布隆过滤器BloomFilter
一、使用场景
缓存穿透问题,除了可以在Redis中添加默认值并设置过期时间的方式之外,其实还有另外一种方式,就是使用布隆过滤器。
布隆过滤器有一个非常好的特征,就是能快速,可靠的帮助我们判断,某个值是否不存在于某个集合中。我们可以充分利用这一特征:
将所有在后台管理系统中添加的SKU商品的id放入到一个集合中(我们称之为所有SKU商品的skuId集合)
当处理获取SKU商品信息的请求时,我们可以取出请求中的skuId,然后利用布隆过滤器判断该skuId是否不在所有SKU商品的skuId集合,如果不在则直接返回
所以,当请求实际获取数据库中不存在的数据时,我们还是不会访问数据库,而是通过布隆过滤器拦截这样该请求
二、 布隆过滤器及其构建过程
那么什么是布隆过滤器呢?布隆过滤器由一个长度为n的二进制数组,和k个hash函数组成。
要构造布隆过滤器,首先得有一个长度为n的二进制数组,每个存储单元的初值为0.
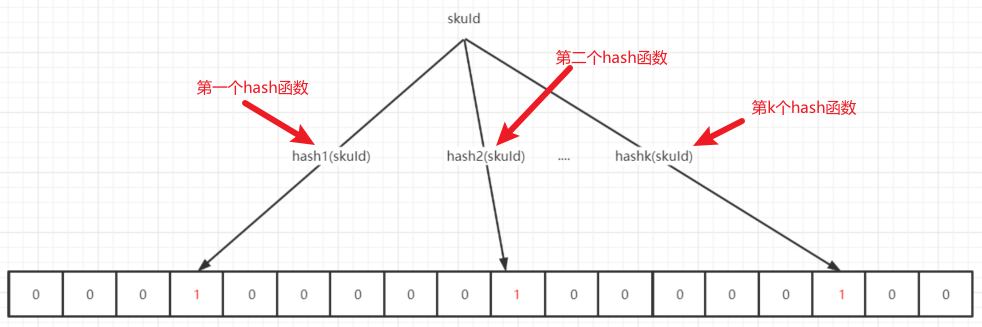
紧接着,我们需要在二进制数组中,标识目标集合中的每一个元素(向布隆过滤器中添加元素),这个过程就需要借助k个hash函数来完成了。对第m个hash函数
它会对标集合中的每个元素x做hash运算,将其映射到二进制数组中的位置i,并将第i个位置的元素值变为1
这个1表示第m个hash函数,在数组中的第i个位置,标记目标元素x存在于目标集合
一旦k个hash函数,将目标数据集合中的所有元素映射完毕,那么布隆过滤器就构建好了。
那么布隆过滤器是如何判断元素是否存在于集合中的呢?看起来很简单,就是对待判断的元素继续根据k个hash函数做hash映射,如果k个hash函数所映射到的数组元素值是否都为1。
看似很简单,但其实不然:
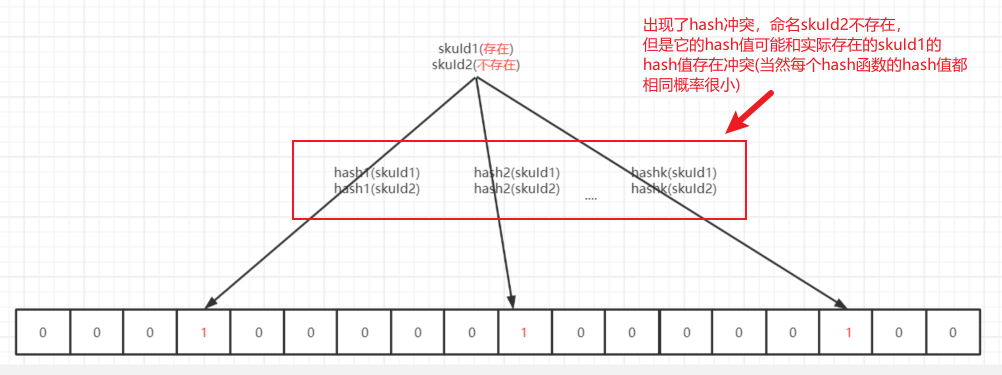
及时对于一个待判断的元素,即使k个hash函数映射到的数组元素的值都是1,也不能说明这个元素在目标集合中是存在的。原因很简单,hash函数还存在hash冲突。
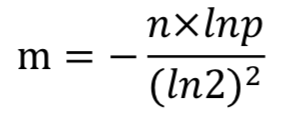
但是反过来,对于一个待判断元素,如果至少有一个hash函数映射到的数组元素为0即映射结果为不存在,那么就一定能说明,该元素在目标集合中不存在。
所以关于关于布隆顾虑器,我们还有以下结论:
使用布隆过滤器判断元素是否存在,是有误判率的。误判率p,二进制位数组长度m,hash函数个数k, 数据规模n(元素数量) 是有关系的,可以通过公式计算,已知数据规模,误判率,可以计算二进制数组长度, 以及hash函数的个数。
对于有n个元素的集合,保证误判率<=p的情况下,二进制数组长度的可以由如下公式求得
在已知二进制数组长度m和数据元素规模n的情况下,可以求得hash函数的个数k为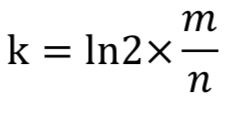
布隆过滤器中的元素是不能被删除的。所谓删除就是指,把二进制数组中该元素经过k个hash函数映射的元素值设置为0。这显然是不合理的,还是因为hash冲突的问题,有可能多个元素经过hash函数映射到同一个位置。如果在二进制数组中,将这个元素的值设置为0,把其他有hash冲突的元素也删除了。
但是布隆过滤器也有自己的优点:
由于布隆过滤器只需要一个二进制数组,占用的空间是比较小的
布隆过滤器的查询和插入的效率是很高的
数据安全性高,因为不存储任何目标集合中的原始数据
三、使用布隆过滤器
如果我们想要判断,一个skuId是否存在于数据库,我们只需要在构造布隆过滤器时,将目标集合变为数据库中所有的SKU商品的id集合即可。
Redisson本身对实现了基于Redis的布隆过滤器,可以非常方便的使用
// 根据指定名称(key)获取布隆过滤器RBloomFilter rbloomFilter = redissonClient.getBloomFilter("xxx");// 初始化布隆过滤器,预计统计元素数量为100000,期望误判率为0.01rbloomFilter.tryInit(100000, 0.01);// 向布隆过滤器中添加目标元素rbloomFilter.add(目标元素);
// 判断目标元素是否存在,返回false表示不存在boolen exists = rbloomFilter.contains(目标元素);在我们的商品服务中,我们需要在服务启动的时候就执行对于布隆过滤器的初始化(即仅仅需要执行一个操作),所以我们可以将布隆过滤器的初始化,可以使用CommandLineRunner接口
public interface CommandLineRunner {
/**该方法会被SpringBoot在初始化完Spring容器之后自动调用* Callback used to run the bean.* @param args incoming main method arguments* @throws Exception on error*/void run(String... args) throws Exception;
}所以我们可以这样使用
/*这个BloomFilterRunner因为加了Component注解,所以会被放到Spring容器中,Spring容器初始化完毕后,该对象的run方法会被自动调用
*/
@Component
public class BloomFilterRunner implements CommandLineRunner {@AutowiredRedissonClient redissonClient;@Overridepublic void run(String... args) throws Exception {RBloomFilter<Long> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);// 初始化布隆过滤器,预计统计元素数量为100000,期望误差率为0.01rbloomFilter.tryInit(100000, 0.01);}
}然后我们在上架SKU商品的时候,向布隆过滤器中添加元素
@Overridepublic void onSale(Long skuId) {/* ...*///向添加布隆过滤器添加元素RBloomFilter<Long> rbloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);rbloomFilter.add(skuId);
}在处理获取详情页商品信息的请求时,首先判断布隆过滤器中是否存在该元素,如果不存在,则直接返回默认值
@Overridepublic ProductDetailDTO getItemBySkuId(Long skuId) {
ProductDetailDTO productDetailDTO = new ProductDetailDTO();RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);if (!bloomFilter.contains(skuId)) {// 如果不存在,则返回默认值return productDetailDTO;}
/*....*/return productDetailDTO;}