深度学习基础—2
第一章、参数初始化
我们在构建网络之后,网络中的参数是需要初始化的。我们需要初始化的参数主要有权重和偏置,偏重一般初始化为 0 即可,而对权重的初始化则会更加重要,我们介绍在 PyTorch 中为神经网络进行初始化的方法。
1.1 常见初始化方法
均匀分布初始化, 权重参数初始化从区间均匀随机取值。即在(-1/√d,1/√d)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量。
正态分布初始化, 随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化。
- 全0初始化,将神经网络中的所有权重参数初始化为 0。
- 全1初始化,将神经网络中的所有权重参数初始化为 1。
- 固定值初始化,将神经网络中的所有权重参数初始化为某个固定值。
kaiming初始化,也叫做HE初始化。HE初始化分为正态分布的HE初始化、均匀分布的HE初始化。xavier初始化,也叫做Glorot初始化,该方法的基本思想是各层的激活值和梯度的方差在传播过程中保持一致。它有两种,一种是正态分布的xavier初始化、一种是均匀分布的xavier初始化。
接下来,我们使用 PyTorch 调用相关 API:
import torch
import torch.nn.functional as F
import torch.nn as nn# 1. 均匀分布随机初始化
def test01():linear = nn.Linear(5, 3)# 从0-1均匀分布产生参数nn.init.uniform_(linear.weight)print(linear.weight.data)# 2. 固定初始化
def test02():linear = nn.Linear(5, 3)nn.init.constant_(linear.weight, 5)print(linear.weight.data)# 3. 全0初始化
def test03():linear = nn.Linear(5, 3)nn.init.zeros_(linear.weight)print(linear.weight.data)# 4. 全1初始化
def test04():linear = nn.Linear(5, 3)nn.init.ones_(linear.weight)print(linear.weight.data)# 5. 正态分布随机初始化
def test05():linear = nn.Linear(5, 3)nn.init.normal_(linear.weight, mean=0, std=1)print(linear.weight.data)# 6. kaiming 初始化
def test06():# kaiming 正态分布初始化linear = nn.Linear(5, 3)nn.init.kaiming_normal_(linear.weight)print(linear.weight.data)# kaiming 均匀分布初始化linear = nn.Linear(5, 3)nn.init.kaiming_uniform_(linear.weight)print(linear.weight.data)# 7. xavier 初始化
def test07():# xavier 正态分布初始化linear = nn.Linear(5, 3)nn.init.xavier_normal_(linear.weight)print(linear.weight.data)# xavier 均匀分布初始化linear = nn.Linear(5, 3)nn.init.xavier_uniform_(linear.weight)print(linear.weight.data)if __name__ == '__main__':test07()
1.2 小节
网络构建完成之后,我们需要对网络参数进行初始化。常见的初始化方法有随机初始化、全0初始化、全1初始化、Kaiming 初始化、Xavier 初始化等,一般我们在使用 PyTorch 构建网络模型时,每个网络层的参数都有默认的初始化方法,当然同学们也可以通过交给大家的方法来使用指定的方式对网络参数进行初始化。
第二章、优化方法
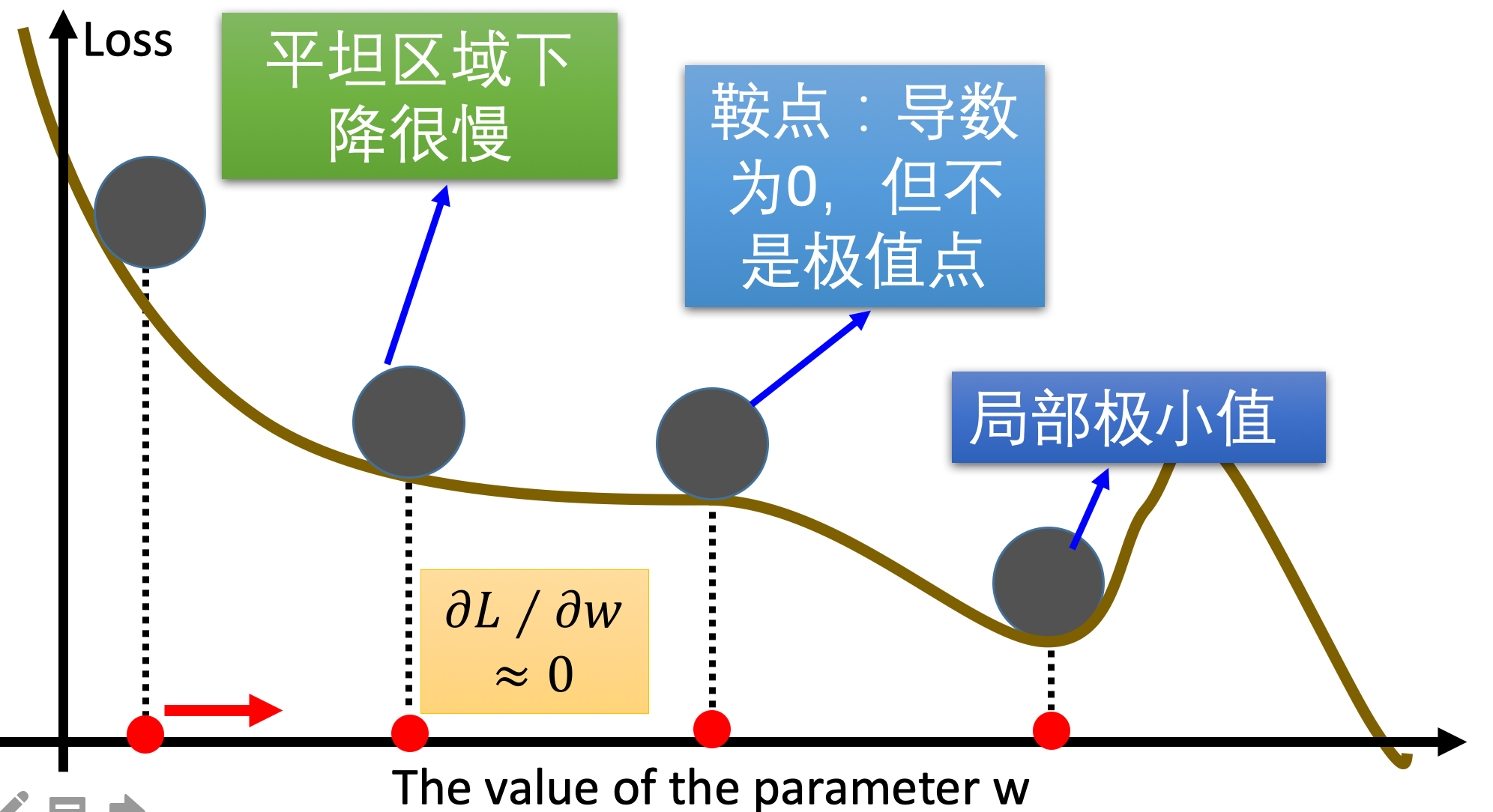
传统的梯度下降优化算法中,可能会碰到以下情况:
- 碰到平缓区域,梯度值较小,参数优化变慢 碰到 “鞍点” ,梯度为 0,参数无法优化;
- 碰到局部最小值 对于这些问题, 出现了一些对梯度下降算法的优化方法,例如:
Momentum、AdaGrad、RMSprop、Adam等。
下面解释鞍点:
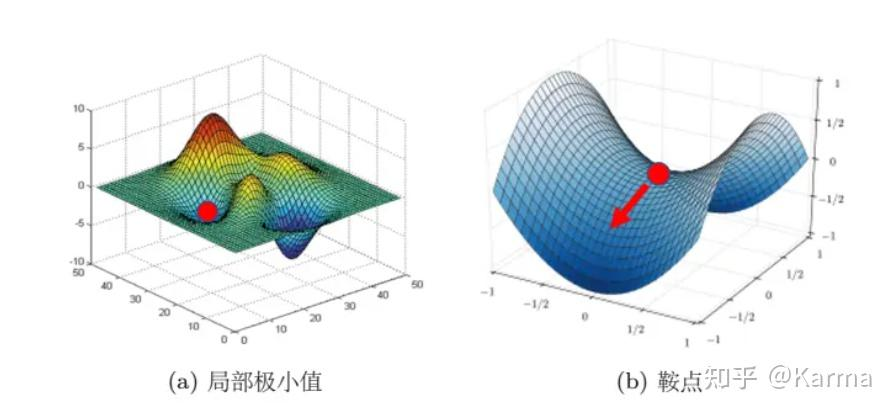
鞍点
(saddle point)与局部极小值点的区别:局部极小值为所在区域loss最小的点;鞍点所在区域还有可以让loss下降的点,只要逃离鞍点,就有可能降低loss。
2.1 指数加权平均
我们最常见的算数平均指的是将所有数加起来除以数的个数,每个数的权重是相同的。加权平均指的是给每个数赋予不同的权重求得平均数。移动平均数,指的是计算最近邻的 N 个数来获得平均数。
指数移动加权平均则是参考各数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近则对平均数的计算贡献就越大(权重越大)。
比如:明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。
- 计算公式可以用下面的式子来表示:
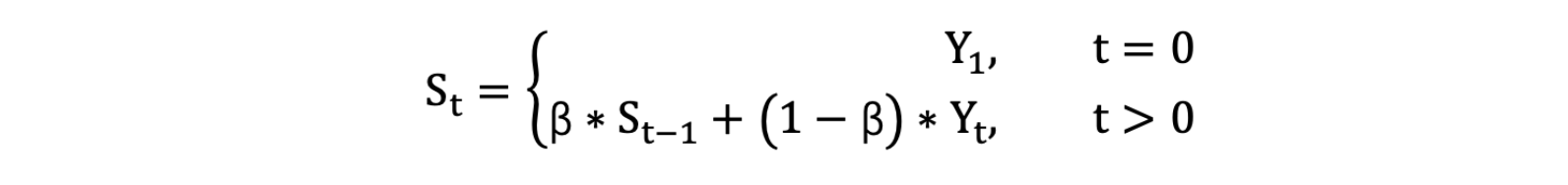
- StS_tSt :表示指数加权平均值;
- YtY_tYt: 表示 t 时刻的值;
- β 调节权重系数,该值越大平均数越平缓。
我们接下来通过一段代码来看下结果,我们随机产生进 30 天的气温数据:
import torch
import matplotlib.pyplot as pltELEMENT_NUMBER = 30# 1. 实际平均温度
def test01():# 固定随机数种子torch.manual_seed(0)# 产生30天的随机温度temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10print(temperature)# 绘制平均温度days = torch.arange(1, ELEMENT_NUMBER + 1, 1)plt.plot(days, temperature, color='r')plt.scatter(days, temperature)plt.show()# 2. 指数加权平均温度
def test02(beta=0.9):# 固定随机数种子torch.manual_seed(0)# 产生30天的随机温度temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10print(temperature)exp_weight_avg = []for idx, temp in enumerate(temperature, 1):# 第一个元素的的 EWA 值等于自身if idx == 1:exp_weight_avg.append(temp)continue# 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气氛乘以 (1-β)new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * tempexp_weight_avg.append(new_temp)days = torch.arange(1, ELEMENT_NUMBER + 1, 1)plt.plot(days, exp_weight_avg, color='r')plt.scatter(days, temperature)plt.show()if __name__ == '__main__':test01()test02(0.5)test02(0.9)
程序结果如下:
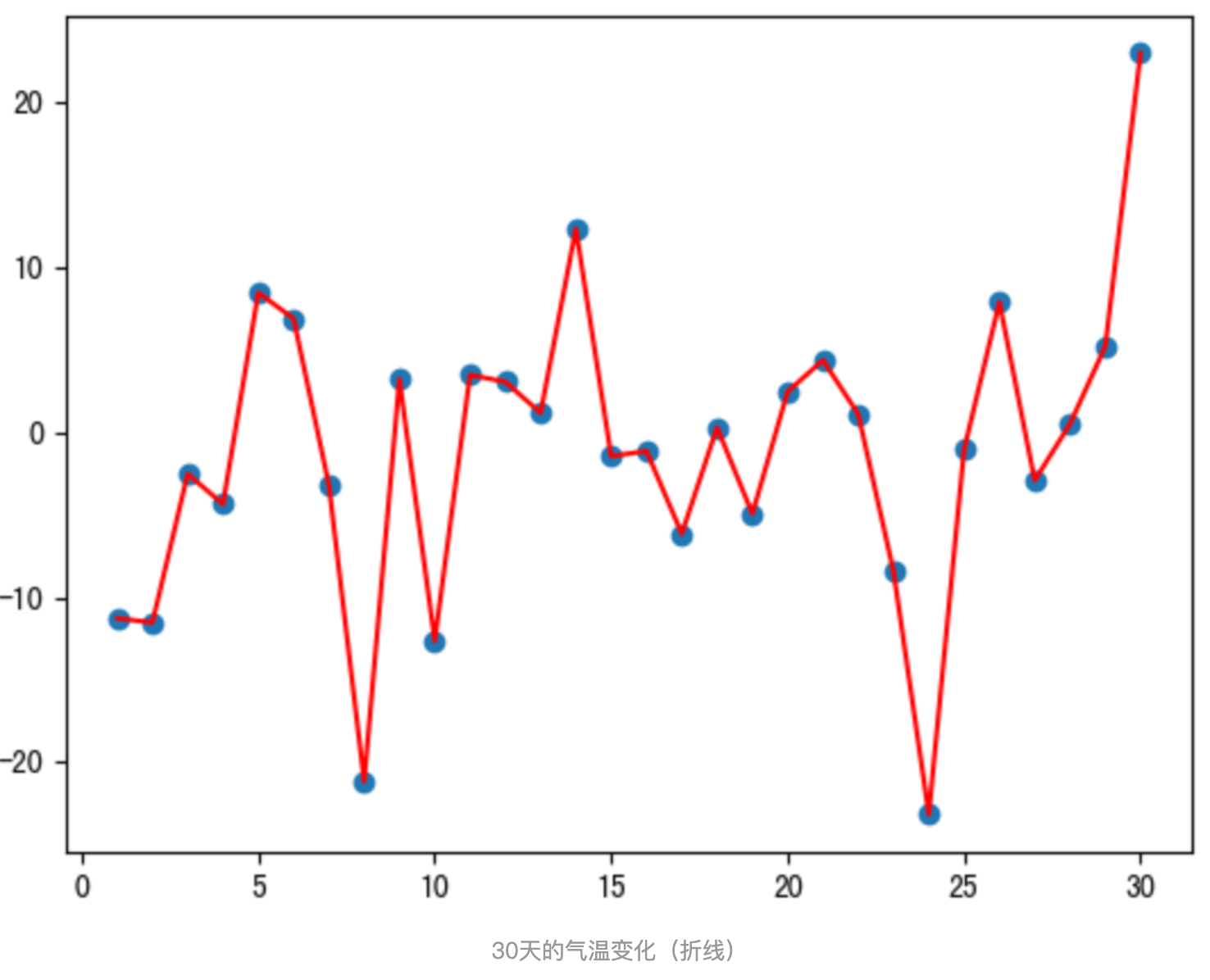
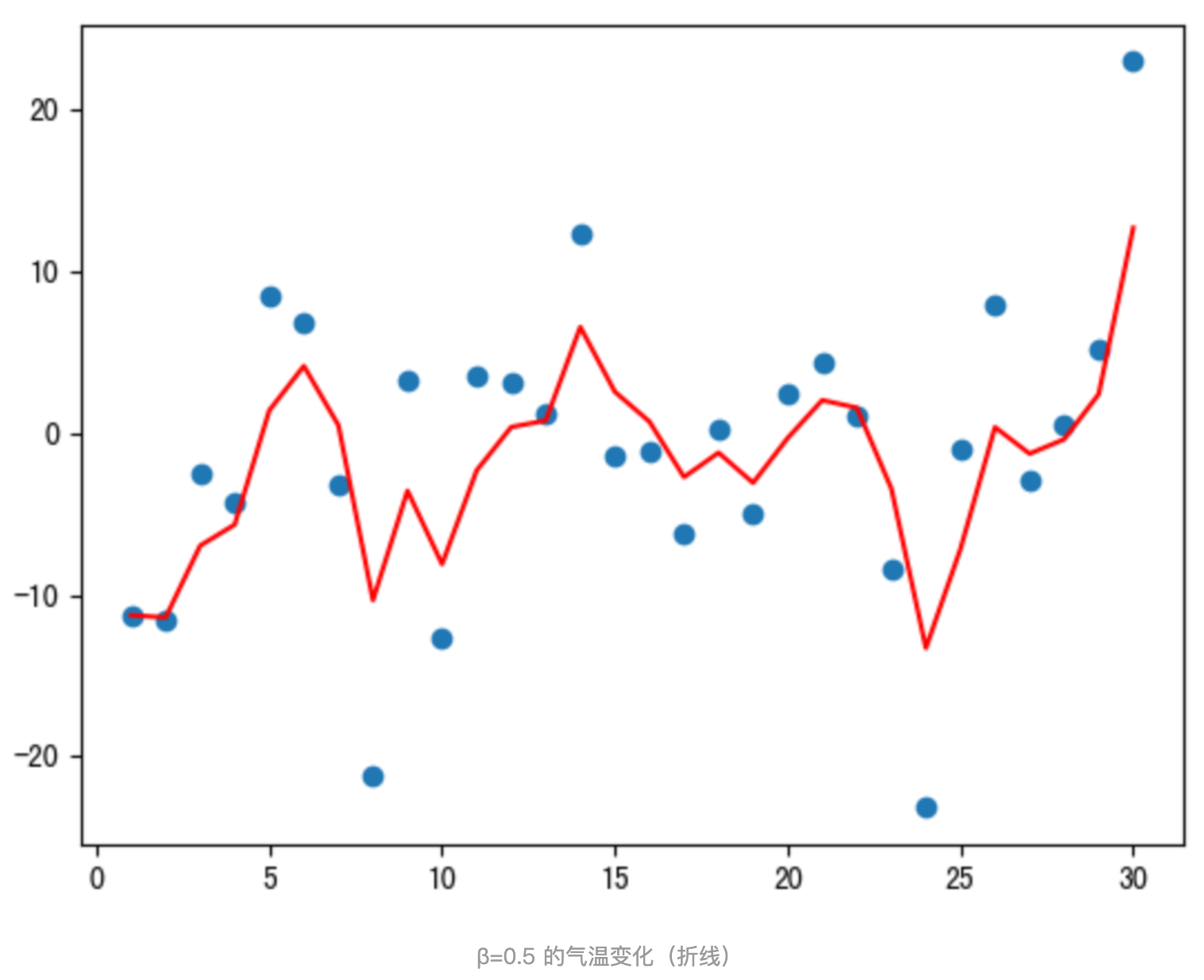
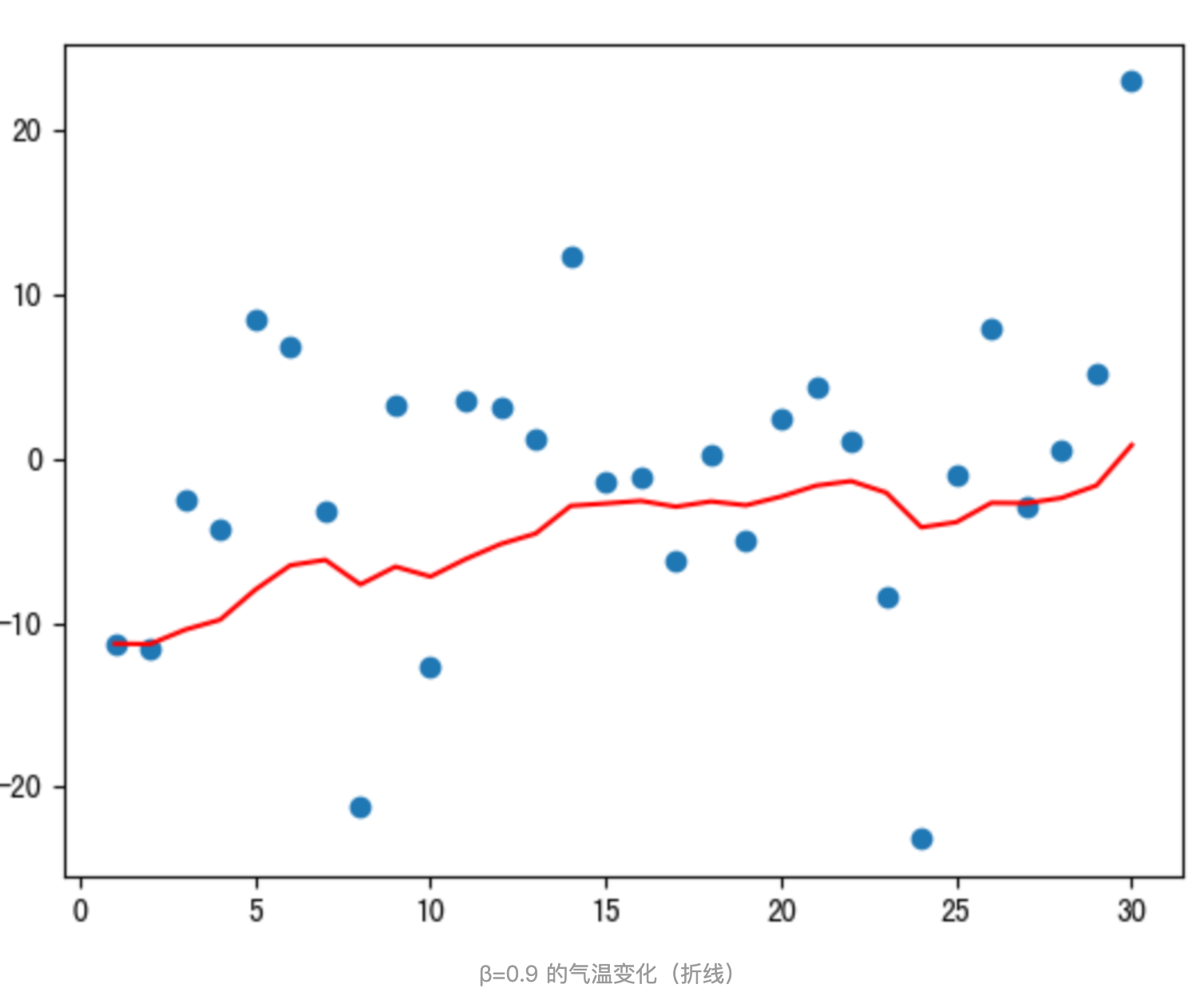
从程序运行结果可以看到:
- 指数加权平均绘制出的气氛变化曲线更加平缓; β 的值越大,则绘制出的折线越加平缓; β 值一般默认都是 0.9。
2.2 Momentum优化方法
当梯度下降碰到 “峡谷” 、”平缓”、”鞍点” 区域时, 参数更新速度变慢. Momentum 通过指数加权平均法,累计历史梯度值,进行参数更新,越近的梯度值对当前参数更新的重要性越大。
梯度计算公式:Dt=β∗St−1+(1−β)∗DtD_t = β * S_{t-1}+ (1 - β) * D_tDt=β∗St−1+(1−β)∗Dt
- St−1S_{t-1}St−1:表示历史梯度移动加权平均值
- DtD_tDt:表示当前时刻的梯度值
- β 为权重系数
咱们举个例子,假设:权重 β 为 0.9,例如:第一次梯度值:s1 = d1 = w1,第二次梯度值:s2 = 0.9 + s1 + d2 * 0.1,第三次梯度值:s3 = 0.9 * s2 + d3 * 0.1,第四次梯度值:s4 = 0.9 * s3 + d4 * 0.1。
- w 表示初始梯度
- d 表示当前轮数计算出的梯度值
- s 表示历史梯度值
梯度下降公式中梯度的计算,就不再是当前时刻 t 的梯度值,而是历史梯度值的指数移动加权平均值。公式修改为:
Wt+1=Wt−a∗DtW_{t+1} = W_t - a * D_tWt+1=Wt−a∗Dt
那么,Monmentum 优化方法是如何一定程度上克服 “平缓”、”鞍点”、”峡谷” 的问题呢?
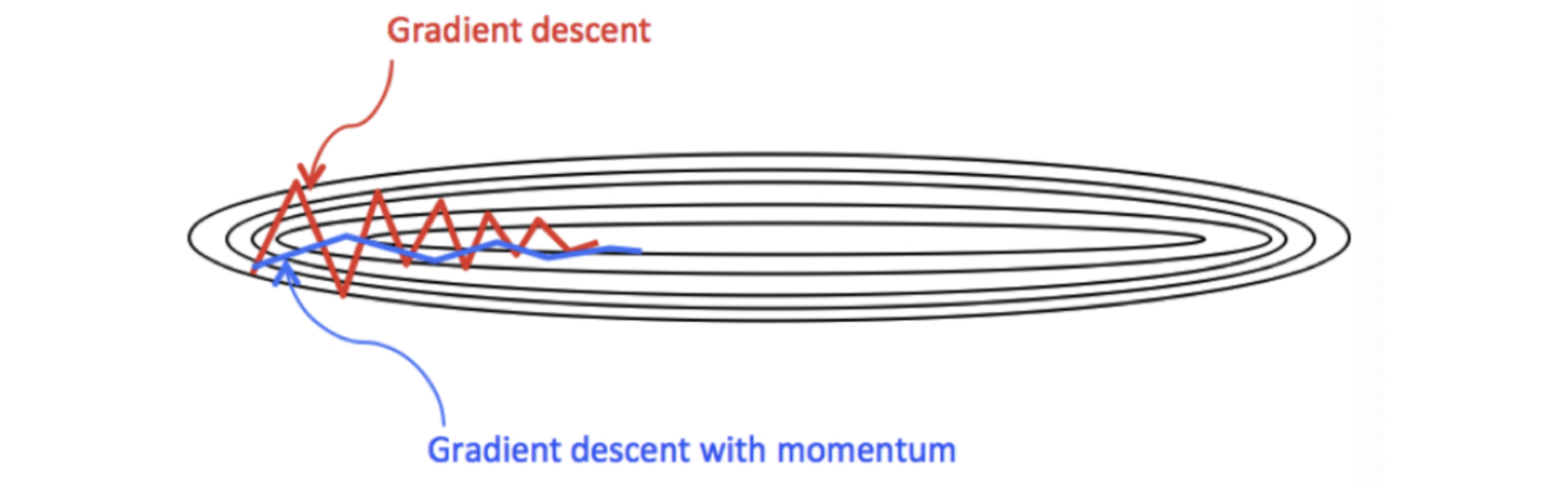
当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。一定程度上有利于降低 “峡谷” 问题的影响。
峡谷问题:就是会使得参数更新出现剧烈震荡。
Momentum 算法可以理解为是对梯度值的一种调整,我们知道梯度下降算法中还有一个很重要的学习率,Momentum 并没有学习率进行优化。
2.3 AdaGrad优化方法
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小,这是因为 AdaGrad 认为:在起初时,我们距离最优目标仍较远,可以使用较大的学习率,加快训练速度,随着迭代次数的增加,学习率逐渐下降。
其计算步骤如下:
- 初始化学习率 α、初始化参数 θ、小常数
σ = 1e-6 - 初始化梯度累积变量
s = 0 - 从训练集中采样 m 个样本的小批量,计算梯度 g
- 累积平方梯度
s = s + g ⊙ g,⊙ 表示各个分量相乘 - 学习率 α 的计算公式如下:
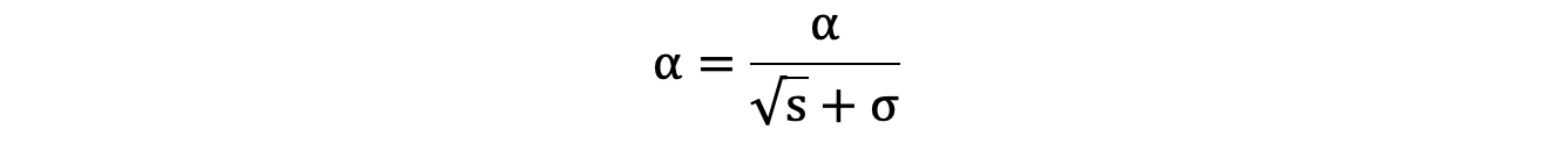
- 参数更新公式如下:
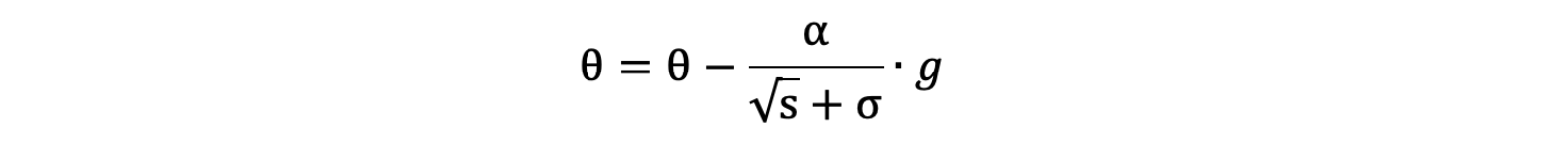
- 重复
2-7步骤.
AdaGrad缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
2.4 RMSProp优化方法
RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数移动加权平均梯度替换历史梯度的平方和。其计算过程如下:
- 初始化学习率 α、初始化参数 θ、小常数
σ = 1e-6 - 初始化参数 θ
- 初始化梯度累计变量 s
- 从训练集中采样 m 个样本的小批量,计算梯度 g
- 使用指数移动平均累积历史梯度,公式如下:
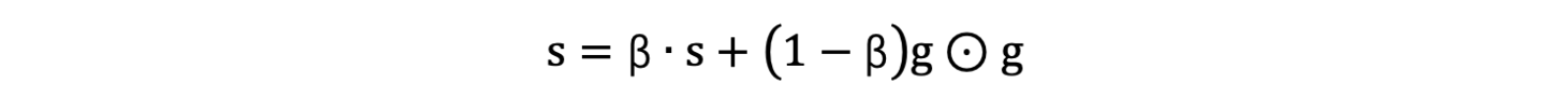
- 学习率 α 的计算公式如下:
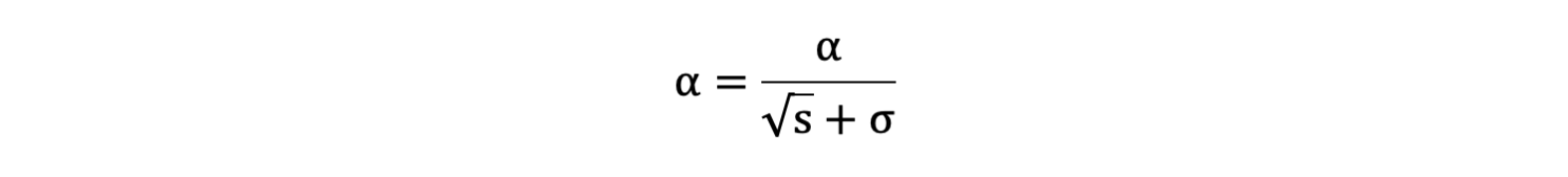
- 参数更新公式如下:
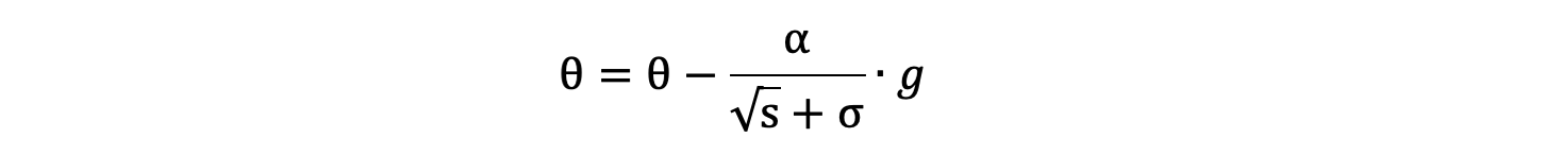
RMSProp 与 AdaGrad 最大的区别是对梯度的累积方式不同,对于每个梯度分量仍然使用不同的学习率。
RMSProp 通过引入衰减系数 β,控制历史梯度对历史梯度信息获取的多少. 被证明在神经网络非凸条件下的优化更好,学习率衰减更加合理一些。
需要注意的是:AdaGrad 和 RMSProp 都是对于不同的参数分量使用不同的学习率,如果某个参数分量的梯度值较大,则对应的学习率就会较小,如果某个参数分量的梯度较小,则对应的学习率就会较大一些。
2.5 Adam优化方法
Momentum 使用指数加权平均计算当前的梯度值、AdaGrad、RMSProp 使用自适应的学习率,Adam 结合了 Momentum、RMSProp 的优点,使用:移动加权平均的梯度和移动加权平均的学习率。使得能够自适应学习率的同时,也能够使用 Momentum 的优点。
2.6 小节
本小节主要学习了常见的一些对普通梯度下降算法的优化方法,主要有 Momentum、AdaGrad、RMSProp、Adam 等优化方法,其中 Momentum 使用指数加权平均参考了历史梯度,使得梯度值的变化更加平缓。AdaGrad 则是针对学习率进行了自适应优化,由于其实现可能会导致学习率下降过快,RMSProp 对 AdaGrad 的学习率自适应计算方法进行了优化,Adam 则是综合了 Momentum 和 RMSProp 的优点,在很多场景下,Adam 的表示都很不错。
第三章、正则化
在训深层练神经网络时,由于模型参数较多,在数据量不足的情况下,很容易过拟合。Dropout 就是在神经网络中一种缓解过拟合的方法。
3.1 Dropout 层的原理和使用
我们知道,缓解过拟合的方式就是降低模型的复杂度,而 Dropout 就是通过减少神经元之间的连接,把稠密的神经网络神经元连接,变成稀疏的神经元连接,从而达到降低网络复杂度的目的。
我们先通过一段代码观察下丢弃层的效果:
import torch
import torch.nn as nndef test():# 初始化丢弃层,p=0.8是以80%的概率舍去神经元dropout = nn.Dropout(p=0.8)# 初始化输入数据inputs = torch.randint(0, 10, size=[5, 8]).float()print(inputs)print('-' * 50)outputs = dropout(inputs)print(outputs)if __name__ == '__main__':test()
程序输出结果:
tensor([[1., 0., 3., 6., 7., 7., 5., 7.],[6., 8., 4., 6., 2., 0., 4., 1.],[1., 4., 6., 9., 3., 1., 2., 1.],[0., 6., 3., 7., 1., 7., 8., 9.],[5., 6., 8., 4., 1., 7., 5., 5.]])
--------------------------------------------------
tensor([[ 0., 0., 15., 0., 0., 0., 0., 0.],[ 0., 0., 0., 0., 10., 0., 0., 0.],[ 0., 0., 0., 45., 0., 0., 0., 0.],[ 0., 0., 15., 0., 0., 0., 0., 0.],[25., 0., 0., 0., 0., 0., 0., 25.]])
我们将 Dropout 层的概率 p 设置为 0.8,此时经过 Dropout 层计算的张量中就出现了很多 0,(神经元失效在张量上的体现就是0),概率 p 设置值越大,则张量中出现的 0 就越多。
上面结果的计算过程如下:
- 先按照 p 设置的概率,随机将部分的张量元素设置为 0;
- 为了校正张量元素被设置为 0 带来的影响,需要对非 0 的元素进行缩放,其缩放因子为:
1/(1-p),上面代码中 p 的值为0.8, 根据公式缩放因子为:1/(1-0.8) = 5; - 比如:第 3 个元素,原来是 3,乘以缩放因子之后变成 15。
我们也发现了,丢弃概率 p 的值越大,则缩放因子的值就越大,相对其他未被设置的元素就要更多的变大。丢弃概率 P 的值越小,则缩放因子的值就越小,相对应其他未被置为 0 的元素就要有较小的变大。
当张量某些元素被设置为 0 时,对网络会带来什么影响?
模型中神经元失效,导致模型变笨。
比如上面这种情况,如果输入Dropout 后的样本,会使得某些参数无法更新,请看下面的代码:
import torch
import torch.nn as nn# 设置随机数种子
torch.manual_seed(0)def caculate_gradient(x, w):y = x @ wy = y.sum()y.backward()print('Gradient:', w.grad.reshape(1, -1).squeeze().numpy())def test01():# 初始化权重w = torch.randn(15, 1, requires_grad=True)# 初始化输入数据x = torch.randint(0, 10, size=[5, 15]).float()# 计算梯度caculate_gradient(x, w)def test02():# 初始化权重w = torch.randn(15, 1, requires_grad=True)# 初始化输入数据x = torch.randint(0, 10, size=[5, 15]).float()# 初始化丢弃层dropout = nn.Dropout(p=0.8)x = dropout(x)# 计算梯度caculate_gradient(x, w)if __name__ == '__main__':test01()print('-' * 70)test02()
程序输出结果:
Gradient: [19. 15. 16. 13. 34. 23. 20. 22. 23. 26. 21. 29. 28. 22. 29.]
----------------------------------------------------------------------
Gradient: [ 5. 0. 35. 0. 0. 45. 40. 40. 0. 20. 25. 45. 55. 0. 10.]
从程序结果来看,是否经过 Dropout 层对梯度的计算产生了不小的影响,例如:经过 Dropout 层之后有一些梯度为 0,这使得参数无法得到更新,从而达到了降低网络复杂度的目的。
第四章、批量归一化
在神经网络的搭建过程中,Batch Normalization (批量归一化)是经常使用一个网络层,其主要的作用是控制数据的分布,加快网络的收敛。
我们知道,神经网络的学习其实在学习数据的分布,随着网络的深度增加、网络复杂度增加,一般流经网络的数据都是一个 mini batch,每个 mini batch 之间的数据分布变化非常剧烈,这就使得网络参数频繁的进行大的调整以适应流经网络的不同分布的数据,给模型训练带来非常大的不稳定性,使得模型难以收敛。
如果我们对每一个 mini batch 的数据进行标准化之后,数据分布就变得稳定,参数的梯度变化也变得稳定,有助于加快模型的收敛。
4.1 批量归一化公式
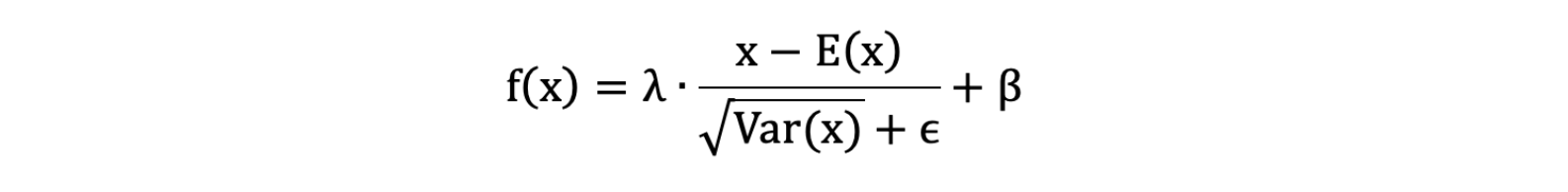
- λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏置;
eps:通常指为1e-5,避免分母为 0;E(x):表示变量的均值;Var(x): 表示变量的方差;
数据在经过 BN 层之后,无论数据以前的分布是什么,都会被归一化成均值为 β,标准差为 γ 的分布。
注意:BN 层不会改变输入数据的维度,只改变输入数据的的分布。 在实际使用过程中,BN 常常和卷积神经网络结合使用,卷积层的输出结果后接 BN 层。
4.2 BN 层的接口
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
- 由于每次使用的
mini batch的数据集,所以 BN 使用移动加权平均来近似计算均值和方差,而momentum参数则调节移动加权平均值的计算; affine = False: 表示 γ=1,β=0,反之,则表示 γ 和 β 要进行学习;BatchNorm2d:适用于输入的数据为 4D,输入数据的形状[N,C,H,W]
其中:N 表示批次,C 代表通道数,H 代表高度,W 代表宽度
由于每次输入到网络中的是小批量的样本,我们使用指数加权平均来近似表示整体的样本的均值和方法,其更新公式如下:
running_mean = momentum * running_mean + (1.0 – momentum) * batch_mean
running_var = momentum * running_var + (1.0 – momentum) * batch_var
上面的式子中,batch_mean 和 batch_var 表示当前批次的均值和方差。而 running_mean 和 running_var 是近似的整体的均值和方差的表示。当我们进行评估时,可以使用该均值和方差对输入数据进行归一化。
第五章、案例-价格分类
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。
我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
全连接网络:当前第
n层的神经元全部与n-1层的神经元连接;
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。
5.1 构建数据集
数据共有 2000 条, 其中 1600 条数据作为训练集, 400 条数据用作测试集。 我们使用 sklearn 的数据集划分工作来完成。并使用 PyTorch 的 TensorDataset 来将数据集构建为 Dataset 对象,方便构造数据集加载对象。
# 构建数据集
def create_dataset():data = pd.read_csv('data/手机价格预测.csv')# 特征值x和目标值y,iloc()根据索引取值x, y = data.iloc[:, :-1], data.iloc[:, -1]x = x.astype(np.float32)y = y.astype(np.int64)# 数据集划分x_train, x_valid, y_train, y_valid = \train_test_split(x, y, train_size=0.8, random_state=88, stratify=y)# 构建数据集(必须是tensor类型)train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.tensor(y_train.values))valid_dataset = TensorDataset(torch.from_numpy(x_valid.values), torch.tensor(y_valid.values))# x_train.shape[0]代表函数,x_train.shape[0]代表列数return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))train_dataset, valid_dataset, input_dim, class_num = create_dataset()
train_test_split 是 scikit-learn 库中用于将数据集分割为训练集和测试集的函数。下面我将详细解释你提到的每个参数的含义:
x: 这是输入特征的数组或矩阵。通常,x 包含你想要用于训练模型的所有特征数据。y: 这是目标变量的数组。y 包含与 x 中的每个样本相对应的标签或目标值。train_size: 这个参数指定训练集的比例。在这个例子中,train_size=0.8意味着 80% 的数据将被用作训练集,剩下的 20% 将用作测试集。random_state: 这个参数用于设置随机数生成器的种子,确保每次运行代码时分割的结果都是一致的。在这个例子中,random_state=88 意味着使用种子 88 来初始化随机数生成器。stratify: 这个参数用于分层抽样。在这个例子中,stratify=y 意味着训练集和测试集中的目标变量 y 的类别分布将与原始数据集中的类别分布保持一致。这对于确保训练集和测试集具有相似的类别比例非常有用,特别是在处理不平衡数据集时。
5.2 构建分类网络模型
我们构建的用于手机价格分类的模型叫做全连接神经网络。它主要由三个线性层来构建,在每个线性层后,我们使用的时 sigmoid 激活函数。
# 构建网络模型
class PhonePriceModel(nn.Module):def __init__(self, input_dim, output_dim):super(PhonePriceModel, self).__init__()# nn.Linear(n1, n2)构建全连接层,n1为输入的神经元个数,n2为输出的神经元个数# self.linear1()为第1层网络self.linear1 = nn.Linear(input_dim, 128)# self.linear2()为第2层网络,其输入的神经元个数必须等于第一层输出的神经元个数self.linear2 = nn.Linear(128, 256)self.linear3 = nn.Linear(256, output_dim)# 定义激活函数,使用sigmoid函数def _activation(self, x):return torch.sigmoid(x)# 前向传播的逻辑必须自己写def forward(self, x):# 将第1层的输出经过激活函数x = self._activation(self.linear1(x))# 将第2层的输出经过激活函数x = self._activation(self.linear2(x))# 第3层的输出层直接输出output = self.linear3(x)return output
我们的网络共有 3 个全连接层, 具体信息如下:
- 第一层: 输入为维度为 20, 输出维度为: 128
- 第二层: 输入为维度为 128, 输出维度为: 256
- 第三层: 输入为维度为 256, 输出维度为: 4
注意:由于手机价格为
0、 1、 2、 3共计4类,故需要最后的网络输出为4个神经元;
5.3 编写训练函数
网络编写完成之后,我们需要编写训练函数。
所谓的训练函数,指的是输入数据读取、送入网络、计算损失、更新参数的流程,该流程较为固定。我们使用的是多分类交叉生损失函数、使用 SGD 优化方法。最终,将训练好的模型持久化到磁盘中。
def train():# 固定随机数种子torch.manual_seed(0)# 初始化模型model = PhonePriceModel(input_dim, class_num)# 损失函数(交叉熵损失函数)criterion = nn.CrossEntropyLoss()# 优化方法(SGD随机梯度下降)optimizer = optim.SGD(model.parameters(), lr=1e-3)# 训练轮数num_epoch = 50# 双层经典循环:外层epoch轮次循环,内层dataloader循环for epoch_idx in range(num_epoch):# 初始化数据加载器,shuffle=True:将数据集打散,不按照之前的数据顺序# batch_size=8:每次将8个样本输入到模型dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)# 训练时间start = time.time()# 计算损失total_loss = 0.0total_num = 1# 准确率correct = 0# 遍历数据集for x, y in dataloader:output = model(x)# 计算损失loss = criterion(output, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()total_num += len(y)total_loss += loss.item() * len(y)print('epoch: %4s loss: %.2f, time: %.2fs' %(epoch_idx + 1, total_loss / total_num, time.time() - start))# 模型保存torch.save(model.state_dict(), 'model/phone-price-model.bin')
模型训练就固定3个大步骤:
- 实例化模型
module = nn.Module()类对象- 选定损失函数
nn.CrossEntropyLoss()- 选定优化器
nn.optim.SGD() 、nn.optim.Adam()经典的双层循环:
- 外层循环指定训练次数
- 内层循环中老三样:1)梯度清零
optimizer.zero_grad();2)反向传播loss.backward();3)参数更新optimizer.step()
5.4 编写评估函数
评估函数、也叫预测函数、推理函数,主要使用训练好的模型,对未知的样本的进行预测的过程。我们这里使用前面单独划分出来的测试集来进行评估。
def test():# 加载模型model = PhonePriceModel(input_dim, class_num)model.load_state_dict(torch.load('model/phone-price-model.bin'))# 构建加载器,验证集中的数据一般不需要打散,故shuffle=Falsedataloader = DataLoader(valid_dataset, batch_size=8, shuffle=False)# 评估测试集correct = 0for x, y in dataloader:output = model(x)# 得到的output为4分类的概率:[0.12, 0.25, 0.56, 0.12, 0.07],需要找出其中最大的y_pred = torch.argmax(output, dim=1)# 如果预预测值等于真实值,那么就累加1次correct += (y_pred == y).sum()print('Acc: %.5f' % (correct.item() / len(valid_dataset)))
程序输出结果:
Acc: 0.54750
5.5 网络性能调优
我们前面的网络模型在测试集的准确率为: 0.54750, 我们可以通过以下方面进行调优:
- 对输入数据进行标准化
- 调整优化方法
- 调整学习率
- 增加批量归一化层
- 增加网络层数、神经元个数
- 增加训练轮数
- 等等…
我进行下如下调整:
- 优化方法由
SGD调整为Adam - 学习率由
1e-3调整为1e-4 - 对数据数据进行标准化
- 增加网络深度, 即: 增加网络参数量
网络模型在测试集的准确率由 0.5475 上升到 0.9625,调整后的完整代码为:
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.optim as optim
import numpy as np
import time
from sklearn.preprocessing import StandardScaler# 构建数据集
def create_dataset():data = pd.read_csv('data/手机价格预测.csv')# 特征值和目标值x, y = data.iloc[:, :-1], data.iloc[:, -1]x = x.astype(np.float32)y = y.astype(np.int64)# 数据集划分x_train, x_valid, y_train, y_valid = \train_test_split(x, y, train_size=0.8, random_state=88, stratify=y)# 数据标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_valid = transfer.transform(x_valid)# 构建数据集train_dataset = TensorDataset(torch.from_numpy(x_train), torch.tensor(y_train.values))valid_dataset = TensorDataset(torch.from_numpy(x_valid), torch.tensor(y_valid.values))return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))train_dataset, valid_dataset, input_dim, class_num = create_dataset()# 构建网络模型
class PhonePriceModel(nn.Module):def __init__(self, input_dim, output_dim):super(PhonePriceModel, self).__init__()self.linear1 = nn.Linear(input_dim, 128)self.linear2 = nn.Linear(128, 256)self.linear3 = nn.Linear(256, 512)self.linear4 = nn.Linear(512, 128)self.linear5 = nn.Linear(128, output_dim)def _activation(self, x):return torch.sigmoid(x)def forward(self, x):x = self._activation(self.linear1(x))x = self._activation(self.linear2(x))x = self._activation(self.linear3(x))x = self._activation(self.linear4(x))output = self.linear5(x)return output# 编写训练函数
def train():# 固定随机数种子torch.manual_seed(0)# 初始化模型model = PhonePriceModel(input_dim, class_num)# 将模型加载到GPU上提升训练速度,两种方法都可以# model = module.cuda()# module = module.to('cuda')# 损失函数criterion = nn.CrossEntropyLoss()# 优化方法optimizer = optim.Adam(model.parameters(), lr=1e-4)# 训练轮数num_epoch = 50for epoch_idx in range(num_epoch):# 初始化数据加载器dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)# 训练时间start = time.time()# 计算损失total_loss = 0.0total_num = 1# 准确率correct = 0for x, y in dataloader:# x = x.to() # 如有GPU,可以将数据加载到GPU# y = y.to() # 如有GPU,可以将数据加载到GPUoutput = model(x)# 计算损失loss = criterion(output, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()total_num += len(y)total_loss += loss.item() * len(y)print('epoch: %4s loss: %.2f, time: %.2fs' %(epoch_idx + 1, total_loss / total_num, time.time() - start))# 模型保存torch.save(model.state_dict(), 'model/phone-price-model.bin')def test():# 加载模型model = PhonePriceModel(input_dim, class_num)model.load_state_dict(torch.load('model/phone-price-model.bin'))# 构建加载器dataloader = DataLoader(valid_dataset, batch_size=8, shuffle=False)# 评估测试集correct = 0for x, y in dataloader:output = model(x)y_pred = torch.argmax(output, dim=1)correct += (y_pred == y).sum()print('Acc: %.5f' % (correct.item() / len(valid_dataset)))if __name__ == '__main__':train()test()
如果需要GPU加速训练过程,需要将模型、数据都加载到GPU上。