3.5-非关系型数据库-反规范化-sql语言
一、非关系型数据库(案例重点)
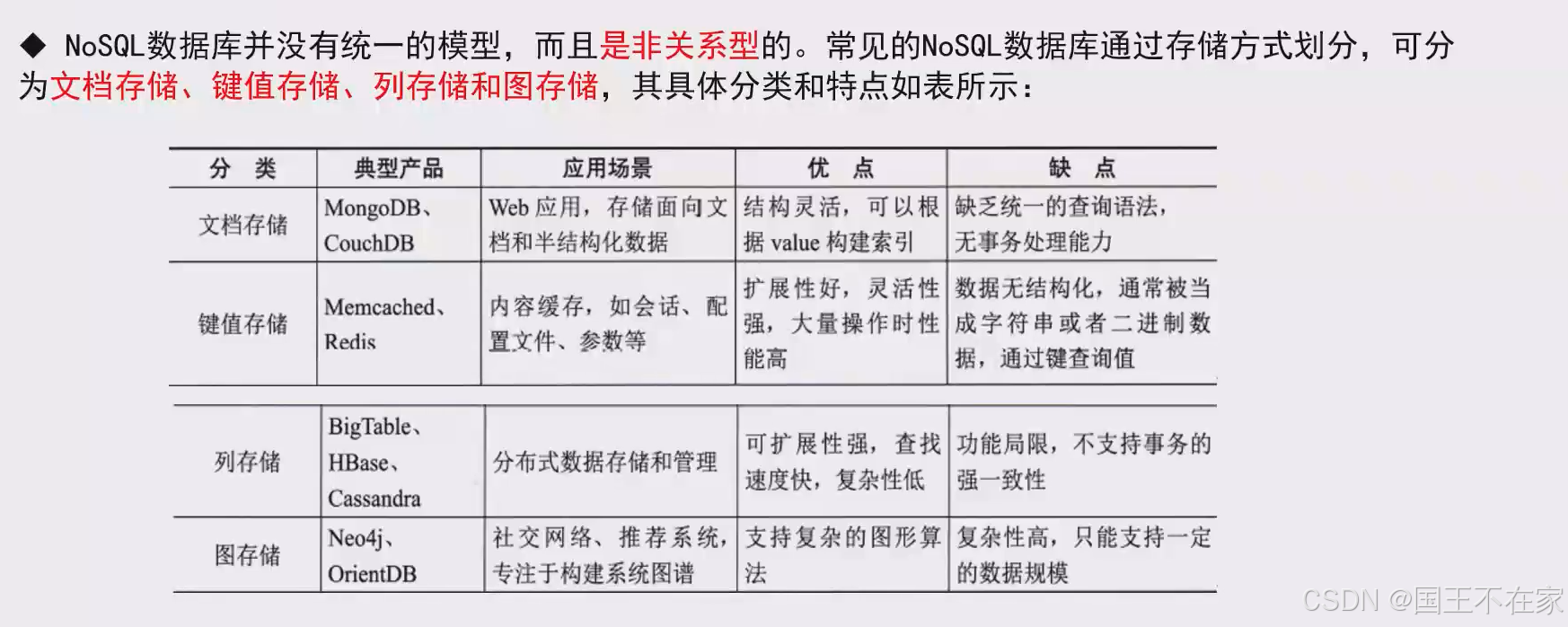
非关系型数据库按存储方式划分:
- 文档存储:MongoDB、CouchDB
- 键值存储:Redis
- 列存储:HBase
- 图存储:OrientDB
CAP理论
关系型数据库事务的基本理论是ACID(强硬)
CAP: 三个特点3选2
- 一致性(C:Consistency):做了某些操作后仍处于一致(数据一致)的状态,所有节点在同一时刻有相同的数据。
- 可用性(A:Availability):所有操作都有响应。
- 分区容忍性(P):网络发生故障时,物理节点发生故障,其他分区的数据库还能继续运行。
由于CAP的存在,为了提高性能,出现了ACID的变种:BASE,即弱一致性理论。基本可用、无连接、最终一致性。
如果选择CP,那就要考虑ACID,因为需要强硬执行,所以需要ACID
如果选择了AP那就要考虑BASE,即放弃强硬执行,追寻最终一致性。
如果选择了CA,那么在网络发生分区是,就不能进行完整的操作。

分区
分区的主要方法
- 内存缓存:使用频率最高的数据复制到缓存中,提高传输速度。
- 集群:为用户提供服务时的透明性,用户感知不到有分区的存在。
- 读写分离:指定一台或多台服务器,所有或部分的写操作被送至此,同时在设定一定数量的副本服务器满足读的请求。
- 范围分割技术\分片:负载均衡。不会让某个服务器负担很重,大家一起来负担访问量。

存储布局
存储布局确定【如何访问磁盘,以及如何直接影响性能】
分为:
- 行存储和列存储:关系型数据库就是行存储,OLTP操作;列存储是用于非关系型数据库,OLAP操作。列存储查询更优,只需要查询少数几个字段,并且更容易设计更好的压缩、解压算法。
- 带有局部性群组的列存储:根据需要将原本不存储在一起的数据,以列为单位存储在单独的子表中。
- LSM-Tree:解决日志记录索引的问题,以满足高效、高性能、安全的读写要求。

文档存储:mongoDB

键值存储

二、反规范化
目的:将表合并,提高查询效率。
具体反规范化的方法:
- 增加冗余列:多个表保留相同列,减少查询时的连接操作。
- 增加派生列:增加数据计算生成的列。
- 重新组表:将两个表重新组表。
- 水平分割表:将数据放在多个独立表中,适用数据规模较大。
- 垂直分割表:对表进行分割,主键与一部分列生成新表,主键与另一部分生成新表。

习题

1、操作记录在日志文件中
数据存储在数据文件中
2、数据仓库4大特点:相对稳定性 。
三、SQL语言(重要)

操作数据
1、查询: select 列 from 表1,表2 where 条件 age>18
2、分组查询:group by 列 having(条件)
【select 列1,avg(score) from t1 group by 列1 having(avg(score)>60)】
goupy by 的列名需要和前面的列名保持一致,且需要用到聚合函数。
3、更名: select sno as "学号" form t1
4、字符串匹配:%匹配多个字符、_ 匹配任意一个字符。
【select * from t1 where name like 'a_'】可以是ab\ac等a开头只有两个字符的数据。
5、排序:order by sno desc 。 desc代表降序

其他操作
distinct:只保留重复的数据中的一条记录。
union :两条SQL进行或操作,存在与第一或第二句的都会被选出
intersect :两条SQL进行交操作,同时存在的才会被选出
min\avg\max

习题
1

解答:
1NF
A
有聚合函数,用零件号进行分组,group by 需要和前面的列保持一致,所以是group by 零件号。
2

1、abcdefg 7个
2、π投影1367对应, R.A,R.C,R.F,R.G A选项
3、R,S
4、B,o选择3<6。