【最新最完整】SpringAI-1.0.0开发MCP Server,搭建MCP Client 实战笔记(进阶+详细+完整代码)
前言
在我前面的笔记中,以及完整实现了SpringAI开发的完整项目
既然是大模型的项目,肯定和MCP脱不开关系,而MCP可以帮我们更好的实现Function Calling
如果不清楚MCP和Function Calling有什么区别,可以去看我之前的笔记
目前网络上绝大部分SpringAI开发MCP的笔记和帖子,用的都是SpringAI-M7、M6甚至更古早的版本
SpringAI-1.0.0正式版改了一些接口,导致大家如果看之前的笔记,学习过程会比较坎坷
因此我过关斩将把问题全部解决之后,完善了之前的项目,也新建了一个demo,大家可以自选学习
同样我也会把源码分享出来
1.Spring AI实现MCP Server
实现的具体方式,是Spirng AI MCP提供了一个MCP Server和Client的启动器
Server启动器的官方介绍

看着很高大上,其实我翻译一下
就是SpringBoot把MCP协议的相关配置给你打包好,然后便于我们直接开发MCP Server
不太了解什么事MCP Server的同学也可以看我之前讲FC和MCP的笔记
简单来讲,就是自己设计一套符合MCP协议的项目,这个项目里面有很多Tool函数,然后打包好暴露给外界
这样就可以让其他人复用
1.1.依赖引入
SpringAI开发MCP Server有三种依赖方式
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-server-webmvc</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-server-webflux</artifactId></dependency>这里先强调一点,我给的依赖是目前官方最新的,这个依赖配置会随着不同版本变化,现在的依赖就和M7M6不一样
因此希望大家学习这种前沿一点的新技术,要多看官方文档!要多看官方文档!要多看官方文档!
官方文档网址:MCP Server Boot Starter :: Spring AI 参考
这三种依赖我简单讲一下区别
1.1.1.Standard MCP Server
标准的MCP Server
spring-ai-mcp-server-spring-boot-starter
只支持STDIO传输,如果不清楚STDIO和SSE的话,可以去了解一下MCP的三大核心通信模式
我这里先直接讲特点这是最基础的数据传输方式,适合单词低延迟的交互,一般用于本地开发与测试
1.1.2.WebMVC Server Transport
基于SpringMVC的MCP Server
spring-ai-starter-mcp-server-webmvc
这个既支持STDIO也支持SSE
SSE传输是基于HTTP协议的,具体的细节大家可以去自己了解
我这里也是直接讲特定,主要是用于开发好的Server直接启动一个web端口,然后让其他Client进行调用
适用于一些需要实时性要求的情况
1.1.3.WebFlux Server Transport
基于Spring WebFlux的MCP Server
我对WebFlux也不是很了解,这里只简单告诉大家
WebFlux是非阻塞式的,MVC是阻塞式的,前者的并发效率会更高一点
这个同样支持STDIO也支持SSE
最后附上我查阅到的一些资料链接
SpringWebflux与SpringMVC性能对比及适用场景分析_spring webflux适用于什么场景-CSDN博客
深度解析:MCP三大核心通信模式STDIO、SSE与Streamable HTTP的终极指南! - 知乎
1.1.4.Maven具体依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.4.3</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.hfutai</groupId><artifactId>mcp-server-test</artifactId><version>0.0.1-SNAPSHOT</version><name>mcp-server-test</name><description>mcp-server-test</description><url/><licenses><license/></licenses><developers><developer/></developers><scm><connection/><developerConnection/><tag/><url/></scm><properties><java.version>17</java.version><spring-ai.version>1.0.0</spring-ai.version></properties><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-server-webflux</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--Lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.22</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>这里需要注意,一些必要的版本要求如下
-
Java运行环境。要求JDK版本17+,
-
Springboot版本。需要使用springboot3以上版本。
然后我这里使用的是WebFlux,用于后续展示STDIO和SSE两种方式
1.1.5.application配置
spring:
# main:
# web-application-type: none
# banner-mode: offai:mcp:server:name: autho-info-serverversion: 1.0.0server:port: 9090name和version随便配
上面的web-application-type和banner-mode我下面会讲干啥的
然后把端口设置一下,不要和Client冲突就行
1.2.代码实现
1.2.1.Tool设计
所谓Tool设计,就是你当前这个MCP Server能具体提供哪些功能模块的服务
每一个Tool就是一个函数,只不过需要使用一些特殊的注解,这一块其实和之前SpringAI的FC开发是完全一样的
直接上代码
@Servicepublic class OpenMyBlogTool {// 目标博客首页 URLprivate static final String BLOG_HOME_URL = "https://blog.csdn.net/2201_75669520?type=blog";@Tool(name = "get-author-info", description = "获取作者信息")public AuthorInfo getAuthorInfo() {// 填写基本信息AuthorInfo authorInfo = new AuthorInfo();authorInfo.setAuthorIntroduction("GM,一名普通的00后程序员");authorInfo.setContact("vx:673274849");authorInfo.setBlogHomeUrl(BLOG_HOME_URL);List<Blog> blogList = new ArrayList<>();OkHttpClient client = new OkHttpClient();// 1. 发送 HTTP 请求获取网页 HTMLString htmlContent = getHtmlContent(client, BLOG_HOME_URL);if (htmlContent == null || htmlContent.isEmpty()) {System.err.println("无法获取网页内容");return authorInfo;}// 2. 解析 HTML 提取博客信息blogList = parseBlogsFromHtml(htmlContent);authorInfo.setBlogList(blogList);return authorInfo;}/*** 发送 HTTP GET 请求,获取网页 HTML 内容*/private String getHtmlContent(OkHttpClient client, String url) {Request request = new Request.Builder().url(url)// 模拟浏览器请求头,避免被识别为爬虫.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36").build();try (Response response = client.newCall(request).execute()) {if (response.isSuccessful() && response.body() != null) {return response.body().string(); // 返回 HTML 字符串} else {System.err.println("请求失败,响应码:" + response.code());return null;}} catch (IOException e) {System.err.println("网络请求异常:" + e.getMessage());e.printStackTrace();return null;}}/*** 解析 HTML 内容,提取博客标题、简介和 URL*/private List<Blog> parseBlogsFromHtml(String htmlContent) {List<Blog> blogList = new ArrayList<>();if (htmlContent == null || htmlContent.isEmpty()) {return blogList;}// 1. 将 HTML 字符串解析为 Document 对象Document doc = Jsoup.parse(htmlContent);// 2. 定位所有博客条目:每篇博客都包裹在 <article class="blog-list-box"> 标签中Elements blogArticles = doc.select("article.blog-list-box");// 3. 遍历每个博客条目,提取信息for (Element article : blogArticles) {Blog blog = new Blog();// 3.1 提取 URL:博客链接在 <article> 下的第一个 <a> 标签的 href 属性中Element linkElement = article.selectFirst("a"); // 找到博客对应的 <a> 标签if (linkElement != null) {String url = linkElement.attr("href"); // 获取 href 属性值(博客详情页链接)blog.setUrl(url);}// 3.2 提取标题:标题在 <a> 标签内的 <h4> 标签中Element titleElement = article.selectFirst("a h4"); // 定位 <a> 下的 <h4> 标签if (titleElement != null) {String title = titleElement.text().trim(); // 去除首尾空格和多余换行blog.setTitle(title);}// 3.3 提取描述:描述在 <div class="blog-list-content"> 标签中Element descElement = article.selectFirst("div.blog-list-content"); // 定位描述标签if (descElement != null) {String description = descElement.text().trim(); // 去除首尾空格blog.setDescription(description);}// 4. 过滤无效数据(标题和 URL 不为空才添加到列表)if (blog.getTitle() != null && !blog.getTitle().isEmpty()&& blog.getUrl() != null && !blog.getUrl().isEmpty()) {blogList.add(blog);}}return blogList;}}可以看到,我只设计了一个Tool,主要功能是获取作者的一些信息
返回DTO设计
@Data@NoArgsConstructor@AllArgsConstructorpublic class AuthorInfo {@ToolParam(description = "作者介绍")private String authorIntroduction;@ToolParam(description = "联系方式")private String contact;@ToolParam(description = "博客首页地址")private String blogHomeUrl;@ToolParam(description = "博客列表")private List<Blog> blogList;}@Data@NoArgsConstructor@AllArgsConstructorpublic class Blog {@ToolParam(description = "文章标题")private String title;@ToolParam(description = "内容描述")private String description;@ToolParam(description = "文章链接")private String url;}包括自我介绍、联系方式、博客网址、文章列表
可以看到,我都加了ToolParam注解,这样可以通过description让大模型知道这些字段的含义
另外,获取博客的文章列表,我用到了okhttp3和jsoup的工具,用于实时获取当前博客的信息
当然,你也可以设计为从数据库当中获取,但是那样就不是实时更新的了
除此之外,还可以获取到博客的粉丝数、浏览量等信息,我这里暂时没有添加
主要想达到的效果就是一个实时性,还记得我之前讲的STDIO和SSE吗,这种实时的功能就是需要通过SSE实现的
具体的可以接着往下看
1.2.2.注册暴露MCP方法
初始化ToolCallbackProvider的Bean对象,注册上面配置的Tools类
@Configurationpublic class ToolCallbackProviderConfig {@Beanpublic ToolCallbackProvider OpenMyBlogTool(OpenMyBlogTool openMyBlogTool) {return MethodToolCallbackProvider.builder().toolObjects(openMyBlogTool).build();}}当然,如果你不想专门写个Config类,也可以在启动类当中直接初始化Bean
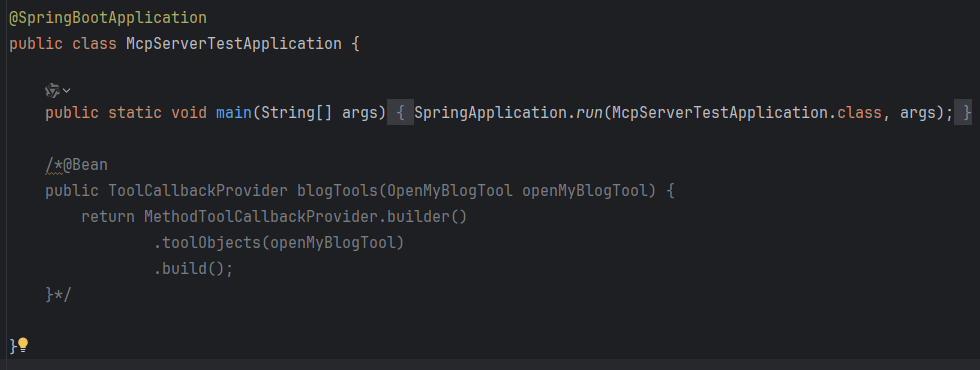
这一步的作用是为了把你的Tool暴露在外,可以被调用
1.2.3.启动MCP Server

启动web之后,如果能看到registered tools这一行,后面为你写的tool数量,那么就启动成功了
这样你的Server就被暴露在你设置的端口下了,其他项目就可以通过MCP Client去找到你暴露Server里面暴露的Tools进行调用
这里分清楚,1.2.2是暴露Tools,1.2.3.启动Server是暴露服务
2.Spring AI实现MCP Client
2.1.依赖引入
2.1.1.Maven具体依赖
核心的依赖只有下面这两个
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-client-webflux</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>但是因为我是在本来的大模型应用项目上进行MCP Client开发,所以说还需要其他依赖
具体的可以看我之前的文章
比如做大模型应用必备的大模型依赖
<!--OpenAI--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId></dependency>2.1.2.application配置
这一块很关键,好好看
spring:ai:openai:base-url: https://dashscope.aliyuncs.com/compatible-modeapi-key: ${OPENAI_API_KEY}#对话模型chat:options:model: qwen-max-latest # 会话模型名称mcp:client:toolcallback:enabled: truename: mcp-clientstdio:servers-configuration: classpath:/mcp-server-config.json # MCP服务配置enabled: truetype: ASYNCsse:connections:author-info-server:url: http://localhost:9090除了上面大模型相关的配置之外,需要仔细看的是mcp相关的配置
这些配置也会随着版本不同更换名称,所以说还是那句老话
多去看官方文档!!!
toolcallback: enabled: true 这个必须配置,不然Client无法通过函数回调获取Tools
type: ASYNC 这个是因为我们使用的Flux,走的非阻塞式,需要设置为异步
然后就是stdio和sse了
这一块我单独讲
2.1.3.STDIO配置
可以看到stido下面,我配置了一个json文件
{"mcpServers": {"baidu-map": {"command": "cmd","args": ["/c","npx","-y","@baidumap/mcp-server-baidu-map"],"env": {"BAIDU_MAP_API_KEY": "LEyBQxG9UzR9C1GZ6zDHsFDVKvBem2do"}}}}如果说之前在其他ai插件上使用过mcp的同学,一眼就可以看出来
这其实就是外部mcp server的一个导入json文件
我们可以在很多mcp server网站上,看到别人开发好的mcp server
例如mcp.so
想要导入其他人开发好的server,就需要通过配置
这里就需要提到,目前主流的server导入方式,只有python和npx(nodejs)
我这里使用的是nodejs,需要大家去下载配置一下,可以看下面这个视频教程
Nodejs安装零基础教程2025哔哩哔哩bilibili
上面我代码配置的,就是百度的MCP Server,可以去网站上看到其他Server的配置,然后加到json里面就好了
配置好的Server意味着你后面就可以让你的大模型去使用了
到这里就会有一个疑问,主包主包,我可以调用其他人写好的,那我自己写好的可以让其他人调用吗?
有的兄弟有的
这就是我接下来要讲的,如何把自己写好的Server打包,让其他人或者其他项目调用
我们刚刚配置的Server启动器的时候,是需要把web启动,然后通过端口调用,那怎么样可以不通过HTTP的方式,而是直接打包调用呢?
其实很简单,JAVA的程序,打包好就是jar包的形式,我们需要先去修改Server的配置
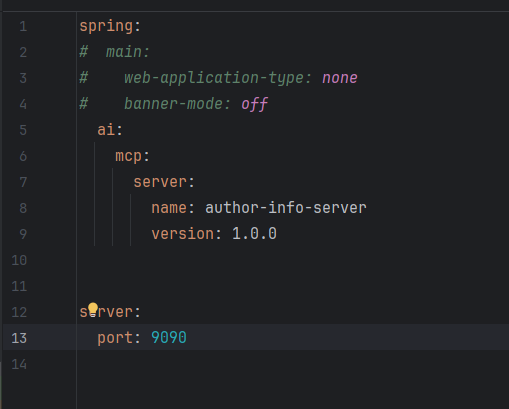
还记得我之前说的吗,上面那个main相关配置的注释,现在就要把注释取消掉
这个注释的主要作用就是,不启动web服务,并且关闭web启动时候的横幅
开启这三行注释之后,我们利用Maven的package对Server进行打包
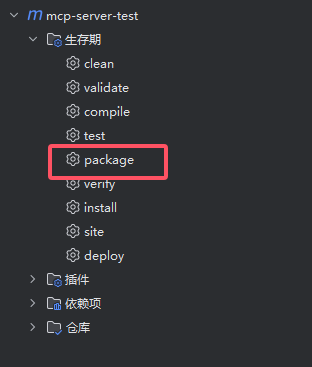
打包完成之后,可以在target目录下找到我们的jar包
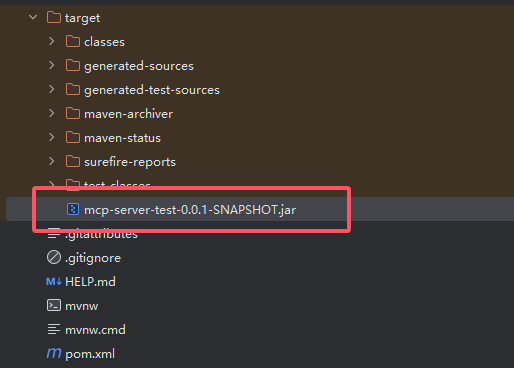
复制jar包的绝对路径,绝对路径,绝对路径!!!
例如我的就是这样:
D:\JavaStudy\013-AIchat\mcp-server-test\target\mcp-server-test-0.0.1-SNAPSHOT.jar
然后你就可以在本来的json当中添加如下配置
或者说在其他的ai插件当中,配置你自己的Server了
"my-csdn-server": {"type": "stdio","command": "java","args": ["-Dspring.ai.mcp.server.stdio=true","-jar","D:/JavaStudy/013-AIchat/mcp-server-test/target/mcp-server-test-0.0.1-SNAPSHOT.jar"]}2.1.4.SSM配置
sse:connections:author-info-server:url: http://localhost:9090配置的格式是
sse:connections:[name]:url:
其中name可以自己设置
这个其实就是你自己起的服务,然后web启动,通过url访问即可
两种方式讲完,我来说说我自己项目当中的使用方式
我通过STDIO的方式,配置了多个外部的Server,来增强我AI聊天模块的功能
通过通过SSE的方式,本地起了author-info-server,用于实时的查看博客的信息
我后续加入了对阅读、点赞、收藏、评论数的获取,这样可以更加直观体现SSE的优势
效果如下

这些信息都是实时从网页上查到的
这种与从数据库里面或者内存当中获取,底层逻辑不同
由此可见,很多特殊需求和场景,是需要用到SSE的
2.2.代码实现
2.2.1.配置ChatClient
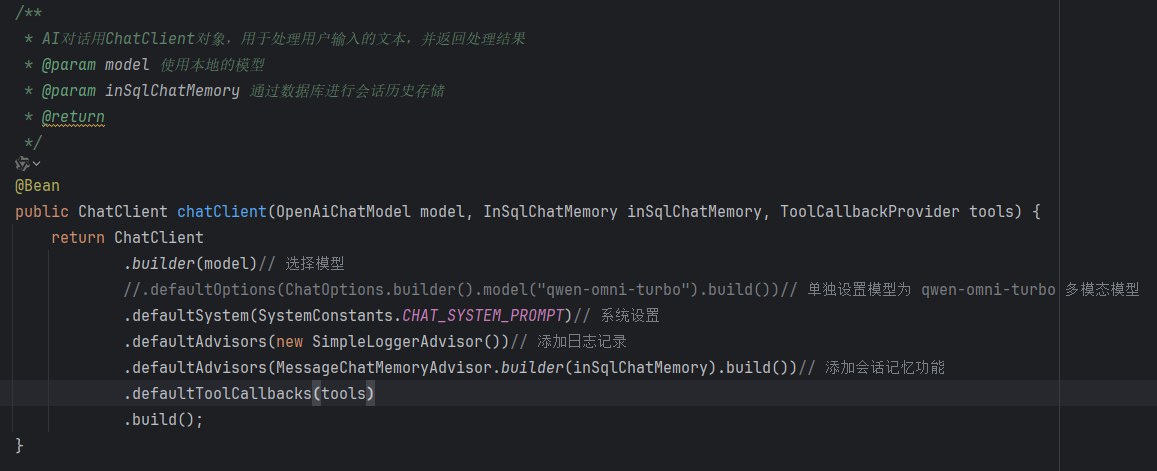
这里是我上个项目的代码
感兴趣的,想要了解springAi的同学,可以去看我之前的文章
这里的关键是,传入 ToolCallbackProvider 这个类的参数
然后通过 .defaultToolCallbacks() 设置
这里需要注意一个问题
可以看到我把多模态的模型设置给注释掉了
需要注意,在使用MCP的时候,或者说FC,都需要去看这个模型支不支持
有些模型是不支持MCP的
2.2.2.配置一下相关的prompt
为了能让大模型应用带给用户更好的体验,我们可以专门为tools设置一下提示词

2.2.3.启动MCP Client
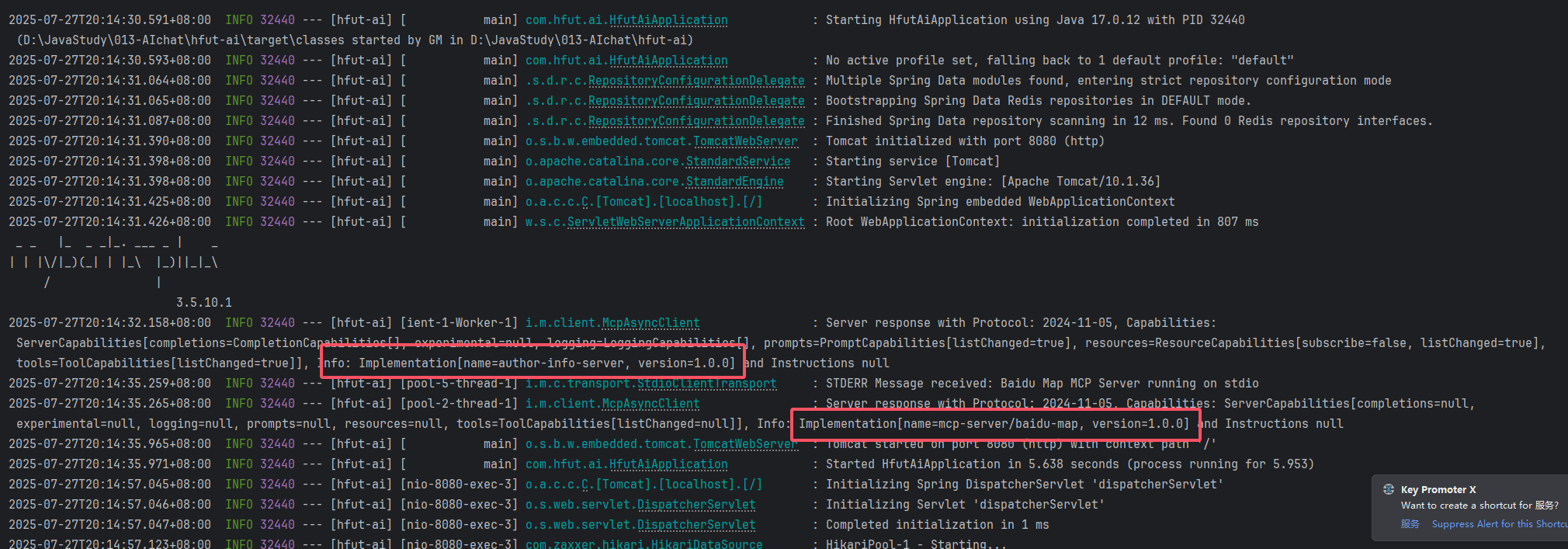
可以看到,先是成功启动了SSE的Server,因为是本地地址调用,一下就能打通
然后是启动baidu的Server,当然,面对具体的场景,我们还可以添加其他的Server
3.实际演示
tools服务介绍

了解作者信息


百度Server提供的天气查询

百度Server提供的路线查询

4.总结
可以看到
实装了MCP的大模型应用,功能远超出之前的普通大模型应用
我们现在不管是在网站上还是app上的大模型,本质上都是接入了超多MCP和知识库的大模型应用
如果只是通过API调用大模型,其实大模型的知识会很局限,并且实时性很低
而MCP非常直接和高效的解决了这个问题
不仅如此
MCP更加战略级的意义是,提高了Server的复用性
不管是跨模型还是跨企业还是跨部门还是跨项目的时候
同一个Server只要打包好,就可以提供给其他人使用
自己开发的Server,一些和自己有关的工具Server,只要符合MCP的协议
就可以在多个项目当中使用,我认为这才是MCP最核心的价值体