MySQL 全详解:从入门到精通的实战指南
目录
MySQL简介
一、MySQL存储引擎
二、MySAM VS InnoDB
2.1 背景
2.2 核心特性对比
2.3 适用场景
2.3.1 MyISAM 适用场景
2.3.2 InnoDB 适用场景
三、索引(InnoDB)
3.1 聚簇索引&辅助索引
3.1.1 工作流程
3.1.2 索引失效
①聚簇索引失效
②辅助索引失效
🔍如何判定索引失效?
3.2 联合索引
3.2.1 底层原理(MySQL--InnoDB为例)
1)核心原理:按顺序构建 “有序结构”
2)生效规则:“前缀匹配” 是关键
3.2.2
1)最左前缀原则
2)联合索引如何B+树中存储
四、事务
事务加锁机制
五、大表优化
①垂直分表
②水平分表
六、日志文件
七、MVCC(多版本并发控制)
八、SQL优化(思考题)
MySQL简介
最原始的计算器只是卡片输入,卡片输出,计算机只有计算能力,根本就没有数据库;后来随着发展,人人都能支付起一台电脑,想在计算机上衍生出来一些娱乐,那么此时存储就成了计算机的一大难题。像记事本,world等原始存储数据的软件,慢,乱且不方便不安全;于是一些小型的数据库软件应运而生。
数据库研究出来就是为了管理数据而生,具备增删改查能力,并且能够保障断电后仍存储(也就是数据本质存储在硬盘中)

但是在国内,PostgreSQL的应用流行度并比不过MySQL(尤其是阿里)
一、MySQL存储引擎
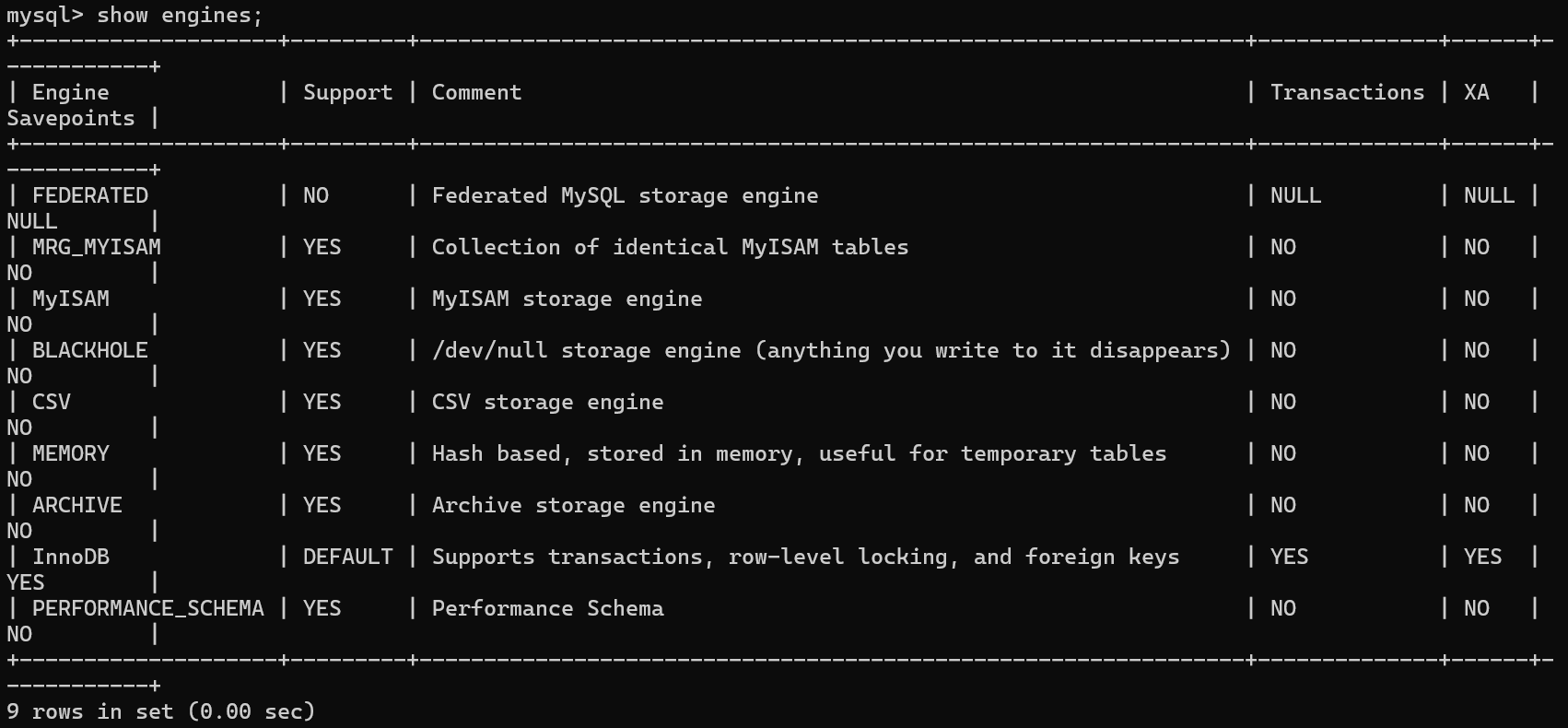
①查看存储引擎(可以在软件中查看,或是在终端输入mysql后查看)--输入以下命令:
show engines;
②查看系统默认存储引擎
show variables like '%storage_engine%';
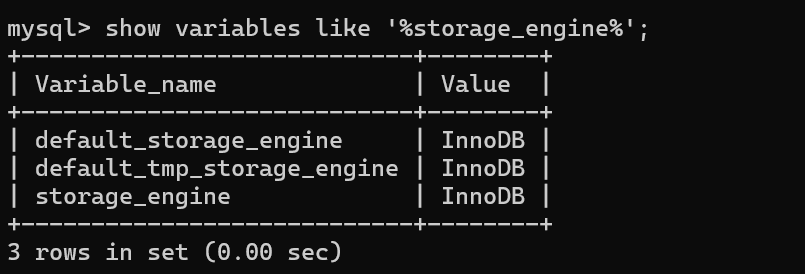
💡MyISAM是MySQL的默认数据库引擎(5.5版之前);不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。可以看见上面系统默认的就是InnoDB。
二、MySAM VS InnoDB
2.1 背景
- MyISAM:MySQL 早期的默认存储引擎(MySQL 5.5 版本前),设计侧重于读取性能优化,但不支持事务和复杂并发控制。
- InnoDB:目前 MySQL 的默认存储引擎(MySQL 5.5 及以后),由 Oracle 开发,以事务支持、崩溃恢复和高并发写性能为核心设计目标。
2.2 核心特性对比
| 特性 | MyISAM | InnoDB |
|---|---|---|
| 事务支持 | 不支持(无 ACID 特性) | 支持(完全符合 ACID:原子性、一致性、隔离性、持久性) |
| 锁机制 | 仅支持表级锁(读锁 / 写锁) | 支持行级锁(默认)+ 表级锁(特殊场景,如全表扫描) |
| 外键支持 | 不支持 | 支持(可通过FOREIGN KEY定义关联) |
| 存储结构 | 每个表对应 3 个文件: - .frm:表结构定义- .MYD:数据文件(MyData)- .MYI:索引文件(MyIndex) | 每个表默认对应 2 个文件(独立表空间模式): - .frm:表结构定义- .ibd:数据 + 索引文件(InnoDB Data) |
| 索引类型 | 非聚簇索引(索引与数据分离,索引指向数据物理地址) | 聚簇索引(主键索引与数据存储在一起,二级索引指向主键) |
| 崩溃恢复 | 不支持崩溃后自动恢复(可能因断电等导致数据文件损坏,需手动执行myisamchk修复) | 支持崩溃自动恢复(依赖redo log和undo log:崩溃后通过日志重放恢复数据一致性) |
| 并发性能 | 写操作(插入 / 更新 / 删除)会加表级写锁,阻塞所有读 / 写请求(读操作加表级读锁,可并发读) | 行级锁支持 “写不阻塞读、读不阻塞写”(仅冲突行阻塞),高并发写场景下性能更优 |
| 自动增长列(AUTO_INCREMENT) | 需通过表级锁保证自增唯一性(高并发插入时可能卡顿) | 通过 “自增锁优化”(innodb_autoinc_lock_mode)支持无锁自增(默认模式下,批量插入也可高效生成自增 ID) |
| 全文索引 | 原生支持全文索引(早期唯一支持该功能的引擎) | MySQL 5.6 及以后支持全文索引(功能与 MyISAM 类似,但结合事务特性更稳定) |
| 空间索引 | 支持(如地理信息数据索引) | 支持(且结合事务和行锁,更适合地理数据的并发操作) |
2.3 适用场景
2.3.1 MyISAM 适用场景
- 读多写少的场景(如新闻网站、博客的文章表,用户访问以读为主,更新频率低);
- 无需事务和数据一致性的场景(如日志表、临时统计报表);
- 对存储占用敏感的场景(如历史归档数据,可通过压缩表节省空间)。
2.3.2 InnoDB 适用场景
- 需要事务支持的场景(如电商订单、支付系统,需保证 “下单 - 扣库存 - 支付” 的原子性);
- 高并发写操作的场景(如用户信息表、商品库存表,频繁更新且需并发支持);
- 对数据可靠性要求高的场景(如金融数据、用户核心数据,需崩溃自动恢复);
- 需要外键约束的场景(如订单表与用户表的关联,通过外键保证数据完整性)。
三、索引(InnoDB)
引入索引的主要目的:加快查询速度。
MySQL索引主要使用的两种数据结构:BTree&&Hash
💡MySQL索引主要使用两种数据结构,就是BTree和Hash,但是现在的MySQL使用InnoDB的引擎,而InnoDB不支持Hash。
- InnoDB 表 → 只有 B+Tree(+AHI)
- MySQL 整体 → 仍支持 HASH,但仅限 MEMORY/NDB 等引擎
3.1 聚簇索引&辅助索引
💡“聚簇索引”和“辅助索引”只是 InnoDB 中对主键索引和非主键索引的物理实现方式(也就是说InnoDB中的非聚簇索引就是指辅助索引):
- 聚簇索引:数据是存放在叶子节点上的。
- 辅助索引:叶子节点上是不存放真实数据的,而是存放聚簇索引的索引值。
3.1.1 工作流程
- 聚簇索引(主键)查数据:主键值 → 直接在聚簇索引 B+ 树找到叶子页 → 叶子页里就是完整行 → 取出返回。
- 辅助索引(二级索引)查数据:索引键值 → 在辅助索引 B+ 树找到叶子页 → 叶子页只存主键值 → 拿主键值再回聚簇索引查一次 → 拿到完整行返回(若查询列全在辅助索引里,则省掉回表)。
🔍什么是回表?在辅助索引中,拿到主键值去聚簇索引,这种二次回树的操作叫做“回表”。🔍为什么能省掉回表呢?这就要知道什么叫“查询列全在辅助索引中”,这边可以举一个例子:比如把 (name, age) 设成联合索引,这两列就是键列,会被完整地写进该索引的所有叶子节点;再加上 InnoDB 的“潜规则”——每一张辅助索引都必须带主键 id,于是叶子节点里最终有 (name, age, id) 三份数据。此刻,执行"SELECT name, age FROM t WHERE name='A'; "语句时—— 不回表。
3.1.2 索引失效
简单来说就是:优化器经过成本估算后,放弃使用索引,改为全表扫描或大范围扫描。
聚簇索引和辅助索引都会失效,只是触发的条件不一样。
①聚簇索引失效
基本不会,因为它就是主键索引,数据按主键顺序物理存放。
唯一可能“看起来失效”的场景:
• 写了 WHERE 非主键列 = ? —— 本来就没用到聚簇索引,自然谈不上失效;
• 写了 WHERE 主键 = 非最左前缀(如 WHERE id+1 = 7)—— 表达式让主键索引无法直接定位,于是退化为全表。
②辅助索引失效
相较于聚簇索引,辅助索引失效的场景就很多了。
- 函数/运算:WHERE DATE(create_time) = '2023-05-01' 或 age+1=20。
- 前模糊:LIKE '%abc'。
- 最左前缀中断:联合索引 (a,b,c) 却只写 WHERE b=1 AND c=1。
- OR 条件:WHERE a=1 OR b=2(两列分别走不同索引或无法合并)。
- 隐式类型转换:WHERE code = 123(code 是 varchar)。
- NULL 判断:WHERE col IS NULL(普通索引对 NULL 支持有限)。
- 范围之后:(a,b,c) 中出现 a>10 AND b=5,b 用不上。
- 数据倾斜/选择性差:优化器认为扫表更快。
- 强制全表:使用 FORCE INDEX 但成本高被忽略,或直接 IGNORE INDEX。
🔍如何判定索引失效?
explain关键字的使用详解:SQL 调优第一步:EXPLAIN 关键字全解析_pgsql explain关键字-CSDN博客
3.2 联合索引
在同一个 B+Tree 中,把多列的值按“指定的先后顺序”组织成一个复合键(composite key),这棵 B+Tree 就是联合索引(composite / compound / multi-column index)。
3.2.1 底层原理(MySQL--InnoDB为例)
1)核心原理:按顺序构建 “有序结构”
联合索引的底层通常以 B + 树 为数据结构(和单字段索引一致),但排序规则是 按索引定义的字段顺序逐级排序。
例如,对表中 (A, B, C) 三个字段创建联合索引,B + 树的排序逻辑是:
- 先按字段 A 排序;
- 当 A 的值相同时,再按字段 B 排序;
- 当 A 和 B 的值都相同时,最后按字段 C 排序。
这种排序方式使得索引树中,相同 A 值的记录会聚集在一起,且内部按 B 有序;相同 A+B 的记录又按 C 有序,类似 “字典先按首字母、再按第二个字母排序” 的逻辑。
2)生效规则:“前缀匹配” 是关键
联合索引的查询生效依赖 “前缀匹配原则”:只有当查询条件中包含索引的 “前缀字段” 时,索引才可能被使用,且从第一个不匹配的字段开始,后续字段无法利用索引排序。
仍以 (A, B, C) 为例:
- 有效场景:
- where A = ?(匹配前缀 A,可利用索引);
- where A = ? and B = ?(匹配前缀 A+B,可利用索引);
- where A = ? and B = ? and C = ?(匹配全部前缀,完全利用索引)。
- 部分有效场景:
- where A = ? and C = ?:仅 A 能利用索引(C 不是前缀,无法通过索引定位 C,需扫描 A 相同的记录后过滤 C)。
- 无效场景:
- where B = ? 或 where B = ? and C = ?(缺少前缀 A,无法利用索引,会全表扫描);
- where A > ? and B = ?(A 是范围查询,后续 B 无法利用索引排序,仅 A 有效)。
💡【注】当索引为(a,b,c)时,下面的这俩个匹配都是有效的:
- where a=xx and b>443 and c=32;
- where c=32 and b =-123 and a =123;
当查询条件中的所有判定都是 等值条件(=) 时,数据库通常会自动优化条件顺序,使其匹配联合索引的字段顺序,因此从结果上看,确实 “不严格要求查询条件的书写顺序”。但这并不意味着联合索引本身的顺序不重要,而是数据库通过 查询重写(Query Rewrite) 技术帮你调整了条件顺序。
3.2.2
1)最左前缀原则
简单而言就是:从联合索引的左边开始,连续匹配到哪一列,索引就用到了哪一列;中间断掉的那一列之后的列就都用不上索引了,但前面已经匹配的部分仍然有效
2)联合索引如何B+树中存储
-
存储规则:按索引定义的列顺序(如
col1→col2→col3)排序,先按首列排,首列相同则按次列排,以此类推;B + 树节点存储完整列组合及对应数据定位信息(如主键)。 -
查询特性:遵循 “最左前缀匹配”,必须从首列开始查询,跳过中间列会导致后续列无法用索引;若查询列全在索引中,可直接从索引获取(索引覆盖),避免回表。
-
设计关键:高频过滤、区分度高的列放前面;避免冗余(如
(col1,col2)已包含col1单列索引功能);注意范围查询会使后续列索引失效。
四、事务
事务加锁机制
乐观锁+悲观锁+页锁(简单了解)MySQL锁、加锁机制(超详细)—— 锁分类、全局锁、共享锁、排他锁;表锁、元数据锁、意向锁;行锁、间隙锁、临键锁;乐观锁、悲观锁-腾讯云开发者社区-腾讯云
五、大表优化
①垂直分表
垂直分表某种意义上来说没什么意义,所以这里不做过多赘述。
②水平分表
水平分库分表在高并发项目场景中比较常见,所以后面会有文章单独详解,这里先不做过多讲解。
六、日志文件
🔍MySAM没有事务,但是InnoDB有事务,所以在binlog,undolog,redolog中,它是缺少了哪一个?
| 日志类型 | MyISAM | InnoDB |
| undo log | ❌ 不支持 | ✅ 支持(事务回滚) |
| redo log | ❌ 不支持 | ✅ 支持(崩溃恢复) |
| binlog | ✅ 支持 | ✅ 支持 |
七、MVCC(多版本并发控制)
这个比较重要,后面会有文章单独讲解。
八、SQL优化(思考题)
🔍1.有没有排查过慢sql的问题?2.如何定位慢SQL(也就是执行时间超过1s的sql)?