Linux的应用层协议——http和https
http
简要概念
域名
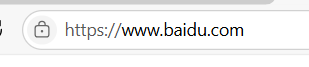
域名,也就是服务器地址,会被解析成IP地址,从下图我们可以看到访问百度的网站和访问百度的IP的效果是一样的
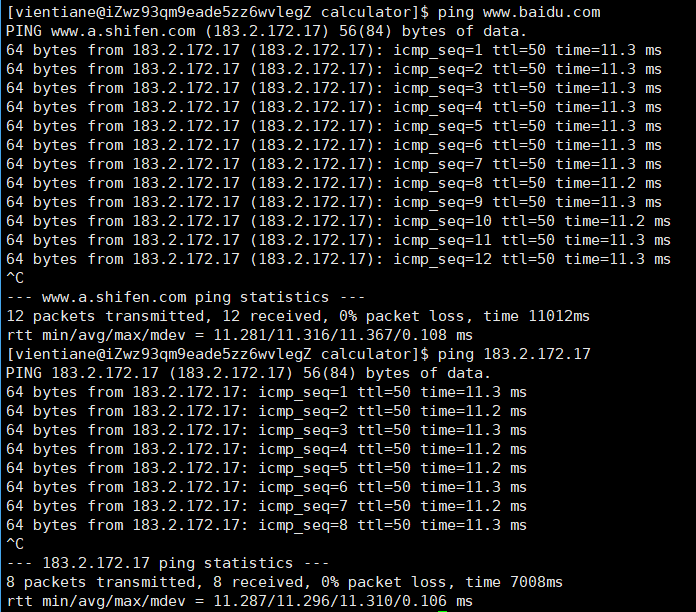
我们在访问这个网页的时候并没有添加端口号,http绑定的端口一般都是80,https绑定的端口一般都是443,在我们搜索后会自动帮我们添加默认端口号,而不需要我们手动去添加端口号
URL
URL(Union Resource Located)统一资源定位符,所有网络上的资源,可以通过唯一的字符串标识和获取

1.协议(Protocol):指定访问资源所使用的协议类型,例如HTTP、HTTPS、FTP等。协议决定了客户端和服务器之间通信的方式,http绑定的端口一般都是80,https绑定的端口一般都是443
2.服务器地址(Hostname):提供服务的服务器的名称,可以是域名或IP地址。例如:www.baidu.com或183.232.231.173。
3.端口号(Port):指定服务器上的特定服务,默认为80(HTTP)或443(HTTPS)。端口号的范围从0到65535。
4.路径(Path):资源在服务器上的位置,以斜杠(/)开头。例如:/img/bdlogo.gif,第一个/一般代表web的根目录,但也可以选择一些合适的相对路径作为根目录
5.查询参数(Query Parameters):对资源进行进一步描述或限制的参数,以问号(?)开头,多个参数之间用&分隔。例如:?name=bob&id=123。
6.片段(Fragment):文档内部某个位置的标识符,以井号(#)开头。例如:#main。
这里会有一个问题,一个URL里包含类似于:/?等特殊字符才能进行搜索,那么如果我刚好需要搜索这些特殊字符的话,web会如何处理。

可以看到aaaaa和bbbbb中间的字段被编码,当数据本身包含和URL中冲突的特殊字符,就需要要求BS双方进行编码和解码,转义的规则:将需要转码的字符转化为16进制,接着从右往左取四位(不足四位按四位处理),每两位当做一位,前面加上%,编码成%XY的格式
http协议格式
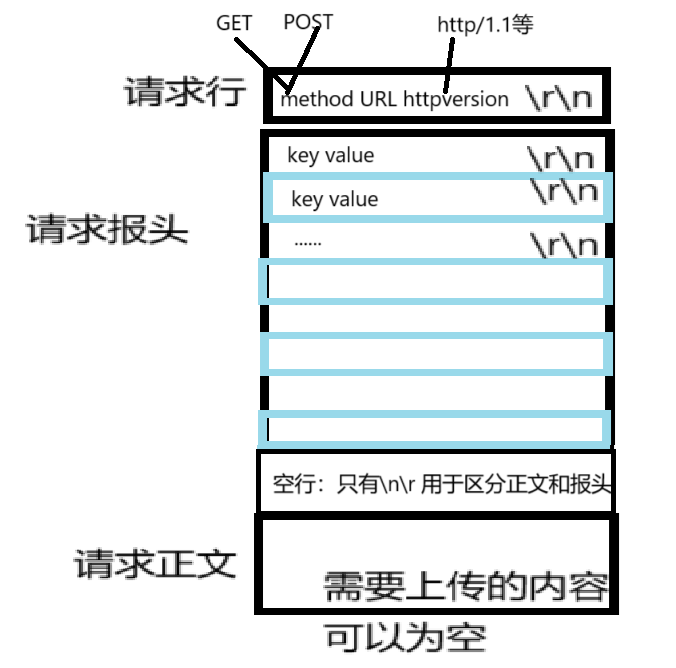
http请求
#pragma once
#include <string>
using namespace std;
#include "TCP.hpp"
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <cstring>
#include "log.hpp"class httpserver;class httpdate
{
public:
public:int socket;httpserver *s;
};class httpserver
{
public:httpserver(string ip, uint16_t port): _ip(ip), _port(port){_listensocket.CreateSocket();_listensocket.BindSocket(_port, _ip);_listensocket.ListenSocket(5);}void run(){while (1){string clientip;uint16_t clientport;int socket = _listensocket.AcceptSocket(&clientip, &clientport);if (socket < 0){log(Warning, "accept fail,errno is %d,error is %s\n", errno, strerror(errno));continue;}log(Info, "accept success,socketfd is %d\n",socket);// 连接成功pthread_t tid;httpdate* clientdata=new httpdate;clientdata->socket = socket;pthread_create(&tid, nullptr, server, clientdata);}}static void Hander(httpdate *arg){char buffer[10240];ssize_t ret = recv(arg->socket, buffer, sizeof(buffer), 0);if (ret > 0){buffer[ret] = '\0';cout << buffer << endl;// 构建一个简单的HTTP响应const char *response ="HTTP/1.1 200 OK\r\n""Content-Type: text/html\r\n""\r\n""<html><body><h1>Hello, World!</h1></body></html>";send(arg->socket, response, strlen(response), 0);}close(arg->socket);}static void *server(void *args){pthread_detach(pthread_self());httpdate *arg = static_cast<httpdate *>(args);arg->s->Hander(arg);return nullptr;}public:string _ip;uint16_t _port;TCP _listensocket;
};
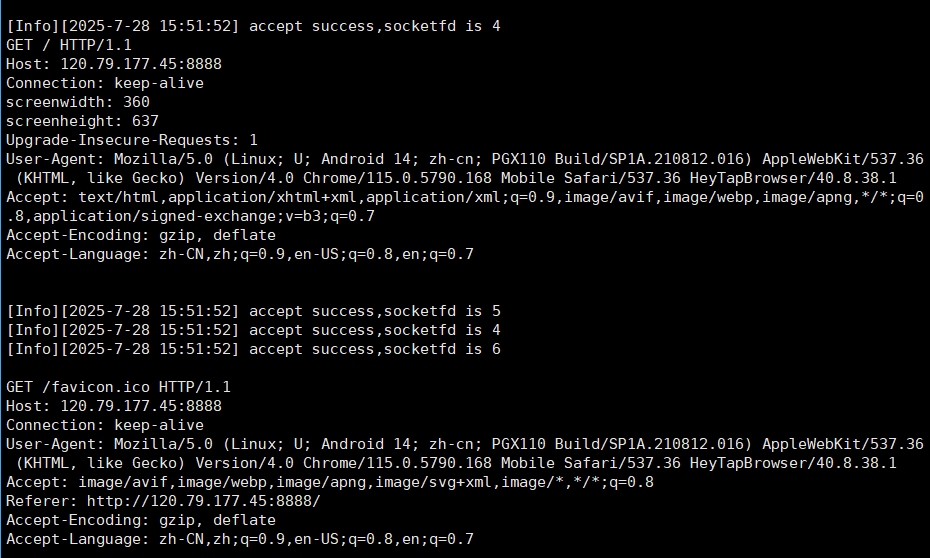
User-Agent代表访问的设备的基本信息
http响应
200表示网页正常,404之类的状态码表示找不到网页等问题
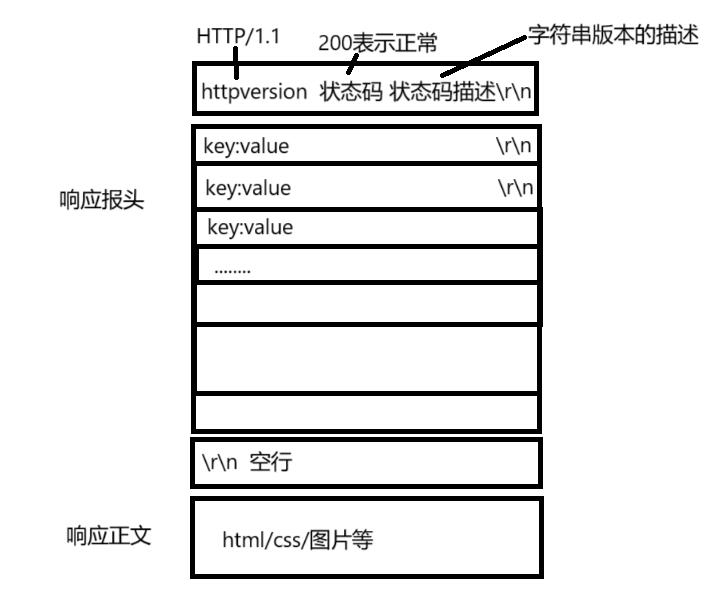
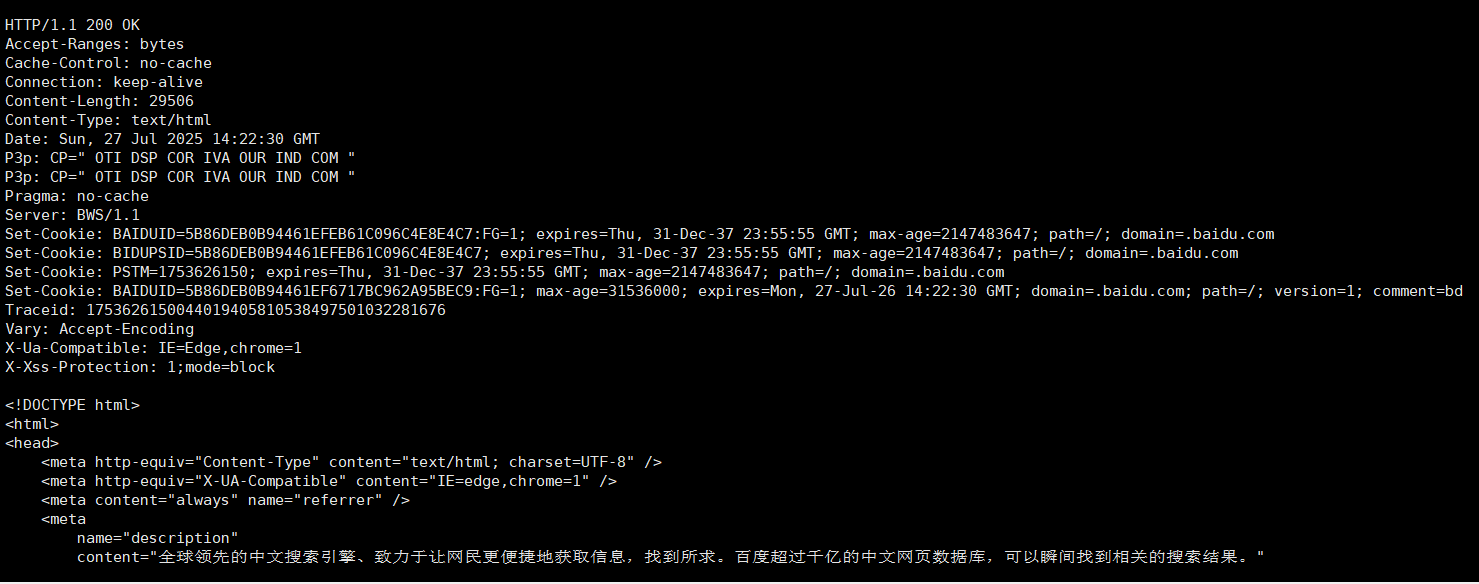
http内容
http方法
GET 用于从服务器获取资源。通常用于请求数据而不对数据进行修改,例如获取网页或图片。数据都是通过表单提交的,比如说我们在登录的时候,GET会把登录的用户名和密码都加到URL里,并且是明文传输,所以这并不安全
POST 向服务器发送数据以创建新资源。常用于提交表单或上传文件,数据包含在请求体中。和GET不同的是,POST会把用户名和密码加入到正文里,相同的是这一部分数据都是明文传输的
PUT 用于更新服务器上的资源。如果资源不存在,则创建新资源。PUT 通常是幂等的,即多次执行相同请求不会产生不同结果。
DELETE 用于删除服务器上的指定资源。
PATCH 对资源进行部分修改,而不是替换整个资源。
HEAD 类似于 GET,但只返回响应头部信息,不返回实际数据。常用于检查资源是否存在或获取元数据。
OPTIONS 用于查询服务器支持的请求方法,通常用于跨域资源共享(CORS)的预检请求。
TRACE 回显服务器收到的请求,主要用于诊断和调试。
CONNECT 建立到服务器的隧道,通常用于 HTTPS 连接。
状态码

重定向包括临时重定向和永久重定向,临时重定向表示资源暂时被移动到了一个新的URL,服务器返回的location字段里给浏览器发送回了目标地址,但仍有可能返回原始URL。搜索引擎会继续抓取和索引原始URL,因为它们认为这是临时的变动。而永久重定向表示资源已经永久地移动到了一个新的URL。与临时重定向不同,搜索引擎会更新它们的索引,将原始URL替换为新的URL
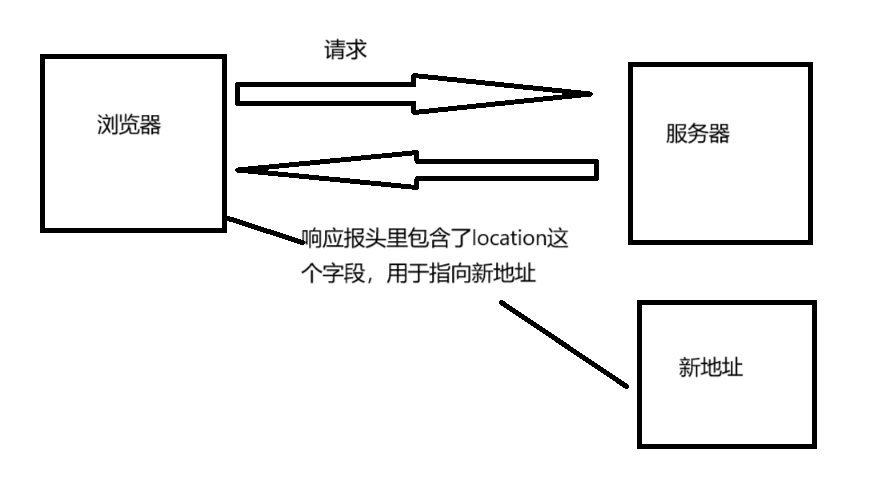
报头属性
请求报头和响应报头里很多属性是可以公用的

短连接表示请求一次后就断开连接,短连接表示在完成一轮请求的时候连接不会断开,所以这里有一个字段称为Connection,如果是长连接会显示keep-alive
Set-Cookie
http协议默认是无状态的,在我们访问第一个网页之后是有缓存的,但第二次访问的时候还是会向服务端请求,但我们现在访问的网页基本上都会记录我们的登录状态,浏览器是一个进程,如果是文件级的cookie文件,是存在磁盘的,关闭浏览器,第二次访问浏览器的时候依旧可以访问cookie文件,如果是内存级,浏览器关闭后就无法再次访问这个cookie文件
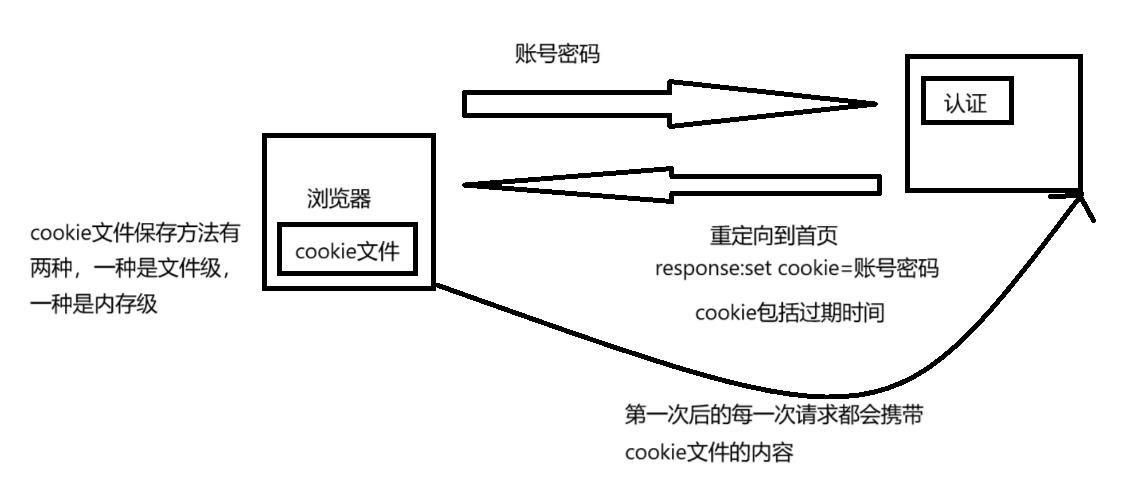
我这边使用的是类似于上图的png作为图片,在添加cookie字段后,我们会发现浏览器自动给我们保存了此cookie,这样就实现了一个会话保持的功能
static void Hander(httpdate *arg){char buffer[20480];ssize_t ret = recv(arg->socket, buffer, sizeof(buffer), 0);if (ret > 0){buffer[ret] = '\0';HttpRequest* request=new HttpRequest;string out=buffer;request->Deserialization(out);//cout<<"out#"<<out<<endl;//request->HttpDebug();//cout << buffer << endl;string text=ReadHtmlContent(request->URL);//不需要再重新编译,修改html文件的时候,服务器可以一直运行,但客户端重新访问的时候可以看到修改的内容//添加报头string responseline="HTTP/1.1 200 OK\r\n";string responseheader="Content-Length: ";//文件的大小responseheader+=to_string(text.size());responseheader+="\r\n";//文件的属性,否则浏览器就无法识别responseheader+="Content-Type: ";responseheader+=request->SuffixToDesc();responseheader+="\r\n";// cout<<"Content-Type:"<<request->SuffixToDesc()<<endl;responseheader+="Set-Cookie: name=vientiane&&passwd=123456\r\n";string responseblank="\r\n";string response=responseline;response+=responseheader;response+=responseblank;response+=text;// // 构建一个简单的HTTP响应cout<<"response#"<<response<<endl;send(arg->socket, response.c_str(), response.size(), 0);}close(arg->socket);}static void *server(void *args){pthread_detach(pthread_self());httpdate *arg = static_cast<httpdate *>(args);arg->s->Hander(arg);return nullptr;}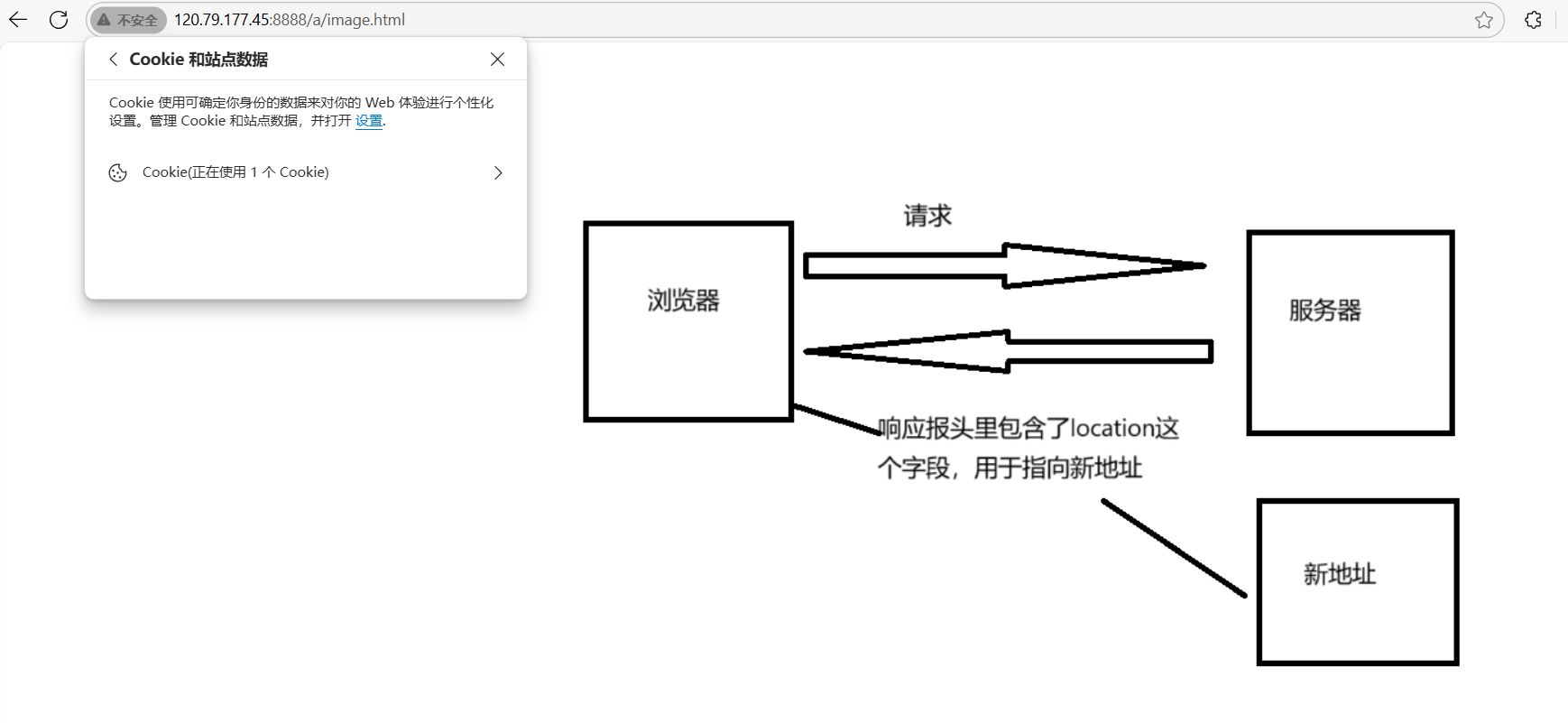
可以看到这里面的cookie文件有保存需要的数据,但这里有一个问题,客户端的防范能力几乎为0,cookie文件容易被盗取,所以就出现session+cookie的解决方案
session
在客户端登录的时候,把请求报文发给服务器认证的时候,服务器会在自己底层生成一个session文件,用于保存用户登录相关的内容,每一个session文件都会有一个sessionID,sessionID不会冲突,所以服务端会返回一个响应报文,调用用户的Set-Cookie,把用户的sessionID保存在Cookie里,session文件是由特定的数据结构管理起来的,这样cookie依旧可以被盗取,但用户信息就不会被泄漏了
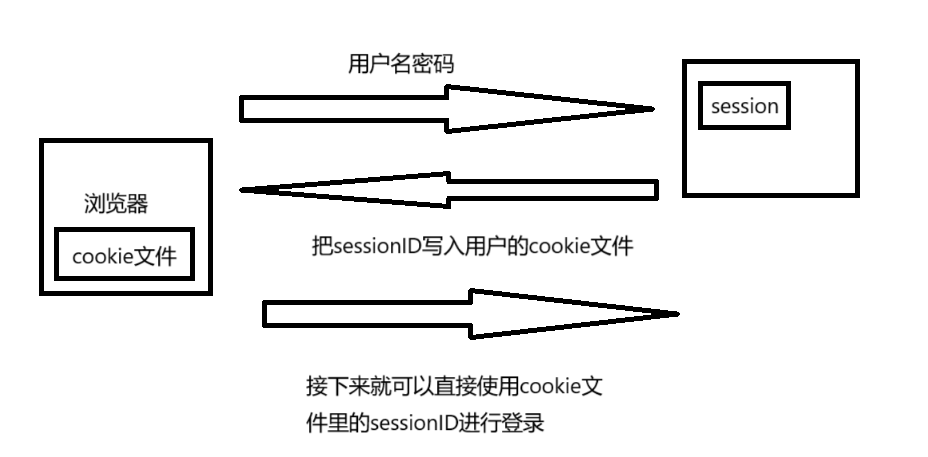
但我们可以看到cookie信息被盗取的问题依旧是没有解决的,但sessionID是被服务器分配的,当服务端甄别到登录有异常就会回收sessionID,这样即使盗取对应信息也没有办法访问
https
https也是一个应用层协议,只是在http上添加了一个加密层,加密就是把明文通过一系列变换,变为密文,解密就是把密文通过一系列变换,转化为明文,中间辅助变为密文的字段称为密钥
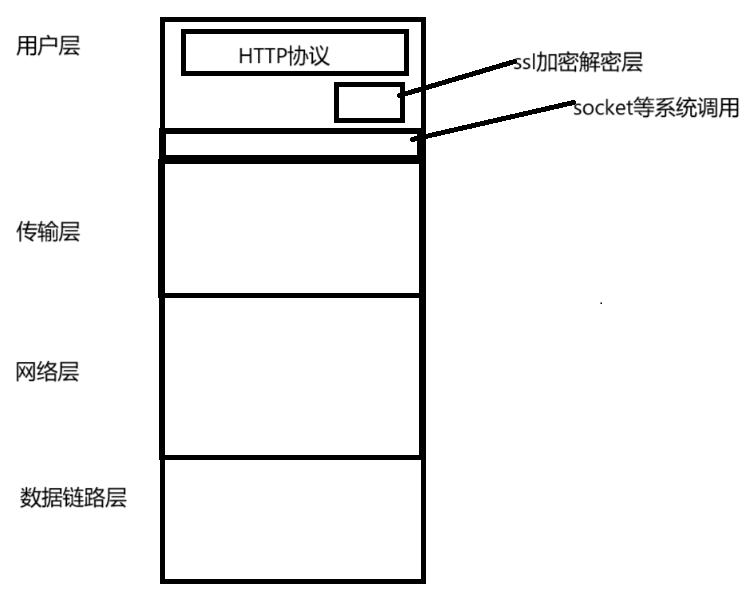
由于加密了,所以下面的网络层,数据链路层和传输层都不知道密文的内容,只有传输双方的应用层才知道数据是什么,http层加上一层加密解密层就是https协议
如果没有加密,http是明文传输的,中间会经过WiFi网点,运营商,路由器等,那么就可能会收到中间人攻击,比如说我们在下载一个软件的时候,点击下载,就给服务器发送了一个HTTP请求,但无论是什么请求都会经过运营商,运营商挟持之后,就把响应给修改了,把返回的地址改为qq浏览器等其他软件的下载地址
加密方式
对称加密
采用单钥密码系统的加密方法,同一个密钥可以用于数据的加密和解密,这种方法称为对称加密或者单密钥加密,像DES,3DES等。
假设明文A为1234,密钥key为5,可以按位与的把数据加密,然后发送到另外一个端口后,对方再按位与一次把数据解密,得到原来的明文,这种加密运行速度快,计算量小
非对称加密
需要两个密钥进行加密和解密,这两个密钥是公开密钥,和私有密钥,通过公钥把明文加密,变为密文,再通过私钥对密文解密,变为明文,也就是说如果我们使用私钥加密,拥有公钥的人都可以进行解密,如果我们使用公钥进行加密,那么只有拥有私钥的人可以进行解密,这一过程也可以反着用,像DSA等算法,但这种加密的运行速度非常慢,计算量大
数据摘要/数据指纹
这项技术的基本原理是使用单向哈希对数据进行运算,生成一串固定长度的数据摘要,这并不是一项加密技术,而是一项判断数据有没有被篡改的技术,有MD5,SHA1等算法,从数据摘要是很难反推原信息的,一般都用于进行数据对比,其实服务端的sessionID就可以依靠这种技术进行处理,只要有一点点的不同,生成的数据摘要就是天差地别的,也可以用于上传云端的功能,如果我们现在需要上传一份资源,而在此之前已经有人上传了,生成了对应的数据指纹,上传云端就不需要再次下载,而是在服务器上生成一个软链接文件,然后指向已经上传在云端的资源
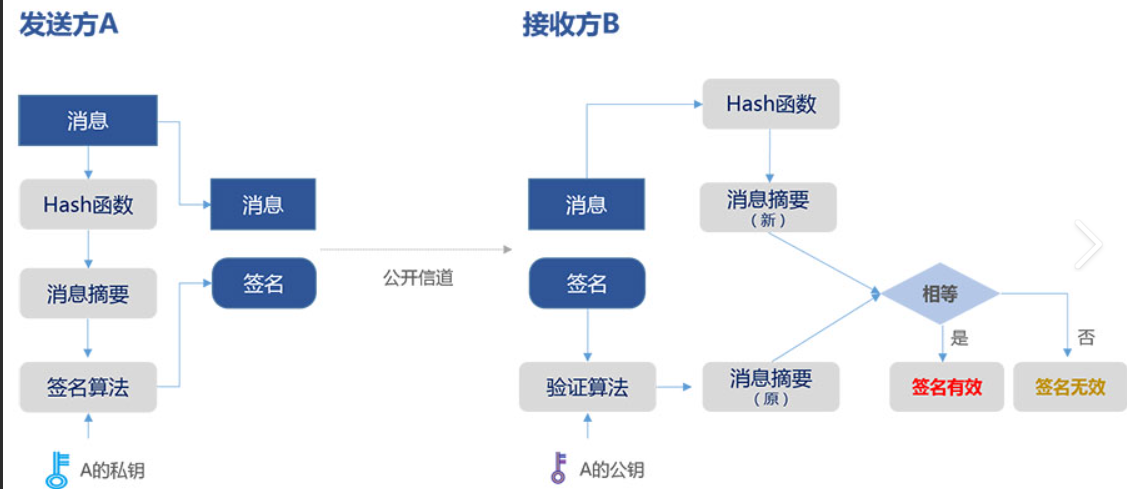
数字签名
数据摘要经过私钥加密后变成数字签名,用于验证原始文章是否被修改。
CA机构有自己的公钥和私钥,用户提交上来的数据通过公开的散列函数进行运算得到一组散列值,然后再通过CA机构的私钥进行加密,才形成签名,散列其实是为了不让中间人用公钥直接访问到明文,而且哈希后也可以提高运算效率
所以客户端收到了服务器发来的证书后,可以通过公钥验证证书
证书
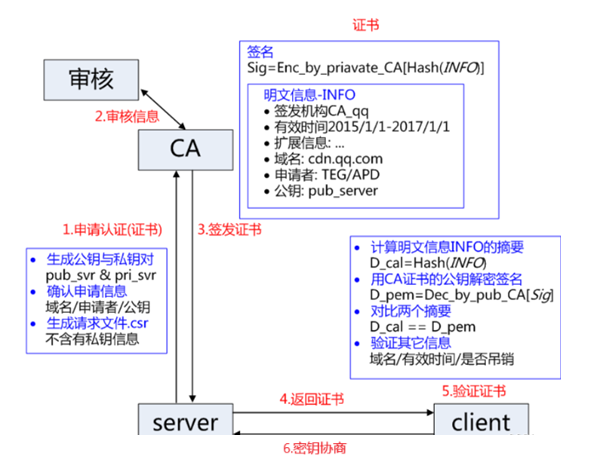
CA认证
服务端在使用https的时候,需要向CA机构认领一份数字证书,证书里有证书申请者信息,公钥信息等,然后服务器把证书传给浏览器,浏览器再从证书里提取签名和明文,通过哈希算法把明文映射为数据摘要,对签名用CA公钥解密获得另一个数据摘要,再对两个数据摘要进行对比就可以判断数据有没有被篡改
设计方案
方案1:如果只使用对称加密,那么密钥只能由一端产生,但如何安全的传到另一端是一个问题。
方案2:如果只使用非对称加密,服务器可以把公钥发送给客户端,只保留私钥,客户端那边加密的数据发送回服务端才能解密,中间商无法修改数据,但有一个问题,如果服务器想把数据发送回客户端,就只能用私钥加密,而客户和黑客是都可以获取公钥的,就都可以对响应数据进行解密。
方案3:如果客户端和服务端都使用非对称加密,但这样效率太低
方案4:如果使用非对称加密和对称加密混合使用,也就是说服务端采用非对称加密,客户端先请求服务器获得公钥,然后再在本地生成对称密钥,用公钥加密发送给服务端,接下来都获得密钥后,只使用对称密钥通信即可。
方案3和4看起来很安全,但这是建立在中间人只在后续通信过程中参与数据交互的情况下的。方案2,3,4最开始都是通过非对称加密把数据发送出去的,如果中间人在客户请求的时候就开始参与了,那么客户端请求的时候,中间人就把客户端的请求发给服务端,在服务端响应的时候,中间人可以把发往客户端的公钥保存下来,然后把自己生成的公钥发送给客户端,服务端在接下来发送数据的时候,就会使用中间人生成的公钥对数据进行加密,发送过程中依旧会经过中间人,中间人就可以对密文数据解密,再用服务器端的公钥进行加密,服务器就无法发现这一串数据有没有被篡改过,这就是中间人攻击(MITM攻击),这里的本质问题是客户端无法发现接收到的公钥是无效的,这就涉及到证书
方案5:使用对称加密,非对称加密和证书三者结合,在验证证书合法性的时候,客户端使用和CA一样的公开哈希算法把证书生成数据摘要,再用CA公钥把证书的数字签名解密了,对比两份数据是否一样,若不一样,则数据被修改过,若一样,则这一份证书可信,如果中间人想修改签名,也做不到,因为中间人没有CA的私钥,如果想修改明文,那么解密签名和明文加密后的信息就匹配不上,即使中间人申请了一个合法的CA证书,域名也匹配不上

总结
综上,https工作过程中涉及的密钥有三组,第一组是非对称加密,服务器持有私钥(在生成csr文件获得的),客户端持有公钥(客户端包含可信任的机构的公钥),用于保证服务器返回的证书的合法性。第二组也是非对称加密,客户端用收到CA证书的密钥给随机生成的密钥加密,服务器通过私钥来解密,获得对应的密钥。第三组是对称加密,服务器和客户端可以通过第二组获得的密钥来通信