度和模型推理阶段合并,消除了调度器和模型 RPC 之间的通信开销。LightLLM 还集成了 OpenAI Triton [238] 以优化服务调度内核。
推理引擎由多个模块组成,每个模块作为单独的进程运行(例如,Metric Server、Health Server、HTTP Server、Router)。这些模块通过 ZeroMQ [237] 或 RPC 进行通信。Cache Manager 存储多模态推理结果,而 Visual Server 处理多模态请求。
LightLLM 还具有 CacheTensorManager 类来处理 Torch 张量的分配和释放。通过在运行时最大化层间张量共享并允许不同 CUDA 图之间的内存共享,它减少了整体内存使用。ModelBackend 定义了处理来自路由器的预填充或解码请求所需的机制和操作。每个后端维护自己的模型对象,支持多个后端并行存在。模型类在设备上执行计算,并包括张量并行支持。
代表性特征总结
- 通用性【低】:TokenAttention 后端为 NVIDIA GPU 提供轻量级占用空间。
- 易部署性【高】:手动源代码构建和自定义依赖项增加了设置复杂性。
- 易用性【中等】:多进程 ZeroMQ 架构和最少的文档增加了学习难度。
- 延迟感知【中等】:Triton 优化的内核和路由器融合缩短了关键路径延迟。
- 吞吐量感知【中等】:高效的路由器调度和内存共享保持较高的 TPS。
- 可扩展性【中等】:多个后端可以同时运行;集群扩展是手动的。
4.18 NanoFlow
NanoFlow [300] 是一款高性能推理引擎,通过引入纳米批处理并支持设备内并行的操作协同调度来提高大型语言模型吞吐量。传统系统按顺序处理管道,通常未充分利用硬件资源。
通过将批处理分成更小的纳米批处理,NanoFlow 提高了优化灵活性。它还可以估计 GPU 内存使用情况,以检查是否可以容纳额外的请求。如有必要,它会将 KV 缓存数据卸载到较低的内存层(如系统内存或磁盘),最大限度地提高整体资源使用率。
为了实现纳米批处理,NanoFlow 将大型语言模型服务操作分为三类:内存密集型操作(如自注意力计算)、计算密集型操作(如通用矩阵乘法(GEMM))和网络密集型操作(如 AllReduce)。然后分析每个操作的资源需求以及相应的迭代或延迟,以确定性能特征和瓶颈。基于这些发现,NanoFlow 最大限度地提高硬件并行性以实现更高的吞吐量。
NanoFlow 由三个主要组件组成。全局批处理调度器收集所有传入请求,创建高性能大小的密集批处理(通过离线分析确定),并使用连续批处理 [280] 技术动态填充这些批处理。它还应用分块预填充 [9] 操作和离散批处理方法,仅选择被确定为最佳的批处理大小,而不是任意大小。通过优先考虑吞吐量而不是仅关注延迟,这种方法利用可用内存并行处理更多请求。
接下来,设备内并行引擎支持纳米批处理的细粒度并行操作,以及执行单元调度以减少任务之间的干扰。最后,KV 缓存管理器监督每个请求的解码状态,估计未来的内存使用情况(假设平均解码长度),并管理 GPU 内存以防止内存不足问题。如果预测的使用量不超过 GPU 限制,则接受请求;否则,将其延迟。
然而,NanoFlow 的纳米批处理机制需要额外的设置(如每个模型的调度优化),并且可能需要管道调整或为新模型重新实现内核。它还引入了开销,可能由于更小的批处理大小而降低单个操作的效率,并且仍然依赖于 NVIDIA GPU。
代表性特征总结
- 通用性【低】:仅在 NVIDIA GPU 上运行,需要每个模型的纳米调度调整。
- 易部署性【低】:研究级代码需要自定义调度文件和环境调整。
- 易用性【低】:稀疏的文档和管道修改限制了可访问性。
- 延迟感知【中等】:内存预测和 KV 卸载避免了 OOM 停顿,间接减少了延迟。
- 吞吐量感知【中等】:纳米批处理加上设备内并行性极大地提高了吞吐量。
- 可扩展性【中等】:限于单个节点,没有分布式调度。
4.19 DistServe
DistServe [297] 是一个服务系统,旨在在多个 GPU 集群上高效运行大型语言模型推理,同时保持低延迟。它将大型语言模型推理请求分解到细粒度级别,以实现并行执行,从而提高吞吐量和资源利用率。传统的推理引擎在单个设备上处理预填充和解码,导致资源干扰和管道效率低下。通过将它们解耦并通过 SwiftTransformer [222] 应用操作内和操作间并行化,DistServe 减少了开销。
DistServe 还解决了大型模型大小的问题,例如 1750 亿参数的模型可能需要 350GB 的内存。它使用低节点亲和性放置算法进行批处理分配,在给定阶段的计算保留在同一节点上时依赖 NVLink。在线调度进一步实时管理工作负载,以满足延迟 SLO 要求。
DistServe 由批处理算法模块、RESTful API 前端、编排层和并行执行引擎组成。批处理模块提供模拟器和算法,根据特定模型和集群设置优化地分配请求。RESTful API 前端支持兼容 OpenAI 的接口,并接受用户输入,如最大输出长度和温度。编排层管理预填充和解码实例,处理请求调度,并协调 KV 缓存传输。对于节点间 GPU 通信,DistServe 使用 NCCL [186],而节点内传输依赖异步内存复制。各个实例通过 Ray [181] 作为 GPU 工作器运行,由并行执行引擎驱动。
由于 DistServe 旨在用于大型 GPU 集群,其并行策略和资源分配可能难以适应更小规模或资源受限的设置(例如,单个或少数 GPU 系统),这可能会限制这些场景下的性能。
代表性特征总结
- 通用性【低】:针对跨多 GPU 集群的超大型模型。
- 易部署性【低】:需要 Ray 集群设置和 NVLink 拓扑感知。
- 易用性【低】:放置算法调优和编排增加了操作员的复杂性。
- 延迟感知【中等】:解耦的预填充和解码阶段减少了负载下的尾部延迟。
- 吞吐量感知【高】:操作内和操作间并行化加上低节点亲和性批处理最大化吞吐量。
- 可扩展性【高】:专为多节点集群设计,可扩展到数百个 GPU。
4.20 vAttention
vAttention [206] 是一款用于在大型语言模型推理期间动态管理 KV 缓存内存的推理引擎。它基于 Sarathi-Serve [9] 构建,包括 sarathi-lean、vattention 内存分配器和自定义统一虚拟内存(UVM)驱动程序等组件。这些元素支持 PagedAttention [125] 和 vAttention 风格的内存管理。
vAttention 解决了与 PagedAttention 中的虚拟连续性相关的复杂性和性能限制 ——PagedAttention 在基于 Transformer 的大型语言模型中常用。它提高了性能(特别是在预填充受限的工作负载中),同时保持与现有内核的兼容性。为实现这一点,vAttention 修改了 PyTorch [201] 缓存分配器,引入虚拟张量,从一开始就保留虚拟内存缓冲区,而不分配物理内存。
与 PagedAttention 不同,在 PagedAttention 中,大型语言模型服务系统必须手动处理 KV 缓存和动态内存块之间的映射,vAttention 集成了内存分配和计算,并支持预测性页面分配。它通过低级 CUDA API(而不是 cudaMalloc)分离虚拟和物理内存使用,并通过 FlashAttention-3 [215] 支持针对 NVIDIA 的 Hopper 架构的优化,将其限制在 NVIDIA GPU 上。
vAttention 实现为一个 Python 库,它包装了与 CUDA 驱动程序接口的 CUDA/C++ 扩展库。在模型服务期间,每个工作器根据模型参数和页面组大小设置 vAttention,根据需要分配虚拟张量。它在启动内核之前检查 KV 缓存是否映射到物理内存,在预填充和解码期间跟踪页面分配。只有当所有当前页面都被使用时,它才会分配新页面,并且一旦请求结束,就会释放或回收页面。
代表性特征总结
- 通用性【低】:专为 NVIDIA Hopper GPU 量身定制,可移植性有限。
- 易部署性【低】:CUDA 驱动程序补丁和自定义 UVM 设置使安装复杂化。
- 易用性【低】:实验性包装器和最少的文档阻碍了快速采用。
- 延迟感知【中等】:预测性页面分配隐藏了内存映射成本并加快了预填充。
- 吞吐量感知【中等】:集成的 KV 内存和计算路径提供适度的增益。
- 可扩展性【中等】:目前仅支持单节点、单 GPU 执行。
4.21 Sarathi-Serve
Sarathi-Serve [8] 是一个基于 vLLM [125] 构建的高性能推理调度器,旨在解决大型语言模型推理中的吞吐量与延迟权衡问题。它依赖 FlashAttention-2 [50] 和 FlashInfer [276] 作为后端,以提高多 GPU 和多节点环境中的解码阶段吞吐量。
以前的系统,如 Orca [280] 和 vLLM [125],面临生成停顿(由于长时间预填充导致解码请求等待)和管道效率低下(由于请求级并行性不足导致 GPU 资源未充分利用)的问题。Sarathi-Serve 通过分块预填充和无停顿调度解决了这些问题,减少了 TBT,同时提供高吞吐量和最小的 TBT 延迟。
Sarathi-Serve 根据 TBT SLO 和分块预填充开销决定每个批处理中的最大令牌数(令牌预算)。在严格的延迟要求下,它设置较小的令牌预算并将提示分成更小的块,以降低尾部延迟为代价,牺牲一些整体系统效率。在较宽松的延迟约束下,它提高令牌预算以提高预填充效率。使用 2048 或 512 等令牌预算,Sarathi-Serve 为各种 SLO 条件提供高效推理。
代表性特征总结
- 通用性【低】:将 vLLM 调度扩展到多个模型类别。
- 易部署性【低】:简单的 CLI 启动服务器,但 CUDA 和 NCCL 版本必须对齐。
- 易用性【低】:交互式 SLO 滑块允许用户轻松权衡延迟和吞吐量。
- 延迟感知【中等】:分块预填充和无停顿调度使 TBT 始终较低。
- 吞吐量感知【中等】:令牌预算批处理适应工作负载以实现最大吞吐量。
- 可扩展性【中等】:通过 FlashAttention-2 支持多 GPU 和多节点部署。
4.22 Friendli Inference
Friendli Inference [71] 是一款基于 Orca [280] 构建的商业大型语言模型推理引擎,旨在通过迭代批处理等功能增强推理。它通过 Friendli Container 和 Friendli Serverless/Dedicated Endpoints 支持基于 Web 和 API 的服务,后者通过管理流量和遵守服务级别协议(SLA)专注于稳定服务。用户可以将 Friendli AI 解决方案与 Amazon SageMaker [16] 和 gRPC [90] 推理服务器集成,同时通过 Grafana [39] 等工具进行监控。
为了优化,Friendli Inference 允许在单个 GPU 上服务多个 LoRA [105] 模型,最大限度地利用不同的用户定义模型。它引入了 TCache,这是一种 GPU 负载减少技术,通过缓存频繁访问的结果来保持与传统框架相比更高的 TTFT。还使用量化技术进一步提高推理性能。然而,Friendli Inference 主要针对 NVIDIA GPU,限制了其在其他硬件平台上的支持。
代表性特征总结
- 通用性【低】:专注于在 NVIDIA GPU 上托管多个 LoRA 模型。
- 易部署性【高】:容器和无服务器选项以及 SageMaker 集成简化了推出。
- 易用性【中等】:带有 Grafana 指标的 Web 控制台简化了监控和管理。
- 延迟感知【中等】:TCache 降低了首次令牌生成时间,但未描述更深层次的延迟工具。
- 吞吐量感知【中等】:迭代批处理和量化提供强大的每秒令牌性能。
- 可扩展性【中等】:专用和无服务器 GPU 实例横向扩展,但缺乏非 GPU 后端。
4.23 Fireworks AI
Fireworks AI [67] 是一个推理平台,用于快速高效地服务大型语言模型和图像模型,支持推理、微调和部署。它提供简单的界面和 API—— 与 LangChain [126] 和 OpenAI API 等服务兼容 —— 并且可以在无服务器、按需或企业环境中运行。除了 NVIDIA GPU 外,Fireworks AI 还支持在 AMD Instinct MI300X [225] 上进行大型语言模型推理,扩大了其硬件兼容性。
为了满足不同的吞吐量和延迟需求,Fireworks AI 使用多种并行化和优化技术,包括多 / 组查询注意力优化、分片、量化和连续批处理。它提供专门为低延迟、高吞吐量或长输入 / 输出序列量身定制的部署配置。特别是,Fireworks AI 采用自己的 MQA [218] 模型和自定义 CUDA 内核(FireAttention)来进一步加速推理。
为确保服务可靠性,Fireworks AI 获得了 SOC 2 Type II [10] 和 HIPAA [169] 认证,确保隐私、安全性、可用性、处理完整性和机密性。
代表性特征总结
- 通用性【低】:在 NVIDIA GPU 和 AMD MI300X 加速器上服务大型语言模型和视觉模型。
- 易部署性【高】:云控制台提供 API 密钥和用于推理或微调的快速模板。
- 易用性【中等】:兼容 OpenAI 的端点和 LangChain 适配器减少了集成工作。
- 延迟感知【中等】:FireAttention 内核和低延迟部署配置最大限度地减少了响应时间。
- 吞吐量感知【中等】:多查询注意力、分片和连续批处理提供高 TPS。
- 可扩展性【高】:无服务器和企业集群弹性扩展,符合 SOC 2 和 HIPAA 标准。
4.24 GroqCloud
GroqCloud [89] 是一个 AI 基础设施平台,通过专门的硬件架构和软件栈专注于为大型语言模型提供高性能、低延迟的推理。它旨在通过提供由 Groq 语言处理单元(LPU)[3, 4] 支持的推理服务来解决传统 GPU 系统中常见的瓶颈和非确定性行为。Groq LPU 专为 AI 推理而构建,比传统 GPU 实现更低的延迟和更高的吞吐量。其张量流处理器(TSP)架构 [4] 在编译时静态调度和锁定模型执行路径,消除了运行时可变性,并实现可预测的响应时间。
Groq LPU 的一个关键优势是即使在批处理大小为 1 的情况下也能保持最佳性能,使其非常适合金融交易和自动驾驶等对延迟敏感的应用。通过其 TruePoint 技术,Groq LPU 在使用 FP16 或 INT8 计算时提供接近 FP32 的精度。对于高吞吐量工作负载,GroqCloud 提供异步批处理 API、用于可扩展吞吐量的 Flex Processing 以及确定性服务质量(QoS)调度,以满足各种 SLA。此外,其无内核编译器方法消除了手动内核优化的需要,简化了开发并降低了维护开销。
然而,由于 GroqCloud 依赖静态编译,它在动态调整批处理大小或处理复杂的运行时分支方面可能灵活性有限。
代表性特征总结
- 通用性【低】:仅在 Groq LPU 上运行,硬件灵活性有限。
- 易部署性【高】:完全托管的云 API 隐藏了所有编译和运行时细节。
- 易用性【低】:确定性 QoS 和简单的 REST 调用便于快速集成。
- 延迟感知【低】:TSP 架构即使在批处理大小为 1 时也能产生亚毫秒级延迟。
- 吞吐量感知【中等】:Flex Processing 在不影响单个请求延迟的情况下保持高吞吐量。
- 可扩展性【高】:LPU pod 在相同的确定性调度下横向扩展。
4.25 Together Inference
Together Inference [239] 是 Together AI 平台的一部分,提供高性能的大型语言模型推理,强调速度、成本和准确性。为了增强大型语言模型服务,它实现了变压器优化的 CUDA 内核、量化 [61] 和推测解码 [131]。Together Inference 提供不同的模型配置,以满足各种需求,从最高性能和全精度准确性到更低的成本和更高的吞吐量。它支持专用实例、无服务器部署和多 GPU 环境;然而,它专为基于 NVIDIA GPU 的服务进行了优化。
代表性特征总结
- 通用性【低】:提供多个精度与成本层级,但仅在 NVIDIA GPU 上。
- 易部署性【高】:通过 Web UI 提供无服务器端点和专用实例。
- 易用性【中等】:类 OpenAI API 简化了现有客户端的迁移。
- 延迟感知【中等】:推测解码和自定义 CUDA 内核减少了中位数和尾部延迟。
- 吞吐量感知【低】:量化、优化的注意力和连续批处理显著提高了 TPS。
- 可扩展性【高】:多 GPU 实例垂直扩展;添加端点可实现水平增长。
5 大型语言模型推理优化(LLM Inference Optimization)
大型语言模型的推理性能不仅取决于模型大小和硬件环境,还取决于各种推理优化技术。前面介绍的专用大型语言模型推理引擎通过采用并行化、高效内存管理、内核优化和量化等方法,追求低延迟和高吞吐量。
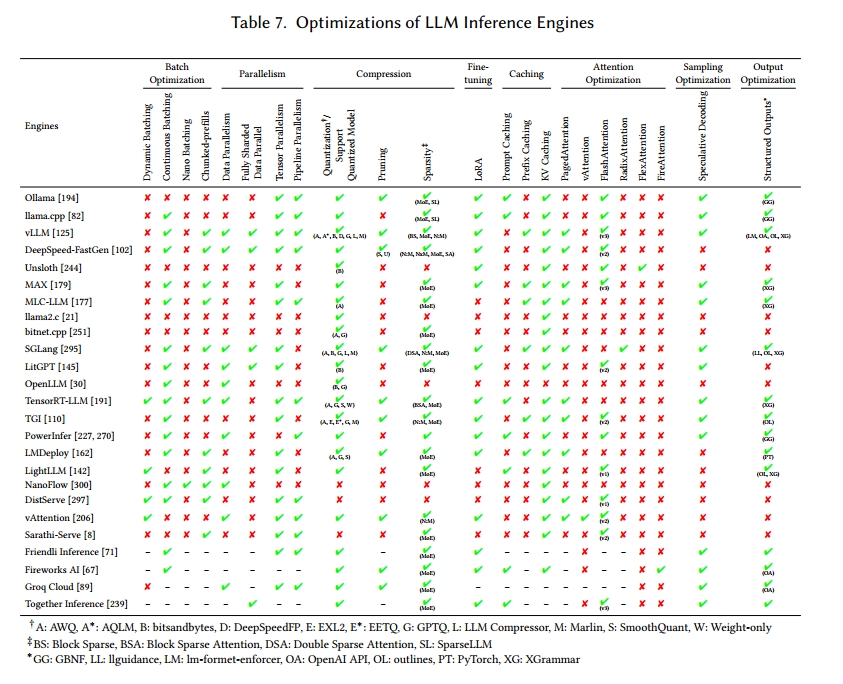
本节将阐述关键的推理优化策略,包括并行处理、内存优化、延迟和吞吐量优化。除了现有推理引擎提供的方法外,我们还将探讨最近关于推理优化的研究成果。表 7 总结了每个大型语言模型推理引擎支持的优化技术。
5.1 批处理优化(Batch Optimization)
在大型语言模型推理中,批处理将多个输入请求组合起来同时处理,从而提高硬件利用率和吞吐量。高效的批处理对于最大限度地提高计算并行性和减少延迟至关重要。
因此,找到最佳批处理大小至关重要。较小的批处理大小会减少响应时间,但可能未充分利用硬件资源;而较大的批处理大小会产生更高的吞吐量,但可能导致更长的响应时间。已有多种方法被提出用于选择最佳批处理大小 [95, 202, 220],推理引擎通常会提供一些机制,根据工作负载和服务级别目标来探索最佳批处理大小。
除了批处理大小外,调度方法也对推理性能有显著影响。如图 9(a)所示,静态批处理处理固定数量的请求,新请求可能需要等待当前批处理完成,这可能会增加延迟。相比之下,动态批处理 [13, 49] 和连续批处理 [99, 280] 会实时调整批处理,通常能减少延迟并提高整体效率。
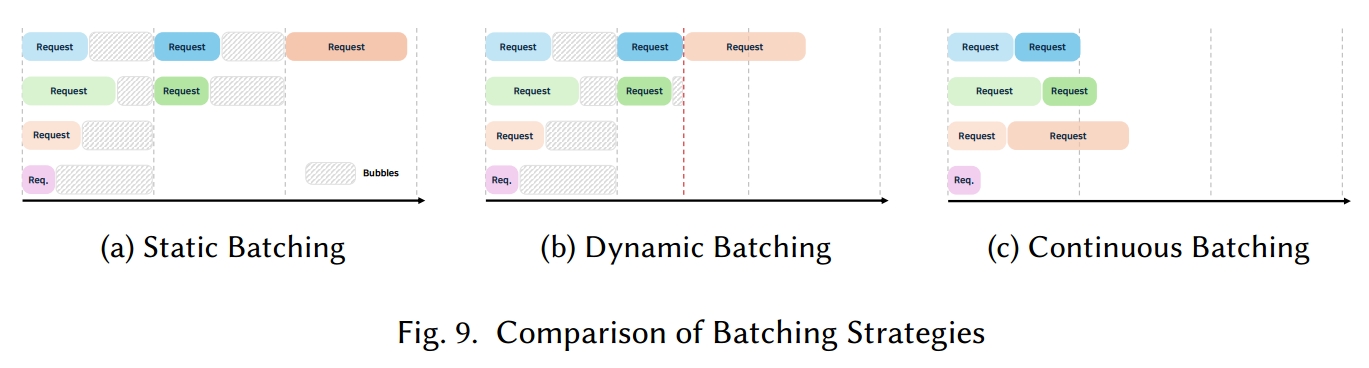
5.1.1 动态批处理(D ynamic Batching)
动态批处理 [13, 49] 缓解了静态批处理的延迟和硬件利用率不足问题。如图 9(b)所示,新请求会立即添加到正在进行的批处理中,从而实现更灵活、更高效的推理。
与静态批处理不同,动态批处理会根据传入的请求和可用的硬件资源重新构建批处理,自适应地确定批处理大小。当新请求到达时,它可以与现有批处理合并或附加到正在进行的过程中,以优化资源使用。
要有效实现动态批处理,必须调整几个参数,包括最大批处理等待时间、最小批处理大小和批处理大小限制。尽管动态批处理可以通过实时减小批处理大小来最小化延迟,但新请求只能在当前批处理完成后才能添加。如果请求的提示或输出令牌长度差异很大,动态调整批处理大小可能会带来开销并降低性能。
5.1.2 连续批处理(Continuous Batching)
连续批处理 [99, 280] 与动态批处理 [13, 49] 类似,但允许新请求不间断地加入正在进行的批处理,从而最大限度地减少延迟。图 9(c)展示了如何不断插入请求以最大限度地提高 GPU 和内存效率。
Orca [280] 通过迭代级调度和选择性批处理实现连续批处理。迭代级调度在每次迭代时形成批处理,同时实时容纳新请求。选择性批处理仅关注可批处理的 Transformer 操作,为已完成的请求提供即时结果,并减少平均响应时间和等待时间。
然而,连续批处理需要复杂的调度,确保新请求可以在不干扰正在进行的处理的情况下集成进来。高效的 KV 缓存管理至关重要,通常涉及分页注意力 [125] 等方法。像 llama.cpp [82]、DeepSpeed-FastGen [102] 和 vLLM [125] 等推理引擎都使用源自 Orca 的连续批处理技术。
5.1.3 纳米批处理(Nano-batching)
纳米批处理由 NanoFlow [300] 提出,通过在单个设备上并行运行计算、内存和网络密集型操作,最大限度地提高资源利用率和吞吐量。传统的推理引擎在请求级别对任务进行批处理,而 NanoFlow 则在操作级别对其进行划分,如图 10 所示。
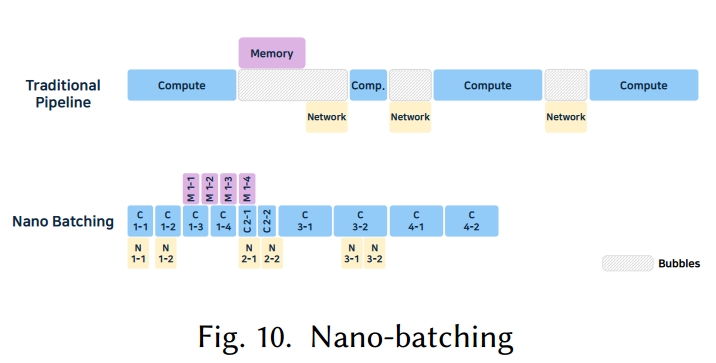
操作单元包括注意力和 KV 生成、GEMM 以及用于多 GPU 同步的集合通信。NanoFlow 动态调整纳米批处理大小以优化每种资源类型,采用一种结合拓扑排序和基于硬件资源及内核优化的贪婪搜索的调度方法。
通过将操作分解为更小的纳米批次,任务可以与用户 - 服务器网络操作重叠并并发运行,从而提高资源利用率并增加吞吐量。然而,纳米批处理需要复杂的调度,且当操作分布在多个 GPU 上时,可能会产生额外的通信开销。
5.1.4 分块预填充(Chunke d-prefills)
分块预填充 [9] 旨在解决动态或连续批处理中出现的流水线效率低下问题,尤其是在多 GPU 环境中:当批次为空时,受内存限制的解码阶段可能会处于空闲状态。此外,一次性处理长提示也会增加延迟,还会影响短请求的处理。
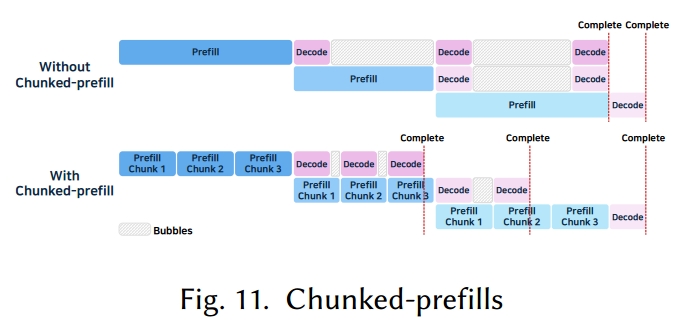
图 11 展示了分块预填充的工作方式:它将长提示拆分为多个片段,然后逐步处理这些片段。第一个片段的解码可以立即开始,而后续片段则进行预填充,这样就能够让这两个阶段并发运行,从而提高资源利用率。
然而,分块预填充需要更精细的批次管理,这增加了调度的复杂性。同时,由于预填充和解码会同时执行,KV 缓存的使用量也可能激增。例如,DeepSpeed-FastGen [102] 的 Dynamic SplitFuse 技术通过拆分提示来更早地生成令牌;而 Sarathi-Serve [8] 的无停顿调度会立即接收新请求,从而消除等待时间并提高效率。
5.2 并行化(Parallelism)
由于大型语言模型可能包含数十亿甚至数万亿个参数,仅依靠单个 GPU 或类似硬件进行推理变得越来越具有挑战性。因此,跨多个设备或节点的分布式和并行处理对于减少延迟和最大化硬件利用率至关重要。
LLM 推理中的并行化策略根据服务器架构和硬件配置的不同,在实现和性能上存在差异。可用 GPU 或加速器的数量、互连带宽、内存层次结构和计算能力等因素,会影响张量并行(TP)[205, 230]、数据并行(DP)[212]、全分片数据并行(FSDP)[292] 和流水线并行(PP)[9, 106] 等技术的有效应用。此外,混合方法可以结合多种策略以进一步提高性能 [46, 269]。
例如,在多节点集群中,节点间通信延迟可能成为瓶颈,因此需要采用通信压缩或异步调度等技术来维持高性能。相反,在单节点多 GPU 设置中,共享内存和高速互连(如 NVLink、NVSwitch)能够实现更高效的同步和工作负载分配。归根结底,任何并行化策略的成功都取决于计算和通信开销的平衡,这强调了根据每个独特的硬件环境和模型架构定制方法的必要性。为了应对这些挑战,研究人员正积极开发自动探索和识别每个系统最佳并行化策略的方法 [139, 175]。各种并行化机制如图 12 所示。
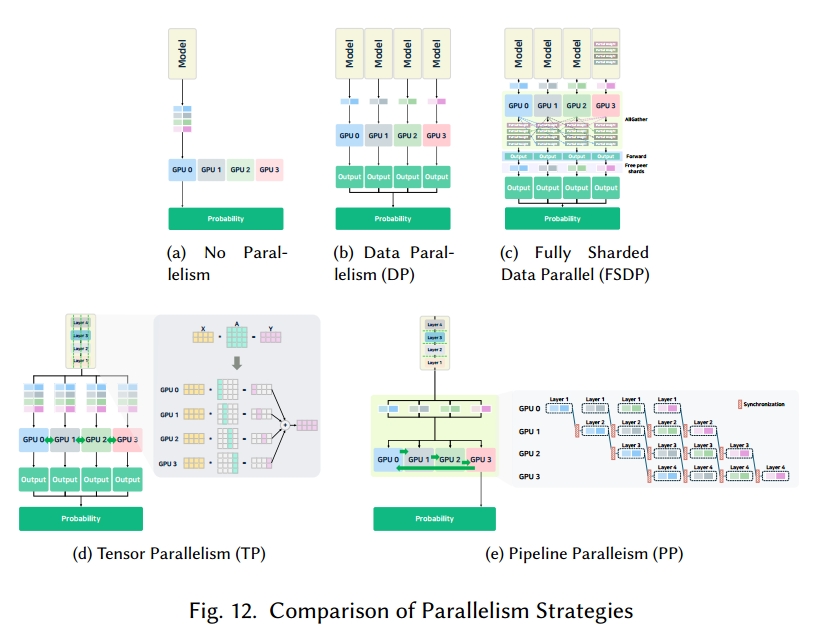
5.2.1 数据并行(Data Parallelism)
如图 12(b)所示,数据并行(DP)[212] 在多个 GPU 或节点上复制相同的模型。一个小批次被分配到可用的硬件设备中,每个设备独立对其分配的数据部分执行推理。计算完成后,输出(或权重)被收集到单个设备中以生成最终结果。
尽管这种方法实现简单,且通信开销相对较低(因为仅在推理后进行同步),但如果整个模型必须驻留在每个设备上,数据并行在处理超大型 LLM 时可能变得不切实际。此外,如果硬件设备的性能差异显著,整个系统可能会遇到瓶颈。
5.2.2 全分片数据并行(Fully Sharde d Data Parallelism)
全分片数据并行(FSDP)[292] 是一种并行化技术,旨在减少大型语言模型训练时的内存使用并提高训练效率。与传统的数据并行不同(传统方法中每个设备都持有模型参数和优化器状态的完整副本),FSDP 将模型的参数、梯度和优化器状态分片到多个设备上。这消除了重复的内存使用,使更大的模型能够在相同的硬件资源上训练。
如图 12(c)所示,FSDP 的工作方式是:在执行每层之前,在每个 GPU 上收集该层的所有参数。这使得全计算可以在每个 GPU 上进行。完整的参数仅在操作期间临时加载到内存中,层完成后立即移除。这种方法不会拆分操作本身,因此实现简单,且与大多数模型兼容。
然而,由于必须在每一层聚集所有参数,存在通信开销。这可能会导致推理期间的性能问题,特别是对于小批量工作负载或对低延迟有要求的场景。此外,如果某一层在全聚集阶段需要的内存超过单个 GPU 的容量,则无法运行该层。
在训练期间,FSDP 通过对激活值和参数进行分片,能显著节省内存。但在推理期间,由于不存在梯度或激活值的重计算,因此内存节省效果较差。所以,推理时是否使用 FSDP 应根据模型大小来决定。
PyTorch 原生支持 FSDP,且它与 PyTorch 的自动求导引擎、检查点机制以及混合精度训练兼容良好。它还能与其他并行策略(如混合并行)灵活结合。在我们研究的大型语言模型推理引擎中,vLLM [125]、DeepSpeed-FastGen [102]、SGLang [295] 和 LitGPT [145] 均支持 FSDP。
5.2.3 张量并行(Tensor Parallelism)
张量并行(TP)[205, 230],也称为模型并行或分片,将大型语言模型的特定操作(如矩阵乘法、注意力机制、全连接层)分配到多个硬件设备上。每个设备处理操作的一部分,之后合并中间结果。
例如,图 12(d)展示了四个 GPU 处理矩阵运算 X×A=Y 的场景。矩阵 A 按行或按列分配到各个 GPU 中,计算通过集合通信(如 All-Reduce 或 All-Gather)进行协调。
通过分散大型计算任务,张量并行加快了推理速度并减少了每个设备的内存占用 —— 因为单个 GPU 无需存储所有权重。然而,频繁的设备间通信可能会增加开销,且不合理的分片可能降低效率。vLLM [125]、DeepSpeed-FastGen [102]、TensorRT-LLM [191] 等推理引擎通常会集成相关技术来应对这些挑战 [193, 224, 269]。
为缓解张量并行中的通信瓶颈 —— 尤其是首次令牌生成时间(TTFT)的性能下降问题,近期研究提出了通信压缩技术,以减少开销并提高推理速度 [97]。
5.2.4 流水线并行(Pipeline Parallelism)
流水线并行(PP)[9, 106] 将大型语言模型的不同部分(层)分配给不同的 GPU。输入数据被分割成微批次,这些微批次依次通过这个层流水线。如图 12(e)所示,若一个 Transformer 模型有 4 层且有 4 个 GPU 可用,则每个 GPU 负责处理其中一层。
这种安排通过在设备间分配层来减少内存使用,还能通过操作重叠加快推理速度。然而,当中间结果在设备间传输时会产生通信开销,且在流水线启动阶段,初始阶段的设备会处于未充分利用的状态直到流水线预热完成。已经提出了多种流水线优化技术来缓解这些问题 [164, 279]。
多种推理框架支持流水线并行(PP),包括 Ollama [194]、llama.cpp [82]、vLLM [125] 和 Friendli Inference [71]。
5.3 压缩(Compression)
随着大型语言模型(LLMs)规模不断扩大,在单个 GPU 或服务器节点上进行推理变得愈发困难。为缓解这一问题,模型压缩技术应运而生,包括量化 [61]、知识蒸馏(KD)[271]、剪枝 [120, 301]、稀疏性优化 [65, 223] 等。其中,量化在节省内存、提高推理速度方面尤为重要,进而降低功耗和成本。剪枝和稀疏性优化能提升计算效率和推理速度,已有多款推理引擎支持这些技术。尽管这些技术与训练或微调紧密相关,但推理引擎在运行量化模型时,仍需确保内核的正确选择和执行。
5.3.1 量化(Quntization)
量化算法:如图 13(a)所示,量化是将预训练的 FP32 或 FP16 模型转换为低精度浮点格式(如 FP4、FP8)或整数格式(如 INT4、INT8)。通过表示更少的不同数值,量化能显著加速矩阵乘法并降低内存需求,且只需付出微小的性能代价。

为将高精度模型转换为低位表示,绝对最大值量化 [52] 等方法通过张量的绝对最大值计算缩放因子。在反量化过程中,通过将缩放因子应用于量化数据来近似模型值。这种方法简单且硬件效率高,但对异常值较为敏感。仿射量化 [167] 等方法通过更灵活地调整分布来解决这一问题。
根据工作流程的不同,可采用多种量化方法。例如,训练后量化(PTQ)[133, 265] 在模型训练后应用量化(图 13(b));量化感知训练(QAT)[42, 159] 则将量化整合到训练过程中(图 13(c))。PTQ 可用于预训练模型,实现简单且快速。应用 PTQ 时,会使用小型代表性样本的校准数据集来优化预训练模型中的量化参数。该数据集有助于确定各层内的激活分布,进而定义量化参数(如裁剪范围和缩放因子)。然而,由于量化效应,PTQ 可能导致精度下降。相比之下,QAT 将量化操作融入训练过程,能够考虑梯度信息,从而更有效地保持精度。但 QAT 涉及额外步骤,如微调量化参数、重新训练和调整训练策略,这会增加整体训练成本 [42]。因此,在实际应用中,即使是对精度要求较高的服务,受现实条件限制,PTQ 的使用也更为频繁。
多种量化方法可用于大型语言模型,且得到了各类推理引擎的支持。通用训练后量化(GPTQ)[69] 提供仅权重量化,通过误差补偿优化每层缩放,以最大限度减少精度损失。激活感知权重量化(AWQ)[146] 根据激活分布对权重进行分组,从而改进权重量化,提高精度。
语言模型 additive 量化(AQLM)[62] 仅使用训练后量化(PTQ)对权重和激活值进行量化,无需量化感知训练(QAT),与 GPTQ 相比,能以更低的开销实现高性能。SmoothQuant [265] 对激活值和权重分布进行归一化,以减少量化过程中的裁剪,实现稳定的基于 PTQ 的激活量化,同时降低延迟和内存使用。
此外,为了在长上下文场景中最小化内存使用,研究者提出了 KV 缓存量化 [104, 161],该方法能在内存效率和生成速度之间取得平衡,同时将对模型质量的影响降至最低。KVQuant [104] 采用超低精度量化,通过通道前和 RoPE 前键量化、非均匀 KV 缓存量化以及每向量密疏量化,实现了精度损失极小的量化。KIVI [161] 对键缓存按通道量化,对值缓存按令牌量化,实现了 2 位量化。
内核代码与硬件支持:许多推理引擎集成了外部量化工具。bitsandbytes [33] 是一个基于 CUDA 的 Python 库,支持 8 位和 4 位量化,vLLM [125]、SGLang [295]、LitGPT [145] 等引擎均支持该库。DeepSpeed FP 是 DeepSpeed 的 6 位和 8 位仅权重量化库,在 NVIDIA GPU 上的 vLLM [125] 中得到部分支持。
ExLlamaV2(EXL2)[242] 是一款面向消费级 GPU 的推理库,提供类似于 GPTQ 的 2 位至 8 位灵活量化,还支持按层混合不同位级的量化。EETQ [182] 为 Transformer 模型提供了一种简单高效的 INT8 仅权重 PTQ 方法。TGI [110] 同时支持 EXL2 和 EETQ。
LLM Compressor [247] 是专为 vLLM 环境设计的量化库,支持仅权重量化和激活量化。它支持混合精度模式(如 W4A16、W8A16),并集成了简单 PTQ、GPTQ [69]、SmoothQuant [265] 等技术。vLLM [125]、SGLang [295] 等推理引擎可采用 LLM Compressor 进行量化。
混合自回归线性内核(Marlin)[70] 是一款针对 FP16×INT4 矩阵乘法的高度优化内核。该内核旨在最大限度提高推理速度,通过充分利用 GPU 全局内存、缓存、共享内存和张量核心,理论上可实现高达 FP16 四倍的性能。Marlin 在 NVIDIA 并行线程执行(PTX)[185] 汇编级实现,依赖于 NVIDIA GPU,vLLM [125]、SGLang [295]、TGI [110] 均支持该内核。
这些量化技术与每个推理引擎所支持的硬件密切相关。如表 8 所示,每个引擎都适用于特定的数据类型,而这些数据类型又决定了量化模型的执行方式。
特别是,基于 4-8 位范围内块级缩放的数据类型(如微缩放(MX)格式 [213])已被提出,用于平衡训练和推理性能、精度以及框架兼容性。例如 MXFP8 和 MXINT8。每个 MX 块包含一个缩放值 X 和一组压缩值(𝑃1, 𝑃2, ..., 𝑃𝑘)。缩放格式(如 E8M0)和元素格式(如 FP4、FP6、FP8、INT8)可独立配置。
传统的 FP8 或 INT8 格式需要单一的张量级缩放因子来匹配整个张量的动态范围,而 MX 格式将张量拆分为更小的子块,并为每个子块分配单独的缩放值,从而规避了 8 位以下格式的局限性。高通 Cloud AI 100 [40]、基于 Hopper 架构的 NVIDIA GPU 等硬件平台支持 MX 格式,部分推理引擎(如 TensorRT-LLM [191])也提供对 MX 格式的支持。
5.3.2 剪枝(Pruning)
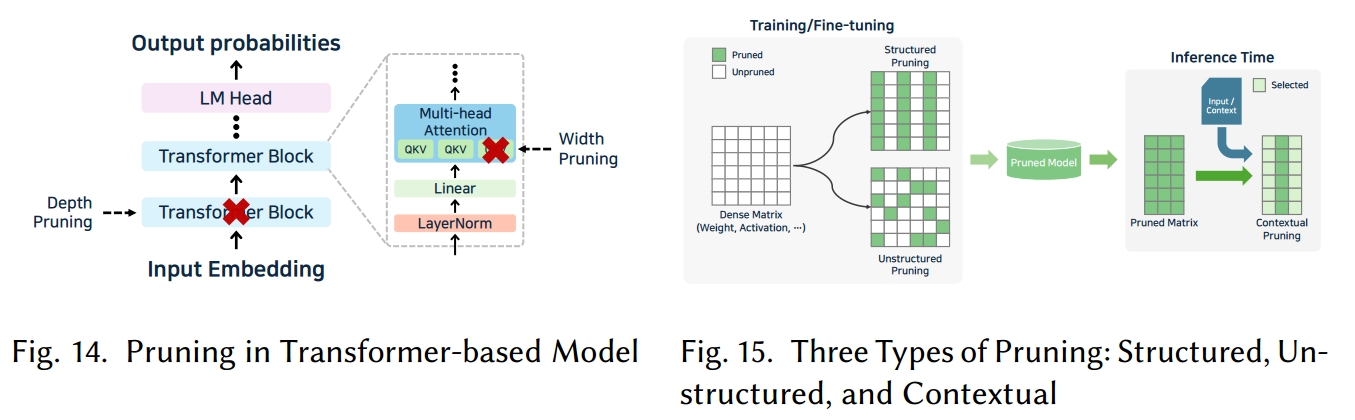
剪枝概述及推理优势:剪枝 [120, 301] 是一种模型压缩技术,通过移除不太重要的参数来减小模型大小。在基于 Transformer 的大型语言模型中,剪枝通常针对权重或注意力头(如图 14 所示)。剪枝可在训练后通过将特定权重置零并移除来应用,也可在训练 / 微调过程中动态应用 [158],还可通过一次性剪枝 [68, 216] 快速缩减大型模型规模。
从推理角度来看,剪枝减少了参数数量,从而提高了内存利用率、带宽效率和缓存使用率。随着更多权重变为零,稀疏计算能够降低实际计算成本。然而,要充分利用稀疏计算,推理引擎或计算库必须支持能够跳过或高效处理零权重的内核。
三种剪枝类型:大型语言模型中的剪枝方法大致可分为三类:结构化剪枝、非结构化剪枝和上下文剪枝 [27],每种剪枝方法如图 15 所示。结构化剪枝会移除具有固定结构的参数组,例如卷积滤波器或神经元通道。由于矩阵维度会实际减小,即使没有专门的稀疏计算内核,推理速度也能得到提升。不过,必须调整推理图或内核以匹配剪枝后的架构。LLM-Pruner [166] 就是一种结构化剪枝方法,它基于梯度信息剪枝低重要性结构。
非结构化剪枝会根据权重的重要性分数移除单个权重。尽管这会减小模型大小和浮点运算次数(FLOPS),但随机稀疏模式的使用可能会限制稠密矩阵乘法内核的性能提升,因此需要优化的稀疏内核才能实现有效加速。例如,NVIDIA CUDA 通过 cuSPARSE [190] 提供稀疏操作。在非结构化剪枝方法中,Wanda [233] 基于权重大小与输入激活值的乘积来剪枝权重。
上下文剪枝会根据输入上下文或领域动态评估权重的重要性,有选择地移除或保留权重。这种方法能使模型适应特定输入,跳过不必要的计算路径,从而提高推理效率。尽管与其他方法相比,稀疏计算带来的性能提升可能较小,但它能提高特定领域的准确性。实现上下文剪枝需要推理引擎支持条件分支或带有跳过特定层逻辑的预编译内核。例如,Mini-GPTs [245] 使用法律和医疗问答数据集,对 Phi-1.5 [135] 和 Opt-1.3 [285] 应用上下文剪枝,以剪枝线性层、激活层和嵌入层。
最新进展:训练后剪枝和令牌剪枝。与量化类似,由于训练或微调成本高昂,训练后剪枝一直是大型语言模型的研究重点。近期的研究工作涉及非结构化和半结构化训练后剪枝算法,通过在大型语言模型层级别剪枝大量权重来解决多重移除问题(MRP)[291]。
在大型语言模型推理中,随着输入令牌长度的增加,首次令牌生成时间(TTFT)通常也会增加。一种提出的解决方案是令牌剪枝 [72],它仅选择性地计算被判断为对下一个令牌预测重要的令牌的 KV 表示 —— 无需额外训练或微调。其余令牌会被延迟处理,仅在需要时才进行计算,这减少了初始计算成本并改善了首次令牌生成时间。
推理引擎对剪枝模型的支持。在本文讨论的推理引擎中,不到一半直接支持剪枝。大多数依赖 NVIDIA 的剪枝库,其中 DeepSpeed-FastGen [102] 通过 DeepSpeed 后端明确支持行剪枝、头剪枝、稀疏剪枝以及结构化 / 非结构化剪枝。其他引擎通常仅支持运行预剪枝模型。
5.3.3 稀疏性优化(Sparsity Optimization)
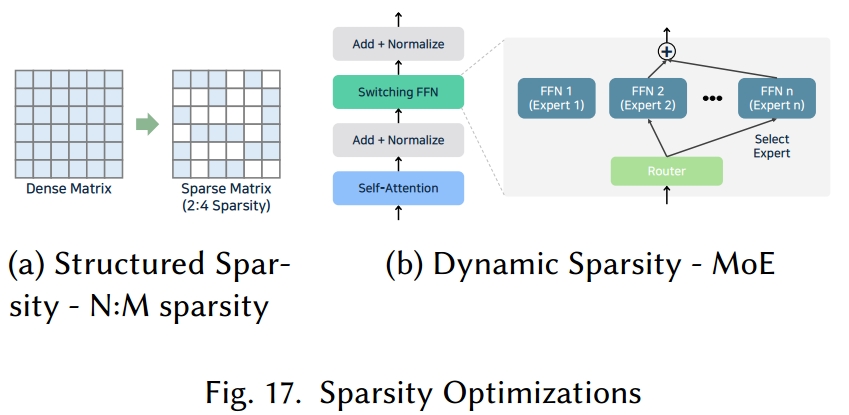
稀疏性优化概述。稀疏性优化 [65, 223] 是一种通过增加模型权重或激活值中的零值数量来降低计算成本并加快推理速度的技术。当硬件或推理引擎支持稀疏操作时,这种方法可以减少内存使用并提高计算性能。尽管与剪枝目标相同,但稀疏性优化侧重于设计稀疏模型结构或应用预定义的稀疏模式以实现计算效率。稀疏性可应用于注意力机制(例如,稀疏注意力模式)或单个头的权重。剪枝可以产生稀疏性,而已有稀疏性的模型可以通过剪枝进一步优化。稀疏性优化技术包括结构化稀疏性 [56, 294]、动态稀疏性 [288] 和内核级稀疏性 [34, 263]。
结构化稀疏性(Structured Sparsity):
结构化稀疏性 [56, 294] 以固定模式在权重或张量值上引入稀疏性,从而简化硬件级优化。典型示例包括 N:M 稀疏性 [287](如图 17(a)所示,在 m 大小的块中保留 n 个活跃值)和块稀疏性 [74](将权重矩阵划分为块并移除部分值以形成稀疏性)。在 NVIDIA GPU 及类似硬件上,这些静态模式可在模型编译时进行优化。然而,固定模式可能会对模型性能产生负面影响。
动态稀疏性与混合专家模型(Dynamic Sparsity and Mixture-of-Experts)
动态稀疏性 [288] 会根据输入令牌仅激活运行时所需的计算,跳过不必要的操作以提高效率。一个典型示例是混合专家模型(MoE)[38],它用多个前馈网络(专家)替代多层感知机(MLP),但仅根据输入令牌激活其中一部分,如图 17(b)所示。这减少了每个令牌的计算量,使大型模型能更高效地运行。
为支持混合专家模型,推理引擎必须提供门控机制和灵活的动态路由架构。混合专家模型的示例包括 Mixtral 8x7B [115]、DeepSpeed-MoE [211] 和 DeepSeek-R1 [96],它们能在有限时间或资源下处理或训练更多令牌。大多数推理引擎都提供混合专家模型支持及相关优化。
稀疏混合专家模型训练的改进(Enhancements to Sparse MoE Training)
在稠密专家模型中,所有专家都会为每个输入激活,导致计算更复杂。稀疏混合专家模型 [60, 66] 通过仅使用部分专家(如仅选择前 k 个专家)来弥补这一不足。为解决因稀疏门控导致的专业化降低或训练不稳定问题,SMoE-Dropout [44] 采用随机路由网络,在训练过程中逐渐增加活跃专家的数量以优化模型。
令牌稀疏性与上下文稀疏性(Token and Contextual Sparsity)
动态稀疏性的另一个示例是动态令牌稀疏性 [72, 272],它通过聚焦于部分令牌来避免对所有令牌计算注意力。除了上下文剪枝 [245],研究者还提出了上下文稀疏性 [12, 160],即根据输入选择性激活部分注意力头或多层感知机参数。在 Deja Vu [160] 等上下文稀疏性研究中,采用了轻量级稀疏方法,根据输入上下文动态跳过计算,解决了验证每个输入是否真正存在上下文稀疏性的高成本问题。
内核级稀疏性(Kernel-Level Sparsity)
内核级稀疏性会检查计算内核中的零值并跳过它们。例如,稀疏矩阵 - 稠密矩阵乘法(SpMM)[34] 内核,或依赖 cuTeSpMM [264] 等库以利用 NVIDIA GPU 张量核心。xFormers [172] 库也包含用于内存高效注意力、稀疏注意力和块稀疏注意力的 CUDA 内核。
推理引擎中的支持(Supp ort in Inference Engines)
已有多个引擎集成了此类方法。vLLM [125]、SGLang [295] 和 TGI [110] 支持 N:M 稀疏性,其中 vLLM 还提供块稀疏性支持。SGLang 应用双重稀疏注意力 [272]—— 这是一种训练后稀疏注意力方法,在自注意力中优先处理关键令牌(令牌稀疏性),同时离线确定重要特征通道(通道稀疏性)。DeepSpeed-FastGen [102] 采用稀疏注意力技术,在自注意力中引入块级稀疏性,通过多种模式和自定义修改减少计算量和内存使用。TensorRT-LLM [191] 利用块稀疏注意力,通过块结构稀疏性加速稀疏矩阵 - 稠密矩阵乘法,依赖 NVIDIA 安培架构及后续 GPU 中的稀疏张量核心。
5.4 微调
大型语言模型通常依赖在大规模数据集上预训练的基础模型来执行各种推理任务。然而,对于特定领域或特定任务的优化,微调能显著提升模型性能。
参数高效微调(Parameter-Effient Fine-Tuning)
微调是一种最初应用于卷积神经网络(CNN)的技术,用于修改预训练模型的参数。它可分为全参数微调 [163](更新每个参数)和参数高效微调(PEFT)[54](仅调整部分参数)。由于全微调需要大量硬件资源,大型语言模型通常更倾向于仅更新模型部分参数的 PEFT 方法。尽管微调主要针对模型训练,但其也直接影响大型语言模型的推理性能。
微调可通过插入适配器网络(额外层)来重新校准参数 [107],或通过提示工程提供特定领域数据来实现 [275]。
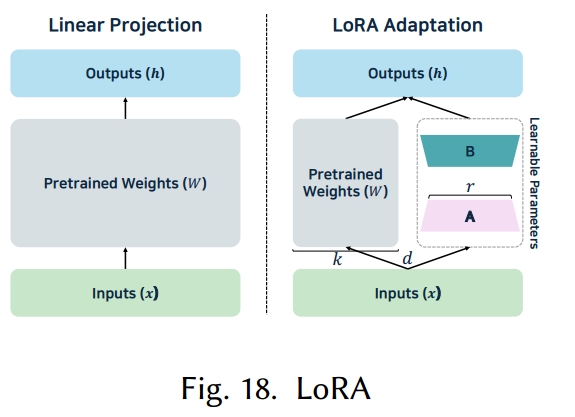
低秩适应(Low-rank adaptation)
低秩适应(LoRA)[105, 219] 是具有代表性的 PEFT 方法。与更新整个模型不同,LoRA 冻结原始权重,仅训练额外的低秩矩阵来调整模型参数。研究表明,尽管大型语言模型中全连接层的维度很大,但适应所需的有效维度相对较低。LoRA 利用这一点,通过低秩矩阵近似权重更新,大幅降低训练成本。如图 18 所示,LoRA 保留预训练权重矩阵,仅训练两个小矩阵𝐴和𝐵。它不直接计算全权重矩阵(𝑑×𝑘,其中𝑑为输入维度,𝑘为输出维度)的更新,而是通过低秩(𝑟)矩阵乘法(𝑑×𝑟和𝑟×𝑘)近似计算𝐴×𝐵。
LoRA 的一个主要优势是能够为不同任务切换不同的 LoRA 模块,无需重新训练整个模型即可快速适应。此外,由于 LoRA 仅更新小型低秩矩阵,训练速度更快,所需内存更少。将这些训练好的模块与原始权重合并通常不会降低推理速度,不过合并可能会限制实时多任务处理能力。
量化低秩适应(Quantize d Low-rank adaptation)
随着大型语言模型规模的增长,出现了量化低秩适应(QLoRA)[53, 286] 等方法,将 4 位量化与 LoRA 微调相结合。QLoRA 通过 4 位量化模型进行反向传播,在保留 LoRA 优势的同时减少内存使用。这使得大型模型可在单个设备上运行,为训练和推理都提供了高效选择。
推理引擎支持(Support in Inference Engines)
Ollama [194]、llama.cpp [82]、Friendli Inference [71] 和 Fireworks AI [67] 支持 LoRA;此外,DeepSpeed-FastGen [102]、SGLang [295]、TensorRT-LLM [191]、Unsloth [244] 和 vLLM [125] 支持 QLoRA。值得注意的是,vLLM [125]、TensorRT-LLM [191]、TGI [110]、LMDeploy [162]、Friendli Inference [71] 和 Together Inference [239] 还提供多 LoRA 功能,能够同时服务多个用户自定义模型。
5.5 缓存
在包含数十亿到数万亿参数的大型语言模型中,重复生成数百到数百万个令牌需要大量计算和内存资源。为解决这一问题,大多数推理引擎采用各种缓存策略,以减少冗余计算并降低延迟。缓存可应用于大型语言模型的多个组件,且不同的缓存优化可组合使用。
5.5.1 提示缓存(Prompt Caching)
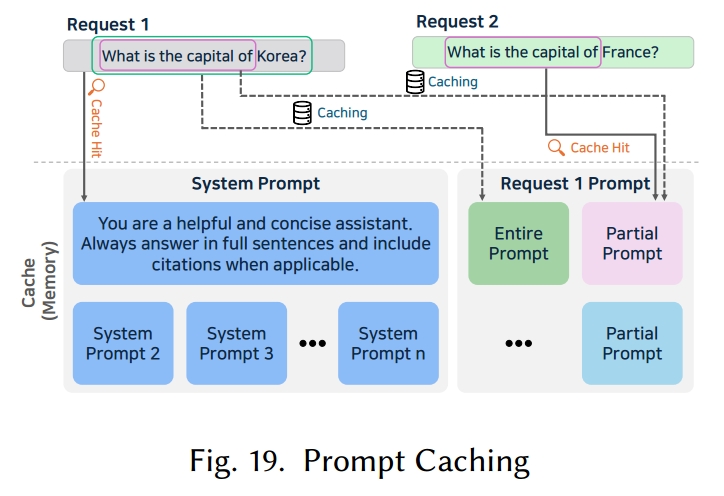
大型语言模型的提示中,有很大一部分可能包含频繁复用的文本。相同内容(如系统消息或常见指令)经常多次出现,尤其是在对话代理、代码助手或大规模文档处理中。为优化这一点,一种名为 “提示缓存” 的技术被提出 [83, 299]。提示缓存预先存储常用文本片段的注意力状态,当提示中再次出现相同片段时,直接复用存储的注意力结果,仅计算新片段,从而加快推理速度。然而,由于 Transformer 架构会应用位置编码机制使得注意力状态依赖于每个片段的位置,这意味着只有当片段出现在相同位置时,其注意力状态才能被复用。为克服这一限制,研究者提出了提示标记语言(Prompt Markup Language,PML)。它明确定义提示的结构,识别可复用片段(提示模块),并为每个模块分配唯一的位置 ID。PML 充当模块位置和层级的架构,提供了在模块级别生成和复用注意力状态的接口。图 19 展示了提示缓存的一个示例。
商业 AI 服务中的提示缓存(Prompt Caching in Commercial AI Ser vices)
ChatGPT [196] 和 Claude [23] 等商业服务也采用了提示缓存技术。ChatGPT 会将具有相同提示的 API 请求路由到之前处理过该提示的服务器,从而复用缓存结果,而非从第一个 token 开始重新计算。这种方法对长提示可将延迟降低高达 80%。为提高缓存命中率,ChatGPT 将静态组件(如指令、示例)放在提示的开头,而动态用户内容放在末尾。ChatGPT 对超过 1024 个 token 的提示应用缓存,并以 128 个 token 为片段触发缓存命中。根据系统负载,它会保留缓存的提示 5 到 60 分钟,自动清除未被使用的提示。Claude 采用类似的格式,提供最多 4 个缓存断点,将提示分割为多个可缓存片段。
缓存命中预测(Cache Hit Pre diction)
已有研究提出了一种提高提示缓存准确性的方法 [299]。该研究建议基于嵌入相似度预测缓存的有效性。在单轮问答场景中,研究使用经知识蒸馏优化的嵌入来判断缓存的响应是否可复用。通过计算提示嵌入之间的余弦相似度,训练模型来决定是否可以复用相同的响应。这项研究还为二元交叉熵(BCE)和平方对数差(SLD)等损失函数提供了有限样本保证。
推理引擎中的支持(Supp ort in Inference Engines)
多个推理引擎(包括 Ollama [194]、llama.cpp [82] 和 TensorRT-LLM [191])支持提示缓存。其中,TensorRT-LLM [191] 提供系统提示缓存功能,而 Ollama [194] 即使在多用户环境下也能提供优化的提示缓存。
5.5.2 前缀缓存(Prefix Caching)
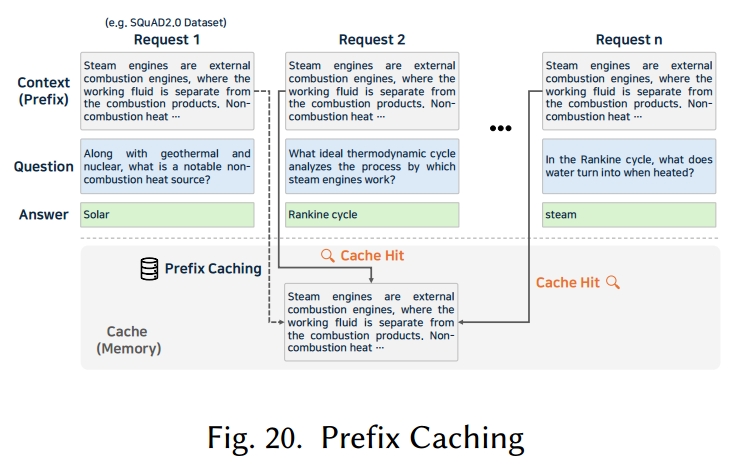
前缀缓存 [152, 199] 在概念上与提示缓存 [83, 299] 相似,但它不缓存整个提示,而是专注于缓存多个请求中重复出现的共同前缀片段,如图 20 所示。在批处理推理中,当多个提示共享相同的前缀时,该共享片段的计算结果可被复用,从而提高效率。例如,在问答任务中,若相同的系统提示或少样本示例被反复使用,在预填充阶段缓存这些提示部分可减少整体推理时间。
然而,前缀缓存通常仅加速预填充阶段,对解码阶段没有影响。因此,如果主要瓶颈源于超长文本的长时间解码,那么前缀缓存带来的性能提升可能会十分有限。此外,如果新请求与任何现有请求都不共享前缀,缓存的优势就会减弱。
推理引擎中的支持(Support in Inference Engines)
vLLM [125] 提供了自动前缀缓存(APC)功能,它会存储先前请求的 KV 缓存,当新请求与现有请求共享前缀时便会复用该缓存,从而跳过共享部分的注意力计算。TGI [110] 采用高性能数据结构而非基础字符串匹配来加快前缀查找速度,并应用分块代码优化内存使用;它还将前缀缓存与 Flashdecoding [103] 内核相结合,以支持长序列的快速推理。MAX [179] 采用基于 PagedAttention [125] 的机制来应用前缀缓存并提高推理效率,其他引擎(如 LMDeploy [162])也包含前缀缓存功能。
5.5.3 KV 缓存(KV Caching)
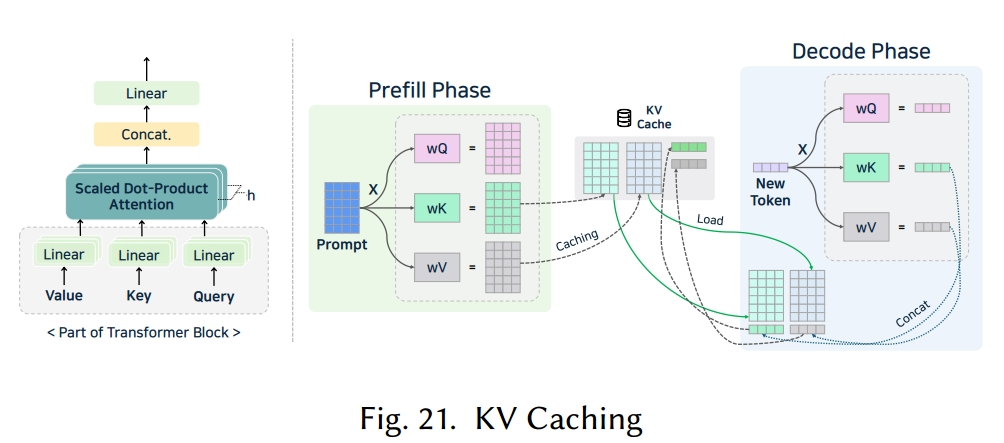
在 Transformer 的自注意力机制中,每个 token 都会关注所有前面的 token,这导致其时间复杂度为 O (n²)。为了减少这种开销,KV 缓存(KV Caching)[75, 204, 256] 应运而生。通过存储每个 token 步骤中生成的 K 矩阵和 V 矩阵,并在后续 token 中复用它们,推理的时间复杂度可降至 O (n)。预填充阶段和解码阶段的 KV 缓存操作如图 21 所示。这在大批量处理或多轮对话场景中能带来显著的效率提升。KV 缓存还能与前缀缓存 [152, 199]、投机解码 [131, 154, 228] 等其他优化技术很好地结合使用。
增大 KV 缓存大小(Increasing KV Cache Size)
然而,由于 K 和 V 都必须存储在内存中,KV 缓存所需的内存会随着上下文长度的增加而显著增加。LLM 推理所需的内存可表示为:每个 token 的 KV 缓存大小𝑆𝐾𝑉 = 2 × 层数(𝑛layers)×(注意力头数(𝑛heads)× 头维度(𝑑head))× 精度(字节数,𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛);KV 缓存的总大小可表示为:Σ𝑆𝐾𝑉 = 批大小(𝑠batch)× 序列长度(𝑙seq)× 2 × 层数(𝑛layers)× 隐藏层大小(𝑠hidden)× 精度(字节数,𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛)。在上述公式中,𝑛layers 表示层数,𝑛heads 表示注意力头数,𝑑head 表示头维度;𝑠batch 表示批大小,𝑙seq 表示序列长度,𝑠hidden 表示隐藏层大小,𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛表示精度(以字节为单位,如 FP16);𝑆𝐾𝑉和 Σ𝑆𝐾𝑉的单位均为字节。公式中乘以 2 是因为要同时考虑 K 和 V 两个部分。
通过减小批大小来减少 KV 缓存内存,虽然能降低内存使用量,但也会降低硬件利用率和吞吐量。限制序列长度则会迫使部分 KV 缓存重新计算,从而导致效率下降。减小模型深度可能会影响性能;因此,当前的研究主要集中在注意力机制、缓存压缩和量化技术上。
KV 缓存优化(KV Cache Optimizations)
如图 3 所示,像分组查询注意力(GQA)[11] 和多查询注意力(MQA)[218] 这类注意力机制,通过减少查询头(Q 头)的数量或复用键值头(KV 头),自然会缩小 KV 缓存的大小。研究还聚焦于 KV 缓存的压缩。MiniCache [149] 采用深度压缩方法,发现中深层的 KV 缓存具有高度相似性。H2O [289] 利用注意力矩阵的稀疏性,仅复用必要部分同时保留相同的输出 token。FlexGen [221] 分析注意力头的结构特性,并提出自适应 KV缓存压缩。如上文 5.3.1 节所述,量化技术也可用于减小 KV 缓存大小 [104, 161]。
随着上下文窗口和模型规模的增长,仅靠 GPU 内存可能不足以存储 KV 缓存,这催生了卸载解决方案。InfiniGen [129] 会推测性地将必要的 KV 片段预取到 CPU 内存中,而 CacheGen [157] 在分布式系统中会将 KV 缓存编码并作为压缩比特流进行流式传输,从而减少网络传输延迟。
推理引擎中的支持(Support in Inference Engines)
许多推理引擎都实现了 KV 缓存。LMDeploy [162] 和 Ollama [194] 采用 INT8 或 FP16 量化来减小缓存大小。DeepSpeed-FastGen [102] 应用基于 ZeRO-Inference [18] 的卸载技术和 4 位量化,以在资源受限环境中提高吞吐量。TensorRT-LLM [191] 提供多种优化,包括分页 KV 缓存、KV 缓存量化、循环 KV 缓存和 KV 缓存复用。它通过基于 LRU(最近最少使用)的淘汰策略以及 KV 感知路由或调度(将请求转发到已缓存所需 KV 的实例)来节省内存。vLLM [125] 实现了 KV 缓存抢占机制,允许中断部分请求以释放空间。尽管被中断的请求需要重新计算,可能会增加端到端延迟,但这种方法能提升整体系统稳定性。
5.6 注意力优化(Attntion Optimization)
注意力机制是基于 Transformer 的大型语言模型的核心,但它高昂的内存和计算成本使得优化对于高效的服务部署至关重要。随着序列长度的增加,注意力操作所需的时间呈二次方增长,而计算和存储 Q、K、V 矩阵会消耗大量内存。因此,提高内存效率和增大批处理大小对于处理多个请求和提升整体吞吐量至关重要。
为提高推理性能,大多数大型语言模型推理引擎都会采用 KV 缓存机制 [157, 231],即存储先前生成的令牌所对应的 K 和 V 向量。这种方法能避免生成后续令牌时的冗余计算,从而减少推理延迟和计算开销。
大型语言模型推理引擎提供了一系列优化技术,用于高效存储和检索 KV 缓存,以及改进推理过程中 Q、K、V 向量的使用方法。
5.6.1 KV 缓存优化(KV Cache Optimization)
分页注意力(PagedAttention)
有效的 KV 缓存管理对于提升大型语言模型推理性能至关重要。传统推理引擎通常会根据最大序列长度分配连续的 KV 缓存,而随着序列长度的变化,这可能导致内部分段和外部分段问题。这些分段问题会降低内存效率并限制并行性。
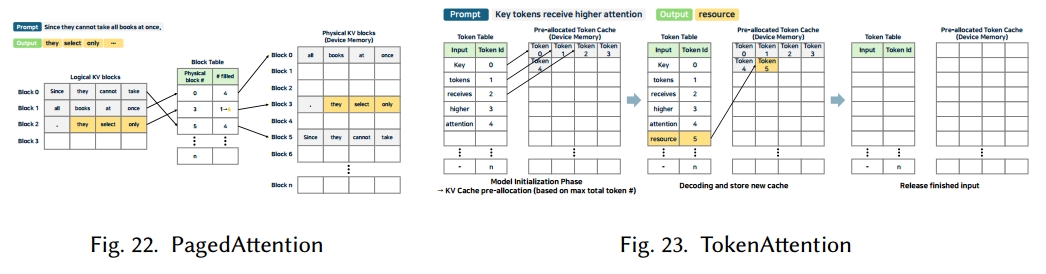
如图 22 所示,PagedAttention [125] 通过采用类 Linux 的分页机制解决了这一问题。它将 KV 缓存划分为更小的页,并使用页表将逻辑块映射到物理块。按需分配新需要的块,而内存来自已完成请求的内存会被快速回收,用于处理新请求。具有相同提示的请求会共享相同的 KV 缓存块,进一步节省内存。多种推理引擎(如 DeepSpeed-FastGen [102]、vLLM [125]、MAX [179]、SGLang [295])都集成了 PagedAttention 以提高推理效率。
LightLLM [142] 引入了 TokenAttention,它在令牌级别管理 KV 缓存(图 23)。与页表不同,TokenAttention 使用令牌表来跟踪每个令牌的实际存储位置。它会根据用户定义的最大令牌限制预分配 KV 缓存,并为新请求分配连续的内存区域。这种策略通过细粒度的内存管理最大限度地减少了碎片化,提高了资源利用率。
其他方法(如 ChunkedAttention [274])通过识别系统提示经常重复这一特点来减少 KV 缓存重复。ChunkedAttention 将 KV 缓存分割成更小的块,并通过前缀感知 KV 缓存(PAKV)结构对其进行组织,使具有相同前缀的请求能够共享缓存块。这进一步提升了内存效率。
5.6.2 I/O 优化(I/O Optimization)
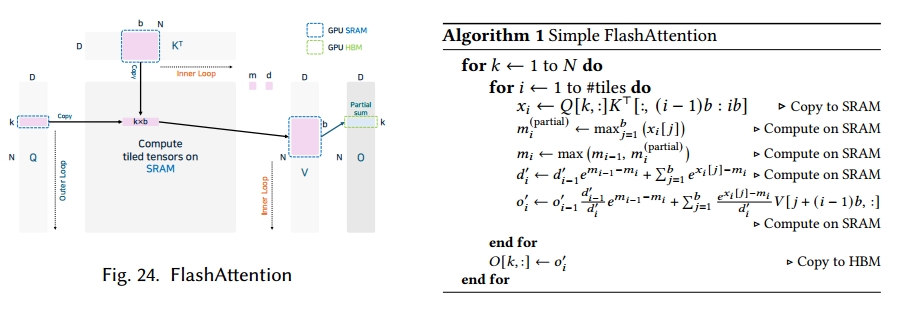
FlashAttention
在大型语言模型推理中,对于长度为𝑛的序列,注意力操作需要 O (𝑛²) 的计算量。这涉及通过 Q、K、V 的点积形成分数矩阵,而由于 GPU 上内存层级之间的频繁数据传输,这一过程对内存的需求极大。
FlashAttention [51] 通过将 Q、K、V 分割成更小的块来减少不必要的数据传输。与先计算整个注意力矩阵再应用 softmax 的方法不同,FlashAttention 对每个瓦片应用在线 softmax,避免了对内存的冗余写入。它还将矩阵乘法和 softmax 融合到单个过程中,从而减少了内核调用开销。
为了说明 FlashAttention 中注意力操作融合的核心思想,我们以简化方式呈现其关键思路(如算法 1 和图 24 所示)。在融合注意力中,每一步仅在芯片上保留一小部分中间结果,这实现了内存高效的自注意力。这种设计在遵循 GPU 共享内存限制的同时,随序列长度𝑁呈线性扩展。
我们将𝑏定义为块大小(也称为瓦片宽度)。沿序列维度的总瓦数为 #tiles = ⎡𝑁/𝑏⎤。术语𝑥𝑖 ∈ R𝑏表示瓦片𝑖的 softmax 前对数几率。我们令𝑚𝑖为从 1 到𝑖的所有瓦片的全局最大值,𝑚(partial)𝑖表示部分瓦片𝑖内的最大值。变量𝑑𝑖是截至瓦片𝑖的 softmax 计算累积分母。最后,𝑜𝑖是累积截至瓦片𝑖结果的部分输出向量(对应于𝑂[𝑘, :])。每次迭代都会计算当前瓦片的局部对数几率𝑥𝑖,并更新 softmax 缩放因子𝑚𝑖、累积分母𝑑𝑖和部分输出𝑜𝑖。
由于𝑥𝑖、𝑚𝑖、𝑑𝑖和𝑜𝑖的大小较小且固定(O (𝑏) 或 O (𝐷)),它们可以在核执行期间驻留在共享内存中。这种设计确保计算在数值上既稳定又高效。这种设计稳定且与并行分块兼容,使其非常适合长序列 Transformer 的推理或训练。
FlashAttention-2 [50] 进一步优化了通用矩阵乘法(GEMM)及相关的非矩阵操作。它合并了某些缩放步骤,并允许沿序列长度维度进行并行化,这在批大小和注意力头数量较小时非常有益。这种策略能最大限度地提高长序列的 GPU 利用率,但最初在 NVIDIA H100 GPU 上的 GEMM 中存在 GPU 使用率低的问题。
为解决这一问题,FlashAttention-3 [215] 引入了异步计算和低精度算术。通过将数据传输和计算分配到不同的 GPU 线程束中,并采用生产者 - 消费者模型,它使 softmax 操作与线程束组矩阵乘加(WGMMA)重叠进行,从而减少了延迟。
现在许多大型语言模型推理引擎都支持 FlashAttention 的各种变体,其中 vLLM [125] 兼容至 FlashAttention-3 [215]。由于这些优化与 NVIDIA GPU 架构密切相关,研究人员正在探索为其他硬件借鉴类似原理的方法 [35,103],旨在将注意力加速技术推广到多种平台。
5.6.3 KV 缓存复用(KV Cache Reuse):
基数注意力(RadixAttention)
基数注意力(RadixAttention)是 SGLang [295] 提出的一种优化技术,能够实现多个操作间 KV 缓存的自动复用。传统推理引擎在一个请求完成后会清空所有相关的 KV 缓存,这阻碍了请求之间的复用,降低了性能。为解决这一限制,SGLang 采用基于基数树的 LRU(最近最少使用)机制管理 KV 缓存,支持快速匹配、插入和删除,并应用缓存感知调度来高效处理各种复用模式。这种方法与连续批处理 [280]、分页注意力(PagedAttention)[125] 和张量并行兼容,即使在缓存未命中的情况下,也只会增加极小的时间和内存开销。
基数注意力通过基数树将令牌序列映射到其对应的 KV 缓存张量,而缓存本身则以非连续的、基于页的内存布局存储。该树驻留在 CPU 内存中,维护成本极低。当启用连续批处理时,活跃批处理引用的节点不能被删除。每个节点都有一个引用计数器,用于跟踪有多少活跃请求在使用它,只有当该计数器归零时,节点才会被移除。
基数注意力也适用于多 GPU 环境。在张量并行下,每个 GPU 都保留自己的共享 KV 缓存和子树,无需 GPU 间同步。SGLang 路由管理器通过合并所有 GPU 子树来构建和管理一个元树。当新的批处理到达时,路由管理器会在元树上执行前缀匹配,并根据请求亲和性选择调度策略。处理完成后,路由管理器和工作节点会独立更新各自的本地树,而路由管理器会在系统低负载时段更新元树以保持一致性。
5.6.4 注意力编程模型(Attntion Programming Model):
FlexAttention
为加速注意力操作,已提出了众多注意力优化方法,但大多数都依赖手动编写特定于硬件的内核,这增加了实现和测试的复杂性。为提高适用性和灵活性,研究者提出了 FlexAttention [57]。
FlexAttention 是一种通用、灵活的编程模型,允许开发人员在 PyTorch [201] 中仅添加极少的额外代码,就能实现各种注意力优化。研究发现,大多数注意力变体都可以通过在 softmax 阶段之前修改中间分数矩阵来实现,因此 FlexAttention 接收两个可调用函数(score_mod 和 mask_mod)以及张量输入。在编译过程中,PyTorch 会自动将这些函数转换为基于模板的手写注意力内核,并且通过 PyTorch 自动求导机制生成前向和反向计算图。算子融合在此过程中自动进行,无需任何底层内核开发就能生成优化的内核代码。
FlexAttention 还通过 BlockMask 支持稀疏性优化,BlockMask 会在掩码矩阵中记录块级稀疏性,以减少计算量和内存使用,同时支持多种注意力变体的灵活组合。该框架允许独立或组合实现相对位置嵌入 [217]、ALiBi [207] 和闪电注意力(FlashAttention)[51] 等技术。
PyTorch 2.5 及更高版本支持 FlexAttention,而 Unsloth [244] 提供了基于 FlexAttention 的多种内核应用。
5.6.5 多查询注意力优化(MQA Optimization):
FireAttention
FireAttention 是 Fireworks AI [67] 开发的一种基于 FP16 和 FP8 的优化技术,旨在提升混合专家模型(MoE)的性能。它作为多查询注意力(MQA)的自定义 CUDA 内核实现,能在 NVIDIA H100 GPU 上针对各种批大小和序列长度高效利用内存带宽。FireAttention 专为多 GPU 环境设计,与传统大型语言模型推理引擎相比,能实现更高的每秒请求数(RPS)和更低的令牌生成延迟。
FireAttention V2 增加了对 NVIDIA Hopper 架构的 FP16 和 FP8 预填充内核支持,并引入了多主机部署优化。在长上下文在线推理工作负载中,与现有引擎相比,它的吞吐量最高可提升 8 倍,延迟最高可降低 12 倍。
FireAttention V3 通过提供专用内核进一步优化了关键矩阵乘法和注意力操作,将支持范围从 NVIDIA GPU 扩展到了 AMD MI300 硬件。
5.7 采样优化(Sampling Optimization)
由于大型语言模型采用自回归方式生成文本,输入序列越长,计算量就越大,用户等待时间也会越长。此外,内存 I/O 延迟(而非原始计算)往往成为主要瓶颈,这会影响交互式 AI 系统或实时翻译等场景的性能 —— 在这些场景中,快速响应至关重要。
投机解码 [131, 262] 借鉴了计算机处理器中投机执行的优化理念,以此加速令牌生成。在投机执行中,会在确认操作是否必要之前并行执行这些操作 —— 这与分支预测颇为相似。

图 25 通过两个模型阐释了大型语言模型中的这一概念:一个是高精度的目标模型(原始大型语言模型),另一个是更轻量、更快的草稿模型。草稿模型生成候选令牌,随后由目标模型进行验证。这种机制称为投机采样,它允许目标模型一次性检查最多𝐾个令牌,并决定接受或拒绝它们。如果某些令牌被拒绝,则会从调整后的概率分布中采样额外令牌。对这些候选令牌的并行验证构成了投机解码,无需改变原始模型的架构即可加快生成速度。
推测解码模型(Speculative Decoding Model)
多个推理引擎可采用多个草稿模型进行推测解码。尽管轻量级大型语言模型通常被用作草稿模型,但有些系统会采用基于增强语言模型效率的外推算法(EAGLE)[137] 构建的模型。EAGLE 是一种推测采样框架,它通过使用超前一步的令牌序列来减少特征级不确定性,并以最小开销实现精准的特征预测。它通过采用树注意力的树结构草稿模型实现推测采样,且仅需添加一个 Transformer 解码器层作为插件模块,足够轻量以适用于实际部署。
由于草稿令牌的接受率同时依赖于位置和上下文,EAGLE-2 [136] 利用草稿模型的置信度分数来估计这一接受率,并动态调整草稿树结构以增加被接受令牌的数量。
顺应近期测试时缩放的趋势,EAGLE-3 [138] 被提出以克服原始 EAGLE [137] 中的特征预测限制 —— 这些限制制约了令牌预测的灵活性并降低了数据增强的效益。EAGLE-3 移除了这些限制,直接预测令牌。通过在训练期间模拟多阶段生成,它最大限度地提高了草稿模型的输入灵活性,并随着训练数据规模扩大实现了更高的加速比。
推测解码的优化(Optimization for Speculative Decoding)
研究仍在不断完善推测执行。基于树的推测推理 [174] 会同时生成多个候选序列,提高目标模型批准令牌的可能性。为解决草稿模型难以适应输入分布变化的问题,在线推测解码 [154] 通过知识蒸馏逐步使草稿模型与目标模型对齐。这使得能够为不同输入模式训练和部署不同的草稿模型,并将查询路由到最合适的草稿模型,从而提高令牌接受率。有研究提出通过应用 MXFP4 仅权重量化 [78] 来加速草稿模型推理。该研究引入了带量化草稿模型的多级推测解码(ML-SpecQD),这种方法将量化与分阶段推测解码相结合,将草稿模型中的令牌生成任务委托给更小的量化草稿模型。谷歌还将推测解码应用于其 AI 搜索功能,使推理速度提升了两倍多。
推理引擎中的支持(Support in Inference Engines)
多个大型语言模型推理框架已整合了推测解码。Ollama [194]、PowerInfer [227]、MAX [179] 和 llama.cpp [82] 均直接提供这一功能。vLLM [125] 执行离线推测解码,一次最多生成 5 个令牌,且包含一个基于 n 元语法的建议模块 —— 该模块将输入字符串拆分为 n 元语法以计算相似度分数。MLC LLM [177] 支持结合轻量级草稿模型的推测解码,还支持 Medusa [37] 和 EAGLE [137] 系列草稿模型;TGI [110] 也提供 Medusa [37] 和 n 元语法方法。SGLang [295] 实现了结合 EAGLE [137]、EAGLE-2 [136] 和 EAGLE-3 [138] 的推测解码,并与基数缓存和分块预填充无缝集成。TensorRT-LLM [191] 兼容 EAGLE [137]、EAGLE-2 [136] 和 Medusa [37] 等草稿模型,此外还支持递归草稿生成器(ReDrafter)[47](递归预测草稿)和前瞻解码(执行并行 n 元语法预测与验证)。商业引擎(包括 Friendli Inference [71] 和 Fireworks AI [67])也利用推测解码来加速推理。
5.8 结构化输出(Structured Outputs)
在自回归大型语言模型中,生成的令牌既作为模型的输入,也作为模型的输出。然而,在令牌化过程中,有意义的单元可能被分割,Unicode 字符也可能被拆分。这一限制在需要问题解决或规划的应用中尤为突出,例如推理任务或 AI 智能体 —— 在这些场景中,JSON、函数调用或代码块等结构化输出至关重要。
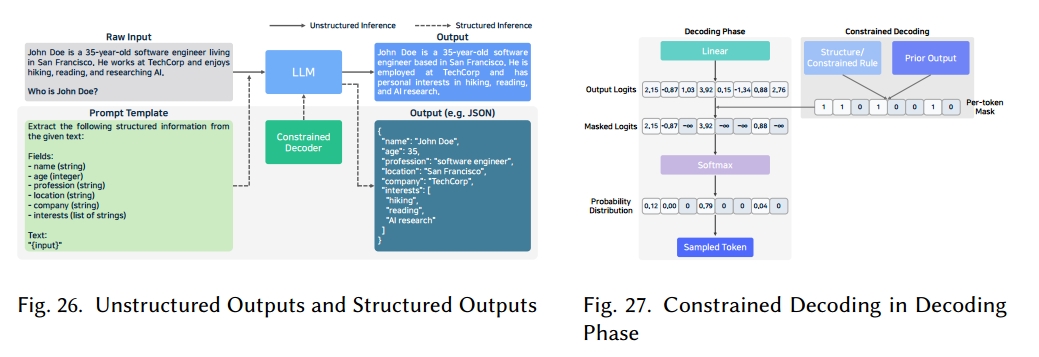
如图 26 所示,结构化输出 [113, 151] 指的是生成遵循预定义格式(如 JSON、XML 或其他结构化模式)的文本。与典型的自由格式大型语言模型输出不同,结构化生成可确保生成的内容符合下游系统预期的约束条件。例如,若数据库条目或 API 调用需要 JSON 格式,结构化输出能让大型语言模型返回有效的 JSON。
现代大型语言模型已超越基本的文本生成功能,能够支持代码创建、函数调用、自主决策等任务。为实现这些应用,推理引擎必须提供机器可读取的结构化输出,以便与其他系统顺畅集成。结构化生成所产生的输出符合明确的模式(如 JSON 或 SQL),从而提高了正确性和一致性,简化了解释与集成过程,并且通过剔除不必要或无效的信息减少了幻觉现象。因此,通常无需额外微调就能满足特定领域的输出要求 [250]。
约束解码 [250, 260] 是生成结构化输出的常用方法。如图 27 所示,在每个解码阶段都会对整个词汇表进行评估,屏蔽掉违反输出模式的令牌。计算完对数几率后,令牌级掩码会使任何可能破坏结构的令牌失效;随后在 softmax 操作前将这些对数几率设为零。这种掩码过程直接影响结构化生成的性能和速度。
在使用有限状态机(FSM)的结构化生成中 [260],大型语言模型会按顺序生成令牌,同时在机器定义的状态间切换。FSM 会记录当前状态,并将任何违反所需格式的令牌概率设为零,从而将其过滤掉。JSON 模式等结构可建模为有向图 FSM,其中每个节点代表有效的部分序列,每条边代表允许的下一个令牌。FSM 解码速度较快,但仅能处理简单模式,难以表示嵌套 JSON 等递归结构。
使用上下文无关文法(CFG)[28, 77] 可支持更复杂的结构化生成。CFG 通过产生式规则定义语言结构,能够捕捉 FSM 无法处理的格式。然而,在运行时使用 CFG 进行引导需要对照整个词汇表递归检查这些规则,并维护多个解析器栈,这会增加显著的计算开销。
结构化输出的库/框架(Library/Frameworks for Structured Outputs)
Outlines [59] 库通过基于有限状态机(FSM)的正则表达式解析器实现引导式生成,该解析器可在解码过程的任意点启动或停止。为高效识别有效令牌,它构建了一个索引,使每个步骤的平均运行时间达到 O (1)。该库通过多项式采样扩展序列,直到出现 EOS 令牌,然后应用布尔掩码生成未归一化的条件分布;同一掩码会在后续步骤中复用。除 FSM 引导外,Outlines 还支持多项选择提示,以及基于扩展巴科斯 - 诺尔范式(EBNF)编写的 CFG 的结构化生成。
XGrammar [58] 是一个专为高效性、灵活性和可移植性设计的结构化生成库。它支持用于复杂格式的 CFG,并包含系统级优化以实现高速执行。其 C++ 后端便于集成到各种运行时环境中。为减少递归开销,XGrammar 将每个 CFG 转换为字节级下推自动机(PDA)。该 PDA 将仅通过位置验证的上下文无关令牌与需要完整栈检查的上下文相关令牌分开。上下文无关令牌会预先验证并缓存以供复用,而上下文相关令牌则由 PDA 动态检查。XGrammar 还维护一个持久化执行栈,用于快速分支和回滚,并扩展上下文窗口以减少上下文相关令牌,使每个令牌的延迟降低多达 100 倍。
LM Format Enforcer [184] 通过令牌级过滤保证输出格式,同时保留模型的表达自由度。它独立于基础模型和令牌器工作,支持批处理解码和波束搜索,并能强制生成 JSON Schema、JSON 或正则表达式等格式。在内部,它将用于读取字符集的字符级解析器与存储令牌器可生成的所有令牌的令牌器前缀树相结合。只有当两种结构都允许时,某个令牌才会被接受。每个令牌生成后,解析器和树会共同推进,为下一步准备约束条件。这种方法严格遵循目标格式,同时允许模型处理空格和词序等细节。
Low-level Guidance(llguidance)[93] 是一个使用 CFG 快速生成结构化输出的库。它接收 CFG、令牌器和令牌前缀,然后计算在遵循前缀的情况下仍能生成符合文法的字符串的有效下一个令牌集(令牌)。该库掩码效率极高,对于包含 128k 条目的令牌器,每个令牌仅需约 50 微秒的 CPU 开销。这种速度源于基于正则表达式导数 [94] 上的厄尔利算法的 CFG 解析器,以及用于掩码计算的令牌前缀字典树。支持的文法格式包括 JSON Schema、正则表达式、源自 Lark [127] 的 CFG,以及 llguidance 自身的文法语法。
GGML 巴科斯 - 诺尔范式(GBNF)[81] 是 llama.cpp [82] 中引入的一种形式文法格式,用于约束输出。它将传统 BNF 表示法与现代正则表达式特性相结合,将文法指定为连接非终结符和终结符的产生式规则。GBNF 与 JSON Schema 兼容,可通过命令行界面(CLI)或应用程序接口(API)使用,便于直接控制结构化生成。
OpenAI 结构化输出 [197] 通过函数调用和响应格式规范实现结构化生成。函数调用允许模型安全调用外部系统函数,而响应格式规范确保输出与所需的 JSON 模式匹配。这两项功能都提供类型安全性,消除了因格式错误导致的后处理或重试需求,且无需大量提示工程就能保持一致的格式。内置的安全策略使系统能够拒绝不安全或不适当的请求。
结构化输出的性能评估(Performance Evaluation of Structured Output)
超越模仿游戏基准(BIG-Bench)[229] 和大规模多任务语言理解(MMLU)-Pro [255] 等基准测试被用于评估大型语言模型的多语言和多任务性能。
随着结构化输出质量对大型语言模型的实际部署变得至关重要,新的基准测试更直接地针对这一能力。JSONSchemaBench [76] 提供了 10,000 个不同复杂度和约束条件的真实世界 JSON 模式,能够从模式遵循度、输出效率和泛化能力等指标评估约束解码技术。借助官方 JSON Schema 测试套件,JSONSchemaBench 对 llguidance [93]、GBNF [81] 等进行评估。Outlines [59]、XGrammar [58]、OpenAI [197] 和 Gemini [86],并提供详细的功能和准确性分析。
StructTest [41] 是一种基于规则的评估工具,用于衡量大型语言模型(LLM)在生成结构化输出时遵循复杂指令的能力。该工具注重成本效益、易用性、减少偏差以及对数据污染的鲁棒性,会报告准确性和一致性,还能间接评估指令分解和推理能力。它已应用于 GPT-3.5、GPT-4 [5]、Claude 3 系列 [22]、DeepSeek-v3 [148] 等模型,用于摘要生成、代码生成、HTML 创建、数学推理等任务。
为进一步研究结构化生成,SoEval [156] 提供了一个结构化输出基准数据集,涵盖 13 种输出类型(如 JSON、XML 等),涉及科学、技术、文学、医疗等 20 多个领域。
推理引擎中的支持(Support in Inference Engines)
从推理引擎角度来看,vLLM [125] 在在线模式(如 OpenAI Completions 和 Chat API [197])和离线模式下,均支持结合 Outlines [59]、LM Format Enforcer [184] 和 XGrammar [58] 的引导解码。SGLang [295] 集成了 Outlines [59]、XGrammar [58] 和 llguidance [93];LightLLM [142] 支持 Outlines [59] 和 XGrammar [58]。MAX [179]、MLC LLM [177] 和 TensorRT-LLM [191] 采用了 XGrammar [58];而 Ollama [194]、llama.cpp [82] 和 PowerInfer [227] 则依靠 GBNF [81] 来执行格式约束。LMDeploy [162] 通过其 PyTorch [201] 接口提供结构化输出;主流商业引擎则通过专有解决方案或与 OpenAI 兼容的 API [197] 提供同等功能。
6 未来方向与开放挑战(Future Directions and Open Challenges)
大型语言模型推理引擎不断支持新的优化方法和模型,但为了灵活应对快速变化的大型语言模型生态系统和多样化的服务需求,还需考虑以下几点。
6.1 多模态大型语言模型的需求(Requirements for Multimodal LLMs)
当前大多数大型语言模型推理引擎都是针对基于文本的模型进行优化的。然而,仅依靠文本处理信息存在局限性。要实现人类级别的智能,必须支持图像、音频、视频等多种数据类型。为此,已开发出 Qwen2-VL [252]、LLaVA-1.5 [150] 等多模态模型。为有效支持这类模型,推理引擎的设计必须能高效处理多模态数据预处理和多流并行执行。
在这种情况下,现有的模型压缩技术(如量化)必须进行调整,以在减小模型规模的同时保留特定模态的信息。仅靠混合并行等软件层面的方法是不够的。因此,需要考虑新的硬件加速内核和解码方法,例如为多模态输入量身定制的投机解码。
在多模态任务中,使模型架构适应硬件的一个很好的例子是多模态旋转位置嵌入(M-RoPE),它在 Qwen2-VL [252] 和 LLaVA-1.5 [150] 中被引入。M-RoPE 扩展了 Transformer 模型中使用的传统位置嵌入,以更有效地捕捉各种多模态输入中的位置关系。
6.2 Transformer 之外的替代架构(Alternative Architectures Beyond Transformers)
尽管基于 Transformer 的模型在大型语言模型推理中仍占主导地位,但专为多模态大型语言模型设计的新架构正在兴起。RetNet [234]、RWKV [203] 等模型提出了标准 Transformer 设计的替代方案。另一个值得注意的方向是 Mamba [91],这是一种为克服 Transformer 局限性而开发的序列建模架构。Mamba 采用选择性状态模型(SSM),能更高效地处理长序列,在不依赖标准注意力机制的情况下实现线性时间复杂度。
Jamba [141] 是一种混合模型,结合了 Mamba [91] 和 Transformer 架构,旨在兼具两者的优势。它还集成了混合专家(MoE)策略,在增加模型容量的同时,使推理时的活跃参数数量保持在可管理范围内。
这些趋势凸显了对支持多样化架构的通用推理引擎的需求日益增长。未来的推理系统不仅要针对 Transformer 模型的内部操作进行优化,还需具备足够的可扩展性和灵活性,以支持新型及不断演进的模型结构。
6.3 面向效率的硬件感知融合与混合精度内核(Hardware-Aware Fusion and Mixed-Pre cision Kernels for Effciency)
在传统以卷积操作为主的 AI 工作负载中,优化通常通过简单的算子融合(如与 ReLU 融合)实现。然而,在基于 Transformer 和扩散模型的生成式 AI 时代,需要更复杂、针对特定硬件架构的融合策略。一个典型例子是 FlashAttention-3 [215],它针对 NVIDIA H100 硬件进行了高度优化。这些复杂的融合技术涉及先进的分块策略,由专业工程师精心设计,以适配硬件的共享内存和缓存大小限制。
此外,如表 8 所示,生成式 AI 模型需要支持多种数据类型精度,以在减小模型规模的同时保持精度。因此,开发能够灵活高效处理混合精度计算的算子内核至关重要。
6.4 扩展上下文窗口与内存管理(Extended Context Windows and Memory Management)
LLM 领域存在一种日益明显的趋势:处理极长的上下文窗口,范围从数万到数百万令牌。例如,ChatGPT o1 [196] 支持多达 128K 令牌,Google Gemini 2.0 Flash [86] 支持 1M 令牌,而最近推出的 Llama 4 Scout [171] 据称可处理多达 10M 令牌。
这种扩展导致 KV 缓存大小急剧增加,给内存管理带来巨大挑战。为解决这一问题,研究者提出了分层缓存管理 [293]、部分卸载到 CPU 内存 [129] 和内存高效注意力机制 [125] 等技术。然而,这些方法尚未能完全应对上下文长度的增长,仍需进一步研究。
6.5 复杂逻辑推理(Complex Logical Reasoning)
现代 LLM 正从简单的响应生成向执行复杂逻辑推理演进。这包括逐步引导用户解决问题、自主生成思维链(CoT)推理 [259],以及与外部工具交互完成任务。
在这类场景中,中间推理步骤可能消耗大量令牌,且通常需要多轮对话来优化答案。因此,管理会话连续性和上下文保存变得至关重要。对此,推理引擎正朝着支持流式输出 [266] 和多轮对话优化 [7,73] 的方向发展。稳定管理长令牌序列和复杂推理流程的能力,正成为 LLM 推理系统的核心竞争力。
6.6 基于应用需求选择推理引擎(Inference Engine Selection Based on Application Nee ds)
LLM 推理引擎的选择与设计应平衡应用需求和系统约束。对于翻译服务或对话代理等需实时交互的应用,延迟优化是首要任务。另一方面,必须处理高流量的服务器端应用则以最大化吞吐量为优先。
展望未来,开发同时支持多模态数据硬件加速和多样化模型架构通用兼容性的推理引擎将变得越来越重要。持续的挑战包括:优化扩展上下文窗口的内存使用、设计能灵活处理复杂推理的架构,以及制定平衡延迟与吞吐量的策略。
6.7 推理中的安全性支持(Security Support in Inference)
在 LLM 推理过程中,已出现提示注入攻击、越狱攻击和数据泄露等漏洞 [273]。提示注入攻击指攻击者操纵输入以覆盖模型的系统提示或目标。在金融、医疗等处理敏感数据的环境中,个人数据泄露风险显著。此外,若恶意攻击生成异常或有害数据,可能严重影响用户体验和系统稳定性。
为降低这些风险,可在模型训练阶段应用对抗训练 [153] 等鲁棒性技术。在推理阶段,可使用 OpenAI Moderation [168] 等工具、防止指令操纵的机制和输入净化方法 [180,183] 来拦截有害或恶意输入。
从服务安全角度,可实施基于角色的访问控制(RBAC)和多因素认证(MFA)以防止未授权访问。此外,可设置访问令牌在特定时间后过期,以增强安全策略。
目前,大多数 LLM 推理引擎主要关注性能,未包含专门的安全功能,但它们试图通过数据过滤和强化伦理政策等方法降低风险。
6.8 支持设备端推理(Support for On-Device Inference)
大多数 LLM 服务利用云端或数据中心的大规模资源执行推理,并将结果交付给用户。这种方式虽能实现快速计算,但依赖网络且需将用户数据传输至服务器,引发隐私担忧。因此,对边缘设备和移动设备上的设备端(或本地)LLM 推理需求日益增长。
传统上,LLM 模型过大而无法在单个设备上运行,但小型语言模型(SLMs)—— 如 Llama 3.2 [88]、Gemma [235]、Phi-3 [2] 和 Pythia [32]—— 的出现,使 LLM 能够在嵌入式系统、移动设备、物联网系统以及单 GPU 环境中运行。
由于边缘环境(如嵌入式和移动系统)的硬件规格低于服务器,模型压缩以及针对硬件的并行化和内存优化都至关重要。例如,移动推理优化包括容错感知压缩、I/O 重计算流水线加载和块生命周期管理 [277]。研究还探索了协同推理,即多个边缘设备共享计算负载 [283]。对于单 GPU 环境,研究者正研究 4 位量化和内存卸载技术,将权重、激活值和 KV 缓存分布到 CPU、磁盘和其他内存资源 [221]。
这些进展有助于降低服务器功耗,并在网络受限环境中实现个性化模型和推理。然而,边缘设备的制造商和运行环境差异显著,难以进行通用优化。此外,开发依赖编译器和硬件的转换工具会产生额外开发成本。
在现有 LLM 推理引擎中,llama.cpp [82]、MLC LLM [177] 和 TensorRT-LLM [191] 对边缘环境提供部分支持。基于 C/C++ 实现的 llama.cpp [82] 在不同平台上具有高度可移植性。MLC LLM [177] 使用 TVM [43] 编译器支持 GPU、移动和 Web 环境,但其硬件兼容性有限。TensorRT-LLM [191] 仅支持特定边缘设备,如 NVIDIA Jetson 系列。
6.9 支持多样化硬件以优化推理(Support Diverse Hardware for Inference Optimization)
传统上以 NVIDIA GPU 为中心的 LLM 推理,如今随着 TPU [116]、神经处理单元(NPUs)和各种 LLM 加速器的出现,正扩展到异构硬件。除广泛使用的 AWS Inferentia [15] 和 Google TPU [116] 外,AMD Instinct MI300X [225]、Furiosa AI RNGD(张量收缩处理器)[121] 和 Cerebras CS-2(WSE-2)[140] 等新型加速器也在开发中。此外,存内处理(PIM)[119,198] 等下一代内存技术也在研发中。
为支持异构硬件,引擎必须整合流水线执行、批处理优化和负载均衡。然而,不同硬件类型在性能、同步和通信开销方面的差异可能带来挑战。研究已探索了在异构 GPU 集群中使用阶段感知分区和自适应量化 [290] 进行 LLM 推理优化,以及基于硬件感知的预填充和解码过程分配以优化推理 [202]。此外,研究者提出了子批交错 [101] 等技术,以优化多 NPU 和 PIM 设备系统的推理。
6.10 支持云编排和服务平台(Support for Cloud Orchestration and Serving Platforms)
云编排和服务策略对 LLM 推理服务至关重要。在云端部署大规模推理服务时,Kubernetes [36] 等编排平台可实现自动扩缩容、硬件资源监控(Prometheus [243]、Grafana [39])和故障恢复。为此,推理引擎应提供容器化环境、多节点部署和负载均衡工具,以便根据服务需求和服务等级目标(SLOs)轻松配置。
大多数 LLM 推理引擎提供内置服务功能,但大规模服务系统需要额外的工作负载分配、调度和自动扩缩容优化。vLLM [125]、TensorRT-LLM [191]、DistServe [297] 和 Sarathi-Serve [297] 利用 Ray [181] 支持分布式运行时和服务。此外,TensorRT-LLM [191] 与 NVIDIA Triton 推理服务器 [187] 和 NVIDIA Dynamo [192] 集成以实现模型部署和执行,而 TGI [110] 可通过 Hugging Face Spaces [109] 部署模型。
7 结论(Conclusion)
本文系统分析了 LLM 推理引擎的优化方法和硬件适配策略。首先,我们明确了仅解码器 Transformer 的内存和计算瓶颈,并总结了批处理、并行化、缓存和压缩等缓解方法。其次,我们从单节点与多节点、同构与异构设备支持两个维度对 25 个开源和商业推理引擎进行分类,并比较了它们的架构目标和支持的硬件。特别是,我们重点从易用性、易部署性、通用支持、可扩展性、吞吐量感知和延迟感知等方面分析了推理引擎。我们的分析表明,选择推理引擎需要平衡多个因素,包括延迟 - 吞吐量权衡、硬件多样性、推理引擎级优化支持和服务等级目标(SLO)。此外,我们概述了未来方向,包括多模态推理支持、Transformer 替代架构、更长上下文窗口、改进的逻辑推理、特定应用设计、更强的安全性、设备端执行、异构加速和云编排。总体而言,本研究为设计和运营下一代推理基础设施提供了实践基础。
总结
之前使用过TGI、llama.cpp、vllm、sglang、ktransformer(这个没有被统计进来)、lmdeploy。TGI是最早使用的,当时它的接口还不是openai的格式(目前已兼容了),支持的模型比较广泛,但是在目前看来,社区不够活跃,而且文档也不够详细,已经被vllm和sglang落下了。vllm和sglang各有优势,用起来都比较顺手,选择哪种根据需要部署的模型而定,有时候可能其中一个模型在某个上面部署会存在问题,这时候看看另一个框架怎么样。lmdeploy用的不是很多,但是它是唯一一个支持kv-cache-int8或int4量化的框架()其余框架大多支持fp8格式的),最新版本的部署起来也比较简单。llama.cpp旨在低资源的环境下部署,可以体验下较大规格的模型。ktransformer是结合CPU和少量GPU进行部署的,推理速度会比llama.cpp快。
如果是生产环境的话,推荐vllm和sglang,支持的模型多,社区活跃,文档也详细。如果是自己玩耍且资源不够的话,推荐使用ollama、llama.cpp、ktransformer。如果不想自己部署,直接用各大公司的在线版本完事。
参考链接:
25种LLM部署框架你知道多少?