VLLM离线推理本地Qwen3_32B大模型
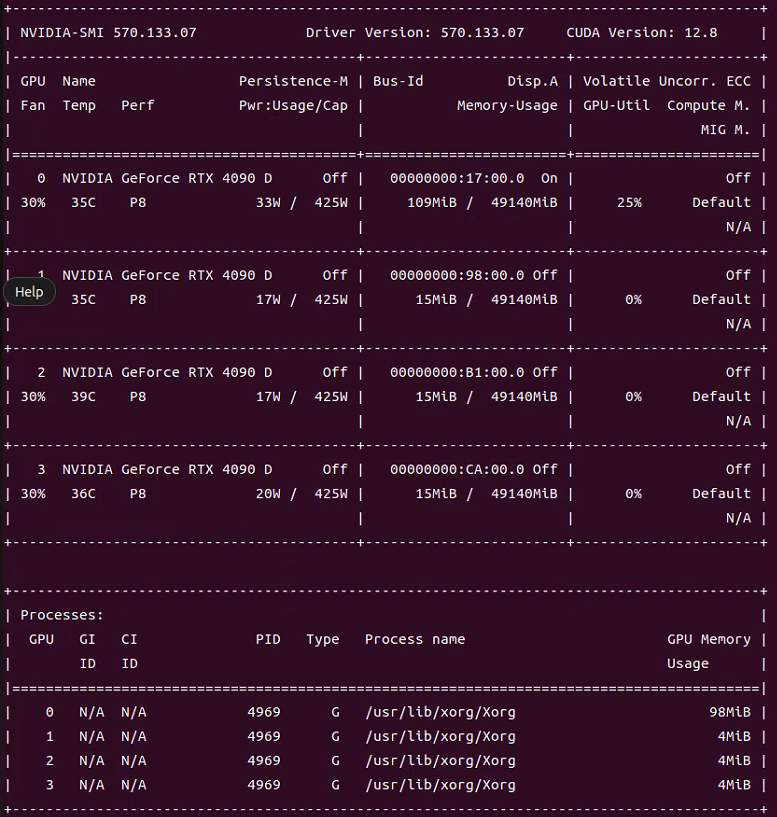
在命令行使用代码查看显卡类型:nvidia-smi
1.安装必要的包:vllm,openai
2.下载 Qwen3_32B 模型到本地路径:
从 modelscope 下载模型: modelscope 中 Qwen3_32B 模型下载地址
modelscope download --model Qwen/Qwen3-32B --local_dir your/local/dir_path3.在命令行中使用vllm serve 推理模型:
注:因为Qwen3_32B 模型在一张4090显卡上跑不起来,故此设置使用了4张4090显卡推理。
vllm serve /home/ubuntu/Desktop/data_zy_0726/model/Qwen/Qwen3-32B \
--tensor-parallel-size 4 \ # 使用4张显卡进行推理
--dtype auto \
--gpu-memory-utilization 0.9 # 设置现存使用率 90%,保留10%防止崩溃参数解释: vllm 参数详解
此时该 Qwen3_32B 模型已经在本地运行起来了,可使用命令:
curl http://localhost:8000/v1/models8000:为默认端口;
进行验证,输出为:

其中:
"id":"/home/ubuntu/Desktop/data_zy_0726/model/Qwen/Qwen3-32B"表示模型名称,在调用 api 时需要使用。
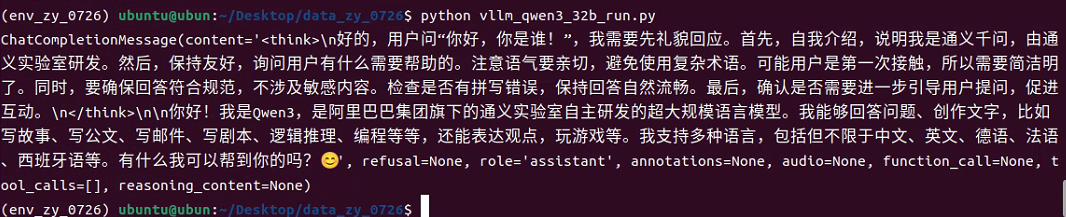
4.使用 openai 框架进行推理:vllm_qwen3_32b_run.py
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", # api 地址api_key="empty" # 如果api_key在使用 vllm serve推理时未设置,则在这里随便填一个即可,用于占位
)completion = client.chat.completions.create(model="/home/ubuntu/Desktop/data_zy_0726/model/Qwen/Qwen3-32B", # 模型名称,及前面所说idmessages=[{"role": "user", "content": "你好,你是谁!"}]
)print(completion.choices[0].message)循环提问:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1",api_key="empty"
)while True:problem = input("请输入你的问题:\n")completion = client.chat.completions.create(model="/home/ubuntu/Desktop/data_zy_0726/model/Qwen/Qwen3-32B", # 模型名称而非本地路径messages=[{"role": "user", "content": problem}])print(completion.choices[0].message)运行代码:
python vllm_qwen3_32b_run.py输出结果: