AI产品经理手册(Ch1-2)AI Product Manager‘s Handbook学习笔记
AI Product Manager's Handbook是AI产品管理者的实战指南,旨在系统化解构人工智能产品的构建逻辑与成功要素。
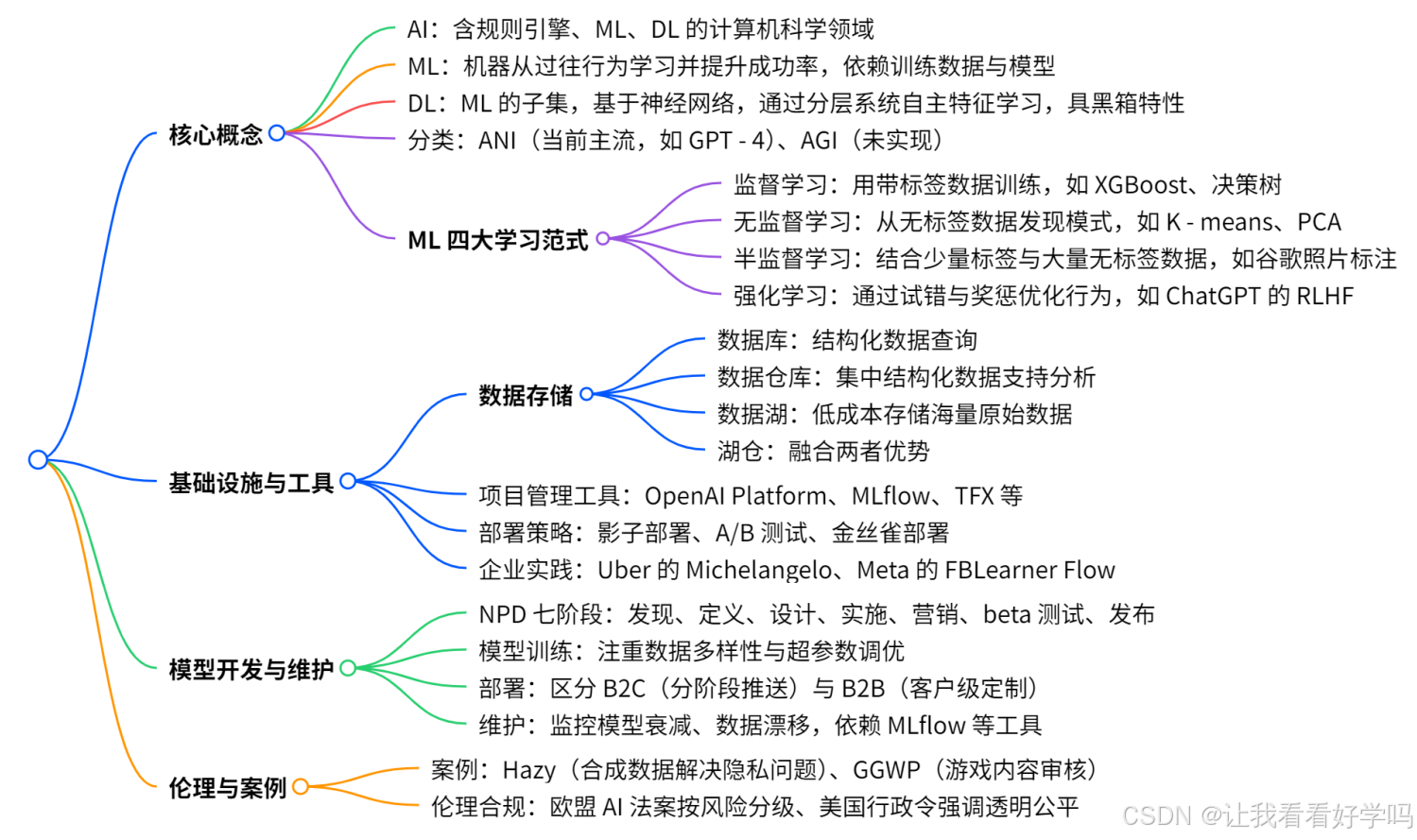
Part1 部分的 Ch1-2 系统梳理人工智能的核心概念、基础设施与工具、模型开发及维护等关键内容,构建 AI 产品管理的知识体系,从核心概念到落地实践形成完整闭环。为 AI 产品经理提供了从理论到实践的全面指导,助力其理解并成功构建、管理 AI 产品。
- 明确 AI、机器学习(ML)、深度学习(DL)的定义与边界,详解 ML 的四大学习范式(监督、无监督、半监督、强化学习)及其典型算法。
探讨 AI 产品构建的基础设施,包括数据存储(数据库、数据仓库、数据湖等)、项目管理工具与部署策略及优秀企业的实践案例。
深入阐述模型开发的全流程 —— 从新产品开发(NPD)的阶段划分,到模型类型选择、训练、部署、测试与持续维护。
通过深度剖析行业标杆案例(如Hazy的隐私安全合成数据、GGWP的游戏内容审核AI),揭示AI产品的核心设计原则:以痛点为锚点,贯穿从数据基建、模型开发到部署维护的全链路。同时强调 AI 伦理与合规的重要性。
目录
Ch1 理解构建AI产品的基础设施和工具
1.1 AI
1.2 ML vs DL
1.3 ML的学习范式
1.4 LLMs,NLP,GANs,生成式AI
1.5 成功AI案例
1.6 实现AI系统的最佳流程
1.7 数据存储与管理
1.8 项目管理 – IaaS
1.9 ML模型部署策略
Ch2 AI产品的模型开发与维护
2.1 新产品开发(NPD)的各个阶段
2.2 OKRs
2.3 训练
2.4 部署
2.5 测试和故障排除(troubleshooting)
2.6 模型更新的伦理挑战
Ch1 理解构建AI产品的基础设施和工具
1.1 AI
-
机器学习(ML)的定义:机器从过往行为中学习,通过学习提升成功率,核心是 “自主学习参数”,需通过反馈持续优化。
-
非 ML 的 AI 形式:依赖固定硬编码规则的 “基于规则引擎” 或 “专家系统”,属于 AI 但非 ML(无自主学习,仅复刻人类规则)。
-
AI 的分类:
- 人工窄智能(ANI / 弱 AI):当前主流,仅在特定领域生效(如 GPT - 4 擅长对话但不会开船)。
- 人工通用智能(AGI / 强 AI):理论中未来状态,可独立完成各类任务,无需人类监督。
1.2 ML vs DL
1 定义
- 机器学习(ML):模型(算法框架)+训练数据(历史数据)。
- 学习机制:通过历史数据建立模式,持续优化模型性能。
- 深度学习(DL):ML子集,但基于神经网络算法(如计算机视觉、自然语言处理模型)。
- 核心区别:①特征学习:自动提取数据中的特征。②模型深度:多层神经网络结构,擅长处理高维度、非结构化数据。
2. DL的实践挑战
- 可解释性问题:
- 技术视角:神经网络内部决策逻辑不透明,工程师难以追踪模型推理路径。
- 商业影响:客户可能因无法理解模型决策而拒绝使用“黑箱”产品(如金融、医疗等高风险场景)。
- 自主性:模型自动选择数据特征,减少工程师干预,但需接受其不可控性。
3. 产品经理的应对策略
- 沟通对齐:①对内:向工程师传递市场需求(如模型可解释性优先级)。②对外:向客户解释技术局限性,权衡性能与透明度。
- 场景适配:①选择ML:需求透明、数据规模有限、需快速迭代的场景。②选择DL:复杂模式识别(如语音、图像),数据量充足且可接受“黑箱”的场景。
1.3 ML的学习范式
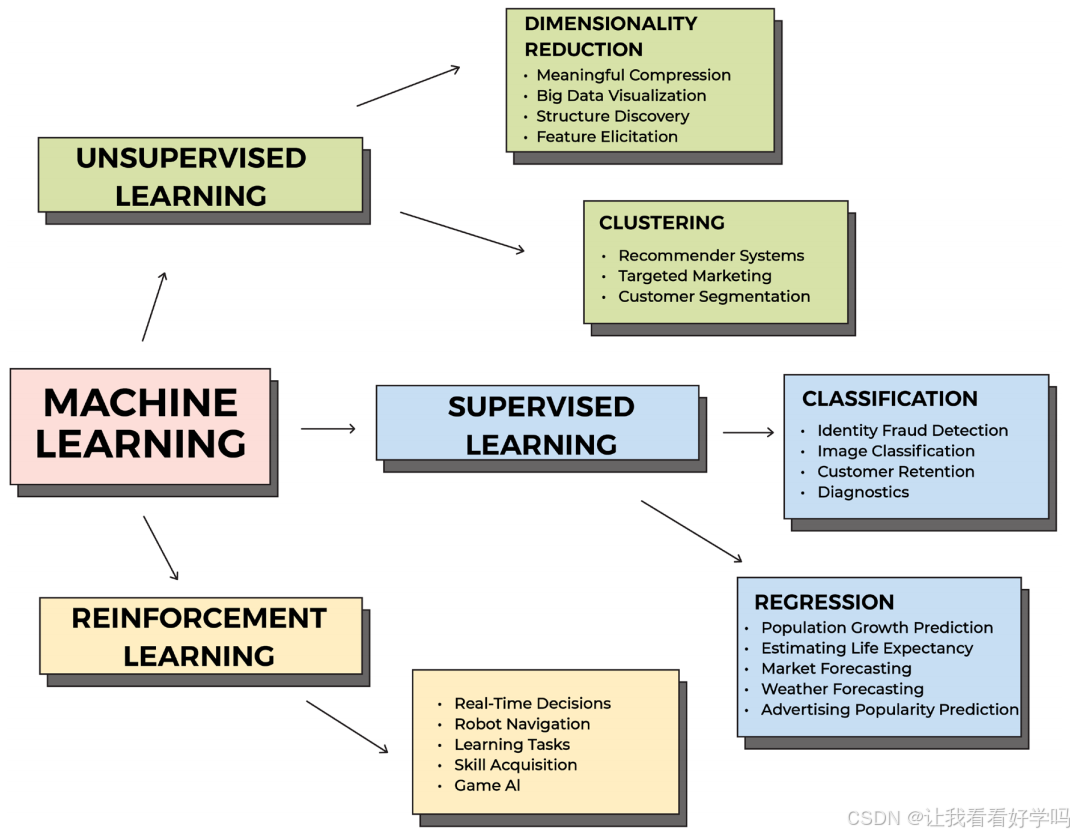
1. 监督学习(Supervised Learning)
- 定义:使用带标签的结构化数据训练模型,机器学习对当前/未来数据点进行正确标注(人类已知 “正确答案”,可通过对比调整模型,直至性能达标)。
- 特点:依赖人工标注数据,目标是让模型 “学会” 复现已知的标签规则,通过不断训练减少误差。
- 应用场景:①分类任务(如垃圾邮件识别、情感分析);②回归任务(如预测价格、销量、疾病风险)。
- 常见算法:
| 算法 | 适用任务 | 原理特点 | 典型应用场景 |
|---|---|---|---|
| XGBoost | 分类/回归 | 多模型组合纠正前序错误,最小化损失函数 | 客户流失预测、欺诈检测 |
| Naive Bayes 朴素贝叶斯 | 分类 | 假设特征独立,概率关联分析 | 垃圾邮件识别、情感判断 |
| SVM 支持向量机 | 分类 | 数据分割为两类,支持多维特征扩展 | 图像/文本分类 |
| Linear Regression 线性回归 | 回归 | 变量线性拟合预测数值 | 价格预测、销售预测 |
| Logistic Regression 逻辑回归 | 分类 | 预测二元分类状态(类似线性回归) | 疾病诊断、客户行为预测 |
| Decision Trees 决策树 | 分类/回归 | 树状节点决策,基于历史数据流预测 | 自动化贷款审批、客户分群 |
| Random Forest 随机森林 | 分类/回归 | 多决策树集成(随机采样+投票机制) | 特征选择、信用评估 |
| KNN K 近邻 | 分类/回归 | 根据邻近数据点的特征分组预测 | 图像识别、推荐系统 |
- 弱监督(Weak Supervision)是其变体 —— 模型从其他 AI 系统标注的数据中学习,适用于高质量标注数据稀缺 / 昂贵的场景。
2. 无监督学习(Unsupervised Learning)
- 定义:使用无标签的非结构化数据,模型自主标注数据并发现未知模式(人类 “不知道正确答案”,依赖机器自主探索)。
- 特点:结果需谨慎对待(可能发现无意义的模式),需大量数据训练(小样本易导致误差),无绝对 “正确答案”,只有 “正确性等级”。
- 应用场景:①聚类(将相似数据分组,如市场细分、新闻主题聚类);②降维(去除次要特征,保留关键信息,简化数据)。
- 常见算法:
- K-means 聚类(分组数据以发现模式,需预设最优聚类数);
- 主成分分析(PCA,降维工具,用于基因组测序、高维数据可视化)。
3. 半监督学习(Semi-supervised Learning)
- 定义:使用少量带标签数据 + 大量无标签数据训练,通过带标签数据 “引导” 模型探索无标签数据的模式(适用于标注数据不足的场景,如新产品缺乏历史数据)。
- 特点:过程类似监督学习,但会预测部分无标签数据,并与带标签数据对比精度以优化;因实施复杂、对数据质量敏感、工具较少,应用范围较窄。
- 应用场景:如谷歌照片中少量标注宠物图片后,模型自主标注更多图片;适用于转录音频等稀缺数据场景。
4. 强化学习(Reinforcement Learning)
- 定义:通过 “试错” 学习,基于奖励 / 惩罚机制优化行为,从与环境的交互中不断调整策略(目标是最大化 “奖励”)。
- 特点:在 “大状态空间” 中学习(环境复杂且动态),依赖反馈加速学习;无直接标签,而是通过行为结果的 “奖惩” 调整。
- 应用场景:机器人控制、自动驾驶、游戏 AI、ChatGPT 的 RLHF(基于人类反馈的强化学习)等。
总结
| 学习范式 | 数据类型 | 核心目标 | 典型应用 | 关键特点 |
|---|---|---|---|---|
| 监督学习 | 带标签数据(结构化) | 复现已知标签规则 | 垃圾过滤、房价预测 | 依赖人工标注,有明确 “正确答案” |
| 无监督学习 | 无标签数据(非结构化) | 发现未知模式 | 市场细分、降维 | 需大量数据,结果需谨慎验证 |
| 半监督学习 | 少量标签 + 大量无标签 | 利用有限标签引导模式探索 | 新场景数据标注(如新产品) | 适用于数据稀缺,实施复杂度高 |
| 强化学习 | 无标签,依赖环境反馈 | 通过奖惩优化行为策略 | 机器人、自动驾驶 | 试错学习,依赖动态环境反馈 |
相关DL资源
- Hugging Face Model Hub: https://huggingface.co/models
- TensorFlow Hub: https://tfhub.dev/
- PyTorch Hub: https://pytorch.org/hub/
- Google Colab: https://colab.research.google.com/
- Kaggle: https://www.kaggle.com/
- TorchVision Model Zoo: https://pytorch.org/vision/stable/models.html
1.4 LLMs,NLP,GANs,生成式AI
1. 生成式AI(Generative AI):通过DL模型生成新内容的AI分支。
三大模型范式:
- 1)潜在变量模型(Latent variable models):模型试图从给定的数据中解读隐藏因素(潜变量)。
- 关键技术:VAE(变分自编码器)、EBM(能量模型)
- 应用案例:Artbreeder、NSynth(Google Magenta)、AutoCAD的生成设计、DeepLog、Netflix的推荐系统。
- 2)对抗模型(Adversarial models):模型通过两个对抗模型的“竞争”来生成数据,一个模型生成数据,另一个模型评估生成的数据。
- 关键技术:GAN(生成对抗网络)
- 应用案例:DeepArt、Jukebox(OpenAI)、DALL-E、GameGAN(NVIDIA)、FaceApp、Prisma。
- 3)序列模型(Sequential models):模型擅长预测序列中的输出,能够根据之前的元素生成内容。
- 关键技术:Transformer、Diffusion
- 应用案例:GPT模型、Smart Compose(Google)、MuseNet(OpenAI)、Google Translate。
2. LLMs利用NLP能力,结合无监督学习、监督学习和强化学习的过程进行训练。
- 以ChatGPT为例,训练过程:
- 无监督预训练 → 海量文本学习语言规律
- 监督微调 → 人类标注优化输出质量
- 强化学习 → 奖励机制提升实用性
- NLP技术
- NLU(自然语言理解):解析用户意图与语义,用于实体识别、情感分析。
- NLG(自然语言生成):生成符合语境的人类语言响应,用于对话系统、文本摘要。
1.5 成功AI案例
主流ML管理平台及功能
| 平台名称 | 所属公司 | 核心功能 | 独特价值 |
|---|---|---|---|
| OpenAI Platform | OpenAI | 开发/部署/管理AI模型 • 训练基础设施、部署流水线、监控系统 | 支持GPT-4等尖端模型的创建与运维 |
| MLflow | Databricks | 开源全生命周期管理 • 实验跟踪(跨实验模型对比)、模型版本管理、部署可视化 | 兼容任意库/框架/语言 |
| TensorFlow Extended (TFX) | 基于TensorFlow的生产级ML流水线 • 跨团队协作、高性能扩展能力 | 端到端部署解决方案 | |
| Michelangelo | Uber | 统一ML操作平台 • 多技能团队协作、标准化可复现流水线、大规模数据预测与部署 | 解决语言/模型/团队孤岛问题,实现全流程标准化 |
| FBLearner Flow | Meta | AI项目集中管理 • 算法可重用性、训练流水线复用、自动化模型训练、实验历史检索 | 构建易用知识库,实现ML资源中心化 |
| SageMaker | Amazon | 全托管式ML服务 • 低代码/无代码界面、与AWS云服务深度集成 | 支持从工程师到业务分析师的多元用户,实现规模化AI运维 |
| Bighead | Airbnb | 集成化ML基础设施(含Zipline/Redspot/DeepThought) • 标准化中央管理、减少重复工作 | 统一ML组织协作,降低错误率 |
1.6 实现AI系统的最佳流程
步骤一:定义
- 明确问题与目标:确定要解决的具体问题及其业务目标。
- 对齐业务影响:将AI系统的目标与业务目标对齐(明确项目有收益),以确保获得组织的投资支持。
- 识别限制与要求:评估基础设施、数据可用性和计算能力的限制。
步骤二:数据可用性和集中化
- 建立数据存储:创建一个中央数据位置存储模型学习所需的数据。
- 数据管道(Data Pipeline)建设:根据数据库和遗留系统的需求,建立ETL(提取、转换、加载)管道,以便为生产化的模型提供数据。
- 数据收集:确定所需的数据类型和数量,从多个来源收集数据,建立集中、集成的数据集。
- 数据质量:确保数据传输系统高效,选择经济且可靠的存储解决方案,并进行数据清洗和处理。
- 数据集划分:将数据集划分为训练集、验证集、测试集,必要时通过生成数据点或外部数据源增强数据集。
步骤三:选择和训练模型
- 模型选择:根据问题性质(如分类/预测)、数据类型(结构化/非结构化)、计算资源限制、组织对透明度的要求等筛选合适的ML模型类别(如决策树、神经网络等),可参考业内已验证对类似问题有效的模型。
- 性能评估:通过实验(超参数调优、交叉验证等)测试不同模型变体及其配置组合,以确定模型的性能指标,评估模型的训练时间和资源消耗,从而确保最终选择满足需求的最优模型或模型组合。
- 资源准备:搭建训练环境,确保有足够的资源来训练模型。
- 模型训练:使用训练数据来训练模型,以理解数据中的模式和关系,并通过调整超参数来优化模型性能。
- 验证与版本管理:定期使用验证集评估模型泛化能力,并在训练和验证过程中记录模型迭代参数与性能变化,维护模型版本。
步骤四:反馈
- 评估模型表现:在测试集上评估模型性能。
- 分析错误:识别模型错误的类型和来源。
- 优化模型:通过超参数调优和特征工程等手段减少错误。
步骤五:部署
- 协作部署:数据工程师与ML工程师合作将模型部署到生产环境。
- 系统集成:通过API/Web服务将模型集成到现有系统/程序中。
- 监控设置:设置性能监控工具(日志系统),跟踪模型表现和系统健康状况。
- 安全措施:实施安全措施,确保模型及其使用的数据保持加密、安全,并仅供授权用户访问。
步骤六:持续维护
- 持续集成(CI):测试和验证代码、组件、数据和模型。
- 持续交付(CD):持续传递模型的代码更改,确保这些更改在进入生产环境之前能在测试环境中得到验证。
- 持续训练(CT):随着数据源更新,模型持续训练并学习新数据。
- 持续监控(CM):通过监控确保模型正常运行,及时发现问题。
1.7 数据存储与管理
ML产品的性能高度依赖数据存储方式。需根据数据类型(结构化/非结构化)和访问需求等选择存储方案。
1. 数据存储选项
- 1)数据库(Database):适合简单的数据存储和快速查询,基于固定关系结构存储结构化数据。
- 适用场景:初期阶段,单一业务线的结构化数据管理。仅需访问少量数据的趋势分析。
- 局限性:①数据孤岛,难以整合不同来源的数据。②不适合复杂的分析需求。
- 解决方案:为了有效查询和分析数据,尤其是使用历史数据进行预测,企业应考虑使用数据仓库。
- 2)数据仓库(Data Warehouse):用于集中存储大量结构化数据,适合整合不同来源的数据。
- 特点:①支持清洗和标准化不同来源的数据。②支持BI工具及各种AI应用。
- 适用场景:①需要较易实现数据分析的组织。②跨业务的数据分享。③使用历史数据进行预测。
- 局限性:成本较高(需预设计数据框架,实时访问成本高)。
- 3)数据湖(Data Lake):存储大量原始、非/半结构化数据,成本较低,适合海量数据长期保存。
- 适用场景:①需要数据/ML工程师灵活建模的场景。②数据使用需求不明确时,作为未来分析的“原始储备”。
- 数据湖仓(Lakehouse,如Databricks):结合数据湖的存储能力与仓库的分析能力,支持非技术用户访问和分析数据。
2. 数据处理流程:数据管道
- 目标:确保数据流动、处理和存储符合业务需求。
- 两类模式:①批处理(Batch Processing):定时处理大批量数据。②实时处理(Real-Time Processing):即时处理流式数据。
- ETL管道:Extract提取 → Transform转换 → Load加载。用于更复杂的数据整合和分析(跨系统数据清洗、标准化、统一存储)。
1.8 项目管理 – IaaS
- 技术债务和准备:大多非技术公司在AI采用方面准备不足,需要管理和整合遗留系统与新AI技术,建立AI生命周期架构,确保有足够的技术技能。
- AIOps:以AI/ML为核心的IT运维解决方案。
- MLOps:优化和管理ML的生命周期,确保模型有效集成到生产环境中。
- 选择合适的基础设施:采用基础设施即服务(IaaS)可以为企业提供灵活性,降低初始投资和运营成本,特别是在AI项目早期。
- 使用IaaS提供商的优势:只需为AI开发人员实际使用数据训练模型的时间付费。
- 持续监测与评估:需考虑计算资源、存储需求、云服务和本地基础设施的管理及成本控制。设立有效的评估机制,评估AI项目对业务的影响,根据反馈进行调整。
1.9 ML模型部署策略
- 在选择合适的ML模型并确保基础设施支持后,可将代码部署到生产环境。
- 模型部署是动态过程,需持续监控模型性能。为防止模型性能衰退和数据漂移,需评估模型的重新训练频率和训练数据的更新策略。例如房地产数据快速变化时,可能需频繁更新和重新部署模型。
- 模型衰减(Model Decay):随时间推移,数据底层模式变化会导致模型性能下降。
- 数据漂移(Data Drift):新数据与训练数据分布差异增大,导致预测准确性降低。
- 部署策略
| 策略 | 定义与流程 | 适用场景 | 优缺点 | 案例 |
|---|---|---|---|---|
| 影子部署(Shadow) | 新旧模型并行运行,新模型处理相同实时请求但不向用户展示结果,仅作性能对比测试。 | ①需验证新模型效果②零风险业务场景③模型架构重大变更时。 | 优:隔离用户风险。 缺:无法观察用户行为。 | 流媒体公司测试新推荐系统:新旧算法并行处理用户数据,仅旧模型输出结果,对比两者处理效果。 |
| A/B测试 | 同时部署两个差异较小的模型,将用户流量分流至不同模型,基于预设假设对比转化指标,选择性能更优模型正式部署 | ①需量化模型商业价值②功能微调验证③转化率优化场景。 | 优:直接对比用户行为,验证假设。 缺:需严格分组;模型差异过大时难以归因效果差。 | 电商公司分2组测试新旧定价算法,对比销售额/用户参与度/转化率等指标。 |
| 金丝雀部署(Canary) | 渐进式扩大用户覆盖范围:先向小部分用户(Canary组)开放,监控反馈并修复问题,分阶段逐步推广至全体用户。 | ①高风险功能上线②用户敏感型变更③需控制故障影响面。 | 优:风险可控,快速回滚 缺:部署周期长;小样本可能无法代表全体用户。 | 社交APP测试照片编辑功能:首批仅向5%用户开放,收集反馈后逐步开放。 |
Ch2 AI产品的模型开发与维护
2.1 新产品开发(NPD)的各个阶段
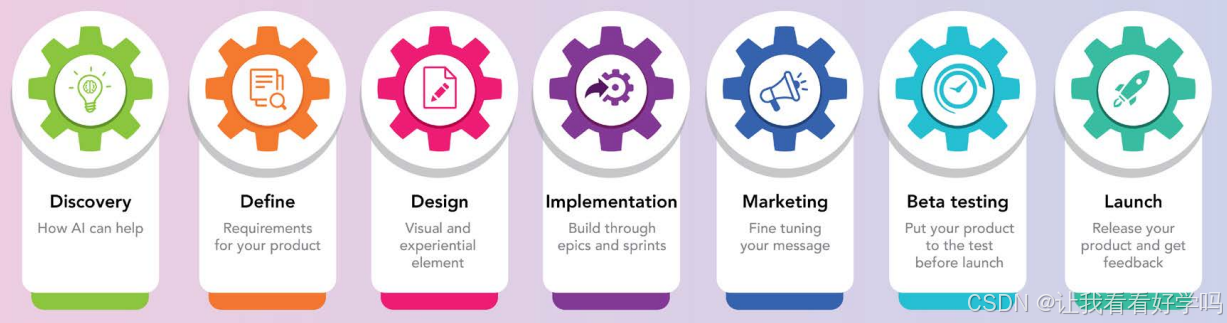
1. 发现阶段(Discovery):明确待解决的市场需求,并判断是否需AI/ML介入。
- 识别问题:头脑风暴,识别需求。
- 找到“为什么”:解答为何选择AI/ML而非传统规则或算法。。
- 收集反馈:收集客户反馈,分析市场,探索潜在解决方案。
2. 定义阶段(Define):确定最小可行产品(MVP)的范围。
- 筛选想法:分析并选择最有潜力解决客户最大问题的方案。
- 确定最少功能:明确MVP所需的基本功能,解决客户主要问题。
- 定义性能指标:设定模型的最低性能要求,确保可行性。
- 迭代改进:快速推出MVP后,通过客户反馈不断优化产品。
3. 设计阶段(Design):制定MVP原型。
- 构建交互框架与视觉体验元素:定义用户界面(UI)、体验流程(UX)及后端接口标准(如API端点结构、命名约定等)。
- 模型选型评估:基于产品特性筛选合适的AI模型,设定性能基准。
- 用户预期管理:搭建用户参与的设计验证闭环,设定性能目标,以便验证早期核心逻辑可行性。
4. 实施阶段(implementation):将规划转为可运行的MVP。
- 关键角色:产品/数据/ML工程师,UI/UX设计师。
- 验证标准:MVP需满足定义阶段设定的标准。
5. 营销阶段(Marketing):宣传产品价值(如何改善用户生活)。
- 传达信息:拥有可行MVP后,传递给更广泛的市场。
- 明确价值主张:确定如何有效传达产品的价值主张。
- AI产品特殊性:避免过度宣传或隐瞒AI能力,防止误解或信任危机。
- 平衡透明性与商业机密:避免过度泄露技术细节,同时确保用户能够清楚产品AI能力。
- 利益相关者一致性:与所有利益相关者达成一致,确定最佳营销方式。
6. 测试阶段(Beta testing):通过真实用户反馈验证产品表现。
- 发布测试版:在选定用户中进行产品测试,收集反馈。
- 管理期望:管理客户对产品性能及误差范围的期望,确保他们了解产品的局限性。
- 识别问题:在发布前早期识别错误或用户体验问题。
7. 发布阶段(Launching):正式将产品推向市场。
- 回顾标准:检查最终版本是否达到最初设定的性能指标及用户期望。
- 市场验证分析:收集用户反馈,评估产品的市场接受度。
- 持续迭代规划:规划可扩展目标(如模型优化、功能迭代等)。
流程核心特征:
- MVP驱动:以最小投入验证核心假设,降低开发风险。
- 数据与模型对齐:定义阶段明确要求数据质量和模型性能。
- 用户参与闭环:从发现到测试阶段均需用户反馈支持决策。
- 动态迭代:AI产品需持续优化模型和用户体验。
2.2 OKRs
在AI产品管理中使用各指标来衡量产品有效性。
1. OKRs(目标与关键结果)
- OKRs的设置:涵盖技术与业务层面,选择两/三个目标开始,为每个目标设置三到五个的关键结果。关注结果,而非实现这些结果的任务。
- 示例:
- 目标:通过提升产品质量来提高客户满意度。
- 关键结果:Q4结束前,①产品净推荐值(NPS)从60提高到70;②客户支持工单减少30%;③产品停机减少到1%以下。
2. 目标与KPIs
- 1)AIOps的常见KPIs
- 分类指标:评估模型如何将标签或类别分配给数据点。
- 准确率、精确率、特异性、召回率、F1分数。
- 回归指标:测量模型预测连续值的准确性。
- 平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)、R平方。
- 聚类指标:评估模型如何将数据点分组。
- 轮廓系数、Davies-Bouldin指数、同质性、完整性。
- NLP指标:评估处理和生成文本的模型质量。
- BLEU分数、ROUGE分数、困惑度。
- 分类指标:评估模型如何将标签或类别分配给数据点。
- 2)IT运营与维护指标:检测时间(MTTD)、确认时间(MTTA)、解决时间(MTTR)、故障间隔时间(MTBF)、服务可用性(AI程序正常运行的时间)、事件与工单率、自动与手动解决比例、用户报告与自动检测比例等。
2.3 训练
1. 数据要求
- 真实场景数据优先:初期可能需要使用第三方/公开数据。后期可与客户建立合作获取真实业务数据,避免过度依赖第三方数据集。
- 数据多样性:数据覆盖多样化用户(除非针对特定群体),防止样本偏差导致系统性歧视。
2. 模型调优
- 最小化损失函数:持续优化损失函数,降低预测误差。模型越准确,损失越小。
- 迭代超参数调优:调整关键超参数(如随机森林的树数量、神经网络的层数)。
- 测试不同模型:通过R平方等指标对比性能。
3. 验证标准:达到NPD定义阶段(Step 2)承诺的性能基准。
4. 模型比较示例(不同模型在相同任务下的表现差异)
- 比较不同模型(OLS回归、随机森林、KNN),使用性能指标(R平方)评估模型优劣。
- R平方是衡量模型拟合度的指标,表示自变量对因变量变异的解释程度。值越接近1,表示模型对数据的拟合越好。
- 1)普通最小二乘(OLS)回归模型
- OLS回归模型(最简单的)作为基准模型,为后续模型的性能提供了一个参考点。OLS模型使用80/20数据拆分,R平方为0.889(测试集的)。

- 2)随机森林模型:使用10次交叉验证,R平方为0.963,优于OLS模型。
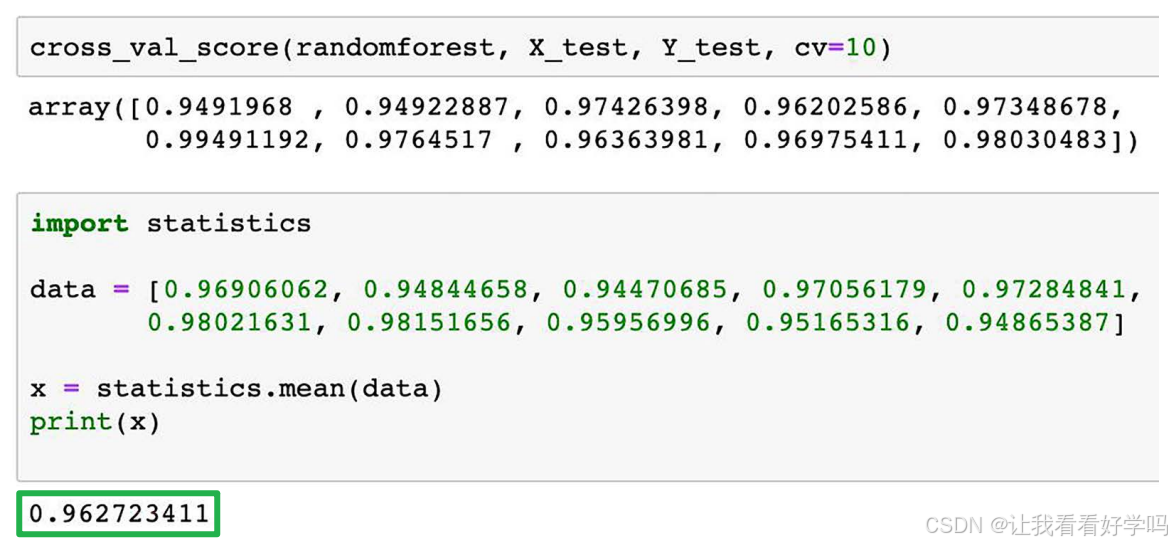
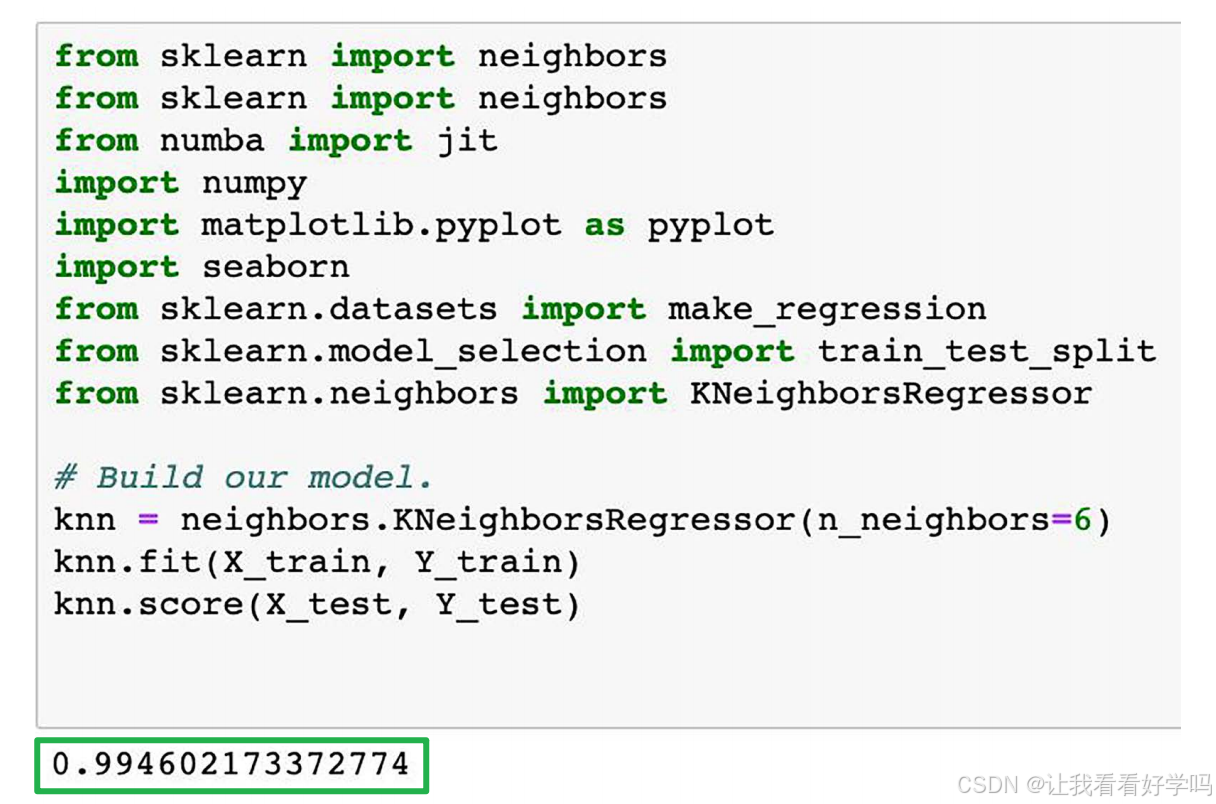
- 3)KNN模型:选择超参数为6,表示进行预测时,模型会考虑与目标点最近的6个邻居(训练样本)。R平方为0.994,显示出最佳性能,但接近1的得分也可能暗示过拟合风险。
- 过拟合:模型在训练数据上表现很好,但在新数据上表现不佳。产品经理应对过于理想的模型结果保持怀疑态度。
2.4 部署
训练完成后,部署是将模型投入生产环境的重要步骤。成功的部署不仅包括模型的上线,还涉及管理客户预期、团队协作、环境分析和用户培训等多个方面。
1. 部署策略:根据产品性质(B2B或B2C)划分
- B2B产品:侧重广泛用户的更新管理,更新通常是分阶段进行的,根据不同用户群体管理更新接收情况。
- B2C产品:注重个别客户的定制化体验,客户的期望管理更重要,模型和训练数据因客户而异。
2. 数据共享与隐私:部署过程中如何处理客户数据
- 某些客户对数据使用持谨慎状态,可能同意提供历史数据用于训练,但不希望这些数据用于提升其他客户的模型性能。
- 某些客户则持开放心态,希望使用所有数据来训练模型,以提高模型性能。
- 部署过程中,需平衡客户对数据使用的期望与模型性能的提升,妥善处理数据共享问题。
3. 环境分析:在部署模型前,ML工程师需分析部署环境,包括访问模型的最佳方式(通常通过API)、调用频率、所需的计算资源及如何持续输入数据。
4. 用户培训:通过应用内提示或团队培训,帮助用户理解如何使用AI产品功能。
2.5 测试和故障排除(troubleshooting)
1. 持续维护的四大支柱:持续集成 / 交付 / 训练 / 监控
- 持续监控:即使模型正常工作,仍需定期监控,确保没有滞后。
- 性能指标:包括准确率、召回率等。监控过程应自动化,以便在某些指标超过阈值时及时发出警报。
- 文档和支持代码的维护:除了监控模型本身外,还需定期记录,持续维护支持代码和文档。但这点常被忽视,实际遇到问题时往往依赖于少数开发人员的经验。
2. 模型部署后的关键挑战
- 模型性能下降:模型会随着时间推移出现性能下降或漂移,尤其是当数据未经过适当清洗时。
- 概念漂移:客户对正确预测的期望也可能会发生变化。例如,新的治疗方法或患者群体的变化可能会影响对模型预测结果的评定。
3. 使用数据科学平台跟踪部署情况:推荐使用具有强大版本控制、变更跟踪、与现有工具集成、具备详细日志记录的工具。
- 开源工具示例:MLflow、DVC、Weights&Biases、Comet、Neptune.ai
2.6 模型更新的伦理挑战
- 模型风险:知识与现实的脱节(生成式AI知识更新滞后)、自动化偏见与危害放大、人类依赖与替代风险。
- 从立法角度看,AI仍处于较为混乱的阶段。随着AI应用的不断扩大,相关法规也会逐步完善。AI产品经理需关注国内外的法律动态,提前做好产品设计和管理的调整。目前,产品经理可参考欧盟的AI伦理原则,帮助避免客户流失、负面影响和法律风险。
- 欧盟AI伦理原则:尊重人类自主权、防止伤害、公平性、透明可解释性。
- 企业责任与伦理实践
- 全员培训伦理意识,避免将责任推给单一岗位(如AI伦理官)。
- 模型全生命周期管理,平衡更新频率与成本,定期监控模型漂移。
- 即使模型效果正常,仍需评估其对社会未直接使用模型者的间接影响(如面部识别技术对隐私的侵蚀)。
- 遵循相关法规建立风险分类和应对流程,提前披露产品风险(如用户协议中的算法局限性说明),防范法律和声誉风险。